python-13(案例讲解)
目录
抓取链家前十页的数据
计算均价和总价
计算的类型(整租,合租)
计算的房型
抓取boss直聘前十页的数据
抓取boss直聘前十页的数据
将获取数据本地序列化
计算每个区的需求个数与均价
抓取链家前十页的数据
链家网址:长沙房产网_长沙房地产_长沙房产门户(长沙链家网)
计算均价和总价
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://cs.lianjia.com/zufang/rs岳麓区/")
# 总价
total = 0
# 记录房间个数
size = 0
for i in range(2):elements = driver.find_elements(By.CSS_SELECTOR, '.content__list--item--main')print(f"第{i+1}页的数据:")for el in elements:# 获取租房标题name = el.find_element(By.CSS_SELECTOR, '.content__list--item--title a').text# 判断是否包含独栋信息if name.__contains__("独栋"):continue# 获取租房的价格price = el.find_element(By.CSS_SELECTOR, '.content__list--item-price em').textprint(f"name={name},price={price}")total += float(price)# 记录房间的个数size += len(elements)# 点击下一页driver.find_element(By.CSS_SELECTOR,'a.next').click()# 模拟睡眠6秒time.sleep(2)
print(f"总价:{total},岳麓区的租房均价为:{total/size}")
计算的类型(整租,合租)
str = """
name=整租·万科里金域国际 4室2厅 南,price=4500
name=独栋·魔方公寓 长沙航天溪湖店 连锁公寓直租无中介费 1室1厅,price=1800
name=整租·潇湘奥林匹克花园 1室1厅 南,price=2200
name=合租·达美美立方 5居室 复式 南卧,price=999
name=整租·万科里金域国际 3室2厅 南,price=3400
"""
# 计算的类型(整租,合租)
print("整租:", str.count("整租"))
print("合租:", str.count("合租"))
计算的房型
由于在爬取的数据中存在“居室”和“室”的区别,所以请将所有的“居室”数据替换成“室”。
str = """
name=整租·万科里金域国际 4室2厅 南,price=4500
name=独栋·魔方公寓 长沙航天溪湖店 连锁公寓直租无中介费 1室1厅,price=1800
name=整租·潇湘奥林匹克花园 1室1厅 南,price=2200
name=合租·达美美立方 5居室 复式 南卧,price=999
name=整租·万科里金域国际 3室2厅 南,price=3400
"""
import re
import collections
st = str.replace('居室','室')
rs = re.findall(r'\d室',st)
print(rs)
print(collections.Counter(rs))
完整可执行且标注代码
import timefrom selenium import webdriver
from selenium.webdriver.common.by import Bydriver = webdriver.Chrome()
driver.get("https://cs.lianjia.com/zufang/rs岳麓区/")# 总价
total = 0
# 记录房间个数
size = 0for i in range(2):elements = driver.find_elements(By.CSS_SELECTOR, '.content__list--item--main')print(f"第{i+1}页的数据:")for el in elements:# 获取租房标题name = el.find_element(By.CSS_SELECTOR, '.content__list--item--title a').text# 判断是否包含独栋信息if name.__contains__("独栋"):continue# 获取租房的价格price = el.find_element(By.CSS_SELECTOR, '.content__list--item-price em').textprint(f"name={name},price={price}")total += float(price)# 顶部滚到底部driver.execute_script('window.scrollTo(0,document.body.scrollHeight);')# 记录房间的个数size += len(elements)# 点击下一页driver.find_element(By.CSS_SELECTOR,'a.next').click()# 模拟睡眠6秒time.sleep(2)print(f"总价:{total},岳麓区的租房均价为:{total/size}")抓取boss直聘前十页的数据
boss直聘网址:BOSS直聘-找工作上BOSS直聘直接谈!招聘求职找工作!
抓取boss直聘前十页的数据
其中参数city=101020100是中国天气网全城市代码weather_cityId。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("https://www.zhipin.com/web/geek/job?query=java&city=101020100")
jobs = []
for i in range(3):time.sleep(6)elements = driver.find_elements(By.CSS_SELECTOR, ".job-card-wrapper")for el in elements:# 获取地区area = el.find_element(By.CSS_SELECTOR,"span.job-area").text# 获取薪酬salary = el.find_element(By.CSS_SELECTOR,"span.salary").textprint(f"area={area},salary={salary}")jobs.append({'area':area,'salary':salary})driver.find_element(By.CSS_SELECTOR,".selected+a").click()
print(jobs)
将获取数据本地序列化
Python的pickle模块是一种用于序列化(将对象转换为字节流)和反序列化(将字节流转换回对象)Python对象的工具。它可以将Python对象保存到文件中或从文件中加载对象。
pickle模块还有其他一些有用的函数和特性。以下是一些常见的功能:
-
pickle.dumps(obj):将对象序列化为字节流,但不保存到文件中。 -
