JVM(三)
在上一篇中,介绍了JVM组件中的类加载器,以及相关的双亲委派机制。这一篇主要介绍运行时的数据区域
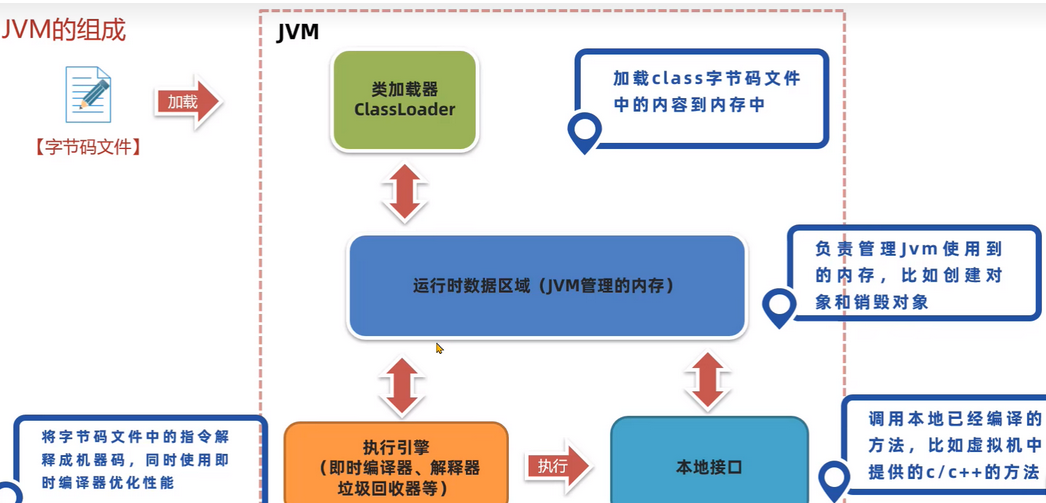
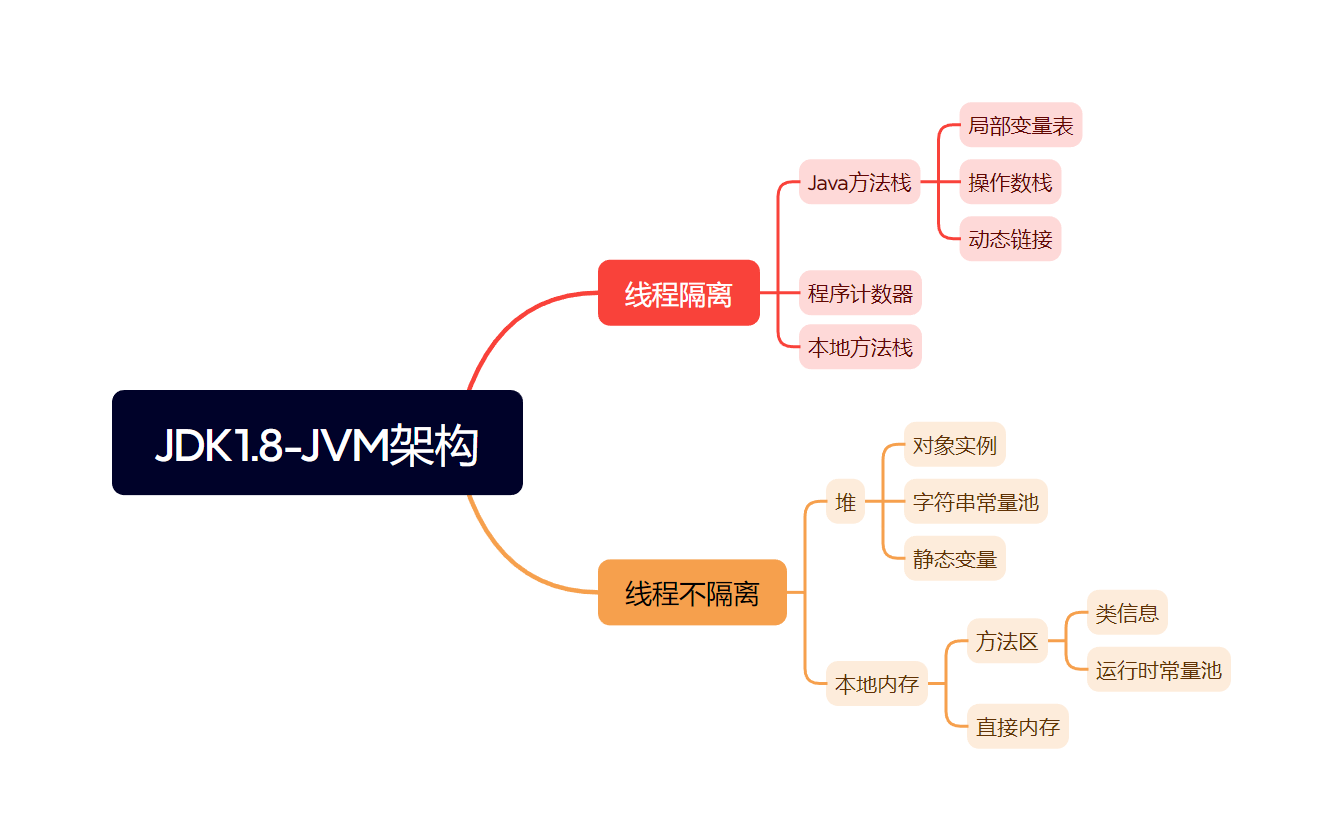
JVM架构图:
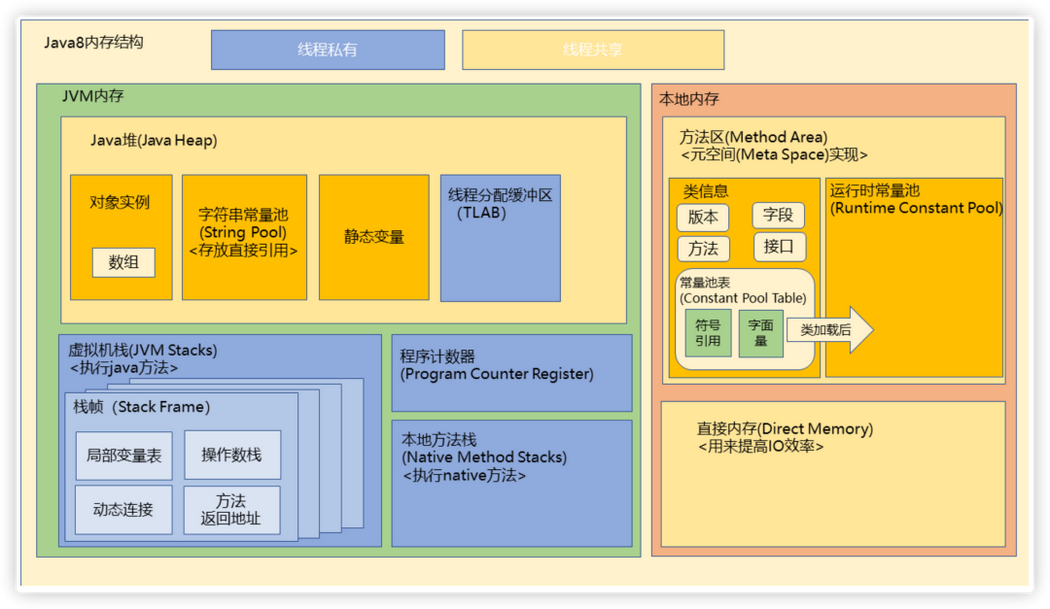
JDK1.8后的内存结构:
 (图片来源:https://github.com/Seazean/JavaNote)
(图片来源:https://github.com/Seazean/JavaNote)
而在运行时数据区域中,根据线程是否共享可以进行分类:
- 线程不共享:程序计数器,本地方法栈,Java虚拟机栈。
- 线程共享:堆,方法区。
1、程序计数器
1.1、概述
简称PC寄存器,用于存储当前线程正在执行的指令的地址或者下一条即将执行的指令的地址。在Java虚拟机中,每个线程都有自己独立的程序计数器,它是线程私有的,不会被线程切换所影响。
它记录了当前线程正在执行的字节码指令的地址。当线程执行一般方法时,程序计数器记录的是正在执行的虚拟机字节码指令的地址,当线程执行的是本地方法(源码中被native关键字修饰的方法)时,程序计数器的值为空(Undefined)。
程序计数器的作用有以下几点:
- 线程切换恢复: 当线程切换回来时,虚拟机通过程序计数器来确定线程上次执行到的位置,从而继续执行。(例如我现在有A,B两个线程并发执行某个方法,该方法有10条指令,A线程首先获得了执行权,在执行到第4条指令时CPU的时间分片结束,B线程获得到了执行权,从第1条指令开始执行,等待CPU时间分片再次结束,假设A线程获得了执行权,就从第4条指令继续执行。)
- 指令定位: 程序计数器指示了当前正在执行的虚拟机指令的地址,帮助虚拟机准确定位下一条需要执行的指令。
- 异常处理: 虚拟机使用程序计数器来记录异常处理代码的起始地址,以便异常处理完成后能够继续执行原来的代码。
- 线程间通信: 在多线程环境下,程序计数器也可以用于线程间通信,例如实现轻量级的线程协作机制。
1.2、案例
例如有如下的一段代码
public class Demo1 {public static void main(String[] args) {int i = 0;if (i ==0){i--;}i++;}
}它的字节码指令是
0 iconst_0
1 istore_1
2 iload_1
3 ifne 9 (+6)
6 iinc 1 by -1
9 iinc 1 by 1
12 return
其中每一行开头处的0,1等代表偏移量,在字节码或者内存中,偏移量表示了某个数据项相对于起始地址的偏移量,以字节为单位。
在加载阶段,虚拟机将字节码的指令读取到内存后,会将偏移量转换为内存地址:

代码的执行过程中,程序计数器会记录下一行字节码指令的地址,执行完当前指令,虚拟机的执行引擎会根据程序计数器执行下一条指令。
2、栈
首先明确一个概念:栈区别于队列,是一种先进后出的数据结构,类似于弹夹,先压入的子弹最后打出,后压入的子弹最先打出。
并且在多线程环境下,栈之间是相互独立的,这一点在JUC并发编程篇中做过验证。
在JVM中,栈又是由三部分组成:
- 局部变量表:存放运行时的所有局部变量
- 操作数栈:用于存放执行过程中的临时数据
- 帧数据:包含动态链接,方法出口,异常表引用等
2.1、局部变量表
我现在有一段代码
public class Demo2 {public static void main(String[] args) {int i = 10;long j = 20;}
}
编译后通过jclasslib查看:
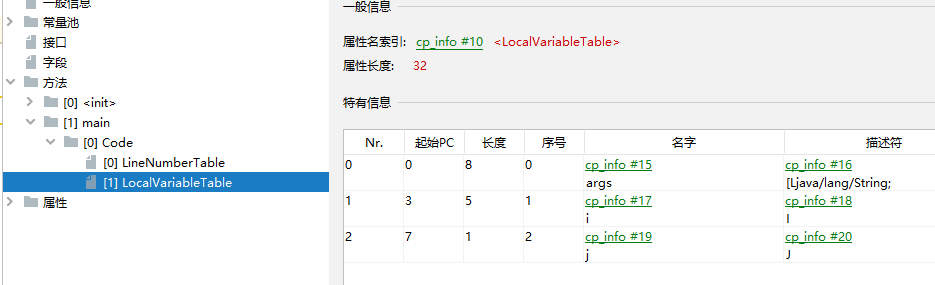
表头的含义:
- Nr.:代表当前元素的编号,在案例中0代表args,1代表i,2代表j。
- 起始PC:表示该局部变量的作用域的起始位置,即该局部变量在方法中有效的起始位置:
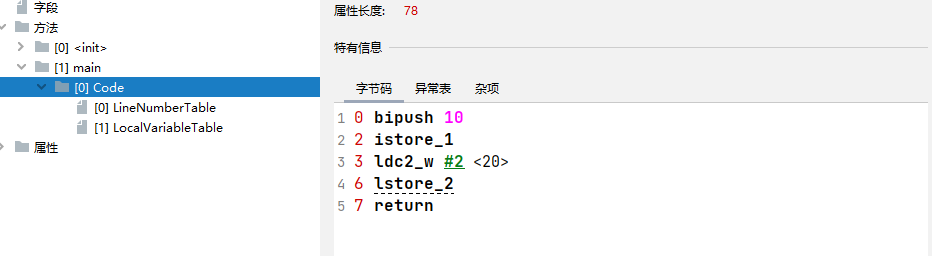
这段字节码大致的含义是:
0 bipush 10: 这条字节码将整数10推送到操作数栈顶。bipush指令用于将一个字节(-128到127之间的整数)推送到操作数栈顶。
2 istore_1: 将操作数栈顶的整数值(之前推送的10)存储到索引为1的本地变量中。istore_1指令将整数值存储到本地变量表中索引为1的位置。
3 ldc2_w #2 <20>: 将一个常量(在常量池中的索引为2的项,可能是一个long或double类型的常量)推送到操作数栈顶。
6 lstore_2: 将操作数栈顶的long类型常量值(之前推送的常量)存储到索引为2的本地变量中。lstore_2指令将long类型的值存储到本地变量表中索引为2的位置。
7 return: 从当前方法返回,没有返回值。return指令用于从当前方法返回,结束方法的执行。
由此可知,当i变量经过了1,2两步后,才算赋值完成,所以i的作用域是从3开始。j同理。
- 长度:表示该局部变量的作用域的长度,即该局部变量在方法中有效的长度。
- 序号:表示该局部变量在局部变量表中的索引位置。局部变量表是按索引顺序存储局部变量的,索引从0开始递增。
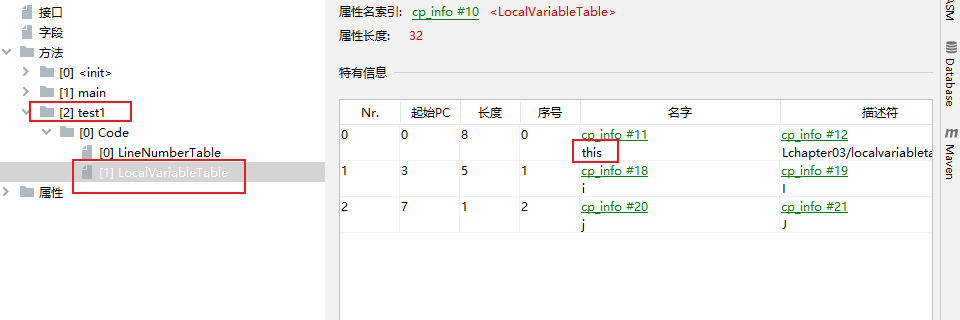
而在实例方法中(区别于被static关键字修饰的静态方法),序号为0的位置会存放一个this。代表调用该方法的对象:
public class Demo2 {public static void main(String[] args) {}public void test1(){int i = 10;long j = 20;}
}
如果是带有参数的方法,方法的参数也是会存放在局部变量表中的,例如main方法的args参数,在第一个案例中就有所体现。
例如在某个实例方法中,有两个参数,并且有两个局部变量,那么在局部变量表中就会有5个元素。
局部变量表中的序号也是能复用的:
public class Demo2 {public static void main(String[] args) {}public void test1(int k,int m){{int a = 1;int b = 2;}{int c = 1;}int i = 0;long j = 1;}
}
上面的案例,在0号索引处存放了this,然后将参数k,m放在了1,2号索引处,第一个代码块中的a,b放在3,4号索引处。
然后执行第二个代码块,a,b的作用范围已经结束了。就会把c放在原先a的3索引的位置。
最后执行给i,j赋值的语句,c的作用范围也结束了,就会把i放在原先c的3索引位置,j方法原先b的4索引位置。
2.2、操作数栈
操作数栈的深度是在编译期就提前确定的:
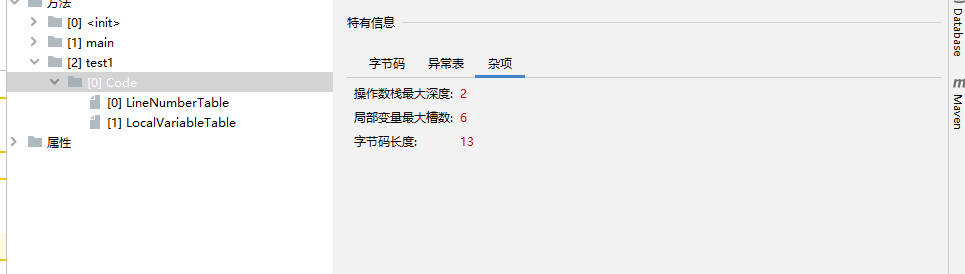
2.3、帧数据
2.3.1、动态链接
动态链接是指在方法调用时,JVM需要确定被调用方法的实际地址或者说是方法在内存中的具体位置。由于Java是一种面向对象的语言,方法调用可能涉及到多态性,即被调用方法的具体实现可能在运行时才能确定。
动态链接会有以下的步骤:
-
查找方法: 当一个方法被调用时,JVM需要查找该方法的具体实现。首先,它会根据方法调用指令中的符号引用(Symbolic Reference)去找到对应的类和方法,这个过程叫做解析。
-
解析: 解析阶段会将符号引用解析为直接引用(Direct Reference),即找到被调用方法在内存中的具体位置。这个过程可能会涉及到类加载、链接等步骤。
-
绑定: 绑定是将方法调用指令与被调用方法的具体实现关联起来的过程。动态绑定是在运行时根据对象的实际类型来确定方法的具体实现。这种机制允许在程序运行时实现多态性。
简单来说,动态链接表现在编译期无法确定,只能在运行期间将符号引用转换为直接引用。(编译和链接阶段,函数调用只是一个符号引用,不包含实际的地址。)
与之相对的是静态链接,在编译阶段,所有的函数调用在链接时就被确定为了直接引用,所有的库函数以及其他被调用的函数的代码都会被复制到可执行文件中。(可执行文件在运行时不再依赖外部的库,因为所有的依赖关系在编译时已经被解决了。)
一般的场景是,如果没有依赖外部的库或动态链接库,是一个独立的执行文件,则是静态链接。如果你的程序需要使用系统提供的共享库或第三方库,则是动态链接。
2.3.2、异常表
异常表是一种数据结构,用于管理和处理Java程序中的异常。异常表存储在方法的字节码中,并由JVM在方法执行期间使用。
public class Demo1 {public static void main(String[] args) {int i = 0;try {i = 1;} catch (Exception e) {i = 2;}}
}
对应的字节码指令:
0 iconst_0
1 istore_1
2 iconst_1
3 istore_1
4 goto 10 (+6) -- 如果没有发生异常,就直接跳到第十步。
7 astore_2
8 iconst_2
9 istore_1
10 return
对应的异常表
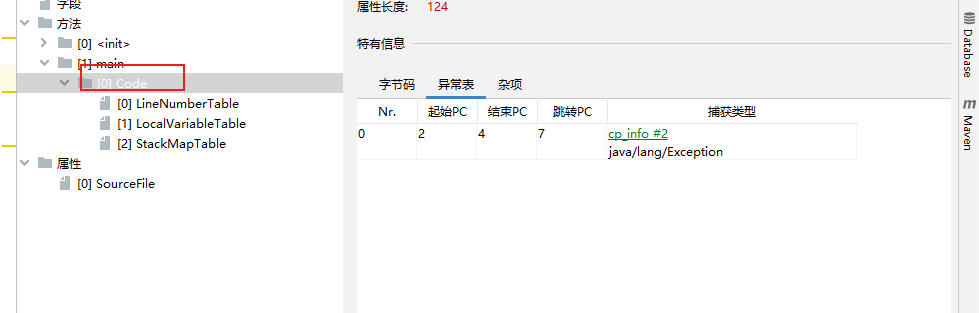
其中起始PC和结束PC就是try...catch块的作用范围,跳转PC为出现异常时执行的代码,捕获类型为捕获何种异常,在案例中是所有Exception类型的。
在栈中,是可能存在内存溢出问题的,通常的原因是递归没有正确设置退出条件,导致栈溢出。
public class Demo1 {static int count = 0;public static void main(String[] args) {test1();}private static void test1() {System.out.println(count++);test1();}
}在执行了大约9800次的时候发生了栈溢出(StackOverflowError)。

