一文彻底讲透 PyTorch
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
汇总合集:
《AIGC 面试宝典》(2024版) 发布!
《大模型面试宝典》(2024版) 发布!
大模型的火热,彻底把PyTorch带火,Tensorflow 最近落寞了很多。想学会大模型,PyTorch 是必需要学的工具之一。
PyTorch 是利用深度学习进行数据科学研究的重要工具,在灵活性、可读性和性能上都具备相当的优势,近年来已成为学术界实现深度学习算法最常用的框架。
考虑到PyTorch的学习兼具理论储备和动手训练,两手都要抓两手都要硬的特点,我梳理一份《深入浅出 PyTorch 》,帮助大家从入门到熟练掌握 PyTorch 工具,进而实现自己的深度学习算法。
需要《深入浅出 PyTorch 》,可以加入我们技术群获取。
技术交流
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗面试与技术交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:深入浅出 PyTorch
方式②、添加微信号:mlc2040,备注:深入浅出 PyTorch +CSDN

内容简介
- 第零章:前置知识
- 人工智能简史
- 相关评价指标
- 常用包的学习
- Jupyter相关操作
- 第一章:PyTorch的简介和安装
- PyTorch简介
- PyTorch的安装
- PyTorch相关资源简介
- 第二章:PyTorch基础知识
- 张量及其运算
- 自动求导简介
- 并行计算、CUDA和cuDNN简介
- 第三章:PyTorch的主要组成模块
- 思考:完成一套深度学习流程需要哪些关键环节
- 基本配置
- 数据读入
- 模型构建
- 损失函数
- 优化器
- 训练和评估
- 可视化
- 第四章:PyTorch基础实战
- 基础实战——Fashion-MNIST时装分类
- 基础实战——果蔬分类实战(notebook)
- 第五章:PyTorch模型定义
- 模型定义方式
- 利用模型块快速搭建复杂网络
- 模型修改
- 模型保存与读取
- 第六章:PyTorch进阶训练技巧
- 自定义损失函数
- 动态调整学习率
- 模型微调-torchvision
- 模型微调-timm
- 半精度训练
- 数据扩充
- 超参数的修改及保存
- PyTorch模型定义与进阶训练技巧
- 第七章:PyTorch可视化
- 可视化网络结构
- 可视化CNN卷积层
- 使用TensorBoard可视化训练过程
- 使用wandb可视化训练过程
- 第八章:PyTorch生态简介
- 简介
- 图像—torchvision
- 视频—PyTorchVideo
- 文本—torchtext
- 音频-torchaudio
- 第九章:模型部署
- 使用ONNX进行部署并推理
- 第十章:常见网络代码的解读(推进中)
- 计算机视觉
- 图像分类
- ResNet源码解读
- Swin Transformer源码解读
- Vision Transformer源码解读
- RNN源码解读
- LSTM源码解读及其实战
- 目标检测
- YOLO系列解读
- 图像分割
- 图像分类
- 自然语言处理
- RNN源码解读
- 音频处理
- 视频处理
- 其他
- 计算机视觉
部分内容展示
在深度学习模型的训练中,权重的初始值极为重要。一个好的初始值,会使模型收敛速度提高,使模型准确率更精确。一般情况下,我们不使用全0初始值训练网络。为了利于训练和减少收敛时间,我们需要对模型进行合理的初始化。PyTorch也在torch.nn.init中为我们提供了常用的初始化方法。
通过本章学习,你将学习到以下内容:
- 常见的初始化函数
- 初始化函数的使用
torch.nn.init内容
通过访问torch.nn.init的官方文档链接 ,我们发现torch.nn.init提供了以下初始化方法:
1 . torch.nn.init.uniform_(tensor, a=0.0, b=1.0)
2 . torch.nn.init.normal_(tensor, mean=0.0, std=1.0)
3 . torch.nn.init.constant_(tensor, val)
4 . torch.nn.init.ones_(tensor)
5 . torch.nn.init.zeros_(tensor)
6 . torch.nn.init.eye_(tensor)
7 . torch.nn.init.dirac_(tensor, groups=1)
8 . torch.nn.init.xavier_uniform_(tensor, gain=1.0)
9 . torch.nn.init.xavier_normal_(tensor, gain=1.0)
10 . torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan__in’, nonlinearity=‘leaky_relu’)
11 . torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)
12 . torch.nn.init.orthogonal_(tensor, gain=1)
13 . torch.nn.init.sparse_(tensor, sparsity, std=0.01)
14 . torch.nn.init.calculate_gain(nonlinearity, param=None)
关于计算增益如下表:
| nonlinearity | gain |
|---|---|
| Linear/Identity | 1 |
| Conv{1,2,3}D | 1 |
| Sigmod | 1 |
| Tanh | 5/3 |
| ReLU | sqrt(2) |
| Leaky Relu | sqrt(2/1+neg_slop^2) |
我们可以发现这些函数除了calculate_gain,所有函数的后缀都带有下划线,意味着这些函数将会直接原地更改输入张量的值。
torch.nn.init使用
