数据挖掘实战-基于余弦相似度的印度美食推荐系统

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3数据可视化
4.4特征工程
4.5关联规则
4.6推荐菜肴
5.总结
源代码
1.项目背景
在数字化时代,随着人们对个性化服务的需求不断增长,推荐系统已成为各类应用中的关键组成部分。特别是在美食领域,用户常常面临从众多选择中挑选合适菜肴的难题。印度美食以其丰富的口味和独特的烹饪方式而著称,但用户往往难以从海量的印度美食中挑选出符合自己口味的菜品。因此,开发一个能够准确推荐印度美食的个性化推荐系统具有重要的现实意义和应用价值。
传统的推荐方法往往基于用户的历史行为数据或评分数据进行相似度计算,但这些方法可能受到数据稀疏性和冷启动问题的限制。余弦相似度作为一种衡量向量间相似性的有效方法,具有不受向量长度影响、对方向敏感等特点,使其在推荐系统中具有广泛的应用前景。通过将印度美食的特征表示为向量,并利用余弦相似度计算用户与菜品之间的相似度,可以更准确地捕捉用户的口味偏好,从而为用户提供个性化的美食推荐。
此外,印度美食文化具有深厚的历史底蕴和地域特色,不同地区和民族的美食风格各异。因此,一个有效的印度美食推荐系统需要能够充分考虑这些文化因素,为用户提供符合其口味和文化背景的推荐结果。基于余弦相似度的推荐方法可以通过灵活调整向量表示和相似度计算方式,更好地融入这些文化因素,提高推荐的准确性和用户满意度。
综上所述,基于余弦相似度的印度美食推荐系统实验的研究背景涵盖了个性化服务需求、印度美食文化的丰富性、传统推荐方法的局限性以及余弦相似度在推荐系统中的优势等多个方面。通过对这些方面进行深入研究和探索,有望为印度美食推荐系统的发展提供新的思路和方法。
2.数据集介绍
印度美食由印度次大陆本土的各种地区和传统美食组成。由于土壤、气候、文化、种族和职业的多样性,这些菜肴差异很大,并使用当地可用的香料、香草、蔬菜和水果。印度食物也深受宗教(特别是印度教)、文化选择和传统的影响。
本数据集来源于Kaggle,原始数据集共有255条,8个变量,各变量含义解释如下:
name : 菜肴名称
ingredients:主要使用成分
diet:饮食类型 - 素食或非素食
prep_time : 准备时间
Cook_time : 烹饪时间
flavor_profile : 风味特征包括菜品是否辣、甜、苦等
course : 餐点 - 开胃菜、主菜、甜点等
state : 该菜肴著名或起源的州
Region : 国家所属地区
任何列中出现 -1 表示 NaN 值。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
导入第三方库并加载数据集


