全文检索-ElasticSearch


1.基本概念
1.Index索引
动词:相当于MySQL中的insert;
名词:相当于MySQL中的DataBase;
2.Type(类型)
在Index(索引)中,可以定义一个或多个类型
类似于MySQL中的Table;每一种类型的数据放在一起
3.Document(文档)
保存在某个索引(index)下,某种类型(Type) 的一个数据(Document),文档是JSON格式的,Document就像是MySQL 中的某个Table里面的内容 类似一行数据

4.倒排索引
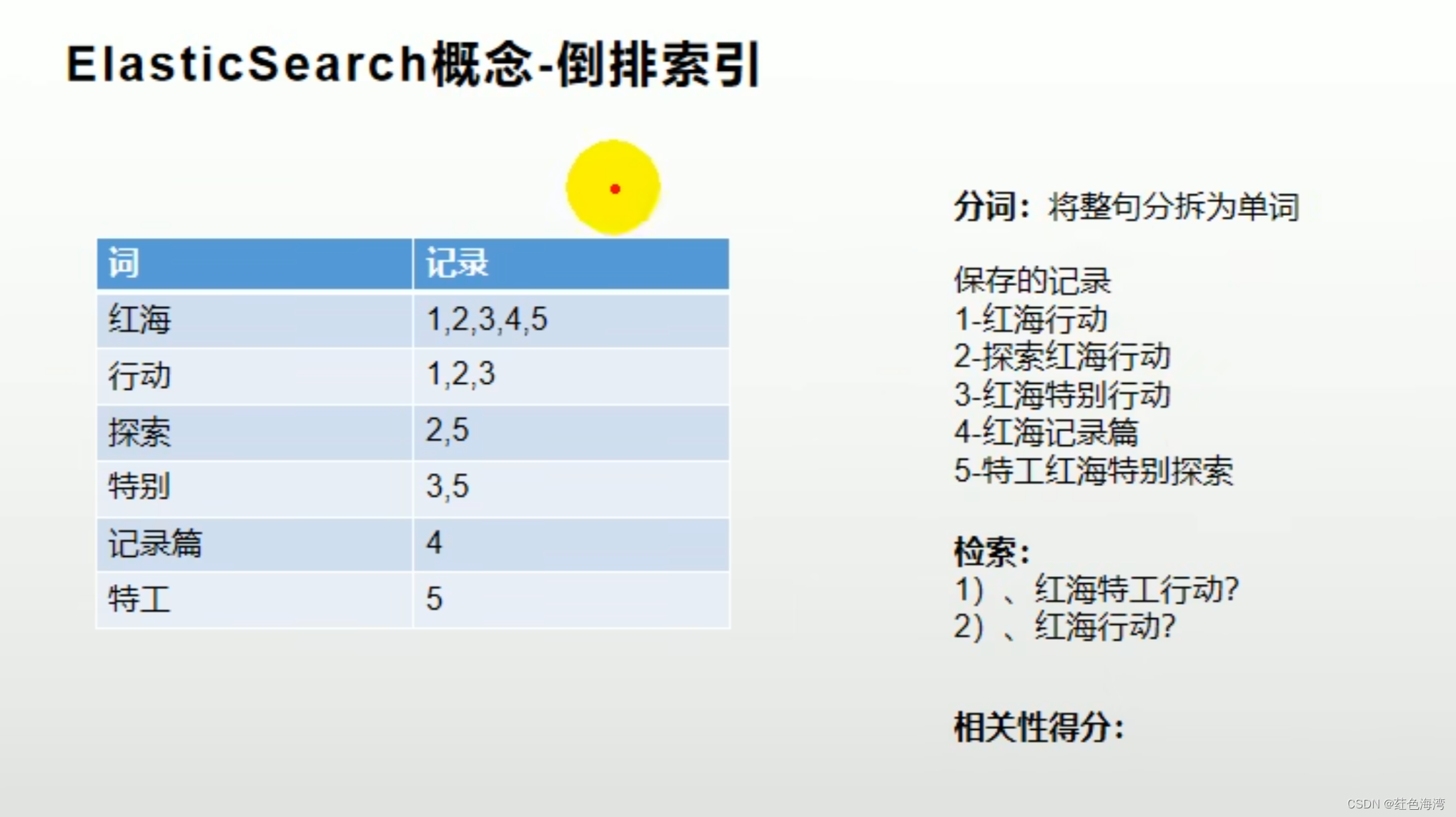
2.Docker 安装ElasticSearch
2.1 拉取镜像
docker pull elasticsearch:7.4.2docker pull kibana:7.4.22.2 创建实例
2.2.1 创建挂载目录
mkdir ./configmkdir ./data记得授予权限
chmod -R 777 ./elasticsearch2.2.2 使容器外任何地址都能够访问 elasticsearch
echo "http.host: 0.0.0.0">>./config/elasticsearch.ymlelasticsearch.yml
http.host: 0.0.0.0
2.2.3 docker 启动
docker run --name elasticsearch -p 9200:9200 -p9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms512m -Xmx1024m" \
-v ./config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v ./data:/usr/share/elasticsearch/data \
-v ./plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
2.3 安装Kibana
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.232.209:9200 -p 5601:5601 \
-d kibana:7.4.2
3.初步检索
3.1 _cat
查看节点信息
http://192.168.232.209:9200/_cat/nodes查看elasticsearch的健康状态
http://192.168.232.209:9200/_cat/health查看elasticsearch的主节点信息
http://192.168.232.209:9200/_cat/master查看所有索引
http://192.168.232.209:9200/_cat/indices3.2 索引一个文档(保存或修改一条记录)
保存一个数据,保存在那个索引的哪个类型下,指定用哪个唯一标识
http://192.168.232.209:9200/customer/external/1
3.3 查询文档
http://192.168.232.209:9200/customer/external/13.4 更新文档

