AAAI2024 基于扩散模型 多类别 工业异常检测 DiAD
前言
本文分享一个基于扩散模型的多类别异常检测框架,用于检测工业场景的缺陷检测或异常检测。
- 设计SG语义引导网络,在重建过程中有效保持输入图像的语义信息,解决了LDM在多类别异常检测中的语义信息丢失问题。
- 高效重建,通过在潜在空间中进行扩散和去噪操作,增强了模型在处理复杂结构和大规模缺陷时的重建能力。
同时分析基础扩散模型DDPM和LDM,对比设计原理和效果。
论文地址:DiAD: A Diffusion-based Framework for Multi-class Anomaly Detection
代码地址:https://github.com/lewandofskee/DiAD
一、基于扩散模型的物体重建与异常检测
如下图所示,是三个扩散模型的模型结构,以及物体重建和修复的效果对比。
- DDPM(Denoising Diffusion Probabilistic Model),去噪网络由编码器(E)和解码器(D)组成。
- LDM(Latent Diffusion Model)去噪网络在编码器和解码器之间,引入了潜在变量进行引导。
- DiAD在编码器和解码器之间,引入了语义引导网络(SG网络)和空间感知特征融合(SFF)模块。
- DDPM和LDM在多类别异常检测中存在问题,类别错误和语义错误。

二、基础扩散模型
1)去噪扩散概率模型(DDPM)
DDPM全称是Denoising Diffusion Probabilistic Model,由两个过程组成:前向扩散过程和反向去噪过程。
前向扩散过程:
- 在前向过程中,噪声样本𝑥𝑡通过马尔科夫链,逐步向初始数据样本𝑥0 ,添加高斯分布的噪声。
- 公式表示:
![]()
反向去噪过程:
- 首先从前向扩散中,采集得到真实噪声标签𝑥𝑇
- 然后根据模型预测ϵθ(xt,t),逐步从𝑥𝑇反向重建 𝑥𝑡−1。
- 公式如下所示:

- 其中𝑧∼𝑁(0,𝐼), 𝜎𝑡是与方差调度相关的固定常数。
- DDPM使用U-Net网络来预测分布。
2)潜在扩散模型(LDM)
LDM全称为Latent Diffusion Model,关注低维潜在空间的条件生成机制。
- 图像通过编码器压缩,扩散和去噪操作在潜在表示空间中进行,
- 随后通过解码器,重建到原始像素空间。
关键模块:
- 预训练自编码器:用于压缩图像,提取特征,得到的特征图送进后续去噪U-Net网络。
- 去噪U-Net:具有注意力机制的网络,在潜在表示空间进行扩散和去噪操作,然后通过解码器重建图像。
流程思路:

LDM的训练优化目标为:
![]()
- 其中, c表示条件机制(如文本或图像),通过交叉注意力机制连接到模型
- 𝑧𝑡表示潜在空间变量。
3)DDPM和LDM总结
DDPM:
- 通过前向扩散过程将噪声逐步添加到图像,反向去噪过程通过马尔科夫链逐步重建图像。
- 使用U-Net网络预测噪声,优化模型参数以最小化预测误差。
LDM:
- 通过预训练自编码器将图像压缩到潜在空间,在潜在空间中进行扩散和去噪操作,然后通过解码器重建图像。
- 使用条件机制(如文本或图像)作为输入,通过交叉注意力机制增强模型的生成能力。
改进点:
- DiAD框架通过引入语义引导网络和空间感知特征融合模块,
- 解决了现有扩散模型在多类别异常检测中的不足,提高了模型在复杂纹理和大规模缺陷重建中的性能。
三、背景
视觉异常检测的目标是:确定异常图像,并准确定位异常区域。
现有模型的局限性:
- 现有的异常检测模型大多对应单一类别,这需要大量的存储空间和训练时间,且随着类别数量的增加,这一需求会更大。
- 迫切需要一种鲁棒且稳定的无监督多类别异常检测模型。
异常检测主流方法分类:
- 合成类(synthesizing-based):通过合成正常样本来学习分布,然后在测试阶段重建异常区域。
- 嵌入类(embedding-based):通过embedding技术学习正常样本的特征分布,用于检测异常。
- 重建类(reconstruction-based):在训练阶段,模型只学习正常图像。在测试阶段,模型重建异常图像为正常图像,通过对比重建图像与输入图像,可以确定异常的位置。
传统重建类方法:
- 包括自编码器(AEs)、变分自编码器(VAEs)和生成对抗网络(GANs),这些方法可以学习正常样本的分布并在测试阶段重建异常区域。
- 这些模型的重建能力有限,无法很好地重建复杂的纹理和物体,尤其是大规模缺陷或消失的情况。
扩散模型:
- 扩散模型(如DDPM和LDM)展示了其强大的图像生成能力。
- 存在的局限性:当前的扩散模型无法有效解决,多类别异常检测问题。
DDPM的局限性:
- 问题:在多类别设置下,可能会出现生成图像类别错误的问题。
- 原因:在输入图像中添加T步噪声后,图像丧失了原始类别信息。在推理过程中,去噪基于高斯噪声分布进行,这可能生成属于不同类别的样本。
LDM的局限性:
- 问题:虽然LDM作为类条件嵌入特征,不存在DDPM中的类别误分类问题,但在生成图像中仍存在语义信息丢失的问题。
- 原因:LDM无法同时保留输入图像的语义信息和重建异常区域,可能导致生成的图像与输入图像在方向一致性和细节上存在显著差异。
四、模型框架
DiAD的模型框架,如下图所示:

SG语义引导网络
- 包括一系列编码块SGEB,和解码块SGDB,以及一个空间感知特征融合SFF模块。
- 输入:包括两部分,图像𝑥0、潜在变量𝑧𝑇经过扩散前向过程后的特征。
- 扩散过程:SG网络在不同尺度下处理噪声,并通过SFF模块融合特征,确保重建过程中保留语义信息。
SD去噪网络
- 输入具有噪声的潜在变量𝑧𝑇、和SG网络输出语义特性信息。
- 在潜在空间中进行扩散和去噪操作。
- 过去噪块(SDEB和SDDB)逐步去除噪声,最终重建潜在表示𝑧^。
异常检测模块(只在推理阶段运行)
- 预训练特征提取器 :处理输入图像𝑥0和重建图像 𝑥0^。
- 特征提取:从不同尺度提取特征图 𝑓1,𝑓2,𝑓3。
- 异常评分:通过计算重建图像和输入图像在不同尺度特征上的差异,生成异常评分图S。
五、创新点——SG语义引导网络
输入变换:
- 输入原始图像𝑥0被一组卷积-SiLU层,转换为具有与潜在表示𝑧相同维度的表示 𝑥。
- 然后,𝑥和 𝑧的和被输入到SG编码块中。
流程思路:
- 通过编码器的连续下采样,结果最终被添加到中间块的输出中。
- 中间块在完成中间处理后,其结果被添加到SD解码器的输出中。
- 为了应对不同场景和类别的多类别任务,SG解码块的结果也被添加到SD解码器的输出中,并结合SFF块共同处理。

SFF设计背景:
- 在多类别异常检测中,数据集包含各种类型的对象和纹理。
- 对于与纹理相关的情况,异常通常较小,因此需要保留原始纹理。
- 而在对象相关的情况下,缺陷往往覆盖较大区域,要求更强的重建能力。
- 因此,挑战在于如何同时保留原始样本的正常信息并重建大规模异常区域。
SFF的提出:
- 为了应对这些挑战,提出了空间感知特征融合块(SFF),其目标是将高尺度的语义信息 集成到低尺度中。
- 这样可以同时保留原始正常样本的信息并重建大规模异常区域。
结构如下图所示,每个SGEB块由三层子层组成。

- SFF块将SGEB3中每一层的特征融合到SGEB4中的每一层中,并将融合的特征添加到原始特征中。
- SFF块通过将高尺度的语义信息集成到低尺度中,实现了对原始正常样本信息的保留和大规模异常区域的重建。

六、核心内容——去噪网络
去噪网络组成:
- 预训练SD去噪网络:包括四个编码块、一个中间块和四个解码块。
- SG语义引导网络:复制SD网络参数以初始化,并在结构上与其类似。
工作原理:

去噪网络的输出被定义为:

特点:
- 语义一致性:通过引入SG网络,在重建过程中有效保持输入图像的语义信息,解决了LDM在多类别异常检测中的语义信息丢失问题。
- 多类别适应性:通过结合SFF块和SG解码块,应对不同场景和类别的多类别任务,提高了模型的灵活性和鲁棒性。
- 高效重建:通过在潜在空间中进行扩散和去噪操作,增强了模型在处理复杂结构和大规模缺陷时的重建能力。
七、核心内容——异常定位和检测
通过多尺度特征提取和余弦相似度计算,DiAD框架能够有效地进行异常定位和检测。
推理阶段:
- 在推理阶段,通过扩散和去噪过程在潜在空间中获得重建图像 𝑥^0。
- 为了进行异常定位和检测,使用相同的ImageNet预训练特征提取器,
- 来提取输入图像𝑥0和重建图像𝑥^0 的特征,并在不同尺度的特征图上计算异常图𝑀𝑛。



方法优点:
- 多尺度特征融合:通过在不同尺度上提取特征并计算异常图,模型能够更全面地检测和定位异常。
- 余弦相似度度量:使用余弦相似度作为度量标准,通过计算输入图像和重建图像特征向量之间的夹角,精确衡量它们的相似性。
- 权重融合:综合不同特征层的异常图,根据每层特征的重要性赋予不同的权重,最终计算出综合异常得分。
八、模型细节设计
数据处理
- 图像尺寸:所有MVTec-AD和VisA数据集的图像都调整为256 x 256的大小。
- 去噪网络:使用第4层SGDB(Semantic-Guided Decoder Block)与SDDB(Stable Diffusion Decoder Block)连接。
- 特征提取网络:采用ResNet50作为特征提取网络,选择第 𝑛层特征用于计算异常定位,其中 𝑛∈{2,3,4}。
模型训练
- 自编码器微调:在训练去噪网络之前,使用KL方法对自编码器进行微调。
- 训练细节:
- 训练1000个epoch。
- 使用单个NVIDIA Tesla V100 32GB GPU。
- 批量大小为12。
- 优化器:Adam,学习率设置为 1𝑒−5。
平滑和异常得分计算
- 平滑方法:使用高斯滤波器(标准差 𝜎=5)对异常定位得分进行平滑。
- 异常检测:图像的异常得分为经过8轮8 x 8大小全局平均池化操作后的最大值。
推理过程
- 去噪时间步:初始去噪时间步设置为1000。
- 采样策略:使用DDIM采样器,默认10步。
九、模型效果
数据集和评估指标
1. MVTec-AD 数据集
- 描述:MVTec-AD数据集模拟了真实世界的工业生产场景,填补了无监督异常检测领域的空白。数据集包含5种纹理和10种对象,共5,354张高分辨率图像。
- 训练集:包含3,629张无异常的样本图像。
- 测试集:包含1,725张图像,包括正常样本和异常样本。
- 标注:提供像素级标注用于异常定位评估。
2. VisA 数据集
- 描述:VisA数据集包含10,821张高分辨率图像,其中9,621张是正常图像,1,200张是包含78种类型异常的图像。
- 结构:数据集包括12个子集,每个子集对应一个独特的对象。12个对象可分类为三种不同的对象类型:复杂结构、多实例和单实例。
3. MVTec-3D 数据集
- 描述:MVTec-3D数据集包含使用高分辨率工业3D传感器获取的4,147张扫描图像,包含10个类别的RGB图像和3D点云。
- 训练集:包含2,656张无异常的样本图像。
- 测试集:包含1,197张图像,包括正常样本和异常样本。仅使用RGB图像进行实验。
4. Medical 数据集
- 描述:合并了BraTS2021、BTCV和LiTS三个医疗数据集,用于多类别异常检测。
- 训练集:包含9,042个切片。
- 测试集:包含5,208个切片。
评估指标
- AUROC(Area Under the Receiver Operating Characteristic Curve):用于评估图像级异常检测和像素级异常定位的指标。
- AP(Average Precision):用于评估检测结果的平均精度。
- F1max:用于评估检测和定位结果的最大F1得分。
- PRO(Per-Region Overlap):用于评估异常定位的指标。
- DICE:在医学领域常用的指标,用于评估检测结果的准确性。
MVTec-AD数据集上,与SOTA方法进行比较:
- 使用 AUROCcls/APcls/F1maxcls 指标进行多类异常检测。

MVTec-AD数据集测试,效果对比:

数据集测试:

使用AU ROC指标进 DiAD设计的消融研究:

VisA数据集测试,效果对比:

MVTec-AD数据集上异常定位的定性比较结果:

示例2:

示例3:

VisA 数据集异常定位的定性比较结果:


分享完成~
后续分析更多工业异常检测、缺陷检测的技术方案。
相关文章:
AAAI2024 基于扩散模型 多类别 工业异常检测 DiAD
前言 本文分享一个基于扩散模型的多类别异常检测框架,用于检测工业场景的缺陷检测或异常检测。 设计SG语义引导网络,在重建过程中有效保持输入图像的语义信息,解决了LDM在多类别异常检测中的语义信息丢失问题。高效重建,通过在潜…...
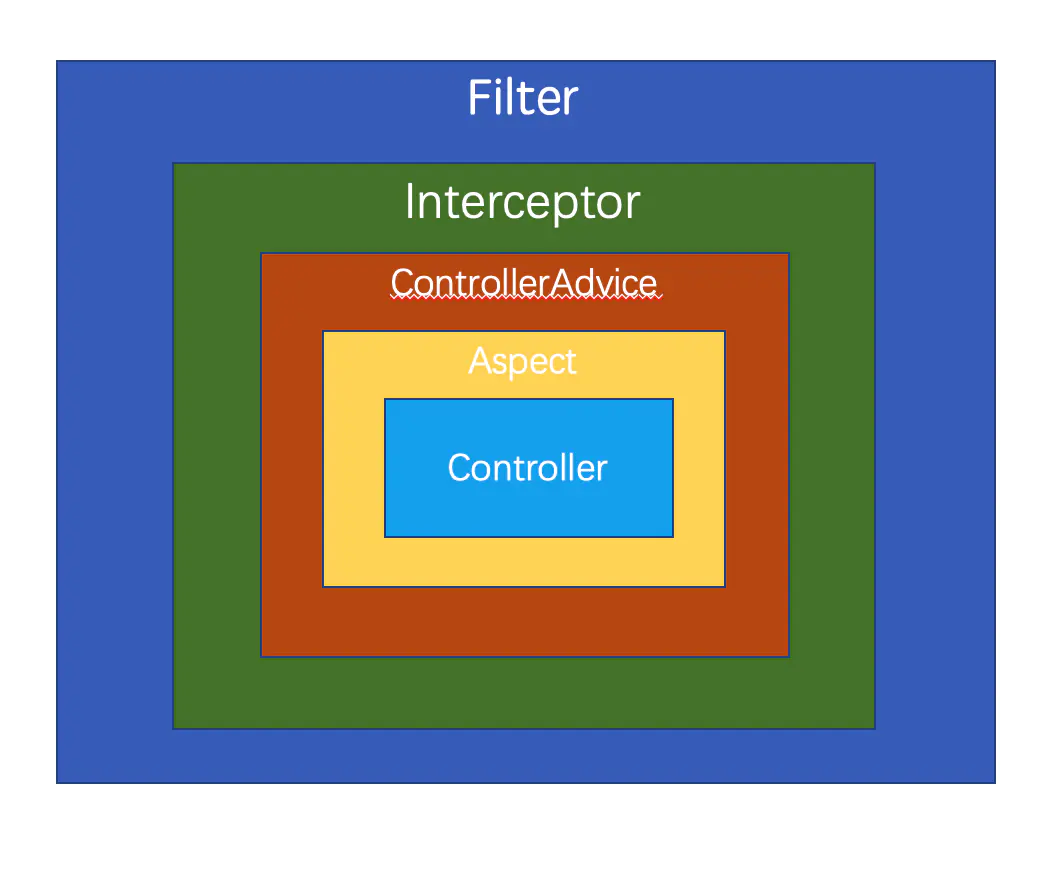
JavaEE-Spring Controller(服务器控制以及Controller的实现和配置)
Spring Controller 服务器控制 响应架构 Spring Boot 内集成了 Tomcat 服务器,也可以外接 Tomcat 服务器。通过控制层接收浏览器的 URL 请求进行操作并返回数据。 底层和浏览器的信息交互仍旧由 servlet 完成,服务器整体架构如下: Server&…...

