51-54 Sora能制作动作大片还需要一段时间 | DrivingGaussian:周围动态自动驾驶场景的复合高斯飞溅
24年3月,北大、谷歌和加州大学共同发布了DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes。视图合成和可控模拟可以生成自动驾驶的极端场景Corner Case,这些安全关键情况有助于以更低成本验证和增强自动驾驶系统安全性。DrivingGaussian采用复合高斯飞溅进行全局渲染,用于表示周围动态自动驾驶场景,在多运动对象、多相机一致性以及高保真度上实现了优秀的性能。
最近我们组精读了几十篇文生图、文生视频特别是关于运动控制方面的经典论文,也实践复现了一部分,个人觉得,用AI自编剧制作出一部动作大片还尚需时日。
Abstract
我们提出了DrivingGaussian,一种用于表示周围动态自动驾驶场景的高效框架。对于运动对象复杂场景,我们首先使用增量静态三维高斯函数,对整个静态背景进行顺序渐进建模。然后,我们利用复合动态高斯图来处理多个移动对象,单独重建每个对象并恢复它们在场景中的准确位置和遮挡关系。我们进一步使用激光雷达先验进行高斯溅射,以重建具有更多细节的场景并保持全景一致性。DrivingGaussian在动态驾驶场景重建方面优于现有方法,实现了高保真度和多相机一致性的逼真环视合成。
https: //github.com/VDIGPKU/DrivingGaussian。
1. Introduction
表示和建模大规模动态场景是3D场景理解的基础,有助于一系列自动驾驶任务,如BEV感知、
- BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera lmages via Spatiotemporal Transformers
- BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework(模型名相同)
- BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
3D检测(ObjectFusion、FUTR3D)和运动规划(nuPlan、Path Planning for Autonomous Driving)。视图合成和可控模拟可以生成自动驾驶极端场景,这些安全关键情况有助于以更低成本验证和增强自动驾驶系统安全性。
不幸的是,从稀疏的车载传感器数据重建如此复杂的 3D 场景具有挑战性,尤其是当自车高速移动时。想象一个场景,车辆出现在左前摄像头捕获的无界场景边缘,迅速移动到前摄像头视图的中心,在随后的帧中缩小成一个遥远的点。对于这样的驾驶场景,自车和动态对象都以相对较高的速度移动,这对场景的构建提出了重大挑战。因为静态背景和动态对象经历快速的变化,然而由有限的视图描述。此外,在多摄像头情况下,由于它们的向外视图、最小重叠以及来自不同方向的光线变化,这变得更加具有挑战性。复杂的几何结构、多样的光学退化和时空不一致性也对360度大规模驾驶场景的建模提出了重大挑战。
神经辐射场NeRF最近已成为一种有前途的重建方法,用于对象级或房间级场景建模。最近的一些研究将NeRF扩展到大规模、无界的静态场景,而一些人专注于对场景中的多个动态对象进行建模。
- Neural Scene Graphs for Dynamic Scenes
- Towards Efficient Neural Scene Graphs by Learning Consistency Fields
然而,基于NeRF的方法计算量大,需要密集重叠视图和一致照明。这些限制了它们以高速向外的多摄像机设置构建驾驶场景的能力。此外,网络容量的限制使它们对具有多个对象的长期动态场景进行建模具有挑战性,从而导致视觉伪影和模糊。
与NeRF相比,3D高斯飞溅3DGS以更明确的3D高斯表示描述场景,并在新颖视图合成方面取得了令人印象深刻的性能。然而,由于固定的高斯和受限的表示能力,原始的3D-GS在建模大规模动态驾驶场景方面仍然面临着重大挑战。一些方法通过构建每个时间戳的高斯,将3D-GS扩展到动态场景。不幸的是,它们专注于单个动态对象,无法处理涉及高速组合静、动态区域和多个移动对象的复杂驾驶场景。
在本文中,我们介绍了DrivingGaussian,这是一个用于表示周围动态自动驾驶场景的新框架。关键思想是使用来自多个传感器序列数据分层建模复杂的驾驶场景。我们采用复合高斯飞溅将整个场景分解为静态背景和动态对象,分别重建每个部分。具体来说,我们首先使用增量静态 3D 高斯序列从周围的多摄像头视图构建综合场景。然后我们使用复合动态高斯图来单独重建每个运动对象,并根据高斯图将动态对象集成到静态背景中。在此基础上,通过高斯飞溅进行全局渲染捕获了现实世界中的遮挡关系,包括静态背景和动态对象。此外,我们在 GS 表示中加入了 LiDAR 先验,它能够恢复更精确的几何形状并保持比利用随机初始化或 SfM 生成的点云更好的多视图一致性。
大量实验表明,我们的方法在公共自动驾驶数据集上实现了最先进的性能。即使没有激光雷达先验,我们的方法仍然表现出良好的性能,证明了它在重建大规模动态场景方面的多功能性。此外,我们的框架实现了动态场景构建和极端情况模拟,有助于验证自动驾驶系统的安全性和鲁棒性。
这项工作的主要贡献是:
• 据我们所知,DrivingGaussian 是第一个基于复合高斯飞溅的大规模动态驾驶场景表示和建模框架。
• 引入了两个新的模块,包括增量静态 3D 高斯和复合动态高斯图。前者逐步重建静态背景,而后者使用高斯图对多个动态对象进行建模。在激光雷达先验的辅助下,该方法有助于在大规模驾驶场景中恢复完整的几何形状。
• 综合实验表明,在具有挑战性的自动驾驶基准测试中,DrivingGaussian 优于以前的方法,并为各种下游任务实现了极端情况的模拟。
2. Related Work
NeRF for Bounded Scenes
神经渲染技术在新视图合成中的快速发展引起了人们的广泛关注。神经辐射场(Neural Radiance Fields, NeRF)利用多层感知器MLP和可微体渲染,可以重建3D场景,并从一组2D图像和相应相机姿态信息中合成新视图。然而,NeRF仅限于有限的场景,要求中心物体和相机之间保持一致的距离。它还很难处理用轻微重叠、向外捕捉的场景。许多方法扩展了NeRF的功能,训练速度、姿态优化、场景编辑和动态场景表示有显著改进。然而,将NeRF应用于大规模的无界场景,如自动驾驶场景,仍然是一个挑战。
NeRF for Unbounded Scenes
对于大规模无界场景,Block-NeRF、Mega-NeRF引入了改进版本的NeRF来模拟多尺度城市级静态场景。受到防止混叠Mipmapping方法的启发,Mip-NeRF、Mip-NeRF 360 将NeRF扩展到无界场景。为了实现高保真渲染,Grid-guided Neural Radiance Fields for Large Urban Scenes将紧凑的多分辨率地面特征平面与大型城市场景的NeRF相结合。StreetSurf提出了一种近景与远景解纠缠方法,该方法可以对无界街景建模,但忽略了道路上的动态物体。然而,这些方法在假设场景保持静态的情况下对场景进行建模,在有效捕获动态元素方面面临挑战。
同时,以前基于NeRF的方法高度依赖于精确的相机姿势。在没有精确姿势的情况下,Robust Dynamic Radiance Fields可以从动态单目视频中进行合成。然而,这些方法仅限于前向单眼视点,并且在处理来自周围多摄像机设置的输入时遇到挑战。对于动态城市场景,Neural Scene Graphs for Dynamic Scenes使用场景图将NeRF扩展到具有多个对象的动态场景。MARS、UniSim提出针对单目动态场景的实例感知、模块化和逼真的模拟器。S-NeRF改进了周围视图的参数化和相机姿态,同时使用激光雷达作为额外的深度监督。SUDS、EmerNeRF将场景分解为静态背景和动态对象,并借助激光雷达和2D光流构建场景。
由于依赖于光线采样,上述基于NeRF方法合成的视图质量在具有多个动态对象和变化,以及光照变化的场景中会下降。此外,激光雷达的利用仅限于提供辅助深度监督,其在重建中的潜在优势,如提供几何先验,尚未得到探讨。
为了解决这些限制,我们利用复合高斯飞溅来建模无界动态场景,其中静态背景随着自车的移动而逐渐重建,多个动态对象通过高斯图建模并集成到整个场景中。使用LiDAR作为高斯的初始化,提供更精确的几何形状先验和全面的场景描述,而不是仅仅作为图像的深度监督。
3D Gaussian Splatting
最近3D-GS建模了一个具有许多3D Gaussians的静态场景,在新的视图合成和训练速度方面取得了最佳结果。与之前明确的场景表示(例如,网格,体素)相比,3D-GS可以用更少的参数建模复杂的形状。与隐式神经渲染不同,3D-GS允许快速渲染和Splat-based栅格化的可微分计算。
Dynamic 3D Gaussian Splatting
最初的3D-GS是用来表示静态场景的,一些研究人员将其扩展到动态对象/场景。给定一组动态单目图像,Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction引入了一个变形网络来模拟高斯运动。4D Gaussian Splatting for Real-Time Dynamic Scene Rendering通过HexPlane连接相邻的高斯函数,实现实时渲染。然而,这两种方法都是为聚焦在中心物体上的单目单摄像机场景而设计的。Dynamic 3D Gaussians: Tracking by Persistent Dynamic View Synthesis使用一组进化的动态高斯函数来参数化整个场景。然而,它需要一个具有密集多视图的相机阵列作为输入。
在现实世界的自动驾驶场景中,数据采集平台的高速移动导致了广泛而复杂的背景变化,然而通常由稀疏视图(例如2-4视图)捕获。此外,快速移动的动态物体具有强烈的空间变化和遮挡,使情况更加复杂。总的来说,这些因素对现有方法构成了重大的挑战。
3. Method
3.1. Composite Gaussian Splatting
3D-GS在纯静态场景中表现良好,但在涉及大规模静态背景和多个动态对象的混合场景中存在明显的局限性。如图 2 所示,我们的目标是针对无界静态背景和动态对象,采用复合高斯飞溅表示surrounding large-scale driving scenes。