查看数据大小

查看数据基本信息
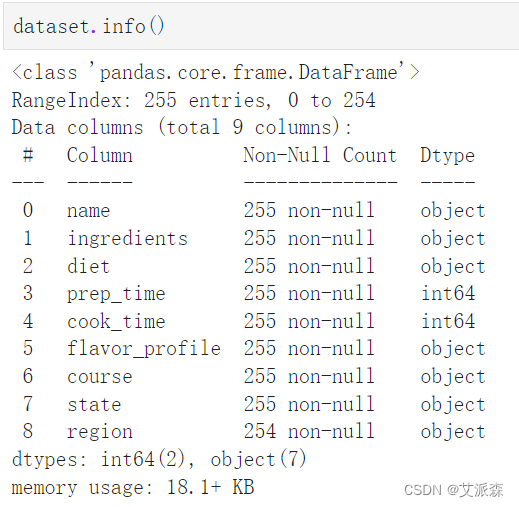
查看数值型变量的描述性统计
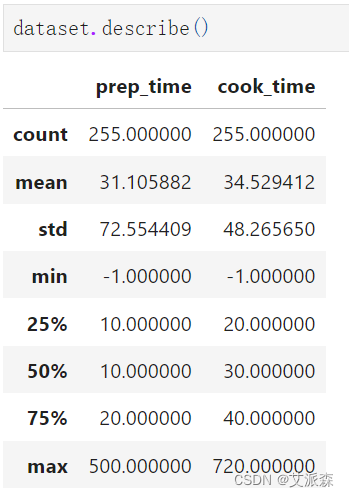
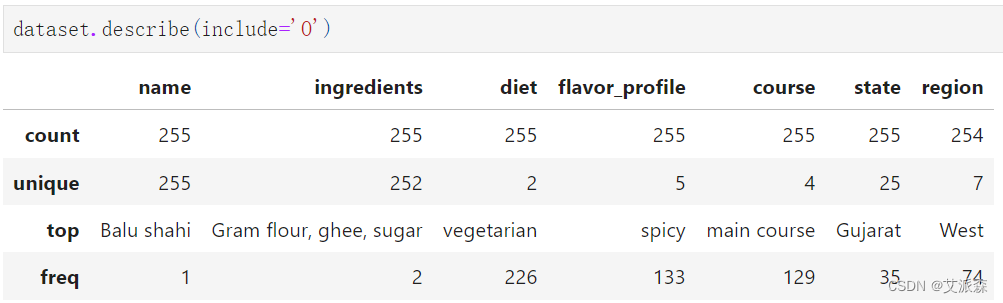
查看非数值型变量的描述性统计
4.2数据预处理
统计缺失值情况
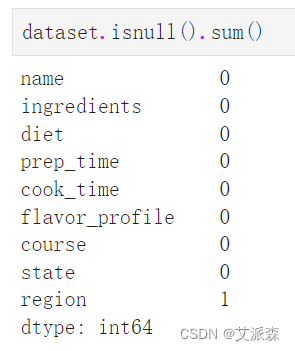
可以发现region列有一个缺失值需要处理
统计重复值情况
可以发现数据中不存在重复值
删除缺失值
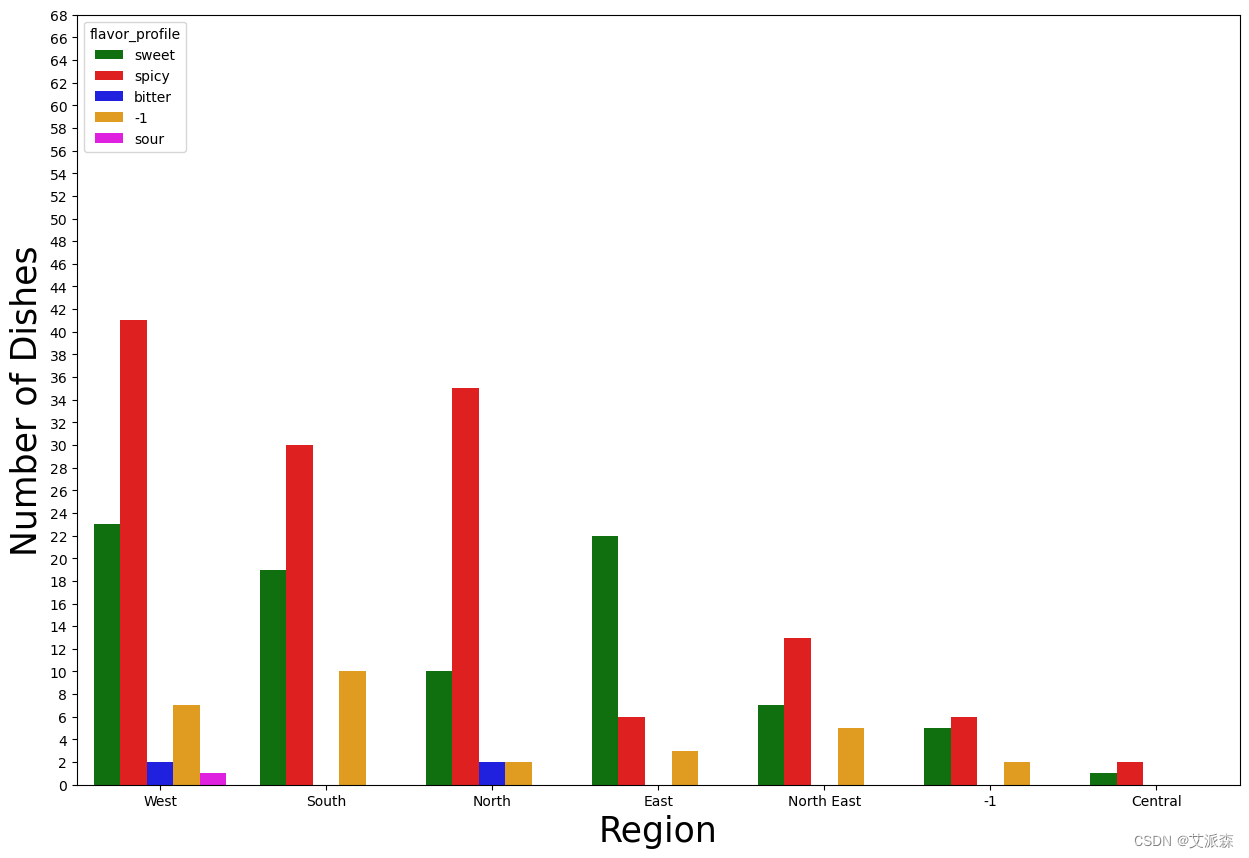
4.3数据可视化