页面导出PDF,非可视区域如何解决
const exportToPDF () > {const element document.getElementById(chart-container);if (!element) return;const originalScrollHeight element.scrollHeight;// 临时解除滚动条限制,确保所有内容都可见element.style.height ${originalScrollHeight}px;// …...

Android UI:ViewTree: 监听
文章目录 涉及设计模式 观察者模式+策略模式API源码分析总结涉及设计模式 观察者模式+策略模式 被观察者:ViewTree ViewTree持有一个观察器ViewTreeObserver 系统在ViewRootImpl和View的相关方法中调用ViewTreeObserver上的注册的监听器的方法,…...

【光伏干货】光伏无人机巡检步骤
随着光伏产业的迅速发展和无人机技术的日益成熟,光伏无人机巡检已成为提高光伏电站运维效率、降低运维成本的重要手段。本文将详细介绍光伏无人机巡检的步骤,帮助读者更好地理解和应用这一技术。 一、前期准备 1、设备检查:对无人机及其相关…...

『大模型笔记』从头开始代码构建GPT!
从头开始代码构建GPT! 文章目录 一. 从头开始代码构建GPT!二. 参考文献一. 从头开始代码构建GPT! 我们构建了一个生成式预训练Transformer (GPT),遵循论文《Attention is All You Need》和OpenAI的GPT-2 / GPT-3的方法。我们讨论了与ChatGPT的联系,ChatGPT已经风靡全球。我…...
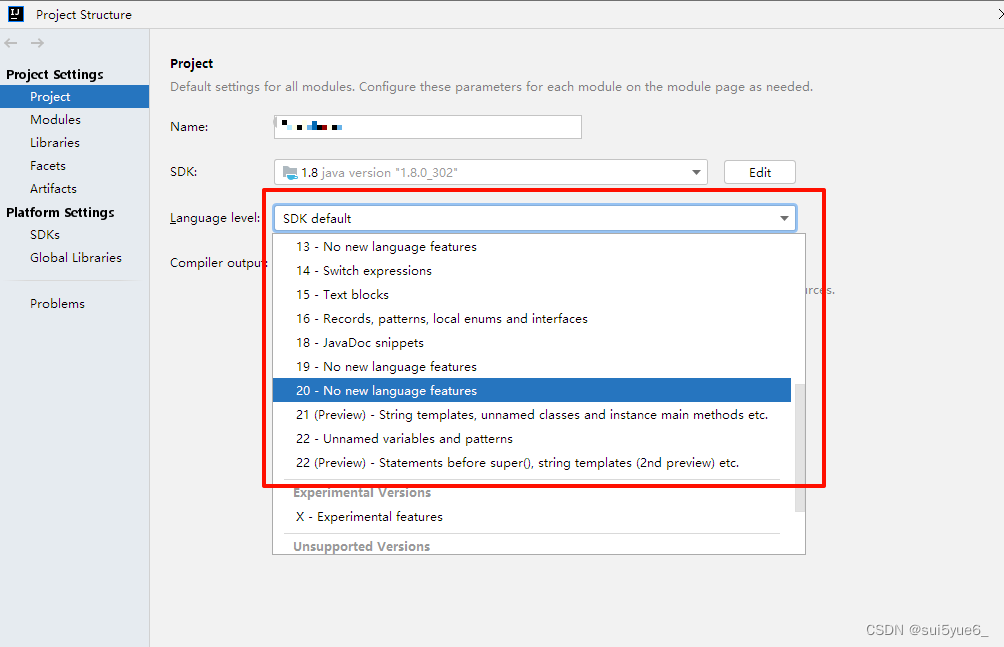
idea的project structure下project [lauguage ]()level 没有java的sdk17选项如何导入
idea的project structure下project lauguage level 没有java的sdk17选项如何导入 别导入了,需要升级idea版本。idea中没有project language level没有17如何添加 - CSDN文库 别听这文章瞎扯淡 2021版本就是没有,直接卸载升级到最新版本就可以了。没办法…...

JavaScript数据类型与转换
JavaScript是一种弱类型语言,在定义变量的时候不用规定数据的类型,但这部表示JavaScript没有规定数据类型。 数值 JavaScript中数值类型不区分浮点数与整数,所有的数值都以浮点型来表示。另外JavaScript核心,Math还提供了大量的…...