图 2. DrivingGaussian总体流程。左:从多传感器包括多摄像头和激光雷达中获取序列数据。中:为了表示大规模动态驾驶场景,我们提出了复合高斯飞溅,它由两个组件组成。第一部分增量地重建广泛的静态背景,第二部分用高斯图构造多个动态对象,并将它们动态集成到场景中。右图:DrivingGaussian 在多个任务和应用场景中表现出优秀的性能。
Incremental Static 3D Gaussians
驾驶场景的静态背景由于其规模大、持续时间长,并且随着车辆自身运动的变化而发生多镜头变换,给图像处理带来了挑战。随着自车的移动,静态背景频繁地经历时间的偏移和变化。由于透视原理,过早地从远离当前的时间步中加入远处街道场景可能会导致规模混乱,产生令人不快的伪影和模糊。为了解决这个问题,我们通过引入增量静态3D高斯来增强3D- GS,利用车辆运动带来的视角变化和相邻帧之间的时间关系,如图 3 所示。
具体而言,我们首先基于LiDAR先验提供的深度范围将静态场景均匀地划分为N个bins(章节3.2)。这些bins按时间顺序排列,记为{bi}N,其中每个bins包含来自一个或多个时间步的多摄像机图像。对于第一个bin内的场景,我们使用LiDAR先验初始化高斯模型(同样适用于SfM点):
![]()
式中,l∈R3为LiDAR先验位置;μ为激光雷达点均值;Σ∈R3×3为各向异性协方差矩阵;而 T 是转置算子。我们利用该bin段内的周围视图作为监督来更新高斯模型的参数,包括位置P (x, y, z),协方差矩阵Σ,与视图相关的颜色c (r, g, b)的球面谐波系数,以及不透明度α。
对于后续的bins,我们使用前一个bin的高斯函数作为位置先验,并根据它们的重叠区域对齐相邻的bin。每个bin的三维中心可以定义为:
![]()
其中^P是当前所有可见区域的高斯坐标的三维中心集合,(xb+1, yb+1, zb+1)是b+1区域内的高斯坐标。迭代地,我们将后续bins的场景合并到先前构建的高斯分布中,并使用多个周围帧作为监督。
### 每个bin根据场景的深度进行分布,并包含一帧或多帧周围图像。相邻的bin有一个小的重叠区域,用于对齐两个bin的静态背景。后一个bin逐渐融合到前一个bin的高斯场中。此外,可以手动指定bin的分布,从而更好地适应极端或深度未知的场景。
增量静态高斯模型Gs可以定义为:
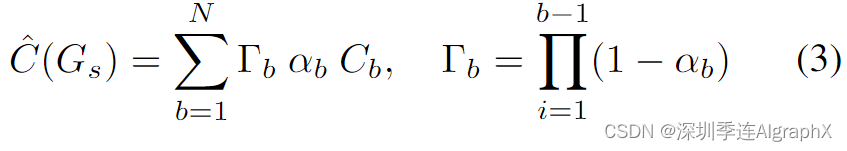
其中^C表示某一视图下每个高斯对应的颜色,α表示不透明度,Γ表示根据各bin处的α累积场景透射率。在此过程中,利用周围多相机图像之间的重叠区域共同形成高斯模型的隐式对齐。
注意,在静态高斯模型的增量构建过程中,前后摄像头对同一场景的采样可能存在差异。为了解决这个问题,我们在3D高斯投影期间使用加权平均来尽可能准确地重建场景的颜色:
![]()
其中,~C为优化的像素颜色,ς为差分飞溅,ω为不同视图的权重,[R, T]为对齐多相机视图的视图矩阵。
Composite Dynamic Gaussian Graph
自动驾驶环境高度复杂,涉及多个动态对象和时间变化。如图 3 所示,由于自车和动态对象的运动,通常从有限的视角(例如,2-4个视角)观察对象。高速还会导致动态对象的显著空间变化,这使得使用固定的高斯函数来表示它们变得具有挑战性。
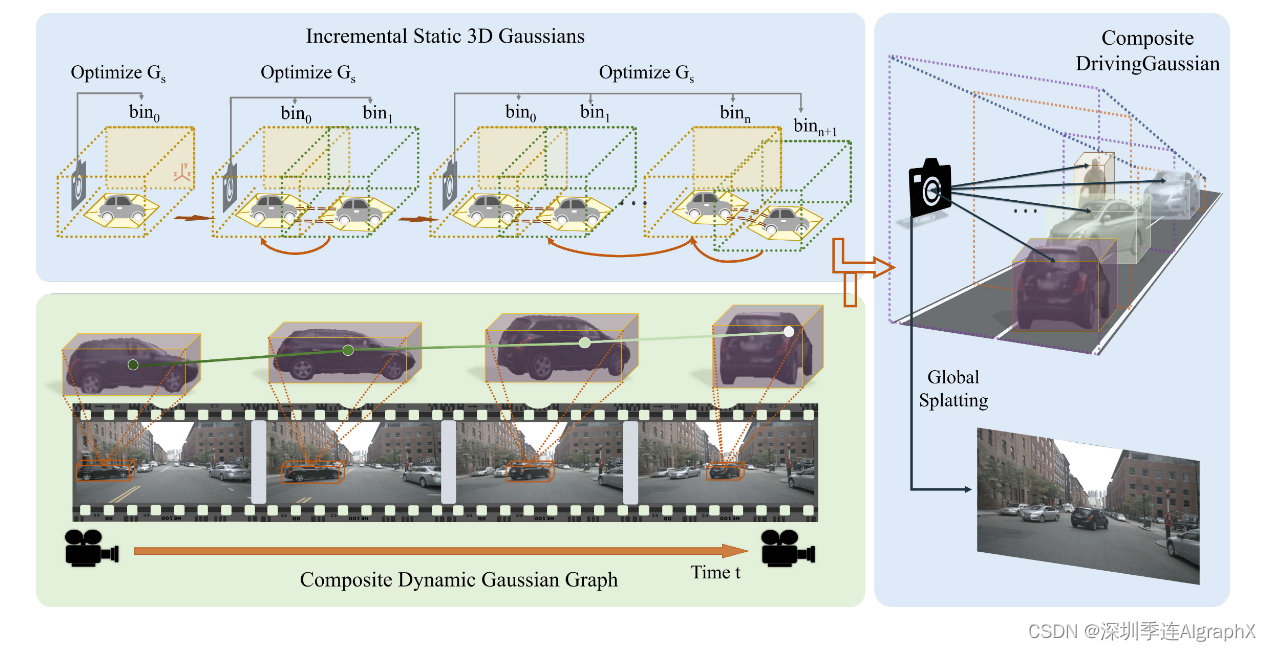
图 3. 增量静态三维高斯和动态高斯图的复合高斯飞溅。我们采用复合高斯飞溅将整个场景分解为静态背景和动态对象,分别重建每个部分并将它们集成以进行全局渲染。
为了应对这些挑战,我们引入了复合动态高斯图(Composite Dynamic Gaussian Graph),从而能够在大规模、长期的驾驶场景中构建多个动态对象。我们首先从静态背景中分解动态前景对象,利用数据集提供的边界框构建动态高斯图。动态对象通过其对象ID和相应的出现时间戳来标识。
### 动态对象是在当前场景中移动的前景实例,而停放的车辆或静态对象则不是。作者提供了两种解耦动态对象的方法,使用3D边界框或预训练的对象分割基础模型(例如,Grounded SAM、SEEM或OmniMotion)。使用3D边界框,作者将每个对象的边界框分别投影到周围视图的2D图像上,并遮罩框内的对象,并将每帧中动态对象与标注中每个对象的ID明确对齐。类似地,使用预训练的动态对象分割模型时,作者通过应用预先训练的模型并用对象ID显式地单独标注每个对象来将动态对象与静态区域分离。
然后构建动态高斯图:
![]()
其中每个节点存储一个实例对象 o∈O, gi∈Gd 表示对应的动态高斯值,mo∈M 为每个对象的变换矩阵。po(xt, yt, zt)∈P 为边界框的中心坐标,ao = (θt, φt)∈A 为时间步长 t∈ T 时边界框的方向。这里,我们分别为每个动态对象计算高斯函数。利用变换矩阵mo,我们将目标物体o的坐标系变换为静态背景所在的世界坐标:
![]()
其中R−1/o和S−1/o是每个物体对应的旋转和平移矩阵。
在对动态高斯图中的所有节点进行优化后,我们使用复合高斯图将动态对象和静态背景结合起来。每个节点的高斯分布根据边界框的位置和方向按时间顺序串联到静态高斯场中。在多个动态对象之间遮挡的情况下,我们根据距离相机中心的距离来调整不透明度:越近的物体不透明度越高。
遵循光的传播原理:
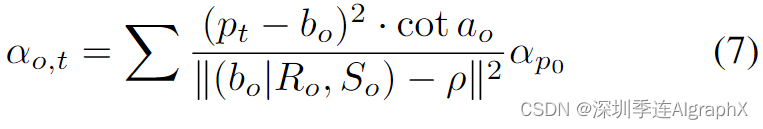
其中αo,t为在时间步长T上调整后的物体高斯不透明度,pt = (xt, yt, zt)为物体高斯中心。[Ro, So]表示对象到世界的变换矩阵,ρ表示相机视角的中心,α/po表示高斯函数的不透明度。最后,包含静态背景和多个动态对象的复合高斯场可表示为:
![]()
其中 Gs 在第 3.1 节中通过增量静态 3D 高斯获得,H 表示优化的动态高斯图。
3.2. LiDAR Prior with surrounding views
原始3D-GS尝试通过structure-from-motion(SfM)初始化高斯函数。然而,用于自动驾驶的无界城市场景包含许多多尺度背景和前景。然而,它们只能通过极其稀疏视图被看见,导致几何结构的错误和不完整的恢复。为了提供更好的高斯初始化,我们在3D高斯之前引入LiDAR,以获得更好的几何形状,并在周围视图配准中保持多相机的一致性。在每个时间步 t∈T,给定一组多相机图像{Ii/t |i = 1 . . . N },从移动平台和多帧 LiDAR 扫描 Lt 收集得来。我们的目标是利用LiDAR图像多模态数据最小化多相机配准误差,获得准确的点云位置和几何先验。
我们首先合并多帧LiDAR扫描,得到场景的完整点云,记为L。我们遵循Colmap,分别从每张图像中提取图像特征X = xq/p。接下来,我们将激光雷达点投射到周围的图像上。对于每个LiDAR点I,我们将其坐标转换为相机坐标系,并通过投影与相机图像平面的2D像素进行匹配:
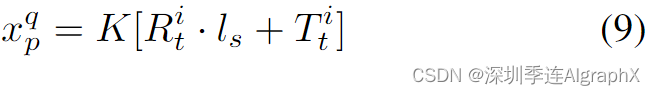
其中xq/p为图像的二维像素,Ii/t,Ri/t、Ti/t分别为正交旋转矩阵和平移向量。K∈R3×3是已知的相机内参。值得注意的是,来自激光雷达的点可能会投影到多个图像中的多个像素上。因此,我们选择距离图像平面欧氏距离最短的点作为投影点,并分配颜色。
与之前的3D重建工作类似,我们将密集束调整(DBA)扩展到多摄像机设置中,获得更新后的LiDAR点。实验结果表明,在与周围多摄像头对齐之前先进行激光雷达初始化有助于为高斯模型提供更精确的几何先验。
### 从数据集导出的激光雷达点被分类为动态前景和静态背景。在激光雷达图像配准过程中,由于拖动、混叠等原因,动态前景可能会导致错位。因此,首先基于分割标签从激光雷达点中剪切出动态对象,在场景之前获得纯静态激光雷达。然后使用多帧聚合,根据增量静态3D高斯的当前可见区域,将点云拼接在一起。
直观地说,在使用移动平台拍摄图像时,附近区域将有更多的像素来表示更精细的细节。相反,使用有限数量的粗略点来描述远处的区域。这一原理同样适用于大规模驾驶场景的3D高斯表示。利用自适应滤波算法来优化激光雷达先验;将先前获得的LiDAR点云体素化为固定大小的体素网格,根据深度沿着从相机中心向前延伸的射线划分体素栅格;接下来对表示远处视图的体素网格内的点应用距离加权并去除孤立的异常值。
3.3. Global Rendering via Gaussian Splatting
我们采用来自3D Gaussian Splatting for Real-Time Radiance Field Rendering提出的可微三维高斯飞溅渲染器ς,将全局复合三维高斯投影到2D中,其中协方差矩阵~Σ为:
![]()
其中J为透视投影的雅可比矩阵,E表示世界矩阵到相机矩阵。
