线性回归模型之套索回归
概述
本案例是基于之前的岭回归的案例的。之前案例的完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge, LinearRegression
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.model_selection import learning_curve, KFolddef plot_learning_curve(est, X, y):# 将数据拆分20次用来对模型进行评分training_set_size, train_scores, test_scores = learning_curve(est,X,y,train_sizes=np.linspace(.1, 1, 20),cv=KFold(20, shuffle=True, random_state=1))# 获取模型名称estimator_name = est.__class__.__name__# 绘制模型评分line = plt.plot(training_set_size, train_scores.mean(axis=1), "--", label="training " + estimator_name)plt.plot(training_set_size, test_scores.mean(axis=1), "-", label="test " + estimator_name, c=line[0].get_color())plt.xlabel("Training set size")plt.ylabel("Score")plt.ylim(0, 1.1)# 加载数据
data = load_diabetes()
X, y = data.data, data.target# 绘制图形
plot_learning_curve(Ridge(alpha=1), X, y)
plot_learning_curve(LinearRegression(), X, y)
plt.legend(loc=(0, 1.05), ncol=2, fontsize=11)
plt.show()
输出结果如下:

套索回归的基本用法
引入套索回归,还是基于糖尿病数据,进行模型的训练。
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
import numpy as np# 加载数据
data = load_diabetes()
X, y = data.data, data.target# 切割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=8)# 使用套索回归拟合数据
reg = Lasso().fit(X_train, y_train)# 查看结果
print(reg.score(X_train, y_train))
print(reg.score(X_test, y_test))
print(np.sum(reg.coef_ != 0))
输出结果如下:
0.3624222204154225
0.36561940472905163
3
调整套索回归的参数
上面的案例中,评分只有0.3,很低,我们可以试试调低alpha的值试试。
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
import numpy as np# 加载数据
data = load_diabetes()
X, y = data.data, data.target# 切割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=8)# 使用套索回归拟合数据
reg = Lasso(alpha=0.1, max_iter=100000).fit(X_train, y_train)# 查看结果
print(reg.score(X_train, y_train))
print(reg.score(X_test, y_test))
print(np.sum(reg.coef_ != 0))
输出如下:
0.5194790915052719
0.4799480078849704
7
可以发现,评分有所增长,10个特征中,这里用到了7个特征。
过拟合问题
如果我们把alpha的值设置得太低,就相当于把正则化的效果去除了,模型就会出现过拟合问题。
比如,我们将alpha设置为0.0001:
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
import numpy as np# 加载数据
data = load_diabetes()
X, y = data.data, data.target# 切割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=8)# 使用套索回归拟合数据
reg = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train)# 查看结果
print(reg.score(X_train, y_train))
print(reg.score(X_test, y_test))
print(np.sum(reg.coef_ != 0))
输出如下:
0.5303797950529495
0.4594491492143349
10
从结果来看,我们用到了全部特征,而且模型在测试集上的分数要稍微低于alpha等于0.1的时候的得分,说明降低alpha的数值会让模型倾向于出现过拟合的现象。
套索回归和岭回归的对比
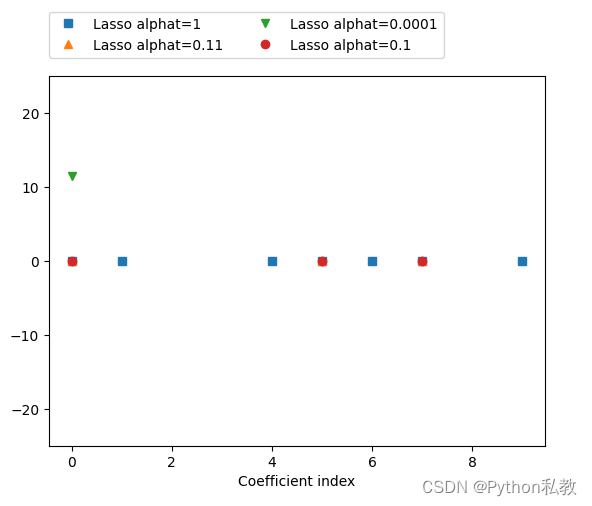
我们采用图像的形式,来对比不同alpha的值的时候,套索回归和岭回归的系数。
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
import numpy as np# 加载数据
data = load_diabetes()
X, y = data.data, data.target# 切割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=8)# 使用套索回归拟合数据并绘图
reg = Lasso(alpha=1, max_iter=100000).fit(X_train, y_train)
plt.plot(reg.coef_, "s", label="Lasso alphat=1")reg = Lasso(alpha=0.11, max_iter=100000).fit(X_train, y_train)
plt.plot(reg.coef_, "^", label="Lasso alphat=0.11")reg = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train)
plt.plot(reg.coef_, "v", label="Lasso alphat=0.0001")reg = Lasso(alpha=0.1, max_iter=100000).fit(X_train, y_train)
plt.plot(reg.coef_, "o", label="Lasso alphat=0.1")plt.legend(ncol=2,loc=(0,1.05))
plt.ylim(-25,25)
plt.xlabel("Coefficient index")
plt.show()
输出:
相关文章:
线性回归模型之套索回归
概述 本案例是基于之前的岭回归的案例的。之前案例的完整代码如下: import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import Ridge, LinearRegression from sklearn.datasets import make_regression from sklearn.model_selectio…...
解决文件夹打开出错问题:原因、数据恢复与预防措施
在我们日常使用电脑或移动设备时,有时会遇到一个非常棘手的问题——文件夹打开出错。这种错误可能会让您无法访问重要的文件和数据,给工作和生活带来极大的不便。本文将带您深入了解文件夹打开出错的原因,并提供有效的数据恢复方案࿰…...
Spring:面向切面(AOP)
1. 代理模式 二十三种设计模式中的一种,属于结构型模式。它的作用就是通过提供一个代理类,让我们在调用目标方法的时候,不再是直接对目标方法进行调用,而是通过代理类**间接**调用。让不属于目标方法核心逻辑的代码从目标方法中剥…...
本地镜像文件怎么导入docker desktop
docker tag d1134b7b2d5a new_repo:new_tag...

