【递归、搜索与回溯】递归、搜索与回溯准备+递归主题
递归、搜索与回溯准备+递归主题
- 1.递归
- 2.搜索
- 3.回溯与剪枝
- 4.汉诺塔问题
- 5.合并两个有序链表
- 6.反转链表
- 7.两两交换链表中的节点
- 8.Pow(x, n)-快速幂(medium)

点赞👍👍收藏🌟🌟关注💖💖
你的支持是对我最大的鼓励,我们一起努力吧!😃😃
搜索是递归中的一个分支,回溯是搜索中的一个分支,因此我们学习顺序是递归、搜索、回溯。
1.递归
什么是递归
在C语言,和数据结构(二叉树、快速排序、归并排序)我们或多或少已经接触过递归;递归大白话来说就是:函数自己调用的情况
为什么会用到递归
以二叉树、快排、归并为例
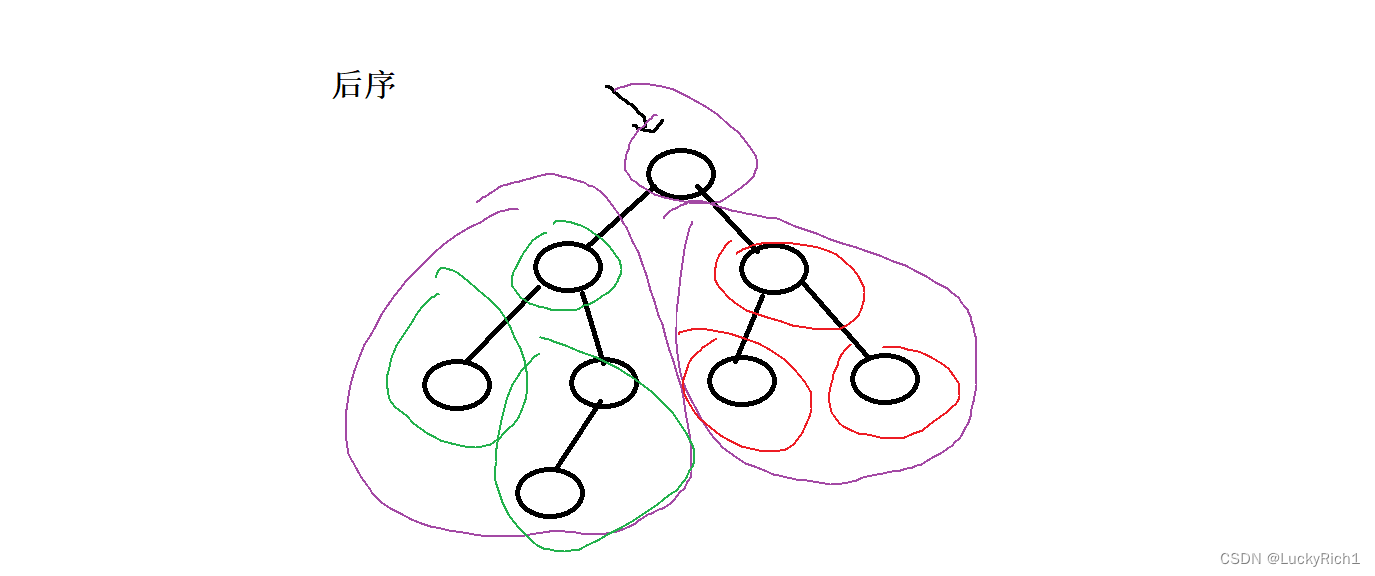
后序:左右根
我们一定是从根节点开始,先找左子树,在找右子树,然后在根节点,
当我们走到下面左子树的时候,也依旧是这样的做法,等到把左子数遍历完了,然后走到右子树依旧是左右根,当右子树走完,才最终回到根节点
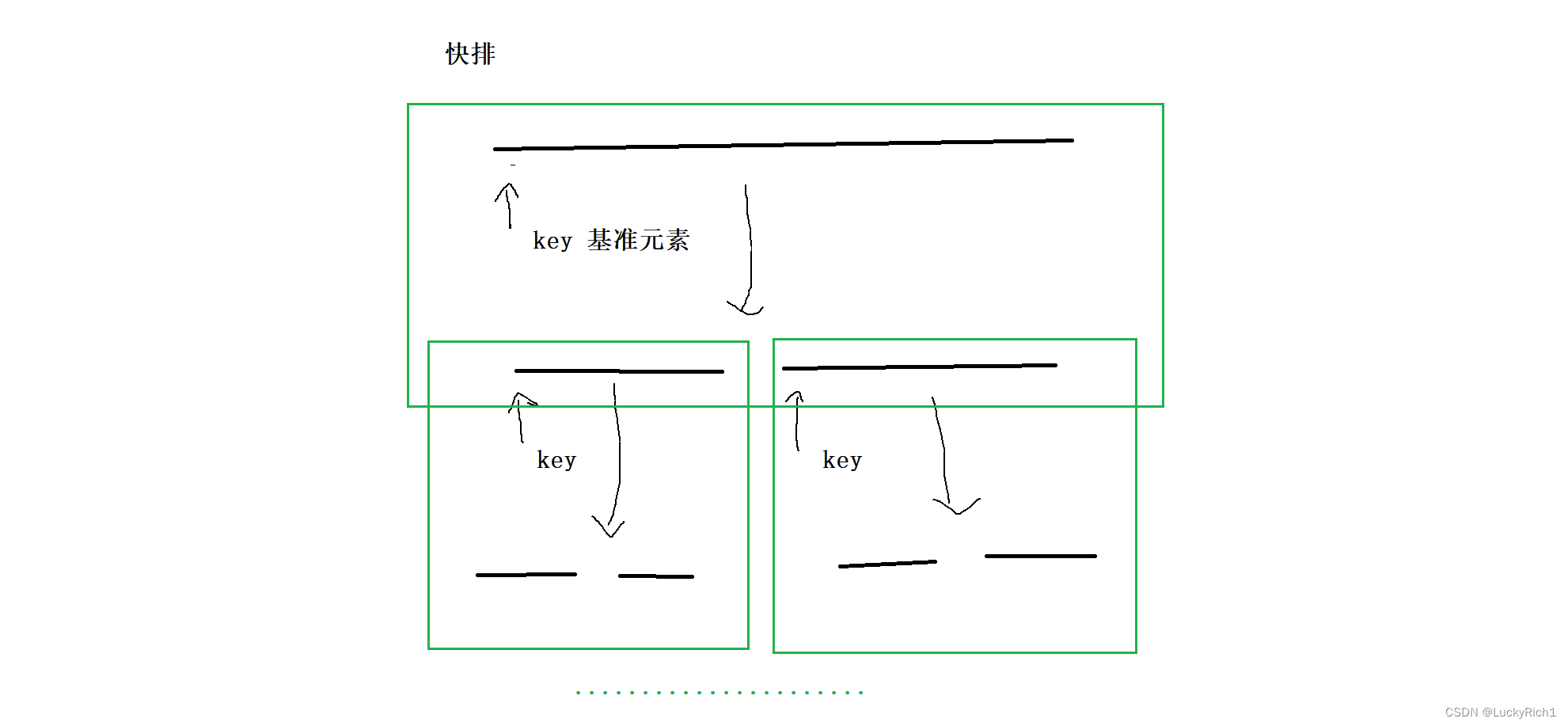
快排每次都找一个基准元素,将数组分成两部分,然后再对分开的部分在找基准元素然后在继续分…
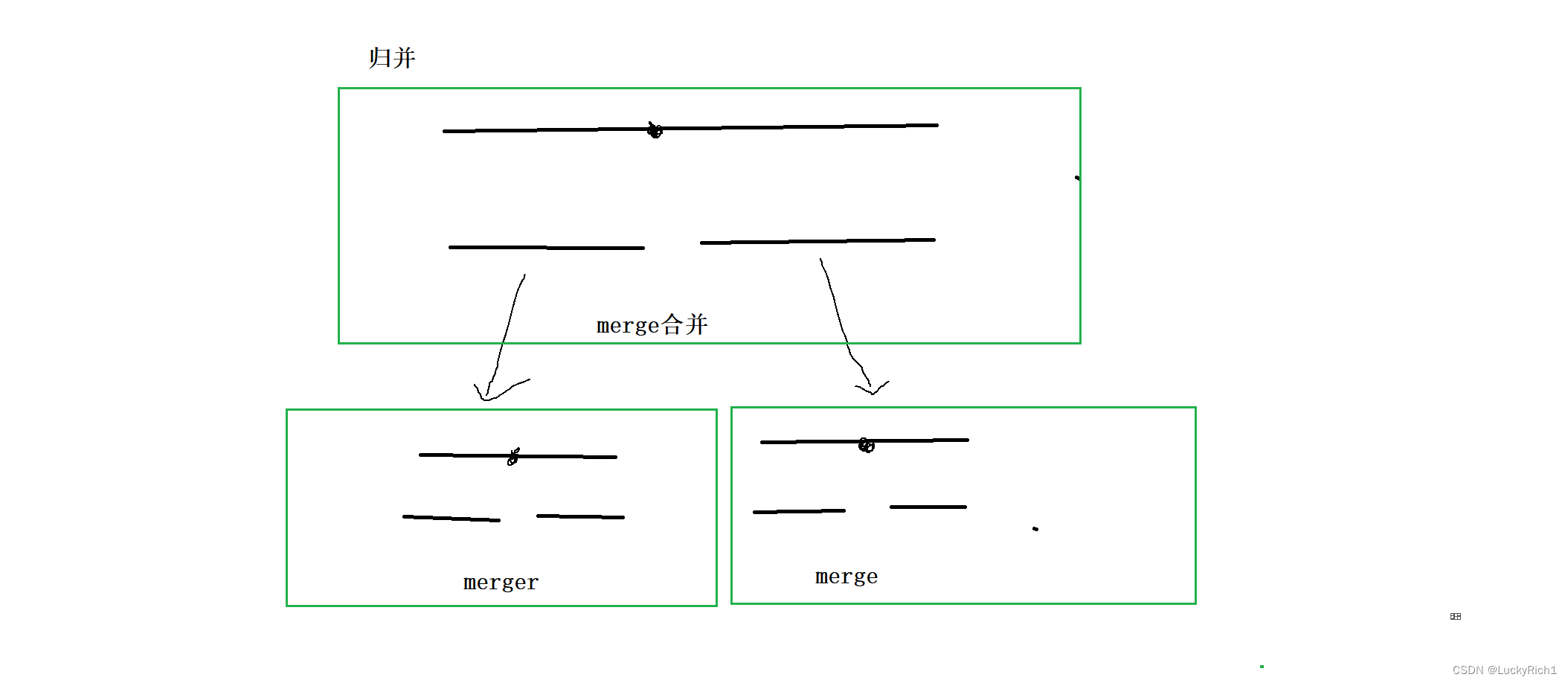
归并,选择中间节点将数组分成两部分,然后再合并,然后分解到下面也是一样的操作,
上面都是解决主问题的时候,出现了相同的子问题。
主问题 -----> 相同的子问题
子问题 -----> 相同的子问题
总结:当出现一个问题,你发现解决这个问题的过程中,会出现相同的子问题,并且这些子问题都可以用同一个函数来解决,此时用递归!
如何理解递归
第一层:递归展开图
第二层:二叉树中的题目
第三层:宏观看待递归的过程
- 不要在意递归的细节展开图
- 把递归的函数当成一个黑盒(我给黑盒一些数据,黑盒最终能够返回我想要的结果,具体里面是如何操作我并不关心)
- 相信这个黑盒一定能完成这个任务
dfs函数看成一个黑盒,我给你一个根节点,你把这个根节点后序遍历一下。我们要有一个心理暗示,相信这个dfs一定能够完成。接下来就是如何完成,后序先要遍历左子树,所以给dfs传入左子树根节点,右子树根节点,关于dfs如何完成并不关心。然后左右子数都完成了,就该根节点了。

如果把递归当成一个黑盒,不用关心那些递归展开图,直接看递归函数是如何进行的看某一层是如何操作的,具体是如何展开并不关心,我相信你一定能够完成这个任务。因为我们有之前第一层第二层的铺垫,编译器是会自动帮我们展开完成左子树右子树的遍历。然后再关注细节问题,这个递归代码就出来了。
merge看成一个黑盒,我给你一个数组和左端点和右端点,你把这个区间排下序,并且我相信这个黑盒一定能够完成任务。具体如何排序,就是选一个中间节点把数组平方成两部分,左边排好序,右边排好序,如何排序merge就是排序的具体你里面是如何操作的我不管,而且一定能够完成任务,因为以前我画过递归展开图。排好序之后再合并有序数组。注意处理细节不能出现死递归。

