Apache Doris 基础 -- 数据表设计(数据模型)
Versions: 2.1
1、模型概览
本主题从逻辑角度介绍了Doris中的数据模型,以便您可以在不同的业务场景中更好地使用Doris。
基本概念
本文主要从逻辑的角度描述Doris的数据模型,旨在帮助用户在不同的场景更好地利用Doris。
在Doris中,数据在逻辑上以表的形式表示。表由行和列组成。行(Row)表示来自用户的单个数据条目。这一行包含一组相关的值,这些值表示表的列(Column)定义的不同属性或字段。
列可以大致分为两种类型:键(Key)和值(Value)。从业务角度来看,Key和Value可以分别对应于维度列和度量列。在Doris中,Key列是在表创建语句中指定的列。在表创建语句中,唯一键(unique key)、聚合键(aggregate key)或重复键(duplicate key)后面的列被认为是键列,而其余列是值列。
Doris中的数据模型主要分为三种类型:
- 重复(Duplicate):此数据模型允许基于指定的键列存储重复行。它适用于必须保留所有原始数据记录的场景。
- 唯一性(Unique):在此数据模型中,每一行都由键列中的值组合唯一标识。这确保给定的键值集不存在重复行。
- 聚合(Aggregate):该模型支持基于键列的数据聚合。它通常用于需要汇总或聚合信息(如总数或平均值)的场景。
2、Duplicate Key Model
在某些多维分析场景中,数据缺少主键和聚合需求。对于这些情况,可以使用重复数据模型。
在Duplicate Data Model中,数据按照导入文件中出现的样子精确地存储,没有任何聚合。即使两行数据相同,也将保留这两行数据。在表创建语句中指定的Duplicate Key仅用于指示数据在存储期间应按哪些列排序。建议选择前2-4列作为“Duplicate Key”。
例如,考虑一个包含以下数据列的表,它不需要主键更新或基于聚合键的聚合:
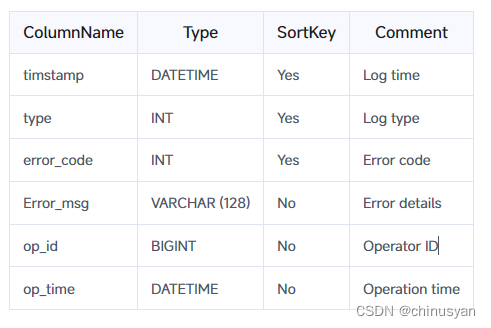
如果在创建表时没有指定数据模型(Unique、Aggregate或Duplicate),则默认创建Duplicate模型表,并根据一定的规则自动选择排序列。例如,在下面的表创建语句中,如果没有指定数据模型,则会建立一个Duplicate模型表,系统将自动选择前三列作为排序列。
CREATE TABLE IF NOT EXISTS example_tbl_by_default
(`timestamp` DATETIME NOT NULL COMMENT "Log time",`type` INT NOT NULL COMMENT "Log type",`error_code` INT COMMENT "Error code",`error_msg` VARCHAR(1024) COMMENT "Error detail message",`op_id` BIGINT COMMENT "Operator ID",`op_time` DATETIME COMMENT "Operation time"
)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);MySQL > desc example_tbl_by_default;
+------------+---------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-------+---------+-------+
| timestamp | DATETIME | No | true | NULL | NONE |
| type | INT | No | true | NULL | NONE |
| error_code | INT | Yes | true | NULL | NONE |
| error_msg | VARCHAR(1024) | Yes | false | NULL | NONE |
| op_id | BIGINT | Yes | false | NULL | NONE |
| op_time | DATETIME | Yes | false | NULL | NONE |
+------------+---------------+------+-------+---------+-------+
6 rows in set (0.01 sec)
没有排序列的默认复制模型(V2.0起)
当用户没有排序需求时,他们可以向表属性添加以下配置。这样,在创建默认Duplicate模型时,系统将不会自动选择任何排序列。
"enable_duplicate_without_keys_by_default" = "true"
CREATE TABLE语句对应如下:
CREATE TABLE IF NOT EXISTS example_tbl_duplicate_without_keys_by_default
(`timestamp` DATETIME NOT NULL COMMENT "Log time",`type` INT NOT NULL COMMENT "Log type",`error_code` INT COMMENT "Error code",`error_msg` VARCHAR(1024) COMMENT "Error detail message",`op_id` BIGINT COMMENT "Operator ID",`op_time` DATETIME COMMENT "Operation time"
)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_duplicate_without_keys_by_default" = "true"
);MySQL > desc example_tbl_duplicate_without_keys_by_default;
+------------+---------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-------+---------+-------+
| timestamp | DATETIME | No | false | NULL | NONE |
| type | INT | No | false | NULL | NONE |
| error_code | INT | Yes | false | NULL | NONE |
| error_msg | VARCHAR(1024) | Yes | false | NULL | NONE |
| op_id | BIGINT | Yes | false | NULL | NONE |
| op_time | DATETIME | Yes | false | NULL | NONE |
+------------+---------------+------+-------+---------+-------+
6 rows in set (0.01 sec)
有排序列复制模型
在表创建语句中,可以指定Duplicate Key来指示数据存储应该根据这些键列进行排序。选择“Duplicate Key”时,建议选择前2 ~ 4列。
表创建语句的示例如下,它根据timestamp、type和error_code列指定排序。
CREATE TABLE IF NOT EXISTS example_tbl_duplicate