【机器学习-23】关联规则(Apriori)算法:介绍、应用与实现
在现代数据分析中,经常需要从大规模数据集中挖掘有用的信息。关联规则挖掘是一种强大的技术,可以揭示数据中的隐藏关系和规律。本文将介绍如何使用Python进行关联规则挖掘,以帮助您发现数据中的有趣模式。 一、引言 1. 简要介绍关联规则学习…...

Gradle筑基——Gradle Maven仓库管理
基础概念: 1.POM pom:全名Project Object Model 项目对象模型,用来描述当前maven项目发布模块的基础信息 pom主要节点信息如下: 配置描述举例(com.android.tools.build:gradle:4.1.1)groupId组织 / 公司的名称com.…...

c++11:智能指针的种类以及使用场景
指针管理困境 内存释放,指针没有置空;内存泄漏;资源重复释放 怎样解决? RAII 智能指针种类 shared_ptr 实现原理:多个指针指向同一资源,引用计数清零,再调用析构函数释放内存。 使用场景…...
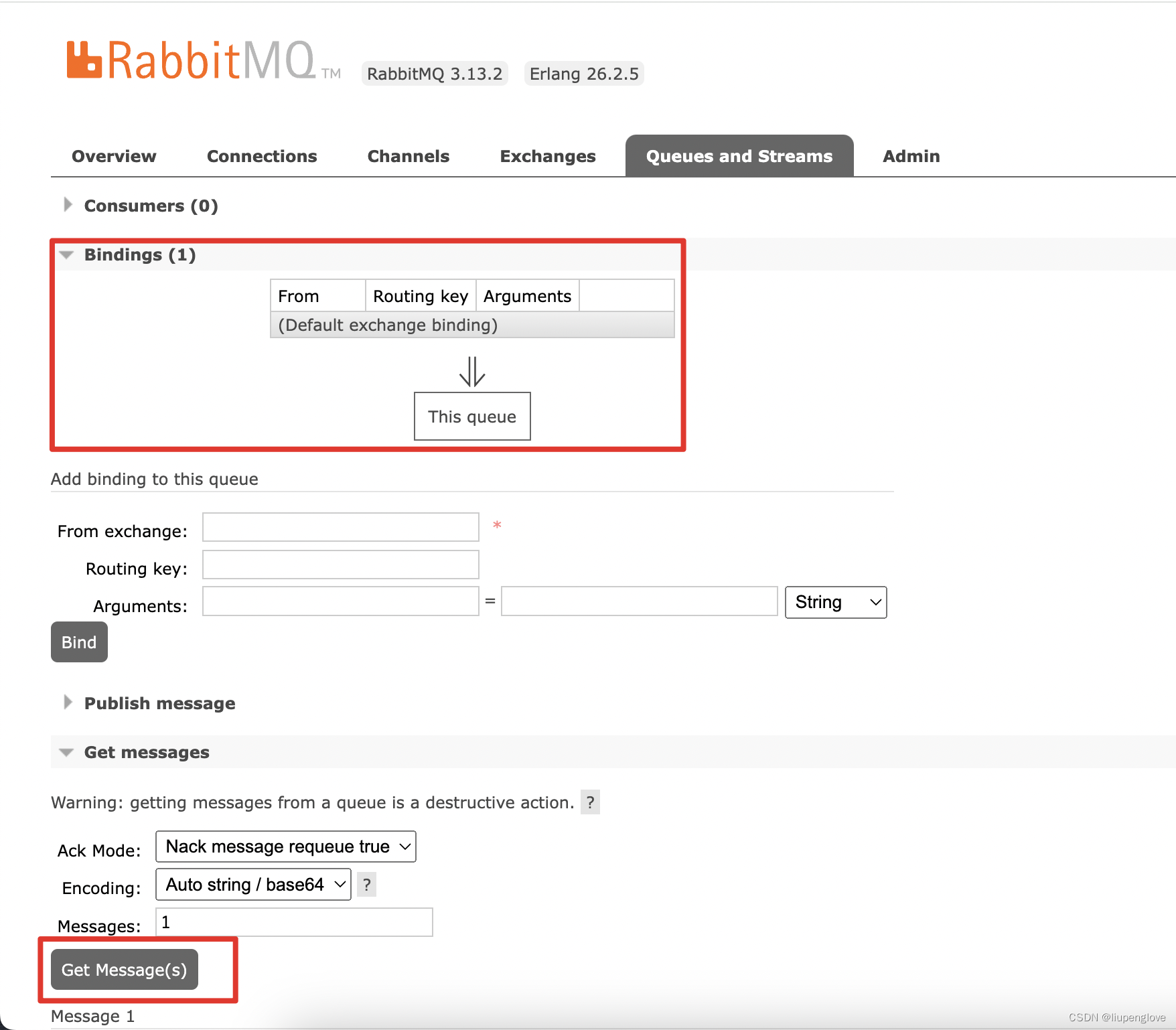
RabbitMQ-默认读、写方式介绍
1、RabbitMQ简介 rabbitmq是一个开源的消息中间件,主要有以下用途,分别是: 应用解耦:通过使用RabbitMQ,不同的应用程序之间可以通过消息进行通信,从而降低应用程序之间的直接依赖性,提高系统的…...

阿里云百炼大模型使用
阿里云百炼大模型使用 由于阿里云百炼大模型有个新用户福利,有免费的4000000 tokens,我开通了相应的服务试试水。 使用 这里使用Android开发了一个简单的demo。 安装SDK implementation group: com.alibaba, name: dashscope-sdk-java, version: 2.…...
)
亲测有效,通过接口实现完美身份证号有效性验证+身份证与姓名匹配查询身份实名认证接口(实时)
最近发现一个限时认证的接口分享给大家,有需要的拿去试下吧. 附上部分密钥f478186edba9854f205a130aa888733d227a8f82f98d84b9【剩余约125450次,无时间限制】 b6131281611f6e1fc86c8662f549bdd683a68517203ba312【剩余约1300次,无时段限制】 …...
试题11 输出什么?
...

对vue3/core源码ref.ts文件API的认识过程
对toRef()API的认识的过程: 最开始认识toRef()是从vue3源码中的ref.ts看见的,右侧GPT已经举了例子 然后根据例子,在控制台输出ref对象是什么样子的: 这就是ref对象了,我们根据对象中有没有__v_isRef来判断是不是一个ref对象,当对象存在且__v_isRef true的时候他就判定为是一个…...

