【机器学习】随机森林:深度解析与应用实践


🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
💫个人格言: "如无必要,勿增实体"

文章目录
- 随机森林:深度解析与应用实践
- 引言
- 1. 随机森林基础
- 1.1 什么是随机森林?
- 1.2 随机森林的核心思想
- 2. 随机森林的构建过程
- 2.1 数据准备
- 2.2 构建决策树
- 2.3 集成预测
- 3. 关键参数与调优
- 3.1 树的数量(n_estimators)
- 3.2 特征随机选择的数量(max_features)
- 3.3 树的最大深度(max_depth)与节点最小样本数(min_samples_split)
- 4. 实际应用案例
- 4.1 信用评分
- 4.2 医疗诊断
- 4.3 推荐系统
- 5. 总结
随机森林:深度解析与应用实践
引言
在机器学习的广阔天地中,集成学习方法因其卓越的预测能力和泛化性能而备受青睐。其中,随机森林(Random Forest)作为集成学习的一个重要分支,凭借其简单、高效且易于实现的特性,在分类和回归任务中展现了非凡的表现。本文将深入探讨随机森林的基本原理、核心构建模块、关键参数调优以及在实际应用中的策略与案例分析,旨在为读者提供一个全面而深入的理解。
1. 随机森林基础
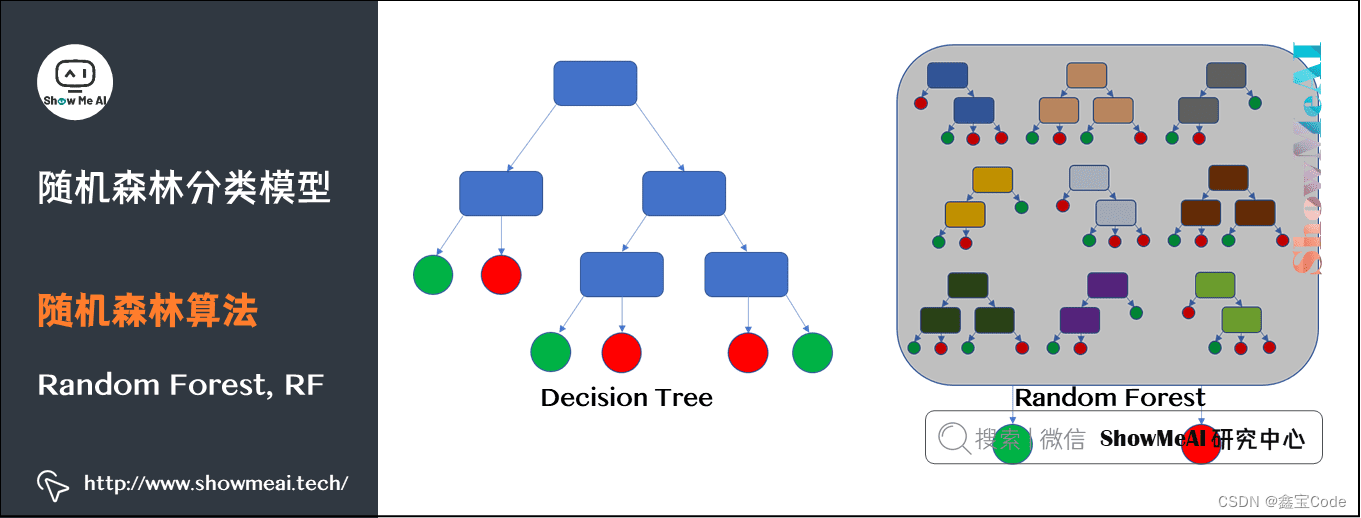
1.1 什么是随机森林?
随机森林是一种基于决策树的集成学习方法,通过构建多个决策树并综合它们的预测结果来提高预测准确性和模型的稳定性。每个决策树都是在训练数据的一个随机子集(bootstrap sample)上,以及特征的一个随机子集上构建的,这种方法减少了模型间的相关性,从而增强了整体模型的泛化能力。
1.2 随机森林的核心思想
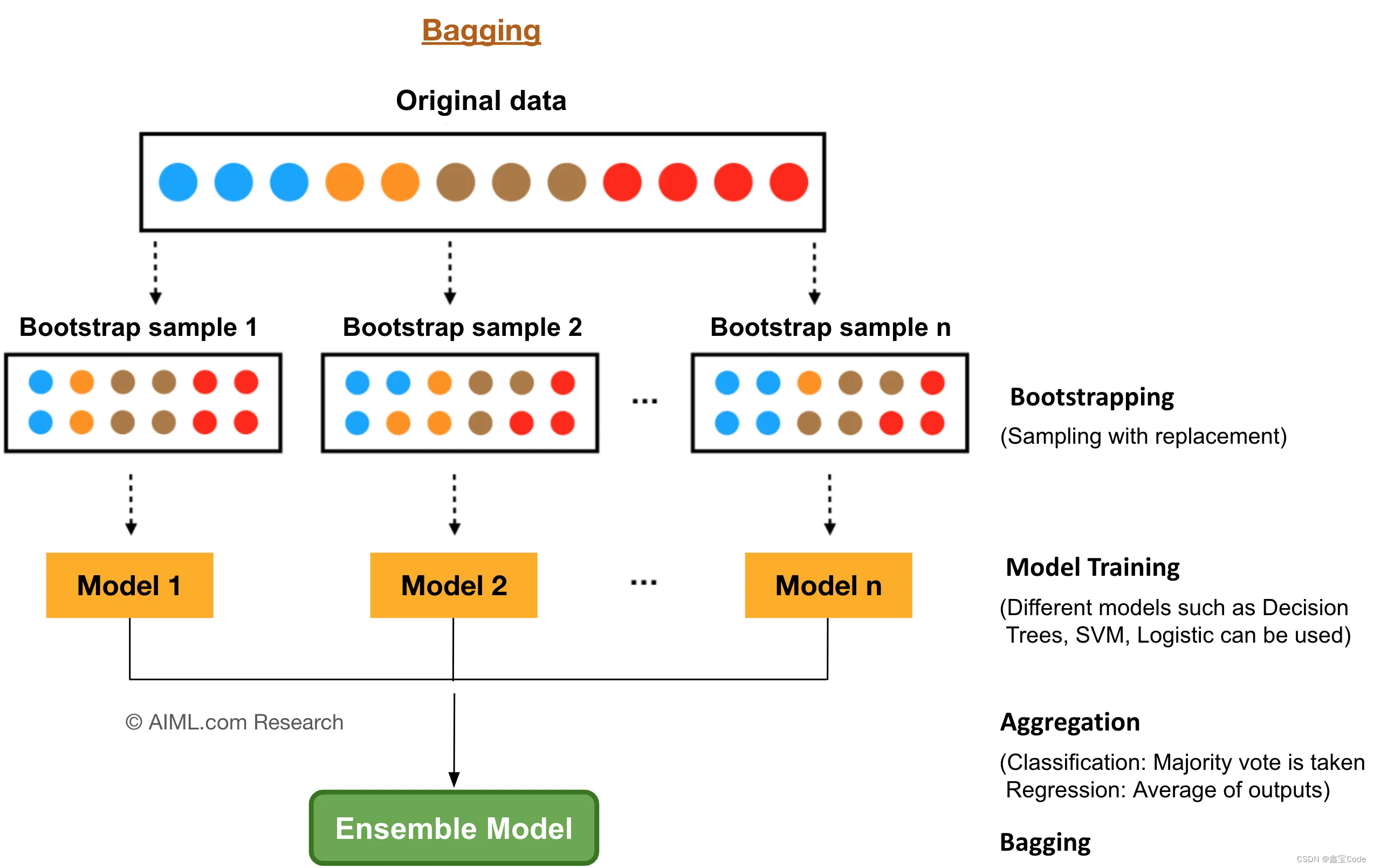
- Bootstrap Aggregating (Bagging):利用自助采样法从原始数据集中有放回地抽取样本,生成多个不同的训练集,每个训练集用于训练一个决策树。
- 特征随机选择:在决策树的每个节点分裂时,不是从所有特征中选择最佳分割特征,而是从一个随机特征子集中选择。
- 树的深度与复杂度控制:通常不剪枝或进行较轻的剪枝,以保持单个决策树的多样性。