栈的大小是可以通过JVM参数进行设置的,如果没有设置栈的大小,JVM也会创建一个默认大小的栈,其大小取决于不同的操作系统。
如果需要手动修改栈的大小,可以通过JVM参数:-Xss栈大小 实现:
例如我将其设置成为了512M:
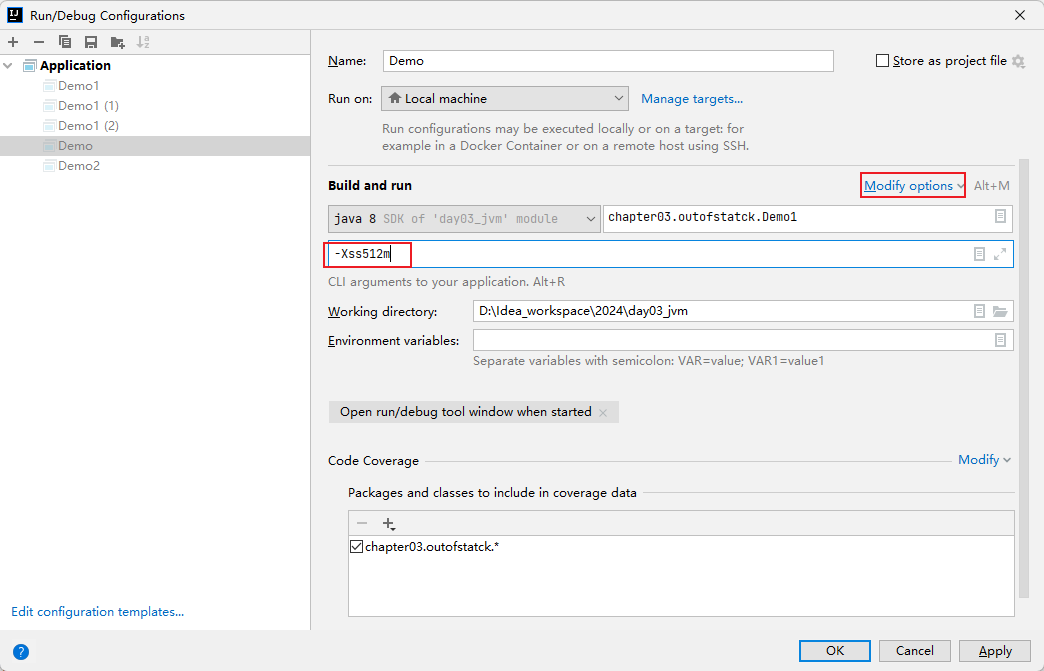
如果局部变量过多,操作数栈深度过大也会影响栈内存的大小。
3、堆
堆内存是用于存储对象实例的内存区域,是 Java 程序中最主要的内存区域之一。堆内存由 JVM 在运行时动态分配和管理,用于存储所有通过New关键字创建的对象实例以及数组对象。
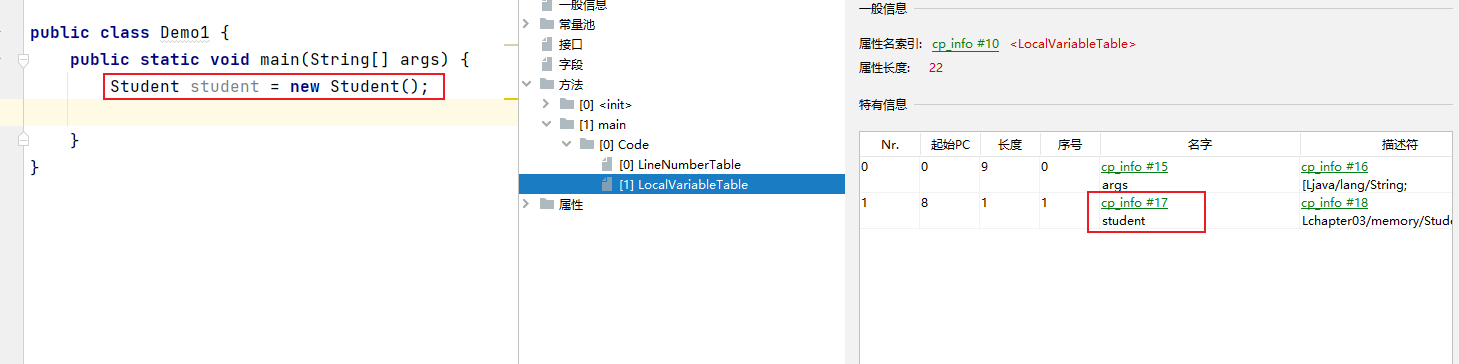
3.1、对象实例
栈中的局部变量表,可以存放堆上对象的引用:
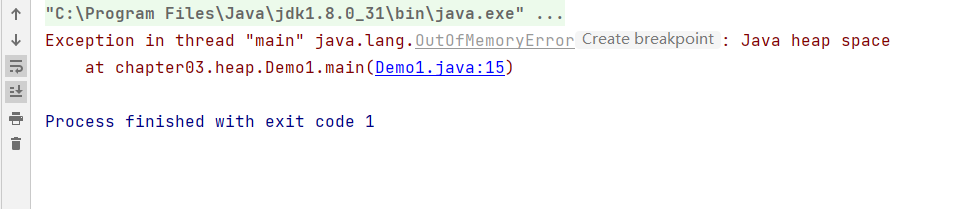
同时堆的内存也会存在溢出现象(OutOfMemoryError):
public class Demo1 {public static void main(String[] args) throws InterruptedException, IOException {ArrayList<Object> objects = new ArrayList<Object>();while (true){objects.add(new byte[1024 * 1024 * 100]);}}
}
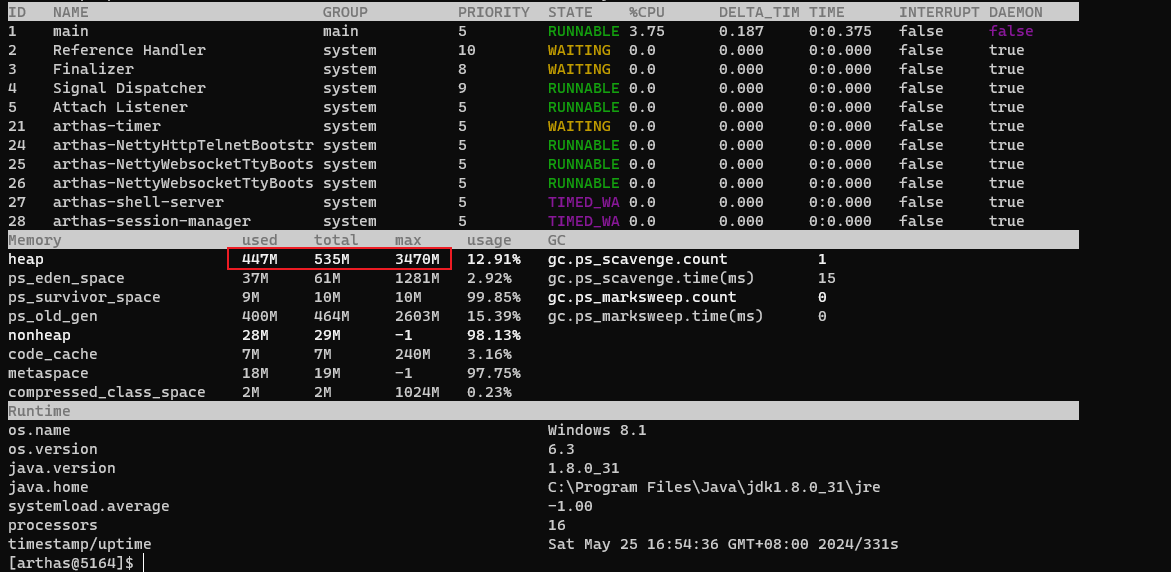
我们也可以通过arthas工具的dashboard命令进行堆内存使用情况的查看:

- used:代表当前已使用的内存。
- total:代表虚拟机分配的可用堆内存。
- max:是java虚拟机可以使用的最大堆内存。
简单来说,当used大于等于total时,total会扩容,但是最大不能超过max。
我们通过在上面的案例的循环中加上
while (true){System.in.read();objects.add(new byte[1024 * 1024 * 100]);
// Thread.sleep(1000);}验证一下,当执行了两次循环后发生了扩容:
堆内存的大小也是可以通过JVM命令去设置的,如果没有设置,max默认是系统最大运行内存的1/4,total是1/64。
修改total的命令是:-Xms,修改max的命令是:-Xmx 其中Xms必须大于1M,Xmx必须大于2M,建议将Xms和Xmx设置成相同的值。
3.2、字符串常量池
字符串常量池用于存储代码中定义的常量字符串。在JDK1.8中,字符串常量池不位于方法区中,而是在堆中(运行时常量池位于直接内存的元空间中)。
例如我现在有以下的代码:
public class Demo2 {public static void main(String[] args) {String a = "1";String b = "2";String c = "12";String d = a + b;System.out.println(c == d);}
}
最终运行的结果是什么?答案是false,通过分析字节码指令,其原因在于,当我们执行String d = a + b 时,在字节码的层面是创建一个StringBuilder的对象,创建的对象会被放在堆内存中。