如何写好一个递归
1.先找到相同的子问题(确定每次要传什么)!!! ----> 函数头设计
2.只关心某一个子问题是如何解决的 -----> 函数体的书写
3.注意一下递归函数的出口即可
2.搜索
搜索 vs 深度优先遍历 vs 深度优先搜索 vs 宽度优先遍历 vs 宽度优先搜索 vs 暴搜
这些都是在搜索经常会碰见的名词
深度优先遍历 vs 深度优先搜索
宽度优先遍历 vs 宽度优先搜索
深度优先遍历一条路走到黑直到不能走在返回
宽度优先遍历一层一层走
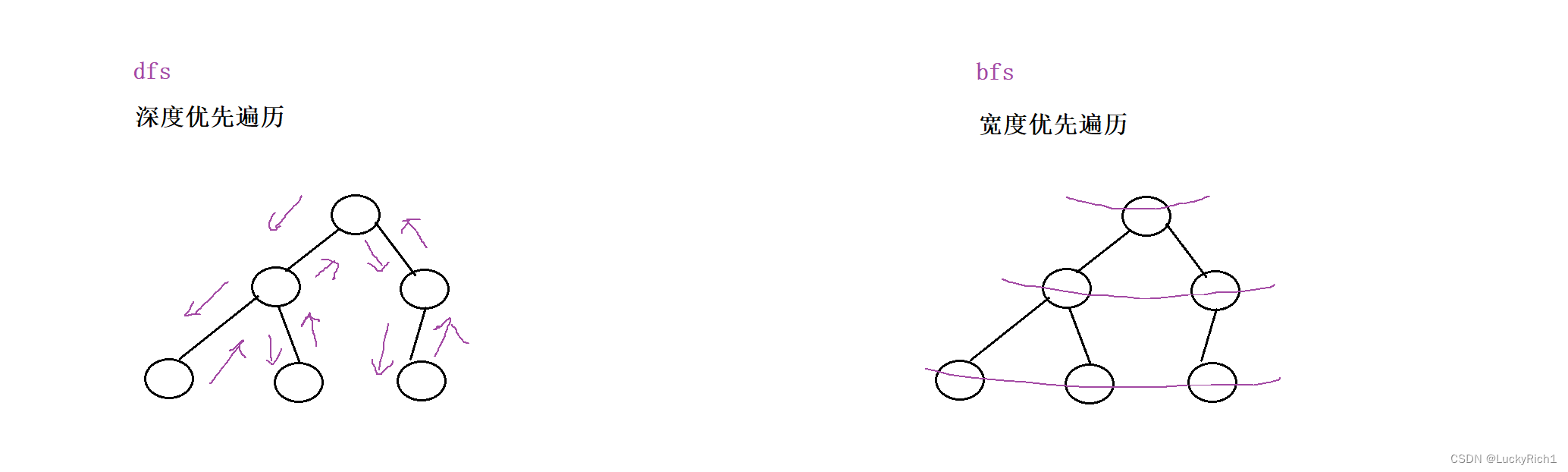
那什么是深度优先搜索和宽度优先搜索呢?
想一个问题,我们遍历的目的是不是为了找到节点里的值啊。所以深度优先遍历和深度优先搜索,宽度优先遍历和宽度优先搜索 其实就是一个东西。
遍历是形式,目的是搜索。 其实就是同一个东西!
搜索就是在这个树或者图,把所有节点都遍历一遍。
关系图
搜索的本质就是:暴力枚举一遍所有的情况。
所以搜索也可以叫做暴搜。
搜索(暴搜),把所有情况都暴力枚举一遍。它分为两种情况:1. dfs ,2. bfs
扩展搜索问题
搜索要么是树状结构,要么是图状结构。其实全排列就是树状结构
此时我们仅需从开始的位置开始把这棵决策树遍历一遍,也就是来一次深度优先遍历就可以把所有结构都可以找到。所以不要把深度优先遍历和宽度优先遍历局限于是必须是二叉树的题目和图的题目,如果一个题目能用一个决策树的形式画出来,我们就可以用搜索的形式把所有结果全都暴力枚举处理。
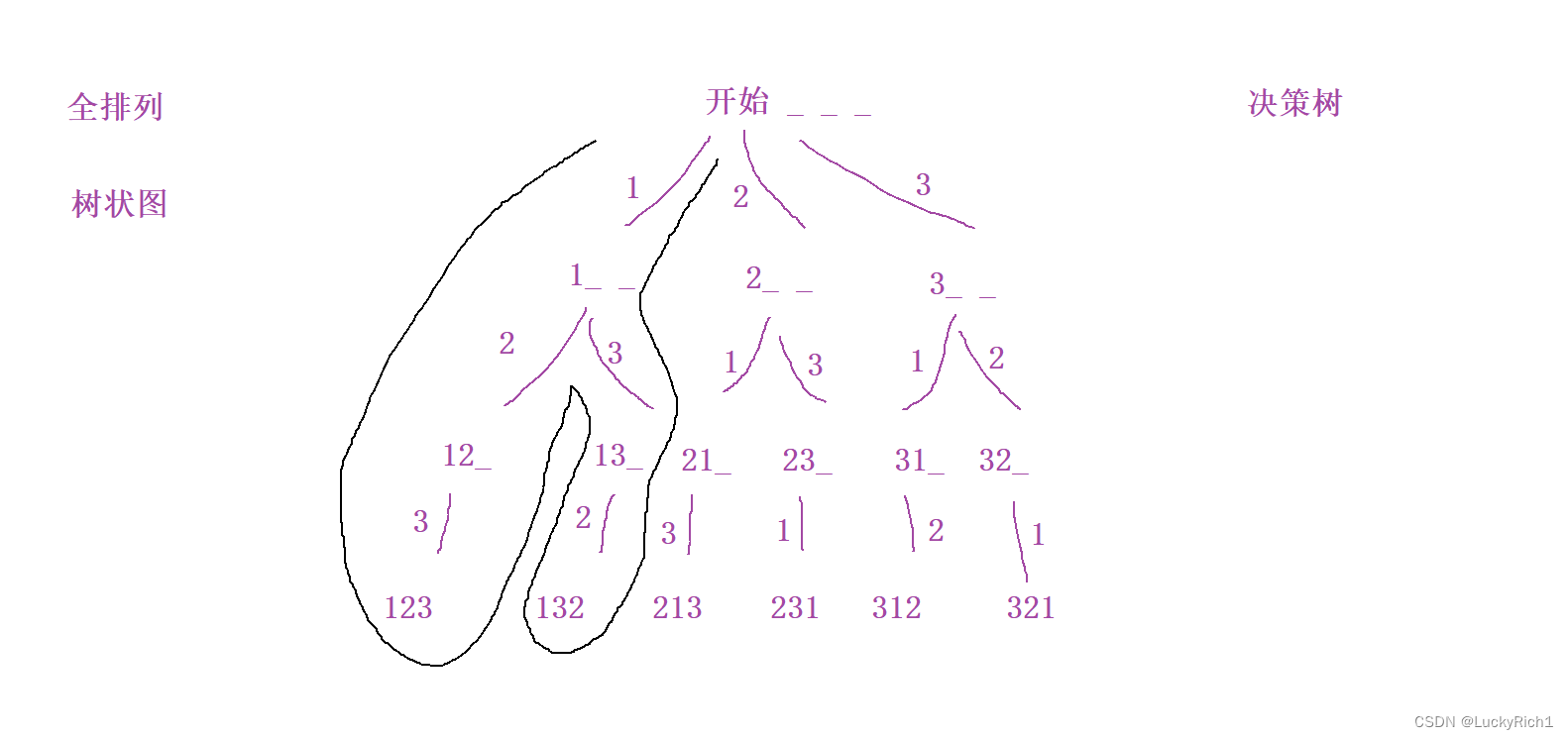
3.回溯与剪枝
回溯本质就是深度优先搜索
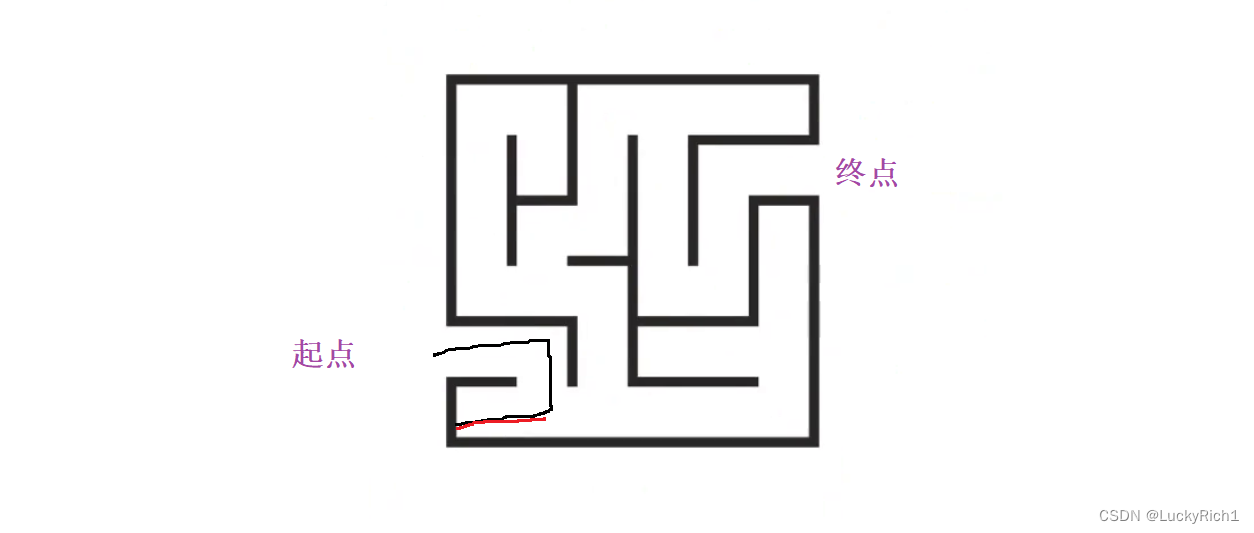
就比如迷宫问题,解决迷宫问题有两种方式,一个是深度优先遍历,一个是宽度优先遍历。下面我们采用深度优先遍历的方式,只要有拐角要么走左边,要么走右边,把所有情况都尝试一遍,一定能找到终点。
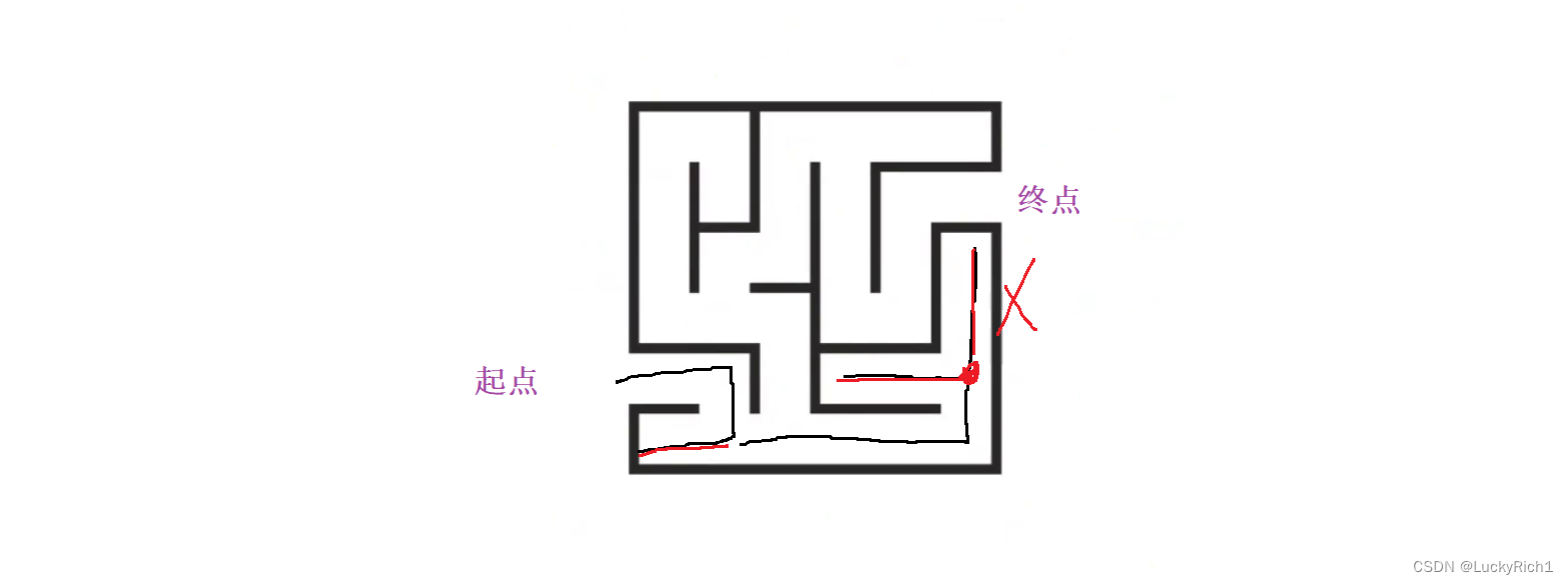
如果发现一条路走不通就返回,其中红色这条线就是回溯。回溯就是在找最终结果时尝试某种情况的时候发现某种情况行不通,此时返回上一级然后从上一级继续开始尝试。 这不是就是深搜的分支吗返回上一层的操作。回退上一级就是回溯,所以不要把回溯和深搜分开。
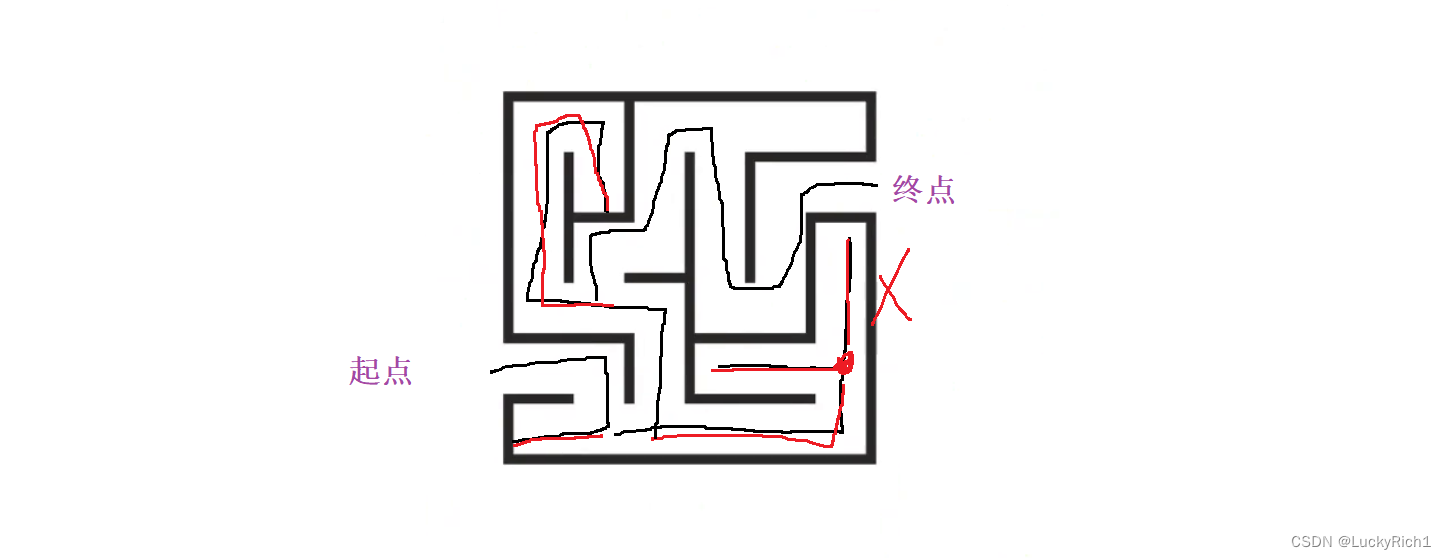
当再次回溯到同一点的时候,但是上面的已经走过了不用再走了,这种情况就是剪枝。剪枝就是这条分叉路口有两种选择,但是我们已经明确知道其中一个选择不是我们最终想要的结果,我们就可以把这个分支剪掉。
所以不要把回溯和剪枝想的有多难,回溯就是深搜的一个小分支而已。
4.汉诺塔问题
题目链接:面试题 08.06. 汉诺塔问题
题目分析:

有三根柱子和一些盘子,将第一根柱子上面所有盘子借助其他柱子移动到最后一根盘子上。
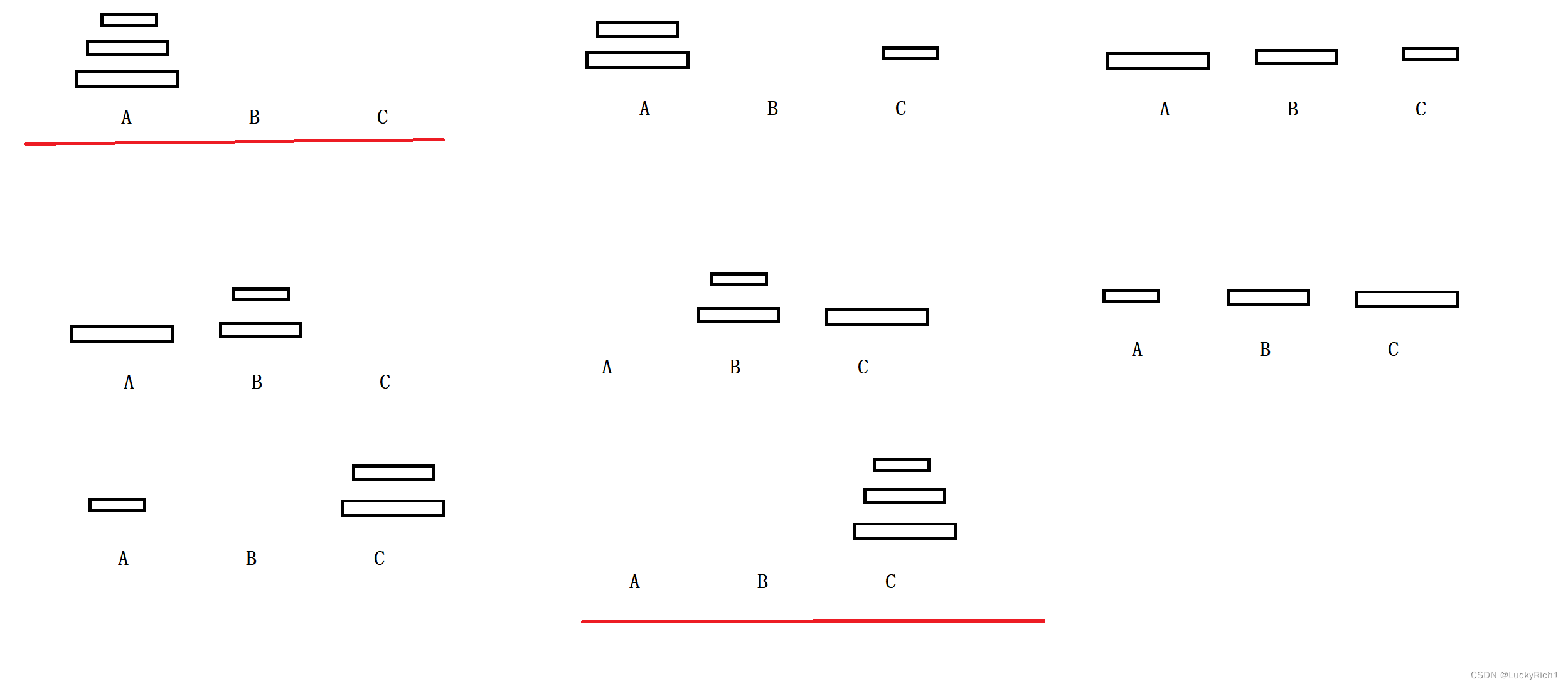
算法原理:
不要看到汉诺塔就马上使用递归,一定知道为什么可以用递归,这比如何用递归解决这个问题更加重要。
1.如何解决汉诺塔问题
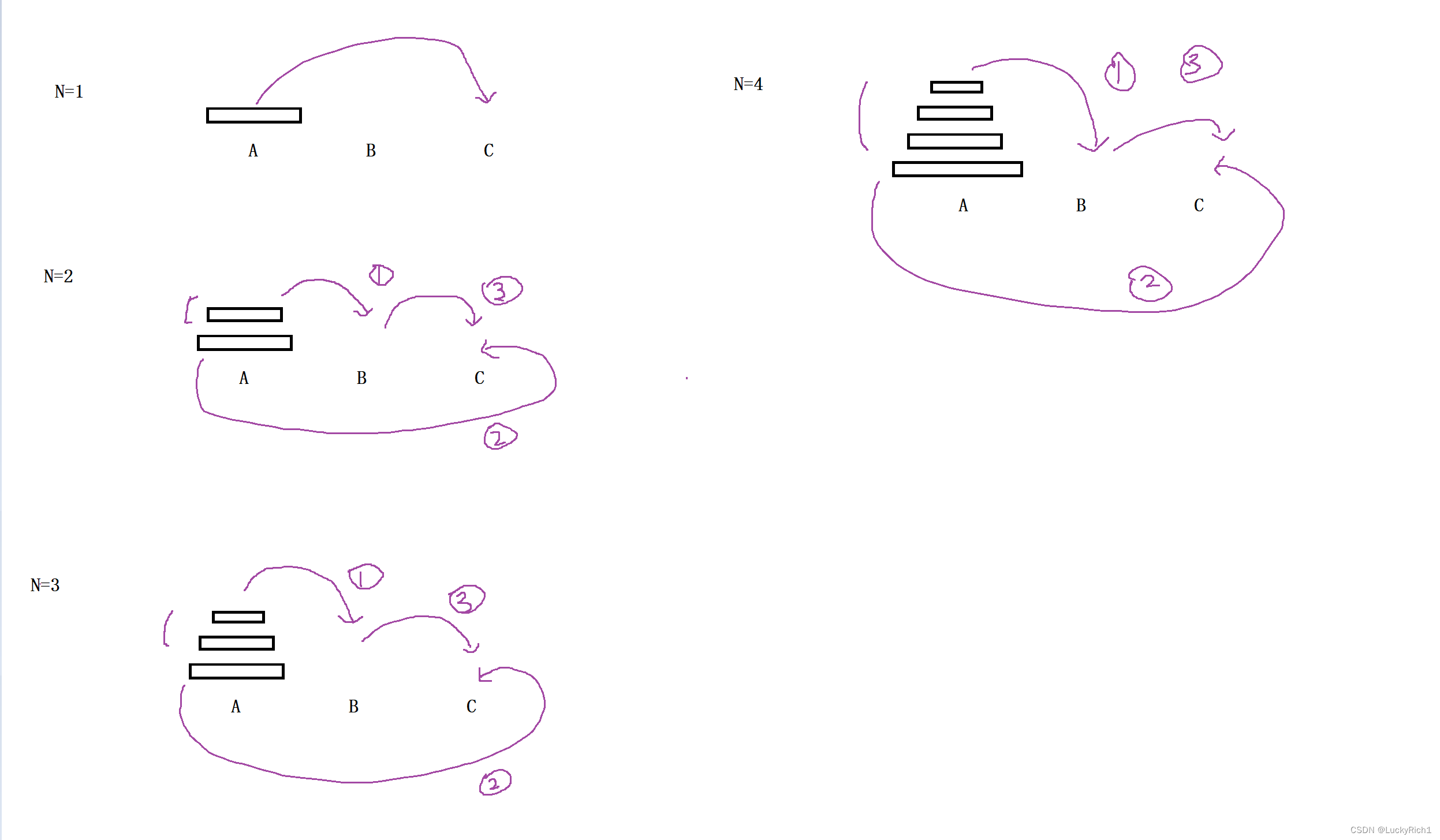
当只有一个盘子的时候,可以直接移动到最后一个柱子上
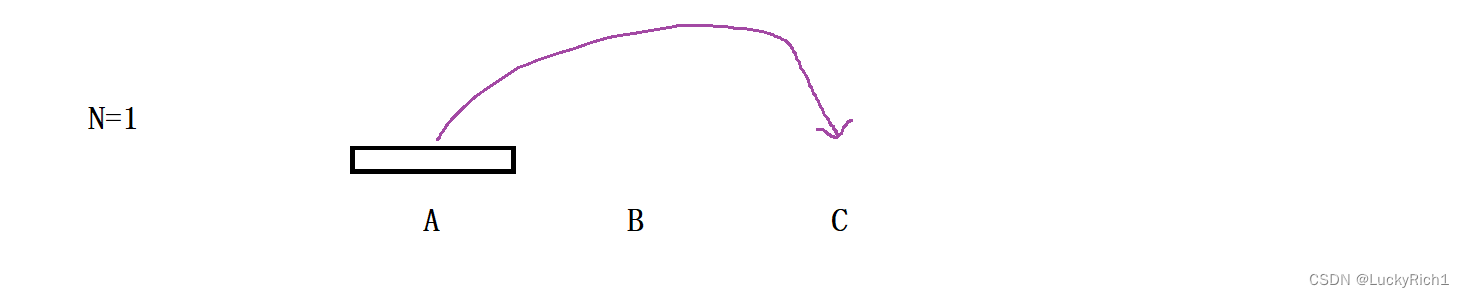
当有两个盘子的时候,1. 将A柱最下面盘子上面的盘子先放到B柱,2. 将A柱最下面的一个放到C柱,3. 然后将B柱上面的盘子在放到C柱
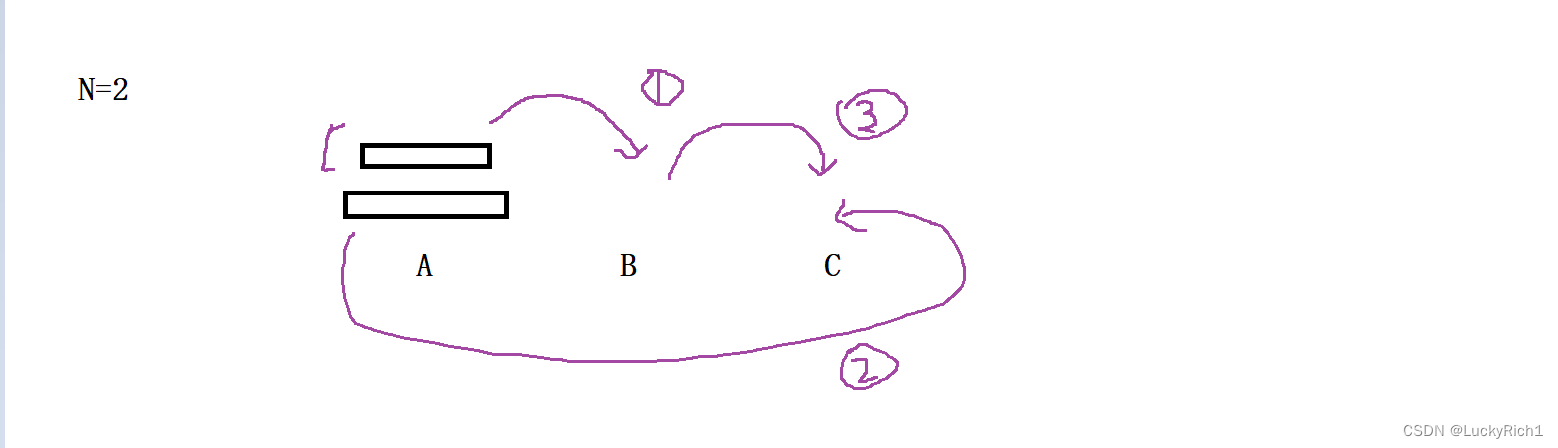
当有三个盘子的时候,1. 将A柱最下面盘子上面的盘子先放到B柱,2. 将A柱最下面的一个放到C柱,3. 然后将B柱上面的盘子在放到C柱
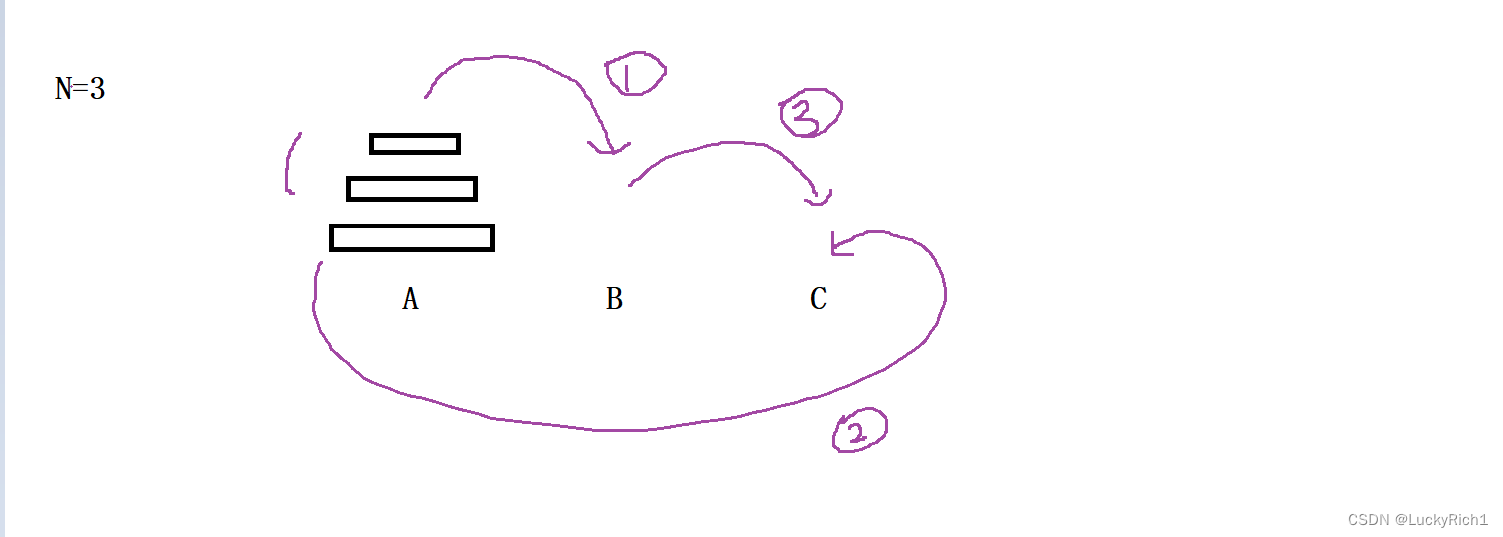
当有四个盘子的时候,1. 将A柱最下面盘子上面的盘子先放到B柱,2. 将A柱最下面的一个放到C柱,3. 然后将B柱上面的盘子在放到C柱
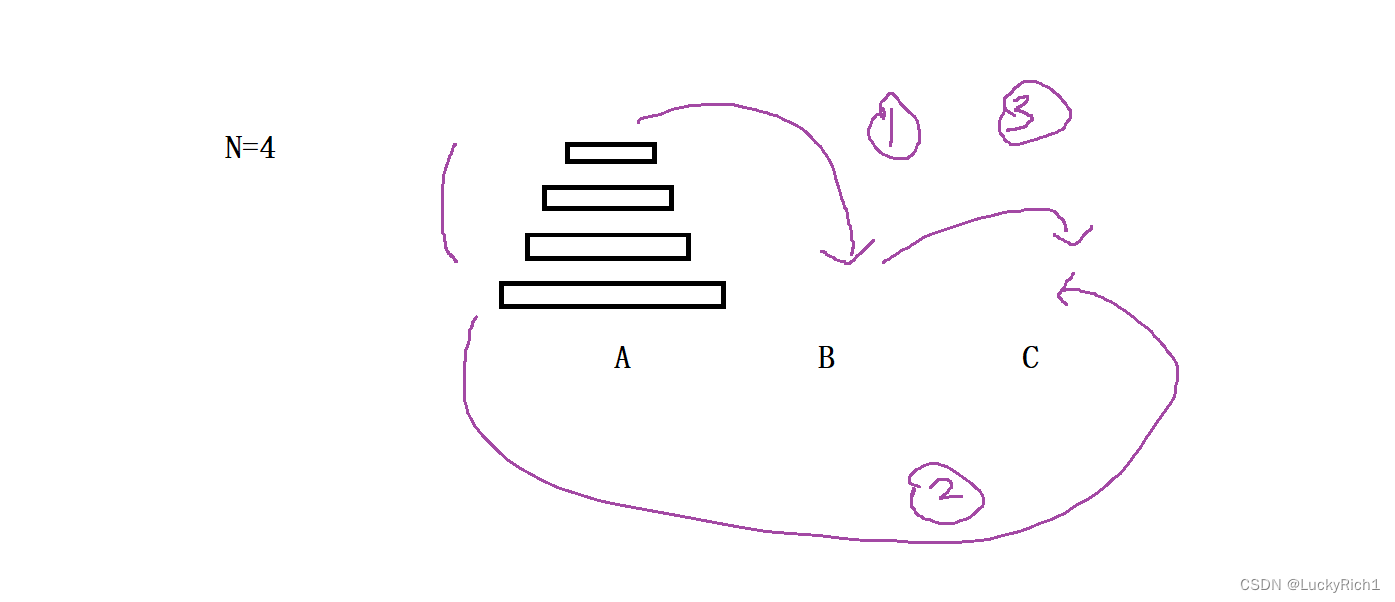
2.为什么可以用递归?
当我们发现解决大问题的时候,出现相同类型的子问题。并且解决方法都是一样的。此时就可以用递归了。
大问题 —> 相同类型的子问题
子问题 —> 相同类型的子问题
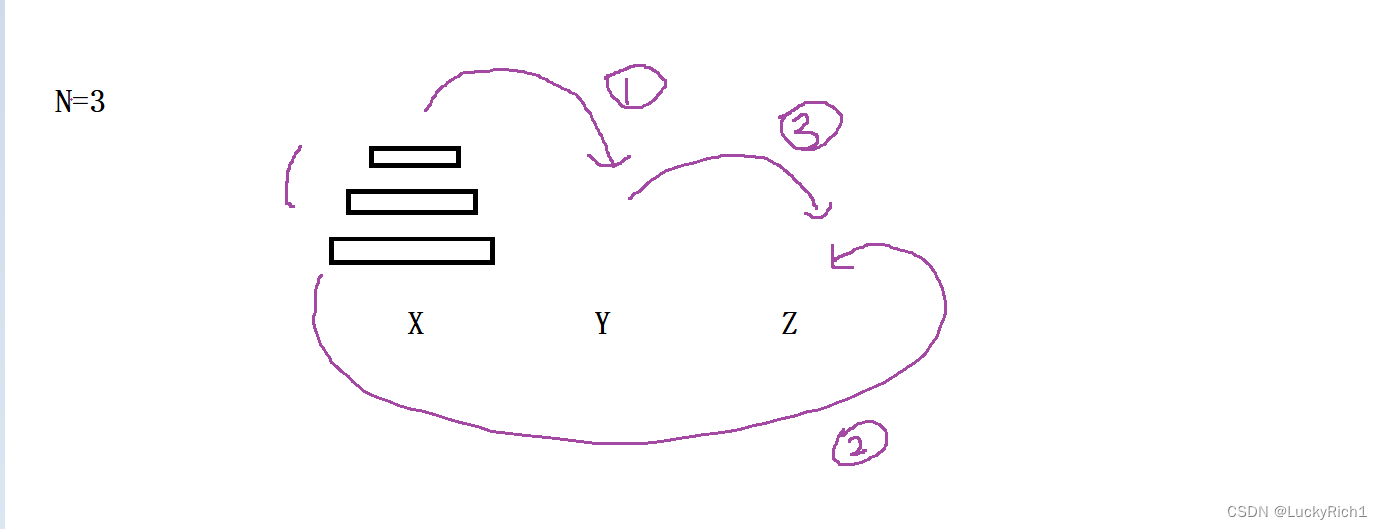
3.如何编写递归?
- 重复的子问题 ----> 函数头
我们发现都是一根柱子上的盘子借助另一个柱子将盘子转移到其他柱子上面的,因此我们可以总结出来。
将 x 柱子上的一堆盘子,借助 y 柱子,转移到 z 柱子上面 ----> void dfs(x,y,z,int n)
- 只关心某一个子问题在做什么 ----> 函数体
dfs(x,z, y,n-1) 将x柱上n-1个盘子借助z柱,转移到y柱子 第
x.back() -> z 将x柱最后一个盘子,转移到z柱
dfs(y,x,z,n-1) 将y柱上n-1个盘子借助x柱,转移到z柱
我们要以宏观角度理解递归函数,只要给它数据它一定能够帮我们完成任务。不用管具体的递归过程。
- 递归的出口
n==1的时候,不用借助其他柱子,直接放就可以了。 x.back() --> z
根据上面我们就可以写代码了
class Solution {
public:void hanota(vector<int>& a, vector<int>& b, vector<int>& c) {dfs(a,b,c,a.size());}void dfs(vector<int>& a, vector<int>& b, vector<int>& c,int n){if(n == 1){c.push_back(a.back());a.pop_back();return;}dfs(a,c,b,n-1);c.push_back(a.back());a.pop_back();dfs(b,a,c,n-1);}
};
有兴趣可以自己画一下递归展开图。
5.合并两个有序链表
题目链接:21. 合并两个有序链表
题目分析:
算法原理:
将两个有序链表合并然后返回合并后的头指针,我们可以先找到l1,l2指向的最小节点当作合并后的头指针,然后让剩下的节点合并,这时就出现了重复的子问题,我们的大问题是将全部的节点合并,此时我们选择了合并后的返回的头指针,那仅让剩下的节点合并。