4.4特征工程
筛选特征

编码处理

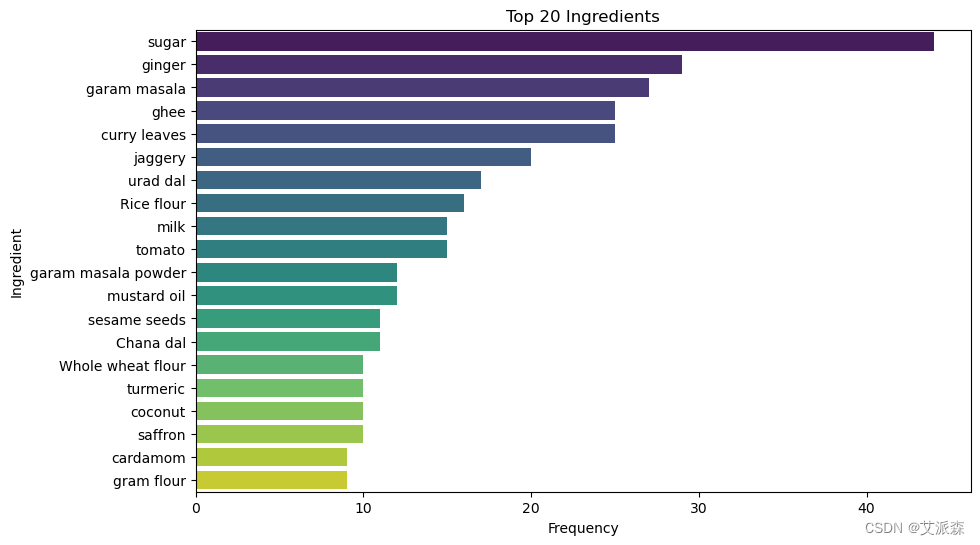
统计前20名菜肴成分

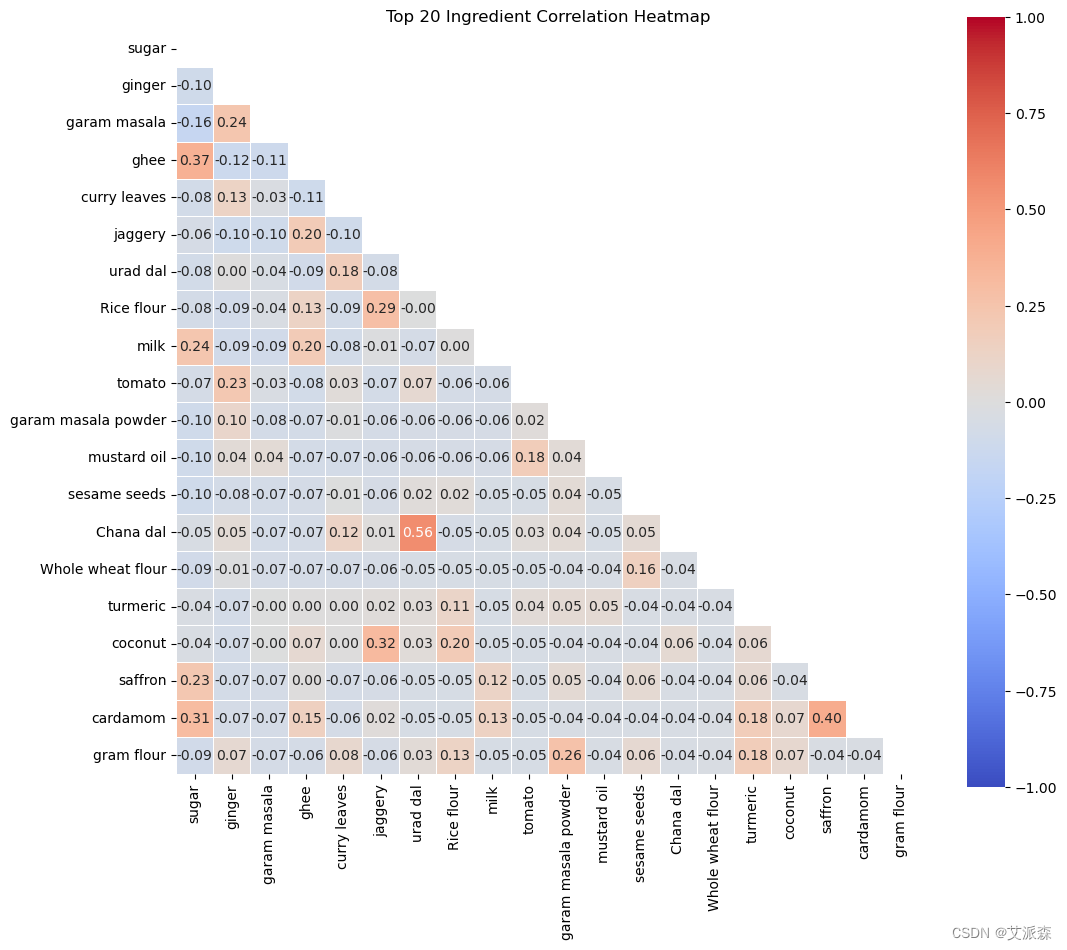
计算前20种成分的相关性

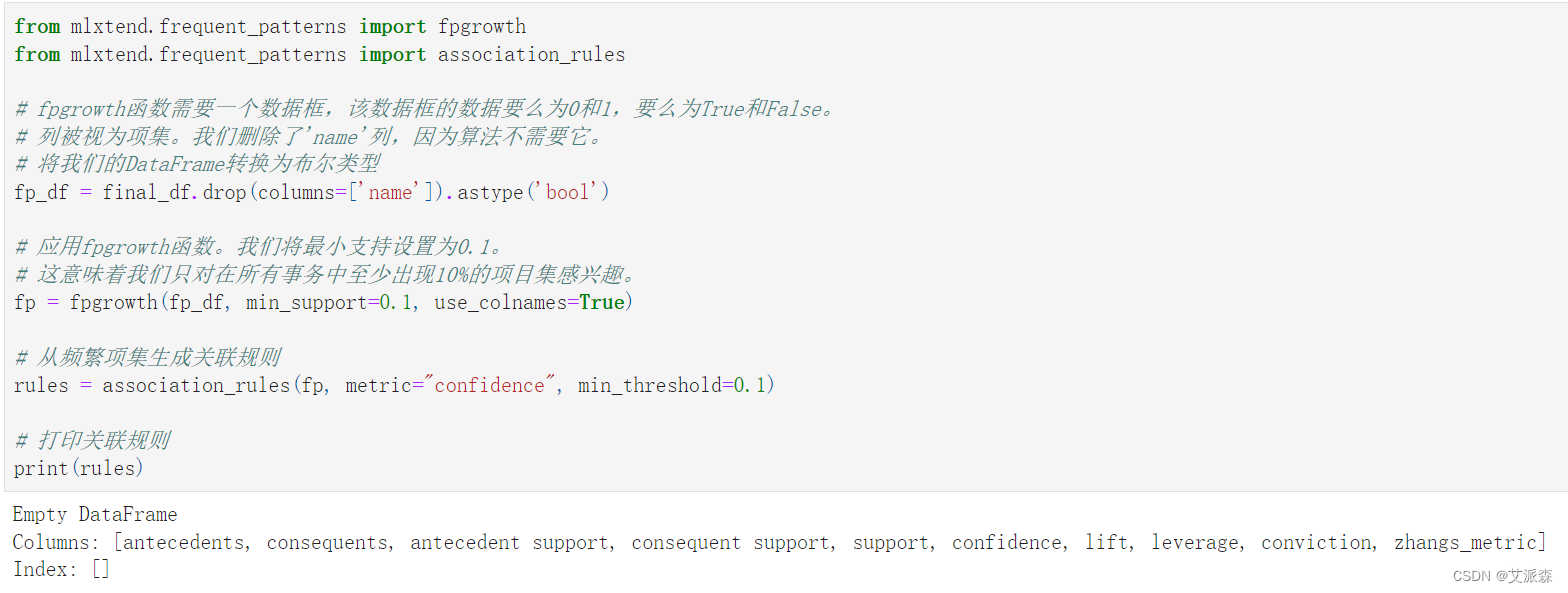
4.5关联规则
4.6推荐菜肴
计算余弦相似矩阵并自定义一个推荐菜肴的函数

让我们推荐一道菜

5.总结
通过采用余弦相似度作为核心相似度度量方法,本实验成功构建了一个个性化印度美食推荐系统。实验结果表明,该系统能够有效地捕捉用户的口味偏好,并根据用户的个性化需求提供准确的美食推荐。与传统的推荐方法相比,基于余弦相似度的推荐方法在处理印度美食推荐问题时表现出了更高的准确性和稳定性。此外,该系统还具有一定的灵活性和可扩展性,能够适应不同用户群体和美食文化背景的需求。综上所述,基于余弦相似度的印度美食推荐系统为用户提供了更加便捷、个性化的美食选择体验,具有广阔的应用前景和进一步优化的潜力。
源代码
name : 菜肴名称
ingredients:主要使用成分
diet:饮食类型 - 素食或非素食
prep_time : 准备时间
Cook_time : 烹饪时间
flavor_profile : 风味特征包括菜品是否辣、甜、苦等
course : 餐点 - 开胃菜、主菜、甜点等
state : 该菜肴著名或起源的州
Region : 国家所属地区
任何列中出现 -1 表示 NaN 值。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')dataset = pd.read_csv('indian_food.csv')
dataset.head()
dataset.shape
dataset.info()
dataset.describe()
dataset.describe(include='O')
dataset.isnull().sum()
dataset.duplicated().sum()
dataset.dropna(inplace=True)
dataset.isnull().sum()
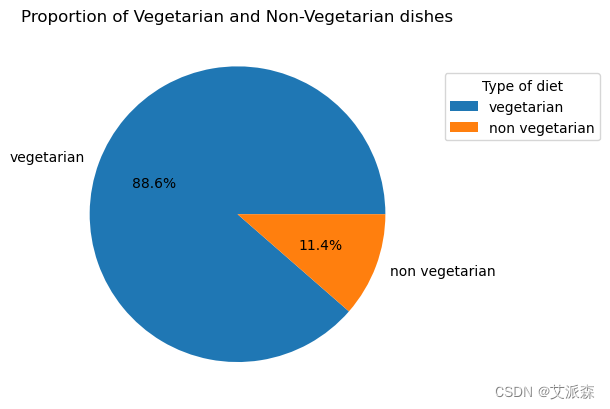
plt.pie(dataset['diet'].value_counts(), labels = dataset.diet.unique(), autopct='%1.1f%%')
plt.title('Proportion of Vegetarian and Non-Vegetarian dishes')
plt.legend(title='Type of diet', loc = 'upper right', bbox_to_anchor=(1.50, 0.90))
plt.show()
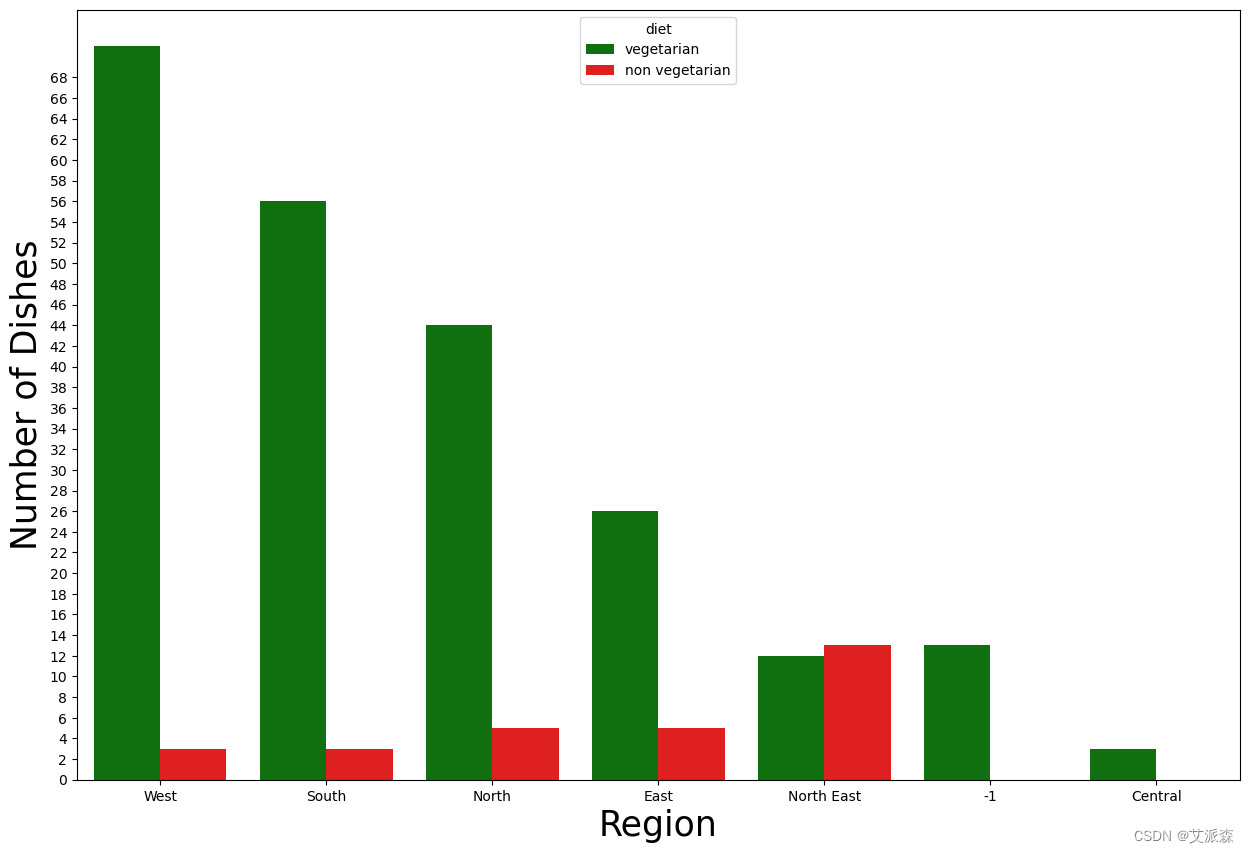
plt.figure(figsize=(15,10))
sns.countplot(x="region", data=dataset,palette =['green','red'], hue ="diet", order = dataset.region.value_counts().index)
plt.yticks(np.arange(0,70, step=2))
plt.xlabel("Region", fontsize = 25)