而c变量的值12是放在字符串常量池中的,所以指向的不是同一个地址(c指向的是字符串常量池中的12,d指向的是堆中的12),使用 == 判断的结果是false。
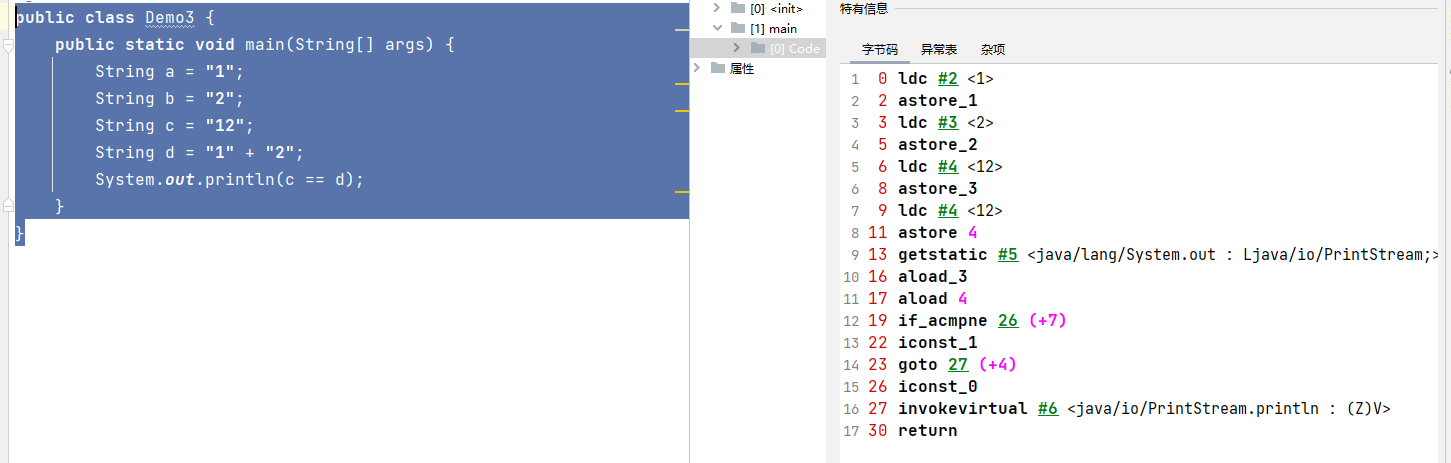
修改一下上面的案例:
public class Demo3 {public static void main(String[] args) {String a = "1";String b = "2";String c = "12";String d = "1" + "2";System.out.println(c == d);}
}运行结果是true,执行 String d = "1" + "2";时不会产生新的对象,而是从字符串常量池中找到c变量的12。
3.3、静态变量
在JDK1.8后,静态变量存放在堆中,静态变量是属于类的,而不是属于类的实例,因此它们只会在类被加载时被初始化,并且在整个应用程序的生命周期内存在,直到应用程序结束或者类被卸载。
4、本地内存
4.1、方法区
用于存储类信息、常量、静态变量和即时编译器编译后的代码等数据。
主要包含了:
-
类信息存储: 方法区主要用于存储加载的类信息,包括类的结构信息、字段信息、方法信息、父类信息、接口信息等。每个加载的类都有对应的 Class 对象在方法区中存储。
-
常量池: 方法区包含了常量池(Constant Pool),用于存储类中的常量信息,如字符串常量、基本类型常量、符号引用等。常量池在类加载时被创建,包括编译时生成的常量和运行时生成的常量。
-
静态变量: 方法区还存储了类的静态变量,即被static修饰的类级别的变量。这些变量在类加载时被初始化,并在整个应用程序的生命周期内保持不变。
-
即时编译器产生的代码: 方法区还用于存储即时编译器(Just-In-Time Compiler,JIT)编译后的本地机器代码,这些代码用于提高 Java 程序的执行效率。
-
运行时常量池: 除了类加载时的常量池,方法区还包含了运行时常量池,它是在类加载完成后在方法区中动态生成的,用于存储运行时解析的常量信息。
在JDK1.8之后,方法区中的永久代(Permanent Generation)被元数据区(Metaspace)所取代。
复习一下,在类的生命周期的加载阶段,类加载器加载完成后,JVM会将读取到的字节码信息保存到内存的方法区中,生成一个InstanceKlass对象,保存类的基本信息。
方法中的静态常量池,连接阶段后,会将符号引用改变成直接引用。(连接阶段中的解析阶段,会将常量池中的符号引用替换成直接引用)。
上面提到过栈和堆都有可能存在内存溢出的问题,而方法区同样可能会内存溢出:
- 在JDK1.7及以前的版本中,方法区位于堆中的永久代空间。
- 在JDK1.8及以后的版本中,方法区位于元空间中,和堆一样是独立的空间。(本地内存)
这样就造成了,在JDK1.7以前的版本,方法区大小受限于堆的大小,而之后的版本,方法区的大小则取决于操作系统的直接内存大小。

