第十四 Elasticsearch介绍和安装
docker-compose安装
kibana:
image: docker.elastic.co/kibana/kibana:7.5.1
container_name: kibana
ports:
- "5601:5601"
environment:
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
depends_on:
- elasticsearch
elasticsearch:
# 使用elasticsearch:7.5.1镜像
image: elasticsearch:7.5.1
container_name: elasticsearch
# 设置环境变量:集群名称为elasticsearch,以确保节点互相发现
environment:
cluster.name: elasticsearch
# 使用单节点发现模式
discovery.type: single-node
ES_JAVA_OPTS: "-Xms64m -Xmx251m"
# 将9200端口映射到主机端口
ports:
- "9200:9200"
- "9300:9300"
# 挂载elasticsearch数据目录
volumes:
- /docker/elasticsearch/data:/usr/share/elasticsearch/data
ik分词器
docker exec -it elasticsearch bash/usr/share/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.5.1/elasticsearch-analysis-ik-7.5.1.zip重启1.Elasticsearch介绍和安装
用户访问我们的首页,一般都会直接搜索来寻找自己想要购买的商品。
而商品的数量非常多,而且分类繁杂。如果能正确的显示出用户想要的商品,并进行合理的过滤,尽快促成交易,是搜索系统要研究的核心。
面对这样复杂的搜索业务和数据量,使用传统数据库搜索就显得力不从心,一般我们都会使用全文检索技术,比如之前大家学习过的Solr。
不过今天,我们要讲的是另一个全文检索技术:Elasticsearch。
1.1.简介
1.1.1.Elastic
Elastic官网:欢迎来到 Elastic — Elasticsearch 和 Kibana 的开发者 | Elastic
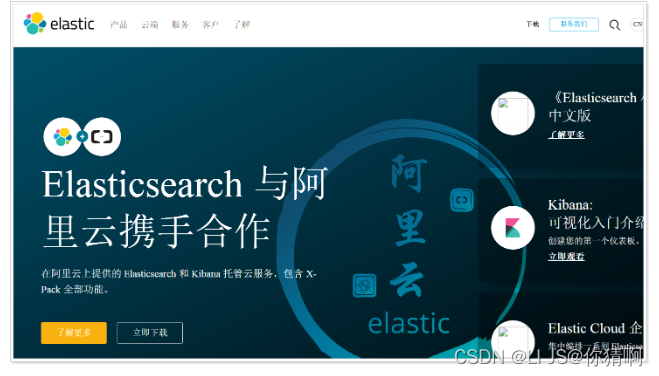
Elastic有一条完整的产品线及解决方案:Elasticsearch、Kibana、Logstash等,前面说的三个就是大家常说的ELK技术栈。
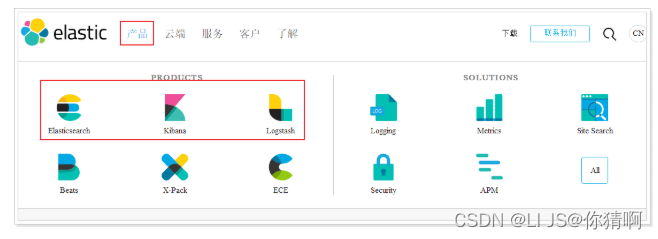
1.1.2.Elasticsearch
Elasticsearch官网:Elasticsearch:官方分布式搜索和分析引擎 | Elastic

如上所述,Elasticsearch具备以下特点:
-
分布式,无需人工搭建集群(solr就需要人为配置,使用Zookeeper作为注册中心)
-
Restful风格,一切API都遵循Rest原则,容易上手
-
近实时搜索,数据更新在Elasticsearch中几乎是完全同步的。
1.1.3.版本
目前Elasticsearch最新的版本是6.3.1,我们就使用6.3.0
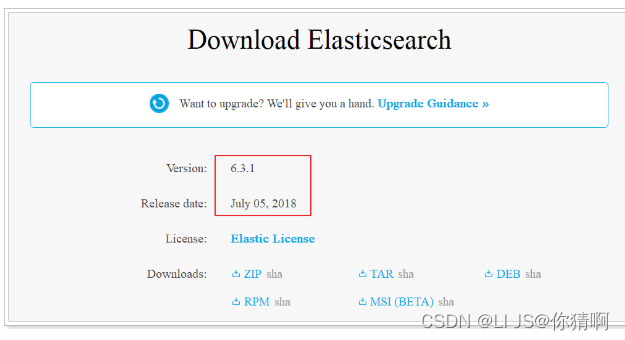
需要虚拟机JDK1.8及以上
1.2.安装和配置
为了模拟真实场景,我们将在linux下安装Elasticsearch。
1.2.1.上传安装包,并解压
我们将安装包上传到:/home/leyou目录

