MongoDB 覆盖索引查询:提升性能的完整指南
MongoDB 覆盖索引查询是一种优化数据库查询性能的技术,它通过创建适当的索引,使查询可以直接从索引中获取所需的数据,而无需访问实际的文档数据。这种方式可以减少磁盘 I/O 和内存消耗,提高查询性能。
基本语法
在 MongoDB 中,覆盖索引查询的基本语法如下:
db.collection.find(<query>, <projection>)
其中,<query> 是查询条件,<projection> 是投影条件。覆盖索引查询的关键在于使用投影条件,只返回查询结果所需的字段,从而避免了对实际文档的访问。
命令
MongoDB 中的覆盖索引查询主要涉及 find() 方法的使用,以及合适的索引创建。
- 创建索引:
db.collection.createIndex({ field1: 1, field2: 1, ... })
- 执行覆盖索引查询:
db.collection.find({ <query> }, { field1: 1, field2: 1, ... })
示例
假设有一个名为 users 的集合,包含以下文档:
{ "_id": ObjectId("5f1d1c6e84e190d8c53f9c76"), "name": "Alice", "age": 30, "city": "New York" }
{ "_id": ObjectId("5f1d1c6e84e190d8c53f9c77"), "name": "Bob", "age": 25, "city": "Los Angeles" }
我们可以为 name 字段创建一个索引,然后执行覆盖索引查询:
// 创建索引
db.users.createIndex({ name: 1 })// 执行覆盖索引查询
db.users.find({ name: "Alice" }, { name: 1, age: 1 })
应用场景
性能优化
覆盖索引查询在 MongoDB 中是一种重要的性能优化手段。它通过利用索引中存储的数据来满足查询的需求,避免了访问实际文档的开销,从而提高了查询性能。
示例代码:
假设有一个名为 products 的集合,其中存储了大量产品信息的文档,我们需要查询某个特定产品的价格。如果我们在 products 集合上创建了一个名为 product_name_index 的索引,包含产品名称和价格字段,那么可以通过覆盖索引查询来高效地获取产品的价格信息:
// 创建索引
db.products.createIndex({ name: 1, price: 1 });// 覆盖索引查询
db.products.find({ name: "iPhone X" }, { price: 1, _id: 0 });
这样,MongoDB 只需查找索引中的数据就能够满足查询需求,而不需要额外地读取实际的文档,大大提高了查询的效率。
减少 IO 操作
覆盖索引查询还可以帮助减少磁盘 IO 操作,因为查询操作在索引中就能得到满足,不需要读取磁盘上的实际文档数据。
示例代码:
假设我们需要查询产品价格在某个范围内的所有产品名称,我们可以通过覆盖索引查询来完成:
// 创建索引
db.products.createIndex({ price: 1 });// 覆盖索引查询
db.products.find({ price: { $gte: 500, $lte: 1000 } }, { name: 1, _id: 0 });
这样,MongoDB 可以直接利用索引中的数据完成查询操作,而不需要读取实际文档数据,从而减少了磁盘 IO 操作。
数据一致性检查
覆盖索引查询还可以用于检查索引中的数据与实际文档中的数据是否一致,有助于发现和纠正数据不一致的问题。
示例代码:
假设我们需要检查产品名称和价格在索引中的数据是否与实际文档中的数据一致,我们可以通过覆盖索引查询来进行检查:
// 覆盖索引查询
var cursor = db.products.find({}, { name: 1, price: 1, _id: 0 });
cursor.forEach(function(doc) {var indexData = db.products.find({ name: doc.name }).explain("executionStats").executionStats;if (indexData.totalDocsExamined > 1) {print("Data inconsistency found for product: " + doc.name);}
});
这段代码会遍历所有文档,对比索引中的数据与实际文档中的数据是否一致,如果存在不一致的情况,则输出相关信息,有助于发现和解决数据一致性问题。
注意事项
索引字段选择
在 MongoDB 中,选择合适的字段创建索引是非常重要的。通常情况下,应该选择经常被查询的字段作为索引,这样可以加快查询的速度,提高系统的性能。在选择索引字段时,需要考虑以下几个因素:
- 频繁查询的字段:经常用于查询条件或排序的字段应该被优先选择作为索引字段。
- 数据分布均匀的字段:选择数据分布均匀的字段作为索引字段可以保证索引的效率,并减少查询时的磁盘 I/O。
- 覆盖索引的字段:如果某个查询可以通过覆盖索引满足,则可以考虑将该查询的字段作为索引字段,以提高查询效率。
示例代码:
假设有一个名为 products 的集合,其中存储了大量产品信息的文档。我们需要根据产品的名称和价格进行查询,并且这两个字段经常被使用作为查询条件。因此,我们可以选择将 name 和 price 字段作为索引字段:
// 创建索引
db.products.createIndex({ name: 1, price: 1 });
通过这样的索引选择,可以加快根据产品名称和价格进行查询的速度,提高系统的性能。
索引大小
索引占用的磁盘空间和内存资源较大,需要根据实际情况进行权衡和管理。创建过多或过大的索引可能会导致磁盘空间和内存资源的浪费,甚至影响数据库的性能。因此,在创建索引时需要注意以下几点:
- 选择合适的字段创建索引:只选择必要的字段创建索引,避免创建过多的冗余索引。
- 定期清理和优化索引:定期清理和优化不再使用的索引,以释放磁盘空间和内存资源。
- 监控索引大小和性能影响:定期监控索引的大小和性能影响,根据实际情况进行调整和优化。
示例代码:
假设我们需要为 products 集合创建一个包含多个字段的复合索引,但是我们只选择了其中几个常用的字段作为索引。通过定期监控索引的大小和性能影响,我们可以根据实际情况进行调整和优化:
// 创建复合索引
db.products.createIndex({ name: 1, category: 1, price: 1 });// 监控索引大小和性能影响
var indexStats = db.products.stats().indexSizes;
var totalIndexSize = 0;
for (var key in indexStats) {totalIndexSize += indexStats[key];
}
print("Total index size: " + totalIndexSize + " bytes");
通过定期监控索引大小,我们可以及时发现索引占用空间过大的情况,并根据实际情况进行调整和优化,以保证系统的性能。
总结
覆盖索引查询是 MongoDB 中优化查询性能的一种重要技术,通过合适的索引创建和查询投影,可以有效地减少查询时间和资源消耗,提高系统的响应速度和并发能力。在设计数据库时,合理利用覆盖索引可以帮助提升整体系统性能,提供更好的用户体验。
相关文章:

MongoDB 覆盖索引查询:提升性能的完整指南
MongoDB 覆盖索引查询是一种优化数据库查询性能的技术,它通过创建适当的索引,使查询可以直接从索引中获取所需的数据,而无需访问实际的文档数据。这种方式可以减少磁盘 I/O 和内存消耗,提高查询性能。 基本语法 在 MongoDB 中&a…...

ECMAScript详解
ECMAScript(简称ES)是一种由Ecma国际(前身为欧洲计算机制造商协会,European Computer Manufacturers Association)通过ECMA-262标准化的脚本程序设计语言。以下是对ECMAScript的详细说明: 1. 定义与起源 …...
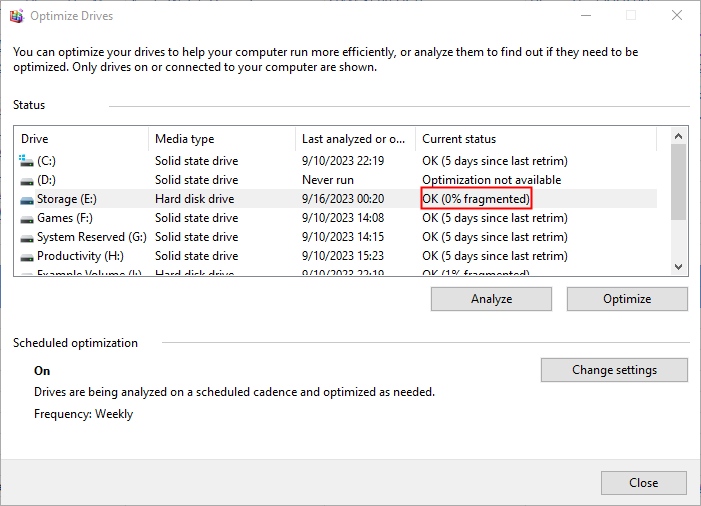
如何在Windows 10上对硬盘进行碎片整理?这里提供步骤
随着时间的推移,由于文件系统中的碎片,硬盘驱动器可能会开始以较低的效率运行。为了加快驱动器的速度,你可以使用内置工具在Windows 10中对其进行碎片整理和优化。方法如下。 什么是碎片整理 随着时间的推移,组成文件的数据块&a…...

