数据结构(十)图
文章目录
- 图的简介
- 图的定义
- 图的结构
- 图的分类
- 无向图
- 有向图
- 带权图(Wighted Graph)
- 图的存储
- 邻接矩阵(Adjacency Matrix)
- 邻接表
- 代码实现
- 图的遍历
- 深度优先搜索(DFS,Depth Fisrt Search)
- 遍历抖索过程
- 广度优先搜索(BFS,Breadth First Search)
- 遍历搜索过程
- 完整代码
图的简介
图的定义
图(Graph)一种比线性表和树更加复杂的结构。在图形结构中,顶点(vertex)之间的关系是任意的,途中任意两个顶点之间都有可能关联。
图的结构

- 顶点(vertex):图中的元素,就叫做顶点。如图:ABCDEF。
- 边(edge): 顶点之间建立的连接关系,就叫做边。如图:顶点A和顶点B中间的连线。
- 度(drgree): 跟顶点相连的边的条数,就叫做度。如图:顶点A与B、C、D相连,则A的度就是3。
图的分类
无向图
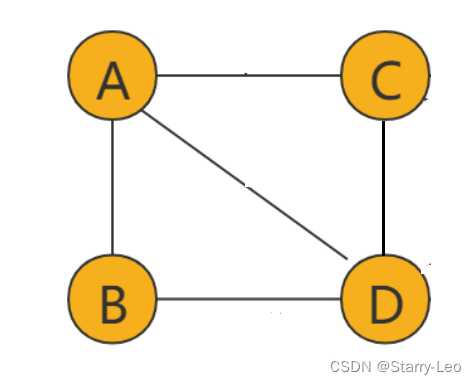
如上图,边(edge)没有方向的图叫做无向图。
有向图
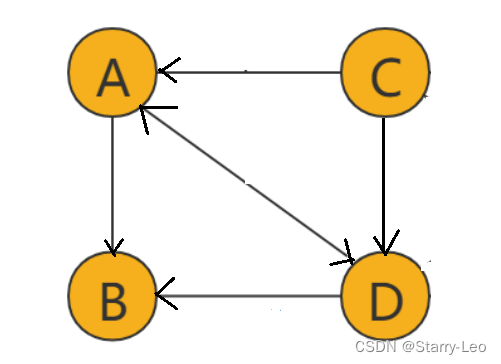
如上图,边(edge)有方向的图叫做有向图。
带权图(Wighted Graph)
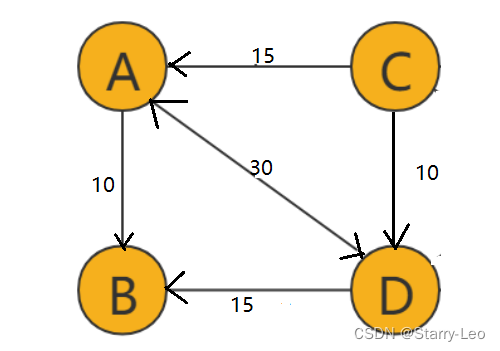
如上图中,每条边都带有一个权重(weight)的图,就是带权图。
图的存储
邻接矩阵(Adjacency Matrix)
邻接矩阵的底层是一个二维数组,如下图,该图可以转化为一个二维数据表格。
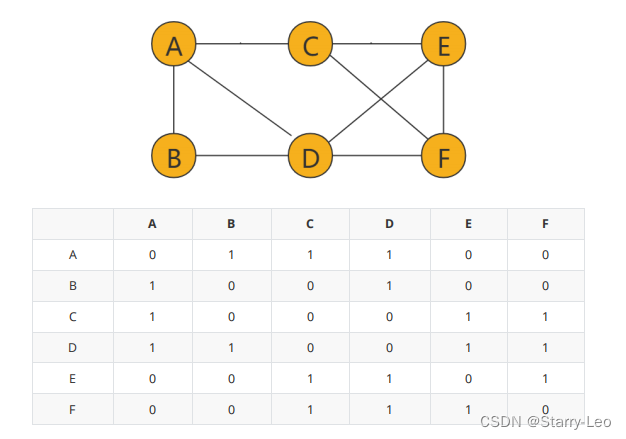
- 无向图
如果顶点 i 和顶点 j 之间有边但是没有方向和权重,那么我们就用array[i][j] = array[j][i] = 1,来表示无向图。
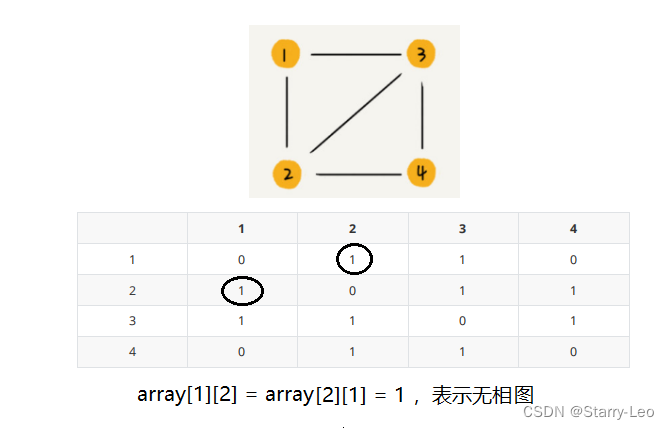
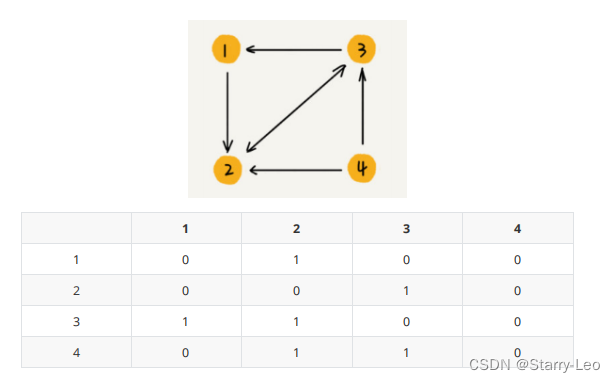
- 有向图
如果顶点 i 到顶点 j 之间,有一条箭头从顶点 i 指向顶点 j 的边,那我们就将 A[i][j]标记为 1。同理,如果有一条箭头从顶点 j 指向顶点 i 的边,我们就将 A[j][i]标记为 1。
- 带权图
数组中就存储相应值当作权重。
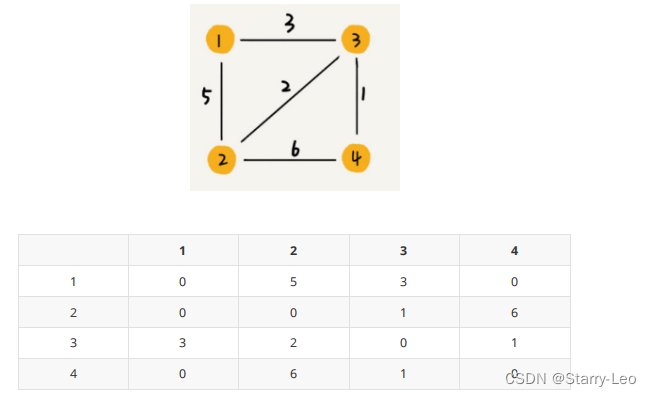
邻接表
邻接表中每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。

