ROCm上来自Transformers的双向编码器表示(BERT)
14.8. 来自Transformers的双向编码器表示(BERT) — 动手学深度学习 2.0.0 documentation (d2l.ai)
代码
import torch
from torch import nn
from d2l import torch as d2l#@save
def get_tokens_and_segments(tokens_a, tokens_b=None):"""获取输入序列的词元及其片段索引"""tokens = ['<cls>'] + tokens_a + ['<sep>']# 0和1分别标记片段A和Bsegments = [0] * (len(tokens_a) + 2)if tokens_b is not None:tokens += tokens_b + ['<sep>']segments += [1] * (len(tokens_b) + 1)return tokens, segments#@save
class BERTEncoder(nn.Module):"""BERT编码器"""def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,ffn_num_hiddens, num_heads, num_layers, dropout,max_len=1000, key_size=768, query_size=768, value_size=768,**kwargs):super(BERTEncoder, self).__init__(**kwargs)self.token_embedding = nn.Embedding(vocab_size, num_hiddens)self.segment_embedding = nn.Embedding(2, num_hiddens)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module(f"{i}", d2l.EncoderBlock(key_size, query_size, value_size, num_hiddens, norm_shape,ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数self.pos_embedding = nn.Parameter(torch.randn(1, max_len,num_hiddens))def forward(self, tokens, segments, valid_lens):# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)X = self.token_embedding(tokens) + self.segment_embedding(segments)X = X + self.pos_embedding.data[:, :X.shape[1], :]for blk in self.blks:X = blk(X, valid_lens)return Xvocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000, 768, 1024, 4
norm_shape, ffn_num_input, num_layers, dropout = [768], 768, 2, 0.2
encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input,ffn_num_hiddens, num_heads, num_layers, dropout)tokens = torch.randint(0, vocab_size, (2, 8))
segments = torch.tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
encoded_X = encoder(tokens, segments, None)
encoded_X.shapetokens = torch.randint(0, vocab_size, (2, 8))
segments = torch.tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
encoded_X = encoder(tokens, segments, None)
encoded_X.shapemlm = MaskLM(vocab_size, num_hiddens)
mlm_positions = torch.tensor([[1, 5, 2], [6, 1, 5]])
mlm_Y_hat = mlm(encoded_X, mlm_positions)
mlm_Y_hat.shapemlm_Y = torch.tensor([[7, 8, 9], [10, 20, 30]])
loss = nn.CrossEntropyLoss(reduction='none')
mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape(-1))
mlm_l.shape#@save
class NextSentencePred(nn.Module):"""BERT的下一句预测任务"""def __init__(self, num_inputs, **kwargs):super(NextSentencePred, self).__init__(**kwargs)self.output = nn.Linear(num_inputs, 2)def forward(self, X):# X的形状:(batchsize,num_hiddens)return self.output(X)encoded_X = torch.flatten(encoded_X, start_dim=1)
# NSP的输入形状:(batchsize,num_hiddens)
nsp = NextSentencePred(encoded_X.shape[-1])
nsp_Y_hat = nsp(encoded_X)
nsp_Y_hat.shapensp_y = torch.tensor([0, 1])
nsp_l = loss(nsp_Y_hat, nsp_y)
nsp_l.shape#@save
class BERTModel(nn.Module):"""BERT模型"""def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,ffn_num_hiddens, num_heads, num_layers, dropout,max_len=1000, key_size=768, query_size=768, value_size=768,hid_in_features=768, mlm_in_features=768,nsp_in_features=768):super(BERTModel, self).__init__()self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,ffn_num_input, ffn_num_hiddens, num_heads, num_layers,dropout, max_len=max_len, key_size=key_size,query_size=query_size, value_size=value_size)self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),nn.Tanh())self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)self.nsp = NextSentencePred(nsp_in_features)def forward(self, tokens, segments, valid_lens=None,pred_positions=None):encoded_X = self.encoder(tokens, segments, valid_lens)if pred_positions is not None:mlm_Y_hat = self.mlm(encoded_X, pred_positions)else:mlm_Y_hat = None# 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))return encoded_X, mlm_Y_hat, nsp_Y_hat
代码解析
这段代码是基于PyTorch框架实现的BERT(Bidirectional Encoder Representations from Transformers)模型。BERT是一种预训练语言表示模型,它可以用于各种自然语言处理(NLP)任务。下面是代码的中文解析:
1. get_tokens_and_segments(tokens_a, tokens_b=None) 函数用于获取输入句子的词元(tokens)及其对应的片段索引。如果有第二个句子 tokens_b,则会进行拼接,并用不同的索引来标识不同的句子。
2. BERTEncoder 类定义了BERT的编码器结构,它包含嵌入层(用于将词元转换为向量表示)、位置嵌入和多个Transformer编码块。
3. forward 方法定义了模型的前向传播逻辑。它将输入的词元和片段索引通过编码器进行编码,并返回编码后的向量表示。
4. 其中 tokens 是批量输入数据的词元索引,`segments` 是对应的片段索引,这里模拟了输入数据作为模型的示例。
5. 创建一个 BERTEncoder 实例,该实例就是BERT模型的编码器部分,类似于 Transformer 模型中的编码器层。
6. MaskLM 类未在代码中定义,通常用来实现BERT的掩码语言模型任务,它在一定比例的输入词元上应用掩码,并训练模型来预测这些被掩码的词元。
7. NextSentencePred 类定义了BERT的下一句预测(Next Sentence Prediction, NSP)任务,是一个简单的二分类器,用来预测给定的两个句子片段是否在原始文本中顺序相邻。
8. BERTModel 类将编码器、掩码语言模型(MaskLM),以及下一句预测(NSP)整合为完整的BERT模型。它通过前向传播来处理输入,同时能够根据需求进行掩码语言模型预测和下一句预测。
9. 模型实例化后,通过随机生成的 tokens 和 segments 调用其 forward 方法,得到编码后的向量 encoded_X,同时执行MLM和NSP任务,输出预测结果。
10. 最后计算MLM和NSP任务的损失,这些损失通常用于训练模型。`CrossEntropyLoss` 是在类别预测问题中经常使用的一个损失函数。
整体来看,这段代码展示了如何构建一个基于BERT结构的模型,其中涵盖了BERT的两个典型预训练任务:掩码语言模型和下一句预测。需要注意的是,这个代码片段作为一个解析,但实际中运行它需要额外的上下文(例如 MaskLM 类的实现)和适当的数据准备和预处理步骤。
相关文章:
ROCm上来自Transformers的双向编码器表示(BERT)
14.8. 来自Transformers的双向编码器表示(BERT) — 动手学深度学习 2.0.0 documentation (d2l.ai) 代码 import torch from torch import nn from d2l import torch as d2l#save def get_tokens_and_segments(tokens_a, tokens_bNone):""&qu…...