科学高效备考AMC8和AMC10竞赛,吃透2000-2024年1850道真题和解析
多做真题,吃透真题和背后的知识点是备考AMC8、AMC10有效的方法之一,通过做真题,可以帮助孩子找到真实竞赛的感觉,而且更加贴近比赛的内容,可以通过真题查漏补缺,更有针对性的补齐知识的短板。 今天我们继续…...

SQL——SELECT相关的题目
目录 197、上升的温度 577、员工奖金 586、订单最多的客户 596、超过5名学生的课 610、判断三角形 620、有趣的电影 181、超过经理收入的员工 1179、重新格式化部门表(行转列) 1280、学生参加各科测试的次数 1068、产品销售分析I 1075、项目员工I …...

etcd集群部署
1.etcd介绍 1.1 什么是etcd etcd的官方定义如下: A distributed, reliable key-value store for the most critical data of distributed systemetcd是一个Go语言编写的分布式、高可用的一致性键值存储系统,用于提供可靠的分布式键值(key value)存储、配置共享和服务发现等…...

VBA_MF系列技术资料1-615
MF系列VBA技术资料1-615 为了让广大学员在VBA编程中有切实可行的思路及有效的提高自己的编程技巧,我参考大量的资料,并结合自己的经验总结了这份MF系列VBA技术综合资料,而且开放源码(MF04除外),其中MF01-0…...

常用激活函数学习
常用激活函数及其应用 ReLU (Rectified Linear Unit) 公式: f ( x ) max ( 0 , x ) f(x) \max(0, x) f(x)max(0,x)理解: 当输入值为正时,输出等于输入值;否则输出为0。ReLU函数简单且计算效率高,能有效缓解梯度消失问题,促进…...

html中被忽略的简单标签
1: alt的作用是在图片不能显示时的提示信息 <img src"https://img.xunfei.cn/mall/dev/ifly-mall-vip- service/business/vip/common/202404071019208761.jp" alt"提示信息" width"100px" height"100px" /> 2&#…...
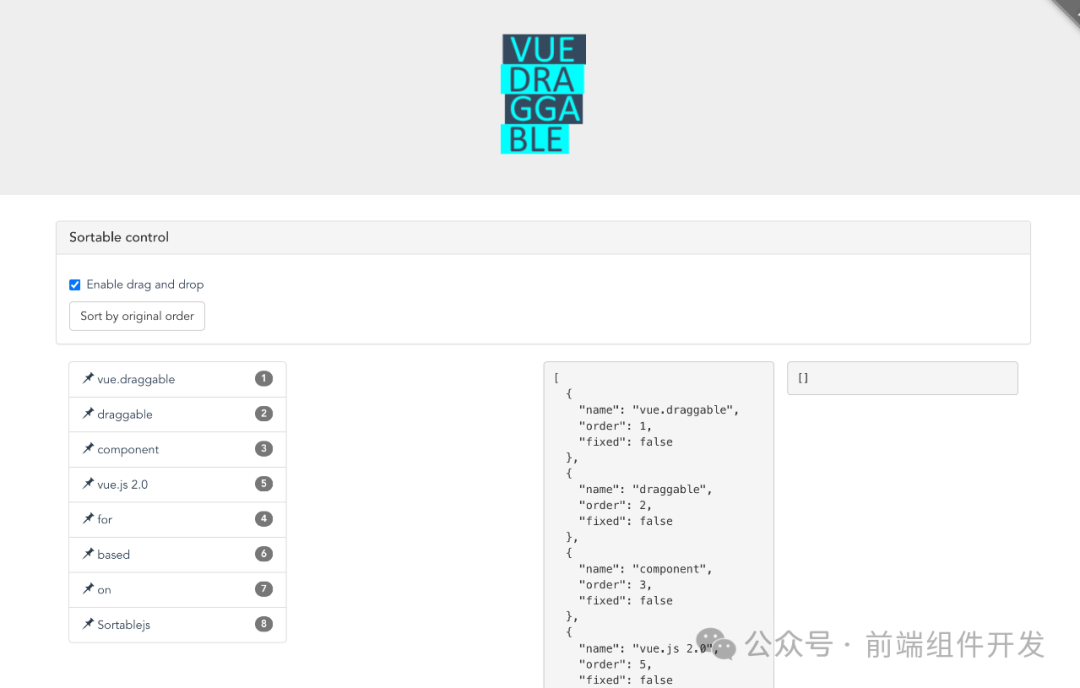
Vue.Draggable:强大的Vue拖放组件技术探索
一、引言 随着前端技术的不断发展,拖放(Drag-and-Drop)功能已经成为许多Web应用不可或缺的一部分。Vue.js作为现代前端框架的佼佼者,为开发者提供了丰富的生态系统和强大的工具链。Vue.Draggable作为基于Sortable.js的Vue拖放组件…...