图中的一个有向图的邻接表的存储方式,前面的数组存储的是所有的顶点,每个顶点后面链接的块代表:前面顶点所指向的顶线和边的权值。如果该点还有其它顶点,则继续在块后面添加即可。
代码实现
定点(Vertex)类:
package com.xxliao.datastructure.graph;/*** @author xxliao* @description: 图 - 定点类* @date 2024/5/29 16:56*/
public class Vertex {// 顶点名称protected String name;// 该顶点出发的边protected Edge edge;public Vertex(String name, Edge edge) {this.name = name;this.edge = edge;}
}
边(Edge)类:
package com.xxliao.datastructure.graph;/*** @author xxliao* @description: 图 - 边类* @date 2024/5/29 16:57*/
public class Edge {// 被指向的顶点protected String name;// 权重protected int weight;// 顶点的下一条边protected Edge next;public Edge(String name, int weight, Edge next) {this.name = name;this.weight = weight;this.next = next;}
}图(Graph)类:
package com.xxliao.datastructure.graph;import java.util.HashMap;
import java.util.List;
import java.util.Map;/*** @author xxliao* @description: 邻接表实现图* @date 2024/5/29 16:00*/
public class Graph {// 存储顶点容器private Map<String,Vertex> vertexes;public Graph() {this.vertexes = new HashMap<String,Vertex>();}/*** @description 添加顶点* @author xxliao* @date 2024/5/29 17:02*/public void addVertex(String vertexName) {vertexes.put(vertexName,new Vertex(vertexName,null));}/*** @description 添加边* @author xxliao* @date 2024/5/29 17:05*/public void addEdge(String beginVertexName,String endVertexName,int weight) {// 获取出发顶点Vertex beginVertex = vertexes.get(beginVertexName);if(beginVertex == null) {// 没有开始顶点,创建beginVertex = new Vertex(beginVertexName,null);vertexes.put(beginVertexName,beginVertex);}// 创建边对象Edge edge = new Edge(endVertexName,weight,null);if(beginVertex.edge == null) {//当前顶点还没有边,直接设置beginVertex.edge = edge;}else {Edge lastEdge = beginVertex.edge;while(lastEdge.next != null) {lastEdge = lastEdge.next;}// 设置到末尾lastEdge.next = edge;}}
}
图的遍历
图的遍历是指,从给定图的任意顶点(可以称为初始顶点)出发,按照某种搜索方法沿着图边访问所有的顶点,且每个顶点仅被访问一次,这个过程就是图的遍历。图的遍历根据搜索过程不用,可以分为深度优先搜索和广度优先搜索。
深度优先搜索(DFS,Depth Fisrt Search)
深度优先搜索,从起点出发,从规定的方向中选择一个方向,不段的往前走,直到无法继续位置,然后尝试另外一个方向,直到最后走完所有顶点。
遍历抖索过程
假设我们有这么一个图,里面有A、B、C、D、E、F、G、H 8 个顶点,点和点之间的联系如下图所示:
 必须依赖栈(Stack),特点是后进先出(LIFO)。
必须依赖栈(Stack),特点是后进先出(LIFO)。
-
第一步,选择一个起始顶点,例如从顶点 A 开始。把 A 压入栈,标记它为访问过(用红色标记),并输出到结果中。

