【知识拓展】机器学习基础(一):什么是预处理对象、模型对象 、pipeline、Tokenizer
前言
公司业务需要一套可离线部署的检索增强生成(RAG)大模型知识库,于是最近花了一周时间了解了AI相关的技术。除了查阅各类高质量技术博客,也自行动手进行了一些demo样例。其中包括huggingface、modelscope等平台,虽能使用,但疑惑还是不少,仅在此记录一些学习中的过程和问题,以便日后自我查阅。
几个关键的概念
对于机器学习方面的初学者来说,预处理对象、模型对象和 pipeline 是经常见到的,尤其是写过一些demo,它们在数据处理、模型训练和预测等过程中起着重要作用。很多时候官方概念可能难以理解,以下是个人经过查阅资料后,解释这些概念及其作用。
下面会根据部分Demo代码案例说明。
预处理对象
对原始数据进行处理和转换的工具或方法,以便将数据转换为适合模型输入的格式。简单的说就是对数据进行预处理,处理成模型所需要的输入格式,例如将文本转化为输入 ID 和其他必要的张量。常见的一些预处理如下:
- 数据清理:处理缺失值、去除噪声、纠正数据错误等。
- 特征工程:生成、选择和转换特征,如标准化、归一化、特征缩放等。
- 数据增强:特别是对于图像数据,可能包括旋转、裁剪、翻转等操作。
- 编码:将分类变量转换为数值形式(如独热编码)。
- 拆分数据:将数据集分为训练集、验证集和测试集。
示例一(使用scikit-learn的预处理对象)
from sklearn.preprocessing import StandardScaler
# 创建预处理对象
scaler = StandardScaler()# 适配数据并进行转换
X_train_scaled = scaler.fit_transform(X_train)
模型对象
模型对象是由特定的算法和参数组成,经过训练后能够进行预测或分类。模型对象通常包括以下部分:
- 结构:模型的架构,例如线性回归、决策树、神经网络等。
- 参数:模型的可调参数,通过训练数据进行学习和优化。
- 训练方法:用于优化模型参数的方法,例如梯度下降。
示例一(使用scikit-learn的模型对象)
接上述示例一
from sklearn.linear_model import LogisticRegression
# 创建模型对象
model = LogisticRegression()# 训练模型
model.fit(X_train_scaled, y_train)
Pipeline
将多个数据处理步骤和模型训练步骤串联起来,以便简化和自动化整个工作流程。它将数据预处理和模型训练过程结合在一起,使得整个过程可以作为一个单独的工作流来处理。简单的说就是将多个步骤封装在一起,使用者无需关注细节,一个高级API。
一个完整的pipeline一般包括了数据的前处理、模型的前向推理、数据的后处理三个过程。
示例一(使用 scikit-learn)
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression# 创建 pipeline 对象
pipeline = Pipeline([
('scaler', StandardScaler()),
('logistic_regression', LogisticRegression())
])# 训练 pipeline
pipeline.fit(X_train, y_train)
示例二:
pipeline 简化了整个处理过程,通过内部调用预处理、模型推理和后处理步骤,让用户能够方便地调用复杂的模型并得到结果。
from modelscope.pipelines import pipeline
# 创建 word segmentation pipeline
word_segmentation = pipeline('word-segmentation', model='damo/nlp_structbert_word-segmentation_chinese-base')# 输入字符串
input_str = '今天天气不错,适合出去游玩'# 输出分词结果
print(word_segmentation(input_str))
Tokenizer
标记器,自然语言处理(NLP)中的一个关键工具,用于将文本数据转换为模型可以处理的格式。具体来说,Tokenizer 将输入的文本字符串分割成更小的单元(通常是单词或子词),然后将这些单元映射到整数 ID。这些整数 ID 作为输入传递给机器学习模型。简单的说,用来作为数据细化处理到最小单元token(标记)。主要功能如下:
分词(Tokenization): 将文本分割成更小的单元,如单词或子词。例如,句子“Hello, how are you?” 可以被分割成 ["Hello", ",", "how", "are", "you", "?"]。
映射到 ID(Token to ID Mapping): 将每个 token 映射到一个唯一的整数 ID。这个映射通常基于一个预定义的词汇表。例如,"Hello" 可能被映射为 123,"how" 可能被映射为 456。
添加特殊标记(Special Tokens): 对于一些模型,需要在输入序列的开头和结尾添加特殊标记。例如,在 BERT 模型中,句子的开头和结尾分别添加
