大模型应用之基于Langchain的测试用例生成
一 用例生成实践效果
在组内的日常工作安排中,持续优化测试技术、提高测试效率始终是重点任务。近期,我们在探索实践使用大模型生成测试用例,期望能够借助其强大的自然语言处理能力,自动化地生成更全面和高质量的测试用例。
当前,公司已经普及使用JoyCoder,我们可以拷贝相关需求及设计文档的信息给到JoyCoder,让其生成测试用例,但在使用过程中有以下痛点:
1)仍需要多步人工操作:如复制粘贴文档,编写提示词,拷贝结果,保存用例等
2)响应时间久,结果不稳定:当需求或设计文档内容较大时,提示词太长或超出token限制
因此,我探索了基于Langchain与公司现有平台使测试用例可以自动、快速、稳定生成的方法,效果如下:
| 用例生成效果对比 | 使用JoyCoder | 基于Langchain自研 |
|---|---|---|
| 生成时长 (针对项目--文档内容较多) | ·10~20分钟左右,需要多次人工操作 (先会有一个提示:根据您提供的需求文档,下面是一个Markdown格式的测试用例示例。由于文档内容比较多,我将提供一个概括性的测试用例模板,您可以根据实际需求进一步细化每个步骤。) ·内容太多时,报错:The maximum default token limit has been reached、UNKNOWN ERROR:Request timed out. This may be due to the server being overloaded,需要人工尝试输入多少内容合适 | ·5分钟左右自动生成 (通过摘要生成全部测试点后,再通过向量搜索的方式生成需要细化的用例) ·内容太多时,可根据token文本切割后再提供给大模型 |
| 生成时长 (针对普通小需求) | 差别不大,1~5分钟 | |
| 准确度 | 依赖提示词内容,差别不大,但自研时更方便给优化好的提示词固化下来 | |
(什么是LangChain? 它是一个开源框架,用于构建基于大型语言模型(LLM)的应用程序。LLM 是基于大量数据预先训练的大型深度学习模型,可以生成对用户查询的响应,例如回答问题或根据基于文本的提示创建图像。LangChain 提供各种工具和抽象,以提高模型生成的信息的定制性、准确性和相关性。例如,开发人员可以使用 LangChain 组件来构建新的提示链或自定义现有模板。LangChain 还包括一些组件,可让 LLM 无需重新训练即可访问新的数据集。)
二 细节介绍
1 基于Langchain的测试用例生成方案
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 方案1:将全部产品需求和研发设计文档给到大模型,自动生成用例 | 用例内容相对准确 | 不支持特大文档,容易超出token限制 | 普通规模的需求及设计 |
| 方案2:将全部产品需求和研发设计文档进行摘要后,将摘要信息给到大模型,自动生成用例 | 进行摘要后无需担心token问题 | 用例内容不准确,大部分都只能是概况性的点 | 特大规模的需求及设计 |
| 方案3:将全部产品需求和研发设计文档存入向量数据库,通过搜索相似内容,自动生成某一部分的测试用例 | 用例内容更聚焦 无需担心token问题 | 不是全面的用例 | 仅对需求及设计中的某一部分进行用例生成 |
因3种方案使用场景不同,优缺点也可互补,故当前我将3种方式都实现了,提供大家按需调用。
2 实现细节
2.1 整体流程

