【Text2SQL 论文】DIN-SQL:分解任务 + 自我纠正 + in-context 让 LLM 完成 Text2SQL
论文:DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction
⭐⭐⭐⭐
NeurIPS 2023, arXiv:2304.11015
Code: Few-shot-NL2SQL-with-prompting | GitHub
文章目录
- 一、论文速读
- 1.1 Schema Linking Module
- 1.2 Classification & Decomposition Module
- 1.3 SQL Generation Module
- 1.3.1 EASY 类型
- 1.3.2 NON-NESTED 类型
- 1.3.3 NESTED 类型
- 1.4 Self-correction Module
- 二、Error cases 分析
- 三、总结
一、论文速读
这篇论文通过对 LLM 做 prompt 来实现 Text2SQL,过程中通过 prompt 让 LLM 分解任务来降低难度,每个子任务通过 in-context learning 让 LLM 来完成,并在完成 SQL 生成后,通过 self-correction 来检查和纠正可能有错误的 SQL。最终,在执行精确度指标上超越了现有的 SOTA 模型。
生成 SQL 被分成四个阶段:
- Schema Linking:输入 NL query 和 DB schema,找出与 query 相关的 tables、columns 以及不同表之间的外键关系
- Classification & Decomposition:将 query 分成了三种不同的难度:EASY、NON-NESTED、NESTED
- SQL Generation:根据不同类型的 query,按照不同的策略来生成对应的 SQL
- Self-correction:通过 prompt 来让 LLM 检查和纠正可能错误的 SQL
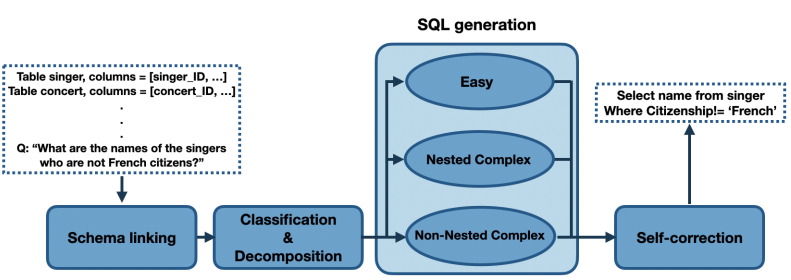
1.1 Schema Linking Module
这个 module 输入 NL query 和 DB 的 schema 信息,输出的是将 query 链接到 DB 中的一些信息,具体来说输出就是:
- table 和 columns 的名称:找到 query 中涉及到的 DB 的 table 和 columns 的名称
- 条件值:从查询中提取出用于条件过滤的值,比如在查询“Find the departments with a budget greater than 500”中,需要提取出条件值“500”。
- 外键关系的确定:如果查询涉及到多个表,需要确定它们之间的关系,如通过外键连接。
下面是使用 in-context learning + CoT 来让 LLM 做 schema-linking 的示例:
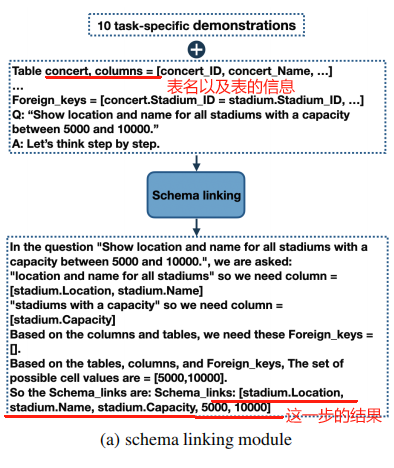
demostration 的一个示例如下:
Table advisor, columns = [*,s_ID,i_ID]
Table classroom, columns = [*,building,room_number,capacity]
Table course, columns = [*,course_id,title,dept_name,credits]
Table department, columns = [*,dept_name,building,budget]
Table instructor, columns = [*,ID,name,dept_name,salary]
Table prereq, columns = [*,course_id,prereq_id]