三十、openlayers官网示例解析Double click, Drag and Zoom——第二次点击鼠标拖拽缩放地图效果、取消地图双击放大事件
这篇展示了如何在地图上添加第二次按下鼠标移动鼠标实现拖拽缩放地图效果。 官网demo地址: Double click, Drag and Zoom 官网介绍文字的翻译如下: 示例比较简单,直接贴代码: const map new Map({//添加第二次点击拖拽缩放地图i…...

前端基础入门三大核心之网络安全篇:TLS/SSL的魔法之旅
前端基础入门三大核心之网络安全篇:TLS/SSL的魔法之旅 TLS/SSL:数据安全的守护神工作原理:四步走,安全到家1. 握手,你好吗?代码示例(伪代码):客户端发起握手请求 2. 身份…...

Flutter 中的 SnackBarAction 小部件:全面指南
Flutter 中的 SnackBarAction 小部件:全面指南 在 Flutter 中,SnackBar 是一种流行的用于提供轻量级反馈的方式,它可以在屏幕上短暂显示消息。SnackBarAction 则是与 SnackBar 结合使用的一种按钮组件,允许用户对显示的消息做出响…...

Point-Nerf 理论笔记和理解
文章目录 什么是point nerf 和Nerf 有什么区别Point Nerf 核心结构有哪些?什么是point-based radiance field? 点云位置以及置信度是怎么来Point pruning 和 Point Growing 什么是point nerf 和Nerf 有什么区别 基本的nerf 是通过过拟合MLP来完成任意视角场景的重…...

深度学习中的梯度消失和梯度爆炸问题
在深度学习领域,随着模型层数的增加,我们常常会遇到两个棘手的问题:梯度消失(Vanishing Gradients)和梯度爆炸(Exploding Gradients)。这两个问题严重影响了深度神经网络的训练效率和性能。本文…...
Flink 通过 paimon 关联维表,内存降为原来的1/4
你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益: 了解大厂经验拥有和大厂相匹配的技术等 希望看什么,评论或者私信告诉我! 文章目录 一…...