解压缩:
tar -zxvf elasticsearch-6.2.4.tar.gz
我们把目录重命名:
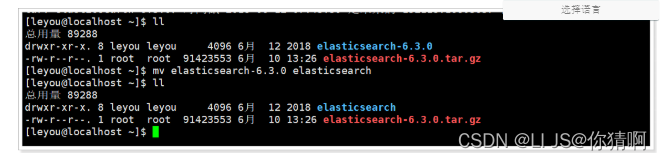
进入,查看目录结构:
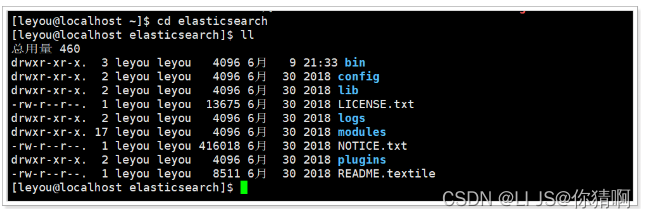
1.2.2.新建一个用户leyou
出于安全考虑,elasticsearch默认不允许以root账号运行。
创建用户:
user add leyou
设置密码:
passwd leyou
切换用户:
su - leyou
给leyou用户可以修改的权限
chown leyou:leyou elasticsearch-6.2.4 -R
拥有--leyou用户:leyou这个组-- elasticsearch-6.2.4这个文件---R表示修改里面所有的内容
1.2.3.修改配置
我们进入config目录:cd config
需要修改的配置文件有两个:
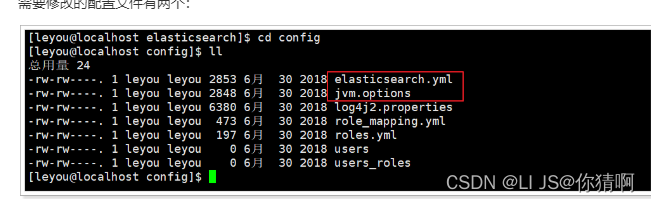
-
jvm.options
Elasticsearch基于Lucene的,而Lucene底层是java实现,因此我们需要配置jvm参数。
编辑jvm.options:
vim jvm.options
默认配置如下:
-Xms1g -Xmx1g
内存占用太多了,我们调小一些:
-Xms512m -Xmx512m一个是最大内存,一个是最小可用,一般是设置一样的,没有最小内存,不用空闲还要去做垃圾回收(垃圾回收会导致程序暂定),
1.避免频繁的¥¥回收: 如果最小可用内存比最大内存要小很多,则 JVM 在运行过程中可能会不断地进行¥¥回收,这会消耗大量的 CPU 时间和系统资源,并且可能会导致应用程序响应变慢。尽管 JVM 可以自动增加堆内存的大小,但它并不能保证在出现内存不足时会在正确的时间点增加内存。
2.提高应用程序的性能:应用程序通常需要处理各种各样的事务,并且使用的内存大小也会随时间变化。将最小内存和最大内存设置为相同的值可以确保 JVM 开始执行时具有足够的内存,从而提高应用程序的性能。
-
elasticsearch.yml
vim elasticsearch.yml
-
修改数据和日志目录:
path.data: /home/leyou/elasticsearch/data # 数据目录位置 path.logs: /home/leyou/elasticsearch/logs # 日志目录位置
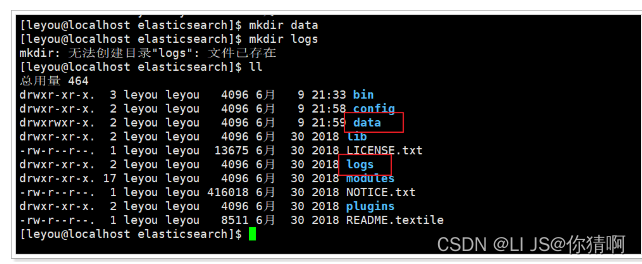
我们把data和logs目录修改指向了elasticsearch的安装目录。但是这两个目录并不存在,因此我们需要创建出来。
进入elasticsearch的根目录,然后创建:
mkdir data mkdir logs
-
修改绑定的ip:
network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何ip来访问0.0.0.0表示任何主机都可以访问
默认只允许本机访问,修改为0.0.0.0后则可以远程访问
目前我们是做的单机安装,如果要做集群,只需要在这个配置文件中添加其它节点信息即可。
elasticsearch.yml的其它可配置信息:
| 属性名 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
1.3.运行
进入elasticsearch/bin目录,可以看到下面的执行文件:
然后输入命令:
./elasticsearch
发现报错了,启动失败:
1.3.1.错误1:内核过低