AWS迁移与传输之AWS DMS
AWS Database Migration Service(AWS DMS)是一项托管的服务,用于帮助企业将现有的数据库迁移到AWS云中的各种数据库引擎中,或者在不同数据库引擎之间进行数据迁移和同步。直接在线迁移,将数据复制到云端,不…...
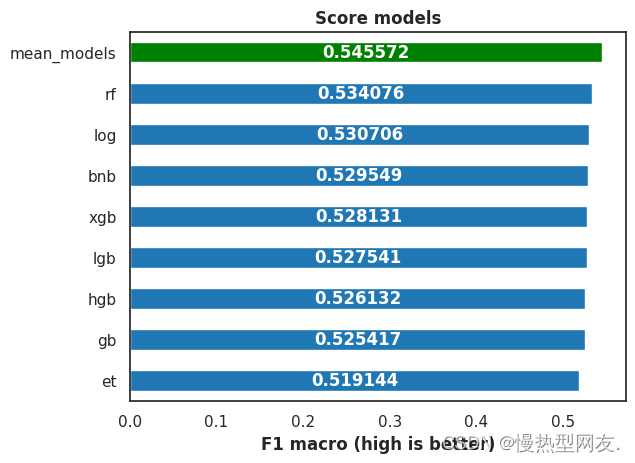
【ML Olympiad】预测地震破坏——根据建筑物位置和施工情况预测地震对建筑物造成的破坏程度
文章目录 Overview 概述Goal 目标Evaluation 评估标准 Dataset Description 数据集说明Dataset Source 数据集来源Dataset Fields 数据集字段 Data Analysis and Visualization 数据分析与可视化Correlation 相关性Hierarchial Clustering 分层聚类Adversarial Validation 对抗…...

kafka监控配置和告警配置
Kafka的监控配置和告警配置是确保Kafka集群稳定运行的关键部分。以下是一些关于Kafka监控配置和告警配置的建议: 一、Kafka监控配置 集群级别参数监控: log.retention.hours:用于控制消息在日志中保留的时间。监控此参数的值,确…...