期权课程之第一节【用生活的例子解释什么是期权】
1、用生活的例子解释什么是期权 期权的英文名也就叫Option【选择】,实际上期权本质也就是一种选择权。 买入资产的例子 假如你【买家】看上了一套老王的【卖家】房子,现价100W、但是目前手头比较紧、但是你又不想错过这个房子,你可以先给老…...

【YOLOv10训练教程】如何使用YOLOv10训练自己的数据集并且推理使用
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...
[windows系统安装/重装系统][step-4][番外篇-2]N卡驱动重装 |解决:开机几小时后电脑卡顿 | 后台自动运行了上千个Rundll32进程问题
现象 开机几小时后,电脑变卡,打开后台管理器都卡,后台管理去转圈圈一小会儿后看到后台进程上千个,好多个Rundll32进程 重启下运行会稍快 重启后运行快,后台管理器反应也快 打开后台管理器不卡(几小时后打…...

Redis开发实战
单机部署安装 服务端下载,安装,启动去官网下载最新的版本:http://redis.io/download ,这里用的是3.0.2解压后,进入解压好的文件夹redis的安装非常简单,因为已经有现成的Makefile文件,所以直接先…...

C++ | Leetcode C++题解之第112题路径总和
题目: 题解: class Solution { public:bool hasPathSum(TreeNode *root, int sum) {if (root nullptr) {return false;}if (root->left nullptr && root->right nullptr) {return sum root->val;}return hasPathSum(root->left…...