我们通常会根据实际模型来使用torch.nn.init进行初始化,通常使用isinstance()来进行判断模块(回顾3.4模型构建)属于什么类型。
import torch
import torch.nn as nnconv = nn.Conv2d(1,3,3)
linear = nn.Linear(10,1)isinstance(conv,nn.Conv2d) # 判断conv是否是nn.Conv2d类型
isinstance(linear,nn.Conv2d) # 判断linear是否是nn.Conv2d类型
True
False
对于不同的类型层,我们就可以设置不同的权值初始化的方法。
# 查看随机初始化的conv参数
conv.weight.data
# 查看linear的参数
linear.weight.data
tensor([[[[ 0.1174, 0.1071, 0.2977],[-0.2634, -0.0583, -0.2465],[ 0.1726, -0.0452, -0.2354]]],[[[ 0.1382, 0.1853, -0.1515],[ 0.0561, 0.2798, -0.2488],[-0.1288, 0.0031, 0.2826]]],[[[ 0.2655, 0.2566, -0.1276],[ 0.1905, -0.1308, 0.2933],[ 0.0557, -0.1880, 0.0669]]]])tensor([[-0.0089, 0.1186, 0.1213, -0.2569, 0.1381, 0.3125, 0.1118, -0.0063, -0.2330, 0.1956]])
# 对conv进行kaiming初始化
torch.nn.init.kaiming_normal_(conv.weight.data)
conv.weight.data
# 对linear进行常数初始化
torch.nn.init.constant_(linear.weight.data,0.3)
linear.weight.data
tensor([[[[ 0.3249, -0.0500, 0.6703],[-0.3561, 0.0946, 0.4380],[-0.9426, 0.9116, 0.4374]]],[[[ 0.6727, 0.9885, 0.1635],[ 0.7218, -1.2841, -0.2970],[-0.9128, -0.1134, -0.3846]]],[[[ 0.2018, 0.4668, -0.0937],[-0.2701, -0.3073, 0.6686],[-0.3269, -0.0094, 0.3246]]]])
tensor([[0.3000, 0.3000, 0.3000, 0.3000, 0.3000, 0.3000, 0.3000, 0.3000, 0.3000,0.3000]])
初始化函数的封装
人们常常将各种初始化方法定义为一个initialize_weights()的函数并在模型初始后进行使用。
def initialize_weights(model):for m in model.modules():# 判断是否属于Conv2dif isinstance(m, nn.Conv2d):torch.nn.init.zeros_(m.weight.data)# 判断是否有偏置if m.bias is not None:torch.nn.init.constant_(m.bias.data,0.3)elif isinstance(m, nn.Linear):torch.nn.init.normal_(m.weight.data, 0.1)if m.bias is not None:torch.nn.init.zeros_(m.bias.data)elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1) m.bias.data.zeros_()
这段代码流程是遍历当前模型的每一层,然后判断各层属于什么类型,然后根据不同类型层,设定不同的权值初始化方法。我们可以通过下面的例程进行一个简短的演示:
# 模型的定义
class MLP(nn.Module):# 声明带有模型参数的层,这里声明了两个全连接层def __init__(self, **kwargs):# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数super(MLP, self).__init__(**kwargs)self.hidden = nn.Conv2d(1,1,3)self.act = nn.ReLU()self.output = nn.Linear(10,1)# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出def forward(self, x):o = self.act(self.hidden(x))return self.output(o)mlp = MLP()
print(mlp.hidden.weight.data)
print("-------初始化-------")mlp.apply(initialize_weights)
# 或者initialize_weights(mlp)
print(mlp.hidden.weight.data)
tensor([[[[ 0.3069, -0.1865, 0.0182],[ 0.2475, 0.3330, 0.1352],[-0.0247, -0.0786, 0.1278]]]])
"-------初始化-------"
tensor([[[[0., 0., 0.],[0., 0., 0.],[0., 0., 0.]]]])
注意:
我们在初始化时,最好不要将模型的参数初始化为0,因为这样会导致梯度消失,从而影响模型的训练效果。因此,我们在初始化时,可以使用其他初始化方法或者将模型初始化为一个很小的值,如0.01,0.1等。
相关文章:
一文彻底讲透 PyTorch
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。 针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。 汇总合集…...