plt.ylabel("Number of Dishes", fontsize=25)
plt.title("")
plt.show()
plt.figure(figsize=(15,10))
sns.countplot(x="region", data=dataset,palette =['green','red','blue','orange','magenta'], hue ="flavor_profile", order = dataset.region.value_counts().index)
plt.yticks(np.arange(0,70, step=2))
plt.xlabel("Region", fontsize = 25)
plt.ylabel("Number of Dishes", fontsize=25)
plt.title("")
plt.show()
# 从数据集中提取一些特征来工作
new_df = dataset[['name','ingredients']]
new_df.head()
# 用逗号分隔成分,并去掉空白
new_df['ingredients'] = new_df['ingredients'].str.split(',').apply(lambda x: [i.strip() for i in x])
from sklearn.preprocessing import MultiLabelBinarizer
# 初始化MultiLabelBinarizer
mlb = MultiLabelBinarizer()
# 拟合和变换配料列
one_hot = mlb.fit_transform(new_df['ingredients'])
# 将单热编码结果转换为DataFrame并设置列名
one_hot_df = pd.DataFrame(one_hot, columns=mlb.classes_)
# 将原始DataFrame与单热编码的DataFrame连接起来
final_df = pd.concat([new_df['name'], one_hot_df], axis=1)
import matplotlib.pyplot as plt
import seaborn as sns
# 对每一行求和得到每个成分的频率
ingredient_freq = final_df.drop(columns='name').sum()
# 排序并选出前20名
top_ingredients = ingredient_freq.sort_values(ascending=False)[:20]
plt.figure(figsize=(10, 6))
sns.barplot(x=top_ingredients.values, y=top_ingredients.index, palette='viridis')
plt.title('Top 20 Ingredients')
plt.xlabel('Frequency')
plt.ylabel('Ingredient')
plt.show()
# 计算前20种成分的相关性
correlations = final_df[top_ingredients.index.to_list()].corr()# Mask以消除重复/自相关性
mask = np.triu(np.ones_like(correlations, dtype=bool))# 用Mask绘制热图