-
第二步,寻找与 A 相连并且还没有被访问过的顶点,顶点 A 与 B、D、G 相连,而且它们都还没有被访问过,我们按照字母顺序处理,所以将 B 压入栈,标记它为访问过,并输出到结果中。
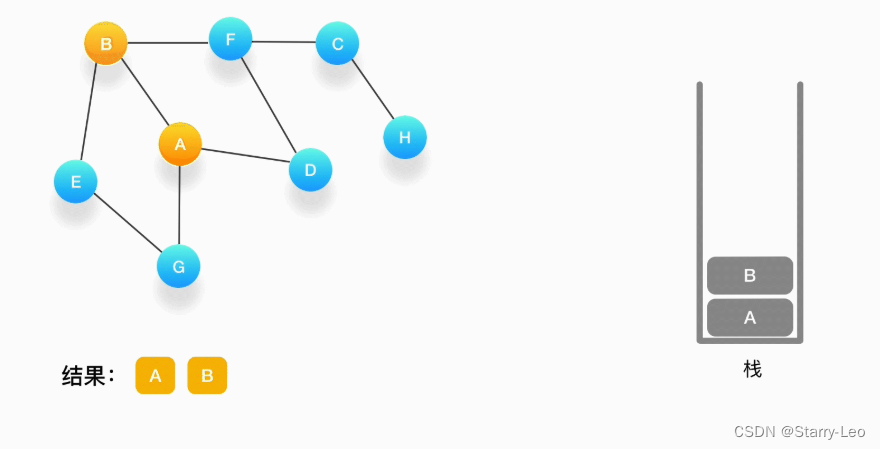
-
第三步,现在我们在顶点 B 上,重复上面的操作,由于 B 与 A、E、F 相连,如果按照字母顺序处理的话,A 应该是要被访问的,但是 A 已经被访问了,所以我们访问顶点 E,将 E 压入栈,标记它为访问过,并输出到结果中。
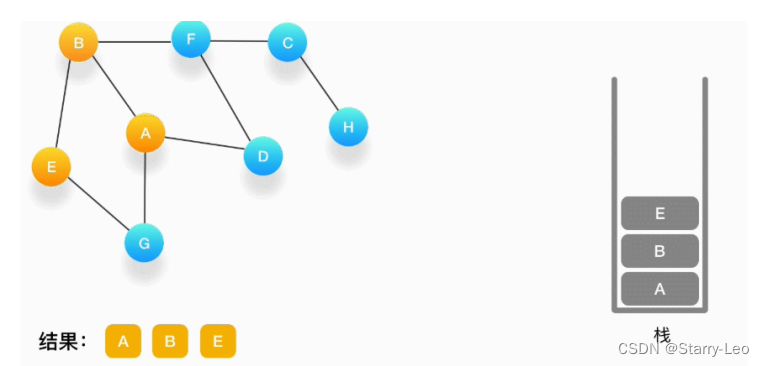
-
第四步,从 E 开始,E 与 B、G 相连,但是B刚刚被访问过了,所以下一个被访问的将是G,把G压入栈,标记它为访问过,并输出到结果中。
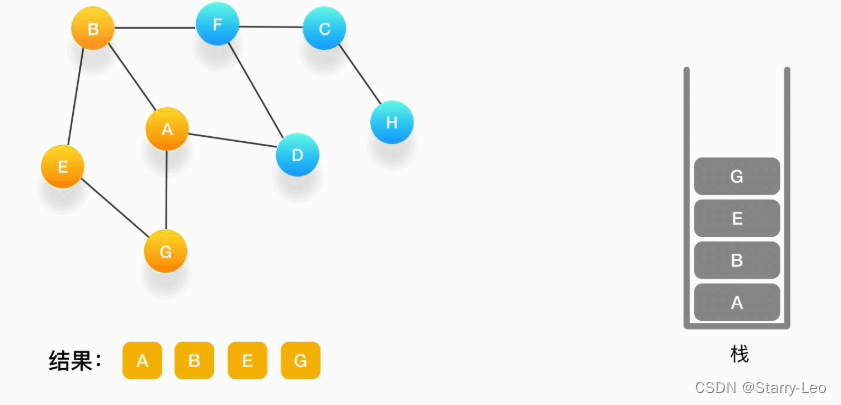
-
第五步,现在我们在顶点 G 的位置,由于与 G 相连的顶点都被访问过了,类似于我们走到了一个死胡同,必须尝试其他的路口了。所以我们这里要做的就是简单地将 G 从栈里弹出,表示我们从 G 这里已经无法继续走下去了,看看能不能从前一个路口找到出路。
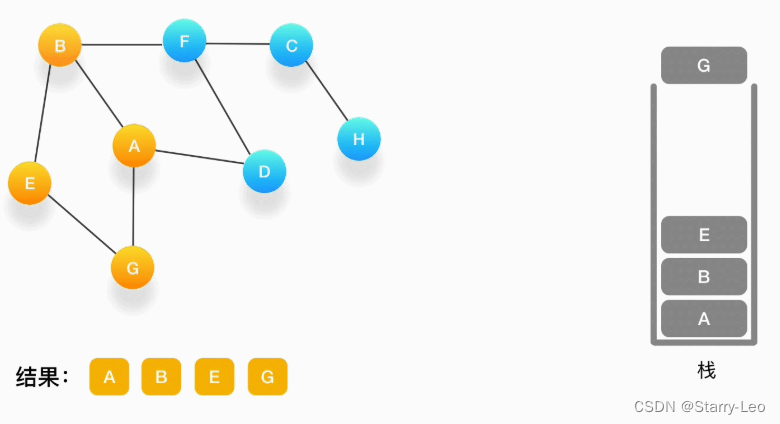 如果发现周围的顶点都被访问了,就把当前的顶点弹出。
如果发现周围的顶点都被访问了,就把当前的顶点弹出。 -
第六步,现在栈的顶部记录的是顶点 E,我们来看看与 E 相连的顶点中有没有还没被访问到的,发现它们都被访问了,所以把 E 也弹出去。
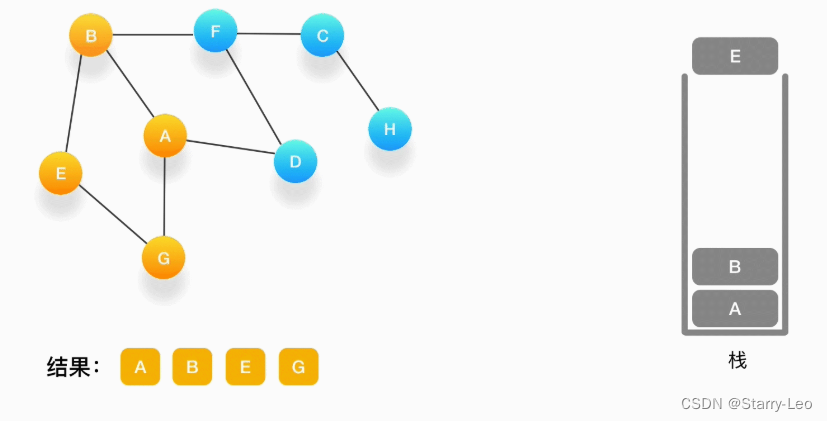
-
第七步,当前栈的顶点是 B,看看它周围有没有还没被访问的顶点,有,是顶点 F,于是把 F 压入栈,标记它为访问过,并输出到结果中。
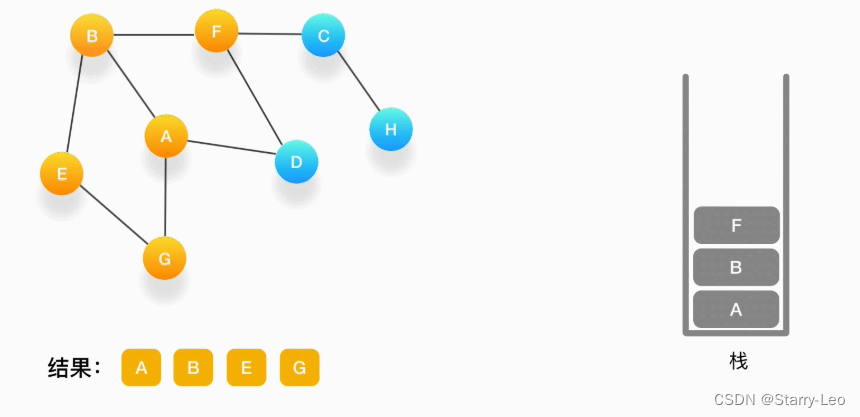
-
第八步,当前顶点是 F,与 F 相连并且还未被访问到的点是 C 和 D,按照字母顺序来,下一个被访问的点是 C,将 C 压入栈,标记为访问过,输出到结果中。
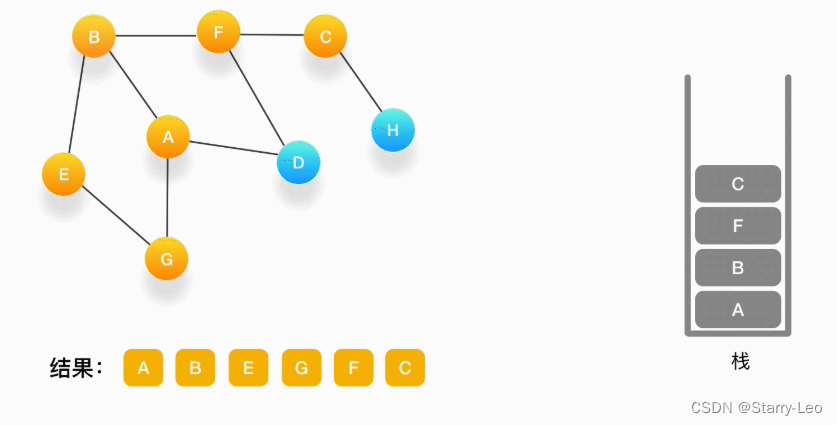