JVM常用概念之锁粗化和循环
1.什么是锁粗化 锁粗化一般指有效地合并几个相邻的锁定块,从而减少锁定开销。如下述代码所示: 锁粗化前代码: synchronized (obj) {// statements 1 } synchronized (obj) {// statements 2 }锁粗化后代码: synchronized (obj)…...
)
HTML (总结黑马的)
<br>换行 <hr>水平线 div 独占一行 span 不换行 header 网页头部 nav 网页导航 footer 网页底部 aside 网页侧边栏 section 网页区块 article 网页文章 空格 < 小于号 > 大于号 图片: <img src"./cat.jpg" alt&q…...

YOLOv8 segment介绍
1.YOLOv8图像分割支持的数据格式: (1).用于训练YOLOv8分割模型的数据集标签格式如下: 1).每幅图像对应一个文本文件:数据集中的每幅图像都有一个与图像文件同名的对应文本文件,扩展名为".txt"; 2).文本文件中每个目标(object)占一行…...

PMBOK® 第六版 项目整合管理概念
目录 读后感—PMBOK第六版 目录 项目往往会牵涉到众多专业的知识以及来自不同专业、具有不同性格且可能处在不同地理位置的人员,存在着诸多不同分工的状况。要是没有统一的目标,相互之间也没有有效的沟通机制,并且不存在计划、监控以及平衡等…...

【Qt】【模型视图架构】代理模型
文章目录 代理模型简单介绍QSortFilterProxyModel类简单介绍排序过滤子类化 代理模型简单介绍 代理模型的作用是可以将一个模型中的数据进行排序或者过滤,然后提供给视图进行显示。 如下所示,创建一个源模型、一个代理模型,界面上创建一个列…...

Flutter 中的 IconTheme 小部件:全面指南
Flutter 中的 IconTheme 小部件:全面指南 Flutter 是一个功能丰富的 UI 开发框架,它允许开发者使用 Dart 语言来构建跨平台的移动、Web 和桌面应用。在 Flutter 的丰富组件库中,IconTheme 是一个用于设置应用中图标主题的小部件,…...

virtualbox虚拟机、centos7安装增强工具
文章目录 1. virtualBox语言设置2. 设置终端启动快捷键3. 添加virtualbox 增强工具4. 设置共享文件夹 1. virtualBox语言设置 virtualbox -> file -> perferences -> language ->选择对应的语言 -> OK virtualbox -> 管理 -> 全局设定 -> 语言 -> …...

Kotlin 泛型
文章目录 定义泛型属性泛型函数泛型类或接口 where 声明多个约束泛型具体化in、out 限制泛型输入输出 定义 有时候我们会有这样的需求:一个类可以操作某一类型的对象,并且限定只有该类型的参数才能执行相关的操作。 如果我们直接指定该类型Intÿ…...
)
Tomcat 面试题(一)
1. 简述什么是Tomcat ? Tomcat是一个开源的Java Servlet容器,它实现了Java Servlet和JavaServer Pages (JSP)技术,提供了一个运行Java Web应用程序的平台。Tomcat由Apache软件基金会维护,并广泛用于开发和部署Web应用程序。 Tom…...