2.2 技术细节说明
•pdf内容解析: :Langchain支持多种文件格式的解析,如csv、json、html、pdf等,而pdf又有很多不同的库可以使用,本次我选择PyMuPDF,它以功能全面且处理速度快为优势
•文件切割处理:为了防止一次传入内容过多,容易导致大模型响应时间久或超出token限制,利用Langchain的文本切割器,将文件分为各个小文本的列表形式
•Memory的使用:大多数 LLM 模型都有一个会话接口,当我们使用接口调用大模型能力时,每一次的调用都是新的一次会话。如果我们想和大模型进行多轮的对话,而不必每次重复之前的上下文时,就需要一个Memory来记忆我们之前的对话内容。Memory就是这样的一个模块,来帮助开发者可以快速的构建自己的应用“记忆”。本次我使用Langchain的ConversationBufferMemory与ConversationSummaryBufferMemory来实现,将需求文档和设计文档内容直接存入Memory,可减少与大模型问答的次数(减少大模型网关调用次数),提高整体用例文件生成的速度。ConversationSummaryBufferMemory主要是用在提取“摘要”信息的部分,它可以将将需求文档和设计文档内容进行归纳性总结后,再传给大模型
•向量数据库:利用公司已有的向量数据库测试环境Vearch,将文件存入。 在创建数据表时,需要了解向量数据库的检索模型及其对应的参数,目前支持六种类型,IVFPQ,HNSW,GPU,IVFFLAT,BINARYIVF,FLAT(详细区别和参数可点此链接),目前我选择了较为基础的IVFFLAT--基于量化的索引,后续如果数据量太大或者需要处理图数据时再优化。另外Langchain也有很方便的vearch存储和查询的方法可以使用
2.3 代码框架及部分代码展示
代码框架:
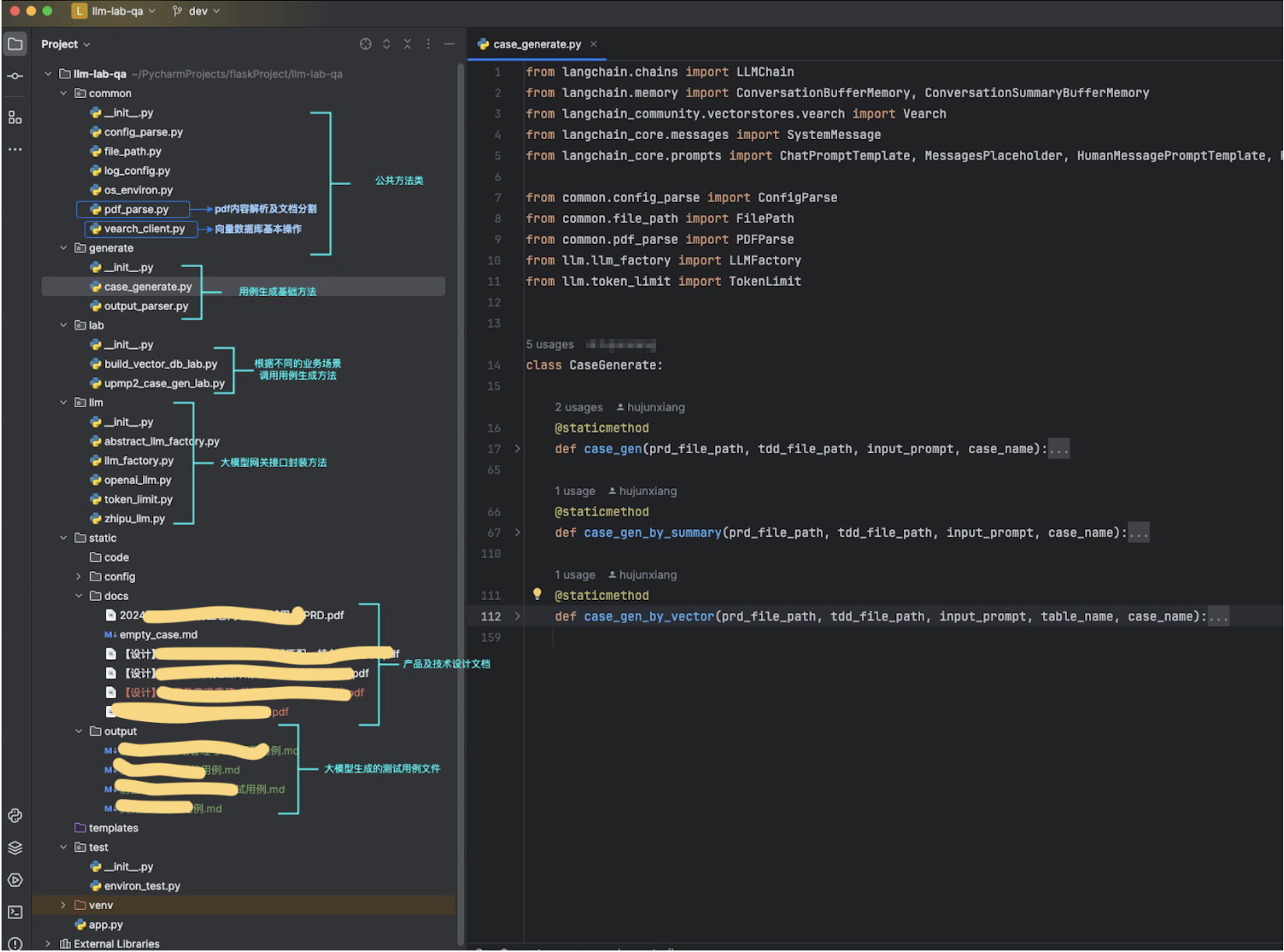
代码示例:
def case_gen(prd_file_path, tdd_file_path, input_prompt, case_name):"""用例生成的方法参数:prd_file_path - prd文档路径tdd_file_path - 技术设计文档路径case_name - 待生成的测试用例名称"""# 解析需求、设计相关文档, 输出的是document列表prd_file = PDFParse(prd_file_path).load_pymupdf_split()tdd_file = PDFParse(tdd_file_path).load_pymupdf_split()empty_case = FilePath.read_file(FilePath.empty_case)# 将需求、设计相关文档设置给memory作为llm的记忆信息prompt = ChatPromptTemplate.from_messages([SystemMessage(content="You are a chatbot having a conversation with a human."), # The persistent system promptMessagesPlaceholder(variable_name="chat_history"), # Where the memory will be stored.HumanMessagePromptTemplate.from_template("{human_input}"), # Where the human input will injected])memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)for prd in prd_file:memory.save_context({"input": prd.page_content}, {"output": "这是一段需求文档,后续输出测试用例需要"})for tdd in tdd_file:memory.save_context({"input": tdd.page_content}, {"output": "这是一段技术设计文档,后续输出测试用例需要"})# 调大模型生成测试用例llm = LLMFactory.get_openai_factory().get_chat_llm()human_input = "作为软件测试开发专家,请根据以上的产品需求及技术设计信息," + input_prompt + ",以markdown格式输出测试用例,用例模版是" + empty_casechain = LLMChain(llm=llm,prompt=prompt,verbose=True,memory=memory,)output_raw = chain.invoke({'human_input': human_input})# 保存输出的用例内容,markdown格式file_path = FilePath.out_file + case_name + ".md"with open(file_path, 'w') as file:file.write(output_raw.get('text')) def case_gen_by_vector(prd_file_path, tdd_file_path, input_prompt, table_name, case_name):"""!!!