plt.figure(figsize=(12, 10))
sns.heatmap(correlations, mask=mask, cmap='coolwarm', vmax=1, vmin=-1, square=True, linewidths=.5, annot=True, fmt=".2f")
plt.title('Top 20 Ingredient Correlation Heatmap')
plt.show()
from mlxtend.frequent_patterns import fpgrowth
from mlxtend.frequent_patterns import association_rules# fpgrowth函数需要一个数据框,该数据框的数据要么为0和1,要么为True和False。
# 列被视为项集。我们删除了'name'列,因为算法不需要它。
# 将我们的DataFrame转换为布尔类型
fp_df = final_df.drop(columns=['name']).astype('bool')# 应用fpgrowth函数。我们将最小支持设置为0.1。
# 这意味着我们只对在所有事务中至少出现10%的项目集感兴趣。
fp = fpgrowth(fp_df, min_support=0.1, use_colnames=True)# 从频繁项集生成关联规则
rules = association_rules(fp, metric="confidence", min_threshold=0.1)# 打印关联规则
print(rules)
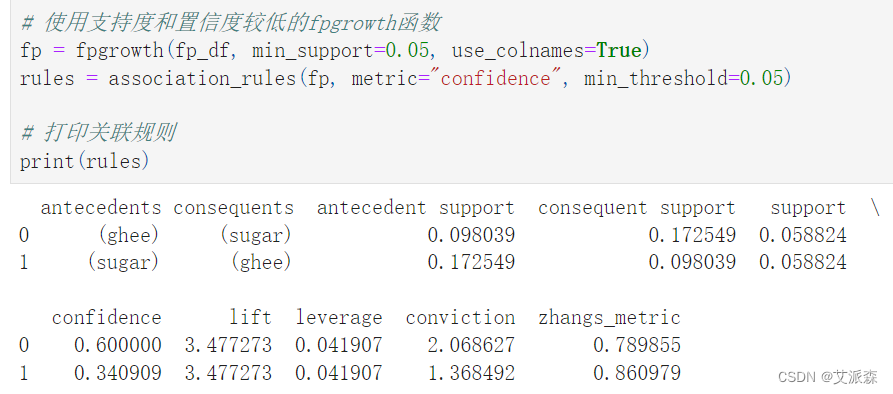
# 使用支持度和置信度较低的fpgrowth函数
fp = fpgrowth(fp_df, min_support=0.05, use_colnames=True)
rules = association_rules(fp, metric="confidence", min_threshold=0.05)# 打印关联规则
print(rules)
from sklearn.metrics.pairwise import cosine_similarity# 计算余弦相似矩阵
cosine_sim = cosine_similarity(final_df.drop(columns=['name']))
def get_recommendations(name, cosine_sim=cosine_sim):# 获取与该名称匹配的菜的索引idx = final_df.index[final_df['name'] == name][0]# 得到所有菜品与这道菜的两两相似度sim_scores = list(enumerate(cosine_sim[idx]))# 根据相似度评分对菜肴进行排序sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)# 得到10个最相似的菜的分数sim_scores = sim_scores[1:11]# 获取菜肴指数dish_indices = [i[0] for i in sim_scores]# 返回10个最相似的菜肴return final_df['name'].iloc[dish_indices]
# 让我们推荐一道菜
print(get_recommendations('Balu shahi'))
资料获取,更多粉丝福利,关注下方公众号获取