跟踪一个Pytorch Module在训练过程中的内存分配情况
跟踪一个Pytorch Module在训练过程中的内存分配情况 代码输出 目的:跟踪一个Pytorch Module在训练过程中的内存分配情况 方法: 1.通过pre_hook module的来区分module的边界 2.通过__torch_dispatch__拦截所有的aten算子,计算在该算子中新创建tensor的总内存占用量 3.通过tensor…...
空间方法×3))
LeetCode 2965.找出缺失和重复的数字:小数据?我选择暴力(附优化方法清单:O(1)空间方法×3)
【LetMeFly】2965.找出缺失和重复的数字:小数据?我选择暴力(附优化方法清单:O(1)空间方法3) 力扣题目链接:https://leetcode.cn/problems/find-missing-and-repeated-values/ 给你一个下标从 0 开始的二维…...
)
【运维】VMware Workstation 虚拟机内无网络的解决办法(或许可行)
【使用桥接模式】 【重置网络】 这个过程涉及管理Linux系统中的网络驱动程序和网络管理工具。以下是每个步骤的详细解释: 卸载网络驱动模块: sudo rmmod e1000 sudo rmmod e1000e sudo rmmod igb这些命令使用 rmmod(remove moduleÿ…...
如何使用Dora SDK完成Fragment流式切换和非流式切换
我想大家对Fragment都不陌生,它作为界面碎片被使用在Activity中,如果只是更换Activity中的一小部分界面,是没有必要再重新打开一个新的Activity的。有时,即使要更换完整的UI布局,也可以使用Fragment来切换界面。 何…...
低代码开发平台(Low-code Development Platform)的模块组成部分
低代码开发平台(Low-code Development Platform)的模块组成部分主要包括以下几个方面: 低代码开发平台的模块组成部分可以按照包含系统、模块、菜单组织操作行为等维度进行详细阐述。以下是从这些方面对平台模块组成部分的说明: …...

Java网络编程(上)
White graces:个人主页 🙉专栏推荐:Java入门知识🙉 🙉 内容推荐:Java文件IO🙉 🐹今日诗词:来如春梦几多时?去似朝云无觅处🐹 ⛳️点赞 ☀️收藏⭐️关注💬卑微小博主&a…...

Spring Kafka 之 @KafkaListener 注解详解
我们在开发的过程中当使用到kafka监听消费的时候会使用到KafkaListener注解,下面我们就介绍下它的常见属性和使用。 一、介绍 KafkaListener 是 Spring Kafka 提供的一个注解,用于声明一个方法作为 Kafka 消息的监听器 二、主要参数 1、topic 描述&…...
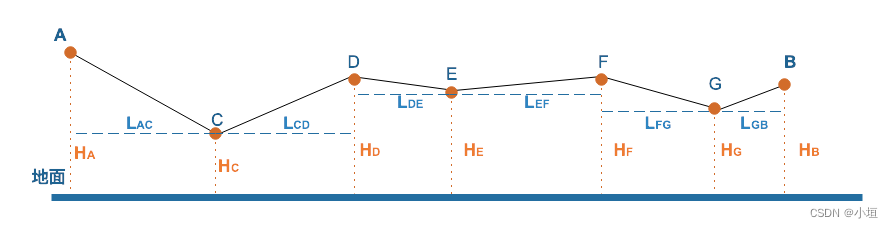
【量算分析工具-贴地距离】GeoServer改造Springboot番外系列九
【量算分析工具-概述】GeoServer改造Springboot番外系列三-CSDN博客 【量算分析工具-水平距离】GeoServer改造Springboot番外系列四-CSDN博客 【量算分析工具-水平面积】GeoServer改造Springboot番外系列五-CSDN博客 【量算分析工具-方位角】GeoServer改造Springboot番外系列…...
文件操作及vi)
【linux】(1)文件操作及vi
文件和目录的创建 创建文件 touch 命令:创建一个新的空文件。 touch filename.txtecho 命令:创建一个文件并写入内容。 echo "Hello, World!" > filename.txtcat 命令:将内容写入文件。 cat > filename.txt然后输入内容&…...
【5】MySQL数据库备份-XtraBackup - 全量备份
MySQL数据库备份-XtraBackup-全量备份 前言环境版本 安装部署下载RPM 包二进制包 安装卸载 场景分析全量备份 | 恢复备份恢复综合 增量备份 | 恢复部分备份 | 恢复 前言 关于数据库备份的一些常见术语、工具等,可见《MySQL数据库-备份》章节,当前不再重…...