3.4.1 _update
这个操作如果修改文档的值和原来一样,则不会更新版本。
3.4.2

3.5 删除文档

3.6 bulk 批量 API


批量操作
从这个网站复制
https://gitee.com/xlh_blog/common_content/blob/master/es%E6%B5%8B%E8%AF%95%E6%95%B0%E6%8D%AE.json#执行 /_bluk

4.进阶检索
1.searchAPI
ES支持两种基本方式检索:
- 一个是通过使用REST request URI 发送搜索参数(uri + 检索参数)
- 另一个是通过使用REST request body 来发送它们 (uri + 请求体)
GET /bank/_search?q=*&sort=account_number:ascq=* 查询所有
sort 跟据 account_number 升序
2.QueryDSL


GET /bank/_search
{"query": {"match_all": {}},"sort": [{"account_number": "asc"},{"balance": "desc"}]
}3.部分检索
GET /bank/_search
{"query": {"match_all": {}},"sort": [{"account_number": "desc"},{"balance": "desc"}],"from": 0,"size": 20,"_source": ["balance","account_number"]}4. match[匹配查询]
GET /bank/_search
{"query": {"match": {"account_number": 20}}}GET /bank/_search
{"query": {"match": {"address": "mill lane"}}}全文检索按照评分进行排序
5.match_phrase [短语匹配]
将需要匹配的值当成一个整体单词(不分词)进行检索
GET /bank/_search
{"query": {"match_phrase": {"address": "mill lane"}}}6.multi_match [多字段匹配]
这是或,只要一个字段满足,就返回
GET /bank/_search
{"query": {"multi_match": {"query": "mill","fields": ["state","address"]}}}能够正常分词
GET /bank/_search
{"query": {"multi_match": {"query": "mill Movico","fields": ["city","address"]}}}
7.bool复杂查询
bool用来做复杂查询:
复合语句可以合并 任何 其他查询语句,包括复合语句,了解这一点是很重要的。这就意味着,复合语句之间可以相互嵌套,可以表达非常复杂的逻辑。
must: 必须达到must列举所有条件 也就是相当于 AND
must_not: 且不满足里面的条件
should: 不是or 就是匹配上面有加分项
GET /bank/_search
{"query": {"bool": {"must": [{"match": {"gender": "m"}},{"match": {"address": "Mill"}}],"must_not": [{"match": {"age": 28 }}],"should": [{"match": {"lastname": "v"}}]}}}8.filter [结果过滤]
并不是所有的查询都需要产生分数,特别是那些仅用于 "filtering" (过滤) 的文档。为了不计算分数Elasticsearch 会自动检查场景并且优化查询的执行。
GET /bank/_search
{"query": {"bool": {"must": [{"match": {"gender": "m"}},{"match": {"address": "Mill"}}],"must_not": [{"match": {"age": 18 }}],"should": [{"match": {"lastname": "Wallace"}}],"filter": {"range": {"age": {"gte": 18,"lte": 20}}}}}
}9.term
和match一样。匹配某个属性的值。全文检索字段用match,其他非text 字段匹配用term
不用全文检索的时候用term 比如数字 年龄
GET /bank/_search
{
"query": {"term": {"age": {"value": "28"}}
}
}GET /bank/_search
{
"query": {"match": {"email.keyword": "margueritewall@aquoavo.com"}
}
}address.keyword 和 match_phrase 区别:
前者 就是精确匹配 ,后者包含这个短语 就行
非文本字段 用 term
文本字段用 match
10. aggregations (执行聚合)
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于 SQL GROUP BY 和 SQL 的聚合函数 。在Elasticsearch 中, 您有执行搜索返回 hits (命中结果) ,并且同时返回聚合结果,把一个响应中的所有hits (命中结果) 分隔开的能力 。 这是非常强大且有效,您可以执行查询和多个聚合,并且在一次使用中得到各自 的(任何一个的) 返回结果,使用一次简化和简化的API 来避免网络往返。
搜索 address 中包含mill 的所有人的年龄分布以及平均年龄,但不显示这些人的详情。
GET /bank/_search
{"query": {"match": {"address": "mill"}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 10}},"ageAvg":{"avg": {"field": "age"}},"blanceAvg":{"avg": {"field": "balance"}}},"size": 0
}复杂:
按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
##按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
GET /bank/_search
{"query": {"match_all": {}},"aggs": {"aggAgg": {"terms": {"field": "age","size": 100},"aggs": {"aggAvg": {"avg": {"field": "balance"}}}}}}
复杂2:
查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资.
##查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资GET /bank/_search
{"query": {"match_all": {}},"aggs": {"aggAggs": {"terms": {"field": "age","size": 100},"aggs": {"avgBalanceAll":{"avg": {"field": "balance"}},"genderAgg": {"terms": {"field": "gender.keyword","size": 2},"aggs": {"avgBlance": {"avg": {"field": "balance"}}}}}}}
}11.mapping(映射)
 所有数据类型
所有数据类型