当文本超级大时,防止token不够,通过向量数据库,搜出某一部分的内容,生成局部的测试用例,细节更准确一些!!!参数:prd_file_path - prd文档路径tdd_file_path - 技术设计文档路径table_name - 向量数据库的表名,分业务存储,一般使用业务英文唯一标识的简称case_name - 待生成的测试用例名称"""# 解析需求、设计相关文档, 输出的是document列表prd_file = PDFParse(prd_file_path).load_pymupdf_split()tdd_file = PDFParse(tdd_file_path).load_pymupdf_split()empty_case = FilePath.read_file(FilePath.empty_case)# 把文档存入向量数据库docs = prd_file + tdd_fileembedding_model = LLMFactory.get_openai_factory().get_embedding()router_url = ConfigParse(FilePath.config_file_path).get_vearch_router_server()vearch_cluster = Vearch.from_documents(docs,embedding_model,path_or_url=router_url,db_name="y_test_qa",table_name=table_name,flag=1,)# 从向量数据库搜索相关内容docs = vearch_cluster.similarity_search(query=input_prompt, k=1)content = docs[0].page_content# 使用向量查询的相关信息给大模型生成用例prompt_template = "作为软件测试开发专家,请根据产品需求技术设计中{input_prompt}的相关信息:{content},以markdown格式输出测试用例,用例模版是:{empty_case}"prompt = PromptTemplate(input_variables=["input_prompt", "content", "empty_case"],template=prompt_template)llm = LLMFactory.get_openai_factory().get_chat_llm()chain = LLMChain(llm=llm,prompt=prompt,verbose=True)output_raw = chain.invoke({'input_prompt': input_prompt, 'content': content, 'empty_case': empty_case})# 保存输出的用例内容,markdown格式file_path = FilePath.out_file + case_name + ".md"with open(file_path, 'w') as file:file.write(output_raw.get('text'))
三 效果展示
3.1 实际运用到需求/项目的效果
用例生成后是否真的能帮助我们节省用例设计的时间,是大家重点关注的,因此我随机在一个小型需求中进行了实验,此需求的PRD文档总字数2363,设计文档总字数158(因大部分是流程图),结果如下:
| 用例设计环节,测试时间(人日)占用效果分析 | 可自动生成用例之前 | 可自动生成用例之后 |
|---|---|---|
| 分析需求&理解技术设计 | 0.5 | 0.25 |
| 与产研确认细节 | 0.25 | 0.25 |
| 设计及编写用例 | 1(39例) | 0.5(45例=25例自动生成+20例人工修正/补充) |
| 评审及用例差缺补漏 | 0.5 | 0.25 |
| 总计(效率提升50%) | 2.5人日 | 1.25人日 |
本次利用大模型自动生成用例的优缺点:
优势:
•全面快速的进行了用例的逻辑点划分,协助测试分析理解需求及设计
•降低编写测试用例的时间,人工只需要进行内容确认和细节调整
•用例内容更加全面丰富,在用例评审时,待补充的点变少了,且可以有效防止漏测
•如测试人员仅负责一部分功能的测试,也可通过向量数据库搜索的形式,聚焦部分功能的生成
劣势:
•暂时没实现对流程图的理解,当文本描述较少时,生成内容有偏差
•对于有丰富经验的测试人员,自动生成用例的思路可能与自己习惯的思路不一致,需要自己再调整或适应
四 待解决问题及后续计划
1.对于pdf中的流程图(图片形式),实现了文字提取识别(langchain pdf相关的方法支持了ocr识别),后续需要找到更适合解决图内容的解析、检索的方式。
2.生成用例只是测试提效的一小部分,后续需要尝试将大模型应用与日常测试过程,目前的想法有针对diff代码和服务器日志的分析来自动定位缺陷、基于模型驱动测试结合知识图谱实现的自动化测试等方向。
相关文章:
大模型应用之基于Langchain的测试用例生成
一 用例生成实践效果 在组内的日常工作安排中,持续优化测试技术、提高测试效率始终是重点任务。近期,我们在探索实践使用大模型生成测试用例,期望能够借助其强大的自然语言处理能力,自动化地生成更全面和高质量的测试用例。 当前…...