pickle.loads(bytes_obj):从字节流中加载对象,而不是从文件中加载。 -
pickle.dump(obj, file):将对象序列化并保存到文件中。 -
pickle.load(file):从文件中加载序列化的对象。
# 将获取到的结果保存到本地
p = Path("jobs.txt")
p.touch()
# 通过pickle.dump实现数据序列化
pickle.dump(jobs,p.open(mode="wb"))
计算每个区的需求个数与均价
# 计算每个区的需求个数与均价
jobs = pickle.load(open('jobs.txt',mode="rb"))
print(jobs)
areas=list(map(lambda a: "".join(re.findall(r'.*?·(.*?)·.*?',a['area'])),jobs))
print(areas)
import collections
rs = collections.Counter(areas)
for k,v in rs.items():print(f"【{k}】的工作岗位需求数:{v}")# 获取该区的工作集合ps = list(filter(lambda e: e['area'].count(k) > 0, jobs))# 获取该区的薪酬总价total = functools.reduce(lambda a,b:a+int(b['salary'].split('-')[0]),ps,0)print(f"该区的工作入门平均薪酬:{total/len(ps)}")
完整可执行且标注代码
序列化
import json # 导入json模块,用于处理JSON数据
import time # 导入time模块,用于延时操作from selenium import webdriver # 导入selenium的webdriver模块,用于自动化浏览器操作
from selenium.webdriver.common.by import By # 导入selenium的By模块,用于定位元素driver = webdriver.Edge() # 初始化Edge浏览器的WebDriver实例
driver.get("") # 访问BOSS直聘网站的URL,这里需要替换为实际的URLjobs = [] # 初始化一个空列表,用于存储抓取的职位信息# try:
for i in range(2): # 循环两次,假设只抓取两页的数据print(f'正在获取第{i+1}页数据') # 打印当前正在抓取的页码time.sleep(20) # 等待20秒,让页面加载完成items = driver.find_elements(By.CLASS_NAME,'job-card-wrapper') # 查找所有具有'job-card-wrapper'类名的元素for item in items: # 遍历这些元素addr = item.find_element(By.CLASS_NAME,'job-area') # 在每个元素中查找具有'job-area'类名的元素price = item.find_element(By.CLASS_NAME,'salary') # 在每个元素中查找具有'salary'类名的元素print(addr.text, price.text) # 打印地址和薪资信息jobs.append({ # 将地址和薪资信息添加到jobs列表中'area': addr.text,'salary': price.text})# 它表示选取所有紧接在类为"selected"的元素后面的同级元素中的标签为"a"的元素driver.find_element(By.CSS_SELECTOR,'.selected+a').click() # 点击下一页的链接print(jobs) # 打印所有抓取到的职位信息# 序列化
with open("jobs.json","w",encoding='utf-8') as fp: # 打开或创建一个名为"jobs.json"的文件,准备写入# ensure_ascii=False (关闭默认阿斯玛写入方式)json.dump(jobs, fp, ensure_ascii=False, indent=2) # 将jobs列表中的数据序列化为JSON格式,并写入文件,格式化输出# except Exception as ex:
# print(ex) # 这行代码被注释掉了,它用于捕获并打印异常信息反序列化
import json # 导入json模块,用于处理JSON数据
import re # 导入re模块,用于正则表达式操作
from collections import Counter # 导入Counter类,用于计数jbos = [] # 初始化一个空列表,用于存储从JSON文件中加载的职位信息# 反序列化
with open('jbos.json', 'r', encoding='utf-8') as fp: # 打开名为'jbos.json'的文件,准备读取jbos = json.load(fp) # 从文件中加载JSON数据到jbos列表中
print(jbos) # 打印加载的职位信息列表# 提取区名
def extract_district(job: dict): # 定义一个函数,用于从职位信息中提取区域名称match = re.search(r'·([^·]+区)·', job['area']) # 使用正则表达式匹配职位区域名称if match: # 如果匹配成功return match.group(1) # 返回匹配到的区域名称return "" # 如果没有匹配到,返回空字符串arears = list(map(extract_district, jbos)) # 使用map函数和extract_district函数,将jbos列表中的每个职位映射到其区域名称,生成一个新的列表arears
print(arears) # 打印提取的区域名称列表# 统计每个区出现的次数
dict = Counter(arears) # 使用Counter类统计arears列表中每个区域出现的次数
print(dict) # 打印区域出现次数的统计结果for k, v in dict.items(): # 遍历统计结果中的每个区域及其出现次数print(f'{k}有{v}条招聘信息') # 打印每个区域的招聘信息数量total = 0 # 初始化总薪水变量count = 0 # 初始化计数器for job in jbos: # 遍历所有职位信息if job['area'].__contains__(k): # 如果职位区域包含当前区域total = total + int(re.search(r'(\d+?)-', job['salary']).group(1)) # 将薪水转换为整数并累加到总薪水count += 1 # 增加计数器print(f'平均薪水{total}') # 打印当前区域的平均薪水相关文章:
)
python-13(案例讲解)
目录 抓取链家前十页的数据 计算均价和总价 计算的类型(整租,合租) 计算的房型 抓取boss直聘前十页的数据 抓取boss直聘前十页的数据 将获取数据本地序列化 计算每个区的需求个数与均价 抓取链家前十页的数据 链家网址:长…...