(`timestamp` DATETIME NOT NULL COMMENT "Log time",`type` INT NOT NULL COMMENT "Log type",`error_code` INT COMMENT "Error code",`error_msg` VARCHAR(1024) COMMENT "Error detail message",`op_id` BIGINT COMMENT "Operator ID",`op_time` DATETIME COMMENT "Operation time"
)
DUPLICATE KEY(`timestamp`, `type`, `error_code`)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);MySQL > desc example_tbl_duplicate;
+------------+---------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-------+---------+-------+
| timestamp | DATETIME | No | true | NULL | NONE |
| type | INT | No | true | NULL | NONE |
| error_code | INT | Yes | true | NULL | NONE |
| error_msg | VARCHAR(1024) | Yes | false | NULL | NONE |
| op_id | BIGINT | Yes | false | NULL | NONE |
| op_time | DATETIME | Yes | false | NULL | NONE |
+------------+---------------+------+-------+---------+-------+
6 rows in set (0.01 sec)
数据将按照导入文件中的原始数据进行存储,不进行任何聚合。即使两行数据完全相同,系统也会保留它们。在表创建语句中指定的Duplicate Key仅用于指示在数据存储期间应使用哪些列进行排序。选择“Duplicate Key”时,建议选择前2 ~ 4列。
3、Unique Key Model
当用户有数据更新需求时,他们可以选择使用Unique数据模型。唯一性模型可以保证主键的唯一性。当用户更新数据时,新写入的数据将用相同的主键覆盖旧数据。
Unique数据模型提供了两种实现方法:
- Merge-on-read。
当用户写入数据时,不会触发重复数据删除相关操作。所有的重复数据删除操作都在查询或压缩过程中执行。因此,merge-on-read 的写性能较好,查询性能较差,内存消耗也较高。 - Merge-on-write。在1.2版本中,我们引入了写时合并(merge-on-write)实现,它在数据写入阶段完成所有的重复数据删除任务,从而提供了出色的查询性能。从2.0版本开始,写时合并已经变得非常成熟和稳定。由于其出色的查询性能,我们建议大多数用户选择此实现。从2.1版本开始,写时合并已经成为Unique模型的默认实现。
Unique模型的默认更新语义是全行UPSERT(full-row UPSERT),代表UPDATE或INSERT。如果行数据的键存在,则执行更新;如果不存在,则插入新数据。在全行UPSERT语义下,即使用户使用INSERT INTO指定要写入的部分列,Doris也会用NULL值或Planner中的默认值填充未提供的列。
如果用户希望更新部分字段,他们需要使用写时合并实现,并通过特定参数启用对部分列更新的支持。请参阅Data Operate/Data Update部分了解更多细节。
让我们以一个典型的用户基本信息表为例,看看如何创建一个具有读时合并和写时合并的Unique模型表。该表没有聚合要求,只需要保证主键的唯一性(主键为user_id + username)。
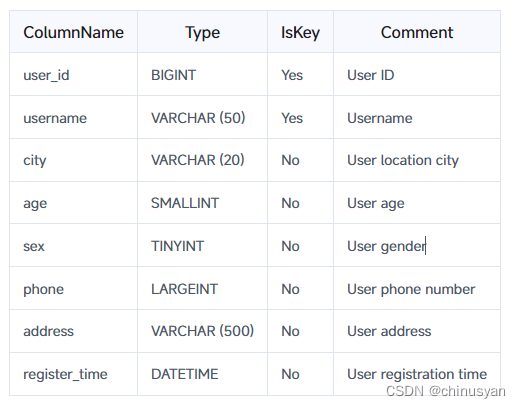
Merge-on-Read
Merge-on-read的表创建语句如下:
CREATE TABLE IF NOT EXISTS example_tbl_unique
(`user_id` LARGEINT NOT NULL COMMENT "User ID",`username` VARCHAR(50) NOT NULL COMMENT "Username",`city` VARCHAR(20) COMMENT "User location city",`age` SMALLINT COMMENT "User age",`sex` TINYINT COMMENT "User gender",`phone` LARGEINT COMMENT "User phone number",`address` VARCHAR(500) COMMENT "User address",`register_time` DATETIME COMMENT "User registration time"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
Merge-on-Write
写时合并的表创建语句如下:
CREATE TABLE IF NOT EXISTS example_tbl_unique_merge_on_write
(`user_id` LARGEINT NOT NULL COMMENT "User ID",`username` VARCHAR(50) NOT NULL COMMENT "Username",`city` VARCHAR(20) COMMENT "User location city",`age` SMALLINT COMMENT "User age",`sex` TINYINT COMMENT "User gender",`phone` LARGEINT COMMENT "User phone number",`address` VARCHAR(500) COMMENT "User address",`register_time` DATETIME COMMENT "User registration time"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true"
);
用户需要在创建表时添加enable_unique_key_merge_on_write" = "true"属性来启用写合并。
"enable_unique_key_merge_on_write" = "true"
在版本2.1中,写时合并将是主键模型的默认方法。
对于新用户,强烈建议使用2.0或更高版本。在2.0版本中,merge-on-write的性能和稳定性得到了显著的改进和优化。
对于1.2版本的用户:
- 建议使用1.2.4或更高版本,该版本修复了一些错误和稳定性问题。
- 在
be.conf中增加配置项disable_storage_page_cache=false。不加该配置项,可能会对数据导入性能造成较大影响。
使用注意事项:
- Unique模型的实现只能在表创建期间确定,不能通过模式更改进行修改。
- 读时合并表不能无缝地升级到写时合并表(由于完全不同的数据组织方法)。如果您需要切换到Merge-on-write,您必须手动执行
INSERT INTO unique-mow-table SELECT * FROM source_table来重新导入数据。 - Whole-row Updates:Unique模型的默认更新语义是整行UPSERT,它代表