2. 随机森林的构建过程
2.1 数据准备
首先,对原始数据进行预处理,包括缺失值处理、数据标准化或归一化等,确保数据质量。
2.2 构建决策树
- Bootstrap采样:从原始数据集中随机抽取N个样本(有放回),形成新的训练集。
- 特征随机选择:在每个节点分裂前,从所有特征中随机选取m个特征作为候选。
- 决策树构建:基于选定的特征,使用某种分裂准则(如信息增益、基尼不纯度)构建决策树,直到满足停止条件(如树的最大深度、节点最小样本数)。
2.3 集成预测
对于分类任务,采用多数投票机制确定最终类别;对于回归任务,则采用平均预测值。
3. 关键参数与调优
3.1 树的数量(n_estimators)
增加树的数量通常能提升模型的稳定性和性能,但过大会导致过拟合风险及计算成本增加。一般通过交叉验证来寻找最优值。
3.2 特征随机选择的数量(max_features)
影响模型的偏差-方差平衡。较小的值会增加模型的多样性,但可能因忽视重要特征而降低性能。常见的设置有“sqrt”(特征总数的平方根)或“log2”。
3.3 树的最大深度(max_depth)与节点最小样本数(min_samples_split)
限制树的复杂度,避免过拟合。适当调整这些参数可以优化模型的泛化能力。
下面是一个使用Python的scikit-learn库实现随机森林分类器的简单示例。这个例子将指导你如何加载数据集、预处理数据、构建随机森林模型、训练模型以及进行预测。
# 导入所需的库
from sklearn.datasets import load_iris # 用于加载Iris数据集
from sklearn.model_selection import train_test_split # 用于数据集的切分
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.metrics import accuracy_score # 评估模型准确率# 加载数据集
iris = load_iris()
X = iris.data # 特征
y = iris.target # 目标变量# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 初始化随机森林分类器
