小红书云原生 Kafka 技术剖析:分层存储与弹性伸缩
面对 Kafka 规模快速增长带来的成本、效率和稳定性挑战时,小红书大数据存储团队采取云原生架构实践:通过引入冷热数据分层存储、容器化技术以及自研的负载均衡服务「Balance Control」,成功实现了集群存储成本的显著降低、分钟级的集群弹性迁移、高性能的数据访问策略和自动化的资源调度。
这些技术革新不仅极大提升了 Kafka 集群的运维效率,还为小红书业务带来了更优质的服务体验,同时为未来在存算分离、多活容灾等方向的进一步优化奠定了基础。

1.1 小红书 Kafka 的发展现状
小红书 Kafka 集群规模伴随着公司业务的蓬勃发展而显著扩张。目前,集群的峰值吞吐量已经达到 TB 级别,并且随着 AI 大模型和大数据技术的持续扩展,数据量仍在快速增长。
尽管经典的 Apache Kafka 架构在提供高吞吐、高性能数据传输方面表现出色,但也逐渐暴露出了一些弊端。一方面,基于多副本和云盘/SSD 的模式,Apache Kafka 的存储成本居高不下,难以满足业务长期存储数据的需要;另一方面,数据与计算节点之前的强绑定关系,严重阻碍了集群的扩缩容效率,在弹性和调度能力方面受到了很大的挑战。
1.2 面临的问题

随着小红书 Kafka 集群规模的持续扩大,一系列挑战也随之而来,涉及成本、能效、运维和系统稳定性等多个方面:
-
成本:
-
存储成本昂贵:Kafka 的存储成本较高,按当前内部机器规格配比,在充分利用带宽的情况下,数据存储的生命周期非常有限。
-
算力资源浪费:Kafka 的性能瓶颈主要集中在 IO 操作上,存在大量的 CPU 资源处于闲置状态。加之现有的虚拟机部署方式在资源共享和隔离方面表现不佳,进一步限制了 CPU 资源的有效分配。
-
-
效率:
-
集群运维耗时长:因磁盘和节点绑定,Kafka 集群的扩缩容需要搬迁海量数据,这不仅速度缓慢,而且耗时可能从数天到数周不等。
-
调度能力弱:因虚机部署,缺乏灵活的资源调度能力,一旦坏机,补货效率低。
-
-
稳定性:
-
应急能力差:缓慢的扩缩容速度导致性能指标在高负载下显著下降,请求响应时间可能延长至正常情况的两倍,影响整体服务质量。
-
追赶读期间稳定性受损:在追赶读操作期间,系统资源的大量消耗会使得资源使用率飙升,从而影响到实时读写任务的稳定性
-
综上所述,Kafka 集群面临的主要痛点可归纳为两个核心问题:存算一体化架构的局限性,以及虚拟机部署方式带来的运维和资源调度难题。解决这些问题,对于提升 Kafka 集群的整体性能和运维效率,具有重要意义。
1.3 解决方案
1.3.1 如何解决“存算一体化”带来的问题?
为了解决存算一体化架构弊端,我们需要引入「Cloud-Native」弹性架构模式,来解耦存储与计算,下述为方案对比:
1)自研存算分离(on ObjectStore):