创建一个有类型定义的索引
PUT /my_index
{"mappings": {"properties": {"age":{"type": "integer" },"email":{"type": "keyword"},"name":{"type": "text"}}}
}添加映射字段
PUT /my_index/_mapping
{"properties": {"employee-id":{"type":"keyword","index":false }}
}index =false 代表不参与索引,是搜索不到他的,相当于冗余存储字段,通过其他字段查出来
迁移数据
创建新索引
PUT /newbank
{"mappings": {"properties": {"account_number": {"type": "long"},"address": {"type": "text"},"age": {"type": "integer"},"balance": {"type": "long"},"city": {"type": "keyword"},"email": {"type": "keyword"},"employer": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"firstname": {"type": "text"},"gender": {"type": "keyword"},"lastname": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"state": {"type": "keyword"}}}
}

上面是6.0以后不用类型保存的迁移方法
下面是6.0之前

POST _reindex
{"source": {"index": "bank","type": "account"},"dest": {"index": "newbank"}
}5.分词

POST _analyze
{"analyzer": "standard","text": "The 2 QUICK Brown_Foxes jumped over the lazy dog's bone."
}1.安装ik分词器
注意:不能用默认elastics-plugin install xx.zip 进行自动安装
进入这个网址下
Index of: analysis-ik/stable/ (infinilabs.com)
进入es 容器·内部 plugins 目录
docker exec -it 容器id /bin/bash
POST _analyze
{"analyzer": "ik_smart","text": "我是中国人"
}POST _analyze
{"analyzer": "ik_max_word","text": "鸡你太美"
}
安装方法和我上一篇文章一样
ElasticSearch-CSDN博客
vagrant ssh密码登录 122集

2.自定义分词器


1.重新安装nginx
命令
在nginx文件夹下,执行
docker run -p 80:80 --name nginx \
-v ./html:/usr/share/nginx/html \
-v ./logs:/var/log/nginx \
-v ./conf:/etc/nginx \
-d nginx:1.102. 创建分词文件
/opt/nginx/html/es/fenci.txt
尚硅谷
乔碧螺3.在es插件,路径下找到xml文件对应的分词库路径,保存位置进行修改
"/opt/elasticearch/plugins/ik/config/IKAnalyzer.cfg.xml"
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><entry key="remote_ext_dict">http://虚拟机地址:80/es/fenci.txt</entry><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
4.修改以后重启restart es容器
docker restart elasticsearch
6.Elasticsearch整合Spirngboot使用
1.Elasticsearch-Rest-Client 官方 RestClient ,封装类ES操作,API层次分明,上手简单。
最终选择Elasticsearch-Rest-Client (elasticsearch-rest-high-level-client)
https://www.elastic.co/guid/en/elasticsearch/client/java-rest/current/java-rest-high.html<!-- 导入ES高阶API--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>${elasticsearch.version}</version></dependency>package com.jmj.gulimall.search.config;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** 导入依赖* 编写配置 给容器中注入一个 RestHighLevelClient* 参照官方API 操作就可以了 https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.4/java-rest-high-getting-started-initialization.html*/
@Configuration
public class GulimallElasticSearchConfig {@Beanpublic RestHighLevelClient esRestClient() {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.232.209", 9200, "http")));return client;}}
2.RequestOption
请求选项:比如安全验证,带token 请求头
package com.jmj.gulimall.search.config;import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** 导入依赖* 编写配置 给容器中注入一个 RestHighLevelClient* 参照官方API 操作就可以了 https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.4/java-rest-high-getting-started-initialization.html*/
@Configuration
public class GulimallElasticSearchConfig {public static final RequestOptions COMMON_OPTIONS;static {RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization", "Bearer " + TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));COMMON_OPTIONS = builder.build();}@Beanpublic RestHighLevelClient esRestClient() {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.232.209", 9200, "http")));return client;}}
3.Index API
第一种