UPDATE OR INSERT。如果一行数据的键存在,它将被更新;如果不存在,则插入新数据。在整行UPSERT语义下,即使用户使用INSERT INTO只指定要插入的某些列,Doris也会用NULL值或计划阶段的默认值填充未提供的列。 - Partial Column Updates: 如果用户希望只更新某些字段,他们必须使用Merge-on-write,并通过特定参数启用对部分列更新的支持。请参考部分列更新的文档以获得相关的使用建议。
4、Aggregate Key Model
以下是演示聚合模型是什么以及如何正确使用它的实际示例。
Importing Data Aggregation
假设业务具有以下数据表模式:
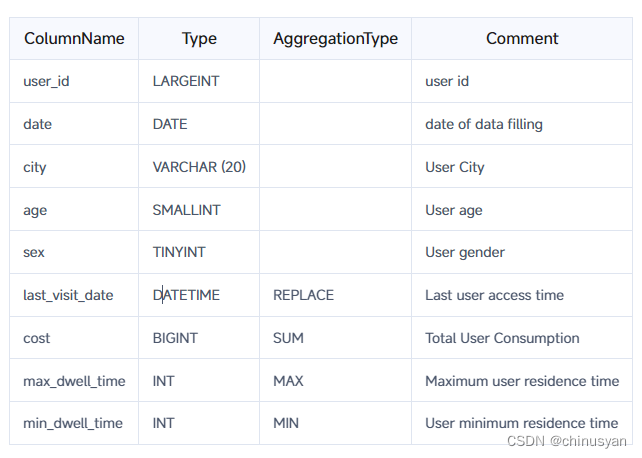
与CREATE TABLE语句对应的语句如下(省略Partition和Distribution信息):
CREATE DATABASE IF NOT EXISTS example_db;CREATE TABLE IF NOT EXISTS example_db.example_tbl_agg1
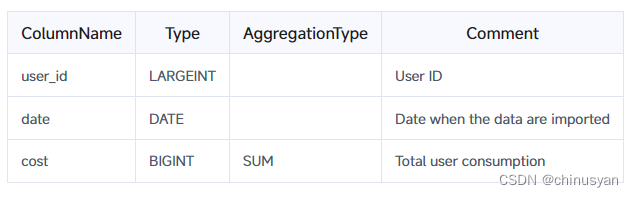
(`user_id` LARGEINT NOT NULL COMMENT "user id",`date` DATE NOT NULL COMMENT "data import time",`city` VARCHAR(20) COMMENT "city",`age` SMALLINT COMMENT "age",`sex` TINYINT COMMENT "gender",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "last visit date time",`cost` BIGINT SUM DEFAULT "0" COMMENT "user total cost",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "user max dwell time",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "user min dwell time"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
如您所见,这是一个典型的用户信息和访问行为事实表。在星型模型中,用户信息和访问行为通常分别存储在维度表和事实表中。这里,为了便于解释,我们将这两种类型的信息存储在一个表中。
表中的列根据是否使用AggregationType设置,分为Key(维度列)和Value(指标列)列。键列没有AggregationType,例如user_id、date和age,而值列有AggregationType。
在导入数据时,在Key列中具有相同内容的行将聚合为一行,并且它们在Value列中的值将按照其AggregationType指定的方式聚合。目前,有几种聚合方法和“agg_state”选项可用:
-
SUM: Accumulate the values in multiple rows.
-
REPLACE: The newly imported value will replace the previous value.
-
MAX: Keep the maximum value.
-
MIN: Keep the minimum value.
-
REPLACE_IF_NOT_NULL: Non-null value replacement. Unlike -
REPLACE, it does not replace null values. -
HLL_UNION: Aggregation method for columns of HLL type, using the HyperLogLog algorithm for aggregation.
-
BITMAP_UNION: Aggregation method for columns of BITMAP type, performing a union aggregation of bitmaps.
如果这些聚合方法不能满足需求,您可以选择使用“agg_state”类型。
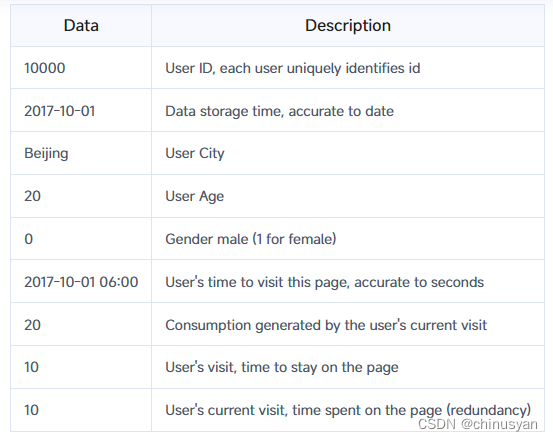
假设您有以下导入数据(原始数据):
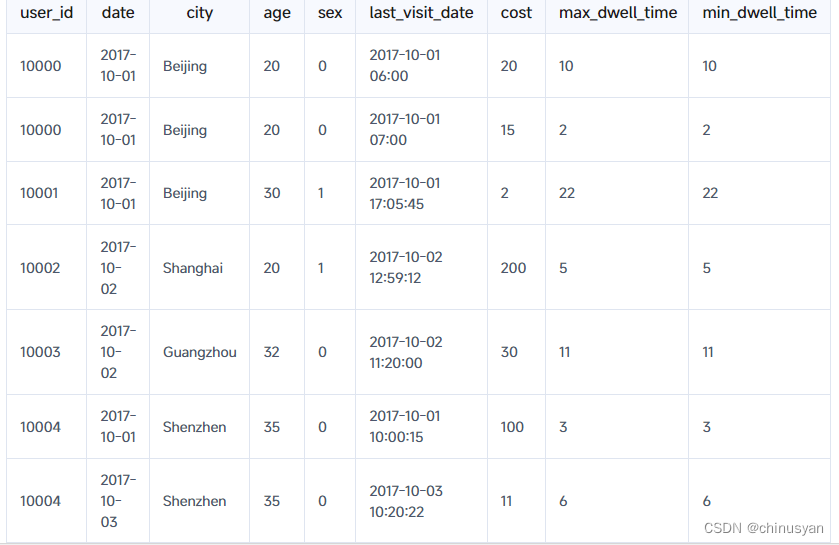
你可以用下面的sql来导入数据:
insert into example_db.example_tbl_agg1 values
(10000,"2017-10-01","Beijing",20,0,"2017-10-01 06:00:00",20,10,10),
(10000,"2017-10-01","Beijing",20,0,"2017-10-01 07:00:00",15,2,2),
(10001,"2017-10-01","Beijing",30,1,"2017-10-01 17:05:45",2,22,22),
(10002,"2017-10-02","Shanghai",20,1,"2017-10-02 12:59:12",200,5,5),
(10003,"2017-10-02","Guangzhou",32,0,"2017-10-02 11:20:00",30,11,11),
(10004,"2017-10-01","Shenzhen",35,0,"2017-10-01 10:00:15",100,3,3),
(10004,"2017-10-03","Shenzhen",35,0,"2017-10-03 10:20:22",11,6,6);
这是一个记录用户在访问某个商品页面时的行为的表格。以第一行数据为例,解释如下:
此批数据正确导入Doris后,将在Doris中保存如下:
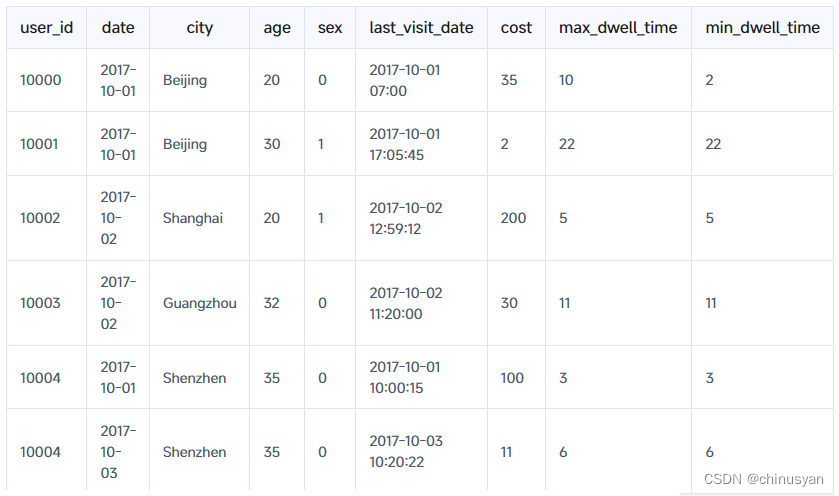
用户10000的数据被聚合到一行,而其他用户的数据保持不变。对于用户10000的聚合数据的解释如下(前5列保持不变,所以从第6列last_visit_date开始):
- 第6列的值为2017-10-01 07:00:
last_visit_date列通过REPLACE进行聚合,因此2017-10-01 07:00取代了2017-10-01 06:00。 - 第7列中的值为35:
cost列通过SUM进行聚合,因此更新值35是20 + 15的结果。 - 第8列中的值为10:
max_dwell_time列是由MAX聚合的,因此10被保存为10到2之间的最大值。 - 第9列中的值为2:
min_dwell_time列由MIN聚合,因此2被保存为10到2之间的最小值。
聚合后,Doris只存储聚合后的数据。换句话说,详细的原始数据将不再可用。
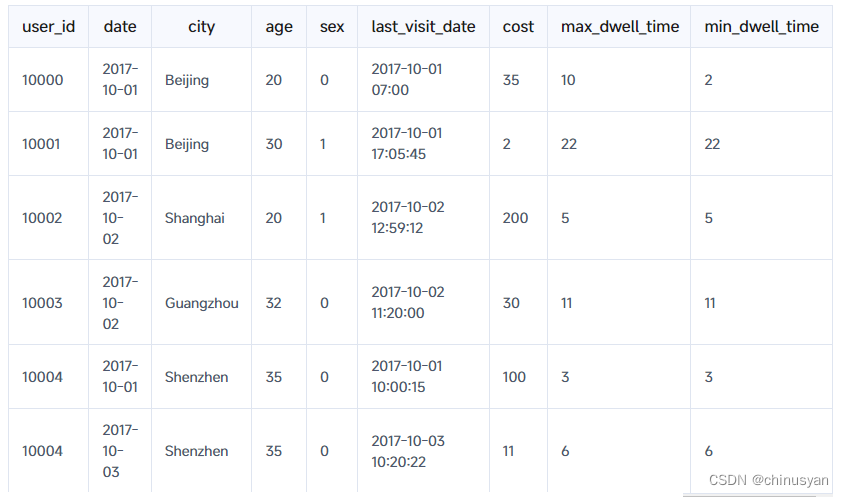
导入数据并与现有数据聚合
假设表中已经包含了之前导入的数据:
现在导入新一批数据:
insert into example_db.example_tbl_agg1 values
(10004,"2017-10-03","Shenzhen",35,0,"2017-10-03 11:22:00",44,19,19),
(10005,"2017-10-03","Changsha",29,1,"2017-10-03 18:11:02",3,1,1);
导入后,存储在Doris中的数据会更新如下:
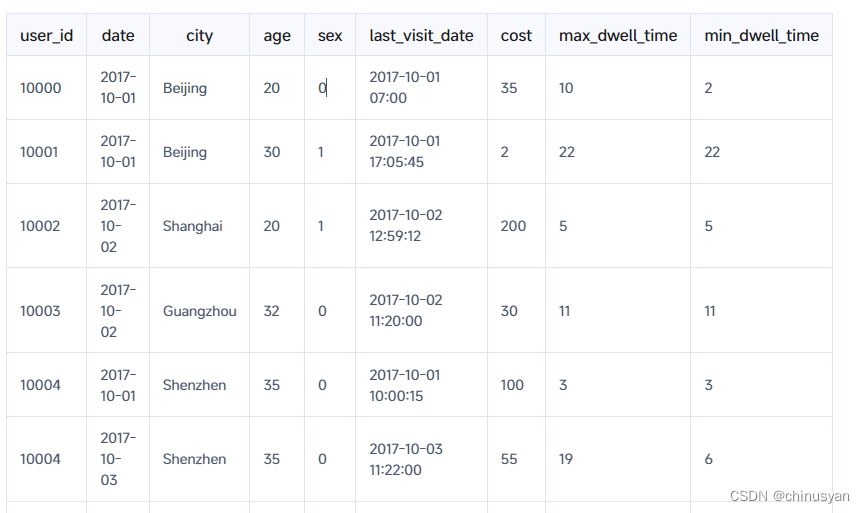