# 这里可以设置随机森林的一些参数,例如n_estimators(树的数量)、max_depth等
rf_classifier = RandomForestClassifier(n_estimators=100, max_depth=4, random_state=42)# 使用训练集训练模型
rf_classifier.fit(X_train, y_train)# 在测试集上进行预测
predictions = rf_classifier.predict(X_test)# 计算并打印模型的准确率
accuracy = accuracy_score(y_test, predictions)
print(f"随机森林模型的准确率: {accuracy:.2f}")
这段代码首先导入了必要的库和模块,然后使用load_iris函数加载了经典的Iris数据集,这是一个用于分类任务的常用数据集,包含了150个样本,每个样本有4个特征和一个目标变量(类别)。接着,数据被划分为训练集和测试集,比例为70%训练,30%测试。之后,初始化了一个随机森林分类器,并设置了树的数量为100,最大树深度为4,以及随机种子以确保结果的可复现性。模型在训练集上进行训练后,对测试集进行预测,并使用accuracy_score函数计算预测的准确率。
4. 实际应用案例
4.1 信用评分
在金融领域,随机森林被广泛应用于信用评级,通过分析客户的交易记录、收入状况、历史还款行为等多维度数据,预测客户的违约风险。
4.2 医疗诊断
随机森林能够处理高维数据,适用于医疗领域的疾病预测。比如,基于病人的生理指标、生活习惯等因素,预测患特定疾病的风险。
4.3 推荐系统
在推荐系统中,随机森林可以用于用户偏好的分类,通过分析用户的历史行为、商品属性等信息,为用户推荐最可能感兴趣的商品或内容。
5. 总结
随机森林以其强大的预测能力、良好的鲁棒性和易于实现的特点,在众多领域展现了其价值。理解其核心原理、掌握关键参数调优技巧,并结合具体应用场景灵活运用,是发挥其最大效能的关键。随着数据科学的不断进步,随机森林及其变种仍在持续发展,为解决更复杂的问题提供可能性。
本文通过对随机森林的基本概念、构建过程、参数调优以及实际应用的深入解析,希望能为读者提供一个全面的认识框架。在实践中,不断探索与创新,将理论知识转化为解决实际问题的能力,是每个算法开发者追求的目标。