同样也可以使用-XX:MaxMetaspaceSize= 命令分配元空间的大小。
4.2、直接内存
是一种在 Java 中进行内存分配和管理的机制,它不同于传统的 Java 堆内存和栈内存。直接内存并不是由 JVM 直接管理的,而是由操作系统管理的一块内存区域。
主要用于提高IO的效率,优势在于它可以通过操作系统的零拷贝技术来实现高效的数据传输。在进行 I/O 操作或者进行大规模数据处理时,直接内存能够直接与操作系统进行交互,避免了数据的多次复制和拷贝,从而提高了系统的性能和效率。
NIO在读写文件时,会将其放入直接内存,并且在堆上维护对直接内存地址的引用。
如果需要创建直接内存,可以使用:
ByteBuffer directBuffer = ByteBuffer.allocateDirect(size);而直接内存和堆,栈,方法区一样,同样会存在内存溢出的问题:
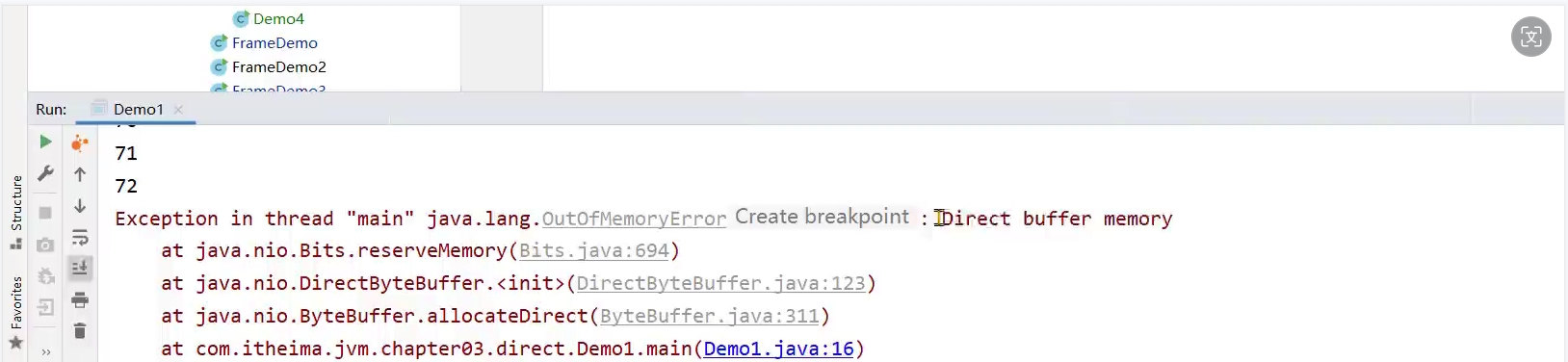
如果需要手动调整直接内存大小,可以通过JVM命令-XX:MaxDirectMemorySize = 大小
补充:
运行时常量池和常量池表:
- 运行时常量池是每个类或接口的一部分,用于存储编译时生成的字面量常量和符号引用。除了字符串常量外,运行时常量池还包含其他类型的常量,如整数常量、浮点数常量等。运行时常量池是类加载过程中的一部分,在类加载后会被存储在方法区(JDK 8 及之前)或元空间(JDK 8 及之后)中。
- 常量池表是 class 文件中的一部分,用于存储编译时生成的常量信息。它包含了类或接口中的所有常量,包括字符串常量、符号引用、方法名、字段名等。常量池表中的每个常量都有一个索引,可以通过索引来访问常量池中的具体内容。运行时常量池实际上是常量池表在运行时被加载到内存中的形式之一。
常量池表在类加载后成为运行时常量池。
相关文章:
JVM(三)
在上一篇中,介绍了JVM组件中的类加载器,以及相关的双亲委派机制。这一篇主要介绍运行时的数据区域 JVM架构图: JDK1.8后的内存结构: (图片来源:https://github.com/Seazean/JavaNote) 而在运行时数据区域中&#…...