Table section, columns = [*,course_id,sec_id,semester,year,building,room_number,time_slot_id]
Table student, columns = [*,ID,name,dept_name,tot_cred]
Table takes, columns = [*,ID,course_id,sec_id,semester,year,grade]
Table teaches, columns = [*,ID,course_id,sec_id,semester,year]
Table time_slot, columns = [*,time_slot_id,day,start_hr,start_min,end_hr,end_min]
Foreign_keys = [course.dept_name = department.dept_name,instructor.dept_name = department.dept_name,section.building = classroom.building,section.room_number = classroom.room_number,section.course_id = course.course_id,teaches.ID = instructor.ID,teaches.course_id = section.course_id,teaches.sec_id = section.sec_id,teaches.semester = section.semester,teaches.year = section.year,student.dept_name = department.dept_name,takes.ID = student.ID,takes.course_id = section.course_id,takes.sec_id = section.sec_id,takes.semester = section.semester,takes.year = section.year,advisor.s_ID = student.ID,advisor.i_ID = instructor.ID,prereq.prereq_id = course.course_id,prereq.course_id = course.course_id]
Q: "Find the buildings which have rooms with capacity more than 50."
A: Let’s think step by step. In the question "Find the buildings which have rooms with capacity more than 50.", we are asked:
"the buildings which have rooms" so we need column = [classroom.capacity]
"rooms with capacity" so we need column = [classroom.building]
Based on the columns and tables, we need these Foreign_keys = [].
Based on the tables, columns, and Foreign_keys, The set of possible cell values are = [50]. So the Schema_links are:
Schema_links: [classroom.building,classroom.capacity,50]
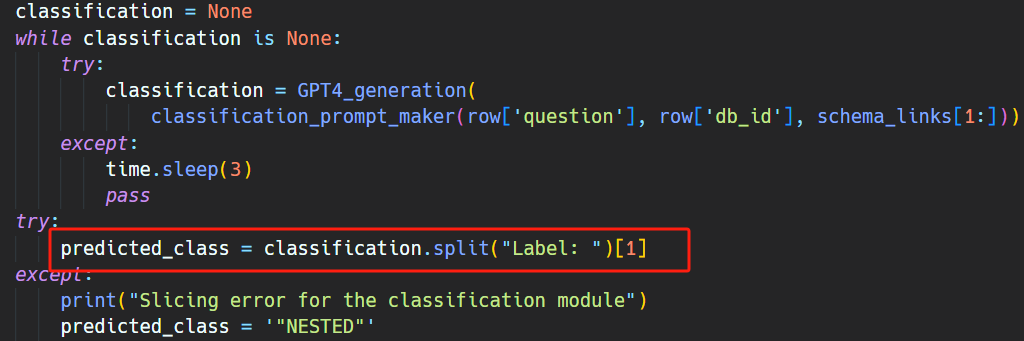
如下面代码所示,schema linking 的结果就是从 GPT 的响应中解析出 Schema_links: 这个字符串后面的内容:

1.2 Classification & Decomposition Module
这一步将 query 分成三种不同的复杂度的类:
- EASY:没有 JOIN 和 NESTING 的单表查询
- NON-NESTED:需要 JOIN 但不需要子查询的查询
- NESTED:可以包含 JOIN、sub-query 和 set opr
下面是一个该 module 的示例:
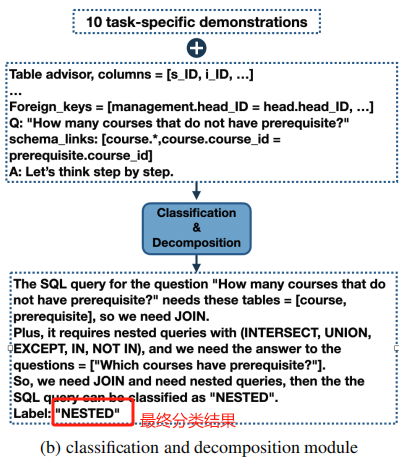
这部分代码如下:
1.3 SQL Generation Module
这一个 module 根据 query 的复杂度类型,使用不同的策略来生成 SQL。
1.3.1 EASY 类型
对于 EASY 类型的 question,不需要中间步骤,只需要少量提示就足够了,下面是一个 exemplar:
Q: "Find the buildings which have rooms with capacity more than 50."
Schema_links: [classroom.building,classroom.capacity,50]
SQL: SELECT DISTINCT building FROM classroom WHERE capacity > 50
即要求 LLM 根据 question 和 schema links 输出 SQL。
1.3.2 NON-NESTED 类型
对于 NON-NESTED 类型的 question,启发 LLM 去思考从而生成 SQL,下面是一个 exemplar:
Q: "Find the total budgets of the Marketing or Finance department."
Schema_links: [department.budget,department.dept_name,Marketing,Finance]
A: Let’s think step by step. For creating the SQL for the given question, we need to join these tables = []. First, create an intermediate representation, then use it to construct the SQL query.
Intermediate_representation: select sum(department.budget) from department where department.dept_name = \"Marketing\" or department.dept_name = \"Finance\"
SQL: SELECT sum(budget) FROM department WHERE dept_name = 'Marketing' OR dept_name = 'Finance'
也就是输入 question 和 schema links,然后加一句 Let's think step by step 启发 LLM 思考,从而得到 SQL。
1.3.3 NESTED 类型
在 “Classification & Decomposition Module” 模块中,除了为其复杂度分类,还会为 NESTED 类型的 user question 生成 sub-question,如下图:
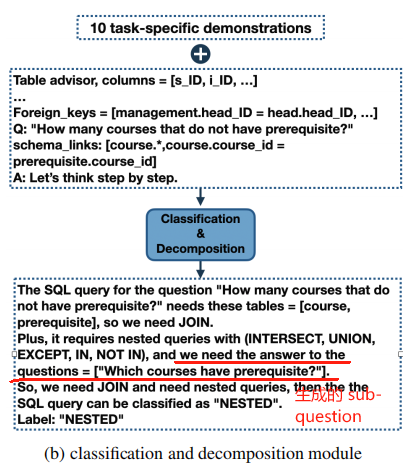
然后,这里的 sub-questions 会被传入 SQL Generation Module 的 prompt 中用于解决 NESTED 类型的 SQL 生成。下面是一个 exemplar:
Q: "Find the title of courses that have two prerequisites?"
Schema_links: [course.title,course.course_id = prereq.course_id]
A: Let's think step by step. "Find the title of courses that have two prerequisites?" can be solved by knowing the answer to the following sub-question "What are the titles for courses with two prerequisites?".
The SQL query for the sub-question "What are the titles for courses with two prerequisites?" is SELECT T1.title FROM course AS T1 JOIN prereq AS T2 ON T1.course_id = T2.course_id GROUP BY T2.course_id HAVING count(*) = 2
So, the answer to the question "Find the title of courses that have two prerequisites?" is =
Intermediate_representation: select course.title from course where count ( prereq.* ) = 2 group by prereq.course_id
SQL: SELECT T1.title FROM course AS T1 JOIN prereq AS T2 ON T1.course_id = T2.course_id GROUP BY T2.course_id HAVING count(*) = 2
exemplar 的 prompt 的组成如下:

可以看到,这就是输入 question、sub-questions、schema links 来生成 SQL。
1.4 Self-correction Module
这一模块的目的是通过 prompt 让 LLM 来检查和纠正生成的 SQL 中可能的错误。这里的 prompt 如下:
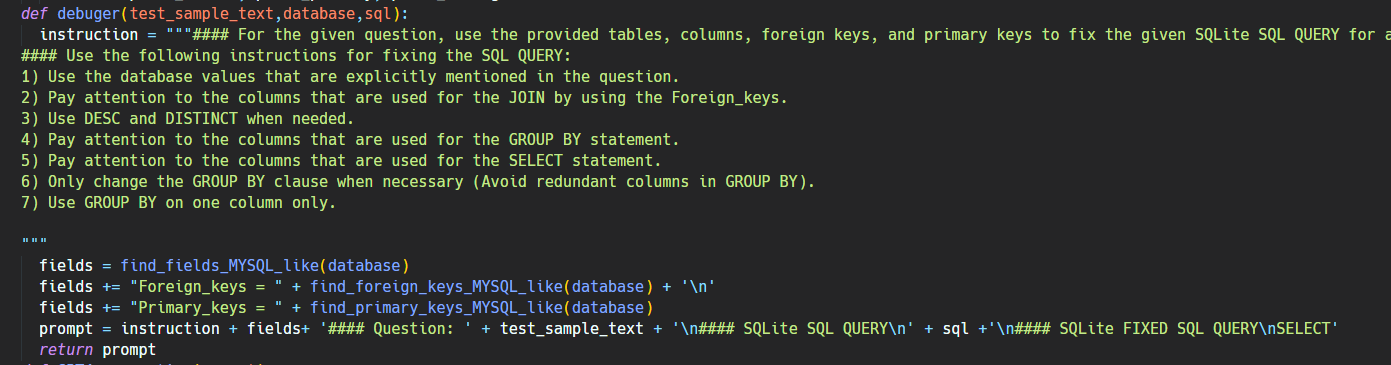
这里的 prompt 让 LLM 多关注自己在生成 SQL 时容易犯的错。
二、Error cases 分析
论文对 error cases 做了分析,总结了如下 LLM 容易出的错:
- Schema linking:这类是犯错最多的情况,指的是 model 错误地识别出 question 中提到的 column names、table names 或者 entities。
- JOIN:第二大类情况,指的是 model 不能识别出所有需要的 tables 以及正确地将这些 tables 连接起来的外键。
- GROUP BY:在生成 GROUP BY 子句时,可能会遗漏或者选错列
- Queries with nesting and set operations:模型不能识别出 nested structure 或者不能检测出正确的 nesting 或 set 操作
- Invalid SQL:一部分 SQL 有语法错误且不能执行
- Miscellaneous:还有其他乱七八糟的原因,比如缺少 predicate、缺少或冗余 DISTINCT、DESC 等关键字
这些容易犯的错,都会在 self-correction module 被多关注来检查和纠正。
三、总结
本论文设计的 prompt 以及思路让 LLM 在解决 Text2SQL 任务上有了不错的表现,产生了与最先进的微调方法相当甚至更优的结果。
但是,本文的思路需要多轮与 LLM 交互,从而产生了巨大的花费和延迟,论文给出,在使用 GPT4 响应 Spider 数据集中 question 时表现出大约 60s 的延迟。
相关文章:
【Text2SQL 论文】DIN-SQL:分解任务 + 自我纠正 + in-context 让 LLM 完成 Text2SQL
论文:DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction ⭐⭐⭐⭐ NeurIPS 2023, arXiv:2304.11015 Code: Few-shot-NL2SQL-with-prompting | GitHub 文章目录 一、论文速读1.1 Schema Linking Module1.2 Classification & Decompo…...