【深度学习】最强算法之:人工神经网络(ANN)
人工神经网络ANN 1、引言2、人工神经网络(ANN)2.1 定义2.1.1 定义2.1.2 应用场景 2.2 核心原理2.3 实现方式2.4 算法公式2.5 代码示例 3、总结 1、引言 小屌丝:鱼哥,看新闻没? 小鱼:新闻天天看,啥事大惊小怪的。 小屌…...

Unity vscode在mac上的编译环境设置
在settings.json文件中配置以下信息。 settings.json路径一般在/Users/xxx/Library/Application Support/Code/User/settings.json {"omnisharp.useGlobalMono": "always","editor.fontLigatures": false,"omnisharp.useModernNet": …...

【Java】在高并发场景下,保证 Redis 缓存一致性的几种方案
在高并发场景下,保证 Redis 缓存一致性是一个常见的挑战。以下是几种常见的解决方案及其优缺点,以及相应的代码示例。 1. Cache Aside Pattern (旁路缓存模式) 原理 读取数据时,先读缓存,如果缓存没有命中,再从数据…...

GaussDB数据库的备份与恢复
1.逻辑备份-gs_dump gs_dump是一款用于导出数据库相关信息的工具,支持导出完整一致的数据库对象(数据库、模式、表、视图等)数据,同时不影响用户对数据库的正常访问。 备份sql语句 gs_dump是openGauss用于导出数据库相关信息的工…...

03-02-Vue组件之间的传值
前言 我们接着上一篇文章 03-01-Vue组件的定义和注册 来讲。 下一篇文章 04-Vue:ref获取页面节点–很简单 父组件向子组件传值 我们可以这样理解:Vue实例就是一个父组件,而我们自定义的组件(包括全局组件、私有组件)…...

昂达固态硬盘数据恢复方法:全面解析与操作指南
在数字化时代,数据已经成为我们生活和工作中不可或缺的一部分。而固态硬盘(SSD)由于其读写速度快、抗震性强等优点,慢慢取代了传统的机械硬盘,成为我们存储数据的主要选择。然而,即便再先进的存储设备&…...
C++的红黑树
目录 基本概念 插入结点的颜色 判断性质是否破坏 调整方式 u为g的右孩子 u存在且为红 u存在且为黑 u不存在 结论 红黑树结点定义 代码实现 基本概念 1、红黑树是一种特殊的二叉搜索树,每个结点会增加一个存储位表示结点的颜色(红或黑&#x…...

Keras深度学习框架第二十九讲:在自定义训练循环中应用KerasTuner超参数优化
1、简介 在KerasTuner中,HyperModel类提供了一种方便的方式来在可重用对象中定义搜索空间。你可以通过重写HyperModel.build()方法来定义和进行模型的超参数调优。为了对训练过程进行超参数调优(例如,通过选择适当的批处理大小、训练轮数或数…...

手机App收集个人信息,用户是否有权拒绝?
其实过度收集个人信息这件事,在APP上随处可见,泛滥成灾。 前两天有个不疼不痒的小软件“小鸡词典”,因为收集个人信息受到了处罚。 小鸡词典因划分为工具类APP过度收集隐私(手机号、地理位置定位)、不同意政策不能用…...

云下到云上,丽迅物流如何实现数据库降本50% | OceanBase案例
在2024年3月20日的首场OceanBase数据库城市行活动中,专注于物流及供应链解决方案的丽迅物流的架构师阳磊,围绕“OB Cloud在丽迅物流的实践”这一主题,进行了精彩的演讲。本文为此次演讲的内容回顾。 在丽迅物流(Lesoon Logistics…...