【二叉树】:LeetCode:100.相同的数(分治)
🎁个人主页:我们的五年 🔍系列专栏:初阶初阶结构刷题 🎉欢迎大家点赞👍评论📝收藏⭐文章 1.问题描述: 2.问题分析: 二叉树是区分结构的,即左右子树是不一…...

[AI Google] 介绍 VideoFX,以及 ImageFX 和 MusicFX 的新功能
VideoFX 是来自 labs.google 的最新实验,您可以查看音乐效果和图像效果的新更新,现在在 110 多个国家可用。 生成式媒体正在改变人们构思创意并增强我们的创造力能力的方式。我们致力于与创作者和艺术家合作构建人工智能,以更好地理解这些生成…...
[7] CUDA之常量内存与纹理内存
CUDA之常量内存与纹理内存 1. 常量内存 NVIDIA GPU卡从逻辑上对用户提供了 64KB 的常量内存空间,可以用来存储内核执行期间所需要的恒定数据常量内存对一些特定情况下的小数据量的访问具有相比全局内存的额外优势,使用常量内存也一定程序上减少了对全局…...

python使用base加密解密
原理 base编码是一种加密解密措施,目前常用的有base16、base32和base64。其大致原理比较简单。 以base64为例,base64加密后共有64中字符。其加密过程是编码后将每3个字节作为一组,这样每组就有3*824位。将每6位作为一个单位进行编码…...

简述vue.mixin的使用场景和原理
Vue.mixin的使用场景 Vue.mixin是Vue的全局混入功能,它提供了一种非常灵活的方式来分发Vue组件中的可复用功能。使用Vue.mixin可以为Vue实例和组件添加全局的方法、属性、钩子函数等。具体的使用场景包括: 全局设置默认属性或方法:例如&…...

C# WPF入门学习(四)—— 按钮控件
上期介绍了WPF的实现架构和原理,之后我们开始来使用WPF来学习各种控件。 一、尝试插入一个按钮(方法一) 1. VS2019 在界面中,点击工具栏中的视图,在下拉菜单中选择工具箱。 至于编译器中的视图怎么舒服怎么来布置&am…...

大模型效能工具之智能CommitMessage
01 背景 随着大型语言模型的迅猛增长,各种模型在各个领域的应用如雨后春笋般迅速涌现。在研发全流程的效能方面,也出现了一系列贯穿全流程的提效和质量工具,比如针对成本较高的Oncall,首先出现了高质量的RAG助手;在开…...
PyQt6--Python桌面开发(33.QToolBar工具栏控件)
QToolBar工具栏控件...

node环境问题(无法加载文件D:\Software\Node.js\node_global\vue.ps1,因为在此系统上禁止运行脚本。)
问题:npm安装lerna显示安装成功,但是lerna -v的时候报错 解决步骤: 1、输入:Get-ExecutionPolicy 2、输入:Set-ExecutionPolicy -Scope CurrentUser(有选项的选Y) 3、输入:RemoteSi…...
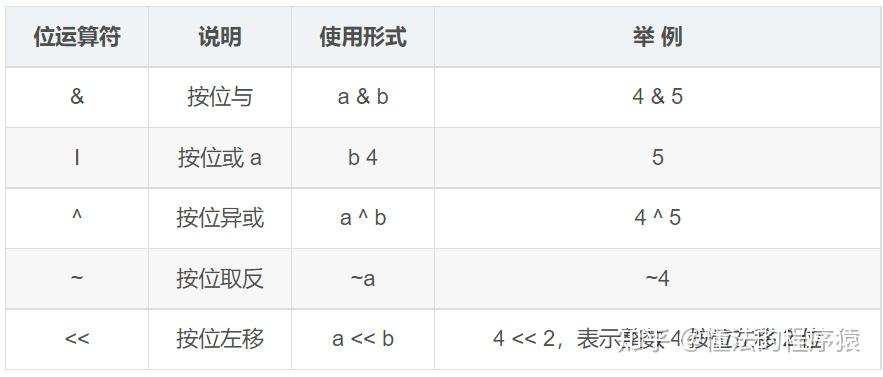
位运算算法
位运算是计算机中常用的一种运算方法,它直接对二进制数的位进行操作。位运算主要包括按位与(&)、按位或(|)、按位异或(^)、按位取反(~)、左移(<<&a…...

重学java 45.多线程 下 总结 定时器_Timer
人开始反向思考 —— 24.5.26 定时器_Timer 1.概述:定时器 2.构造: Timer() 3.方法: void schedule(TimerTask task, Date firstTime, long period) task:抽象类,是Runnable的实现类 firstTime:从什么时间开始执行 period:每隔多长时间执行一次…...

MongoDB(介绍,安装,操作,Springboot整合MonggoDB)
目录 MongoDB 1 MongoDB介绍 MongoDB简介 MongoDB的特点 MongoDB使用场景 小结 2 MongoDB安装 安装MongoDB 连接MongoDB MongoDB逻辑结构 MongoDB数据类型 小结 3 MongoDB操作 操作库和集合 操作文档-增删改 操作文档-查询 MongoDB索引 小结 4 SpringBoot整合…...