第二种

第三种

第四种

/*** 测试存储数据到ES* 更新也可以*/@Testvoid indexData() throws IOException {//index索引 usersIndexRequest indexRequest = new IndexRequest("users");//设置document id ,不设置就会默认生成/*** 若是同样的id重复执行,就是更新操作 乐观锁控制版本*/indexRequest.id("1");//1. key value pair
// indexRequest.source("userName","zhangsan","age",18,"gender","男");//2,JSONUser user = new User("zhangsan", "男", 18);String json = new ObjectMapper().writeValueAsString(user);//一秒超时时间indexRequest.timeout(TimeValue.timeValueSeconds(1));indexRequest.source(json, XContentType.JSON);//要保存的内容//执行操作IndexResponse index = client.index(indexRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);//提取有用的响应数据System.out.println(index);}4.查询API
@Datapublic static class Account{private int account_number;private String firstname;private String address;private int balance;private String gender;private String city;private String employer;private String state;private int age;private String email;private String lastname;}/*** search检索*/@Testvoid searchData() throws IOException {//1、创建检索请求SearchRequest searchRequest = new SearchRequest();//2、指定索引searchRequest.indices("bank");//3、检索条件DSLSearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// sourceBuilder.query();
// sourceBuilder.from();
// sourceBuilder.size();
// sourceBuilder.aggregations();// sourceBuilder.query(QueryBuilders.matchAllQuery());sourceBuilder.query(QueryBuilders.matchQuery("address","mill"));//按照年龄进行分组TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);sourceBuilder.aggregation(ageAgg);//计算平均薪资AvgAggregationBuilder balanceAge = AggregationBuilders.avg("balanceAvg").field("balance");sourceBuilder.aggregation(balanceAge);System.out.println("检索条件:"+sourceBuilder);searchRequest.source(sourceBuilder);//4、执行检索SearchResponse response = client.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);//5、响应 分析结果
// System.out.println(response.toString());SearchHits hits = response.getHits();SearchHit[] hits1 = hits.getHits();for (SearchHit documentFields : hits1) {String sourceAsString = documentFields.getSourceAsString();Account account = new ObjectMapper().readValue(sourceAsString, Account.class);System.out.println(account);}//获取分析数据Aggregations aggregations = response.getAggregations();Terms ageAgg1 = aggregations.get("ageAgg");for (Terms.Bucket bucket : ageAgg1.getBuckets()) {String keyAsString = bucket.getKeyAsString();System.out.println("年龄:"+keyAsString+"=>"+bucket.getDocCount());}Avg balanceAvg = aggregations.get("balanceAvg");System.out.println("平均薪资:"+balanceAvg.getValue());}
7.SKU 在es种存储的模型
其中,库存信息的标题使用了ik分词器,图片信息,品牌名,品牌id等信息均不可检索。商品的规格参数等信息以nested类型,即嵌入属性存储。相关的细节这里不再赘述。
PUT product
{"mappings": {"properties": {"skuId": {"type": "long"},"spuId": {"type": "long"},"skuTitle": {"type": "text","analyzer": "ik_smart"},"skuPrice": {"type": "keyword"},"skuImg": {"type": "keyword","index": false,"doc_values": false},"saleCount": {"type": "long"},"hosStock": {"type": "boolean"},"hotScore": {"type": "long"},"brandId": {"type": "long"},"catalogId": {"type": "long"},"brandName": {"type": "keyword","index": false,"doc_values": false},"brandImg": {"type": "keyword","index": false,"doc_values": false},"catalogName": {"type": "keyword","index": false,"doc_values": false},"attrs": {"type": "nested","properties": {"attrId": {"type": "long"},"attrName": {"type": "keyword","index": false,"doc_values": false},"attrValue": {"type": "keyword"}}}}}
}
8.ES扁平化处理
PUT my_index/_doc/1
{"group":"fans","user":[{"first":"John","last":"Smith"},{"first":"Alice","last":"White"}]
}
GET my_index/_search
{"query": {"bool": {"must": [{"match": {"user.first": "Alice"}},{"match": {"user.first": "Alice"}}]}}
}
取消扁平化处理
PUT my_index
{"mappings": {"properties": {"user":{"type": "nested"}}}
}再次查询