C++之map
1、标准库的map类型 2、插入数据 #include <map> #include <string> #include <iostream>using namespace std;int main() {map<string, int> mapTest;// 插入到map容器内部的元素是默认按照key从小到大来排序// key类型一定要重载小于号<运算符map…...

【量算分析工具-方位角】GeoServer改造Springboot番外系列六
【量算分析工具-概述】GeoServer改造Springboot番外系列三-CSDN博客 【量算分析工具-水平距离】GeoServer改造Springboot番外系列四-CSDN博客 【量算分析工具-水平面积】GeoServer改造Springboot番外系列五-CSDN博客 【量算分析工具-方位角】GeoServer改造Springboot番外系列…...

【机器学习】机器学习与大模型在人工智能领域的融合应用与性能优化新探索
文章目录 引言机器学习与大模型的基本概念机器学习概述监督学习无监督学习强化学习 大模型概述GPT-3BERTResNetTransformer 机器学习与大模型的融合应用自然语言处理文本生成文本分类机器翻译 图像识别自动驾驶医学影像分析 语音识别智能助手语音转文字 大模型性能优化的新探索…...

上传图片并显示#Vue3#后端接口数据
上传图片并显示#Vue3#后端接口数据 效果: 上传并显示图片 代码: <!-- 上传图片并显示 --> <template><!-- 上传图片start --><div><el-form><el-form-item><el-uploadmultipleclass"avatar-uploader&quo…...

音视频开发14 FFmpeg 视频 相关格式分析 -- H264 NALU格式分析
H264简介-也叫做 AVC H.264,在MPEG的标准⾥是MPEG-4的⼀个组成部分–MPEG-4 Part 10,⼜叫Advanced Video Codec,因此常常称为MPEG-4 AVC或直接叫AVC。 原始数据YUV,RGB为什么要压缩-知道就行 在⾳视频传输过程中,视频⽂件的传输…...
Qt学习记录(15)数据库
目录 前言: 数据库连接 项目文件加上sql 打印查看Qt支持哪些数据库驱动 QMYSQL [static] QSqlDatabase QSqlDatabase::addDatabase(const QString &type, const QString &connectionName QLatin1String(defaultConnection)) 数据库插入 头文件.h 源…...

c++常用设计模式
1、单例模式(Singleton):保证一个类只有一个实例,提供一个全局访问点; class Singleton { private:static Singleton* instance;Singleton() {}public:static Singleton* getInstance() {if (instance nullptr) {instance new Singleton()…...