复合高斯场将全局三维高斯投影到多个二维平面上,并在每个时间步使用周围视图进行监督。在全局渲染过程中,下一个时间步的高斯值最初对当前图像是不可见的,随后与相应的全局图像进行监督。
本方法的损失函数由三部分组成,遵循S3IM,我们首先将Tile Structural Similarity (TSSIM)引入到Gaussian Splatting中,它测量了渲染的Tile与相应的ground truth之间的相似性。
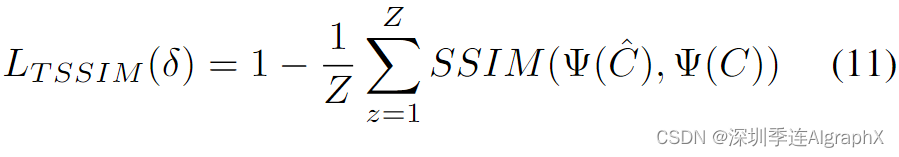
分成M块,δ 是高斯函数的训练参数,Ψ(^C)表示复合高斯飞溅的渲染块,Ψ(C)表示配对的真值块。我们还引入了鲁棒损失来降低三维高斯图像中的异常值,其可以定义为:
![]()
其中κ∈(0,1)是控制损失鲁棒性的形状参数,I和^I分别表示地面真值和合成图像。
通过监督LiDAR的期望高斯位置,进一步利用LiDAR损失,获得更好的几何结构和边缘形状:
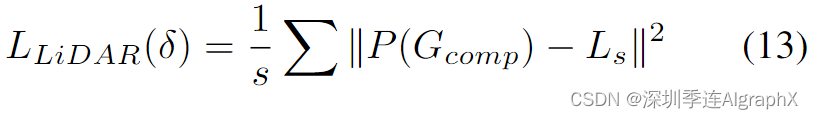
### Global rendering全局渲染的目的是还原真实驾驶场景中,多个动态物体的位置关系和遮挡,全局渲染基于高斯分布的显式几何场景结构,保留了原始遮挡关系和精确的空间位置。
4. Experiments
4.1. Datasets
nuScenes数据集是一个公开的自动驾驶大规模数据集,包含1000个驾驶场景,由多个传感器(6个摄像头,1个激光雷达等)采集。它有23个对象类的标注,具有精确的3D边界框。我们的实验使用6个具有挑战性场景的关键帧,从6个摄像头和相应的激光雷达扫描(可选)中收集周围视图作为输入。
KITTI-360数据集包含多个传感器,对应超过320k的图像和点云。尽管数据集提供了立体摄像机图像,但我们仅使用单个摄像机来证明我们的方法在单目场景中也表现良好。
4.2. Implementation Details
我们的实现主要基于3D-GS框架,通过微调优化参数来适应大规模的无界场景。我们没有使用SfM点或随机初始化点作为输入,而是使用前面3.2节中提到的LiDAR作为初始化。考虑到计算成本,我们对LiDAR点使用体素网格滤波器,在不损失几何特征的情况下减小尺度。考虑到对象在大规模场景中相对较小,我们对初始点设置为3000的动态对象采用随机初始化。我们将总训练迭代增加到50,000次,将密度梯度的阈值设置为0.001,并将不透明度间隔重置为900。增量静态三维高斯图的学习率与官方设置相同,而复合动态高斯图的学习率从1.6e-3呈指数衰减到1.6e-6。所有的实验都是在8台RTX8000上进行的,总共384gb的内存。
4.3. Results and Comparisons
Comparisons of surrounding views synthesis on nuScenes
如表 1 所示,我们的方法在很大程度上优于InstantNGP,后者使用基于哈希的NeRF进行新视图合成。Mip-NeRF和MipNeRF360是针对无界户外场景设计的两种方法,我们的方法在所有评估指标上也明显优于他们。
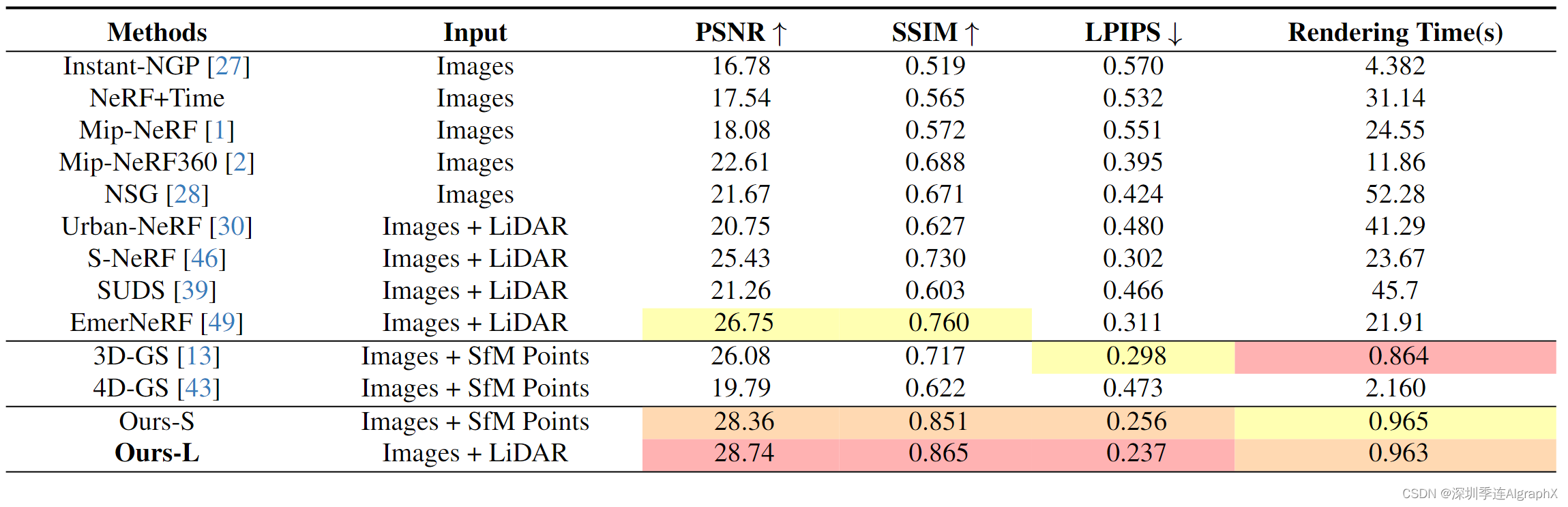
Urban -NeRF首次将激光雷达引入NeRF来重建城市场景。然而,它主要只利用激光雷达提供深度监督。相反,我们利用激光雷达作为更精确的几何先验,并将其合并到高斯模型中,这被证明对大规模场景重建更有效。与S-NeRF和SUDS相比,我们提出的方法取得了更好的效果。S-NeRF和SUDS都将场景分解为静态背景和动态对象,并借助LiDAR构建场景。与我们的主要竞争对手EmerNeRF相比,EmerNeRF使用流场对动态驾驶场景进行时空表征。我们的方法在所有指标上都优于它,消除了估计场景流的必要性。对于基于高斯的方法,我们的方法在所有评估指标上提高了我们的基线方法3D-GS在大规模场景上的性能,并获得了最佳结果。
我们还对具有挑战性的nuScenes驾驶场景与主要竞争对手EmerNeRF和3D-GS进行了定性比较。对于多摄像头的周围视图合成,如图 1 所示,我们的方法能够生成逼真的渲染图像,并确保多摄像头之间的视图一致性。与此同时,EmerNeRF和3D-GS具有挑战性的区域中表现不佳,显示出诸如重影、动态物体消失、植物纹理细节丢失、车道标记和远处场景模糊等不良视觉伪影。