[CLS]和[SEP]标记。生成注意力掩码(Attention Mask): 创建一个掩码,指示哪些 token 是实际输入,哪些是填充部分(padding)。填充部分是为了使输入序列达到固定长度。
解码(Decoding): 将整数 ID 序列转换回原始文本或接近原始文本的形式。这在生成任务中非常重要,如文本生成或翻译。
示例一(使用 Hugging Face 的 AutoTokenizer 进行分词和编码)
from transformers import AutoTokenizer
# 指定模型名称
model_name = 'bert-base-uncased'# 自动加载对应的标记器
tokenizer = AutoTokenizer.from_pretrained(model_name)# 输入文本
input_text = "Hello, how are you?"# 分词和编码
encoded_input = tokenizer(input_text, return_tensors='pt')print(encoded_input)
# 输出:
# {'input_ids': tensor([[ 101, 7592, 1010, 2129, 2024, 2017, 1029, 102]]),
# 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0]]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}
示例二(使用BERT 模型的BertTokenizer将输入文本处理成模型可以接受的格式)
from transformers import BertModel, BertTokenizer
model_name = 'bert-base-uncased'
model = BertModel.from_pretrained(model_name)
tokenizer = BertTokenizer.from_pretrained(model_name)input_text = "Hello, how are you?"
inputs = tokenizer(input_text, return_tensors="pt")print(inputs)
# 输出:
# {'input_ids': tensor([[ 101, 7592, 1010, 2129, 2024, 2017, 1029, 102]]),
# 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0]]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}outputs = model(**inputs)
print(outputs)
BertTokenizer和AutoTokenizer区别
BertTokenizer是专门为 BERT(Bidirectional Encoder Representations from Transformers)模型设计的标记器。
AutoTokenizer是一个通用的标记器加载器,能够根据模型名称自动选择合适的标记器。
示例(pipeline传入自定义预处理对象、模型对象)
from modelscope.pipelines import pipeline
from modelscope.models import Model
from modelscope.preprocessors import Preprocessor# 定义自定义预处理对象
class CustomPreprocessor(Preprocessor):
def __init__(self):
super().__init__()
def __call__(self, text):
# 简单的预处理逻辑:转小写并去除标点符号
import re
text = text.lower()
text = re.sub(r'[^\w\s]', '', text)
return {'text': text}# 加载预训练模型
model = Model.from_pretrained('damo/nlp_structbert_sentiment-classification_chinese-base')# 创建自定义预处理对象实例
custom_preprocessor = CustomPreprocessor()# 创建 pipeline,传入自定义预处理对象和模型对象
text_classification_pipeline = pipeline(
task='text-classification',
model=model,
preprocessor=custom_preprocessor
)# 输入文本
input_text = "今天的天气真好!"# 进行预测
result = text_classification_pipeline(input_text)
print(result)
分析:
自定义预处理对象:
- 我们定义了一个
CustomPreprocessor类,继承自Preprocessor。- 在
__call__方法中,实现了简单的文本预处理逻辑:将文本转换为小写并去除标点符号。加载预训练模型:
- 使用