【数字移动通信】期末突击
文章目录 复习题一.简答题1、常用的移动通信系统有哪些?2、分别列出1G,2G,3G,4G的典型系统或标准?3、移动通信信道的基本特征?4、电波传播预测模型是用来计算什么量的,在选择传播预测模型时,主要考虑哪些因素?5、什么…...
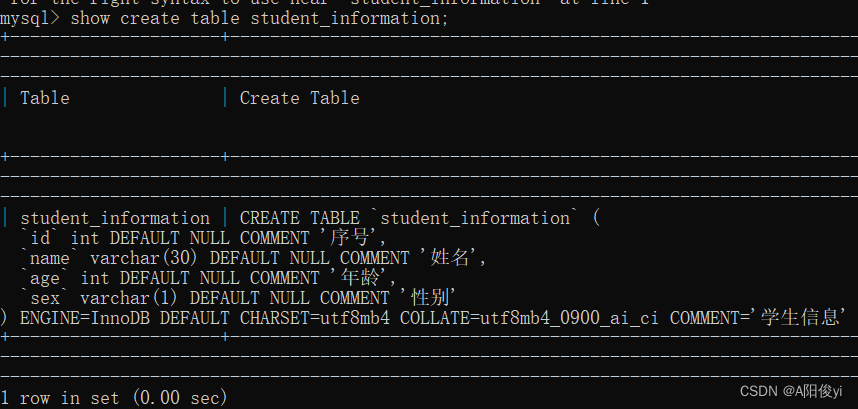
数据库(5)——DDL 表操作
表查询 先要进入到某一个数据库中才可使用这些指令。 SHOW TABLES; 可查询当前数据库中所有的表。 表创建 CREATE TABLE 表名( 字段1 类型 [COMMENT 字段1注释] ...... 字段n 类型 [COMMENT 字段n注释] )[COMMENT 表注释]; 例如,在student数据库里创建一张studen…...
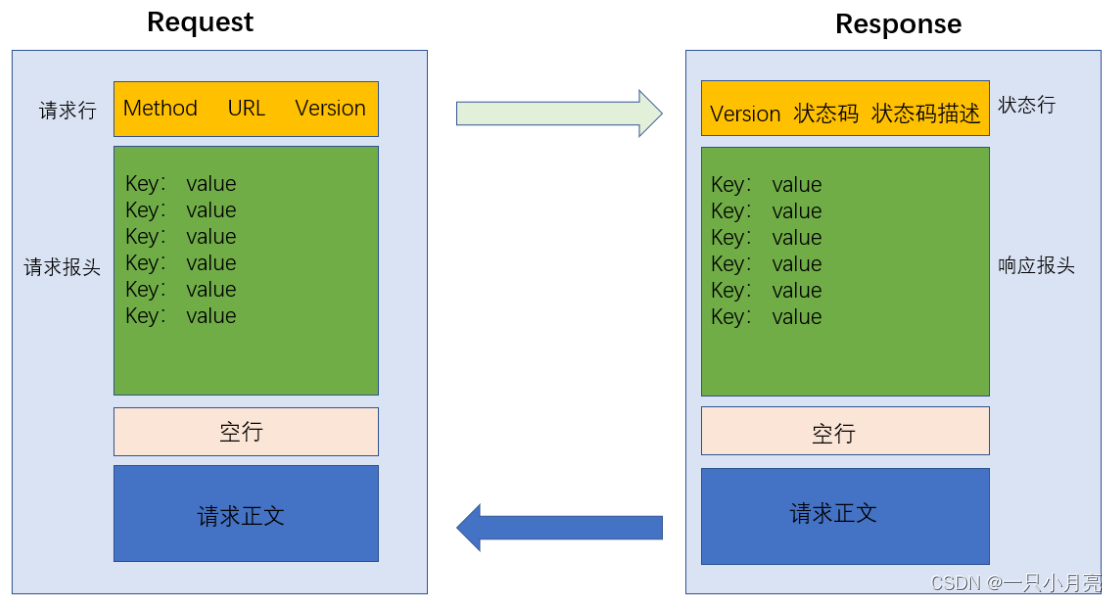
【Java EE】网络协议——HTTP协议
目录 1.HTTP 1.1HTTP是什么 1.2理解“应用层协议” 1.3理解HTTP协议的工作过程 2.HTTP协议格式 2.1抓包工具的使用 2.2抓包工具的原理 2.3抓包结果 3.协议格式总结 1.HTTP 1.1HTTP是什么 HTTP(全称为“超文本传输协议”)是一种应用非常广泛的应…...

Docker提示某网络不存在如何解决,添加完网络之后如何删除?
Docker提示某网络不存在如何解决? 创建 Docker 网络 假设现在需要创建一个名为my-mysql-network的网络 docker network create my-mysql-network运行容器 创建网络之后,再运行 mysqld_exporter 容器。完整命令如下: docker run -d -p 9104…...

C++ 红黑树
目录 1.红黑树的概念 2.红黑树的性质 3.红黑树节点的定义 4.红黑树的插入操作 5.数据测试 1.红黑树的概念 红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。 通过对任何一条从根到叶子的路径上各个…...

PTA 6-4 配对问题
许多大学生报名参与大运会志愿者工作。其中运动场引导员需要男女生组队,每组一名男生加一名女生,男生和女生各自排成一队,依次从男队和女队队头各出一人配成小组,若两队初始人数不同,则较长那一队未配对者调到其他志愿…...

sklearn基础教程
scikit-learn是一个用于机器学习的Python库,提供了多种机器学习的方法和模型,以及数据预处理、特征选择、模型评估等功能。它简化了机器学习流程,并且具有易于使用和灵活的特点。 本教程将介绍sklearn的基础知识和常用功能,帮助你…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...
)
Windows 10/11系统下,SecureCRT 8.7.2保姆级安装与激活图文指南(含Keygen使用避坑点)
Windows平台SecureCRT 8.7.2全流程部署与安全配置指南在当今远程运维与网络管理的日常工作中,一款可靠的终端仿真工具如同工程师的瑞士军刀。作为行业标杆的SecureCRT,其8.7.2版本在Windows 10/11环境下的部署却常让新手陷入各种技术陷阱——从安装路径选…...

组态王通用扫码枪配置
使用组态王扫码枪驱动,是绑定变量,扫码后直接就可以显示扫码内容。解决每次扫码输入数据时必须先用鼠标点进输入框内的问题。驱动安装先添加驱动,亚控网站的文件为 barcodescanner,这个文件是组态王通用扫码枪的驱动,但…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

Hindsight测试策略:单元测试、集成测试和端到端测试
Hindsight测试策略:单元测试、集成测试和端到端测试 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight作为一款专注于Agent Memory的开源项目,其可…...

基于雷达与光敏传感器的低功耗智能窗防设备设计与实现
1. 项目概述:一个基于雷达与光敏的智能窗防设备几年前,我因为一次短暂的出差,家里空置了几天,回来后就一直琢磨着怎么给家里的窗户加点“动静”。市面上的智能安防摄像头固然好,但要么需要复杂的布线,要么云…...

基于PIC32的嵌入式MIDI合成器:从波表合成到硬件实现
1. 项目概述:一个基于嵌入式微控制器的MIDI声音合成器如果你对电子音乐制作、嵌入式开发,或者DIY硬件合成器感兴趣,那么“REMI Synth”这个项目绝对值得你花时间深入了解。它本质上是一个数字单音MIDI控制的声音合成器,核心是一块…...

Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例
Arcmap实操:如何用‘渔网’给你的地图做一次‘CT扫描’——以韶关市路网密度可视化为例 想象一下,医生通过CT扫描将人体内部结构分层呈现,而GIS中的"渔网"工具同样能对城市路网进行"切片式"分析。这种空间离散化技术&…...