9. 商城上架
@Override@Transactional(rollbackFor = Exception.class)public void up(Long spuId) {//组装需要的数据//1. 查出当前 spuid 对应的所有sku 信息,品牌 的名字。List<SkuInfoEntity> skuInfoEntityList = skuInfoService.getSkusBySpuId(spuId);//TODO 查询当前sku的所有可以用来检索的属性List<ProductAttrValueEntity> baseAttrs = productAttrValueService.baseAttrlistforspu(spuId);List<Long> attrIds = baseAttrs.stream().map(a -> a.getAttrId()).collect(Collectors.toList());List<Long> searchAttrIds = attrService.selectSearchAtts(attrIds);List<SkuEsModel.Attrs> attrsList = baseAttrs.stream().filter(item -> searchAttrIds.contains(item.getAttrId())).map(item -> {SkuEsModel.Attrs attrs1 = new SkuEsModel.Attrs();BeanUtils.copyProperties(item, attrs1);return attrs1;}).collect(Collectors.toList());//TODO 发送远程调用 库存系统查询是否有库存List<Long> skuIds = skuInfoEntityList.stream().map(s -> s.getSkuId()).distinct().collect(Collectors.toList());List<SkuHasStockVo> skusHasStock = wareFeignService.getSkusHasStock(skuIds);Map<Long, Boolean> stockMap = skusHasStock.stream().collect(Collectors.toMap(s -> s.getSkuId(), s -> s.getHasStock()));//2.封装每个SKU 的信息List<SkuEsModel> upProducts = skuInfoEntityList.stream().map(sku -> {SkuEsModel esModel = new SkuEsModel();BeanUtils.copyProperties(sku, esModel);esModel.setSkuPrice(sku.getPrice());esModel.setSkuImg(sku.getSkuDefaultImg());Long skuId = esModel.getSkuId();Boolean aBoolean = stockMap.get(skuId);if (aBoolean!=null){esModel.setHasStock(aBoolean);}else {esModel.setHasStock(false);}//TODO 热度评分esModel.setHotScore(0L);//TODO 查询品牌和分类的名字信息BrandEntity brand = brandService.getById(esModel.getBrandId());esModel.setBrandName(brand.getName());esModel.setBrandImg(brand.getLogo());CategoryEntity category = categoryService.getById(esModel.getCatalogId());esModel.setCatalogName(category.getName());//设置检索属性esModel.setAttrs(attrsList);return esModel;}).collect(Collectors.toList());//TODO 将数据发送给es进行保存searchFeignService.productStatusUp(upProducts);//TODO 修改状态this.update(new UpdateWrapper<SpuInfoEntity>().set("publish_status", ProductConstant.StatusEnum.SPU_UP.getCode()).set("update_taime",new Date()).eq("id",spuId));//Feign调用流程/*** 1、构造请求数据,将对象转为json* 2、发送请求进行执行(执行成功会解码响应数据)* 3、执行请求会有重试机制* //默认重试机制是关闭状态* while(true){* * }*/}相关文章:
全文检索-ElasticSearch
1.基本概念 1.Index索引 动词:相当于MySQL中的insert; 名词:相当于MySQL中的DataBase; 2.Type(类型) 在Index(索引)中,可以定义一个或多个类型 类似于MySQL中的Tab…...

C编程惯用法:深入剖析与实战指南
C编程惯用法:深入剖析与实战指南 在C语言编程的浩瀚海洋中,掌握一些惯用法对于提升代码质量、增强可读性以及降低出错率至关重要。本文将从四个方面、五个方面、六个方面和七个方面,详细剖析C编程中的惯用法,帮助您更好地理解和应…...

MySQL数据表的设计
实际工程中, 对于数据表的设计和创建, 我们遵循以下步骤: 首先确定实体, 找到关键名词, 提取关键信息, 设计表有哪些列, 每一列是什么. (有几个实体, 一般就创建几个表, 一般一个表对应一个实体) 实体之间的关系: 1. 一对一关系 例如: 一个学生, 只能有一个账号; 一个账号只…...
Flutter开发效率提升1000%,Flutter Quick教程之对写好的Widget进行嵌套
通常写代码的时候,我们是先写好外面的Widget,再写里面的Widget。但是,也有的时候,我们写好了一个Widget,但是我们觉得有必要再在外面嵌套一个Widget,这时候应该怎么做呢?(还有其他方…...

2020编程语言排序:探索编程界的热门与趋势
2020编程语言排序:探索编程界的热门与趋势 在数字时代的浪潮中,编程语言作为构建数字世界的基石,其流行度和影响力不容忽视。2020年,各大编程语言在各自的领域里展现出独特的魅力和实力。本文将从四个方面、五个方面、六个方面和…...
提高工作效率的招数
自己的工作效率为啥比别人低,因为不会使用工具,这就是一个大冤种。 1.血泪教训,写代码调用第三方接口的时候已经要打印调用日志,不然扯皮真的难搞。 2.pg 上测试或的时候由于schema 错误mybatis会给你报空指针一样,还…...

css特殊效果和页面布局
特殊效果 圆角边框:div{border-radius: 20px 10px 50px 30px;} 四个属性值按顺时针排列,左上的1/4圆半径为20px,右上10,右下50,左下30。 div{border-radius: 20px;} 四角都为20px。 div{border-radius: 20px 10…...