leetcode力扣 2024. 考试的最大困扰度
一位老师正在出一场由 n 道判断题构成的考试,每道题的答案为 true (用 ‘T’ 表示)或者 false (用 ‘F’ 表示)。老师想增加学生对自己做出答案的不确定性,方法是最大化有连续相同结果的题数。(…...
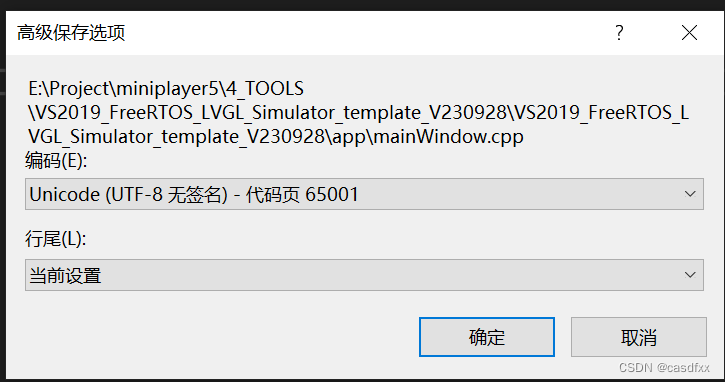
lvgl无法显示中文
环境: VS2019、LVGL8.3 问题: VS2019默认编码为GB2312, 解决: VS2022设置编码方式为utf-8的三种方式_vs utf8-CSDN博客 我用的方法2,设置为 utf-8无签名就行。...

读书笔记-Java并发编程的艺术-第1章 并发编程的挑战
文章目录 1.1 上下文切换1.1.1 多线程一定快吗1.1.2 如何减少上下文切换 1.2 死锁1.3 资源限制的挑战 1.1 上下文切换 即时是单核处理器也支持多线程执行代码,CPU通过给每个线程分配CPU时间片来实现这个机制。时间片是CPU分配给多个线程的时间,因为时间…...

RUST 和 GO 如何管理它们的内存
100编程书屋_孔夫子旧书网 Go 中的内存管理 Go 中的内存不会在缓存键被驱逐时立即释放。 相反,垃圾收集器会经常运行以发现任何没有引用的内存并释放它。 换句话说,内存会一直挂起,直到垃圾收集器可以评估它是否真正不再使用,而…...

对于高速信号完整性,一块聊聊啊(12)
常见的无源电子器件 电子系统中的无源器件可以按照所担当的电路功能分为电路类器件、连接类器件。 A、电路类器件: (1)二极管(diode) (2)电阻器(resistor) …...

C++学习笔记(19)——模板
目录 模板参数与非类型模板参数 模板参数 类型模板参数——传递类型 非类型模板参数——传递数量 C11希望array替代静态数组,但实际上vector包揽了一切 模板总结 优点: 缺点: 模板特化:针对某些类型进行特殊化处理 特化…...
java8新特性——函数式编程详解
目录 一 概述1.1 背景1.2 函数式编程的意义1.3 函数式编程的发展 Lambda表达式1.1 介绍1.2 使用Lambda的好处1.3 Lambda方法1.3.1 Lambda表达式结构1.3.2 Lambda表达式的特征 1.4 Lambda的使用1.4.1 定义函数式接口1.4.2 Lambda表达式实现函数式接口1.4.3 简化Lambda表达式1.4.…...

mybatis-plus小课堂: apply 拼接 in SQL,来查询从表某个范围内的数据
文章目录 引言I mybatis-Plus 之 apply 拼接 in SQL1.1 apply源码实现1.2 apply 拼接 in SQL : 非字符串数组1.3 apply 拼接 in SQL : 字符串数组II 如果in的数量太多,采用子查询。III 常见问题: Cause: comColumn xxx in where clause is ambiguoussee also引言 I mybati…...

民宿推荐系统-手把手调试搭建
民宿推荐系统-手把手调试搭建 民宿推荐系统-手把手调试搭建...
线性回归模型
目录 1.概述 2.线性回归模型的定义 3.线性回归模型的优缺点 4.线性回归模型的应用场景 5.线性回归模型的未来展望 6.小结 1.概述 线性回归是一种广泛应用于统计学和机器学习的技术,用于研究两个或多个变量之间的线性关系。在本文中,我们将深入探讨…...