-
第九步,当前顶点为 C,与 C 相连并尚未被访问到的顶点是 H,将 H 压入栈,标记为访问过,输出到结果中。
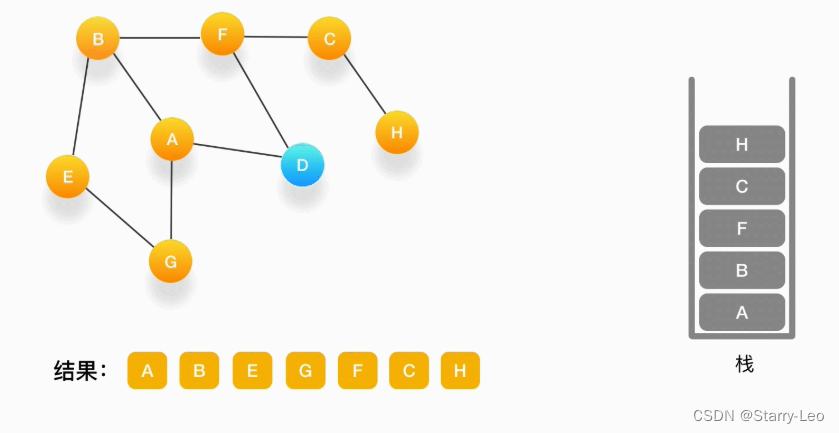
-
第十步,当前顶点是 H,由于和它相连的点都被访问过了,将它弹出栈。
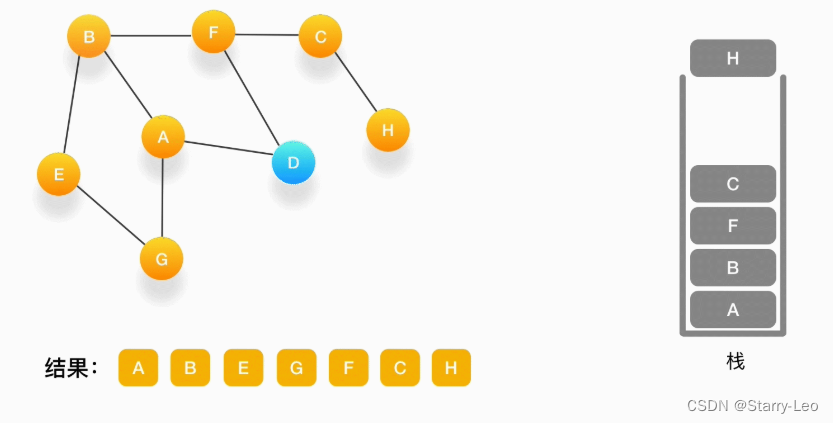
-
第十一步,当前顶点是 C,与 C 相连的点都被访问过了,将 C 弹出栈。
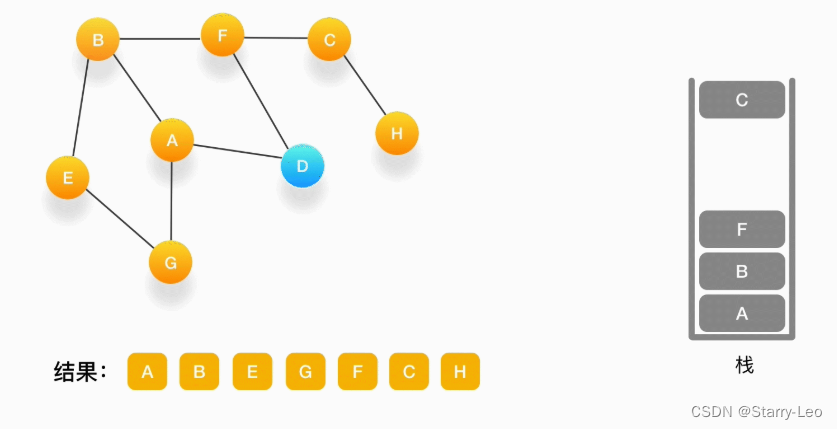
-
第十二步,当前顶点是 F,与 F 相连的并且尚未访问的点是 D,将 D 压入栈,输出到结果中,并标记为访问过。
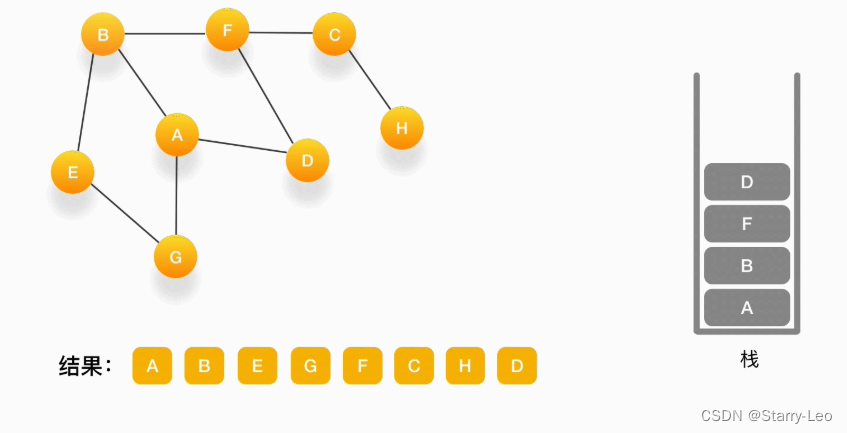
-
第十三步,当前顶点是 D,与它相连的点都被访问过了,将它弹出栈。以此类推,顶点 F,B,A 的邻居都被访问过了,将它们依次弹出栈就好了。最后,当栈里已经没有顶点需要处理了,我们的整个遍历结束。
广度优先搜索(BFS,Breadth First Search)
遍历搜索过程
假设我们有这么一个图,里面有A、B、C、D、E、F、G、H 8 个顶点,点和点之间的联系如下图所示,
对这个图进行深度优先的遍历。
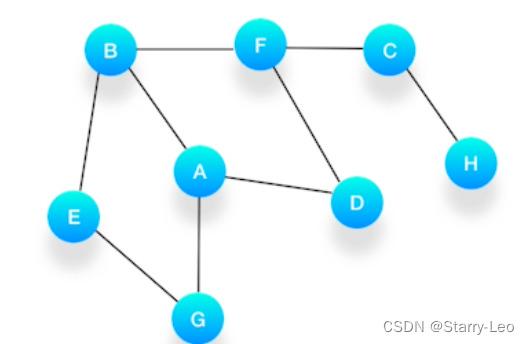
依赖队列(Queue),先进先出(FIFO)。
一层一层地把与某个点相连的点放入队列中,处理节点的时候正好按照它们进入队列的顺序进行。
- 第一步,选择一个起始顶点,让我们从顶点 A 开始。把 A 压入队列,标记它为访问过(用红色标记)。
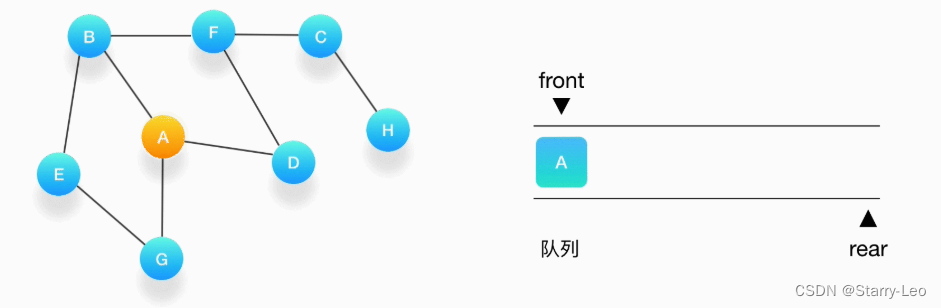
- 第二步,从队列的头取出顶点 A,打印输出到结果中,同时将与它相连的尚未被访问过的点按照字母大
小顺序压入队列,同时把它们都标记为访问过,防止它们被重复地添加到队列中。
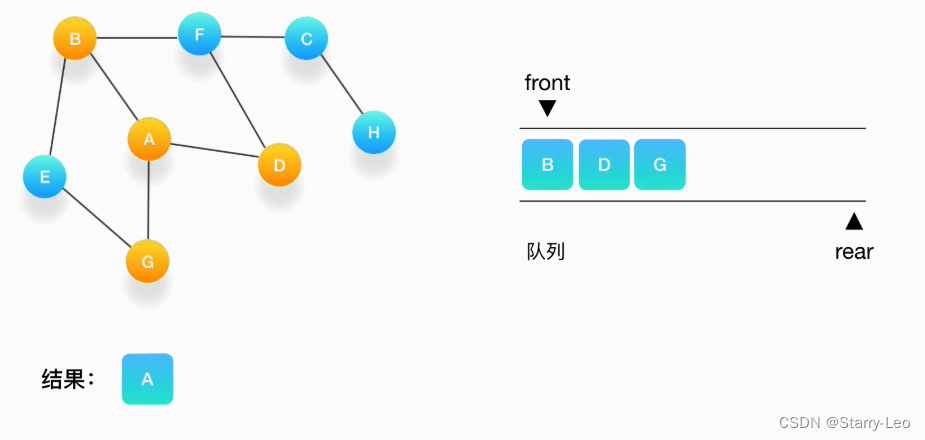
- 第三步,从队列的头取出顶点 B,打印输出它,同时将与它相连的尚未被访问过的点(也就是 E 和 F)
压入队列,同时把它们都标记为访问过。