我们使用的是centos6,其linux内核版本为2.6。而Elasticsearch的插件要求至少3.5以上版本。不过没关系,我们禁用这个插件即可。
修改elasticsearch.yml文件,在最下面添加如下配置:
bootstrap.system_call_filter: false
然后重启
1.3.2.错误2:文件权限不足
再次启动,又出错了:
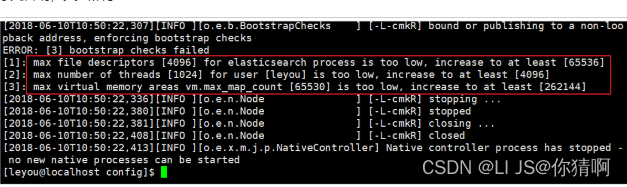
[1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
我们用的是leyou用户,而不是root,所以文件权限不足。
首先用root用户登录。
然后修改配置文件:
vim /etc/security/limits.conf
添加下面的内容:
* soft nofile 65536 * hard nofile 131072 * soft nproc 4096 * hard nproc 4096
1.3.3.错误3:线程数不够
刚才报错中,还有一行:
[1]: max number of threads [1024] for user [leyou] is too low, increase to at least [4096]
这是线程数不够。
继续修改配置:
vim /etc/security/limits.d/90-nproc.conf
修改下面的内容:
* soft nproc 1024
改为:
* soft nproc 4096
1.3.4.错误4:进程虚拟内存
[3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
vm.max_map_count:限制一个进程可以拥有的VMA(虚拟内存区域)的数量,继续修改配置文件, :
vim /etc/sysctl.conf
添加下面内容:
vm.max_map_count=655360
然后执行命令:
sysctl -p
1.3.5.重启终端窗口
所有错误修改完毕,一定要重启你的 Xshell终端,否则配置无效。
exit后再重新连接
1.3.6.启动
再次启动,终于成功了!
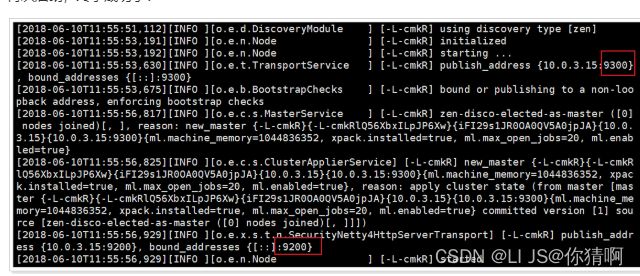
可以看到绑定了两个端口:
-
9300:集群节点间通讯接口
-
9200:客户端访问接口
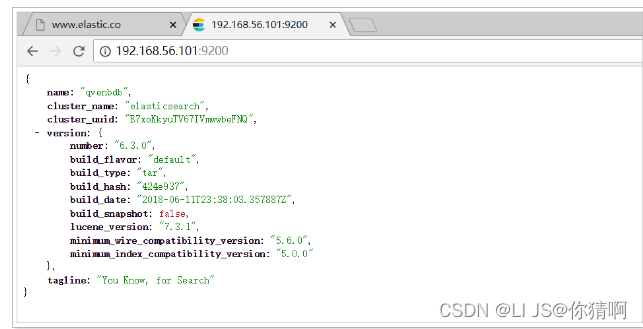
我们在浏览器中访问:http://192.168.56.101:9200
1.4.安装kibana
1.4.1.什么是Kibana?
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。
而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法。
1.4.2.安装
因为Kibana依赖于node,我们的虚拟机没有安装node,而window中安装过。所以我们选择在window下使用kibana。
最新版本与elasticsearch保持一致,也是6.3.0(版本一致)
解压到特定目录即可
1.4.3.配置运行
配置
进入安装目录下的config目录,修改kibana.yml文件:
修改elasticsearch服务器的地址:
elasticsearch.url: "http://192.168.56.101:9200"
而如果设置store为true,就会在_source以外额外存储一份数据,多余,因此一般我们都会将store设置为false,事实上,store的默认值就是false。
运行
进入安装目录下的bin目录:
双击运行:
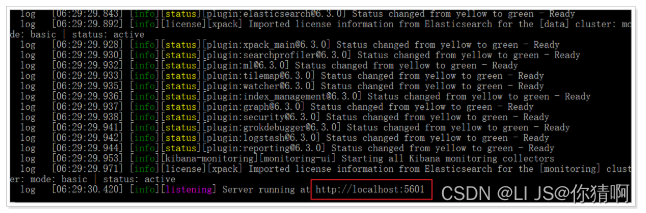
发现kibana的监听端口是5601
我们访问:http://127.0.0.1:5601
1.4.4.控制台
选择左侧的DevTools菜单,即可进入控制台页面:
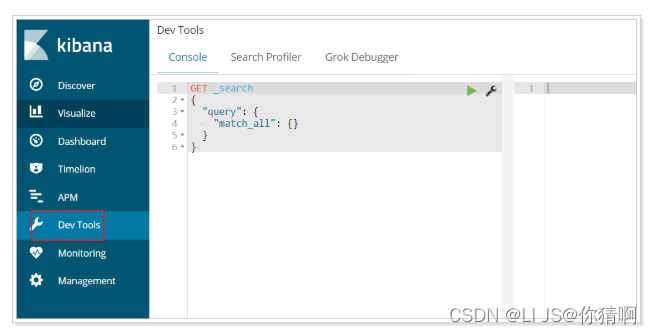
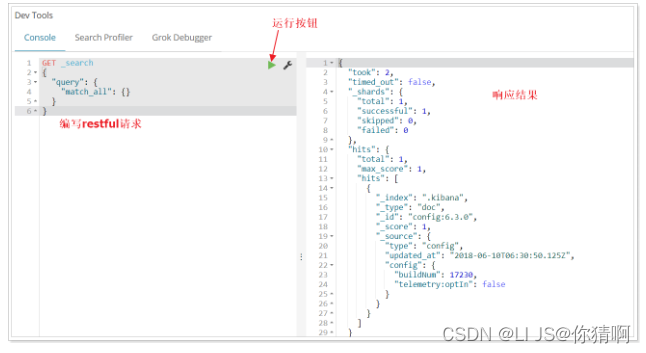
在页面右侧,我们就可以输入请求,访问Elasticsearch了。
1.5.安装ik分词器
Lucene的IK分词器早在2012年已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且开发为ElasticSearch的集成插件了,与Elasticsearch一起维护升级,版本也保持一致,最新版本:6.3.0
1.5.1.安装
上传课前资料中的zip包,解压到Elasticsearch目录的plugins目录中:
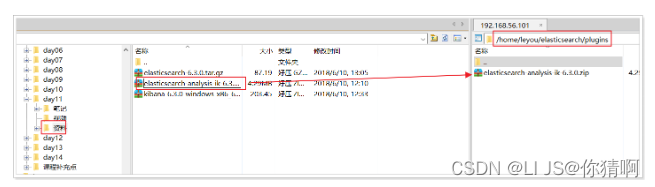
使用unzip命令解压:
unzip elasticsearch-analysis-ik-6.3.0.zip -d ik-analyzer
然后重启elasticsearch:
1.5.2.测试
大家先不管语法,我们先测试一波。
在kibana控制台输入下面的请求:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
运行得到结果:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国人",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}
1.7.API
Elasticsearch提供了Rest风格的API,即http请求接口,而且也提供了各种语言的客户端API
1.7.1.Rest风格API(就是http请求可以访问,用postman也可以测试)
文档地址:Elasticsearch Guide [8.7] | Elastic
1.7.2.客户端API
Elasticsearch支持的客户端非常多:Elasticsearch Clients | Elastic