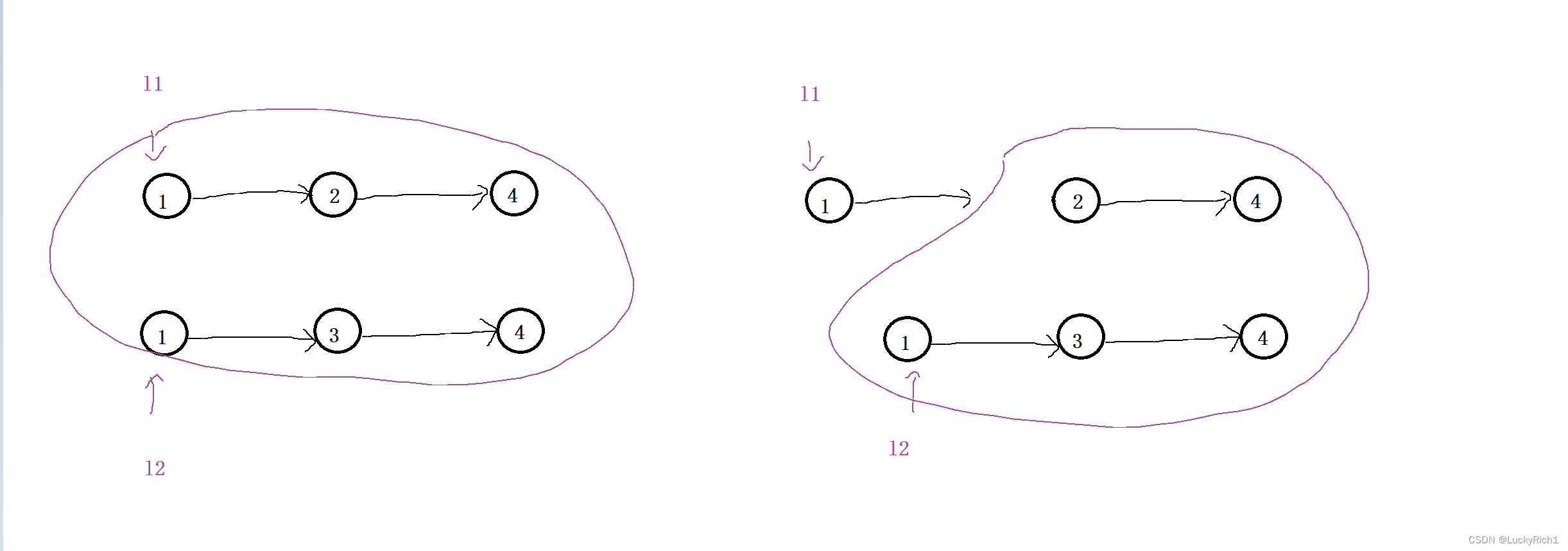
解法:递归
1.重复的子问题 —> 函数头的设计
合并两个有序链表 --> Node* dfs(l1 ,l2) ,仅需传两个链表的头指针,然后把合并后的头指针给我返回来就好了。具体这个dfs怎么去完成这个任务我不管,我相信它 一定能够完成任务。给它两个链表头指针就能给我返回合并之后的头指针。
2.只关心某一个子问题在做什么事情 —> 函数体的设计
- 比大小
- l1->next=dfs(l1->next,l2) l1当头指针让它连接剩下节点合并后的结果,相信dfs一定能把剩下节点合并,此时仅需让l1连着剩下节点合并后的结果就好了。剩下节点如何合并我不关心,我相信dfs一定将合并后的结果给我。
- return l1
这里假设l1较小,如果l2较小上面l1改成l2就行了
3.递归的出口
当l1为空,返回l2 ,l2为空 返回l1 ,l1 l2 都为空返回任意一个
class Solution {
public:ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {if(l1 == nullptr) return l2;if(l2 == nullptr) return l1;if(l1->val <= l2->val){l1->next=mergeTwoLists(l1->next,l2);return l1;}else{l2->next=mergeTwoLists(l1,l2->next);return l2;}}
};
小总结:
循环(迭代) vs 递归
循环(迭代) vs 递归 都是解决重复的子问题 这件事情,所以 它们两者之间可以相互转化。循环改递归,递归改循环。
什么时候用循环,什么时候用递归?
我们先解决递归和深搜的关系,我们在回头看这个东西
就比如汉诺塔那个问题 递归展开图。真正展开就是下面这个样子。 它展开的顺序和树的深度优先遍历是一模一样的。递归的展开图,其实就是对一棵树做一次深度优先遍历(dfs)
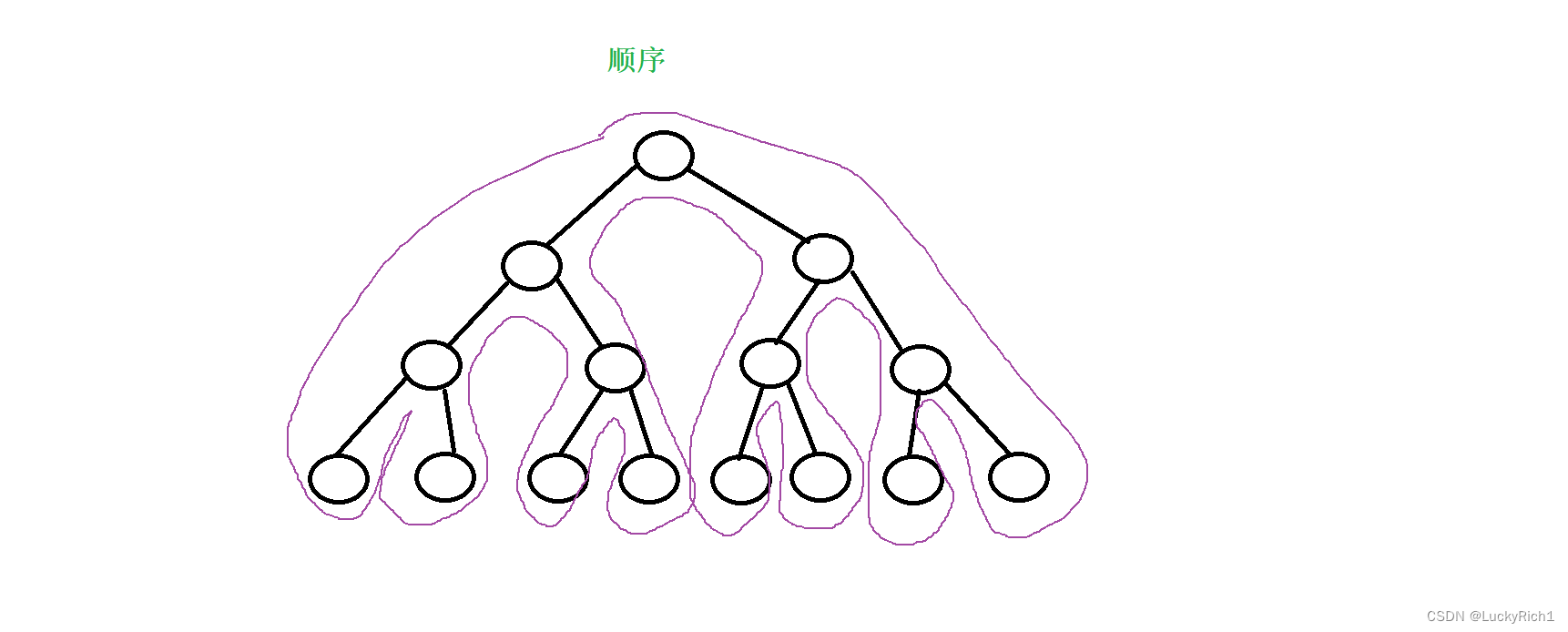
如果此时你想把这个递归转化成循环的话,需要借助一个栈,因为你递归展开左边的图的时候还需要展开右边的图,因此首先要保存一下这个信息等左边递归回来的时候在从这里出发去右边递归。但是这样成本就来了,本来汉诺塔递归代码就三四行,你要借助栈把它改成循环那代码量就上来了。
所以当递归展开图有点麻烦的时候,我们用递归解决这个问题比较好。
如果递归展开图是如下面的形状,这棵树只有一个分支,像这样的递归改成循环是比较容易的。
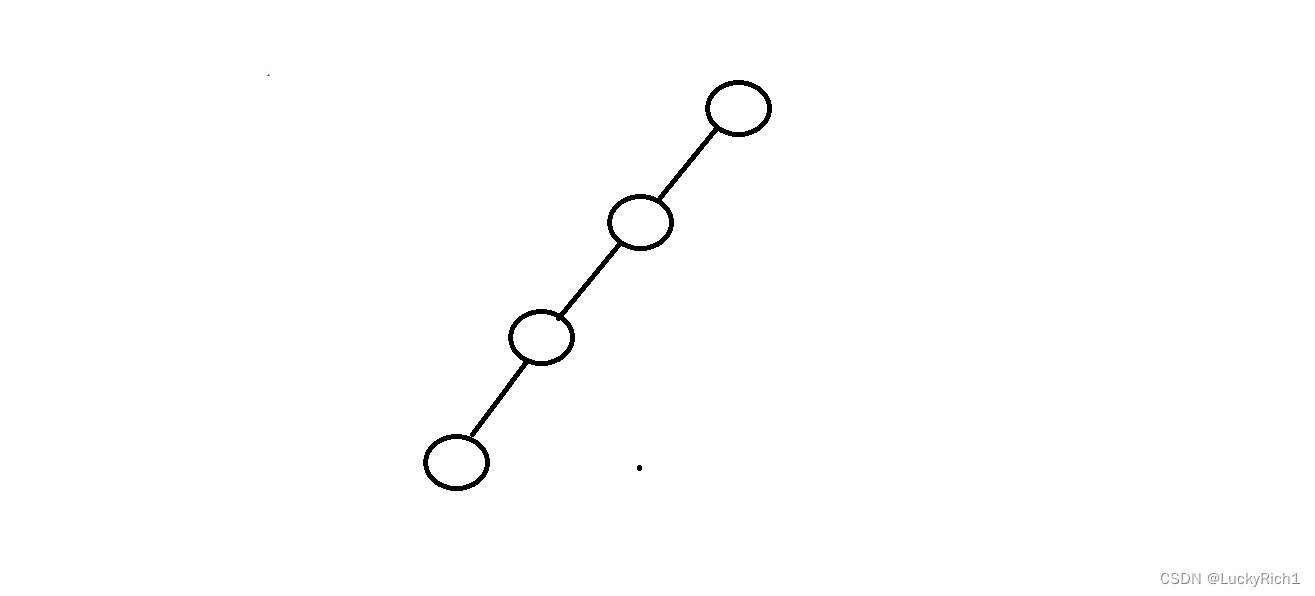
先序遍历和后序遍历对于上面的图来说虽然都是遍历,但是处理时机不一样结果就不意义。先序遍历是从上到下历,后序遍历是从下到上。那什么时候搞先序什么时候搞后序呢?那个方式简单就用那个,后面的题我们会体会到。中序遍历仅适用于二叉树。
6.反转链表
题目链接:206. 反转链表
题目描述:
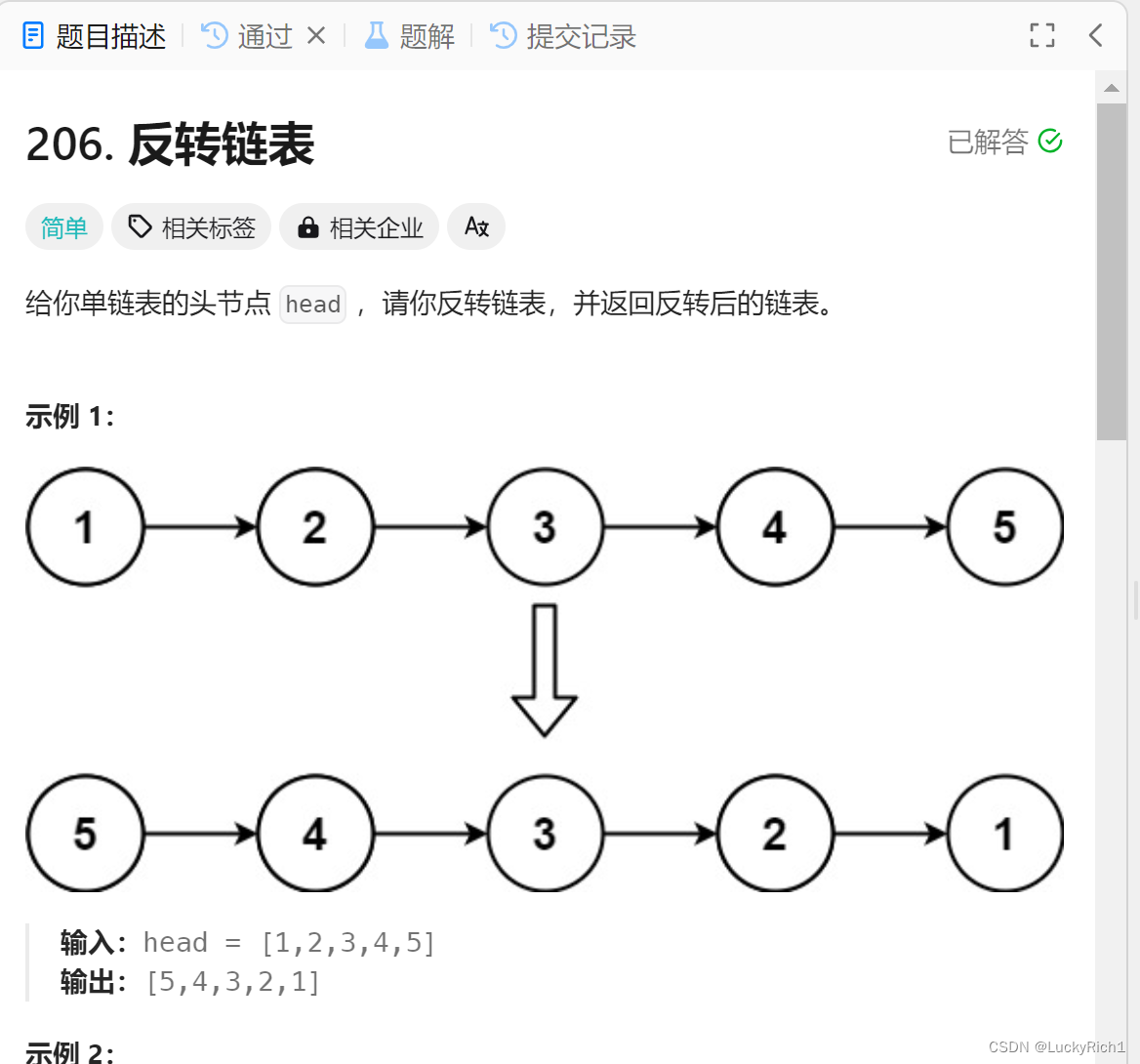
算法原理:
这题循环也能做,不过这里我们不考虑用循环,直接用递归,不过我们以两种视角来做这道题。
解法:递归
第一种视角:从宏观角度看待问题
要求逆序整个链表,我可以先把前两个节点逆序一下,可以让