STM32无源蜂鸣器播放音乐
开发板:野火霸天虎V2 单片机:STM32F407ZGT6 开发软件:MDKSTM32CubeMX 文章目录 前言一、找一篇音乐的简谱二、确定音调三、确定节拍四、使用STM32CubeMX生成初始化代码五、代码分析 前言 本实验使用的是低电平触发的无源蜂鸣器 无源蜂鸣器是…...

【云原生】kubernetes中的认证、权限设置---RBAC授权原理分析与应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

【Python设计模式04】策略模式
策略模式(Strategy Pattern)是一种行为型设计模式,它定义了一系列算法,并将每个算法封装起来,使它们可以互相替换。策略模式让算法的变化不会影响使用算法的客户端,使得算法可以独立于客户端的变化而变化。…...

私域用户画像分析:你必须知道的3个关键点!
在互联网时代的变革中,私域流量成为越来越多企业的关注焦点。而了解私域用户画像是建立精准营销策略的关键一步。 今天,就给大家分享私域用户画像分析的三个关键点,让大家都能更好地进行用户画像分析。 1、市场需求 理解市场需求是把握用户…...
【MATLAB源码-第74期】基于matlab的OFDM-IM索引调制系统不同频偏误码率对比,对比OFDM系统。
操作环境: MATLAB 2022a 1、算法描述 OFDM-IM索引调制技术是一种新型的无线通信技术,它将正交频分复用(OFDM)和索引调制(IM)相结合,以提高频谱效率和系统容量。OFDM-IM索引调制技术的基本思想…...

优于其他超导量子比特数千倍!猫态量子比特实现超过十秒的受控比特翻转时间
内容来源:量子前哨(ID:Qforepost) 文丨娴睿/慕一 排版丨沛贤 深度好文:2000字丨8分钟阅读 摘要:量子计算公司Alice & Bob和QUANTIC团队(国立巴黎高等矿业学院PSL分校、巴黎高等师范学院和…...
QtXlsx库编译使用
文章目录 一、前言二、Windows编译使用2.1 用法①:QtXlsx作为Qt的附加模块2.1.1 检验是否安装Perl2.1.2 下载并解压QtXlsx源码2.1.3 MinGW 64-bit安装模块2.1.4 测试 2.2 用法②:直接使用源码 三、Linus编译使用3.1、安装Qt5开发软件包:qtbas…...

LeetCode题练习与总结:二叉树的层序遍历Ⅱ--107
一、题目描述 给你二叉树的根节点 root ,返回其节点值 自底向上的层序遍历 。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历) 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[…...
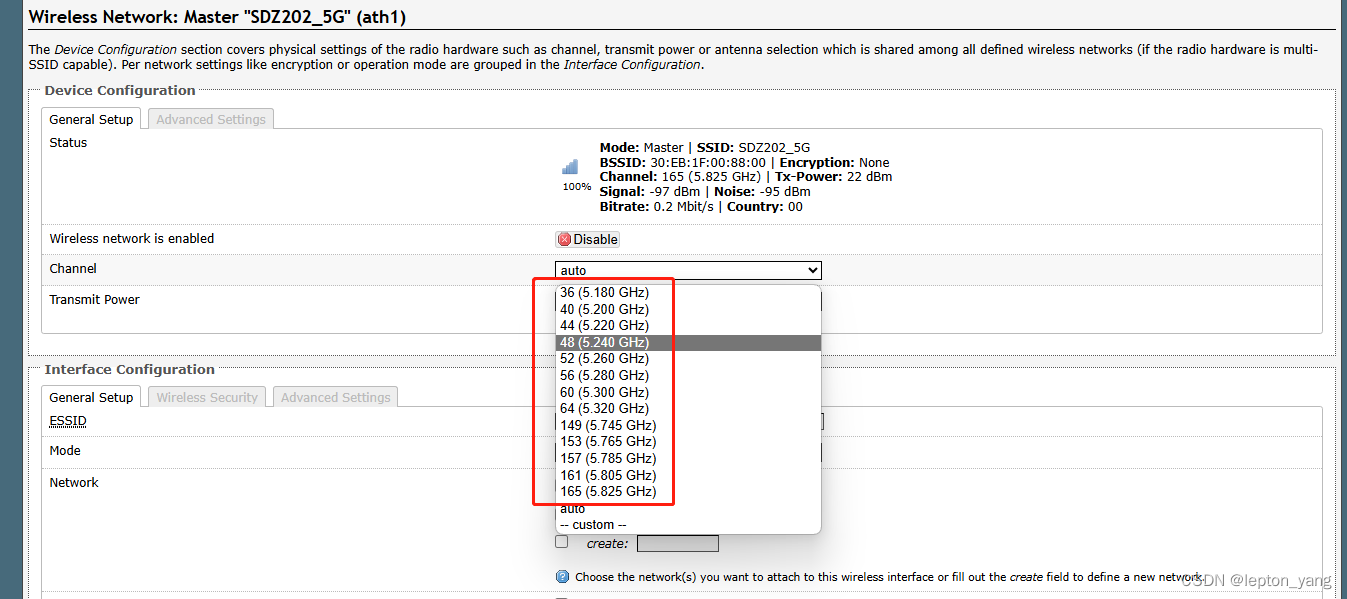
WIFI国家码设置的影响
记录下工作中关于国家码设置对WIFI的影响,以SKYLAB的SKW99和SDZ202模组为例进行说明。对应到日常,就是我们经常提及手机是“美版”“港版”等,它们的wifi国家码是不同的,各版本在wifi使用中遇到的各种情况与下面所述是吻合的。 现…...