我们进一步展示了动态时间场景的重建结果。我们的方法准确地模拟了大规模场景中的动态对象,减轻了这些动态元素的丢失、重影或模糊等问题。我们还在构建动态对象时保持一致性,即使它们以相对较快的速度移动。相比之下,其他两模型都无法对快速运动的动态对象进行建模,如图 4 所示。

Comparisons of mono-view synthesis on KITTI-360
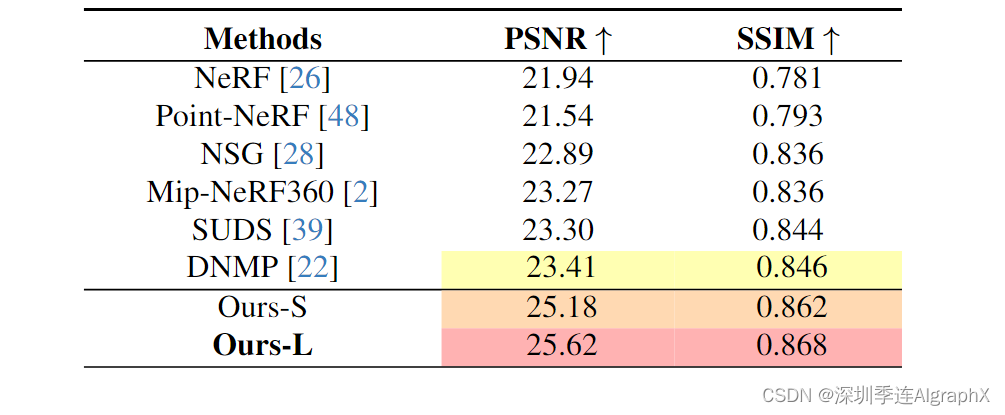
为了进一步验证我们的方法在单目驾驶场景设置上的有效性,我们在KITTI-360数据集上进行了实验,并与现有的SOTA方法进行了比较,包括基于NeRF的方法NeRF、MipNeRF360、基于点云的方法Point-NeRF、基于图的方法NSG、基于流的方法SUDS和基于网格的方法DNMP。如表 2 所示,我们的方法在单目驾驶场景中表现出最优的性能,大大超过了现有的方法。更多的结果和视频可在补充材料中找到。
4.4. Ablation Study
Initialization prior for Gaussians
通过对比实验分析了不同的先验和初始化方法对高斯模型的影响。原始3D-GS提供了两种初始化模式:随机生成点云和COLMAP计算的SfM点。我们还提供了另外两种初始化方法:从预训练的NeRF模型导出的点云和预先使用LiDAR生成的点云。同时,为了分析点云量的影响,我们将激光雷达降采样到600K,并采用自适应滤波(1M)来控制生成的激光雷达点的数量。我们还为随机生成的点设置了不同的最大阈值(600K和1M)。其中,SfM600K±20K为COLMAP计算的点数,NeRF- 1m±20K为预训练的NeRF模型生成的总点数,LiDAR- 2m±20K为LiDAR原始点数。
如表 3 所示,随机生成的点云会导致最差的结果,因为它们没有任何几何先验。
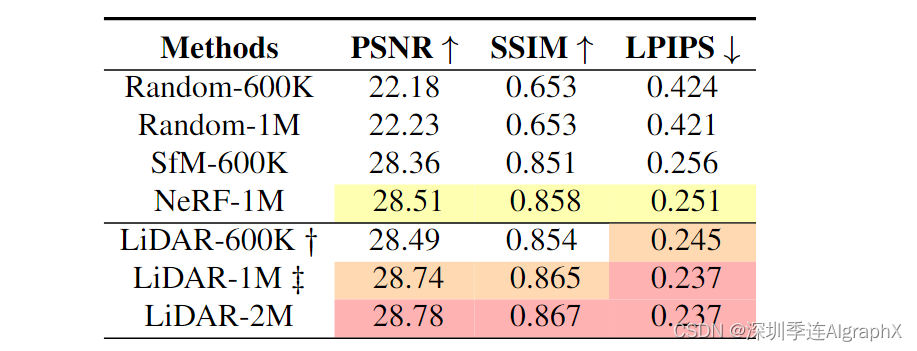
初始化的SfM点也不能充分恢复场景的精确几何形状,由于稀疏的点和不可容忍的结构误差。利用由预训练的NeRF模型生成的点云提供了相对准确的几何先验,但仍然存在明显的异常值。对于使用LiDAR先验初始化的模型,虽然降采样会导致局部区域的几何信息丢失,但仍然保留了相对准确的结构先验,从而超过了SfM(图5)。我们还可以观察到,实验结果并没有随着LiDAR点数量的增加而线性变化。我们推断这是因为过于密集的点云存储了干扰高斯模型优化的冗余特征。
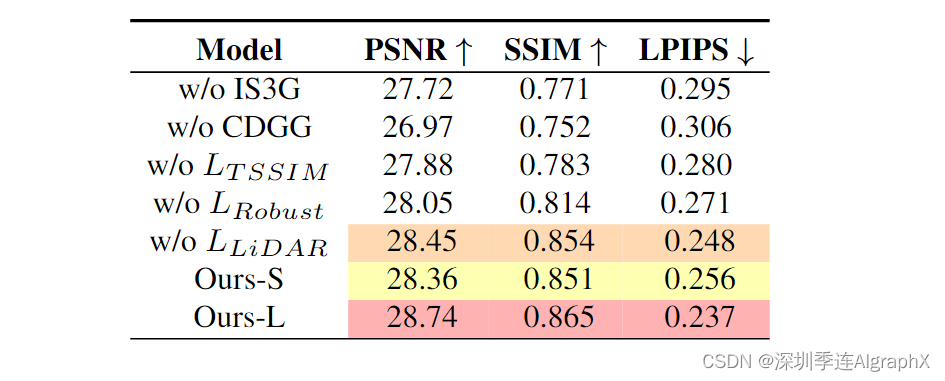
Effectiveness of Each Module
我们分析了提议的每个模块对最终性能的贡献。如表 4 所示,复合动态高斯图模块在动态驾驶场景重建中起着至关重要的作用,而增量静态三维高斯图模块则可以实现高质量的大规模背景重建。这两个新颖的模块显著提高了复杂驾驶场景的建模质量。对于所提出的损失函数,结果表明Ltssim和Lrobust都显著提高了渲染质量,增强了纹理细节并去除了伪像。Llidar在LiDAR先验的辅助下,帮助高斯函数获得更好的几何先验。实验结果还表明,即使在没有LiDAR先验的情况下,Driving-Gaussian算法也表现出良好的性能,对各种初始化方法具有很强的鲁棒性。
4.5. Corner Case Simulation
我们证明了方法在真实驾驶场景中模拟Corner Case的有效性。如图 6 所示,我们可以在重构的高斯场中插入任意动态对象。仿真场景保持了时间相干性,且多个传感器间具有良好的一致性。我们的方法实现了自动驾驶场景的可控仿真和编辑,促进了安全自动驾驶系统的研究。
Figure 6. Example of corner case simulation. A man walking on the road suddenly falls, and a car approaches ahead.
5. Conclusion
我们介绍了DrivingGaussian,这是一种利用基于复合高斯飞溅来表示大规模动态自动驾驶场景的新框架。DrivingGaussian使用增量静态3D高斯逐步对静态背景进行建模,并使用复合动态高斯图捕获多个运动对象。我们进一步利用激光雷达先验实现精确的几何结构和多视图一致性。DrivingGaussian在两个自动驾驶数据集上实现了最先进的性能,允许高质量的周围视图合成和动态场景重建。
### 局限性:主要局限性在于对极小、众多的物体(石头)和具有总反射特性(如玻璃镜和水表面)的材料进行建模。猜测这些扭曲失真主要是由于3D Gaussain在计算全反射表面密度时表示密集反射光和误差的缺点。如何重建这些具有挑战性的区域将是未来研究的重点。
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删,转发请注明出处。
DrivingGaussian-https://arxiv.org/abs/2312.07920
相关文章:
51-54 Sora能制作动作大片还需要一段时间 | DrivingGaussian:周围动态自动驾驶场景的复合高斯飞溅
24年3月,北大、谷歌和加州大学共同发布了DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes。视图合成和可控模拟可以生成自动驾驶的极端场景Corner Case,这些安全关键情况有助于以更低成本验证和增强自…...