点击Java Rest Client后,你会发现又有两个:
Low Level Rest Client是低级别封装,提供一些基础功能,但更灵活
High Level Rest Client,是在Low Level Rest Client基础上进行的高级别封装,功能更丰富和完善,而且API会变的简单

1.7.3.如何学习
建议先学习Rest风格API,了解发起请求的底层实现,请求体格式等。
2.操作索引
2.1.基本概念
Elasticsearch也是基于Lucene的全文检索库,本质也是存储数据,很多概念与MySQL类似的。
对比关系:
索引(indices)--------------------------------Databases 数据库
类型(type)-----------------------------Table 数据表
文档(Document)----------------Row 行
字段(Field)-------------------Columns 列
详细说明:
| 概念 | 说明 |
|---|---|
| 索引库(indices) | indices是index的复数,代表许多的索引, |
| 类型(type) | 类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念 |
| 文档(document) | 存入索引库原始的数据。比如每一条商品信息,就是一个文档 |
| 字段(field) | 文档中的属性 |
| 映射配置(mappings) | 字段的数据类型、属性、是否索引、是否存储等特性 |
是不是与Lucene和solr中的概念类似。
另外,在SolrCloud中,有一些集群相关的概念,在Elasticsearch也有类似的:
-
索引集(Indices,index的复数):逻辑上的完整索引
-
分片(shard):数据拆分后的各个部分
-
副本(replica):每个分片的复制
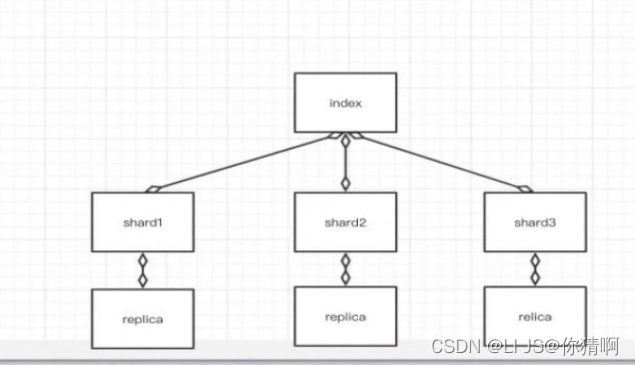