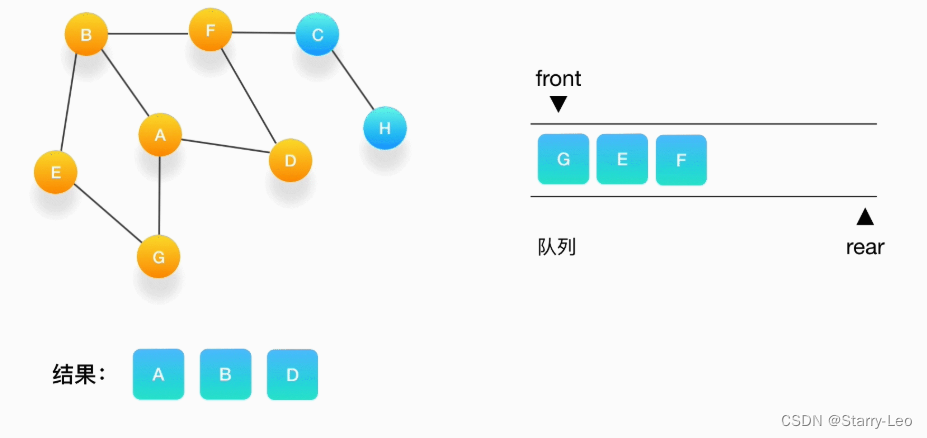
- 第四步,继续从队列的头取出顶点 D,打印输出它,此时我们发现,与 D 相连的顶点 A 和 F 都被标记
访问过了,所以就不要把它们压入队列里。
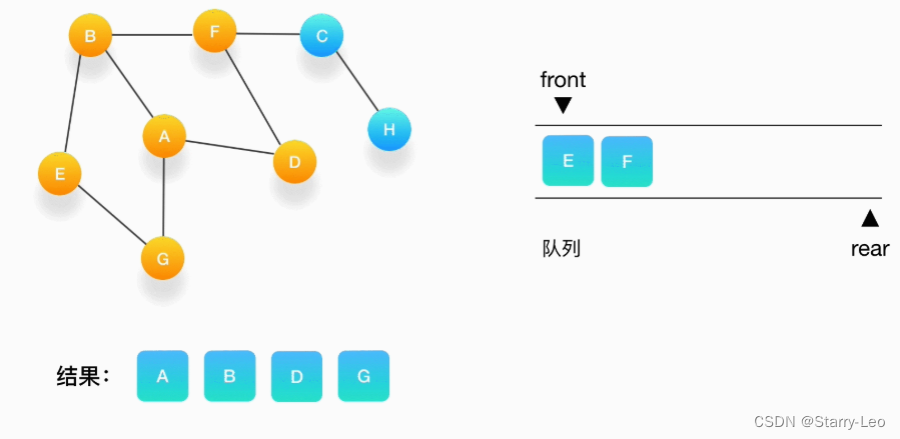
- 第五步,接下来,队列的头是顶点 G,打印输出它,同样的,G 周围的点都被标记访问过了。我们不做
任何处理。
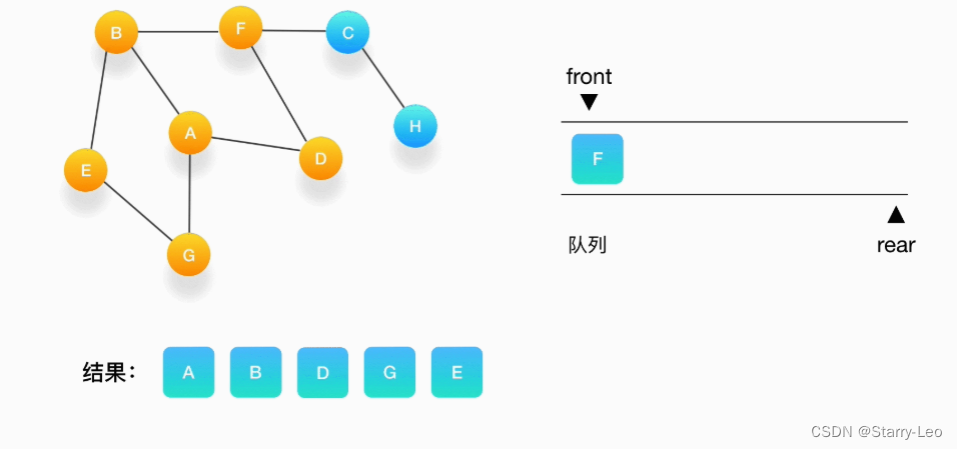
- 第六步,队列的头是 E,打印输出它,它周围的点也都被标记为访问过了,我们不做任何处理。
- 第七步,接下来轮到顶点 F,打印输出它,将 C 压入队列,并标记 C 为访问过。
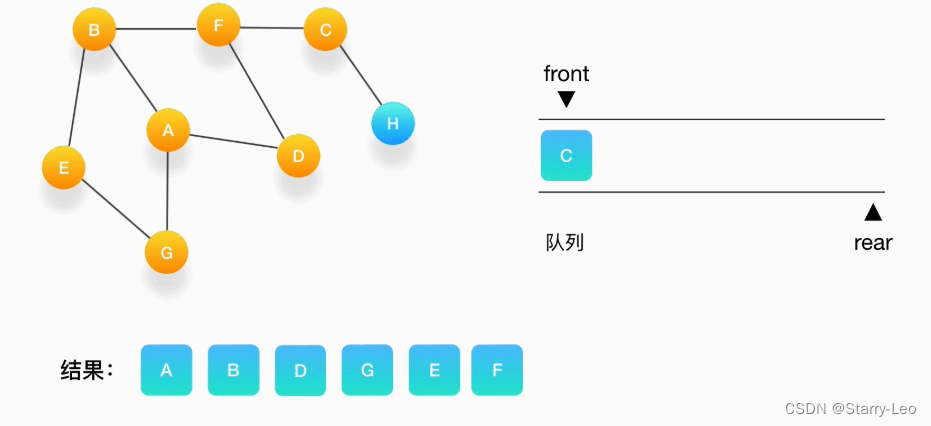
- 第八步,将 C 从队列中移出,打印输出它,与它相连的 H 还没被访问到,将 H 压入队列,将它标记为
访问过。