基于Springboot+vue实现的汽车服务管理系统
作者主页:Java码库 主营内容:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app等设计与开发。 收藏点赞不迷路 关注作者有好处 文末获取源码 技术选型 【后端】:Java 【框架】:spring…...

ROS2从入门到精通4-3:全局路径规划插件开发案例(以A*算法为例)
目录 0 专栏介绍1 路径规划插件的意义2 全局规划插件编写模板2.1 构造规划插件类2.2 注册并导出插件2.3 编译与使用插件 3 全局规划插件开发案例(A*算法)常见问题 0 专栏介绍 本专栏旨在通过对ROS2的系统学习,掌握ROS2底层基本分布式原理,并具有机器人建…...
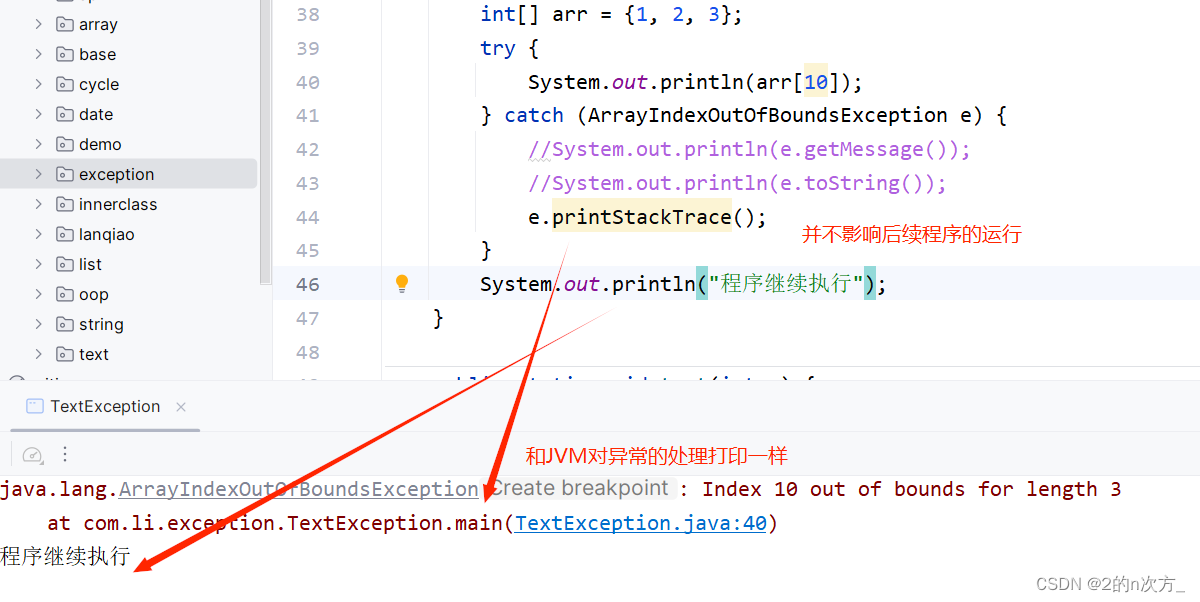
Java学习【认识异常】
Java学习【认识异常】 认识异常异常的种类异常的作用 异常的处理方式JVM默认的处理方式捕获异常finally 多个异常的处理异常中的方法抛出异常 自定义异常 认识异常 在Java中,将程序执行过程中发生的不正常行为称为异常 异常的种类 Error代表的是系统级别的错误&a…...

uniapp+h5 ——微信小程序页面截屏保存在手机
web-view 需要用到 web-view ,类似于iframe, 将网页嵌套到微信小程序中,参数传递等; 示例(无法实时传递数据),页面销毁时才能拿到h5传递的数据,只能利用这点点击跳转到小程序另一个…...
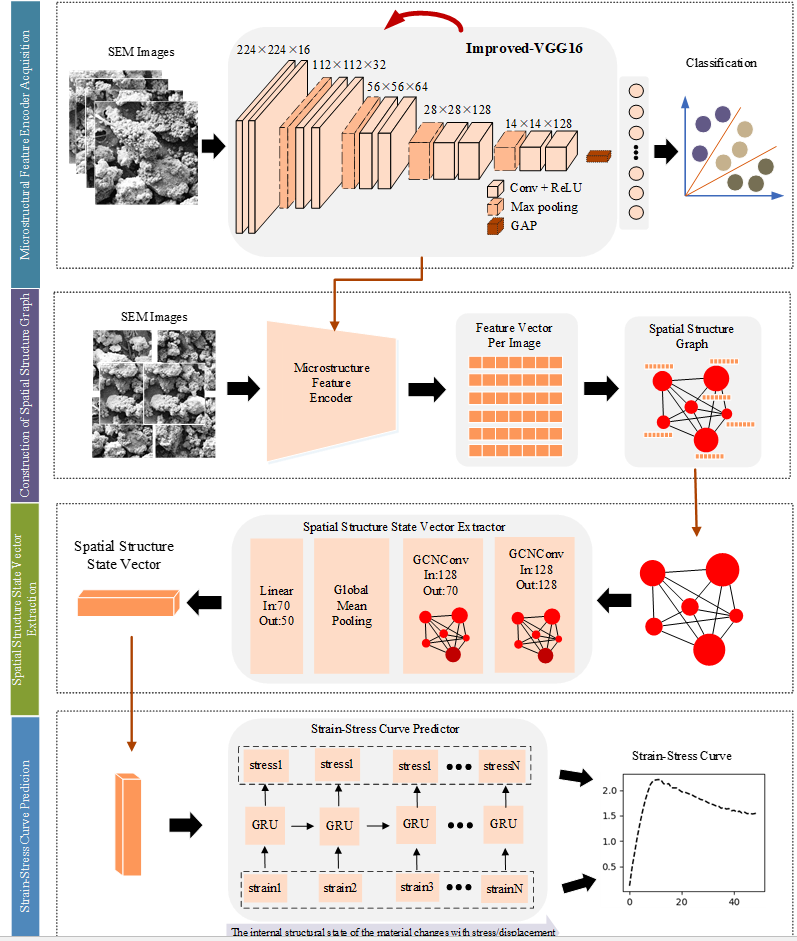
三、基于图像分类预训练编码及图神经网络的预测模型 【框图+源码】
背景: 抽时间补充,先挖个坑。 一、模型结构 二、源码...
Linux - 高级IO
目录 理解五种IO模型非阻塞IO的设置多路转接之select 实现一个简易的select服务器select服务器的优缺点 多路转接之poll 实现一个简易的poll服务器poll服务器的优缺点 多路转接之epoll epoll原理epoll的优势用epoll实现一个简易的echo服务器 epoll的LT和ET工作模式 什么是LT和…...