关于智慧校园安全用电监测系统的设计
人生人身安全是大家关注的话题,2019年12月中国消防统计近五年发生在全国学生宿舍的火灾2314起(中国消防2019.12.应急管理部消防救援局官方微博),违规电器是引发火灾的主因。如果在各寝室安装智能用电监测器实时监督线路参数&#…...

Flutter 中的 FormField 小部件:全面指南
Flutter 中的 FormField 小部件:全面指南 在Flutter的世界里,表单是用户输入数据的基本方式之一。FormField是一个强大的小部件,它将表单字段的创建、验证和管理集成到了一个易于使用的抽象中。本文将为您提供一个全面的指南,帮助…...
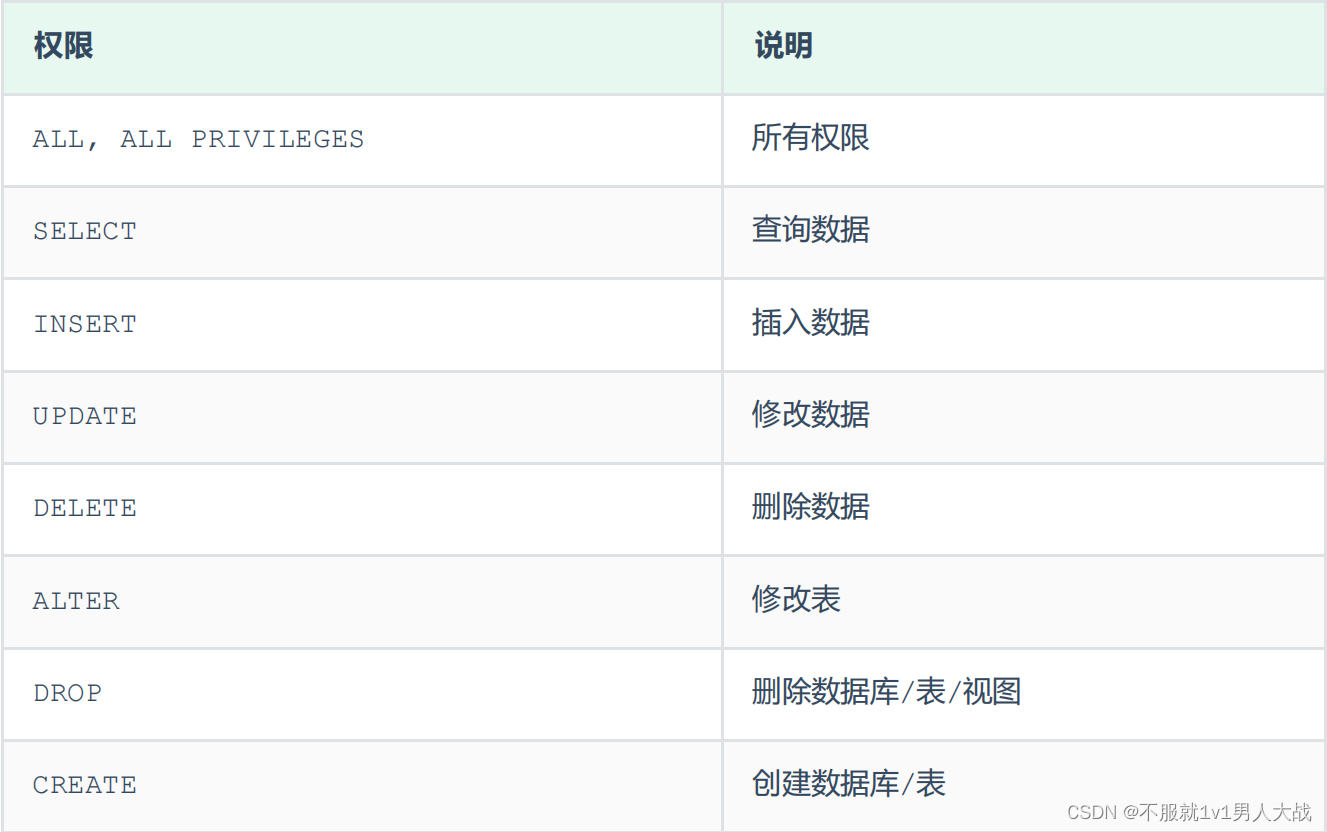
数据库DCL语句
数据库DCL语句 介绍: DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访 问权限。 管理用户: 查询用户: select * from mysql.user;创建用户: create user 用户名主机名 identified by 密码;修改用…...