要注意的是:Elasticsearch本身就是分布式的,因此即便你只有一个节点,Elasticsearch默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。
2.2.创建索引
2.2.1.语法
Elasticsearch采用Rest风格API,因此其API就是一次http请求,你可以用任何工具发起http请求
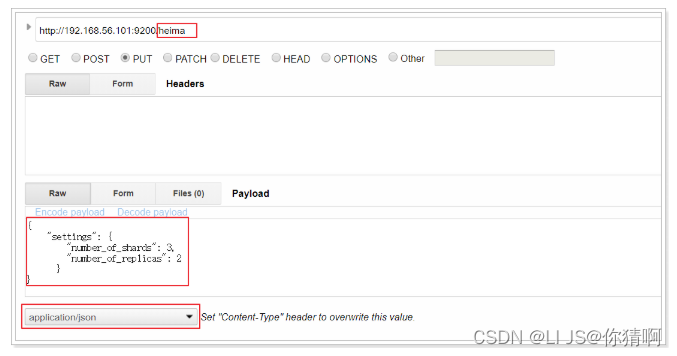
创建索引的请求格式:
-
请求方式:PUT
-
请求路径:/索引库名
-
请求参数:json格式:
{ "settings": { "number_of_shards": 3, "number_of_replicas": 2 } }-
settings:索引库的设置
-
number_of_shards:分片数量
-
number_of_replicas:副本数量
-
-
2.2.2.测试
我们先用RestClient来试试
响应:
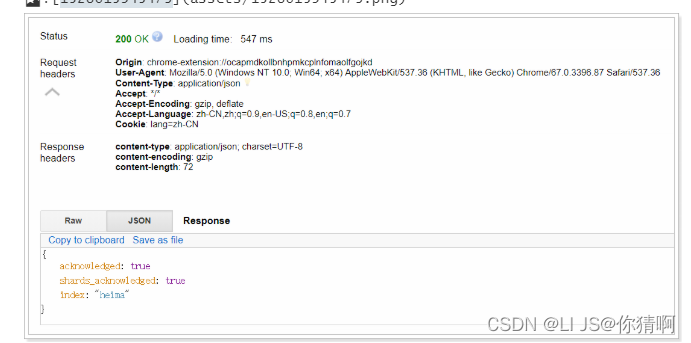
可以看到索引创建成功了。
2.2.3.使用kibana创建
kibana的控制台,可以对http请求进行简化,示例:
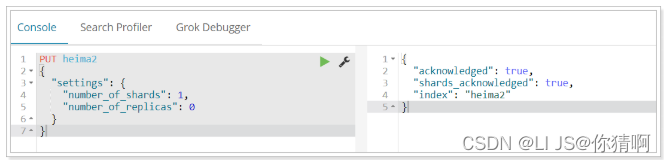
相当于是省去了elasticsearch的服务器地址
而且还有语法提示,非常舒服。
2.3.查看索引设置
语法
Get请求可以帮我们查看索引信息,格式:
GET /索引库名
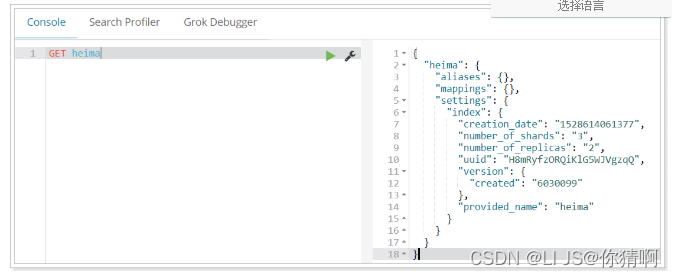
或者,我们可以使用*来查询所有索引库配置:
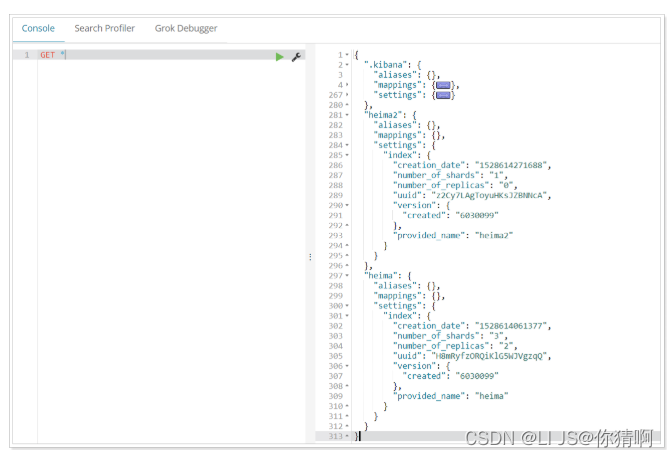
2.4.删除索引
删除索引使用DELETE请求
语法
DELETE /索引库名
示例
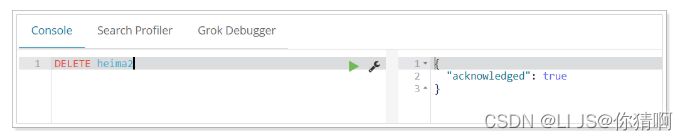
再次查看heima2:
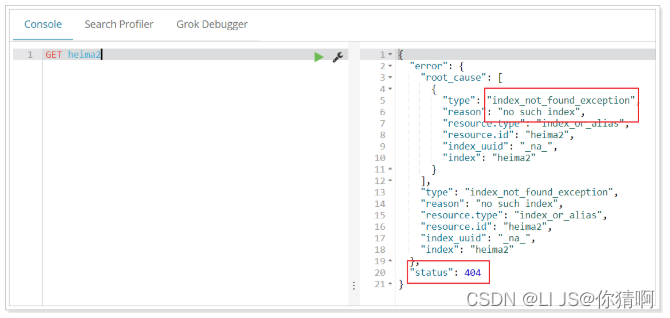
当然,我们也可以用HEAD请求,查看索引是否存在:

2.5.映射配置
索引有了,接下来肯定是添加数据。但是,在添加数据之前必须定义映射。
什么是映射?
映射是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等
只有配置清楚,Elasticsearch才会帮我们进行索引库的创建(不一定)
相关文章:
第十四 Elasticsearch介绍和安装
docker-compose安装 kibana: image: docker.elastic.co/kibana/kibana:7.5.1 container_name: kibana ports: - "5601:5601" environment: ELASTICSEARCH_HOSTS: http://elasticsearch:9200 depends_on: - elasticsearch…...
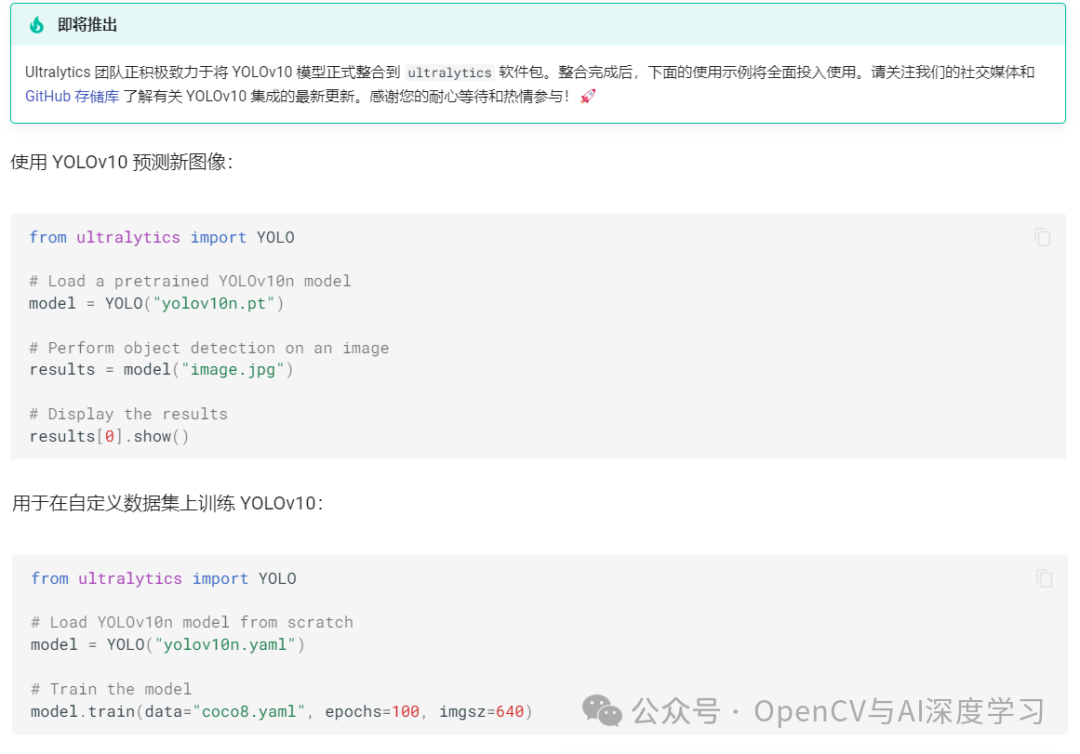
YOLOv10介绍与推理--图片和视频演示(附源码)
导 读 本文主要对YOLOv10做简单介绍并给出推理图片和视频的步骤演示。 YOLOv10简介 YOLOv10是清华大学的研究人员在Ultralytics Python包的基础上,引入了一种新的实时目标检测方法,解决了YOLO 以前版本在后处理和模型架构方面的不足。通过消除非最大抑…...

Java实验08
实验一 demo.java package q8.demo02;public class demo{public static void main(String[] args) {WindowMenu win new WindowMenu("Hello World",20,30,600,290);} }WindowMenu.java package q8.demo02; import javax.swing.*;public class WindowMenu extends…...
MyBatis复习笔记
3.Mybatis复习 3.1 xml配置 properties:加载配置文件 settings:设置驼峰映射 <settings><setting name"mapUnderscoreToCamelCase" value"true"/> </settings>typeAliases:类型别名设置 #这样在映射…...

HTML的基石:区块标签与小语义标签的深度解析
📚 HTML的基石:区块标签与小语义标签的深度解析 🌐 区块标签:构建网页的框架🏠 <div>:万能的容器📚 <section>、<article>、<aside>:语义化的布局 …...

Windows域控简介
一、Windows 域控概念 Windows 域控即 Active Directory(AD)域控制器,它是 Windows Server 中的一个角色,用于管理网络中的用户帐户、计算机和其他设备。AD 域控制器的功能包括: 用户认证:允许用户通过用…...