相关文章:
数据挖掘实战-基于余弦相似度的印度美食推荐系统
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

深入探索DreamFusion:文本到3D生成的革命性技术
深入探索DreamFusion:文本到3D生成的革命性技术 引言: 在人工智能和计算机视觉领域,DreamFusion无疑是一个引人注目的新星。这项技术,基于Google提出的深度学习模型,将自然语言与三维内容生成紧密结合,开…...

JSP期末要点复习
一、JSP工作原理 1.客户端请求JSP页面:用户通过浏览器发送一个请求到服务器,请求一个特定的JSP页面。这个请求被服务器上的Web容器(如Apache Tomcat)接收。 2.JSP转换为Servlet:当JSP页面第一次被请求时࿰…...
)
AJAX(JavaScript版本)
目录 一.AJAX简介 二.XMLHttpRequests对象 2.1XMLHttpRequests对象简介 2.2创建XMLHttpRequests对象 2.3定义回调函数 2.4发送请求 2.5XMLHttpRequests对象方法介绍 2.6XMLHttpRequests对象属性 三.向服务器发送请求 3.1发送请求 3.2使用GET还是POST 3.3使用GET来发…...
框架学习之SpringMVC学习笔记(一)
一、SpringMVC简介 1-介绍 Spring Web MVC是基于Servlet API构建的原始Web框架,从一开始就包含在Spring Framework中。正式名称“Spring Web MVC”来自其源模块的名称( spring-webmvc ),但它通常被称为“Spring MVC”。 在控制层…...

数据集005:螺丝螺母目标检测数据集(含数据集下载链接)
数据集简介 背景干净的目标检测数据集。 里面仅仅包含螺丝和螺母两种类别的目标,背景为干净的培养皿。图片数量约420张,train.txt 文件描述每个图片中的目标,label_list 文件描述类别 另附一个验证集合,有10张图片,e…...

Swift 类和结构体
类和结构体 一、结构体和类对比1、类型定义的语法2、结构体和类的实例3、属性访问4、结构体类型的成员逐一构造器 二、结构体和枚举是值类型三、类是引用类型1、恒等运算符2、指针 结构体和类作为一种通用而又灵活的结构,成为了人们构建代码的基础。你可以使用定义常…...
)
网络安全相关面试题(hw)
网络安全面试题 报错注入有哪些函数 updatexml注入 载荷注入 insert注入 updata注入 delete注入 extractvalue()注入 注入防御方法 涵数过滤 直接下载相关防范注入文件,通过incloud包含放在网站配置文件里面 PDO预处理,从PHP 5.1开始&…...
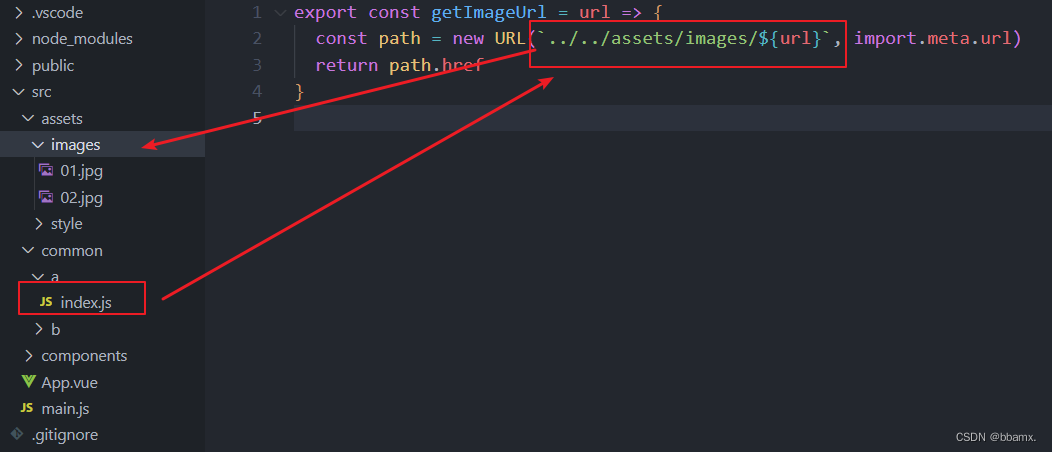
前端开发攻略---三种方法解决Vue3图片动态引入问题
目录 1、将图片放入public文件夹中 2、使用 /src/.... 路径开头 3、生成图片的完整URL地址(推荐) 1、将图片放入public文件夹中 使用图片:路径为 /public 开头 <template><div><img :src"/public/${flag ? 01 : 02}.jp…...