数据挖掘实战-基于余弦相似度的印度美食推荐系统
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

深入探索DreamFusion:文本到3D生成的革命性技术
深入探索DreamFusion:文本到3D生成的革命性技术 引言: 在人工智能和计算机视觉领域,DreamFusion无疑是一个引人注目的新星。这项技术,基于Google提出的深度学习模型,将自然语言与三维内容生成紧密结合,开…...

JSP期末要点复习
一、JSP工作原理 1.客户端请求JSP页面:用户通过浏览器发送一个请求到服务器,请求一个特定的JSP页面。这个请求被服务器上的Web容器(如Apache Tomcat)接收。 2.JSP转换为Servlet:当JSP页面第一次被请求时࿰…...
)
AJAX(JavaScript版本)
目录 一.AJAX简介 二.XMLHttpRequests对象 2.1XMLHttpRequests对象简介 2.2创建XMLHttpRequests对象 2.3定义回调函数 2.4发送请求 2.5XMLHttpRequests对象方法介绍 2.6XMLHttpRequests对象属性 三.向服务器发送请求 3.1发送请求 3.2使用GET还是POST 3.3使用GET来发…...
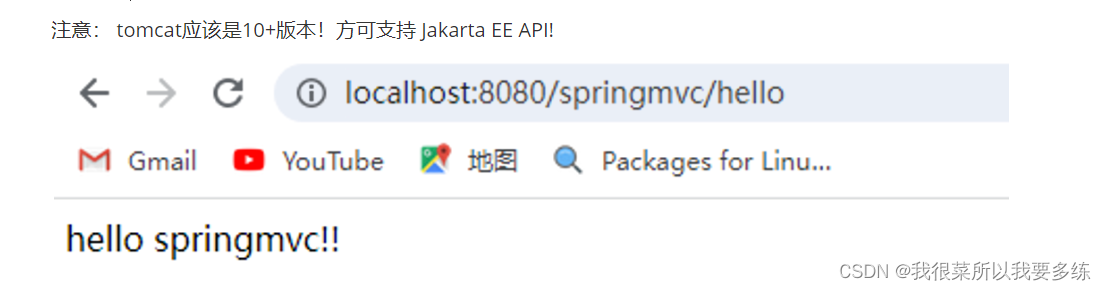
框架学习之SpringMVC学习笔记(一)
一、SpringMVC简介 1-介绍 Spring Web MVC是基于Servlet API构建的原始Web框架,从一开始就包含在Spring Framework中。正式名称“Spring Web MVC”来自其源模块的名称( spring-webmvc ),但它通常被称为“Spring MVC”。 在控制层…...

数据集005:螺丝螺母目标检测数据集(含数据集下载链接)
数据集简介 背景干净的目标检测数据集。 里面仅仅包含螺丝和螺母两种类别的目标,背景为干净的培养皿。图片数量约420张,train.txt 文件描述每个图片中的目标,label_list 文件描述类别 另附一个验证集合,有10张图片,e…...