Model.from_pretrained方法加载 ModelScope 提供的预训练模型damo/nlp_structbert_sentiment-classification_chinese-base。创建
pipeline并传入自定义组件:
- 使用
pipeline函数创建一个文本分类的 pipeline。- 将自定义的预处理对象
custom_preprocessor和预训练模型对象model作为参数传入pipeline。进行预测:
- 输入文本
input_text通过text_classification_pipeline进行处理和预测,得到结果。
Preprocessor.from_pretrained方法
用来加载与模型相关的预处理对象。
from modelscope.models import Model
from modelscope.pipelines import pipeline
from modelscope.preprocessors import Preprocessor, TokenClassificationTransformersPreprocessor# 加载预训练模型
model = Model.from_pretrained('damo/nlp_structbert_word-segmentation_chinese-base')# 从模型目录中加载预处理器
tokenizer = Preprocessor.from_pretrained(model.model_dir)
# 或者直接调用构造函数创建预处理器对象
# tokenizer = TokenClassificationTransformersPreprocessor(model.model_dir)# 创建 pipeline,并传入模型和预处理器
word_segmentation = pipeline('word-segmentation', model=model, preprocessor=tokenizer)# 输入文本
input = '今天天气不错,适合出去游玩'# 进行分词处理
print(word_segmentation(input))
# 输出:{'output': ['今天', '天气', '不错', ',', '适合', '出去', '游玩']}
方法的作用
用于从指定的目录加载预处理器配置和相关资源。这个方法通常会:
- 读取配置文件:在模型目录中,通常有一个或多个配置文件(例如
config.json),其中包含了预处理器的配置参数。- 加载必要的资源:预处理器可能需要一些词汇表、词典、模型权重等文件,这些文件通常也存储在模型目录中。
- 初始化预处理器:根据读取的配置和加载的资源,初始化预处理器对象,使其可以执行预处理任务。
典型模型目录结构
根据以上,我们大致能推测出,模型目录中的文件结构应该会有一定标准,典型的结构如下。
model_directory/
│
├── config.json
├── preprocessor_config.json #预处理器配置文件(modelscope),包含预处理器的配置信息和参数设置。用于初始化预处理器对象。
├── vocab.txt #词汇表文件,包含模型使用的词汇列表。每行一个词汇,通常由预训练过程中使用的词汇表生成。
├── tokenizer_config.json #标记器配置文件,包含标记器的配置信息和参数设置。用于初始化标记器对象。
├── pytorch_model.bin
├── special_tokens_map.json #特殊标记映射文件,定义了特殊标记(如[CLS],[SEP],[PAD])的映射关系。
├── added_tokens.json #新增标记文件,包含训练过程中添加的额外标记及其映射关系。此文件并非所有模型目录中都存在,只有在训练过程中有新增标记时才会出现。
├── model_card.json #模型卡片文件(modelscope),包含模型的描述、用途、性能、训练数据等信息。用于提供模型的元数据和使用说明。
└── README.md
下面对主要文件进行说明:
config.json
模型配置文件,包含模型的架构信息和超参数设置。通常由模型的创建者生成,并包含模型的详细配置。
示例:
{
"hidden_size": 768,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"vocab_size": 30522
}
pytorch_model.bin
文件是模型的权重文件,是模型文件结构中最重要的部分之一。它包含了模型在训练过程中学习到的所有参数(如权重和偏差),这些参数决定了模型的行为和性能。这个文件通常比较大。
相关文章:
:什么是预处理对象、模型对象 、pipeline、Tokenizer)
【知识拓展】机器学习基础(一):什么是预处理对象、模型对象 、pipeline、Tokenizer
前言 公司业务需要一套可离线部署的检索增强生成(RAG)大模型知识库,于是最近花了一周时间了解了AI相关的技术。除了查阅各类高质量技术博客,也自行动手进行了一些demo样例。其中包括huggingface、modelscope等平台,虽能使用,但疑惑…...