面试题:说一下 http 报文都有哪些东西?
面试题:说一下 http 报文都有哪些东西? HTTP 是传输超文本(实际上除了 HTML,可以传输任何类型的文件,如视频、音频、文本等)的协议,是一组用于浏览器-服务器之间数据传输的规则。 HTTP 位于 OS…...
开山之作!Python数据与算法分析手册,登顶GitHub!
若把编写代码比作行军打仗,那么要想称霸沙场,不能仅靠手中的利刃,还需深谙兵法。 Python是一把利刃,数据结构与算法则是兵法。只有熟读兵法,才能使利刃所向披靡。只有洞彻数据结构与算法,才能真正精通Pyth…...

编译安装gcc-11及可能遇到的bug
编译安装脚本 GCC_VERSION11.1.0 PACKAGE_DIR/path/to/gcc/source/code GCC_DIR$PACKAGE_DIR/gcc-$GCC_VERSION GCC_INSTALL_DIR/path/to/install/gccmkdir -p $GCC_INSTALL_DIR cd $GCC_INSTALL_DIR rm -rf * cd $PACKAGE_DIR rm -rf gcc-$GCC_VERSION if [ ! -f "gcc-$…...

vue项目引入json/js文件批量或单个方法
vue项目 json // 方式一 : 将文件内容完整的引入 import json from ./src/assets/xxx.json console.log(json) console.log(---)// 方式二 : 部分引入-名称必须是文件中定义的key import {name1,name2} from ./src/assets/xxx.json console.log(name1)…...
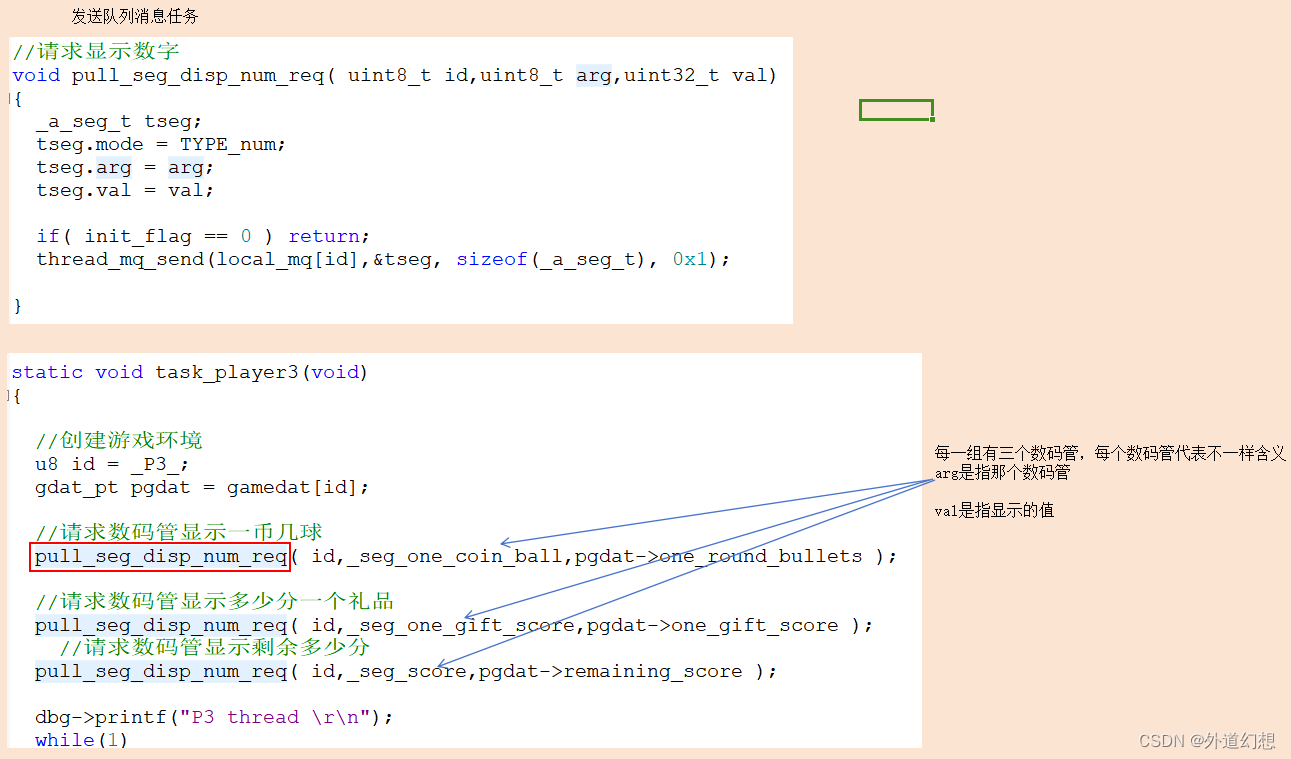
守护任务用来防止资源冲突
背景:有三个任务,他们都需要操作数码管。每个任务对应三个数码管,共9个数码管。硬件上9个数码管的控制使用一套硬件完成。 策略:每个任务都往自己的队列里面发数据,单独建立一个监听任务:处理所有队列的数…...