JavaScript中对象的增删改查
1. 增(添加属性) let obj {}; // 添加一个属性 obj.name John Doe; // 或者使用方括号语法添加属性(这对于动态属性名很有用) let propName age; obj[propName] 30; console.log(obj); // 输出: { name: John Doe, …...
)
技术周总结 2024.05.27~06.02(java bean冲突 软件工程)
文章目录 一、05.28 周二1.1)问题01:java 引用的jar包中bean名称冲突了,怎么解决?1.2)问题02:使用SparkSession将json字符串转成 DataFrame 二、06.01 周六2.1)问题01:系统架构师考试…...
)
「前端+鸿蒙」核心技术HTML5+CSS3(八)
1、网站布局详解 网站布局是前端开发中的核心概念之一,它决定了网页的视觉结构和用户浏览的逻辑顺序。以下是几种常见的布局方式及其代码示例: 固定布局: 固定布局通常具有固定的宽度和高度,适用于传统的桌面视图。 <!DOCTYPE html> <html> <head><…...

15届蓝桥杯决赛,java b组,蒟蒻赛时所写的题思路
这次题的数量是10题,初赛是8题,还多了两题,个人感觉java b组的题意还是比较清晰的(不存在读不懂题的情况),但是时间感觉还是不够用,第4题一开始不会写,后面记起来写到结束也没调出来…...