Linux dig 命令
dig 命令是一个用于在 Unix/Linux 操作系统中执行 DNS 查询的工具。它是 DNS 客户端,通常用于查询 DNS 服务器的信息,如域名解析、IP 地址查询等。 博主博客 https://blog.uso6.comhttps://blog.csdn.net/dxk539687357 一、常见 DNS 记录类型 类型描述…...

后台接口返回void有设置response相关内容,前端通过open打开接口下载excel文件
1、引入依赖,用来生成excel <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>2.1.2</version></dependency> 2、接口类代码如下: /*** 企业列表--导出*/Api…...

scp问题:Permission denied, please try again.
我把scp归纳三种情况: 源端root——》目标端root 源端root——》目标端mysql(任意)用户 源端(任意用户)——》目标端root用户 在scp传输文件的时候需要指导目标端的用户密码,如root用户密码、mysql用户…...

new CCDIKSolver( OOI.kira, iks ); // 创建逆运动学求解器
demo案例 new CCDIKSolver(OOI.kira, iks); 在使用某个特定的库或框架来创建一个逆运动学(Inverse Kinematics, IK)求解器实例。逆运动学在机器人学、动画和计算机图形学等领域中非常重要,它用于根据期望的末端执行器(如机器人的…...

【Go】Swagger v2 转 OpenApi v3 CLI - swag2op
写这个工具的原因,也是受万俊峰老师的启发,他把工作中重复的事情,整合到一个工具,然后开源,这件事很赞。 swag2op 在 【Go】Go Swagger 生成和转 openapi 3.0.3 这篇文档,主要是对 swagger 如何生成&#…...

python Z-score标准化
python Z-score标准化 Zscore标准化sklearn库实现Z-score标准化手动实现Z-score标准化 Zscore标准化 Z-score标准化(也称为标准差标准化)是一种常见的数据标准化方法,它将数据集中的每个特征的值转换为一个新的尺度,使得转化后的…...
人工智能的数学基础(高数)
🌞欢迎来到人工智能的世界 🌈博客主页:卿云阁 💌欢迎关注🎉点赞👍收藏⭐️留言📝 🌟本文由卿云阁原创! 📆首发时间:🌹2024年5月29日&…...
React(四)memo、useCallback、useMemo Hook
目录 (一)memo API 1.先想一个情景 2.用法 (1)props传入普通数据类型的情况 (2)props传入对象的情况 (3)props传入函数的情况 (4)使用自定义比较函数 3.什么时候使用memo? (二)useMemo Hook 1.用法 2.useMemo实现组件记忆化 3.useMemo实现函数记忆化 …...

前端介绍及工具环境搭建
前端发展历史 前端介绍 1.什么是前端 前端 :针对浏览器的开发,代码在浏览器中运行后端 :针对服务器的开发,代码在服务器中运行 2.前端的用处? 前端在现代技术环境中扮演着⾄关重要的⻆⾊。 作为⽤户与⽹站或应⽤程…...
uniapp高校二手书交易商城回收系统 微信小程序python+java+node.js+php
每年因为有大量的学生在接受教育,每到大学毕业季的时候,所使用的大量书籍对他们自己来说,很多是没有用,同时由于书籍多和不方便携带,导致很多大学生在毕业时将教材直接丢弃是在校大学生处理已用教材的一种主要方式。然…...

Vue3 图片或视频下载跨域或文件损坏的解决方法
Vue3 图片或视频下载跨域或文件损坏的解决方法 修改跨域配置文件下载方法 修改跨域配置文件 修改vite.config.ts文件proxy里面写跨域地址,如下图,图片地址就是我们要跨域的目标地址: 下载方法 如下就是我取消上面那句后的报错 然后调用两…...