mysql-日志管理-error.log
日志管理 默认的数据库日志 vim /etc/my.cnf //错误日志 log-error/usr/local/mysql/mysql.log查看数据库日志 tail -f /usr/local/mysql/mysql.log1 错误日志 :启动,停止,关闭失败报错。rpm安装日志位置 /var/log/mysqld.log #默认开启 2 …...
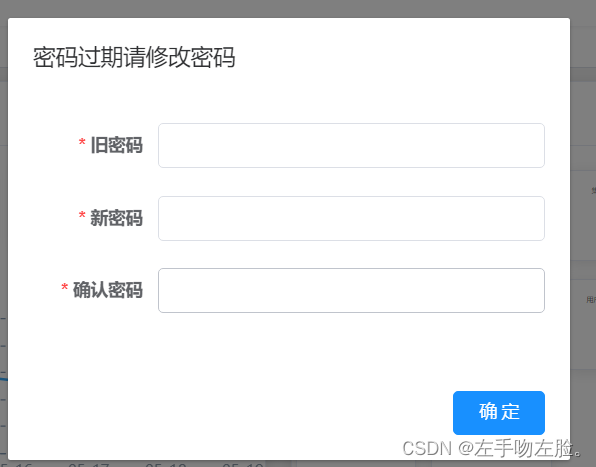
弱密码系统登录之后强制修改密码
在你登录的时候,获取到弱密码,然后将他存到vuex里面,在登录进去之后,index页面再去取,思路是这样的 一、vuex里面定义密码字段 我是直接在user.js里面写的 import { login, logout, getInfo } from /api/login impo…...

IPD的势、道、法、术、器
目录 简介 一、势:为什么 IPD 是必然选择? 二、道:IPD 的底层哲学 三、法与术:从战略到执行的具体路径 四、器:让流程真正落地的工具与组织 不是每家公司都需要全套 IPD,但每家公司都需要 IPD 思维 简…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

别再死记硬背Payload了!我用XSS-Game靶场,带你拆解18种过滤规则背后的绕过逻辑
从XSS-Game靶场实战中掌握18种过滤规则的逆向思维在网络安全领域,跨站脚本攻击(XSS)始终是Web应用面临的主要威胁之一。许多开发者虽然了解XSS的基本概念,但当面对各种复杂的过滤规则时,往往不知如何系统分析并构造有效…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

3步深度解锁:网络设备权限管理工具的实战手册
3步深度解锁:网络设备权限管理工具的实战手册 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾面对功能受限的网络设备感到束手无策?当默认配置锁死了硬…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

结肠“瑞士卷”制片法
在肠道病理研究中,如何完整保留小鼠结肠的全层结构、同时避免人为损伤,一直是实验操作的难点。本文分享一套改良版“瑞士卷”制片技术,无需剖开肠管、无需机械顶压,即可获得高质量的全结肠切片,特别适合炎症、隐窝异常…...
)
【小白快速上手】 OpenClaw 安装部署全流程(含安装包)
OpenClaw 一键安装包|一键部署,告别复杂环境配置 适配系统:Windows10/11 64 位当前版本:v2.7.5(虾壳云版)核心优势:全程可视化操作,无需命令行、无需手动配置 Python/Node.js&#…...