可以看到,User 10004的现有数据和新导入的数据已经聚合。同时,新增了用户10005的数据。
在Doris中,数据聚合发生在以下3个阶段:
1、每批导入数据的ETL阶段。在此阶段,将在内部聚合一批导入数据。
2、底层BE的数据压缩阶段。在此阶段,BE将聚合来自已导入的不同批次的数据。
3、数据查询阶段。查询中涉及的数据将相应地聚合。
在不同阶段,数据的汇总程度不同。例如,当刚导入一批数据时,它可能不会与现有数据聚合。但对于用户来说,他们只能查询聚合数据。也就是说,用户看到的是聚合的数据,他们不应该假设他们看到的是不聚合的或部分聚合的。
agg_state
AGG_STATE不能用作键列,在创建表时,需要声明聚合函数的签名。用户不需要指定长度或默认值。数据的实际存储大小取决于函数的实现。
CREATE TABLE
set enable_agg_state=true;
create table aggstate(k1 int null,k2 agg_state<sum(int)> generic,k3 agg_state<group_concat(string)> generic
)
aggregate key (k1)
distributed BY hash(k1) buckets 3
properties("replication_num" = "1");
agg_state用于声明数据类型为agg_state, sum/group_concat是聚合函数的签名。
请注意,agg_state是一种数据类型,类似于int、数组(array)或字符串(string)。
agg_state只能与state/merge/union函数组合子一起使用。
agg_state表示聚合函数的中间结果。例如,对于聚合函数sum, agg_state可以表示sum(1,2,3,4,5)等求和值的中间状态,而不是最终结果。
agg_state类型需要使用state函数生成。对于当前表,对于“sum”和group_concat聚合函数,分别是sum_state和group_concat_state。
insert into aggstate values(1,sum_state(1),group_concat_state('a'));
insert into aggstate values(1,sum_state(2),group_concat_state('b'));
insert into aggstate values(1,sum_state(3),group_concat_state('c'));
此时,该表只包含一行。请注意,下表只作说明用途,不能直接选择/显示:
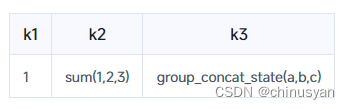
插入另一条记录。
insert into aggstate values(2,sum_state(4),group_concat_state('d'));
这张表目前的结构是……
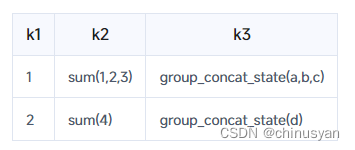
我们可以使用merge操作来组合多个状态,并返回聚合函数计算出的最终结果。
mysql> select sum_merge(k2) from aggstate;
+---------------+
| sum_merge(k2) |
+---------------+
| 10 |
+---------------+
sum_merge首先将sum(1,2,3)和sum(4)合并为sum(1,2,3,4),并返回计算结果。因为group_concat有特定的顺序要求,所以结果不稳定。
mysql> select group_concat_merge(k3) from aggstate;
+------------------------+
| group_concat_merge(k3) |
+------------------------+
| c,b,a,d |
+------------------------+
如果不想要最终的聚合结果,可以使用union将多个中间聚合结果组合起来,生成一个新的中间结果。
insert into aggstate select 3,sum_union(k2),group_concat_union(k3) from aggstate ;
这张表目前的结构是……
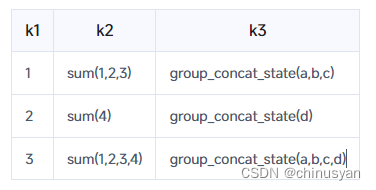
您可以通过查询实现这一点。
mysql> select sum_merge(k2) , group_concat_merge(k3)from aggstate;
+---------------+------------------------+
| sum_merge(k2) | group_concat_merge(k3) |
+---------------+------------------------+
| 20 | c,b,a,d,c,b,a,d |
+---------------+------------------------+mysql> select sum_merge(k2) , group_concat_merge(k3)from aggstate where k1 != 2;
+---------------+------------------------+
| sum_merge(k2) | group_concat_merge(k3) |
+---------------+------------------------+
| 16 | c,b,a,d,c,b,a |
+---------------+------------------------+
用户可以使用agg_state执行更详细的聚合函数操作。
agg_state带来了一定的性能开销。
5、用法说明
列类型建议
创建表时对列类型的建议:
1、键列应该在所有值列之前。
2、只要可能,请选择整数类型。这是因为整数类型的计算和搜索效率远远高于字符串类型。
3、选择不同长度的整数类型时,遵循充分性原则。
4、对于VARCHAR和STRING类型的长度,也要遵循充分性原则。
聚合模型的局限性
本节是关于聚合模型的局限性。
聚合模型只表示聚合的数据。这意味着我们必须确保尚未聚合的数据(例如,两个不同的导入批)的表示一致性。下面通过示例提供进一步的解释。
假设您有以下表模式:
假设已有两批数据导入到存储引擎中,如下所示:
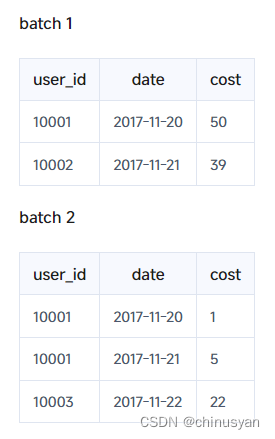
如您所见,这两个导入批中关于User 10001的数据尚未聚合。但是,为了保证用户只能查询聚合后的数据,如下所示:
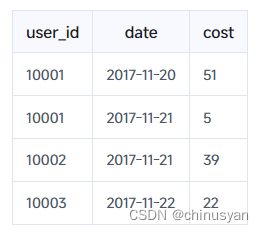
我们向查询引擎添加了一个聚合操作符,以确保数据的表示一致性。
另外,在聚合列(Value)上,当执行与聚合类型不一致的聚合类查询时,请注意语义。例如,在上面的示例中,如果执行以下查询:
SELECT MIN(cost) FROM table;
结果是5,不是1。
同时,这种一致性保证可能会大大降低某些查询的效率。
以基本count(*)查询为例:
SELECT COUNT(*) FROM table;
在其他数据库中,这样的查询可以快速返回结果。因为在实际实现中,模型可以通过对行进行计数并在导入时保存统计信息来获得查询结果,或者通过仅扫描某一列数据以在查询时获得计数值,开销很小。但是在Doris的聚合模型中,此类查询的开销很大。
对于前面的例子:
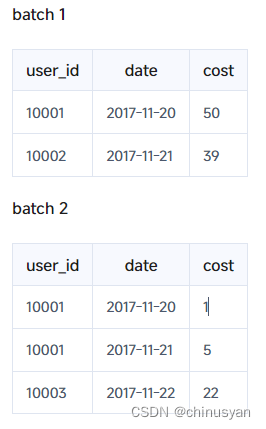
由于最终的聚合结果为:

select count (*) from table的正确结果;应该是4。但是,如果模型只扫描user_id列并在查询时操作聚合,则最终结果将是3(10001,10002,10003)。如果它不操作聚合,最终结果将是5(两批共5行)。显然,这两个结果都是错误的。
为了得到正确的结果,我们必须同时读取user_id和date列,并在查询时执行聚合。也就是说,在count(*)查询中,Doris必须扫描所有的AGGREGATE KEY列(在本例中是user_id和date)并聚合它们以获得语义正确的结果。这意味着如果有许多聚合列,count(*)查询可能涉及扫描大量数据。
因此,如果需要执行频繁的count (*)查询,我们建议通过添加值为1的列和聚合类型SUM来模拟count (*)。这样,上例中的表模式将被修改如下:
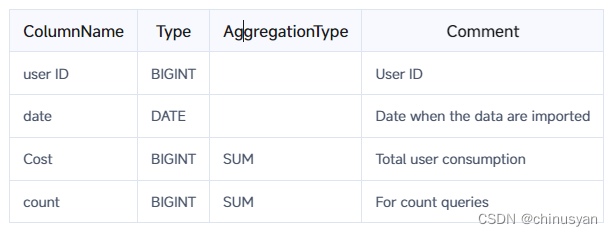
上面的代码添加了一个count列,它的值总是1,所以select count (*) from table;相当于select sum (count) from table;后者比前者效率高得多。然而,这种方法也有它的缺点。也就是说,它要求用户不能在AGGREGATE KEY列中导入具有相同值的行。否则,选择sum (count) from table;只能表示原始导入数据的行数,而不是select count (*) from table的语义;
另一种方法是添加值为1但聚合类型为REPLACE的count列。然后选择sum (count) from table;和select count (*) from table;可以产生同样的结果。此外,此方法不要求导入数据中不存在相同的AGGREGATE KEY列。
Merge on write of unique model
unique 模型中的写时合并实现不像聚合模型那样施加相同的限制。在“写时合并”中,模型为每个导入的行集添加删除位图(delete bitmap),以标记正在覆盖或删除的数据。如上例所示,导入第一批后,数据状态如下:
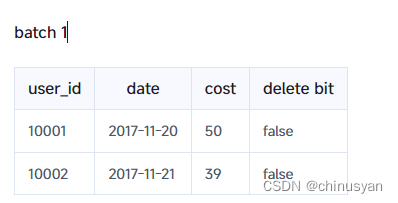
导入第二批数据后,第一批数据中的重复行将被标记为已删除,两批数据的状态如下
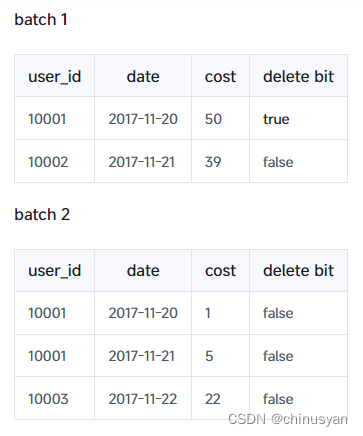
在查询中,删除位图中所有标记为true的数据都不会被读取,因此不需要进行数据聚合。由于上述数据中有4行有效数据,因此查询结果也应该是4。这也使开销最小,因为它只扫描一列数据。
在测试环境中,Unique Model的Merge on Write中的count(*)查询的性能是Aggregate Model的10倍。
Duplicate model
复制模型不像聚合模型那样施加相同的限制,因为它不涉及聚合语义。对于任何列,它都可以在count(*)查询中返回语义正确的结果。
Key columns
对于Duplicate、Aggregate和Unique模型,Key列将在创建表时指定,但存在一些区别:在Duplicate模型中,表的Key列可以视为“排序列”,而不是唯一标识符。在聚合和唯一模型中,Key列既是“排序列”又是“唯一标识符列”。
选择数据模型的建议
由于数据模型是在构建表时建立的,并且此后不可撤销,因此选择合适的数据模型非常重要。
1、聚合模型通过预聚合可以大大减少扫描数据量和查询计算量。因此,它非常适合具有固定模式的报表查询场景。但是这个模型对count(*)查询不友好。同时,由于Value列上的聚合方法是固定的,因此在其他类型的聚合查询中应该考虑语义正确性。
2、对于需要唯一主键的场景,唯一模型保证主键的唯一性。缺点是它不能利用预聚合带来的优势,例如查询中的ROLLUP。对于聚合查询有高性能要求的用户,建议使用1.2版以来新添加的Merge on Write实现。
3、Duplicate Model适用于任何维度的临时查询。虽然它可能无法利用预聚合特性,但它不受聚合模型约束的限制,可以充分发挥列存储的优势(仅读取相关列,而不是所有键列)。
4、如果用户需要使用部分更新,请参考部分更新文档
相关文章:
Apache Doris 基础 -- 数据表设计(数据模型)
Versions: 2.1 1、模型概览 本主题从逻辑角度介绍了Doris中的数据模型,以便您可以在不同的业务场景中更好地使用Doris。 基本概念 本文主要从逻辑的角度描述Doris的数据模型,旨在帮助用户在不同的场景更好地利用Doris。 在Doris中,数据在…...