linux mail命令及其历史
一、【问题描述】 最近隔壁组有人把crontab删了,crontab这个命令有点反人类,它的参数特别容易误操作: crontab - 是删除计划表 crontab -e 是编辑,总之就是特别容易输入错误。 好在可以通过mail命令找回,但是mai…...
和以数据为中心(Data-Centric)的区别)
数据驱动(Data-Driven)和以数据为中心(Data-Centric)的区别
一、什么是数据驱动? 数据驱动(Data-Driven)是在管理科学领域经常提到的名词。数据驱动决策(Data-Driven Decision Making,简称DDD)是一种方法论,即在决策过程中主要依赖于数据分析和解释&…...

aosp14的分屏接口ISplitScreen接口获取方式更新-学员疑问答疑
背景: 有学员朋友在学习马哥的分屏pip自由窗口专题时候,做相关分屏做小桌面项目时候,因为原来课程版本是基于android 13进行的讲解的,但是现在公司已经开始逐渐进行相关的android 14的适配了,但是android 14这块相比a…...
定积分求解过程是否变限问题 以及当换元时注意事项
目录 定积分求解过程是否变限问题 文字理解: 实例理解: 易错点和易混点: 1:定积分中的换元指什么? 2: 不定积分中第一类换元法和第二类换元法的本质和区别 3: df(x) ----> df(x)这…...
)
保研机试算法训练个人记录笔记(七)