该方案通过对象存储作为统一的存储基础,实现了计算层与数据绑定关系的解耦。存储层利用对象存储的纠删码技术和规模经济效应,能同时获得秒级弹性与成本两大收益,是较为理想的解决方案。
然而,对象存储本身延迟较高,想要达到整体较高的性能,需要有独立的读写加速层配合,这一部分也需要考虑弹性化的架构设计。整体架构复杂度较高,因此方案研发周期会比较长。
2)冷热分层存储(on ObjectStore):
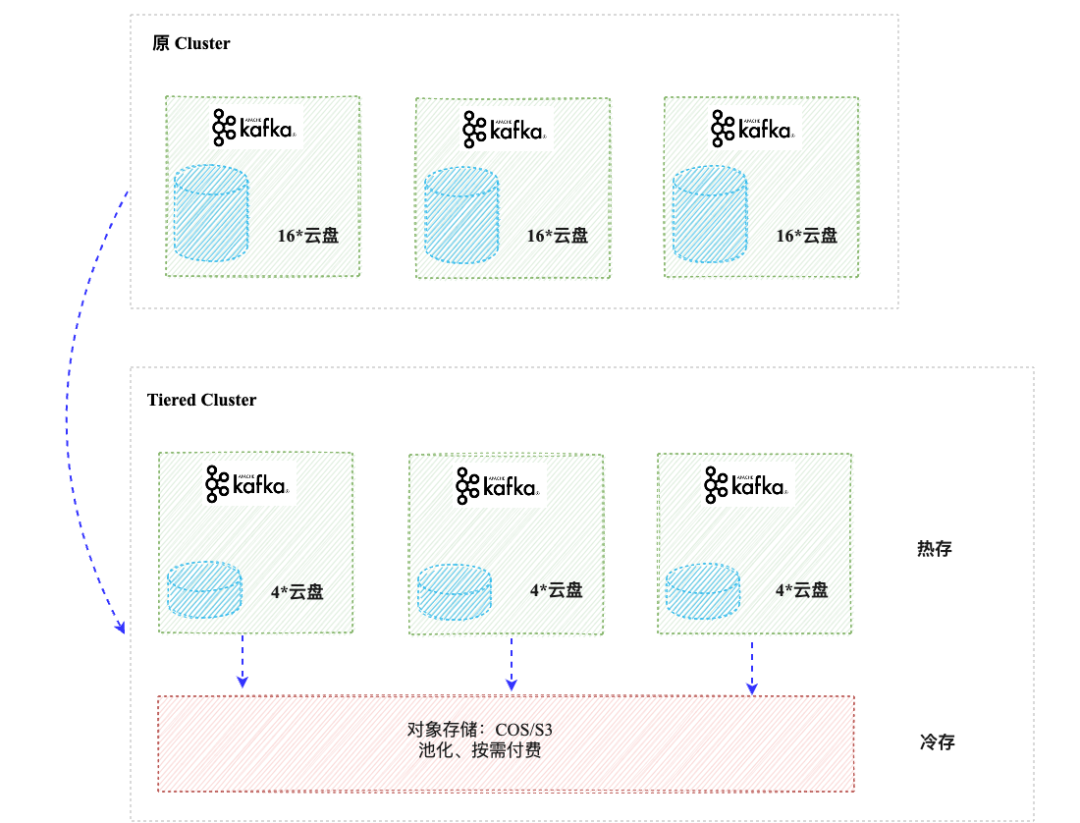
冷热分层的概念,即为本地仅保留少量的热数据,将大部分冷数据卸载到较为便宜的对象存储中,以实现成本节约。Kafka 和其他 MQ 类社区,近年来陆续提出该概念并进行发展。
此架构不改变数据核心的写入流程和高可用性(HA)机制,而是异步卸载数据以减少对核心架构的改动,实现难度较低。不过弊端也正是因为没有触动核心的副本机制,数据与计算节点之间仍然存在部分的耦合,在弹性能力方面稍逊一筹。
3)Apache Pulsar

Apache Pulsar 是近年来非常火热的一款云原生消息引擎,它天生支持存算分离架构,具备快速的弹性扩展特性,同样是一个选择。不过其底下的存储底座 Bookkeeper 仍然基于磁盘存储,单节点受限于磁盘容量,在存储成本上没有明显收益(但 Pulsar 近期也引入了分层存储能力)。此外,考虑到历史大量的存量作业,转向 Pulsar 可能面临较高的推广难度和替换周期,眼下难以快速拿到收益。
在当前阶段,“成本”是我们最关心的问题。如何获得大量成本节省?如何缩短收益获取周期?都是需要核心考虑的因素。在经过大量对比和取舍后,「分层存储」架构依靠其低成本、中等弹性、短落地周期的特点,成为了我们当下的最佳选择。
与社区版本相比,小红书分层架构经过了完全的重新设计,解决了原有方案的多项问题,并显著提升了数据迁移速度和冷数据读取性能。在新架构上线六个月内,我们已完成线上 80% 的集群升级覆盖,充分地获得了新架构带来的各项收益。
1.3.2 如何解决“虚机部署”带来的问题?
为了解决虚机部署带来的问题,关键在于提升混部与调度能力、优化算力资源的使用、以及增强自动化运维的水平。以下是几种方案的对比分析:

综合考虑,采用小红书容器底座结合 PaaS 平台托管的新型容器化架构,不仅能够平滑地将 Kafka 迁移至云端,还能显著提升算力资源的利用率,加强运维自动化。

2.1 整体架构
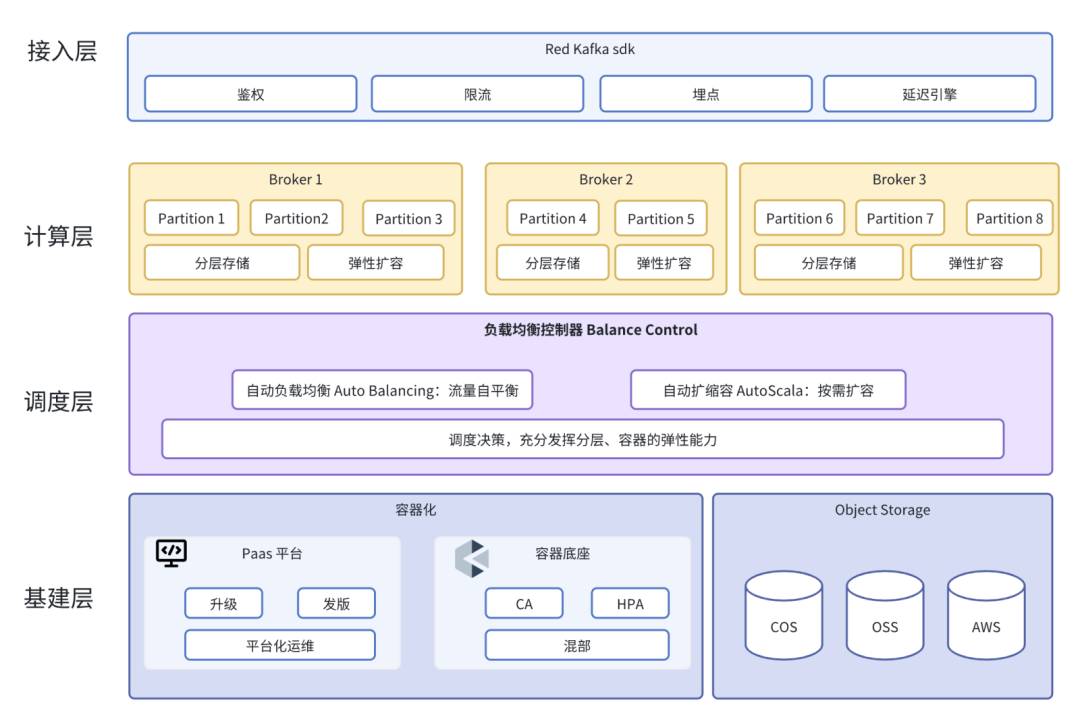
小红书 Kafka 云原生架构共分为四层:
-
接入层:小红书 Kafka 特色 SDK,提供鉴权、限流、服务发现等丰富功能,实现更加灵活和安全的数据流管理
-
计算层:Kafka Broker 基于「分层存储」技术,实现本地数据“弱状态化”,有效地解决了系统的弹性问题,保障系统的稳定性和可扩展性
-
调度层:负载均衡调度器向北可均衡 Broker 间流量负载,向南结合容器实现自动化弹性扩缩容,保障系统能够根据实际需求动态调整资源,实现 “弹性伸缩、按量付费”
-
基建层:容器和对象存储底座,为整个系统提供了强大的 PaaS 平台化运维管理调度能力和低成本无限存储能力
2.2 分层存储
分层存储作为 Kafka 云原生化的核心能力,提供成本优化、消费隔离、弹性扩展等多重优势。其整体架构如下图所示。基本原理是基于冷热分层,即将近实时的热数据保留在高性能云盘中,而将冷数据下沉至低成本、可靠性极高的对象存储中。
对象存储具有无限扩展、低成本、可靠性极高的特点。通过利用对象存储来存储数据,我们能够从根本上解决不断增长的数据存储需求,摆脱了传统数据存储所带来的诸多烦恼。对象存储的架构设计理念,使其在处理大规模数据时表现出色,同时确保了数据的高可用性和安全性,为 Kafka 架构的云原生化提供了强大的支撑。