“雪糕刺客”爆改“红薯刺客”,钟薛高给了消费品牌哪些启示?
夏日袭来,一支价格高昂却让人眼前一亮的雪糕,曾一度成为市场热议的焦点。然而,随着消费者对性价比的日益关注,曾经的“雪糕刺客”钟薛高,其创始人林盛近期以直播带货红薯开启他的还债之路,高打情怀“直播自…...
多输入多输出非线性对象的模型预测控制—Matlab实现
本示例展示了如何在 Simulink 中设计多输入多输出对象的闭环模型预测控制。该对象有三个操纵变量和两个测量输出。 一、非线性对象的线性化 运行该示例需要同时安装 Simulink 和 Simulink Control Design。 % 检查是否同时安装了 Simulink 和 Simulink Control Design if ~m…...

多项分布模拟及 Seaborn 可视化教程
多项分布 简介 多项分布是二项分布的推广,它描述了在 n 次独立试验中,k 种不同事件分别出现次数的离散概率分布。与二项分布只能有两种结果(例如成功/失败)不同,多项分布可以有 k 种(k ≥ 2)及…...

学计算机,我错了吗?
今天,我的一位朋友告诉我,终于找到一家小公司入职,年前 1 月辞职,本想休息一段时间,没成想,休息到 6 月份,现在程序员真的越来越难找工作了。 肯定有人在想,现在这种行情࿰…...