项目延期,不要随意加派人手
遇到软件项目出现延期的情况时,不建议随意加派人手。原因如下: 有些任务是不可拆分的,不能拆分为多个并行任务,增加人员不会加快项目进度。新增加人员需要原有人员介绍项目中的技术架构、业务知识,在开发过程中也难免…...
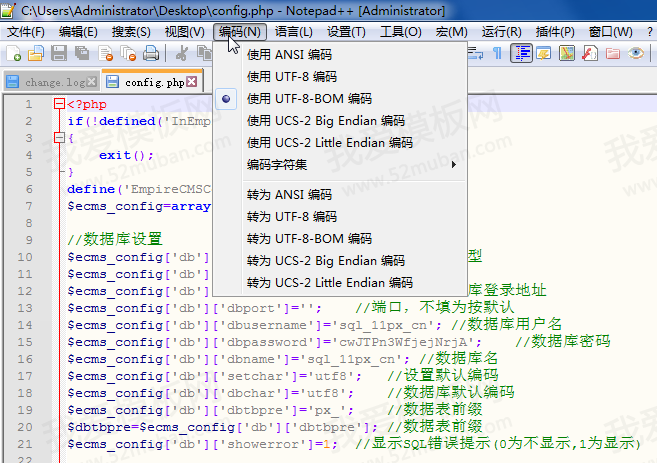
帝国CMS验证码不显示怎么回事呢?
帝国CMS验证码有时候会不显示或打叉,总结自己的解决方法。 1、检查服务器是否开启GD库 测试GD库是否开启的方法:浏览器访问:/e/showkey/index.php,如果出现一堆乱码或报错,证明GD库没有开启,开启即可。 2…...

【必会面试题】Redis 中的 zset数据结构
目录 Redis 中的 zset(sorted set,有序集合)数据结构在底层可以使用两种不同的实现:压缩列表(ziplist) 和 跳跃表(skiplist)。具体使用哪种结构取决于存储元素的数量和大小ÿ…...

括号匹配数据结构
括号匹配是一种数据结构问题,用于检查给定的字符串中的括号是否匹配。例如,对于字符串 "((())())",括号是匹配的,而对于字符串 "())(",括号是不匹配的。 常见的解决括号匹配问题的数据结构是栈。…...

c语言:strcmp
strcmp函数是用于比较两个字符串的库函数,其功能是根据ASCII值逐一对两个字符串进行比较。 语法:strcmp(str1, str2) 返回值: 如果str1等于str2,则返回0。 如果str1小于str2,则返回负数(具体值取决于C…...

传统关系型数据库与hive的区别
数据库和Hive之间存在本质的区别,主要体现在设计目的、数据处理方式、数据存储、查询延迟、数据更新能力、以及适用场景等方面。下面详细阐述它们之间的主要差异: 设计目的与应用场景: 数据库:主要是面向事务处理(OLTP…...
windows-386、windows-amd64、windows-arm64这三者有什么区别?
选择文件的版本出现下面问题: Architectures windows-386 :这些是针对 32 位 Windows 系统编译的。windows-amd64 :这些是针对具有 AMD 或 Intel x86-64 架构的 64 位 Windows 系统编译的。windows-arm64 :这些是针对具有 ARM 架…...
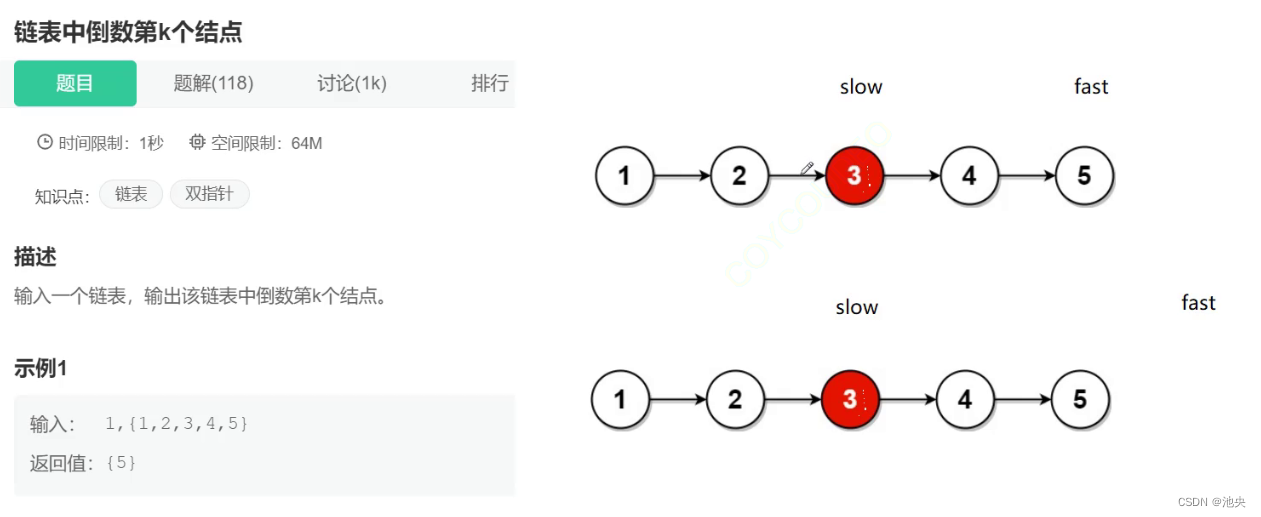
链表经典题目—相交链表和链表倒数第k个节点
🎉🎉🎉欢迎莅临我的博客空间,我是池央,一个对C和数据结构怀有无限热忱的探索者。🙌 🌸🌸🌸这里是我分享C/C编程、数据结构应用的乐园✨ 🎈🎈&…...