相关文章:
【机器学习】随机森林:深度解析与应用实践
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 随机森林:深度解析与应用实践引言1. 随机森林基础1.1 什么是随机森林…...
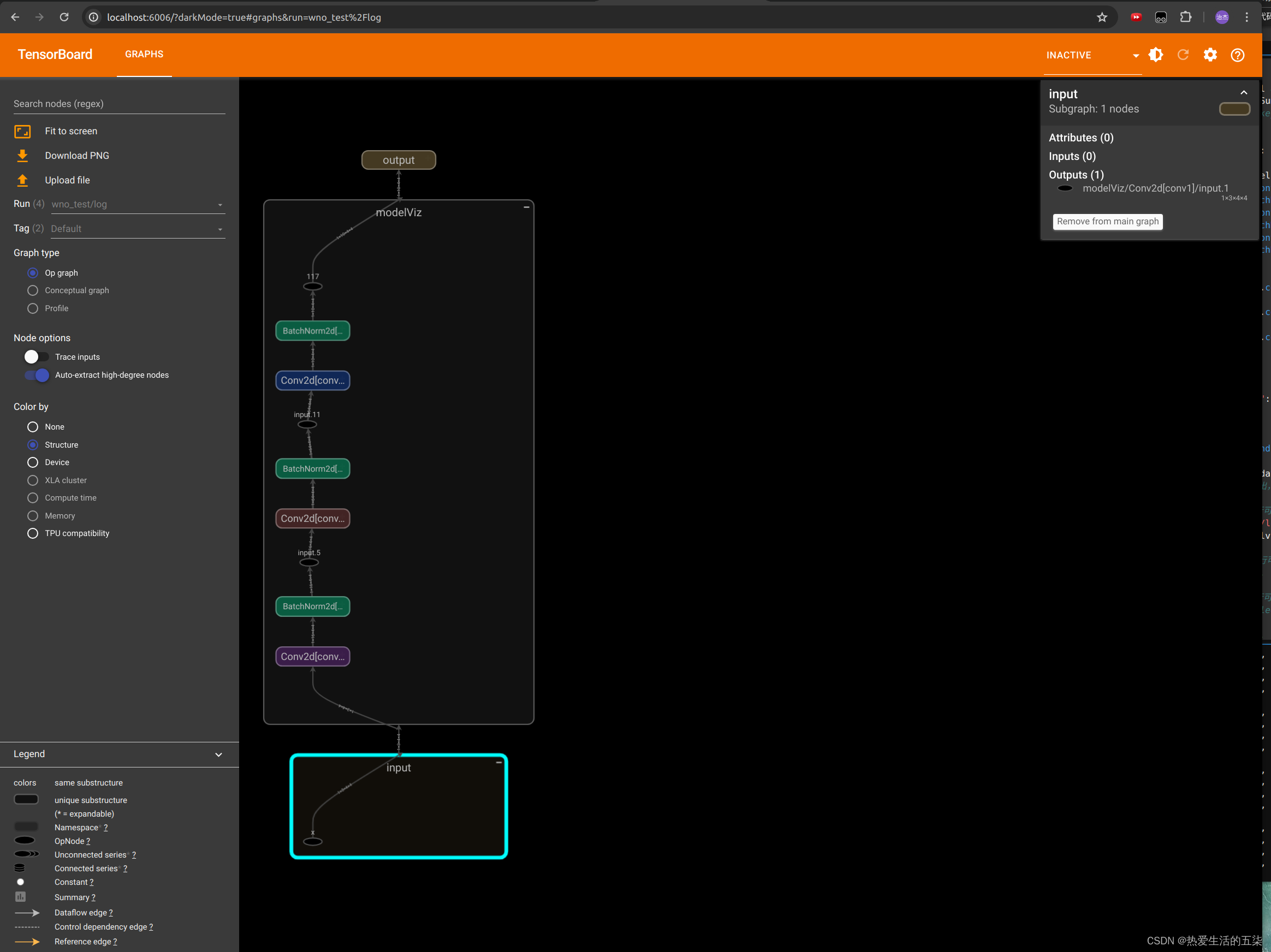
pytorch使用tensorboardX面板自动生成模型结构图和各类可视化图像
总结: 在原本代码中额外添加如下几行即可实现查看模型结构: from tensorboardX import SummaryWriter # 用于进行可视化# 1. 来用tensorflow进行可视化with SummaryWriter("./log", comment"sample_model_visualization") as sw: …...