学习小心意——简单的循坏语句
for循坏 基本语法格式 for 变量 in 序列:代码块 示例代码如下 for i in range(10):print(i)#输出结果:0 1 2 3 4 5 6 7 8 9 简单案例代码如下 利用for语句遍历序列 # 遍历字符串打印每个字母 for letter in "python":print(letter)# 遍历列表并打印每个元素 a …...

C++ 类方法解析:内外定义、参数、访问控制与静态方法详解
C 类方法 类方法,也称为成员函数,是属于类的函数。它们用于操作或查询类数据,并封装在类定义中。类方法可以分为两种类型: 类内定义方法: 直接在类定义内部声明和定义方法。类外定义方法: 在类定义内部声明方法,并在…...
pytorch+YOLOv8-1
1.工具开发 2.idea配置pytorch环境 默认安装新版本torch pip install torch 3.pytorch验证 4. print(torch.cuda.is_available()) 输出结果为 False 说明我只能用cpu...

JavaScript 基础 - 对象
对象 对象是一种无序的数据集合,可以详细的描述描述某个事物。 注意数组是有序的数据集合。它由属性和方法两部分构成。 语法 声明一个对象类型的变量与之前声明一个数值或字符串类型的变量没有本质上的区别。 <script>let 对象名 {属性名:属性值…...

代码随想录第23天|回溯part3 组合与分割
39.组合总和 class Solution { public:vector<vector<int>> res;vector<int> path;void backTracking(vector<int>& candidates,int target,int sum,int n,int step){if(n > 150) return;if(sum > target) return;if(sum target){res.push_…...

nginx和proxy_protocol协议
目录 1. 引言2. HTTP server的配置3. Stream server的配置3.1 作为proxy_protocol的前端服务器3.2 作为proxy_protocol的后端服务器1. 引言 proxy_protocol 是haproxy开发的一种用于在代理服务器和后端服务器之间传递客户端连接信息的协议。使用 proxy_protocol 的主要优势是能…...

【pytorch】数据转换/增强后保存
数据转换 from PIL import Image from pathlib import Path import matplotlib.pyplot as plt import numpy as npimport torch import torchvision.transforms as Tplt.rcParams["savefig.bbox"] = tight # orig_im...
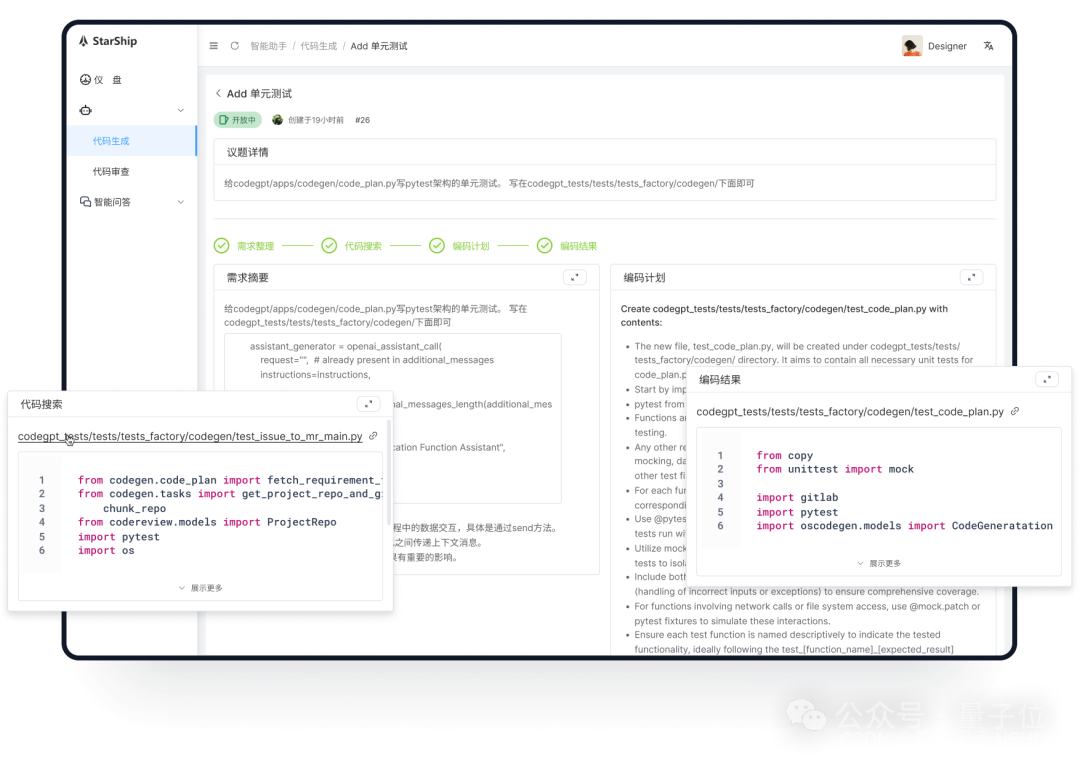
超越Devin!姚班带队,他们创大模型编程新世界纪录
超越Devin!SWEBench排行榜上迎来了新玩家—— StarShip CodeGen Agent,姚班带队初创公司OpenCSG出品,以23.67%的成绩获得全球第二名的成绩。 同时创造了非GPT-4o基模的最高纪录(SOTA)。 我们都知道,SWEBe…...

江苏大信环境科技有限公司:环保领域的开拓者与引领者
2009 年,江苏大信环境科技有限公司在宜兴环保科技工业园成立。自创立之始,该公司便笃定坚守“诚信为本、以质量求生存、以创新谋发展”这一经营理念,全力以赴为客户构建专业的工业有机废气治理整体解决方案,进而成为国家高新技术企…...

关于 Bean 容器的注入方式,99 % 的人都答不全!
引言:在使用 Spring 框架开发应用程序时,依赖注入是一个至关重要的概念。而对于 Bean 容器的注入方式,虽然我们可能都有一定的了解,但实际上很多人在被问及这个问题时可能并不能完整地回答。本文将深入探讨 Spring 中 Bean 容器的…...