【动手学深度学习】softmax回归从零开始实现的研究详情
目录 🌊1. 研究目的 🌊2. 研究准备 🌊3. 研究内容 🌍3.1 softmax回归的从零开始实现 🌍3.2 基础练习 🌊4. 研究体会 🌊1. 研究目的 理解softmax回归的原理和基本实现方式;学习…...
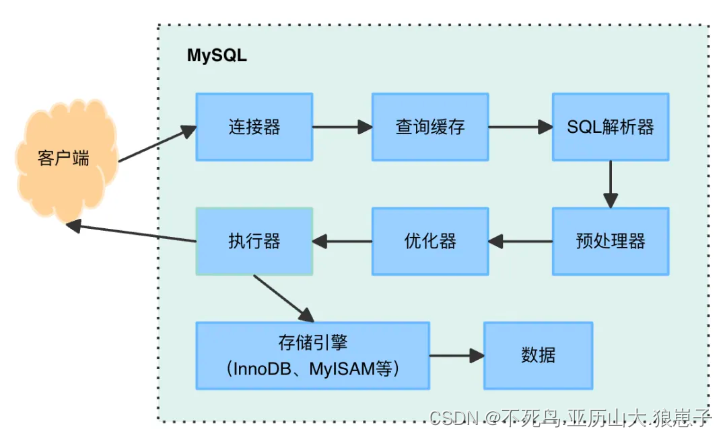
MySQL:MySQL执行一条SQL查询语句的执行过程
当多个客户端同时连接到MySQL,用SQL语句去增删改查数据,针对查询场景,MySQL要保证尽可能快地返回客户端结果。 了解了这些需求场景,我们可能会对MySQL进行如下设计: 其中,连接器管理客户端的连接,负责管理连接、认证鉴权等;查询缓存则是为了加速查询,命中则直接返回结…...

解决Python导入第三方模块报错“TypeError: the first argument must be callable”
注意以下内容只对导包时遇到同样的报错会有参考价值。 问题描述 当你尝试导入第三方模块时,可能会遇到如下报错信息: TypeError: the first argument must be callable 猜测原因 经过仔细检查代码,我猜测这个错误的原因是由于变量名冲突所…...

在python中连接了数据库后想要在python中通过图形化界面显示数据库的查询结果,请问怎么实现比较好? /ttk库的treeview的使用
在Python中,你可以使用图形用户界面(GUI)库来显示数据库的查询结果。常见的GUI库包括Tkinter(Python自带)、PyQt、wxPython等。以下是一个使用Tkinter库来显示数据库查询结果的简单示例。 首先,你需要确保…...
OZON的选品工具,OZON选品工具推荐
在电商领域,选品一直是决定卖家成功与否的关键因素之一。随着OZON平台的崛起,越来越多的卖家开始关注并寻求有效的选品工具,以帮助他们在这个竞争激烈的市场中脱颖而出。本文将详细介绍OZON的选品工具,并推荐几款实用的辅助工具&a…...
营销方案撰写秘籍:包含内容全解析,让你的方案脱颖而出
做了十几年品牌,策划出身,混迹过几个知名广告公司,个人经验供楼主参考。 只要掌握以下这些营销策划案的要点,你就能制作出既全面又专业的策划案,让你的工作成果不仅得到同事的认可,更能赢得老板的赏识&…...
如何制作一本温馨的电子相册呢?
随着科技的不断发展,电子相册已经成为了一种流行的方式来记录和分享我们的生活。一张张照片,一段段视频,都能让我们回忆起那些温馨的时光。那么,如何制作一本温馨的电子相册呢? 首先,选择一款合适的电子相册…...

485通讯网关
在工业自动化与智能化的浪潮中,数据的传输与交互显得尤为重要。作为这一领域的核心设备,485通讯网关凭借其卓越的性能和广泛的应用场景,成为了连接不同设备、不同协议之间数据转换和传输的桥梁。在众多485通讯网关中,HiWoo Box以其…...

Anaconda中的常用科学计算工具
Anaconda中的常用科学计算工具 Anaconda是一个流行的Python科学计算环境,它提供了大量的科学计算工具,这些工具可以帮助用户进行数据分析、机器学习、深度学习等任务。以下是一些常见的Anaconda中的科学计算工具: NumPy:一个用于…...
Java 中BigDecimal传到前端后精度丢失问题
1.用postman访问接口,返回的小数点精度正常 2.返回到页面里的,小数点丢失 3.解决办法,在字段上加注解 JsonFormat(shape JsonFormat.Shape.STRING) 或者 JsonSerialize(using ToStringSerializer.class) import com.fasterxml.jackson.a…...