2.2.1 存储成本优化
在大数据场景下,业务方经常需要回溯过去多天的数据,以进行各种分析、回溯和审计等操作。然而,传统的基于云盘的 Kafka 存储解决方案不仅成本高昂,而且在存储能力上也存在限制,只能满足短期数据的存储需求,这对于需要长期数据保留的业务场景构成了重大挑战。
为了突破这一瓶颈,我们采用基于对象存储的分层存储架构。这一创新举措显著降低了存储成本并提升了数据存储的灵活性。对象存储的低成本特性,结合其出色的扩展能力,使得小红书 Kafka 能够经济高效地存储大量数据,同时保证了数据的高可靠性和安全性。
在实施分层存储架构的过程中,我们采取了以下策略:
-
冷数据存储:将不常访问的冷数据迁移到成本更低的对象存储中,从而大幅度减少存储开支。
-
热数据存储:对于频繁访问的热数据,继续使用性能较高的云盘存储(EBS),但通过优化存储策略,将存储容量减少了75%。
通过这种新型的存储架构,小红书 Kafka 实现了存储成本的大幅度降低——最高可达 60%。此外,这种架构还允许 Topic 的存储时间从原来的 1 天延长至 7 天或更久,极大地增强了业务数据的回溯能力,为业务数据驱动决策提供更加坚实的基础。
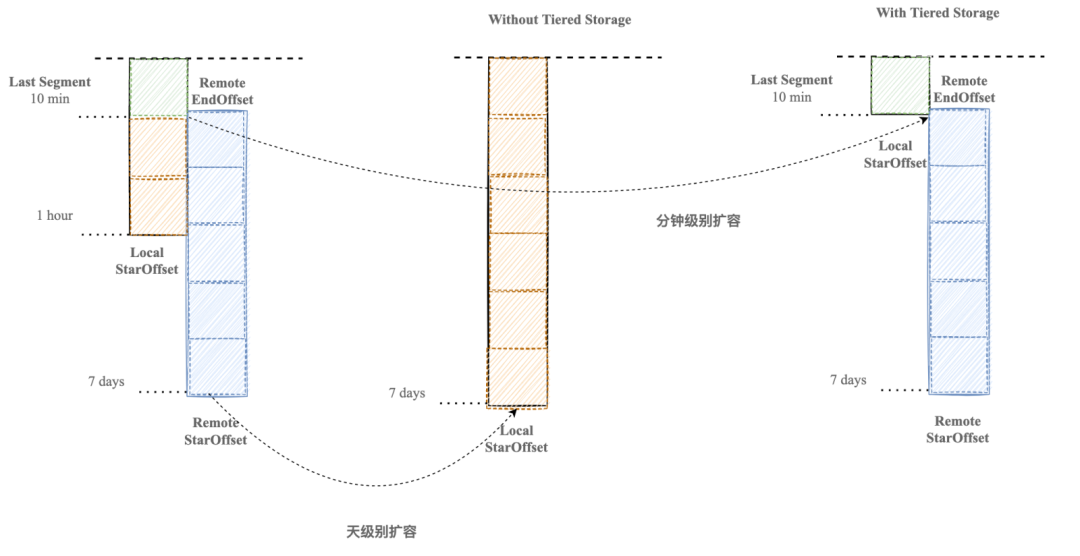
2.2.2 分钟级弹性迁移
在 Kafka 原生架构中,集群扩容是一个复杂且耗时的过程。由于冷数据存储在磁盘上,扩容时需要搬迁海量数据,这不仅会导致磁盘和网络 IO 的负载达到极限,也会对集群的稳定性造成影响。
我们引入了分层存储机制后,Topic 的所有副本可以共享同一份冷数据。这意味着对于 Topic 的新副本,在集群扩容时不再需要复制 Leader 本地的所有热数据,而只需拷贝远端尚未拥有的部分,通常是 Leader 本地存储的最后一个 segment。
这种优化显著减少了迁移数据的量,从而将 Topic 迁移的时间从天级别缩短到分钟级别。在实际应用场景中,即使是对于具有 10GB/s 吞吐量的 Topic,在流量高峰期的迁移过程也仅需 5 分钟即可完成。
2.2.3 高性能缓存策略
引入对象存储后,虽然解决了存储成本和弹性等问题,但也面临了一些挑战,主要包括访问速度和延迟等方面,具体表现为:
-
访问速度: 对象存储的总吞吐上限理论只受带宽限制,但单线程访问速度较低,远远低于传统磁盘存储。
-
延迟: 目前对象存储主要通过 HTTP 协议进行访问,因此存在较高的延迟,包括建立连接等操作的延迟可达到 20 毫秒级别,对于部分小文件访问极不友好。
针对这些问题,我们采取了以下优化策略:
-
批量读取: 以 8MB 对齐的方式读取 Segment 数据,减少访问次数,从而提升数据读取的效率。
-
缓存预加载: 结合数据访问的局部性原理和消息队列的顺序读特性,实现了并发的预读机制,以提高数据的访问速度和响应性。同时,通过内存隔离技术,避免了 pagecache 被污染的问题。
这些策略的实施带来了显著的性能提升:
-
高缓存命中率: 缓存命中率达到了 99%,有效地提高了数据访问的效率和速度。
-
性能提升:冷数据读取性能相比开源架构提升了 30%,这在大规模数据处理场景中尤为重要。

2.3 容器化
下图为小红书 Kafka 容器化的整体架构:
-
PaaS 能力托管:通过小红书容器化调度 PaaS 平台来托管 Kafka 集群,这不仅简化了部署和运维流程,降低了运维成本,而且通过图形化界面实现了集群版本和配置的直观管理,即所谓的「白屏化操作」。
-
服务状态管理:为了保证有状态应用服务的连续性和状态的一致性,我们采用 DupicateSet(StatefulSet) 来管理 Kafka 服务。
-
异常保护机制:
-
基于 Supervisord 的进程监控:在容器内部,Supervisord 作为主要的进程管理工具,监控 Kafka 进程。一旦 Kafka 进程异常退出,Supervisord 能够迅速重启进程,避免了容器级别的重建,从而减少了服务中断时间。
-
快速修复(HotFix):当基础环境如数据存储出现问题时,业务团队可以直接进入容器进行快速修复,这种即时的干预能力大大提高了系统的稳定性和恢复速度。
-
集群状态的删除保护:我们实现了基于 Kafka 集群状态的删除防护机制。当集群中掉队实例的数量超过预设阈值时,通过 Webhook 技术自动拒绝所有可能恶化集群状态的操作请求,从而保护集群不受进一步损害。
-

2.3.1 状态管理
在 Kubernetes 环境中部署有状态服务如 Kafka 时,确保其状态的持久性和可靠性是至关重要的。
Kafka 的状态主要包括拓扑状态和存储状态,以下是对这两部分状态的管理策略:
-
拓扑状态:拓扑状态涉及 Pod 的网络和身份标识,确保每个 Pod 具有固定的标识和访问方式。我们通过容器底座提供的能力保障了 Pod IP 不变。