Spring的@Async注解及其用途
Spring 的 Async 注解是 Spring Framework 4.2 版本引入的功能,它用于支持异步方法执行。当一个方法标注了 Async,Spring 会在一个单独的线程中调用该方法,从而不会阻塞主线程的执行。 Async 注解的用途: 提高性能:通…...
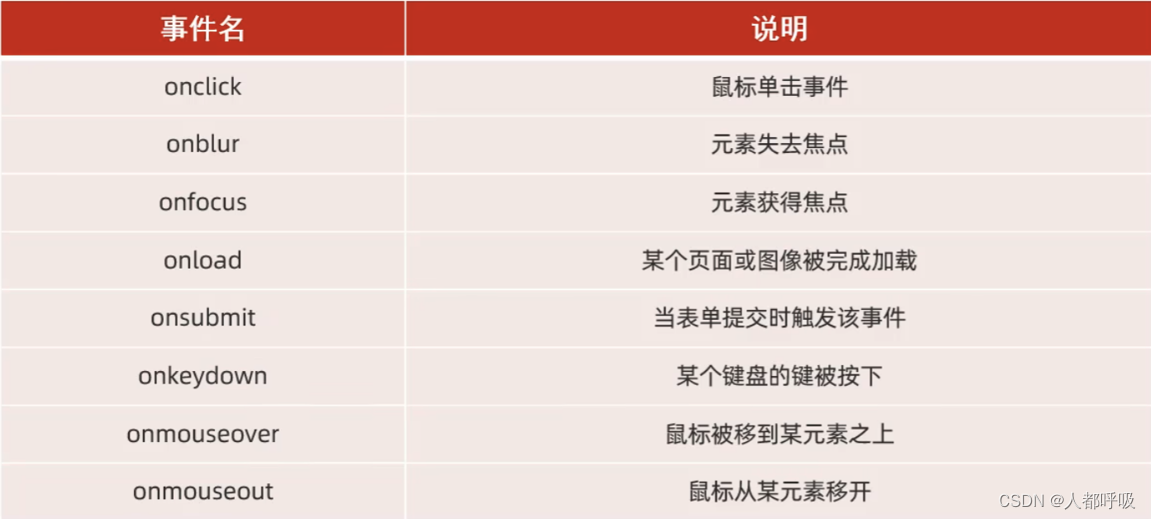
JS(DOM、事件)
DOM 概念:Document Object Model,文档对象模型。将标记语言的各个组成部分封装为对应的对象: Document:整个文档对象Element:元素对象Attribute:属性对象Text:文本对象Comment:注释对象 JavaScript通过DOM,就能够对HTML进行操作: 改变 HTML 元素的内…...

学习小心意——python的构造方法和析构方法
构造方法和析构方法分别用于初始化对象的属性和释放类占有的资源 构造方法_init_() 语法格式如下: class 类名:def __init__(self, 参数1, 参数2, ...):# 初始化代码self.属性1 参数1self.属性2 参数2# ... 示例代码如下 class Student:def __init__(self):s…...

GB/T 23995-2009 室内装饰装修用溶剂型醇酸木器涂料检测
溶剂型醇酸木器涂料是指以醇酸树脂为主要成膜物,通过氧化干燥成膜的溶剂型木器涂料适用于室内木制品表面的保护及装饰。 GB/T 23995-2009室内装饰装修用溶剂型醇酸木器涂料检测项目: 测试指标 测试方法 在容器中状态 GB/T 23995 细度 GB/T 6753.1 …...
Maven 中的 classifier 属性用过没?
最近训练营有小伙伴问到松哥一个关于 Maven 依赖的问题,涉及到 classifier 属性,随机问了几个小伙伴,都说工作中没用到过,因此简单整篇文章和小伙伴们分享下。 Maven 大家日常开发应该都有使用,Maven 中有一个比较好玩…...
)
手把手教你用WouoUI-PageVersion打造128*64 OLED炫酷UI(附Air001移植避坑指南)
嵌入式UI开发实战:WouoUI-PageVersion在128*64 OLED屏上的高效移植与优化 在资源受限的嵌入式设备上实现流畅的UI动画一直是个技术挑战。本文将带你深入探索如何利用WouoUI-PageVersion框架,在仅有4KB RAM和32KB Flash的Air001等微控制器上,打…...

2025届学术党必备的六大AI论文助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek DeepSeek身为人工智能写作工具,于学术论文撰写里能够起到辅助方面的作用…...

5个技巧让你高效畅玩Switch游戏:开源Ryujinx模拟器全攻略
5个技巧让你高效畅玩Switch游戏:开源Ryujinx模拟器全攻略 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx是一款采用C#语言开发的开源Nintendo Switch模拟器&#x…...
)
基于Copula函数的多风场出力相关性分析场景生成与聚类削减方法(MATLAB实现)
考虑多风场出力相关性的可再生能源场景生成/风电场景生成,并通过聚类算法场景削减成几个场景,每个场景都有确定的出现概率。 完美复现《考虑多风电场出力 Copula 相关关系的场景生成方法》 Copula 函数(连接函数)描述空间相邻风电场间的相关性࿰…...

Cobalt Strike实战指南:从基础配置到高级渗透技巧
1. Cobalt Strike基础入门 第一次接触Cobalt Strike时,我被它强大的功能震撼到了。这款工具不仅能够模拟高级威胁攻击,还能进行红队协作操作,是渗透测试领域的瑞士军刀。记得刚开始搭建环境时,我在Kali和Windows双系统间反复切换&…...

AI for Science 之数论:当人工智能叩响数学王冠的大门
AI for Science 之数论:当人工智能叩响数学王冠的大门 引言 数论,被誉为“数学的皇冠”,以其问题的纯粹与结论的深刻,吸引着从欧几里得到高斯的无数智者。它研究整数的性质,是数学中最古老、最基础的分支之一。如今&…...

从商业目标到技术实现:通用系统设计的四层逻辑框架
文章目录1. 商业目标(Business Goals)2. 业务逻辑(Business Logic)3. 应用逻辑(Application Logic)4. 技术架构(Technical Architecture)5. 四层逻辑的流动与反馈参考资料在构建任何…...

BetterJoy终极指南:在Windows电脑上完美使用Switch手柄玩游戏
BetterJoy终极指南:在Windows电脑上完美使用Switch手柄玩游戏 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitco…...

效率提升秘籍:基于任务类型用openclaw在快马平台智能切换最佳ai模型
最近在开发过程中,我发现一个很有意思的现象:不同的AI模型其实各有专长。比如有些模型特别擅长生成前端UI代码,有些则对算法逻辑更在行。但每次手动切换模型实在太麻烦了,于是我决定在InsCode(快马)平台上开发一个智能切换工具。 …...

如何用ESP32打造你的个性化智能网络收音机:YoRadio完全指南
如何用ESP32打造你的个性化智能网络收音机:YoRadio完全指南 【免费下载链接】yoradio Web-radio based on ESP32-audioI2S library 项目地址: https://gitcode.com/GitHub_Trending/yo/yoradio 你是否厌倦了传统收音机有限的功能和单调的操作界面?…...