vue2和3区别
Vue2和Vue3在**源码架构、性能提升以及API设计**等方面存在区别。具体分析如下: 1. **源码架构** - **Vue2**:Vue2的源码相对更传统,主要使用Options API来构建组件。这种方式要求开发者在一个对象中定义组件的各种属性(如data、m…...
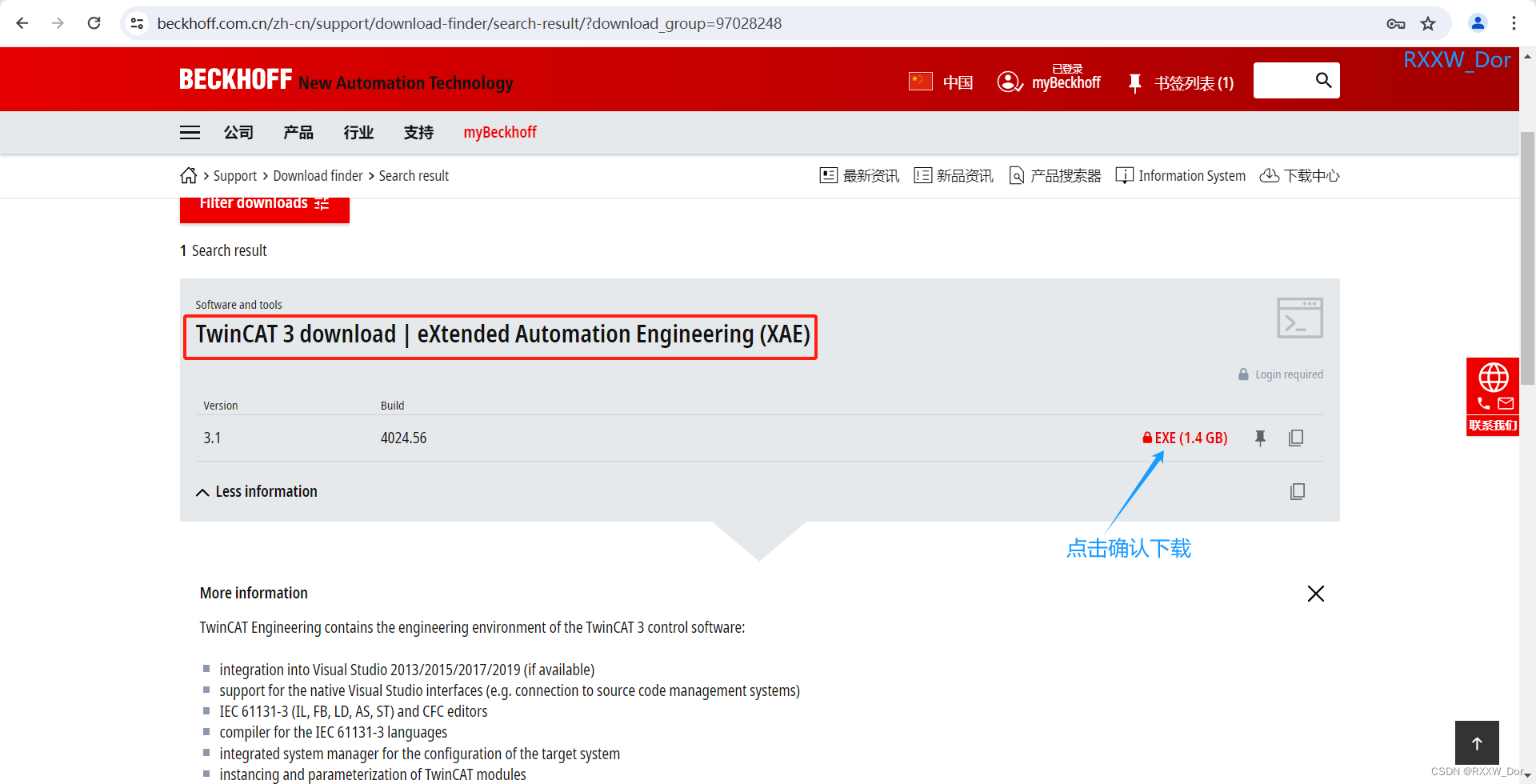
倍福TwinCAT3 PLC编程软件下载安装
1、哪里下载TwinCAT3 链接: Search result | 倍福 中国https://www.beckhoff.com.cn/zh-cn/support/download-finder/search-result/?download_group=97028248下载倍福PLC编程软件需要注册,大家可以提前注册,注册好后就可以开始愉快的下载了 安装前需要注意将各杀毒软件卸…...

Linux一键式管理jar程序执行周期【完整脚本复制可用】
最近由于频繁更新程序,项目又没有自动部署架构,单独执行脚本很麻烦。因此整理了一个脚本,一键式执行。 linux脚本执过程: 1.ps -ef|grep xxx.jar 查询.jar的进程, 2.如果有删除kill -9 进程。 3. 进程删除成功后 nohup…...

设计模式之六大设计原则
文章目录 高内聚低耦合设计原则开闭原则单一职责原则里氏代换原则依赖倒置原则迪米特原则接口隔离原则 高内聚低耦合 提高代码的可读性、可维护性和可扩展性,降低开发和维护的成本,并减少系统的风险 内聚: 内聚表示一个模块内部各个元素之间…...

【iOS】UI学习(一)
UI学习(一) UILabelUIButtonUIButton事件 UIViewUIView对象的隐藏UIView的层级关系 UIWindowUIViewController定时器与视图对象 UISwitch UILabel UILabel是一种可以显示在屏幕上,显示文字的一种UI。 下面使用代码来演示UILabel的功能&#…...

如何使用Vue和Markdown实现博客功能
创建Vue项目和安装依赖 npm install -g @vue/cli vue create vue-blog cd vue-blog npm install vue-markdown-loader --save-dev配置Vue项目以解析Markdown 在 vue.config.js 文件中添加以下配置: module.exports = {chainWebpack: config => {config...