CentOS8实战:ZeroTier构建安全异地虚拟局域网
1. 为什么选择ZeroTier替代传统内网穿透方案 最近在帮朋友搭建远程办公环境时,遇到了一个典型问题:分布在三个不同物理位置的服务器需要像在同一个办公室内网那样互相访问。最初考虑使用FRP方案,但实测下来发现几个痛点:首先是带宽…...

δ - mem:提升大型语言模型内存效率,得分最高可达 1.31 倍!
快速通道可了解 arXiv 成为独立非营利组织的情况,也能直达康奈尔大学官网。同时,还能通过链接进行捐赠,支持 arXiv 的发展。搜索与导航提供了多种搜索途径,可在所有字段(标题、作者、摘要等)进行搜索。还有…...

ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案
ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的情况ÿ…...

JetBrains IDE试用期重置终极指南:3种简单方法实现30天无限续杯
JetBrains IDE试用期重置终极指南:3种简单方法实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否在使用IntelliJ IDEA、PyCharm、WebStorm等JetBrains IDE时遇到过试用期突然结束…...

DIY便携FPV地面站:从电路设计到3D打印的完整制作指南
1. 项目概述:为什么需要一个便携式FPV地面站?玩FPV(第一人称视角)飞行,无论是竞速穿越还是航拍探索,最核心的体验就是那块屏幕。大多数飞手依赖FPV眼镜带来的沉浸感,但在很多场景下,…...

Kubernetes上Jenkins全栈部署:动态Agent与生产环境调优指南
1. 项目概述:一个面向Kubernetes的Jenkins全栈部署方案在容器化和云原生技术成为主流的今天,如何高效、稳定地部署和管理持续集成/持续交付(CI/CD)流水线,是每个开发团队和运维工程师必须面对的课题。传统的单体Jenkin…...

faah:轻量级自动化任务编排器,简化运维与数据处理工作流
1. 项目概述:一个被低估的自动化利器最近在整理自己的自动化工具链时,又翻出了kiron0/faah这个项目。说实话,第一次看到这个仓库名,我也有点懵——“faah”?这名字听起来不像是一个典型的工具。但点进去之后࿰…...

构建团队技能仓库:从知识管理到可执行技能包的系统化实践
1. 项目概述:从“技能包”到高效能工具箱最近在梳理团队内部的技术资产时,我反复思考一个问题:如何让那些散落在个人电脑、项目文档和口头交流中的“隐性知识”和“高效技能”,变成一个团队可以随时取用、持续进化的公共资产&…...

基于Go的轻量级自托管IM系统OpenWhisp部署与架构解析
1. 项目概述:一个开源的即时通讯解决方案最近在折腾一个内部协作工具,需要集成一个轻量级的即时通讯模块。市面上成熟的方案不少,但要么是SaaS服务,数据不在自己手里,心里不踏实;要么是像Rocket.Chat、Matt…...

【模拟电路】Circuit JS:从零到一,构建你的首个交互式电路实验
1. 初识Circuit JS:你的虚拟电路实验室 第一次接触Circuit JS时,我正为一个简单的LED电路设计发愁。传统仿真软件要么安装复杂,要么收费昂贵,直到发现这个直接在浏览器里运行的免费工具。打开网页的瞬间,就像走进了中学…...