西门子全球业务调整:数十亿欧元交易额,开启新篇章
导语 大家好,我是社长,老K。专注分享智能制造和智能仓储物流等内容。 新书《智能物流系统构成与技术实践》 导语 大家好,我是社长,老K。专注分享智能制造和智能仓储物流等内容。 在风起云涌的全球经济舞台上,西门子&am…...
AI遇上遥感,未来会怎样?
随着航空、航天、近地空间等多个遥感平台的不断发展,近年来遥感技术突飞猛进。由此,遥感数据的空间、时间、光谱分辨率不断提高,数据量也大幅增长,使其越来越具有大数据特征。对于相关研究而言,遥感大数据的出现为其提…...
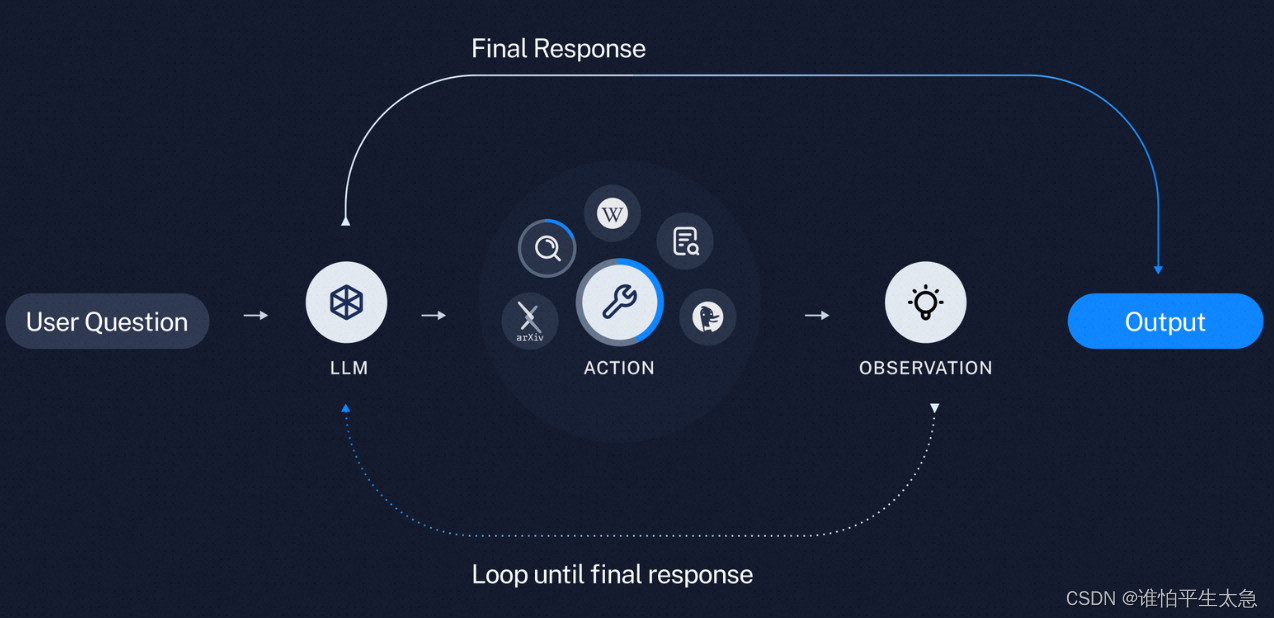
认知架构 cognitive architecture
Assistants API:以开发人员为中心。 有状态的API:允许存储以前的消息、上传文件、访问内置工具(代码解释器)、通过函数调用控制其他工具。 认知架构应用的两个组件:(1)如何提供上下文给应用 &…...

数据插值之朗格朗日插值(一)
目录 一、引言 二、代码实现 2.1 Lagrange插值求插值多项式: 代码解析: 1.vpa解释 2.ploy(x)解释: 3.conv()解释 4.poly2sym()解释 2.2 Lagrange插值求新样本值和误差估计: 代码解析&…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

万星easy-vibe:描述需求即发布 零基础无需学语法
开源Easy-Vibe是一套开源AI编程学习方案,把学习顺序从先学语法再做项目翻转为直接做项目。文章拆解了项目驱动、提示词编写、AI编辑器和多Agent协作的完整流程,解释了为什么想法比语法更重要。 github上datawhalechina/easy-vibe:它在GitHub…...

ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍
ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

昇腾CANN elec-ops-simulation 实战:电力系统仿真——潮流计算与暂态稳定分析在 NPU 上的加速
电力系统仿真:500 节点电网的牛顿-拉夫逊潮流计算 → 解 10001000 稀疏雅可比矩阵(每迭代 1 次矩阵求逆)→ CPU 迭代 15 次 2.4s。实时调度要求 < 100ms → NPU 加速:雅可比矩阵求解用 Cube 单元做批量小矩阵 LU 分解 → 每迭…...