C# 键值对
一、键值对的基本使用 1、增 Dictionary<int, decimal> dic new Dictionary<int, decimal>();//创建键值对,键的类型为int 值的类型为decimaldic.Add(1, 2.5m);dic.Add(2, 3.7m);dic.Add(3, 4.2m);//添加三组数据 2、删 ① 根据键值对中的键值删除某…...

android 应用安装目录
三方:data/app/ 系统应用:system/app/ 声明so压缩 android:extractNativeLibstrue如果lib没有so,可能是在base.apk,如果so不压缩,直接在base.apk运行时提取 https://www.cnblogs.com/xiaxveliang/p/14583802.html 若…...

Centos 7 安装刻录至硬件服务器
前言 在日常测试中,会遇到很多安装的场景,今天给大家讲一下centos 7 的安装,希望对大家有所帮助。 一.下载镜像 地址如下: centos官方镜像下载地址https://www.centos.org/download/ 按照需求依次点击下载 二.镜像刻录 镜像刻…...

动手学深度学习4.6 暂退法-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:丢弃法_哔哩哔哩_bilibili 本节教材地址:4.6. 暂退法(Dropout)…...

C++ 头文件优化
C 是一种灵活的语言,所以需要一种积极的方法来分析和减少编译时依赖。一种常见的达到这个目的的方法是,将依赖从头文件里转移到源代码文件里。实现这个目的的方法叫做提前声明。 简而言之,这些声明告诉编译器某个函数接受和返回哪些参数&…...

DataRockMan洛克先锋OZON选品工具
随着全球电子商务的飞速发展,跨境电商平台已成为越来越多企业和个人追逐市场红利的重要战场。在众多跨境电商平台中,OZON以其独特的市场定位和强大的用户基础,吸引了无数卖家的目光。然而,如何在OZON平台上成功选品,成…...
-全文解析器-MeCab)
【MySQL精通之路】全文搜索(9)-全文解析器-MeCab
主博客: 【MySQL精通之路】全文搜索功能-CSDN博客 目录 1.介绍 2.安装MeCab Parser插件 3.创建使用MeCab分析器的FULLTEXT索引 4.MeCab Parser空间处理 5.MeCab分析程序停止字处理 6.MeCab Parser术语搜索 7.MeCab分析程序通配符搜索 8.MeCab语法分析器短语…...