2024蓝桥杯国赛C++研究生组游记+个人题解
Day0 开始复习,过了一遍大部分板子 本来打算再学一遍SAM,但是想到去年考了字符串大题今年应该不会再考了吧。。 过了一遍数据结构和图论,就1点了 两点的时候还没睡着,舍友打游戏好像打到2点过。。 Day1 相当困 第一题&…...
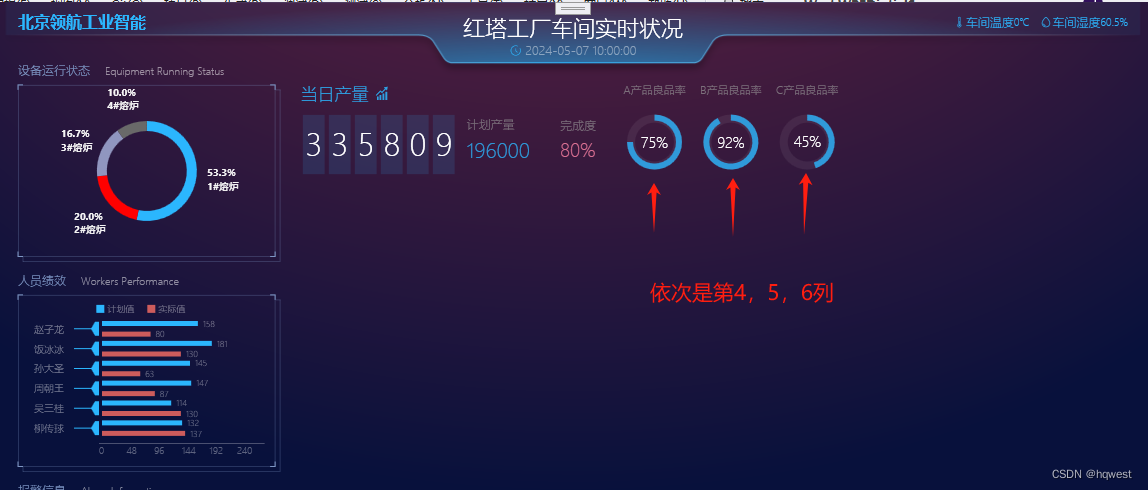
C#WPF数字大屏项目实战07--当日产量
1、第2列布局 第2列分三行,第一行分6列 2、当日产量布局 3、产量数据布局 运行效果 4、计划产量和完成度 运行效果 5、良品率布局 1、添加用户控件 2、用户控件绘制圆 2、使用用户控件 3、运行效果 4、注意点 这三个数值目前是静态的,可以由后台程序项…...
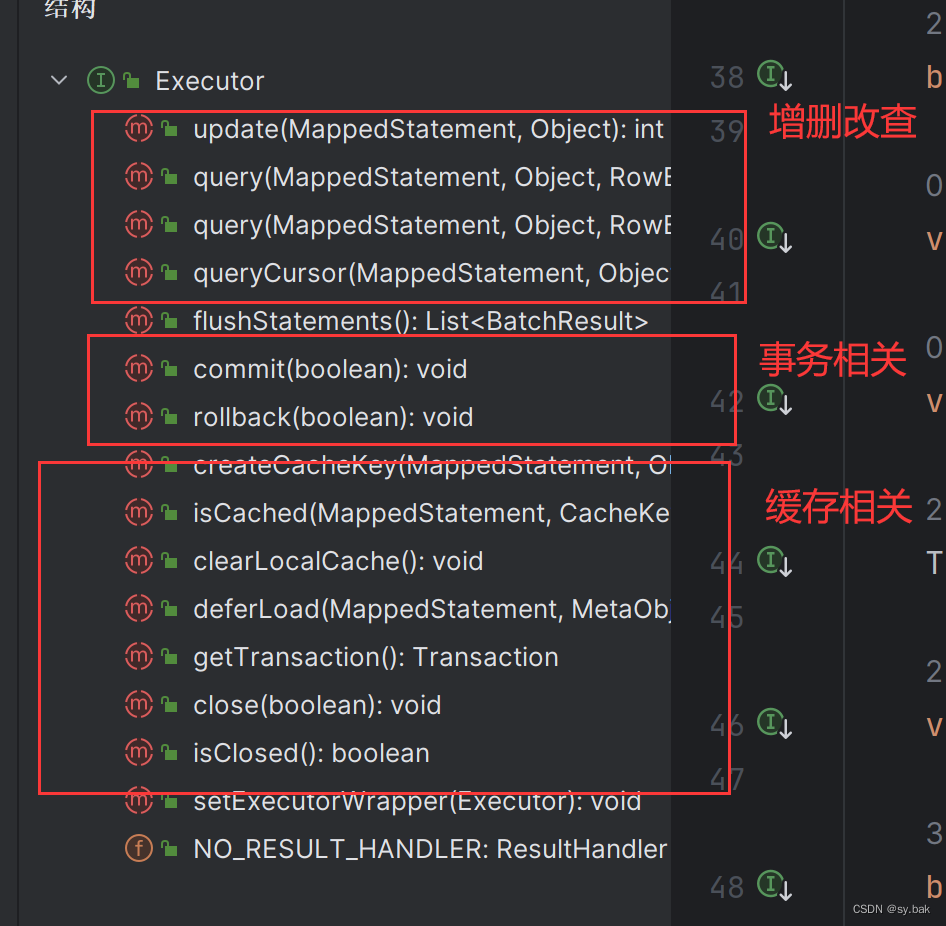
MyBatis源码分析--02:SqlSession建立过程
我们再来看看MyBatis使用流程: InputStream inputStream Resources.getResourceAsStream("myBatis_config.xml"); SqlSessionFactory sqlSessionFactory new SqlSessionFactoryBuilder().build(inputStream); SqlSession session sqlSessionFactory.op…...
SOUI Combobox 实现半透明弹出下拉框
SOUI默认情况下combobox的弹出框不是半透明的,这个时候如果背景透明时,滚动条会出现黑色背景,这个时候只需要在在combobox下添加一个子节点 <dropdownStyle translucent"1"></dropdownStyle> 这样一个窗口默认即实现…...
【含Python源码 MX_002期】)
Python 猜数系统 PyQt框架 有GUI界面 (源码在最后)【含Python源码 MX_002期】
一、系统简介 猜数界面是一个基于PyQt框架创建的简单图形用户界面(GUI),用于让用户参与猜数字游戏。简要介绍一下界面的各个部分: 游戏开始按钮:点击此按钮开始游戏。在点击前,需要在文本框中输入参与游戏…...
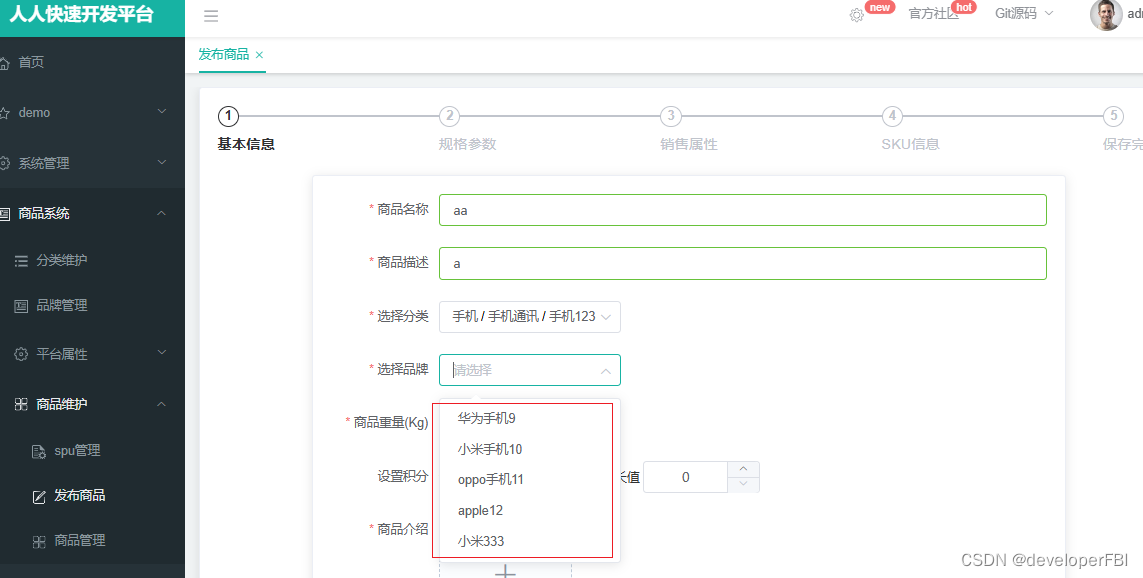
npm install pubsub-js报错的解决汇总
我在练习谷粒商城P83时,选择分类时触发向后端请求选择分类catId绑定的品牌数据,发现前端控制台报错: "PubSub is not definded",找不到pubsub。 因为缺少pubsub包,所以开始安装此包。 于是在网上一顿搜索猛如虎&…...
nuxt2:自定义指令 / v-xxx / directives / 理解 / 使用方法 / DEMO
一、理解自定义指令 在 vue 中提供了一些对于页面和数据更为方便的输出,这些操作就叫做指令,以 v-xxx 表示,比如 html 页面中的属性 <div v-xxx ></div>。自定义指令很大程度提高了开发效率,提高了工程化水平&#x…...