head->next->next=head;head->next=nullptr
虽然完成了前两个节点的逆置,但是此时有一个问题,你发现后面的节点丢弃了!
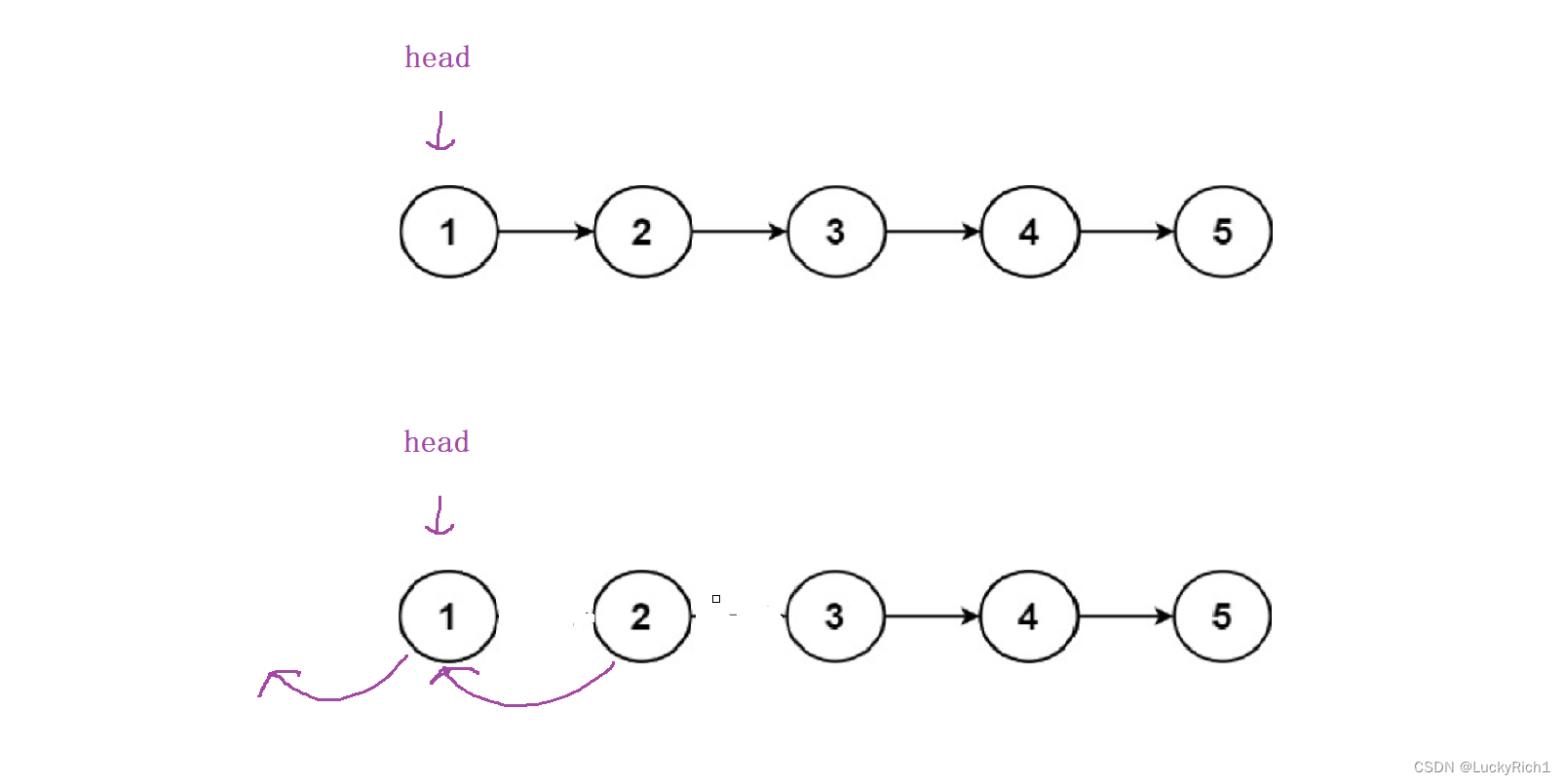
所以先逆置前面两个节点是不行的,因此先把后面一堆节点逆置,具体怎么逆置并不关心,我相信dfs一定可以把head->next后面节点全部逆置,逆序完之后,我仅需在把head连接到逆序链表的后面。如何连接和刚才做法一下,head->next->next=head;head->next=null;此时就完成了整个链表逆序。
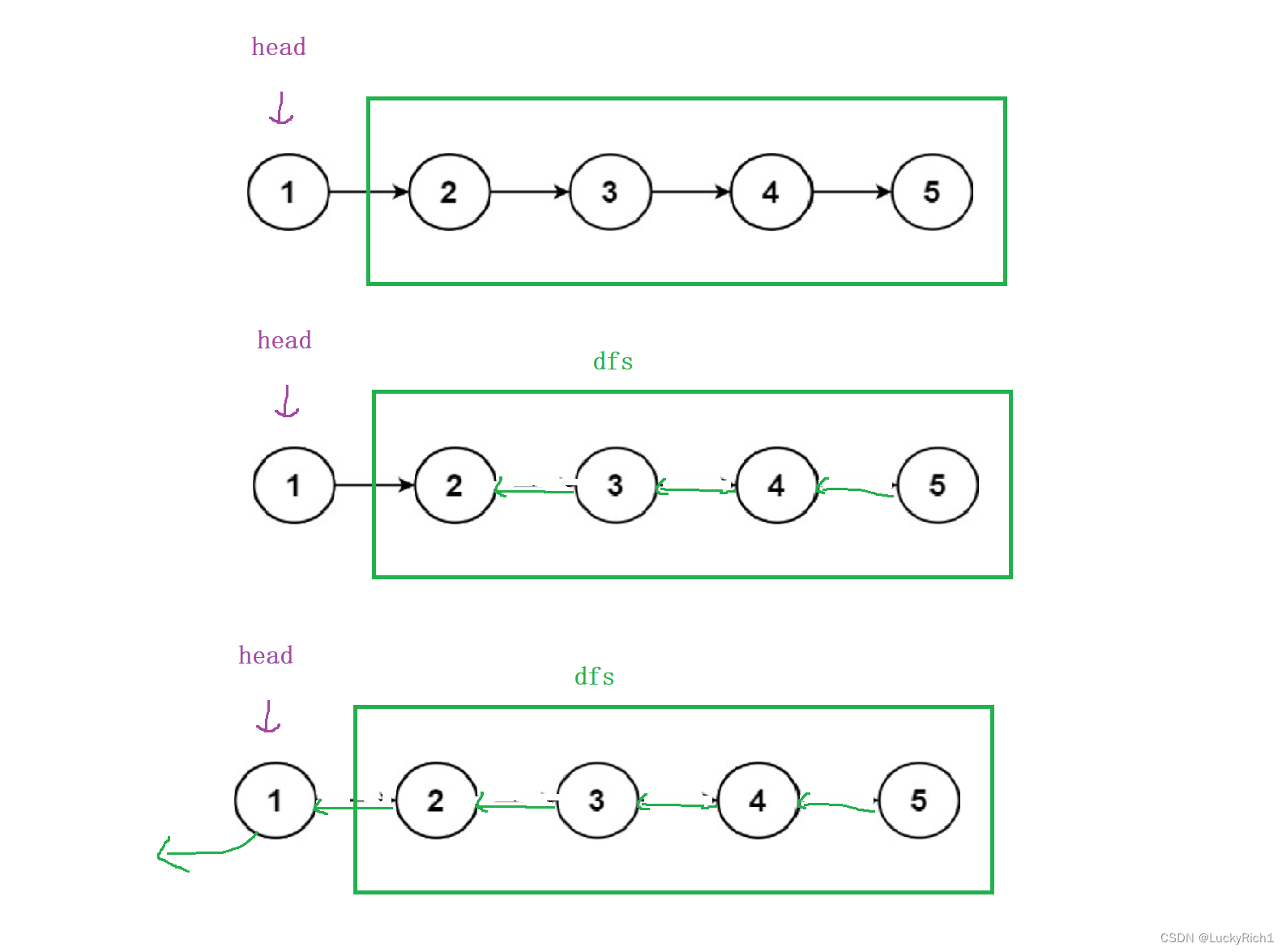
- 让当前节点后面的链表先逆置,并且把头结点返回
- 让当前节点添加到逆置后的链表即可
如果上面不太理解,那我们换一种角度
第二种角度:将链表看成一棵树
无论是二叉树,还是多叉树都是树形结构,但是链表其实也是一个树形结构,无非就是一个节点只有一个分支!
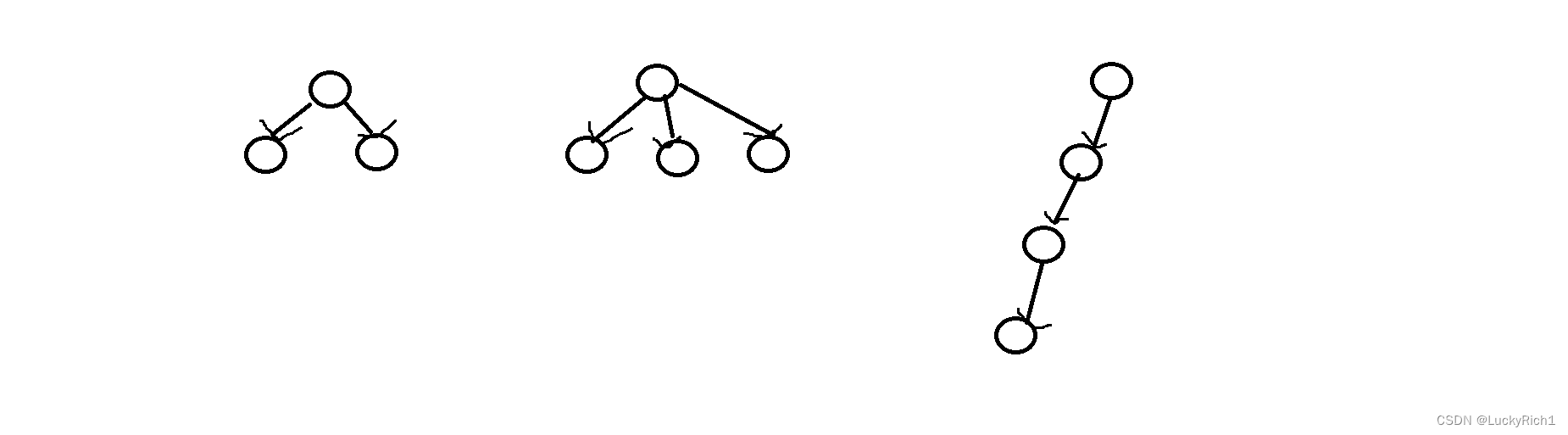
然后对这个链表做一次逆置,仅需做一次后序遍历即可!
从上往下走,当发现此时有个节点为null或者是叶子节点的时候,这就是我们要找的逆置之后的头,这个头要一层层的返回去,每个递归函数内部都做同样的事情,把头返回去,然后逆置。
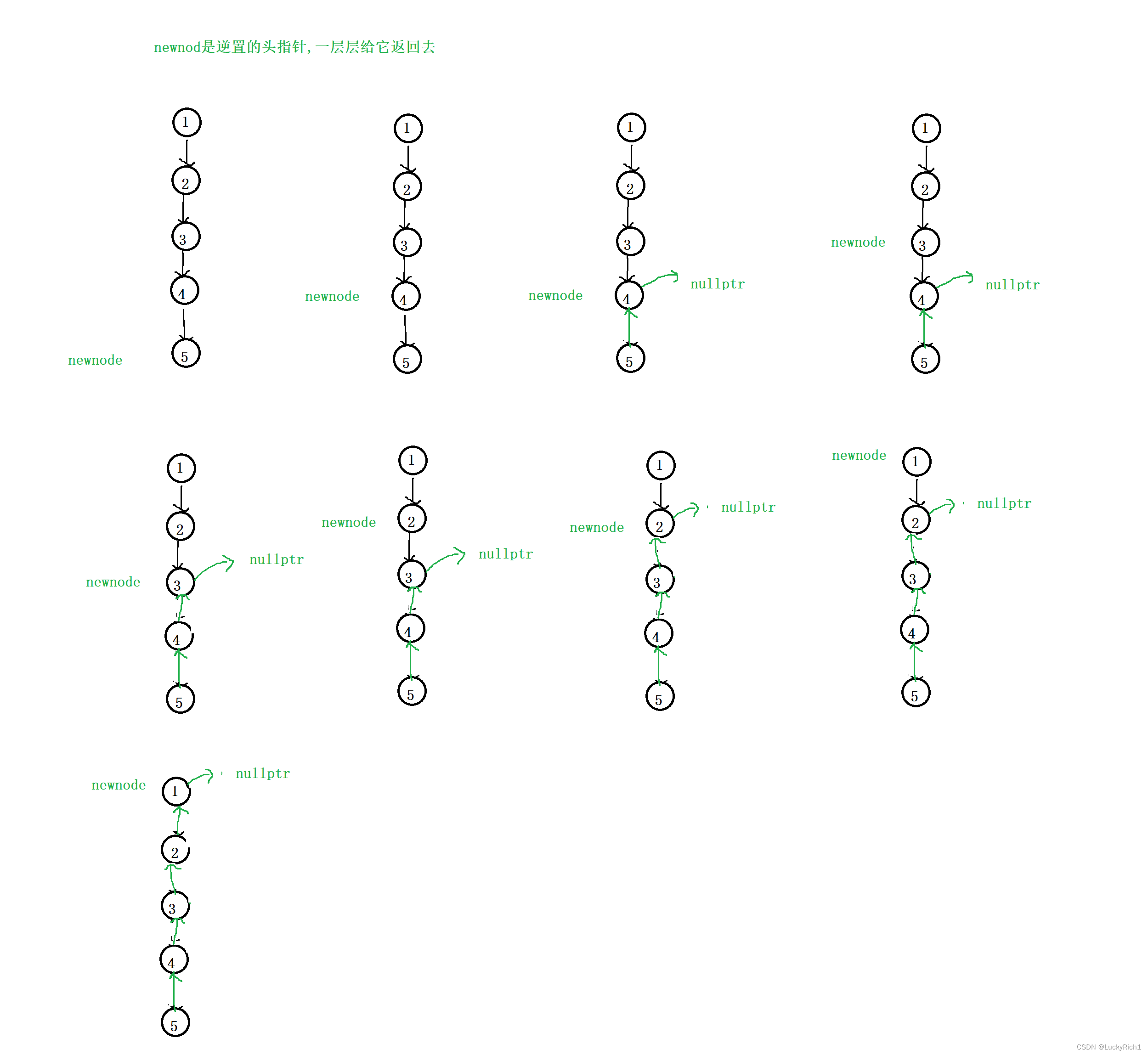
class Solution {
public:ListNode* reverseList(ListNode* head) {if(head == nullptr || head->next == nullptr)return head;ListNode* newhead=reverseList(head->next);head->next->next=head;head->next=nullptr;return newhead;}};
7.两两交换链表中的节点
题目连接:24. 两两交换链表中的节点
题目描述:
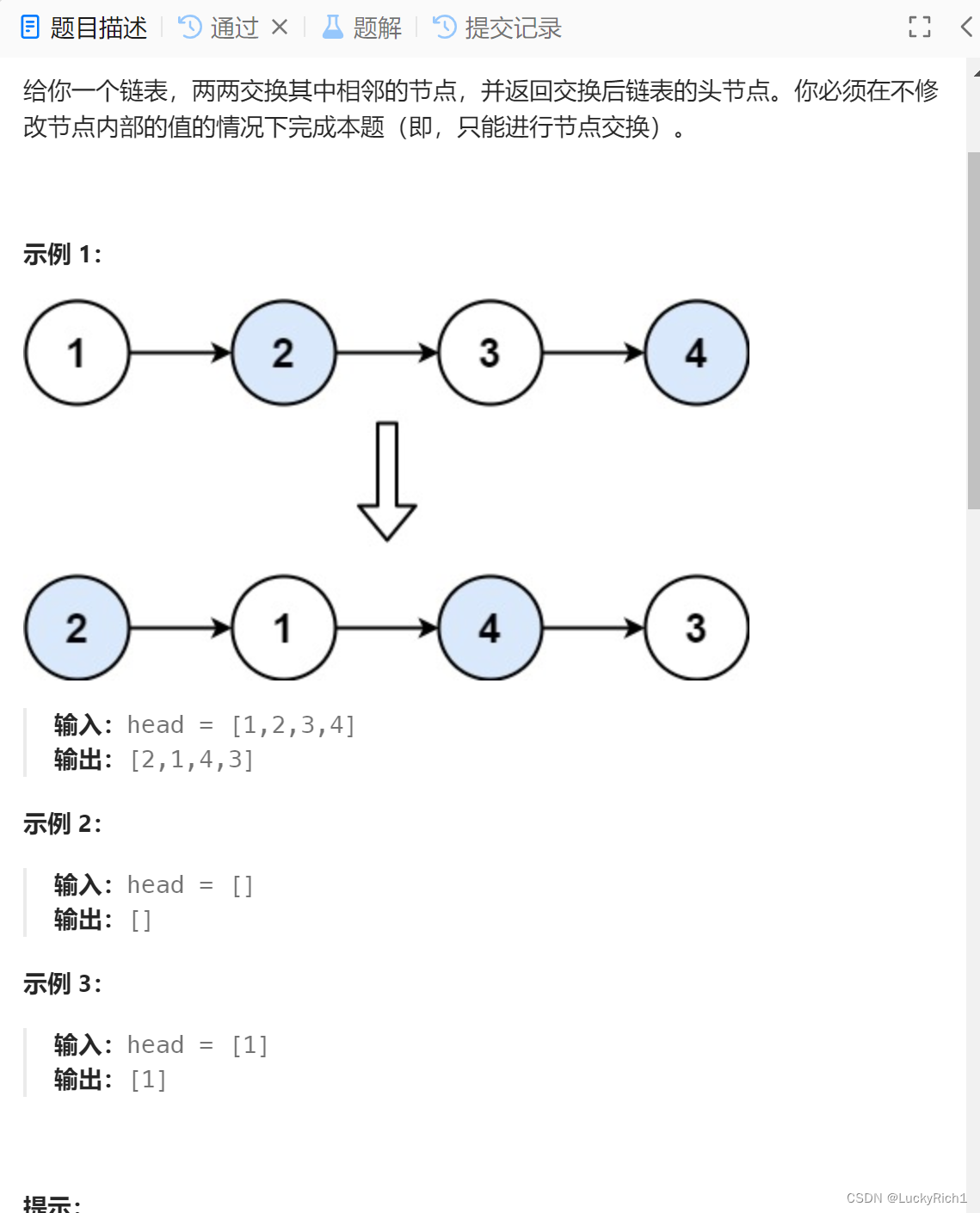
注意不能改变节点内的值,而是要改变指针指向
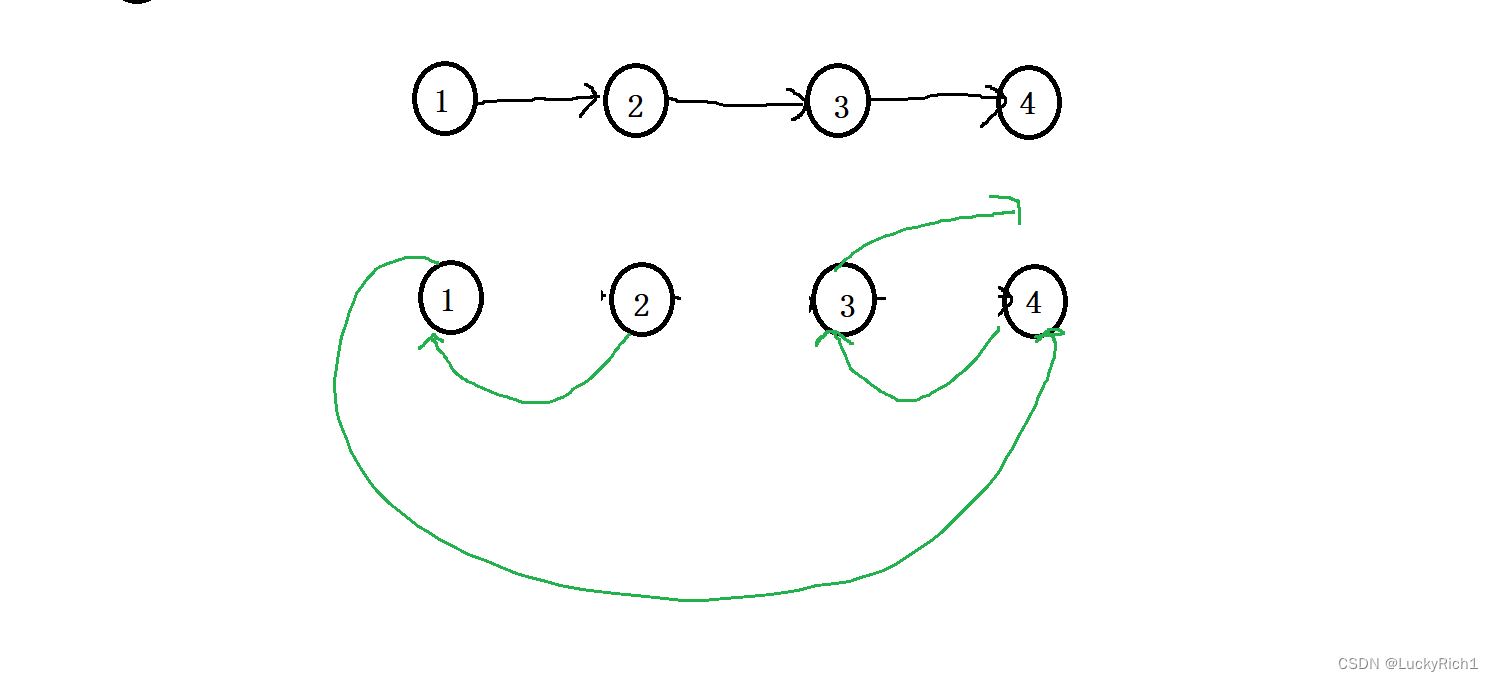
算法原理:
从上面的题我们就知道了,可以以两种视角看待链表递归了。不过我们还是用常用的宏观角度解决问题。把递归函数看成一个黑盒并且相信它一定能够完成任务,这样非常简单。
解法:递归
当有上面链表逆置的基础,你发现这两道题是一模一样的。这道题让把链表两两交换然后把交换后的链表头指针返回。那就给dfs赋予一个使命,给它传一个链表的头指针然后把链表两类交换并且交换后的链表头指针返回。
此时让后面的节点先两两交换然后把头指针返回来,然后仅需将前面两个节点交换一下,将交换后的结果和后面的链表连起来就可以了。
class Solution {
public:ListNode* swapPairs(ListNode* head) {if(head == nullptr || head->next == nullptr)return head;auto tmp=swapPairs(head->next->next);auto ret=head->next;head->next->next=head;head->next=tmp;return ret;}
};
8.Pow(x, n)-快速幂(medium)
题目链接:50. Pow(x, n)
题目描述:

这里是一个快速幂算法。给一个数快速求出它的幂。
算法原理:
解法一:暴力循环
但可能会有越界风险
解法二:快速幂
快速幂有两种实现方式:1. 递归,2. 迭代
这里我们主要是递归。上面暴力循环,假设x^n 需要 x乘n次。想办法优化一下
当求x的n次幂,我可以先求出x的n/2次幂,这样就知道一半的幂了,此时在乘一次一半的幂。不就得到答案了吗,注意这里n是要分偶次和奇次的。
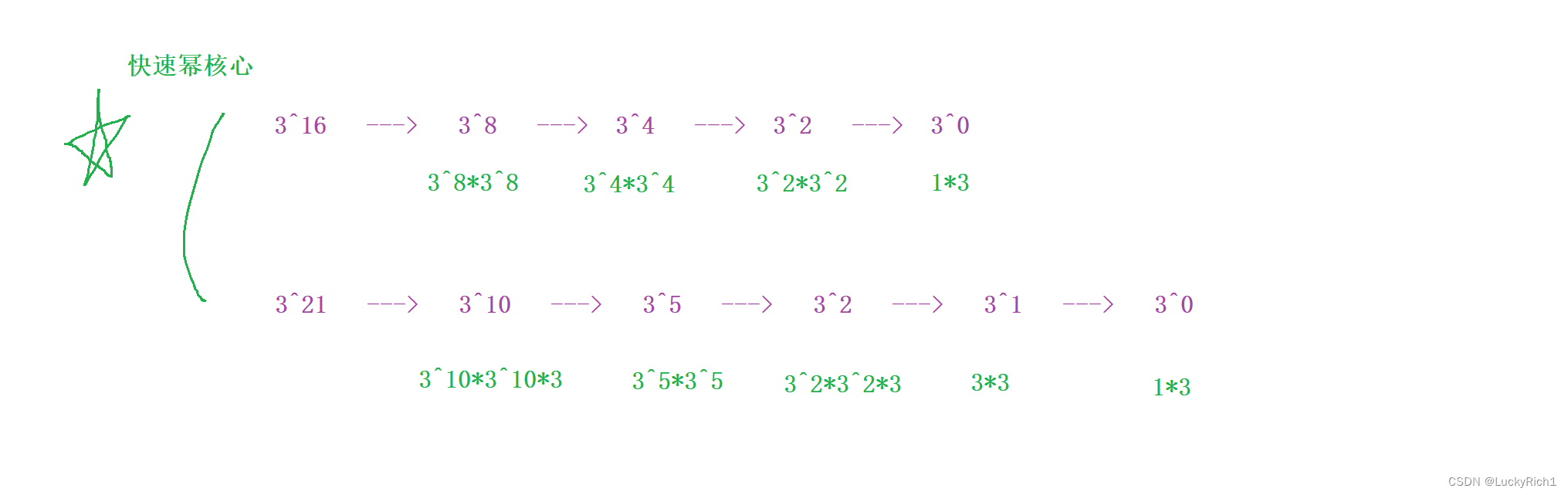
当我们在解决一个大问题的时候又出现了相同的子问题,此时我们就可以用递归了!
- 相同的子问题 —> 函数头
int pow(x,n),我只要给pow一个数x,一个幂n,让它把x的幂给我返回来。我不关心它是如何实现的。 - 只关心每一个子问题都做了什么 —> 函数体
首先我要知道一半的幂是多少 tmp=pow(x,n/2)
然后分情况f返回 return n%2 == 0 ? tmp * tmp : tmp * tmp * x - 递归出口
n==0,就不用在递归了
注意有细节问题:
-
n有可能是负数
负数转成正数,结果用1除一下
2^-3 —> 1/2^3 -
n有可能是-2^31
-2 ^ 31转成正数是2 ^ 31,这比int最大还要大,因此强制转化为long long
class Solution {
public:double myPow(double x, int n) {return n<0 ? 1.0/pow(x,-(long long)n) : pow(x,n);}double pow(double x,long long n){if(n == 0) return 1.0;double tmp=pow(x,n/2);return n%2 == 0 ? tmp*tmp : tmp*tmp*x;}
};
相关文章:
【递归、搜索与回溯】递归、搜索与回溯准备+递归主题
递归、搜索与回溯准备递归主题 1.递归2.搜索3.回溯与剪枝4.汉诺塔问题5.合并两个有序链表6.反转链表7.两两交换链表中的节点8.Pow(x, n)-快速幂(medium) 点赞👍👍收藏🌟🌟关注💖💖 你…...