【工具】 MyBatis Plus的SQL拦截器自动翻译替换“?“符号为真实数值
【工具】 MyBatis Plus的SQL拦截器自动翻译替换"?"符号为真实数值 使用MyBatis的配置如下所示: mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl调用接口,sql日志打印如下: 参数和sql语句不…...
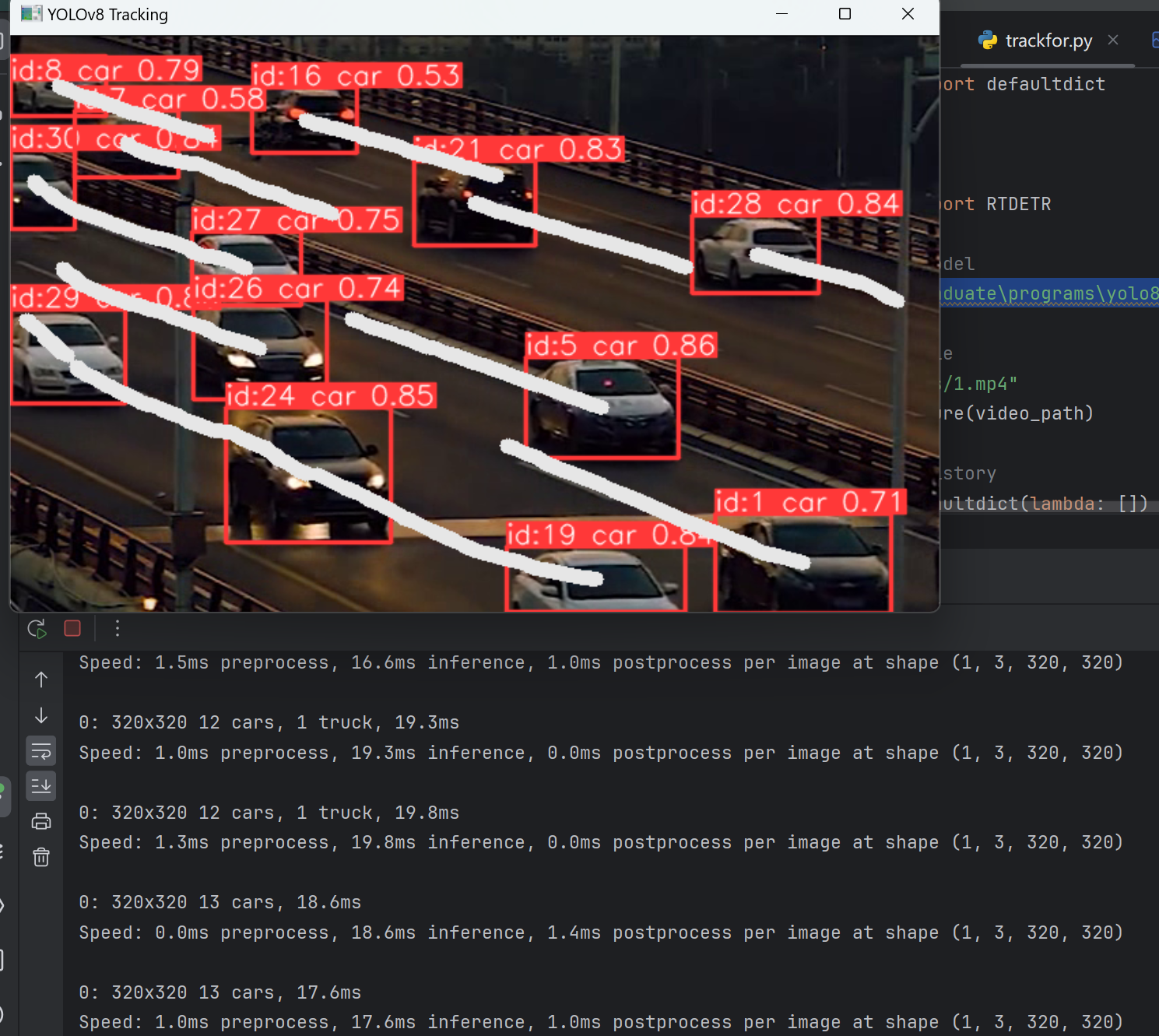
RT-DETR:端到端的实时Transformer检测模型(目标检测+跟踪)
博主一直一来做的都是基于Transformer的目标检测领域,相较于基于卷积的目标检测方法,如YOLO等,其检测速度一直为人诟病。 终于,RT-DETR横空出世,在取得高精度的同时,检测速度也大幅提升。 那么RT-DETR是如…...