1初识C#
1、Console安慰 Console.WriteLine("Hello, world!"); // 输出 "Hello, world!" 并换行 Console.WriteLine(123.45); // 输出数字 123.45 并换行 Console.WriteLine("Name: " name); // 输出 "Name: [变量name的值]" 并换行 2、 C…...

查询指定会话免打扰
查询指定用户(requestId) 为指定会话(targetId)的设置的免打扰状态。 提示 该设置为用户级别设置。对应的设置接口详见设置指定会话免打扰。 请求方法 POST: https://数据中心域名/conversation/notification/get.json 频率限…...

自动化测试框架选型:Selenium vs Cypress深度对比
在快速迭代的软件开发周期中,自动化测试框架的选型直接影响产品质量与交付效率。Selenium与Cypress作为当前主流工具,分别代表了传统与现代化的技术路线。本文将从架构设计、核心特性、适用场景及未来趋势等维度,为测试从业者提供深度对比分析…...

Switch模拟器Ryujinx全攻略:从安装到优化的跨平台游戏体验
Switch模拟器Ryujinx全攻略:从安装到优化的跨平台游戏体验 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Switch模拟器Ryujinx是一款用C#编写的开源项目,它能让…...

颈源性耳鸣,别当成耳部疾病治
耳朵里嗡嗡响、耳鸣不止,听力不受影响,去耳鼻喉科检查却查不出问题,吃药、调理也没有效果,这种耳鸣很可能不是耳部本身的问题,而是颈椎病变引发的颈源性耳鸣,也是极易被误诊的颈椎并发症。颈椎两侧分布着椎…...

告别论文格式内耗!从标题层级到参考文献,这款工具一键搞定全流程合规排版
在学位论文撰写中,标题层级混乱、页眉页脚错位、参考文献格式不统一、图表排版杂乱是贯穿全文的高频痛点,堪称学术写作的 “格式重灾区”。传统 Word/WPS 依赖手动刷样式、调格式,耗时数小时还易反复出错;LaTeX 门槛高、中文适配差…...

快速掌握Fast-F1:Python赛车数据分析终极指南
快速掌握Fast-F1:Python赛车数据分析终极指南 【免费下载链接】Fast-F1 FastF1 is a python package for accessing and analyzing Formula 1 results, schedules, timing data and telemetry 项目地址: https://gitcode.com/GitHub_Trending/fa/Fast-F1 想要…...

使用Python运行VirtualLab Fusion光学仿真
摘要 VirtualLab Fusion允许Python外部访问其建模技术、求解器和结果。这个用例介绍了一种使用路径变量和Visual Studio代码将Python连接到VirtualLab Fusion的简单方法。在本示例中,我们将演示如何使用Python脚本运行光学仿真,以向用户简要概述这种跨…...

【系统分析师_知识点整理】 8.项目管理
核心考向:进度管理(计算 选择最高频):关键路径、ES/EF/LS/LF、总浮动时间、自由浮动时间、PDM 四种依赖、进度偏差分析;范围管理:WBS、范围确认、范围控制、范围边界定义;成本管理:…...
Pixel Dream Workshop一文详解:基于diffusers的FluxPipeline定制部署
Pixel Dream Workshop一文详解:基于diffusers的FluxPipeline定制部署 1. 像素幻梦创意工坊概述 Pixel Dream Workshop(像素幻梦创意工坊)是一款专为像素艺术创作设计的AI生成工具,基于最新的FLUX.1-dev扩散模型构建。与传统AI绘…...

实战调试:段页式内存管理中的首次页故障剖析
1. 段页式内存管理基础概念 段页式内存管理是现代操作系统的核心机制之一,它巧妙结合了分段和分页两种技术的优势。简单来说,就像我们整理衣柜时既按季节(分段)又用收纳盒(分页)来管理衣物。CPU看到的线性地…...

Opyrator UI设计技巧:5个Streamlit自动生成界面教程
Opyrator UI设计技巧:5个Streamlit自动生成界面教程 【免费下载链接】opyrator 🪄 Turns your machine learning code into microservices with web API, interactive GUI, and more. 项目地址: https://gitcode.com/gh_mirrors/op/opyrator Opyr…...