9.第九步,队列里只剩下 H 了,将它移出,打印输出它,发现它的邻居都被访问过了,不做任何事情。
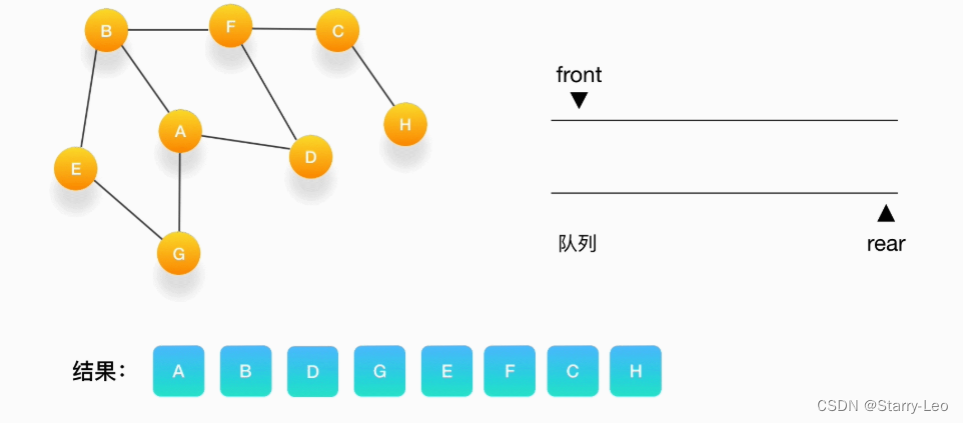
- 第十步,队列为空,表示所有的点都被处理完毕了,程序结束。
完整代码
https://github.com/xxliao100/datastructure_algorithms.git
相关文章:
数据结构(十)图
文章目录 图的简介图的定义图的结构图的分类无向图有向图带权图(Wighted Graph) 图的存储邻接矩阵(Adjacency Matrix)邻接表代码实现 图的遍历深度优先搜索(DFS,Depth Fisrt Search)遍历抖索过程…...