基础—SQL—DCL(数据控制语言)小结
一、总结 在SQL分类中的DCL语句部分,主要讲到了两个部分的知识。 1、用户管理 用户管理,主要是管理哪些用户可以访问当前 mysql 数据库。 包括:创建用户、修改用户密码以及删除用户 2、权限控制 权限管理,主要是控制我们当前用户…...

一文彻底讲透 PyTorch
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。 针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。 汇总合集…...

美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训
https://www.mckinsey.com/mgi/our-research/At-250-sustaining-Americas-competitive-edge 美国不断自我革新的历史,为这个国家面对充满巨大机遇却又充满不确定性的未来提供了引人深思的经验教训 这一切始于一场惊天动地的反抗行动。 1776年7月,来自13…...

抖音图片怎么去水印?2026年在线去水印工具+方法盘点,总有一款适合你
开篇:为什么要去水印? 保存抖音图片时,总会遇到水印的困扰。这些水印包含抖音logo、发布者名称,有时还会有账号信息。对于自媒体创作者、内容整理者或普通用户来说,去除水印往往是必需的。本文将介绍当下最实用的抖音图…...

智能路由器项目解析:基于策略路由实现多线路流量智能调度
1. 项目概述:一个“聪明”的路由器能做什么?最近在GitHub上看到一个挺有意思的项目,叫smart-router,作者是c0nSpIc0uS7uRk3r。光看名字,你可能会觉得这又是一个关于家庭网络优化的工具,但点进去仔细研究后&…...

5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager
5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是不是经常在右键文件时,面对几十个…...

MemPrivacy:面向端云智能体的隐私保护个性化记忆管理框架
之前文章介绍过:89.2%攻击成功率!腾讯、字节研究发现 OpenClaw Agent 存在可利用结构性漏洞 今天介绍一个 MemPrivacy 项目,来自 MemTensor、荣耀和同济大学的联合团队。 他们的研究让云端智能体能正常"记住你",但永远看…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

构建轻量级应用沙盒:Microverse原理与实践指南
1. 项目概述:一个轻量级、可移植的“微宇宙”开发沙盒最近在折腾一些边缘计算和嵌入式AI应用的原型验证,经常遇到一个头疼的问题:开发环境和部署环境不一致。在本地笔记本上跑得好好的Python脚本,放到树莓派或者Jetson Nano上&…...

Apache Burr框架:构建可观测有状态数据应用的核心原理与实践
1. 项目概述:一个用于构建和评估数据产品的Python框架如果你正在处理数据密集型应用,比如推荐系统、个性化广告或者任何需要根据用户行为实时调整策略的场景,你肯定遇到过这样的困境:模型训练和离线评估做得再好,一旦上…...

知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧
知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧 【免费下载链接】zhihu-api Zhihu API for Humans 项目地址: https://gitcode.com/gh_mirrors/zh/zhihu-api 在当今数据驱动的时代,知乎数据采集和Python API开发已成为获取高质量中文知识…...