输入格式: 在第1 行给出不超过10^5 的正整数N, 即参赛}人数。随后N 行,每行给出一位参赛者的 信息和成绩,包括其所代表的学校的编号(从1 开始连续编号)及其比赛成绩(百分制)…...
-查询优化(23)-避免全表扫描)
【MySQL精通之路】SQL优化(1)-查询优化(23)-避免全表扫描
当MySQL使用全表扫描来解析查询时,EXPLAIN的输出在type列中显示ALL。 这种情况通常发生在以下情况下: 该表非常小,因此执行全表扫描比查找关键字更快。这对于少于10行且行长较短的表来说很常见。 对于索引列,ON或WHERE子句中没有…...
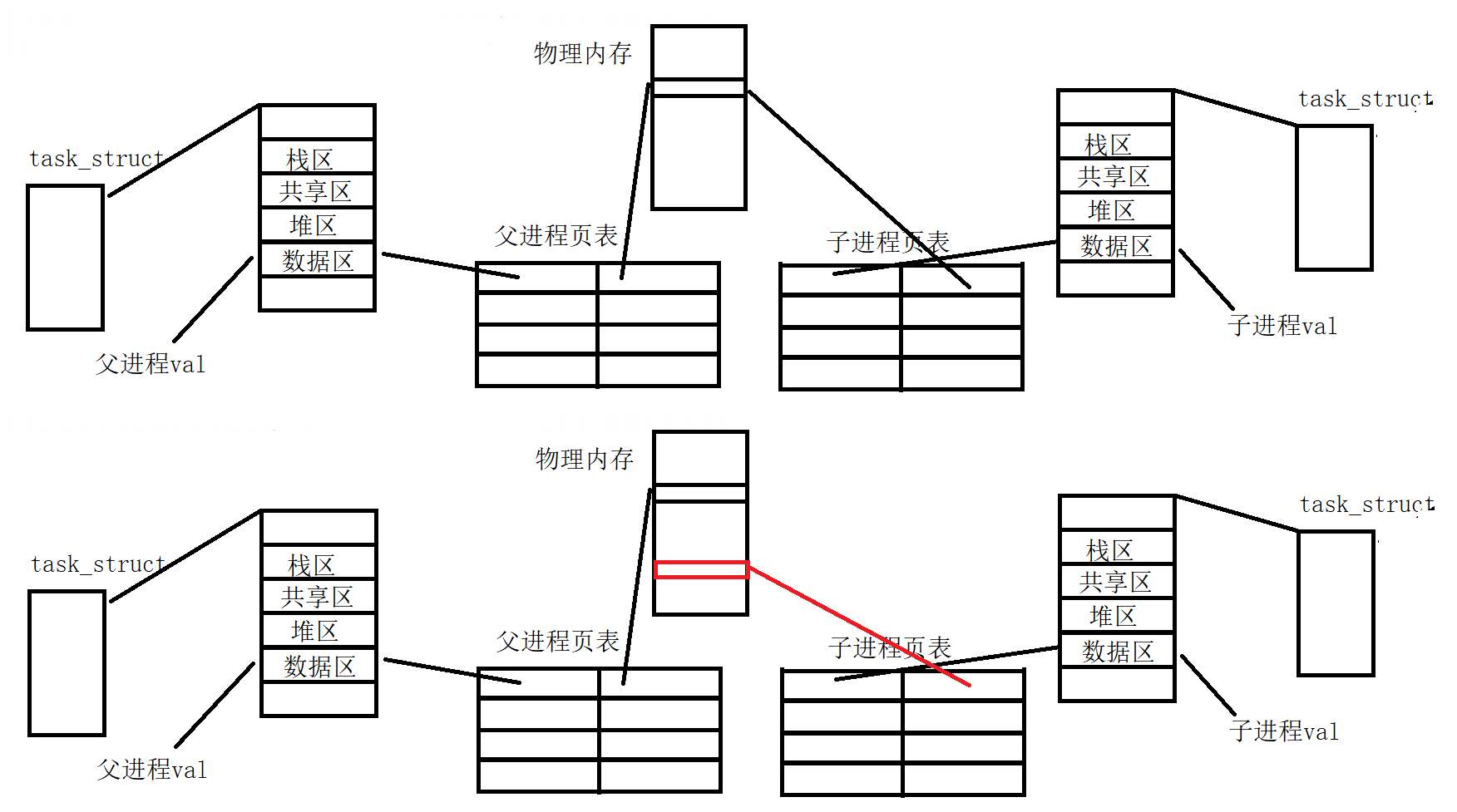
【Linux】写时拷贝技术COW (copy-on-write)
文章目录 Linux写时拷贝技术(copy-on-write)进程的概念进程的定义进程和程序的区别PCB的内部构成 程序是如何被加载变成进程的?写时复制(Copy-On-Write, COW)写时复制机制的原理写时拷贝的场景 fork与COWvfork与fork Linux写时拷贝技术(copy-…...

用python使用主成分分析数据
import pandas as pd #导入处理二维表格的库 import numpy as np #导入数值计算的库 from sklearn.preprocessing import StandardScaler #导入数据标准化模块 import matplotlib.pyplot as plt #导入画图的包 from sklearn.decomposition import PCA #导入主成…...