Swift 类和结构体
类和结构体 一、结构体和类对比1、类型定义的语法2、结构体和类的实例3、属性访问4、结构体类型的成员逐一构造器 二、结构体和枚举是值类型三、类是引用类型1、恒等运算符2、指针 结构体和类作为一种通用而又灵活的结构,成为了人们构建代码的基础。你可以使用定义常…...
)
网络安全相关面试题(hw)
网络安全面试题 报错注入有哪些函数 updatexml注入 载荷注入 insert注入 updata注入 delete注入 extractvalue()注入 注入防御方法 涵数过滤 直接下载相关防范注入文件,通过incloud包含放在网站配置文件里面 PDO预处理,从PHP 5.1开始&…...
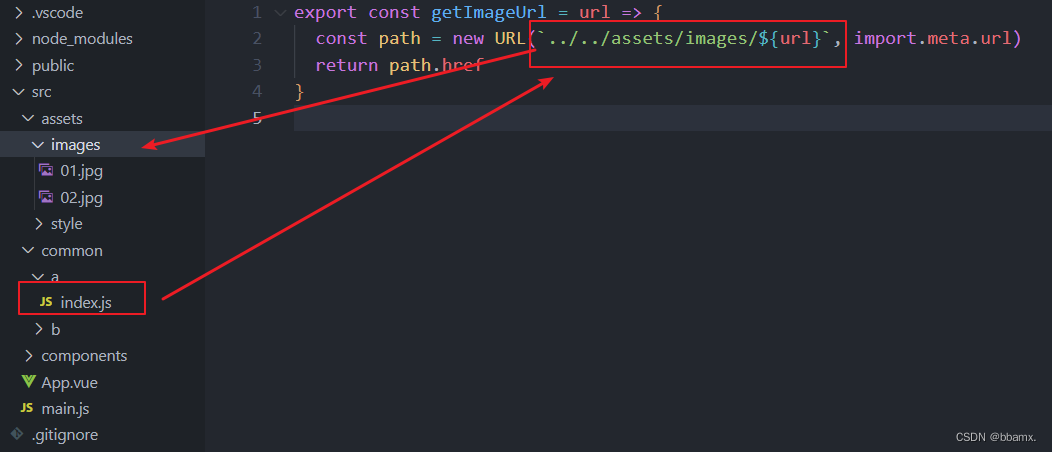
前端开发攻略---三种方法解决Vue3图片动态引入问题
目录 1、将图片放入public文件夹中 2、使用 /src/.... 路径开头 3、生成图片的完整URL地址(推荐) 1、将图片放入public文件夹中 使用图片:路径为 /public 开头 <template><div><img :src"/public/${flag ? 01 : 02}.jp…...

零售EDI:Target DVS EDI项目案例
Target塔吉特是美国一家巨型折扣零售百货集团,与全球供应商建立长远深入的合作关系,目前国内越来越多的零售产品供应商计划入驻Target。完成入驻资格审查之后,Target会向供应商提出EDI对接邀请,企业需要根据指示完成供应商EDI信息…...

AWS安全性身份和合规性之AWS Firewall Manager
AWS Firewall Manager是一项安全管理服务,可让您在AWS Organizations中跨账户和应用程序集中配置和管理防火墙规则。在创建新应用程序时,您可以借助Firewall Manager实施一套通用的安全规则,更轻松地让新应用程序和资源从一开始就达到合规要求…...
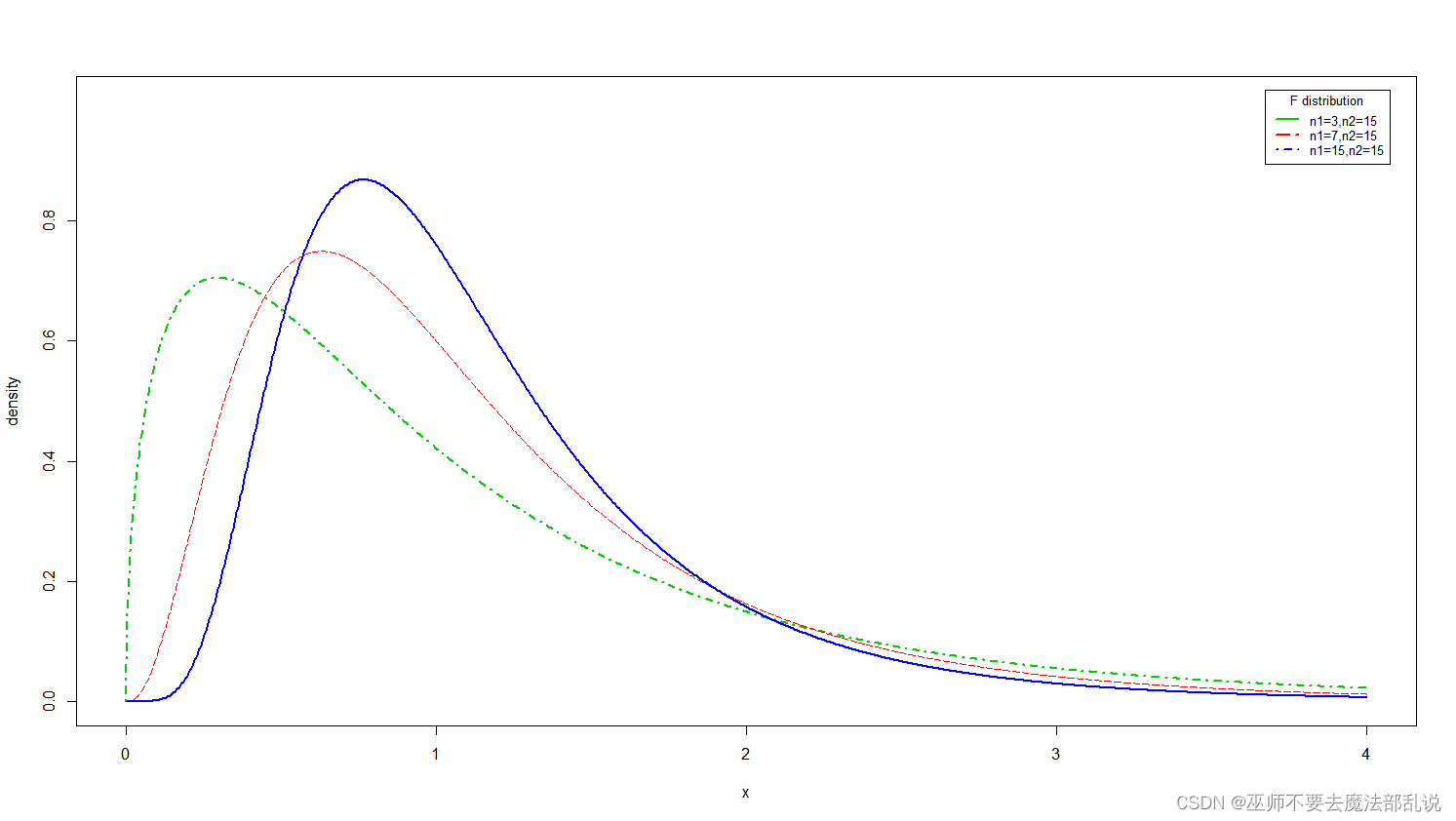
R实验 随机变量及其分布
实验目的: 掌握常见几种离散性随机变量及其分布在R语言中对应的函数用法;掌握常见几种连续性随机变量及其分布在R语言中对应的函数用法;掌握统计量的定义及统计三大抽样分布在R语言中对应的函数用法。 实验内容: (习题…...