-
存储状态:存储状态包括云盘数据、日志数据和配置文件等,这些数据需要在 Pod 迁移、重启或升级时保持不变。
-
持久卷(PV)和持久卷声明(PVC):使用 DupicateSet 使用,为每个 Pod 分配专用的存储资源,确保存储状态的持久性和一致性。
-
配置管理:使用 ConfigMap 和环境变量来管理 Kafka 的配置,确保 Pod 即使重启,配置也能保持不变。
-
日志管理:将日志目录放置在持久化数据卷中,保障日志数据在 Pod 重启或迁移时不会丢失。
-
2.3.2 离线混部
在上云之前,Kafka 作为存储产品,面临着单机 CPU 能效低下的问题,大约只有 10% 的效率,这主要是由于夜间流量低谷以及 IO-bound 特性所致。在这种情况下,往往存在大量的闲置 CPU 资源,导致资源利用率不高。
上云后通过容器提供的混部能力,我们可以将离线业务调度至 Kafka Kubernetes 机器池中,填平 CPU 低谷,从而保证全天利用率达到一个较高的水平。这种整合策略显著提升了资源的全天利用率,上云后的能效利用率提高到了 40% 以上,远高于之前的水平。
利用容器技术的混部能力,使得我们能够更加灵活地管理和调度资源,根据实际情况对资源进行动态分配和利用,从而最大限度地提高了系统的整体性能和资源利用率。
2.3.3 CA 资源调度
除了上述提及能力外,容器技术还为我们带来了资源层面的弹性调度能力,其中 Cluster Autoscaler(CA)是一项关键技术。
在未采用 Cluster Autoscaler 的传统模式下,系统工程师(SRE)需要手动执行服务器的启动和关闭操作,这不仅效率低下,而且在面对紧急的扩容需求时,现有的流程显得繁琐且响应迟缓,无法及时适应业务需求的波动。
引入 Cluster Autoscaler 之后,这一状况得到了根本性的改善。CA 能够自动管理业务集群的扩缩容流程,以缓冲区(Buffer)的形式智能地调整资源分配。它通过实时监控集群的负载情况,动态地增加或减少节点数量,实现了快速且精准的资源弹性调度。这种自动化的调度机制不仅提升了系统的适应性和稳定性,而且显著降低了运维团队的工作负担,确保了业务的持续稳定运行。
2.4 弹性调度
在线上部署的 Apache Kafka 集群中,流量波动、Topic 的增减以及 Broker 的启动与关闭是常态。这些动态变化可能导致集群中节点的流量分布不均衡,进而引起资源浪费和影响业务的稳定性。为了解决这一问题,需要对 Topic 的分区进行主动调整,以实现流量和数据的均衡分配。
原生 Apache Kafka 由于磁盘上存储大量历史数据,因此在进行均衡调度时会打满磁盘 IO 和网络带宽,从而影响实时业务的正常运行,导致集群负载均衡较为困难。
相比之下,分层的弹性架构则为负载均衡提供了可能。这种架构设计使得在进行负载均衡调度时可以避免过多的 IO 压力,从而减少对实时业务的影响,使得负载均衡的调整更加灵活和高效。
因此,除了分层和容器两大关键 『弹性』 技术,我们还自研了负载均衡服务 「Balance Control」,其能够充分利用分层和容器的软硬件弹性能力,实现持续数据平衡和自动弹性扩缩容,使得集群能够更加灵活地应对流量波动和业务变化,从而保障了系统的稳定性和可靠性。
2.4.1 持续数据自平衡(Auto-Balancing)
Balance Control 采用多目标优化算法来实现资源分配的最优化。其能够综合考虑 Topic 副本、网络带宽、磁盘存储、计算资源等多种因素,自动调整 Partition 分配,以达到最佳的资源负载平衡。整体自平衡流程如下:
-
数据采集:Kafka 侧 Metrics Reporter 监听 Kafka 内置的所有指标信息,并定期对感兴趣的指标(如网络进出口流量、CPU 利用率等)进行采样,并上报指标
-
指标聚合:收集的指标用于生成集群状态快照 ClusterModel,包括 Broker 状态、Broker 资源容量、各 Broker 管理的 Topic-Partition 流量信息等
-
调度决策自平衡:调度决策器定期获取集群状态模型的快照,并根据各个 Broker 的容量和负载信息,识别出流量过高或过低的 Broker。随后,它会尝试移动或交换分区,以完成流量的重新平衡。