用WPS将多张图片生成一个pdf文档,注意参数设置
目录 1 新建一个docx格式的文档 2 向文档中插入图片 3 设置页边距 4 设置图片大小 5 导出为pdf格式 需要把十几张图片合并为一个pdf文件,本以为很简单,迅速从网上找到两个号称免费的在线工具,结果浪费了好几分钟时间,发现需要…...
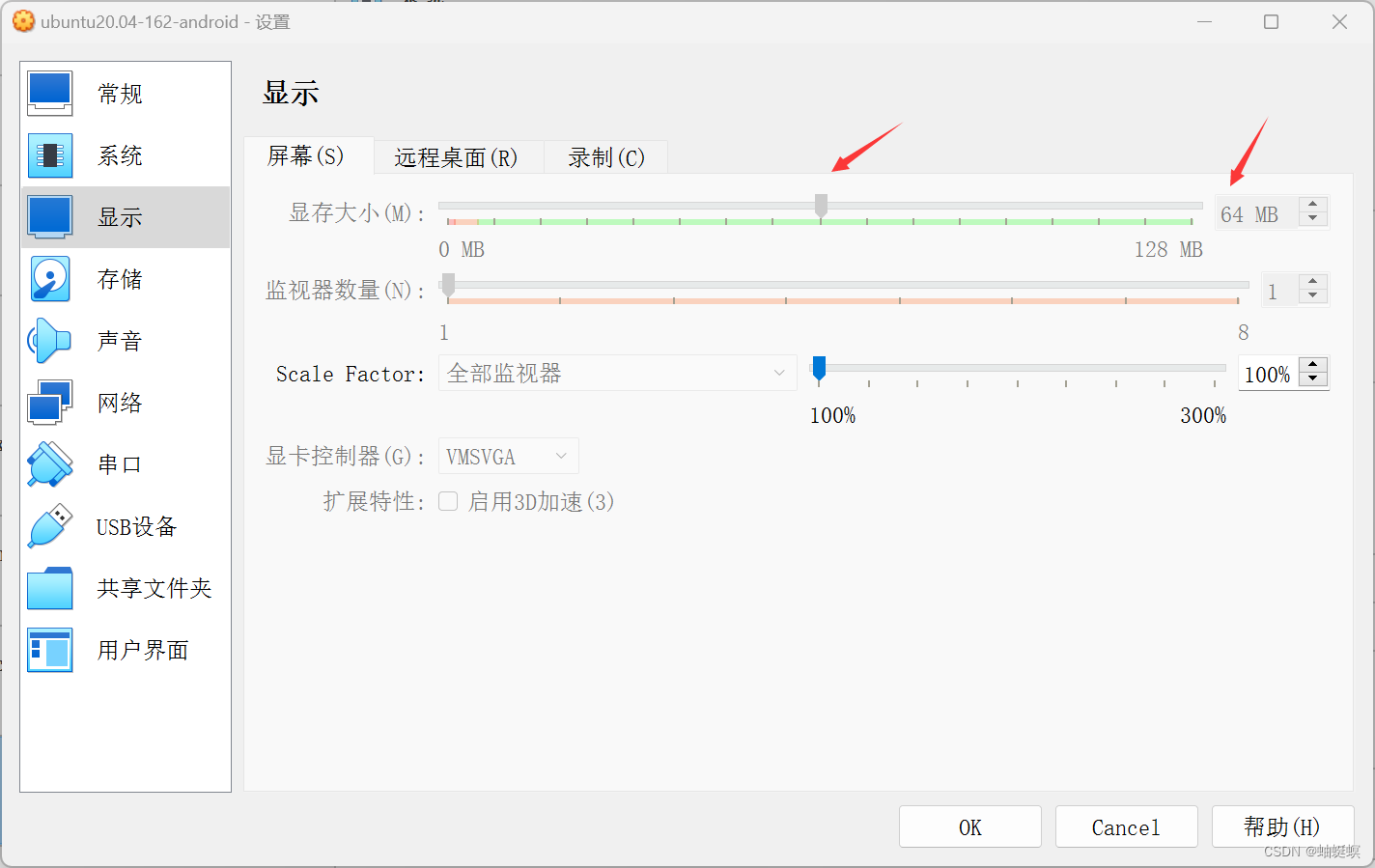
virtual box ubuntu20 全屏展示
virtual box 虚拟机 ubuntu20 系统 全屏展示 ubuntu20.04 视图-自动调整窗口大小 视图-自动调整显示尺寸 系统黑屏解决 ##设备-安装增强功能 ##进入终端 ##终端打不开,解决方案-传送门ubuntu Open in Terminal打不开终端解决方案-CSDN博客 ##点击cd盘按钮进入文…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

PentestGPT实战部署指南:AI驱动的渗透测试工作流落地
1. 这不是另一个“AI安全”的概念玩具,而是一套能真正跑起来的渗透测试辅助工作流“PentestGPT”这个名字刚在GitHub上出现时,我第一反应是点开又关掉——过去三年里,我见过太多打着“AI渗透”旗号的项目:有的只是把ChatGPT API封…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南
Unlock-Music:浏览器中一键解锁加密音乐文件的完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: http…...

独立开发者利用taotoken模型广场为不同任务选择性价比最优模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用taotoken模型广场为不同任务选择性价比最优模型 对于独立开发者而言,在有限的预算内高效完成多样化的开…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...