Java 写入 influxdb
利用Python随机生成一个1000行的csv文件 import csv import random from datetime import datetime, timedelta from random import randint, choice# 定义监控对象列表和指标名称列表 monitor_objects [Server1, Server2, Server3, DB1] metric_names [CPUUsage, MemoryUsa…...

npm的基本命令和用法
1. 安装与初始化 安装npm 首先,确保你的系统中已安装了Node.js,因为npm随Node.js一同分发。访问Node.js官网下载并安装适合你操作系统的版本。安装完成后,在终端或命令提示符中输入以下命令来验证安装: 1$ node -v 2$ npm -v …...

Python 基于深度图、RGB图生成RGBD点云数据
RGBD点云生成 一、概述1.1 定义1.2 函数讲解二、代码示例三、结果示例一、概述 1.1 定义 RGBD点云:是一种包含颜色和深度信息的点云数据。RGB代表红、绿、蓝三原色,表示点云中每个点的颜色信息;D代表深度,表示点云中每个点的相对于相机的距离信息。通过结合颜色和深度信息…...
力扣刷题--LCR 075. 数组的相对排序【简单】
题目描述 给定两个数组,arr1 和 arr2, arr2 中的元素各不相同 arr2 中的每个元素都出现在 arr1 中 对 arr1 中的元素进行排序,使 arr1 中项的相对顺序和 arr2 中的相对顺序相同。未在 arr2 中出现过的元素需要按照升序放在 arr1 的末尾。 …...

机器学习笔记——K近邻算法、手写数字识别
KNN算法 “物以类聚,人以群分”相似的数据往往拥有相同的类别 其大概原理就是一个样本归到哪一类,当前样本需要归到频次最高的哪个类去 也就是说有一个待分类的样本,然后跟他周围的k个样本来看,k中哪一个类最多,待分类…...
基于STM32实现智能园艺系统
目录 引言环境准备智能园艺系统基础代码示例:实现智能园艺系统 土壤湿度传感器数据读取水泵控制温湿度传感器数据读取显示系统用户输入和设置应用场景:智能农业与家庭园艺问题解决方案与优化收尾与总结 1. 引言 本教程将详细介绍如何在STM32嵌入式系统…...

独立开发者如何借助Taotoken低成本试验多种大模型效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken低成本试验多种大模型效果 对于独立开发者或小微团队而言,在创意验证或产品原型阶段&#…...

从零打造高效社区:BBS-Go现代化开源论坛完整解决方案
从零打造高效社区:BBS-Go现代化开源论坛完整解决方案 【免费下载链接】bbs-go A lightweight community and Q&A platform for forums, knowledge bases, and discussions. 项目地址: https://gitcode.com/gh_mirrors/bb/bbs-go 你是否曾为团队内部沟通不…...

高性能混合数据聚类算法:k-prototypes架构设计与性能优化深度解析
高性能混合数据聚类算法:k-prototypes架构设计与性能优化深度解析 【免费下载链接】kmodes Python implementations of the k-modes and k-prototypes clustering algorithms, for clustering categorical data 项目地址: https://gitcode.com/gh_mirrors/km/kmod…...

大学生如何学习AI智能体?从零基础到OPC一人公司
掌握AI智能体能力,是大学生未来就业和创业的核心竞争力。 在AI智能体时代,普通人若能借助模型、智能体和自动化工具完成从任务交付到产品落地的闭环,将成为稀缺人才。智能体来了旗下的OPC中国,为大学生提供了完整的学习、实训和就…...

Illustrator智能填充脚本Fillinger:如何3步完成复杂图案设计
Illustrator智能填充脚本Fillinger:如何3步完成复杂图案设计 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在Adobe Illustrator中,你是否曾为填充复杂形状…...

混合强化学习驱动的智能营销决策框架
1. 项目概述:当营销决策遇上“会思考的机器人” 你有没有遇到过这样的场景:市场部刚上线一套新用户分群模型,A/B测试跑了一周,结果发现高价值用户转化率不升反降;或者运营团队精心设计的优惠券发放策略,在季…...

技术解密:Godot RE Tools - 游戏逆向工程的智能解决方案
技术解密:Godot RE Tools - 游戏逆向工程的智能解决方案 【免费下载链接】gdsdecomp Godot reverse engineering tools 项目地址: https://gitcode.com/GitHub_Trending/gd/gdsdecomp Godot RE Tools 是一款专业的Godot游戏逆向工程工具,能够从AP…...

如何快速掌握专业字体设计:开源Bebas Neue字体完全指南
如何快速掌握专业字体设计:开源Bebas Neue字体完全指南 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue 你是否曾经在设计项目中被字体选择困扰?面对那些要么过于普通缺乏个性,…...

5分钟掌握跨平台音乐格式转换:Unlock-Music浏览器端音频解密终极指南
5分钟掌握跨平台音乐格式转换:Unlock-Music浏览器端音频解密终极指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项…...

CTF 竞赛干货|50 个实战解题思路,收藏一篇就够用
CTF选手必藏的50个实战解题思路!一篇够用! CTF竞赛的核心逻辑 • 核心目标:快速拆解问题(Flag导向)、工具链协作、模式化思维。• 关键原则:先广度后深度(优先收集信息)、分治策略&…...