fast admin实现多数据库导入数据
思路 1创建多数据库连接 2后端的前台代码能使用get或者post请求传递选中数据给后台 3后台能够接收到 4后台接收到id或者全字段数据后对数据进行处理,然后使用多数据库操作将其存入第二个数据库 实现 1config文件下创建新数据库连接 db_config2 > [// 数据库类…...

NLP基础——序列模型(动手学深度学习)
序列模型 定义 序列模型是自然语言处理(NLP)和机器学习领域中一类重要的模型,它们特别适合处理具有时间顺序或序列结构的数据,例如文本、语音信号或时间序列数据。 举个例子:一部电影的评分在不同时间段的评分可能是…...

机器学习AI大模型的开源与闭源:哪个更好?
文章目录 前言一、开源AI模型1.1 开源的优点1.2 开源的缺点 二、闭源AI模型2.1 闭源的优点2.2 闭源的缺点 三、开源与闭源的平衡3.1 开源与闭源结合的案例3.2 开源与闭源的战略选择 小结 前言 在过去的几年里,人工智能(AI)和机器学习…...

关于大模型多轮问答的两种方式
前言 大模型的多轮问答难点就是在于如何精确识别用户最新的提问的真实意图,而在常见的使用大模型进行多轮对话方式中,我接触到的只有两种方式: 一种是简单地直接使用 user 和 assistant 两个角色将一问一答的会话内容喂给大模型,…...

达梦数据库相关SQL及适配Mysql配置总结
🍓 简介:java系列技术分享(👉持续更新中…🔥) 🍓 初衷:一起学习、一起进步、坚持不懈 🍓 如果文章内容有误与您的想法不一致,欢迎大家在评论区指正🙏 🍓 希望这篇文章对你有所帮助,欢…...

Centos7.9实现多台机器ssh免密登录
1.本机(172.16.10.228)先生成密钥对 ssh-keygen -t rsa 2.执行命令,把本机公钥拷贝到远程机器 ssh-copy-id rootdistinctIp 3.查看一下远程机器 、/root/.ssh/authorized_keys文件 cat /root/.ssh/authorized_keys 会看到里边多了个公钥…...