Python知识详解【1】~{正则表达式}
正则表达式是一种用于匹配字符串模式的文本工具,它由一系列普通字符和特殊字符组成,可以非常灵活地描述和处理字符串。以下是正则表达式的一些基本组成部分及其功能: 普通字符:大多数字母和数字在正则表达式中表示它们自己。例如…...
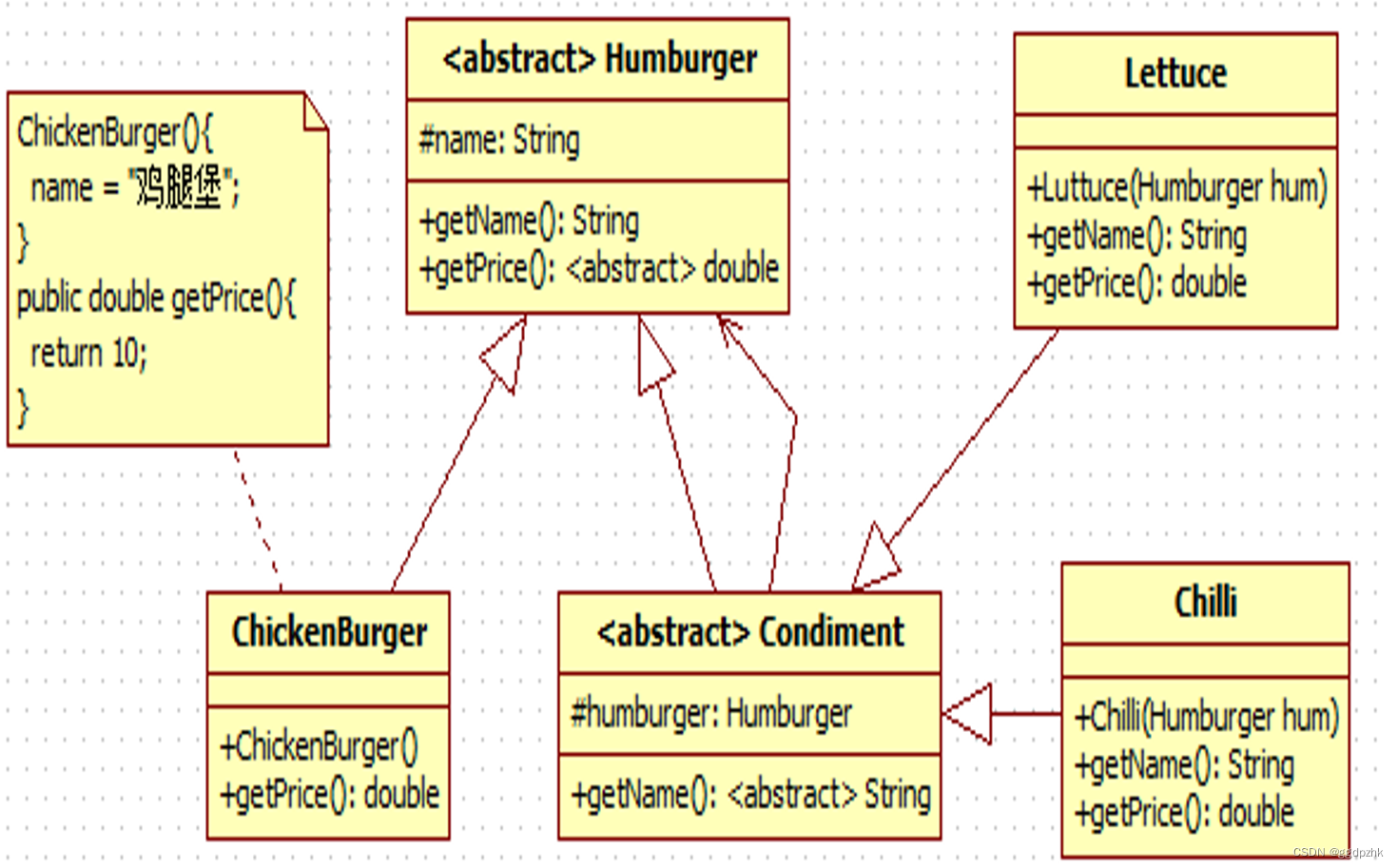
装饰模式:鸡腿堡
文章目录 UML类图目录结构Humburger.javaChickenBurger.javaCondiment.javaChuilli.javaLettuce.javaTest.java深度理解test怎么写 UML类图 目录结构 我们从指向最多的开始写 Humburger.java package zsms;public abstract class Humburger {protected String name;public S…...

视图【mysql数据库】
目录 一、视图的创建、查看、修改、删除 二、cascaded、local检查选项 cascaded和local的区别 三、视图的更新 四、视图的作用 一、视图的创建、查看、修改、删除 二、cascaded、local检查选项 上面的几句SQL中,我们虽然给视图插入了id 30的数据,但…...
函数)
opencv的findContours()函数
来自WaTab AI Pro 请详细解释cv2.findContours(): cv2.findContours() 是 OpenCV 中用于检测图像轮廓的函数。轮廓可以看作是将连续的点(沿边界)连接在一起的一条曲线,具有相同的颜色或强度。该函数常用于图像处理和计算机视觉中…...
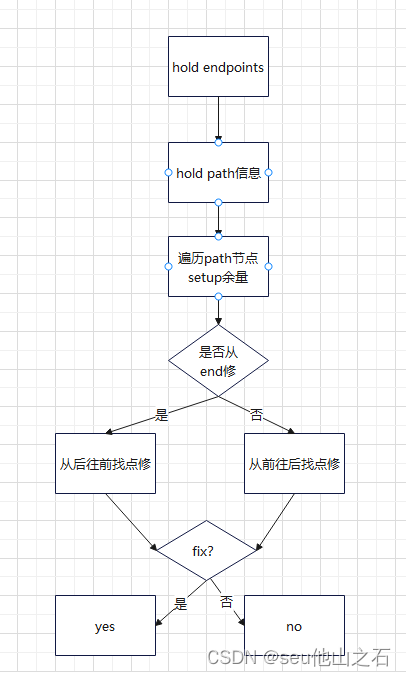
多电压档hold扫尾
MMMC下STA收敛更为困难,setup通过DMSA可以很好的得到收敛;但是常规的时序修复工具很难通过工具得到最终clean的时序状态,本文介绍一种多模多角下hold的收敛方法。 该方法主要通过遍历hold路径上多电压setup的余量,支持从前往后和从…...
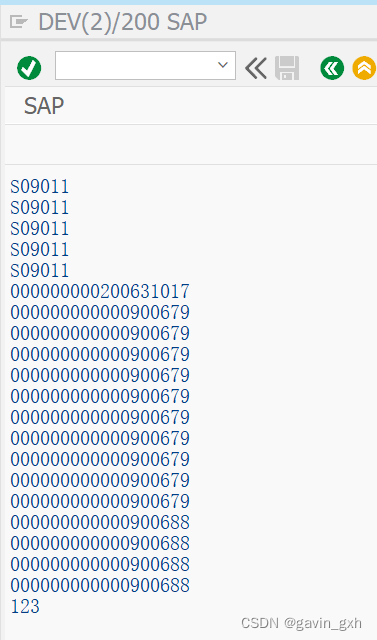
ABAP Json解析案例
ABAP解析返回的JSON 案例 DATA:LTOKEN TYPE STRING.DATA: LL_LINES(10),"行数LL_TABIX(10),"循环标号LL_PECNT TYPE P LENGTH 6 DECIMALS 2, "百分比LL_PECET(6),"百分数LL_TEXT(40)."消息CLEAR: LL_LINES,LL_TABIX,LL_PECNT,LL_PECET,LL_TEXT.* …...