OneNote Markdown插件:重新定义智能笔记编辑的架构革命
OneNote Markdown插件:重新定义智能笔记编辑的架构革命 【免费下载链接】NoteWidget Markdown add-in for Microsoft Office OneNote 项目地址: https://gitcode.com/gh_mirrors/no/NoteWidget 你是否曾为OneNote中复杂的格式设置而烦恼?是否在技…...

Diablo Edit2:暗黑破坏神II全版本角色存档编辑器终极指南
Diablo Edit2:暗黑破坏神II全版本角色存档编辑器终极指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否厌倦了在暗黑破坏神II中花费数百小时刷装备?是否想要尝试各…...

终极Windows进程内存操控指南:Xenos DLL注入器深度实战解析
终极Windows进程内存操控指南:Xenos DLL注入器深度实战解析 【免费下载链接】Xenos Windows dll injector 项目地址: https://gitcode.com/gh_mirrors/xe/Xenos 在Windows系统开发与安全研究领域,DLL注入技术一直是连接应用程序与系统底层的关键桥…...

5步解决Windows包管理器Winget安装难题:专业修复指南
5步解决Windows包管理器Winget安装难题:专业修复指南 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh_mirrors/wi/w…...

机器学习模型虚假相关性识别与应对:四大评估框架与实战指南
1. 项目概述:当模型学会了“走捷径”在机器学习项目里摸爬滚打这么多年,我越来越觉得,模型训练最让人头疼的,不是调不出更高的准确率,而是你永远不知道它到底“学会”了什么。很多时候,模型在测试集上表现优…...

CapyMOA:Python流式机器学习框架,高效应对概念漂移与在线持续学习
1. 项目概述:为什么我们需要CapyMOA?在现实世界的机器学习应用中,数据很少是静止不动的。想象一下,你正在构建一个金融欺诈检测系统,攻击者的策略会随时间不断演变;或者是一个工业物联网传感器监控平台&…...

[智能体-28]:Python HTTP 请求库:requests 背景、原理、作用 完整版详解
一、全称与字面含义Requests:英文本意「请求、申请」Python 中:HTTP 请求库二、诞生背景Python 原生自带 urllib、urllib2语法冗长、写法繁琐、兼容性差、使用门槛高。2011 年 Kenneth Reitz 开发 requests口号:HTTP for Humans(给…...

在VirtualBox里跑Win10,远程桌面连不上?试试这个被忽略的虚拟机专用配置
VirtualBox虚拟机Win10远程桌面黑屏?这个隐藏配置项可能是关键在混合开发环境中,许多技术从业者习惯使用VirtualBox等虚拟化工具搭建多操作系统平台。一个常见场景是在Windows 7宿主机上运行Windows 10虚拟机,通过远程桌面进行跨系统操作。但…...

基于RTK-GPS与ResNet50的自主草坪清扫机器人系统设计与实践
1. 项目概述与核心挑战在公园维护的日常工作中,草坪垃圾清理是一项既耗费人力又效率低下的重复性劳动。传统的清扫方式要么依赖人工,要么使用大型、笨重且可能损伤草皮的设备。我们团队的目标,是设计并实现一个能够自主、高效且温和地完成这项…...

从PSCI到ATF:手把手带你拆解Linux ARM64平台CPU休眠唤醒的完整调用链
ARM64平台CPU休眠唤醒全链路解析:从内核到固件的技术实现在当今移动计算和嵌入式系统领域,电源管理已成为衡量系统设计优劣的关键指标之一。作为系统级电源管理的核心组成部分,CPU的休眠唤醒机制直接影响着设备的续航能力和响应速度。本文将深…...