rapidssl泛域名https600元一年
泛域名https证书也可以称之为通配符https证书,指的是可以用一张https证书为多个网站(主域名以及主域名下的所有子域名网站)传输数据加密,并且提供身份认证服务的数字证书产品。RapidSSL旗下的泛域名https证书性价比高,申请速度快,…...
月薪5万是怎样谈的?
知识星球(星球名:芯片制造与封测技术社区,星球号:63559049)里的学员问:目前是晶圆厂的PE,但是想跳槽谈了几次薪水,都没法有大幅度的增长,该怎么办?“学得文武…...
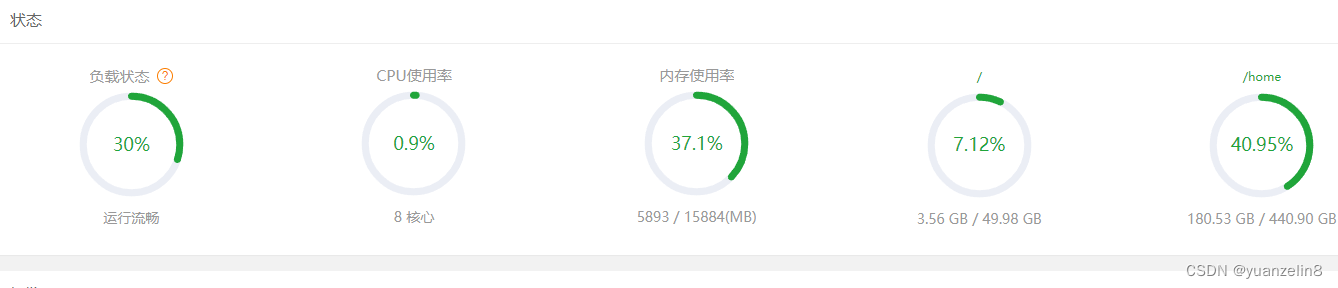
linux下宝塔负载100%解决方法
今天发现服务器宝塔面板负载居然是100% 但是cpu 和内存其实并不高 通过命令查看主机 uptime 中load average 居然高达18.23 看来负载是真的高了 通过vmstat 看看具体问题 procs: r 表示运行和等待CPU时间片的进程数,这个值如果长期大于系统CPU个数…...
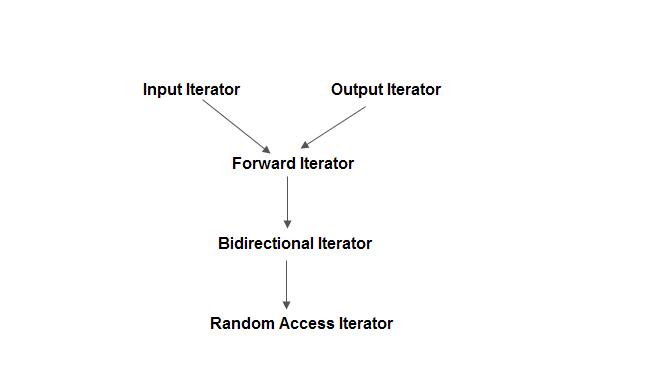
【C++】STL快速入门基础
文章目录 STL(Standard Template Library)1、一般介绍2、STL的六大组件2.1、STL容器2.2、STL迭代器2.3、相关容器的函数vectorpairstringqueuepriority_queuestackdequeset, map, multiset, multimapunordered_set, unordered_map, unordered_multiset, …...

面向对象编程的魅力与实战:以坦克飞机大战为例
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、面向对象编程的引言 二、理解面向对象编程与面向过程编程的差异 三、创建类与对象&…...

二叉树——堆的实现
一.前言 前面我们讲解了二叉树的概念以及二叉树的存储结构:https://blog.csdn.net/yiqingaa/article/details/139224974?spm1001.2014.3001.5502 今天我们主要讲讲二叉树的存储结构,以及堆的实现。 二.正文 1.二叉树的顺序结构及实现 1.1二叉树的顺序…...

【Spring】DynamicDataSourceHolder 动态数据源切换
【Spring】DynamicDataSourceHolder 动态数据源切换 常见场景常见工具一、AbstractRoutingDataSource1.1、 定义 DynamicDataSourceHolder1.2、 配置动态数据源1.3、 在Spring配置中定义数据源1.4、在业务代码中切换数据源 二、Dynamic Datasource for Spring Boot2.1. 添加依赖…...

神经网络辅助可变形匹配滤波器在光通信中的应用
1. 神经网络辅助可变形匹配滤波器技术解析在光通信系统中,匹配滤波器作为信号检测的关键组件,其性能直接影响整个通信链路的可靠性。传统固定匹配滤波器基于理想信道假设设计,当面对实际系统中的带宽限制、大气湍流等复杂信道条件时ÿ…...

AI时代的个人隐私与网络安全自保——从账号密码到设备行为的完整体系
一个很多人没做但很简单的事:去搜索一下自己的真实姓名、手机号、家庭住址,看看哪些信息已经公开在网上。知道自己的暴露面,才知道要重点保护什么。 haveibeenpwned是免费、靠谱、隐私友好的数据泄露查询工具。 安全防护不追求完美࿰…...

【企业级AI Agent操作安全白皮书】:基于ISO/IEC 27001与NIST AI RMF的6类操作审计红线
更多请点击: https://codechina.net 第一章:AI Agent自主操作软件的定义与安全治理边界 AI Agent自主操作软件是指具备感知环境、规划决策、调用工具(如API、CLI、GUI自动化接口)并闭环执行任务能力的智能体系统。其核心特征在于…...

Mootdx架构深度解析:Python金融数据接口的工程化实践
Mootdx架构深度解析:Python金融数据接口的工程化实践 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融科技快速发展的今天,数据获取的便捷性与稳定性成为量化分析的基…...

LeetCode 930:和相同的二元子数组 | 前缀和与哈希表
LeetCode 930:和相同的二元子数组 | 前缀和与哈希表 引言 和相同的二元子数组(Binary Subarrays With Sum)是 LeetCode 第 930 题,难度为 Medium。题目要求在二元数组(元素只有 0 和 1)中找出子数组和等于 …...

《离别的最后》的内容入口:收尾场景如何被记住
从内容传播角度看,《离别的最后》的入口在“最后”这个收束动作。它不是笼统告别,而是写到一段关系、一个阶段或一次转身即将落下尾音的时刻。这首歌不适合被写成普通伤感推荐。更准确的角度,是把它放在收尾场景里:删掉草稿、收起…...

Oracle EBS关联公司段的设计逻辑和设计哲学
从设计逻辑 → 核心原理 → 完整配置事例 → 业务分录实例 → 常见坑的完整说明,全部围绕 “关联公司段(Intercompany Company Segment)” 在 EBS R12 里的设计与实现,不绕弯一、关联公司段的 “设计核心逻辑”1. 本质定义关联公司…...

【教育部“人工智能+教育”试点标杆】:从零部署到常态化应用——某省327所乡村校6个月落地实录
更多请点击: https://intelliparadigm.com 第一章:PlayAI教育领域应用案例 PlayAI 作为面向教育场景的轻量级AI交互平台,已在多个K12及职业教育机构落地实践,聚焦于个性化学习路径生成、实时学情反馈与智能助教协同三大方向。其核…...
)
为什么顶尖团队禁用Claude自动生成微服务?(内部泄露的5条红线规则与替代性增强方案)
更多请点击: https://intelliparadigm.com 第一章:为什么顶尖团队禁用Claude自动生成微服务?(内部泄露的5条红线规则与替代性增强方案) 顶尖工程团队在微服务架构演进中,普遍将大语言模型(LLM&…...

使用curl命令快速测试Taotoken大模型API连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令快速测试Taotoken大模型API连通性 在集成大模型能力时,开发者通常需要一种快速、直接的方式来验证API的连…...