四数之和-力扣
本题在三数之和的基础上,再增加一重循环进行解答 首先注意的点是,一级剪枝处理,target > 0 && nums[i] > target 此处只有整数才可剪枝处理,如果target为负数,nums[i] < target,也不能代…...
JS 中怎么删除数组元素?有哪几种方法?
正文开始之前推荐一位宝藏博主免费分享的学习教程,学起来! 编号学习链接1Cesium: 保姆级教程+源码示例2openlayers: 保姆级教程+源码示例3Leaflet: 保姆级教程+源码示例4MapboxGL: 保姆级教程+源码示例splice() JavaScript中的splice()方法是一个内置的数组对象函数, 用于…...

Git如何将pre-commit也提交到仓库
我一开始准备将pre-commit提交到仓库进行备份的,但是却发现提交不了,即使我使用强制提交都不行。 (main) $ git add ./.git/hooks/pre-commit(main) $ git status On branch main nothing to commit, working tree clean# 强制提交(main) $ git add -f .…...

vmware中Ubuntu虚拟机和本地电脑Win10互相ping通
初始状态 使用vmware17版本安装的Ubuntu的20版本,安装之后什么配置都要不懂,然后进行下述配置。 初始的时候是NAT,没动的. 设置 点击右键编辑“属性” 常规选择“启用”: 高级选择全部: 打开网络配置,右键属…...

比较含退格的字符串-力扣
做这道题时出现了许多问题 第一次做题思路是使用双指针去解决,快慢指针遇到字母则前进,遇到 # 则慢指针退1,最开始并未考虑到 slowindex < 0 ,从而导致越界。第二个问题在于,在最后判断两个字符串是否相同时,最初使…...

NSSCTF-Web题目4
[SWPUCTF 2021 新生赛]hardrce 1、题目 2、知识点 rce:远程代码执行、url取反编码 3、解题思路 打开题目 出现一段代码,审计源代码 题目需要我们通过get方式输入变量wllm的值 但是变量的值被过滤了,不能输入字母和\t、\n等值 所以我们需…...

7. CSS 网格布局
CSS3引入了强大的网格布局(Grid Layout),它提供了一种二维的布局方式,使得创建复杂的网页布局变得更加简单和直观。通过定义行和列,我们可以精确控制网页元素的排列和对齐。本章将详细介绍网格布局的基本概念和属性&am…...

如何配置才能连接远程服务器上的 redis server ?
文章目录 Intro修改点 Intro 以阿里云服为例。 首先,我在我买的阿里云服务器中以下载源码、手动编译的方式安装了 redis-server,操作流程见:Ubuntu redis 下载解压配置使用及密码管理 && 包管理工具联网安装。 接着,我…...
MindSpore实践图神经网络之环境篇
MindSpore在Windows11系统下的环境配置。 MindSpore环境配置大概分为三步:(1)安装Python环境,(2)安装MindSpore,(3)验证是否成功 如果是GPU环境还需安装CUDA等环境&…...