首次使用Taotoken从注册到发出第一个API请求的全流程指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 首次使用Taotoken从注册到发出第一个API请求的全流程指南 对于初次接触大模型API的开发者来说,从注册平台到成功发出第…...

如何快速获取网易云QQ音乐歌词:3大场景解决你的本地音乐无歌词困扰
如何快速获取网易云QQ音乐歌词:3大场景解决你的本地音乐无歌词困扰 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为本地音乐播放时没有歌词而烦恼吗&am…...

2026年主流行工具有何不同?subAgent是趋势还是营销?深度解析!
AI Coding工具中的“subAgent”正从营销词发展为工程抽象,实现上下文、权限、任务和执行的拆分管理。主流工具如Claude Code、Codex、OpenClaw、Gemini CLI均在强化subAgent能力,但设计哲学各异。文章从技术视角解析subAgent的本质、各工具异同及使用选择…...

终极指南:5分钟为WinForms应用注入Material Design现代化界面
终极指南:5分钟为WinForms应用注入Material Design现代化界面 【免费下载链接】MaterialSkin Theming .NET WinForms, C# or VB.Net, to Googles Material Design Principles. 项目地址: https://gitcode.com/gh_mirrors/mat/MaterialSkin MaterialSkin 2是一…...

贝壳季报图解:营收189亿 经调整净利16亿同比增15.7%
雷递网 雷建平 5月19日贝壳(纽交所代码:BEKE;香港联交所代号:2423)今日公布其截至2026年3月31日止第一季度未经审计财务业绩。财报显示,贝壳2026年第一季度贝壳实现净收入189亿元,净利润12.55亿…...

FontForge终极指南:免费开源字体编辑器从零到精通
FontForge终极指南:免费开源字体编辑器从零到精通 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge FontForge是一款完全免费的开源字体编辑器,…...
)
TVA驱动智能家居的视觉范式革命(4)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

推理服务为什么一上自动 Prompt 优化就开始成本失控:从 Prompt 版本爆炸到在线 A/B 收敛的工程实战
一、自动 Prompt 优化的成本幻觉 不少团队上线推理服务后,发现同一任务换句 Prompt 输出质量可提升 20%。🚀 自动 Prompt 优化因此成了香饽饽——系统同时维护几十个版本在线分流。但两周后账单涨了 40%。⚡️ 问题不在 Prompt,而是版本爆炸把…...

智能视频转PPT:3分钟实现视频内容自动提取的完整方案
智能视频转PPT:3分钟实现视频内容自动提取的完整方案 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 你是否曾为整理会议录像中的PPT内容而烦恼?手动暂停、截…...

【Perplexity健身计划搜索实战指南】:20年AI搜索专家亲授3大精准检索心法,错过再等一年
更多请点击: https://codechina.net 第一章:Perplexity健身计划搜索实战指南导论 Perplexity 是一款以推理深度和引用可追溯性见长的 AI 搜索工具,特别适合需要结构化、证据支撑型信息检索的场景。在健身领域,用户常面临计划泛滥…...