OrangePi Kunpeng Pro开发板初体验——家庭小型服务器
引言 在开源硬件的浪潮中,开发板作为创新的基石,正吸引着全球开发者的目光。它们不仅为技术爱好者提供了实验的平台,更为专业开发者带来了实现复杂项目的可能性。本文将深入剖析OrangePi Kunpeng Pro开发板,从开箱到实际应用&…...
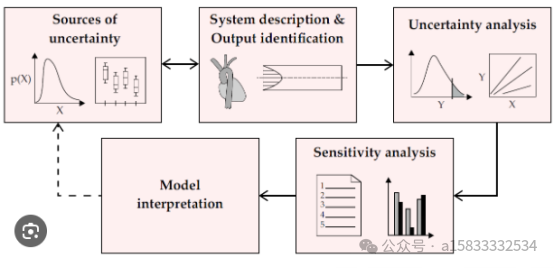
AquaCrop农业水资源管理,模拟作物生长过程中水分的需求与消耗
AquaCrop是由世界粮食及农业组织(FAO)开发的一个先进模型,旨在研究和优化农作物的水分生产效率。这个模型在全球范围内被广泛应用于农业水管理,特别是在制定农作物灌溉计划和应对水资源限制方面显示出其强大的实用性。AquaCrop 不…...

爬虫之re数据清洗
文章目录 一、正则【Regular】二、重要语法1、获取内容: 左边(.*?)右边2、替换数据: re.sub(源数据|源数据, 目标数据, 字符串) 一、正则【Regular】 概念: 根据程序员的指示, 从<字符串>中提取数据 结果: 列表 使用频率: 正则跟xpath相比, 正则是弟弟 二、重要语法 …...

惯性动作捕捉与数字人实时交互/运营套装,对高校元宇宙实训室有何作用?
惯性动作捕捉与数字人实时交互/运营套装,可以打破时空限制,通过动捕设备写实数字人软件系统动捕设备系统定制化数字人短视频渲染平台,重塑课程教学方式,开展元宇宙沉浸式体验教学活动和参观交流活动。 写实数字人软件系统内置丰富…...

Leecode---栈---每日温度 / 最小栈及栈和队列的相互实现
栈:先入后出;队列:先入先出 一、每日温度 Leecode—739题目: 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温…...

Linux系统编程——动静态库
目录 一,关于动静态库 1.1 什么是库? 1.2 认识动静态库 1.3 动静态库特征 二,静态库 2.1 制作静态库 2.2 使用静态库 三,动态库 3.1 制作动态库 3.2 使用动态库一些问题 3.3 正确使用动态库三种方法 3.3.1 方法一&…...

json formatter哪个好用
在众多的JSON Formatter工具中,确实有几个相当出色的选择,它们各自拥有独特的特点和优势,可以满足不同用户群体的需求。下面就来为大家推荐几个好用的JSONFormatter工具: 1. JSON Formatter & Validator:这款工具…...

react的hooks是什么意思
React Hooks 是 React 16.8 版本引入的一个新特性,它允许你在不编写类组件的情况下使用状态和其他React特性。Hooks使得函数组件变得更加灵活和强大,因为你可以在其中添加状态逻辑、生命周期方法以及其他React功能。 在传统的React类组件中,…...
)
AVFrame相关接口(函数)
分配和释放 分配 AVFrame AVFrame *av_frame_alloc(void); 分配一个新的 AVFrame 并返回一个指向它的指针。返回的 AVFrame 需要手动释放。 释放 AVFrame void av_frame_free(AVFrame **frame); 释放由 av_frame_alloc 分配的 AVFrame。这个函数会释放帧的数据并将指针设为 …...