MVC前端怎么写:深入解析与实战指南
MVC前端怎么写:深入解析与实战指南 在Web开发领域,MVC(Model-View-Controller)是一种广泛使用的架构模式,它将应用程序的数据、界面和控制逻辑分离,使得代码更加清晰、易于维护。本文将详细探讨MVC前端如何…...

LINUX网络设置
一、1.1.ifconfig:当前设备正在启动的网卡(启动的) ifconfig -a :当前所有设备的网卡(启动的和没有启动的都包括) 1.2.ifconfig展示的ens33各行含意: 1.2.1 ens33: flags 4163<UP, …...

双指针解题
验证回文数(验证回文数-CSDN博客)和判断在子序列(判断子序列-CSDN博客)已经在之前进行了计算,今天有三个新的双指针问题: 两数之和II—输入有序数组 给你一个下标从 1 开始的整数数组 numbers ࿰…...
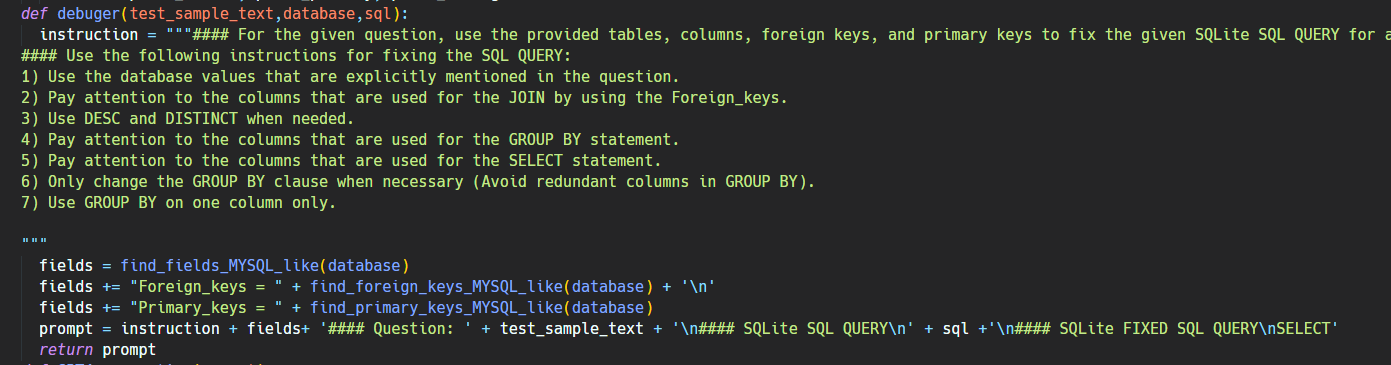
【Text2SQL 论文】DIN-SQL:分解任务 + 自我纠正 + in-context 让 LLM 完成 Text2SQL
论文:DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction ⭐⭐⭐⭐ NeurIPS 2023, arXiv:2304.11015 Code: Few-shot-NL2SQL-with-prompting | GitHub 文章目录 一、论文速读1.1 Schema Linking Module1.2 Classification & Decompo…...

基于Springboot+vue实现的汽车服务管理系统
作者主页:Java码库 主营内容:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app等设计与开发。 收藏点赞不迷路 关注作者有好处 文末获取源码 技术选型 【后端】:Java 【框架】:spring…...

ROS2从入门到精通4-3:全局路径规划插件开发案例(以A*算法为例)
目录 0 专栏介绍1 路径规划插件的意义2 全局规划插件编写模板2.1 构造规划插件类2.2 注册并导出插件2.3 编译与使用插件 3 全局规划插件开发案例(A*算法)常见问题 0 专栏介绍 本专栏旨在通过对ROS2的系统学习,掌握ROS2底层基本分布式原理,并具有机器人建…...
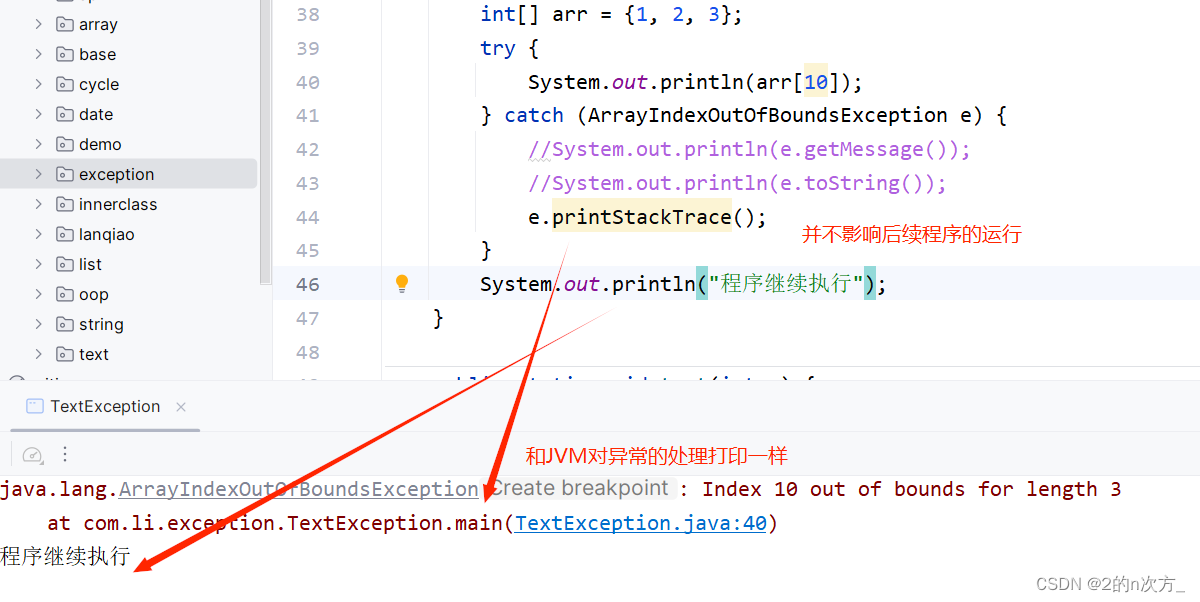
Java学习【认识异常】
Java学习【认识异常】 认识异常异常的种类异常的作用 异常的处理方式JVM默认的处理方式捕获异常finally 多个异常的处理异常中的方法抛出异常 自定义异常 认识异常 在Java中,将程序执行过程中发生的不正常行为称为异常 异常的种类 Error代表的是系统级别的错误&a…...

uniapp+h5 ——微信小程序页面截屏保存在手机
web-view 需要用到 web-view ,类似于iframe, 将网页嵌套到微信小程序中,参数传递等; 示例(无法实时传递数据),页面销毁时才能拿到h5传递的数据,只能利用这点点击跳转到小程序另一个…...
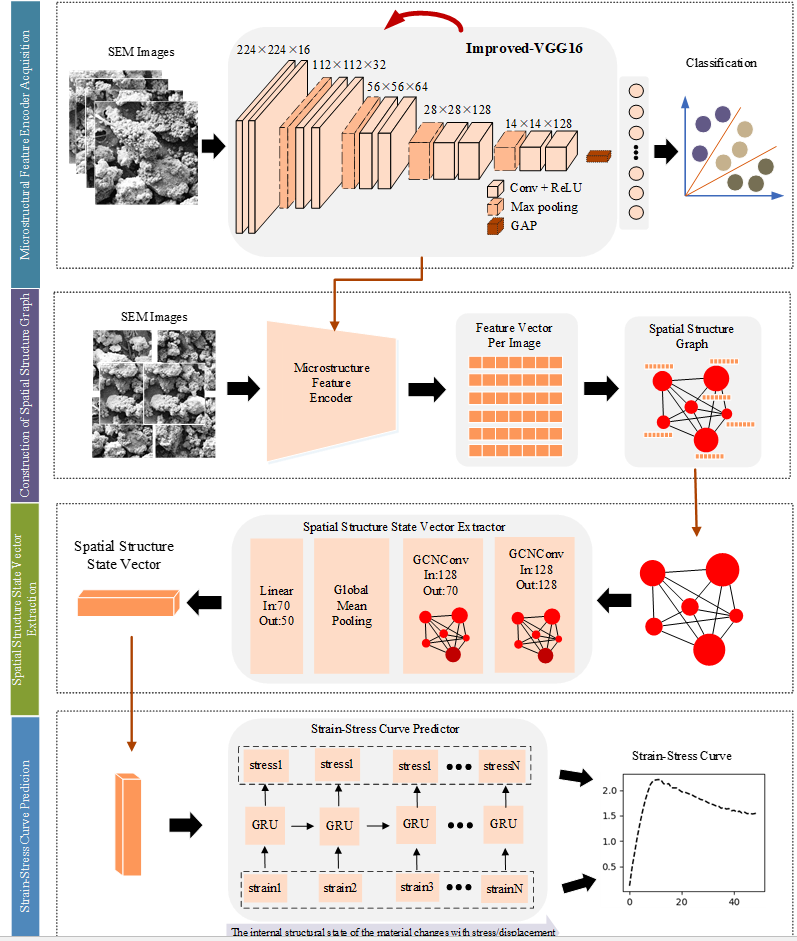
三、基于图像分类预训练编码及图神经网络的预测模型 【框图+源码】
背景: 抽时间补充,先挖个坑。 一、模型结构 二、源码...
Linux - 高级IO
目录 理解五种IO模型非阻塞IO的设置多路转接之select 实现一个简易的select服务器select服务器的优缺点 多路转接之poll 实现一个简易的poll服务器poll服务器的优缺点 多路转接之epoll epoll原理epoll的优势用epoll实现一个简易的echo服务器 epoll的LT和ET工作模式 什么是LT和…...