零售EDI:Target DVS EDI项目案例
Target塔吉特是美国一家巨型折扣零售百货集团,与全球供应商建立长远深入的合作关系,目前国内越来越多的零售产品供应商计划入驻Target。完成入驻资格审查之后,Target会向供应商提出EDI对接邀请,企业需要根据指示完成供应商EDI信息…...

AWS安全性身份和合规性之AWS Firewall Manager
AWS Firewall Manager是一项安全管理服务,可让您在AWS Organizations中跨账户和应用程序集中配置和管理防火墙规则。在创建新应用程序时,您可以借助Firewall Manager实施一套通用的安全规则,更轻松地让新应用程序和资源从一开始就达到合规要求…...
R实验 随机变量及其分布
实验目的: 掌握常见几种离散性随机变量及其分布在R语言中对应的函数用法;掌握常见几种连续性随机变量及其分布在R语言中对应的函数用法;掌握统计量的定义及统计三大抽样分布在R语言中对应的函数用法。 实验内容: (习题…...

rapidssl泛域名https600元一年
泛域名https证书也可以称之为通配符https证书,指的是可以用一张https证书为多个网站(主域名以及主域名下的所有子域名网站)传输数据加密,并且提供身份认证服务的数字证书产品。RapidSSL旗下的泛域名https证书性价比高,申请速度快,…...
月薪5万是怎样谈的?
知识星球(星球名:芯片制造与封测技术社区,星球号:63559049)里的学员问:目前是晶圆厂的PE,但是想跳槽谈了几次薪水,都没法有大幅度的增长,该怎么办?“学得文武…...
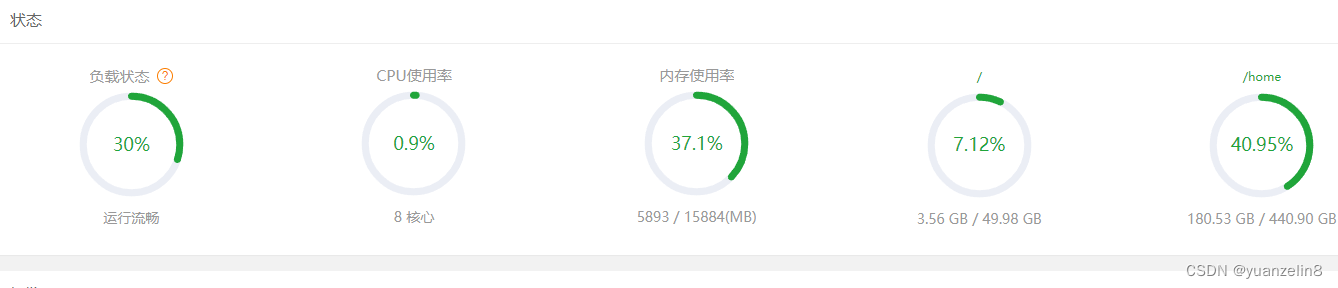
linux下宝塔负载100%解决方法
今天发现服务器宝塔面板负载居然是100% 但是cpu 和内存其实并不高 通过命令查看主机 uptime 中load average 居然高达18.23 看来负载是真的高了 通过vmstat 看看具体问题 procs: r 表示运行和等待CPU时间片的进程数,这个值如果长期大于系统CPU个数…...
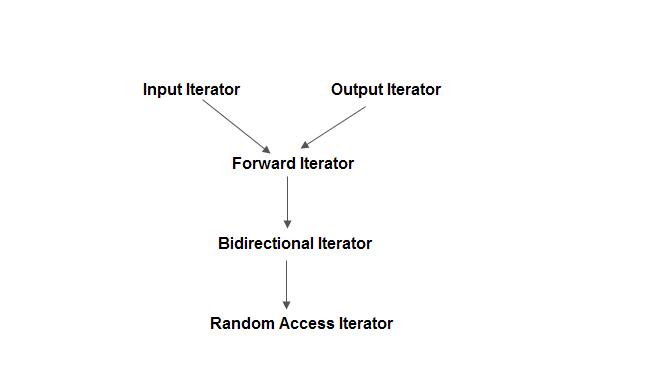
【C++】STL快速入门基础
文章目录 STL(Standard Template Library)1、一般介绍2、STL的六大组件2.1、STL容器2.2、STL迭代器2.3、相关容器的函数vectorpairstringqueuepriority_queuestackdequeset, map, multiset, multimapunordered_set, unordered_map, unordered_multiset, …...