在Linux/Ubuntu/Debian上安装TensorFlow 2.14.0
在Ubuntu上安装TensorFlow 2.14.0,可以遵循以下步骤。请注意,由于TensorFlow的版本更新可能很快,这里提供的具体步骤可能需要根据你的系统环境和实际情况进行微调。 准备工作 检查系统要求:确保你的Ubuntu系统满足TensorFlow的运…...

多语言for循环遍历总结
多语言for循环遍历总结 工作中经常需要遍历对象,但不同编程语言之间存在一些细微差别。为了便于比较和参考,这里对一些常用的遍历方法进行了总结。 JAVA 数组遍历 Test void ArrayForTest() {String[] array {"刘备","关羽", &…...

实战react项目:基于快马ai快速构建包含图表与导航的用户数据仪表盘
最近在做一个用户数据仪表盘项目,正好用React配合Ant Design实现了一套完整的界面。这种包含导航、图表和动态数据的页面在后台系统中很常见,记录下我的实现思路和踩坑经验。 项目结构规划 首先用create-react-app初始化项目,然后按功能模块…...

League-Toolkit技术解析:从原理到实践的全方位指南
League-Toolkit技术解析:从原理到实践的全方位指南 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-Toolkit是一…...

DSQC346G 3HAB8101-8 机器人伺服驱动单元
DSQC346G 3HAB8101‑8 机器人伺服驱动单元介绍DSQC346G(3HAB8101‑8)是一款专用于工业机器人伺服系统的驱动单元,用于控制伺服电机的运动与输出,实现机器人关节或轴的精确位置、速度和力矩控制,是机器人驱动链中的核心…...

5个效率提升技巧:Cursor AI功能优化指南
5个效率提升技巧:Cursor AI功能优化指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial request li…...

零基础玩转像素心智:手把手教你用情绪解码器分析用户评论
零基础玩转像素心智:手把手教你用情绪解码器分析用户评论 1. 认识像素心智情绪解码器 1.1 什么是情绪解码器 像素心智情绪解码器(Pixel Mind Decoder)是一款基于M2LOrder核心引擎构建的AI情绪识别工具。它将复杂的自然语言处理技术封装在一个充满复古游戏风格的1…...

对于多轮对话中的对话策略优化,OpenClaw 的在线强化学习更新频率?
关于OpenClaw在多轮对话中对话策略的在线强化学习更新频率,其实并没有一个公开的、固定的官方数字。这倒不是因为它是什么秘密,而是因为这类系统的更新机制往往不是按“每隔几秒一次”这样刻板的方式来运作的。它更像是一个动态调整的过程,取…...

Visio高效安装与激活全攻略:从零开始到成功运行
1. Visio安装前的准备工作 第一次安装Visio的朋友们,我强烈建议先做好这些准备工作。我自己在帮同事安装Visio时,经常遇到因为前期准备不足导致安装失败的情况。首先,检查你的电脑是否已经安装了其他版本的Office软件。如果之前安装过Office …...

用STM32F103C8T6和F9P模组DIY一台RTK无人车:从蓝牙遥控到自主导航的保姆级教程
用STM32F103C8T6和F9P模组打造高精度RTK无人车:从零构建到自主导航全流程解析 在创客圈子里,能够自主导航的智能小车一直是热门项目。但传统基于普通GPS的方案定位精度往往在米级徘徊,难以实现真正的精准控制。而将RTK(实时动态定…...

从大疆NAZA换到匿名P2飞控:一个DIY玩家的真实体验与参数调试避坑指南
从大疆NAZA到匿名P2飞控:一位DIY玩家的深度迁移指南 当我的F450机架在狭小卧室里显得笨拙不堪时,我意识到需要一次彻底的"瘦身计划"。这不是简单的机架更换,而是一次从商业飞控到开源系统的完整迁移——将大疆NAZA积累的经验移植到…...

万象视界灵坛快速部署:GitLab CI流水线自动触发镜像构建与K8s滚动更新
万象视界灵坛快速部署:GitLab CI流水线自动触发镜像构建与K8s滚动更新 1. 项目概述 万象视界灵坛(Omni-Vision Sanctuary)是一款基于OpenAI CLIP技术的高级多模态智能感知平台。该平台通过创新的像素风格界面,将复杂的语义对齐过…...