面试题:说一下 http 报文都有哪些东西?
面试题:说一下 http 报文都有哪些东西? HTTP 是传输超文本(实际上除了 HTML,可以传输任何类型的文件,如视频、音频、文本等)的协议,是一组用于浏览器-服务器之间数据传输的规则。 HTTP 位于 OS…...
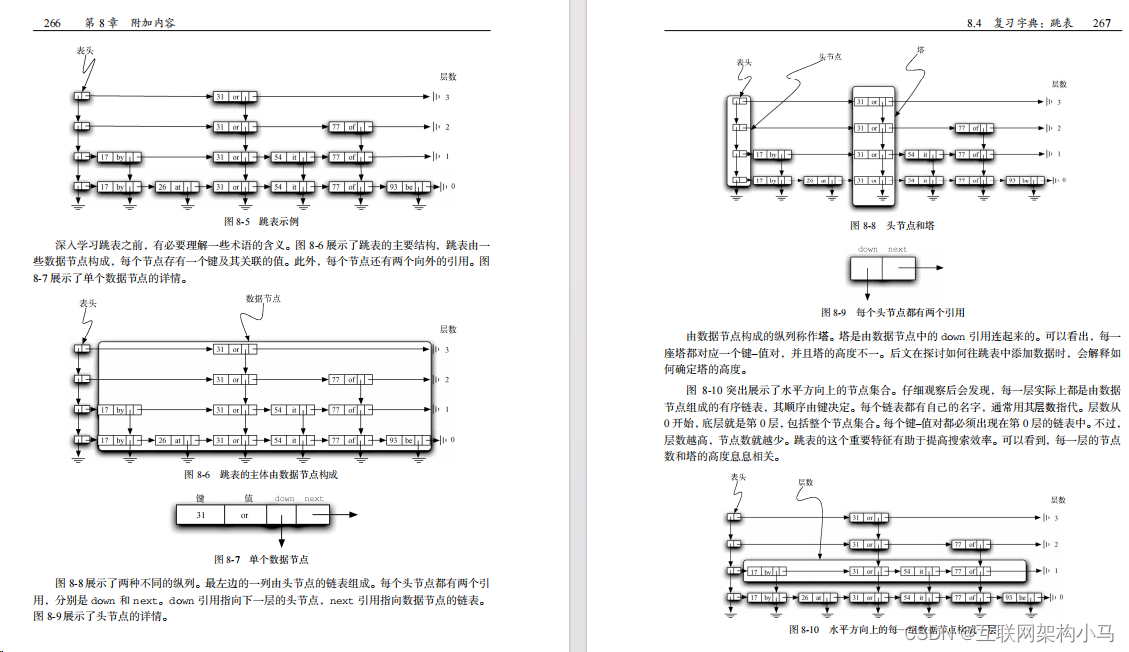
开山之作!Python数据与算法分析手册,登顶GitHub!
若把编写代码比作行军打仗,那么要想称霸沙场,不能仅靠手中的利刃,还需深谙兵法。 Python是一把利刃,数据结构与算法则是兵法。只有熟读兵法,才能使利刃所向披靡。只有洞彻数据结构与算法,才能真正精通Pyth…...

编译安装gcc-11及可能遇到的bug
编译安装脚本 GCC_VERSION11.1.0 PACKAGE_DIR/path/to/gcc/source/code GCC_DIR$PACKAGE_DIR/gcc-$GCC_VERSION GCC_INSTALL_DIR/path/to/install/gccmkdir -p $GCC_INSTALL_DIR cd $GCC_INSTALL_DIR rm -rf * cd $PACKAGE_DIR rm -rf gcc-$GCC_VERSION if [ ! -f "gcc-$…...

vue项目引入json/js文件批量或单个方法
vue项目 json // 方式一 : 将文件内容完整的引入 import json from ./src/assets/xxx.json console.log(json) console.log(---)// 方式二 : 部分引入-名称必须是文件中定义的key import {name1,name2} from ./src/assets/xxx.json console.log(name1)…...
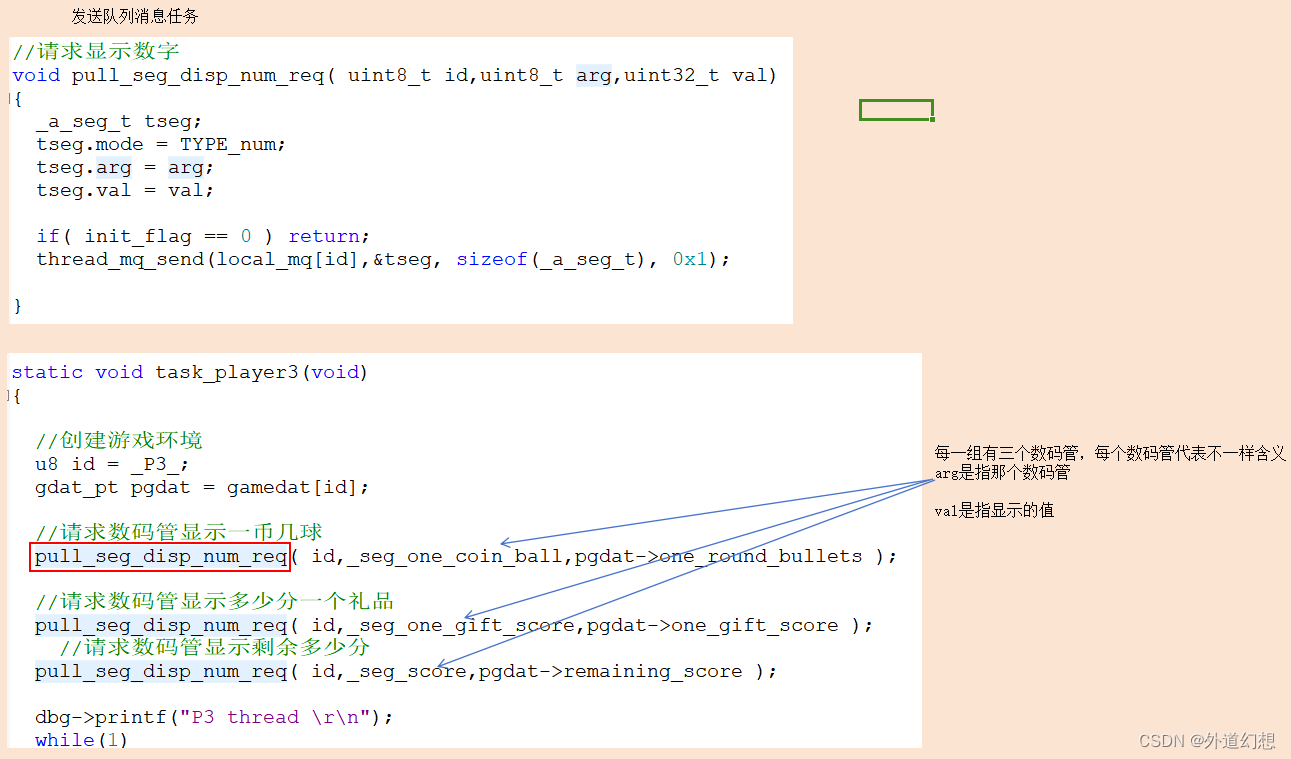
守护任务用来防止资源冲突
背景:有三个任务,他们都需要操作数码管。每个任务对应三个数码管,共9个数码管。硬件上9个数码管的控制使用一套硬件完成。 策略:每个任务都往自己的队列里面发数据,单独建立一个监听任务:处理所有队列的数…...

fast admin实现多数据库导入数据
思路 1创建多数据库连接 2后端的前台代码能使用get或者post请求传递选中数据给后台 3后台能够接收到 4后台接收到id或者全字段数据后对数据进行处理,然后使用多数据库操作将其存入第二个数据库 实现 1config文件下创建新数据库连接 db_config2 > [// 数据库类…...

NLP基础——序列模型(动手学深度学习)
序列模型 定义 序列模型是自然语言处理(NLP)和机器学习领域中一类重要的模型,它们特别适合处理具有时间顺序或序列结构的数据,例如文本、语音信号或时间序列数据。 举个例子:一部电影的评分在不同时间段的评分可能是…...

机器学习AI大模型的开源与闭源:哪个更好?
文章目录 前言一、开源AI模型1.1 开源的优点1.2 开源的缺点 二、闭源AI模型2.1 闭源的优点2.2 闭源的缺点 三、开源与闭源的平衡3.1 开源与闭源结合的案例3.2 开源与闭源的战略选择 小结 前言 在过去的几年里,人工智能(AI)和机器学习…...

关于大模型多轮问答的两种方式
前言 大模型的多轮问答难点就是在于如何精确识别用户最新的提问的真实意图,而在常见的使用大模型进行多轮对话方式中,我接触到的只有两种方式: 一种是简单地直接使用 user 和 assistant 两个角色将一问一答的会话内容喂给大模型,…...

老Mac焕新实战:OpenCore Legacy Patcher全解析——让旧硬件重获新生
老Mac焕新实战:OpenCore Legacy Patcher全解析——让旧硬件重获新生 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 当你的Mac弹出"此Mac不支…...

终极多店铺管理指南:如何在Fecshop中轻松运营多个独立商城
终极多店铺管理指南:如何在Fecshop中轻松运营多个独立商城 【免费下载链接】yii2_fecshop Yii2_fecshop是一个基于Yii2框架的电商系统,适合用于搭建在线商城、B2C网站等。特点:功能丰富、易于扩展、支持多种支付方式。 项目地址: https://g…...

WebDataset商业应用:企业级深度学习项目的数据管理策略
WebDataset商业应用:企业级深度学习项目的数据管理策略 【免费下载链接】webdataset A high-performance Python-based I/O system for large (and small) deep learning problems, with strong support for PyTorch. 项目地址: https://gitcode.com/gh_mirrors/w…...

Nano-Banana企业级部署:支持API接入PLM系统,打通产品数据链路
Nano-Banana企业级部署:支持API接入PLM系统,打通产品数据链路 1. 引言:企业级部署的价值与意义 在现代制造业和设计行业中,产品数据管理一直是个令人头疼的问题。设计师创作的产品分解图、技术团队制作的结构示意图、营销部门需…...

3个步骤掌握macOS自动点击器:彻底告别重复鼠标操作的完整方案
3个步骤掌握macOS自动点击器:彻底告别重复鼠标操作的完整方案 【免费下载链接】macos-auto-clicker A simple auto clicker for macOS Big Sur, Monterey, Ventura, Sonoma and Sequoia. 项目地址: https://gitcode.com/gh_mirrors/ma/macos-auto-clicker 你…...

XXMI启动器:二次元游戏模组统一管理平台完整指南
XXMI启动器:二次元游戏模组统一管理平台完整指南 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 还在为多款二次元游戏模组管理而烦恼吗?XXMI启动器为你提…...
)
GEE实战:手把手教你用Sentinel-2数据计算植被覆盖度(附完整代码与避坑指南)
GEE实战:从零到一掌握Sentinel-2植被覆盖度计算全流程 清晨的阳光透过实验室的窗户洒在桌面上,一位生态学研究生正盯着电脑屏幕发愁——导师要求她在一周内完成研究区域的植被覆盖度分析,但GEE平台上那些晦涩的代码和突如其来的报错信息让她手…...

Qwen-Turbo-BF16企业级部署方案:高可用架构设计
Qwen-Turbo-BF16企业级部署方案:高可用架构设计 1. 引言 想象一下这样的场景:你的电商平台正在经历促销活动,每秒涌入成千上万的图片生成请求。突然,某个GPU节点出现故障,整个服务开始变得不稳定,用户等待…...

STM32+OneNET 智能家居项目踩坑全记录:数据不显示、更新慢、步长校验全解析
一、OneNET 数据更新极慢,2 分钟才刷新一次 问题现象 代码里设置的是timeCount>200(约 5 秒)发送一次数据,结果 OneNET 平台要 2 分钟才更新一次,完全不实时。 根因分析 主循环耗时严重!原本以为 5 …...

5步搞定CYBER-VISION零号协议:Anaconda环境搭建与依赖安装
5步搞定CYBER-VISION零号协议:Anaconda环境搭建与依赖安装 1. 为什么选择Anaconda管理AI项目环境 在开始安装CYBER-VISION零号协议前,我们需要先解决一个关键问题:如何避免Python环境混乱。想象你正在装修房子,把所有工具和材料…...