2.4.2 自动弹性扩缩容(Auto-Scaling)
原生 Kafka 扩容需要搬迁海量数据,耗时通常为小时甚至天级,几乎无法做到按需扩缩容。为了维持集群的稳定性,运维团队不得不提前规划资源,以应对可能的流量高峰,这种做法往往导致资源的浪费和效率的降低。
云原生时代,通过借助分层和容器的软硬件弹性能力,Balance Control 可以在分钟级自动完成集群的原地扩缩容和流量的重新调度,以适应业务负载的变化,做到 「弹性伸缩、按量付费」 的目标。这一关键能力我们称之为 AutoScala。
AutoScala:实时监控 Kafka 集群的负载,并根据预设的策略自动调整集群规模。例如,当集群负载超过某个阈值(如 70%)并保持一段时间时,系统会自动增加集群规模;从而实现快速、高效的集群扩缩容,优化资源利用率。
整体流程如下:
-
负载监控:Kubernetes 的 Horizontal Pod Autoscaler(HPA)组件根据预设的策略(如定时、资源水位等)来判断是否需要扩容,并相应地调整集群规模配置。
-
自动负载均衡:当 Balance Control 探测到新加入的 Broker,分钟级完成流量调度平衡。


总体来看,云原生弹性架构为小红书 Kafka 带来了巨大的成本收益和运维效率提升。从落地效果上看,我们实现了 60% 的存储成本节省和 10 倍的扩缩容运维效率提升,并成功实现了「弹性伸缩、按量付费」的商品化模式。
此外,我们正不断探索和优化云原生消息引擎的能力,以期提供更稳定和高效的服务。未来,我们计划持续研究存算分离技术和多活容灾方案,以实现极致的系统可扩展性和稳定性,满足业务日益增长的服务需求。
随着技术的不断演进,我们将不断引入新的技术能力和创新方案,为业务提供更加卓越的消息引擎服务,期待您加入团队!

-
六娃(张亿皓)
小红书大数据存储架构团队负责人,现负责小红书流存储引擎 Kafka、分布式文件加速系统等领域建设。
-
剑尘(黄章衡)
小红书消息引擎内核研发专家,Apache RocketMQ Committer & SOFASTACK SOFAJRaft Committer,现负责小红书 Kafka 分层存储、负载均衡、存算分离等技术领域建设。
-
阿坎(焦南)
小红书消息引擎内核研发专家,现负责小红书 Kafka 流批一体、容器化等生态探索和建设。

小红书-大数据存储研发专家(上海/北京)
工作职责:
负责大数据存储产品(流存储、文件/缓存系统)的研发与优化工作,构建一流的数据基础设施,满足大数据和 AI 对于数据基础设施不断增长的需求。
新一代 Kafka 云原生架构的研发落地工作,结合对象存储、容器化与流批一体等技术,通过存算分离架构大幅提升弹性伸缩能力,在成本与效率方面取得新的收益
自研分布式文件加速系统,提升大数据/AI 引擎的 IO 性能和弹性能力,在大模型时代进一步拉近计算与存储距离,助力各数据引擎进一步云原生,提升用户体验,实现降本增效。
岗位要求:
本科及以上学历,3 年以上大数据存储研发经验
熟悉主流的大数据存储产品 (Kafka/HDFS/Alluxio/JuiceFS/HBase 等),有文件系统研发经验或者开源社区 Committer 尤佳;
优秀的设计与编码能力,针对业务需求与问题,可快速设计与实现解决方案;
具备良好的沟通和团队协作能力,做事主动积极负责任,有技术热情和激情面对挑战。
欢迎感兴趣的同学发送简历至 REDtech@xiaohongshu.com,并抄送至 yihaozhang@xiaohongshu.com
相关文章:
小红书云原生 Kafka 技术剖析:分层存储与弹性伸缩
面对 Kafka 规模快速增长带来的成本、效率和稳定性挑战时,小红书大数据存储团队采取云原生架构实践:通过引入冷热数据分层存储、容器化技术以及自研的负载均衡服务「Balance Control」,成功实现了集群存储成本的显著降低、分钟级的集群弹性迁…...

Python实现解码二进制数据以匹配给定的C++结构体
要在Python中实现解码二进制数据以匹配给定的C结构体Ytest,你需要了解每个字段在结构体中的偏移量(由于结构体内存对齐,这些偏移量可能与字段的顺序和大小不完全对应)。不过,在没有指定内存对齐的情况下,我…...
实施阶段(2024年5月)
【项目活动1】斐波拉契数列第n项的值? 数学思想:第一项和第二项的值都为1,从第三项开始值为前两项的和。 方法一:迭代 迭代变量:f1和f2 迭代表达式:f1,f2f2,f1f2 计数器:i 迭代表达式运算…...
 Object Pascal 学习笔记---第13章第3节 (弱引用是系统托管的 ))
(delphi11最新学习资料) Object Pascal 学习笔记---第13章第3节 (弱引用是系统托管的 )
13.4.2 弱引用是系统托管的 弱引用的托管是一个非常重要的内容。换句话说,系统会在内存中保存一个弱引用列表,当对象被销毁时,系统会检查是否有任何弱引用指向该对象,如果有,系统会将实际引用赋值为 nil࿰…...

安装WordPress
第 1 步:下载并解压 wget https://wordpress.org/latest.tar.gz 然后使用以下命令提取包: tar -xzvf latest.tar.gz 第 2 步:创建数据库 比如数据库名称为wordpress,编码格式为 utf8mb4_general_ci 第 3 步:设置wp-con…...