Unity3D DOTS JobSystem物理引擎的使用详解
前言 Unity3D DOTS(Data-Oriented Technology Stack)是Unity引擎的一项新技术,旨在提高游戏性能和扩展性。其中的Job System是一种用于并行处理任务的系统,可以有效地利用多核处理器的性能。在本文中,我们将重点介绍如…...

vue3+element-plus 表单校验和循环form表单校验
1.HTML页面 //el-form 标签添加上 ref"form2Form" :rules"rules2" :model"form2" 正常表单校验 //没有循环表单的使用事例<el-form-item label"投保人名称" class"insurance-date-no1" prop"tbrName">…...

傅里叶级数7大核心性质详解:从时移特性到微分性快速掌握
傅里叶级数7大核心性质详解:从时移特性到微分性快速掌握 信号与系统课程中,傅里叶级数就像一把瑞士军刀,能将复杂的周期信号拆解成简单的正弦波组合。对于备考学生而言,掌握其核心性质不仅能快速解题,更能深入理解信号…...

BGE-Reranker-v2-m3性能实测:毫秒级响应的RAG优化方案
BGE-Reranker-v2-m3性能实测:毫秒级响应的RAG优化方案 1. 引言:RAG系统的精准度挑战 在实际的RAG(检索增强生成)应用场景中,很多开发者都会遇到这样的困境:明明检索到了一堆看似相关的文档,但…...

云容笔谈·东方红颜影像生成系统Python爬虫实战:自动化采集图像数据训练集
云容笔谈东方红颜影像生成系统Python爬虫实战:自动化采集图像数据训练集 最近在尝试训练一个专注于东方人物风格的AI绘画模型,最头疼的问题就是数据。网上图片虽然多,但风格杂乱、质量参差不齐,手动一张张找、一张张筛࿰…...

DeepChat行业应用:生物医药文献摘要→靶点关系提取→实验设计建议
DeepChat行业应用:生物医药文献摘要→靶点关系提取→实验设计建议 1. 项目背景与核心价值 在生物医药研发领域,研究人员每天需要阅读大量文献,从海量信息中提取关键发现、识别药物靶点关系,并设计后续实验方案。传统的人工处理方…...

GME-Qwen2-VL-2B-Instruct保姆级教程:多GPU并行推理加速图文批量匹配效率
GME-Qwen2-VL-2B-Instruct保姆级教程:多GPU并行推理加速图文批量匹配效率 1. 工具简介 GME-Qwen2-VL-2B-Instruct是一个专门用于图文匹配度计算的本地工具,基于先进的多模态模型开发。这个工具解决了传统图文匹配中经常遇到的打分不准问题,…...
)
农产投入线上管理|基于springboot + vue农产投入线上管理系统(源码+数据库+文档)
农产投入线上管理系统 目录 基于springboot vue农产投入线上管理系统 一、前言 二、系统功能演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue农产投入线上管理系统 一、前…...

C++编程中new与delete操作符的深度解析
C编程中new与delete操作符的深度解析 在C编程的广阔天地里,内存管理是一个既基础又至关重要的环节。对于每一位C开发者而言,掌握内存的动态分配与释放是构建高效、稳定应用程序的基石。在众多内存管理工具中,new与delete操作符无疑是最为核心…...

ESP-NOW低功耗传感网络框架:节点-主机架构与AES-GCM加密实现
1. EspNowNetwork 项目概述EspNowNetwork 是一套面向 ESP32 系列 SoC(包括 ESP32-S2、ESP32-C3、ESP32-C6)的模块化固件框架,专为构建低功耗、高可靠性的点对多点无线传感网络而设计。其核心目标并非替代 Wi-Fi 或 BLE 协议栈,而是…...

DuinoMemory:面向Arduino的轻量级嵌入式智能指针库
1. 项目概述DuinoMemory 是一款专为 Arduino 及资源受限嵌入式系统设计的轻量级智能指针库。它不依赖 STL、不使用异常(exceptions)、不启用 RTTI,完全以头文件形式提供(header-only),所有实现均通过 C 模板…...

嵌入式滚动平均滤波库:SimpleSmooth轻量级实现
1. 项目概述 SimpleSmooth 是一个专为嵌入式系统设计的轻量级滚动平均值计算库,其核心目标是为模拟信号采集(如 ADC 读数)提供低开销、无动态内存分配、零依赖的数字滤波能力。该库并非从零构建,而是对 Arduino 官方示例中经典平…...