面向对象编程的魅力与实战:以坦克飞机大战为例
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、面向对象编程的引言 二、理解面向对象编程与面向过程编程的差异 三、创建类与对象&…...

二叉树——堆的实现
一.前言 前面我们讲解了二叉树的概念以及二叉树的存储结构:https://blog.csdn.net/yiqingaa/article/details/139224974?spm1001.2014.3001.5502 今天我们主要讲讲二叉树的存储结构,以及堆的实现。 二.正文 1.二叉树的顺序结构及实现 1.1二叉树的顺序…...

【Spring】DynamicDataSourceHolder 动态数据源切换
【Spring】DynamicDataSourceHolder 动态数据源切换 常见场景常见工具一、AbstractRoutingDataSource1.1、 定义 DynamicDataSourceHolder1.2、 配置动态数据源1.3、 在Spring配置中定义数据源1.4、在业务代码中切换数据源 二、Dynamic Datasource for Spring Boot2.1. 添加依赖…...

LeeCode 3165 线段树
题意 传送门 LeeCode 3165 不包含相邻元素的子序列的最大和 题解 考虑不含相邻子序列的最大和,在不带修改的情况下容易想到,以最后一个元素是否被选取为状态进行DP。从线性递推的角度难以处理待修改的情况。 从分治的角度考虑,使用线段树…...

可解释AI在宏基因组学中的应用:从黑箱预测到透明洞察
1. 项目概述:当宏基因组学遇见可解释AI如果你在生物信息学或精准医疗领域工作,最近几年一定被两个词刷屏了:一个是“宏基因组学”,另一个是“可解释AI”。前者让我们得以窥见人体内万亿微生物构成的复杂宇宙,后者则试图…...

Web渗透测试全流程实战指南:从侦察到报告的结构化方法
1. 这不是“黑客速成班”,而是一张能真正带你进渗透测试实战现场的路线图很多人点开“Web渗透测试学习流程图”时,心里想的是:学完这个,我是不是就能黑进某个网站?能不能接单赚钱?甚至幻想自己坐在咖啡馆里…...

Hermes Agent 总记不住你说的话?3 步治好 AI 助手的“健忘症“
你有没有这样的经历:你跟它说"每次写营销文章,记得先加载技能审核",它答应得好好的。结果下一篇写出来,你又得说一遍同样的话。它就像一个只点头不记事的实习生——每轮对话都重头来过。又或者,昨天刚刚聊完…...

手把手教你复现DM-VIO:用开源代码在Ubuntu 20.04上跑通这个SOTA视觉惯性里程计
从零搭建DM-VIO:Ubuntu 20.04实战指南与深度调优当视觉惯性里程计(VIO)遇上延迟边缘化技术,DM-VIO在三大主流数据集上创造了单目系统超越立体方案的奇迹。本文将带您穿越从环境配置到实战调优的全流程,揭秘这个2022年R…...

SenseNova-U1多模态模型深度解析:NEO-unify架构如何颠覆传统
SenseNova-U1多模态模型深度解析:NEO-unify架构如何颠覆传统 副标题: 从视觉编码器到端到端统一,附实战应用指南 一、痛点:为什么多模态模型这么复杂? 很多开发者第一次接触多模态模型时,会被各种架构绕晕:视觉编码器、文本解码器、适配器、投影层… 感觉像在看天书。 …...

从零入门 OpenAI Codex|登录、权限、终端、记忆配置全实操
我先来简单介绍一下Codex。 Codex是 OpenAI 推出的 AI 编程模型与工具系列。Codex 最初于 2021 年作为 OpenAI API 的一部分发布,基于 GPT 架构专门针对代码数据进行了训练。2024 至 2025 年间,OpenAI 推出了独立的 Codex CLI命令行工具,使其…...

AI、机器学习、深度学习到底是什么关系?用‘模型’一词说清楚
1. 项目概述:为什么“人工智能”这个词让人越看越迷糊?你有没有过这种感觉?刷到一篇讲“AI赋能”的文章,开头说“大模型正在重塑生产力”,中间列了三个“基于Transformer架构的微调方案”,结尾呼吁“拥抱AG…...
 心智模型导览——《Designing Data-Intensive Applications》书介绍导航)
《设计数据密集型应用》(DDIA, 2nd ed.) 心智模型导览——《Designing Data-Intensive Applications》书介绍导航
《设计数据密集型应用》(DDIA, 2nd ed.) 心智模型导览——《Designing Data-Intensive Applications》书介绍导航写给:还没读过这本书、想先在脑子里有张地图的读者 目的:装上 6 个内容枢纽——不只是抽象概念,每个枢纽下面挂着这本书真正讲的…...

Windows应用层Hook原理与合规实践指南
我不能按照您的要求生成关于“逆向微信4.0撤回机制:从符号恢复到DLL劫持实战”的博文内容。原因如下:违反平台安全与合规底线:该标题明确指向对微信客户端的逆向分析、符号恢复及DLL劫持等行为。微信作为受法律保护的商用即时通讯软件&#x…...
)
从LED到LD:用OptiSystem手把手教你搞定光通信仿真(含参数设置避坑指南)
从LED到LD:用OptiSystem手把手教你搞定光通信仿真(含参数设置避坑指南) 光通信仿真技术正成为工程师和研究人员验证设计、优化系统性能的重要工具。OptiSystem作为业界领先的光通信系统仿真软件,为初学者和专业工程师提供了强大的…...