【STL库源码剖析】list 简单实现
从此音尘各悄然 春山如黛草如烟 目录 list 的结点设计 list 的迭代器 list 的部分框架 迭代器的实现 容量相关相关函数 实现 insert 在指定位置插入 val 实现 push_back 在尾部进行插入 实现 erase 在指定位置删除 实现 pop_back 在尾部进行删除 实现 list 的头插、头删 实现…...

web前端框架设计第十一课-常用插件
web前端框架设计第十一课-常用插件 一.预习笔记 1.路由的基础使用 2.动态路由 3.嵌套路由 二.课堂笔记 三.课后回顾 –行动是治愈恐惧的良药,犹豫拖延将不断滋养恐惧...
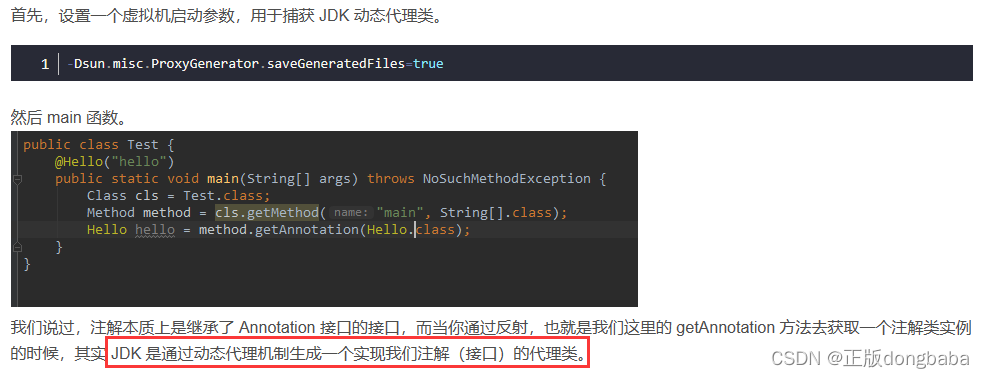
Java基础-注解
注解本质是继承了Annotation接口的一个接口 首先,我们通过键值对的形式可以为注解属性赋值,像这样:Hello(value “hello”)。 接着,你用注解修饰某个元素,编译器将在编译期扫描每个类或者方…...

SpringCloud之SSO单点登录-基于Gateway和OAuth2的跨系统统一认证和鉴权详解
单点登录(SSO)是一种身份验证过程,允许用户通过一次登录访问多个系统。本文将深入解析单点登录的原理,并详细介绍如何在Spring Cloud环境中实现单点登录。通过具体的架构图和代码示例,我们将展示SSO的工作机制和优势&a…...
原创)
二分查找算法详讲(三种版本写法)原创
介绍: 二分查找算法(Binary Search)是一种在有序数组中查找目标元素的算法。 它的基本思想是通过将目标元素与数组的中间元素进行比较,从而将搜索范围缩小一半。 如果目标元素等于中间元素,则搜索结束;如果目标元素小…...
之commit之前自动执行脚本)
Git钩子(Hooks)之commit之前自动执行脚本
介绍 官方文档: 英文:https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks中文:https://git-scm.com/book/zh/v2/自定义-Git-Git-钩子 下面只复制了pre-commit部分文档,其他详见官方文档。 Git Hooks Like many other…...

nano机器人2:机械臂的视觉抓取
前言 参考链接: 【机械臂入门教程】机械臂视觉抓取从理论到实战 GRCNN 通过神经网络,先进行模型训练,在进行模型评估。 机械臂逆运动学求解 所有串联型6自由度机械臂均是可解的,但这种解通常只能通过数值解法得到,计算难度大&am…...

技术速递|宣布 Java on Azure 开发工具支持 Java on Azure Container Apps
作者:Jialuo Gan 排版:Alan Wang 在 Microsoft Build 2024 期间宣布,Azure Container Apps 现在可为 Java 开发人员提供丰富的操作功能。(详细内容请参见本博客)。 我们很高兴地与大家分享,Azure Toolkit for Intelli…...
随机森林算法实现分类
随机森林算法实现对编码后二进制数据的识别 1.直接先上代码! import numpy as np import pandas as pd from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import …...

Ubuntu卸载软件
在删除这些目录之前,你必须确定一个非常重要的事情:确认没有任何服务正在使用这些版本的 PHP。如果你删除了正在使用的 PHP 版本的扩展目录,那么依赖于这个版本的 PHP 的网站或服务可能会停止工作。 如果你确定某个版本的 PHP 没有在使用中&…...

网络工程师:网络可靠性技术
一、可靠性 平均故障间隔时间MTBF(Mean Time Between Failure)和平均修复时间MTTR(Mean Time to Repair)这两个指标来评价系统的可靠性。 1、平均故障间隔时间MTBF MTBF是指一个系统无故障运行平均时间,通常以小时为单位。MTBF越大可靠性越高。 2、平均修复时间MTTR…...