MVS net笔记和理解
文章目录 传统的方法有什么缺陷吗?MVSnet深度的预估 传统的方法有什么缺陷吗? 传统的mvs算法它对图像的光照要求相对较高,但是在实际中要保证照片的光照效果很好是很难的。所以传统算法对镜面反射,白墙这种的重建效果就比较差。 …...
)
Linux 编译屏障之 ACCESS_ONCE()
文章目录 1. 前言2. 背景3. 为什么要有 ACCESS_ONCE() ?4. ACCESS_ONCE() 代码实现5. ACCESS_ONCE() 实例分析6. ACCESS() 的演进7. 结语8. 参考资料 1. 前言 限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做…...

Discuz!X3.4论坛网站公安备案号怎样放到网站底部?
Discuz!网站的工信部备案号都知道在后台——全局——站点信息——网站备案信息代码填写,那公安备案号要添加在哪里呢?并没有看到公安备案号填写栏,今天驰网飞飞和你分享 1)工信部备案号和公安备案号统一填写到网站备案…...

LPDDR6带宽预计将翻倍增长:应对低功耗挑战与AI时代能源需求激增
在当前科技发展的背景下,低能耗问题成为了业界关注的焦点。国际能源署(IEA)近期报告显示,日常的数字活动对电力消耗产生显著影响——每次Google搜索平均消耗0.3瓦时(Wh),而向OpenAI的ChatGPT提出的每一次请求则消耗2.9…...

云原生架构内涵_3.主要架构模式
云原生架构有非常多的架构模式,这里列举一些对应用收益更大的主要架构模式,如服务化架构模式、Mesh化架构模式、Serverless模式、存储计算分离模式、分布式事务模式、可观测架构、事件驱动架构等。 1.服务化架构模式 服务化架构是云时代构建云原生应用的…...

宏基因组分析流程(Metagenomic workflow)202405|持续更新
Logs 增加R包pctax内的一些帮助上游分析的小脚本(2024.03.03)增加Mmseqs2用于去冗余,基因聚类的速度非常快,且随序列量线性增长(2024.03.12)更新全文细节(2024.05.29) 注意&#x…...
)
一千题,No.0037(组个最小数)
给定数字 0-9 各若干个。你可以以任意顺序排列这些数字,但必须全部使用。目标是使得最后得到的数尽可能小(注意 0 不能做首位)。例如:给定两个 0,两个 1,三个 5,一个 8,我们得到的最…...

PV PVC
默写 1 如何将pod创建在指定的Node节点上 node亲和、pod亲和、pod反亲和: 调度策略 匹配标签 操作符 nodeAffinity 主机 In,NotIn,Exists,DoesNotExist,Gt,Lt podAffinity …...

深入理解Nginx配置文件:全面指南
Nginx 是一个高性能的 HTTP 服务器和反向代理服务器,也是一个电子邮件(IMAP/POP3)代理服务器。由于其高效性和灵活性,Nginx 被广泛应用于各种 web 服务中。本文将详细介绍 Nginx 配置文件的结构和主要配置项,帮助你深入…...

【传知代码】自监督高效图像去噪(论文复现)
前言:在数字化时代,图像已成为我们生活、工作和学习的重要组成部分。然而,随着图像获取方式的多样化,图像质量问题也逐渐凸显出来。噪声,作为影响图像质量的关键因素之一,不仅会降低图像的视觉效果…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

Caliper 配置文件解析:fisco-bcos.json
config.yaml 文件 config.yaml 是 Caliper 的主配置文件,通常包含以下内容: test:name: fisco-bcos-test # 测试名称description: Performance test of FISCO-BCOS # 测试描述workers:type: local # 工作进程类型number: 5 # 工作进程数量monitor:type: - docker- pro…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...
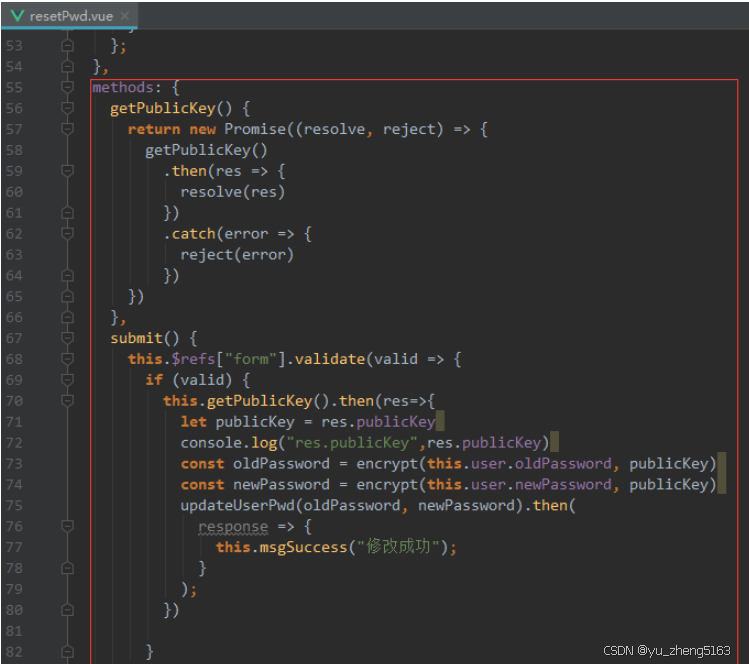
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...

AD学习(3)
1 PCB封装元素组成及简单的PCB封装创建 封装的组成部分: (1)PCB焊盘:表层的铜 ,top层的铜 (2)管脚序号:用来关联原理图中的管脚的序号,原理图的序号需要和PCB封装一一…...