智能AI研修系统:解锁轻量化智能研修的核心技术逻辑
很多人以为智能AI研修系统,只是普通的线上听课、刷题工具,其实这是很大的误解。传统研修模式模式固化、内容同质化严重,还需要人工统计学时、整理学习资料,费时又低效。而智能AI研修系统,是依托多项AI核心技术打造的专…...

从硬盘拷贝文件到内存,CPU真的在摸鱼吗?深入聊聊DMA背后的性能优化哲学
从硬盘拷贝文件到内存,CPU真的在摸鱼吗?深入聊聊DMA背后的性能优化哲学 当你从硬盘拷贝一个10GB的电影文件到内存时,系统监控显示CPU占用率几乎没变化——这似乎违背直觉。难道CPU真的在"摸鱼"?实际上,这背后…...

Hermes Agent用户如何快速接入Taotoken的多模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent用户如何快速接入Taotoken的多模型服务 基础教程类,面向使用Hermes Agent的开发者,详细说明在…...

如何在Windows上使用iperf3进行专业级网络性能测试:完整指南
如何在Windows上使用iperf3进行专业级网络性能测试:完整指南 【免费下载链接】iperf3-win-builds iperf3 binaries for Windows. Benchmark your network limits. 项目地址: https://gitcode.com/gh_mirrors/ip/iperf3-win-builds iperf3作为专业的网络性能基…...
)
告别PyCharm导包烦恼:一劳永逸配置Python虚拟环境(含venv/pipenv对比)
彻底告别Python依赖混乱:虚拟环境配置全指南与PyCharm深度整合 每次打开PyCharm准备大干一场时,却被各种"ModuleNotFoundError"打断思路?明明用pip安装的包,在IDE里却死活找不到?这些问题背后往往隐藏着一个…...

基于Docker部署开源系统监控工具clwatch:原理、实战与安全指南
1. 项目概述:一个开源的系统监控仪表盘最近在GitHub上闲逛,发现了一个挺有意思的项目,叫clwatch。光看名字,你可能会联想到htop或者glances这类命令行下的系统监控工具。没错,clwatch的核心定位就是一个在终端里运行的…...

【信息科学与工程学】【通信工程】第十二篇 信息论01
信息论数学理论体系 信息论建立在坚实的数学基础之上,主要涉及概率论、统计学、随机过程、线性代数、优化理论和实分析等多个领域。以下是信息论中数学理论的全面梳理: 一、概率论基础 1.1 基本概念 概率空间 (Ω,F,P) 随机变量:离散型、连续型、混合型 概率分布:PM…...
)
深入理解C语言指针(三)
点击表格内对应链接跳转对应内容⬇️⬇️⬇️ 作者主页吃透C语言专栏Gitee仓库文章目录一,字符指针变量1.与字符的搭配2.与字符串的搭配(1)字符串详解(2)字符数组或者常量字符串的使用(1)字符数组的使用(2)常量字符串的使用二,数组指针变量1.概念2.使用…...

MATLAB findpeaks:从基础语法到实战调优,精准捕获数据峰值
1. 初识findpeaks:你的数据峰值探测器 第一次接触MATLAB的findpeaks函数时,我正处理一组振动传感器采集的工业设备数据。面对屏幕上杂乱无章的波形曲线,这个函数就像突然递过来的放大镜,让我瞬间看清了隐藏在噪声中的关键特征点。…...

紫光Pango设计流程文件全解析:.vm、.sdc、.pcf都是干嘛用的?
紫光Pango设计流程文件全解析:.vm、.sdc、.pcf都是干嘛用的? 在数字芯片设计领域,紫光Pango作为国产EDA工具链的重要代表,其完整的设计流程会生成多种中间文件格式。这些文件如同设计流程中的"路标",指引着综…...