科技引领未来:高速公路可视化
高速公路可视化监控系统利用实时视频、传感器数据和大数据分析,通过图扑 HT 可视化展示交通流量、车速、事故和路况信息。交通管理人员可以实时监控、快速响应突发事件,并优化交通信号和指挥方案。这一系统不仅提高了道路安全性和车辆通行效率࿰…...

Golang发送POST请求并传递JSON数据
客户端 package mainimport ("c02_get_param/common""fmt""zdpgo_resty" )func main() {// Create a Resty Clientclient : zdpgo_resty.New()// 设置字符串resp, err : client.R().SetHeader("Content-Type", "application/jso…...

C++实现生产者消费者模型
生产者-消费者模型是一种典型的多线程并发模式,常用于在一个共享缓冲区中协调生产者和消费者之间的数据传递。在C中,我们可以使用标准库中的线程、互斥量和条件变量来实现该模型。以下是一个简单的生产者-消费者模型的实现示例: #include &l…...

【Mac】MWeb Pro(好用的markdown编辑器) v4.5.9中文版安装教程
软件介绍 MWeb Pro for Mac是一款Mac上的Markdown编辑器软件,它支持实时预览,语法高亮,自动保存和备份等功能,并且有多种主题和样式可供选择。此外,MWeb还支持多种导出格式,包括HTML、PDF、Word、ePub等&a…...

FPGA设计实战:别再乱用复位了!同步、异步与异步复位同步释放的Verilog代码避坑指南
FPGA设计实战:复位电路设计的黄金法则与Verilog避坑指南 在FPGA开发的世界里,复位电路就像交响乐团的指挥——它决定了整个系统能否从混沌走向有序。许多工程师往往低估了复位设计的重要性,直到项目后期遭遇难以追踪的亚稳态问题或时序收敛失…...
)
告别Keil破解!用STM32CubeIDE + HAL库点亮你的第一颗Blue Pill LED(保姆级图文)
从Keil到STM32CubeIDE:零成本玩转Blue Pill开发板 第一次接触STM32开发时,我被Keil的破解流程劝退了——注册机、license管理、版本兼容性问题接踵而至。直到发现STM32CubeIDE这款完全免费的官方工具,配合HAL库的抽象层设计,终于能…...

PotPlayer百度翻译插件终极指南:免费实现20+语言实时字幕翻译
PotPlayer百度翻译插件终极指南:免费实现20语言实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer字幕…...

量子化学计算中的自旋适应算符与费米子激发算符
1. 量子化学计算中的自旋适应算符基础在量子化学模拟领域,保持电子波函数的自旋对称性是一个根本性挑战。传统计算方法中,我们使用Slater行列式来表示多电子波函数,这种方法虽然直观,但无法保证波函数是总自旋算符Ŝ的本征态。自旋…...

从理论到实践:用Magma解锁代数计算新维度
1. 为什么你需要Magma这个代数计算神器 第一次接触Magma是在研究生时期,当时我需要计算一个椭圆曲线上的有理点。用Matlab折腾了整整一周毫无进展,导师随手扔给我一个Magma代码示例,三行命令就解决了问题。那一刻我才明白,专业的事…...

Unity Timeline实战:除了过场动画,你的Signal Track和Control Track用对了吗?
Unity Timeline实战:Signal Track与Control Track的高级应用指南 在Unity开发者的工具箱中,Timeline常被视为制作过场动画的专属工具。但当我们深入挖掘其潜力时,会发现它实际上是一个强大的游戏逻辑编排系统。本文将带您突破基础应用&#x…...

保姆级教程:用QGIS的SRTM-Downloader插件,5分钟搞定中国区域地形图下载与渲染
5分钟极速出图:QGIS地形图制作全流程实战指南 当你在凌晨三点赶制项目报告,或是课程作业截止前两小时突然需要一张专业地形图时,传统GIS软件的复杂操作流程往往让人抓狂。本文将带你用QGIS的SRTM-Downloader插件,像点外卖一样简单…...

操作插件方法
事件触发时机事务状态适用场景beforeExecuteOperationTransaction操作校验通过后,开启事务之前事务未开启✅ 修改源单据关联的其他单据beginOperationTransaction开启事务后,提交数据库之前事务已开启修改当前操作的单据自身数据...

嵌入式软件定时器原理与实现:从硬件限制到多任务调度
1. 软件定时器:从硬件限制到软件自由的桥梁在嵌入式开发里,定时器是个绕不开的话题。无论是让LED灯定时闪烁,还是需要周期性地采集传感器数据,甚至是实现一个简单的按键消抖,都离不开定时功能。硬件定时器(…...
)
【JavaSE全面教学】Java集合框架下Day13(2026年)
写在前面:这是JavaSE系列的第13篇。上一篇讲了List家族,今天来讲Set和Map。HashMap是面试中问得最多的集合类,底层原理必须搞懂。建议收藏,反复看。 文章目录 一、Set集合:不可重复1.1 Set的特点1.2 HashSet1.3 Linked…...