详解 Spark SQL 代码开发之数据读取和保存
一、通用操作
/**
基本语法:1.读取:SparkSession.read[.format("format")[.option("...")]].load("path")2.保存:DataFrame.write[.format("format")[.option("...")]][.mode("SaveMode")].save("path")说明:1.默认读取和保存的文件格式为 parquet2."format"包含:"csv"、"jdbc"、"json"、"orc"、"parquet" 和 "textFile"3.option("…") 是在 "jdbc" 格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable4."SaveMode" 指定保存模式,SaveMode 是一个枚举类,其中的常量包括:4.1 "error":默认值,如果文件已经存在则抛出异常4.2 "append":如果文件已经存在则追加4.3 "overwrite":如果文件已经存在则覆盖4.4 "ignore":如果文件已经存在则忽略
*/
object TestSparkSqlRead {def main(args: Array[String]): Unit = {// 创建 sparksql 环境对象val conf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")val spark = SparkSession.builder().config(conf).getOrCreate()// 引入环境对象中的隐式转换import spark.implicits._// val df = spark.read.load("data/user.json") // errorval df = spark.read.format("json").load("data/user.json")df.show()// 直接查询文件:文件格式.`文件路径`spark.sql("select * from json.`data/user.json`").show()// df.write.save("output") // 默认保存为 parquet 格式df.write.format("json").save("output")// df.write.format("json").mode("overwrite").save("output") // 覆盖保存// 关闭环境spark.close()}}
二、parquet
/**SparkSQL默认的读取保存数据源为 Parquet 格式Parquet 是一种能够有效存储嵌套数据的列式存储格式基本语法:1.读取:1.1 SparkSession.read.load("path") 1.2 SparkSession.read.parquet("path")2.保存:2.1 DataFrame.write[.mode("SaveMode")].save("path") 2.2 DataFrame.write[.mode("SaveMode")].parquet("path")
*/
object TestSparkSqlRead {def main(args: Array[String]): Unit = {// 创建 sparksql 环境对象val conf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")val spark = SparkSession.builder().config(conf).getOrCreate()// 引入环境对象中的隐式转换import spark.implicits._val df = spark.read.load("data/user.parquet")val df1 = spark.read.parquet("data/user.parquet")df.show()df.write.save("output") df1.write.parquet("output1") // 关闭环境spark.close()}}
三、json
/**基本语法:1.读取:SparkSession.read.json("path") 2.保存:DataFrame.write[.mode("SaveMode")].json("path") 注意:Spark 读取的 JSON 文件不是传统的 JSON 文件,每一行都应该是一个 JSON 串
*/
object TestSparkSqlRead {def main(args: Array[String]): Unit = {// 创建 sparksql 环境对象val conf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")val spark = SparkSession.builder().config(conf).getOrCreate()// 引入环境对象中的隐式转换import spark.implicits._val df = spark.read.json("data/user.json")df.show()df.write.json("output") // 关闭环境spark.close()}}
四、csv
/**基本语法:1.读取:1.1 SparkSession.read.format("csv")[.option(...)].load("path") 1.2 SparkSession.read.csv("path") 2.保存:2.1 DataFrame.write.format("csv")[.mode("SaveMode")].save("path") 2.2 DataFrame.write[.mode("SaveMode")].csv("path") 说明:csv 是默认以逗号为分隔符的文件格式
*/
object TestSparkSqlRead {def main(args: Array[String]): Unit = {// 创建 sparksql 环境对象val conf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")val spark = SparkSession.builder().config(conf).getOrCreate()// 引入环境对象中的隐式转换import spark.implicits._val df = spark.read.format("csv") // 指定读取文件格式.option("sep", ";") // 指定分隔符.option("inferSchema", "true") .option("header", "true") // 指定第一行是否为表头.load("data/user.csv")df.show()df.write.format("csv").save("output") // 关闭环境spark.close()}}
五、mysql
-
导入 mysql 依赖
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.27</version> </dependency> -
读取和保存数据
/** 基本语法:1.读取:1.1 SparkSession.read.format("jdbc").option("url", "..")…….load() 1.2 SparkSession.read.jdbc("url", "table", prop: Properties)2.保存:2.1 DataFrame.write.format("jdbc").option("url", "..")……[.mode("SaveMode")].save()2.2 DataFrame.write[.mode("SaveMode")].jdbc("url", "table", prop: Properties)*/ object TestSparkSqlRead {def main(args: Array[String]): Unit = {// 创建 sparksql 环境对象val conf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")val spark = SparkSession.builder().config(conf).getOrCreate()// 引入环境对象中的隐式转换import spark.implicits._// 1. 读取// 1.1 方式一:val df = spark.read.format("jdbc") // 指定读取文件格式.option("url", "jdbc:mysql://linux:3306/spark") // 连接url.option("driver", "com.mysql.jdbc.Driver") // 驱动.option("user", "root") // 用户名.option("password", "123123") // 密码.option("dbtable", "user") // 表名.load()// 1.2 方式二:val df1 = spark.read.format("jdbc").options(Map("url" -> "jdbc:mysql://linux:3306/spark?user=root&password=123123","dbtable" -> "user","driver" -> "com.mysql.jdbc.Driver")).load()// 1.3 方式三:val props: Properties = new Properties()props.setProperty("user", "root")props.setProperty("password", "123123")val df2 = spark.read.jdbc("jdbc:mysql://linux:3306/spark", "user", props)df.show()// 2. 保存// 2.1 方式一df.write.format("jdbc") // 指定读取文件格式.option("url", "jdbc:mysql://linux:3306/spark") // 连接url.option("driver", "com.mysql.jdbc.Driver") // 驱动.option("user", "root") // 用户名.option("password", "123123") // 密码.option("dbtable", "user1") // 表名.mode(SaveMode.Append).save() // 2.2 方式二df2.write.mode("append").jdbc("jdbc:mysql://linux:3306/spark", "user2", props)// 关闭环境spark.close()}}
六、hive
1. 内置 hive
Spark 在安装编译后内部已经可以支持 Hive 表访问、 UDF (用户自定义函数) 以及 Hive 查询语言(HiveQL/HQL) 等
// 内置 Hive 的元数据存储在 derby 中,默认仓库地址为 $SPARK_HOME/spark-warehouse
// 进入 spark-shell// 1. 创建 hive 表
spark.sql("create table user(username string, age bigint)")// 2. 加载数据到表中
spark.sql("load data local inpath 'data/user.txt' into table user")// 3. 展示所有表
spark.sql("show tables").show// 4. 查询表数据
spark.sql("select * from user").show2. 外部 hive
-
配置连接外部 Hive
-
将外部 Hive 的安装目录下的
hive-site.xml配置文件拷贝到 Spark 安装目录的conf目录下 -
将 Mysql 连接的驱动 jar 包拷贝到 Spark 安装目录的
jars目录下(外部 Hive 的元数据库使用 MySQL) -
如果访问不到 hdfs,则需要把
core-site.xml和hdfs-site.xml两个配置文件拷贝到 Spark 安装目录的conf目录下 -
启动 spark-shell,执行
spark.sql("show tables").show检查是否可以连接外部 Hive
-
-
程序代码操作外部 Hive
-
引入依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.0.0</version> </dependency> <dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>1.2.1</version> </dependency> <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.27</version> </dependency> -
将
hive-site.xml文件拷贝到项目的 resources 目录中,同时确保 target/classes 目录下也有该文件 -
编码
object TestSparkSqlRead {def main(args: Array[String]): Unit = {// 若出现用户无权限的错误,可在首行添加// System.setProperty("HADOOP_USER_NAME", "root")// 创建 sparksql 环境对象,并开启 Hive 支持val conf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")// 配置修改数据库仓库的地址// conf.set("spark.sql.warehouse.dir", "hdfs://linux:8020/user/hive/warehouse")val spark = SparkSession.builder().enableHiveSupport() // 启用 hive 支持.config(conf).getOrCreate()// 使用 sparksql 操作 hivespark.sql("show tables").show()// 关闭环境spark.close()}}
-
-
其他连接方式
-
spark-sql cli
#进入 spark-sql CLI bin/spark-sql#编写HQL show tables; -
spark beeline
#启动 Thrift Server sbin/start-thriftserver.sh#使用 beeline 连接 Thrift Server bin/beeline -u jdbc:hive2://linux:10000 -n root#编写HQL show tables;
-
相关文章:

详解 Spark SQL 代码开发之数据读取和保存
一、通用操作 /** 基本语法:1.读取:SparkSession.read[.format("format")[.option("...")]].load("path")2.保存:DataFrame.write[.format("format")[.option("...")]][.mode("Save…...
Pulsar 社区周报 | No.2024-05-30 | BIGO 百页小册《Apache Pulsar 调优指南》
“ 各位热爱 Pulsar 的小伙伴们,Pulsar 社区周报更新啦!这里将记录 Pulsar 社区每周的重要更新,每周发布。 ” BIGO 百页小册《Apache Pulsar 调优指南》 Hi,Apache Pulsar 社区的小伙伴们,社区 2024 上半年度的有奖问…...

第二证券股票杠杆:4分钟直线涨停!这一赛道,AH股集体爆发!
今日早盘,A股继续小幅震动收拾,首要股指涨跌互现,两市个股跌多涨少,成交有萎缩的趋势。 盘面上,医药、中字头、旅游、房地产等板块相对活跃,混合实践、玻璃基板、AI手机PC、光刻机等板块跌幅居前。 “中字…...

JavaScript 进阶征途:解锁Function奥秘,深掘Object方法精髓
个人主页:学习前端的小z 个人专栏:JavaScript 精粹 本专栏旨在分享记录每日学习的前端知识和学习笔记的归纳总结,欢迎大家在评论区交流讨论! 文章目录 🈵Function方法 与 函数式编程💝1 call 💝…...

斜拉桥智慧施工数字孪生
基于图扑自主研发的 HT for Web 产品,利用现场照片及 CAD 图纸,结合 PBR 材质,搭建了具有赛博朋克风格的智慧斜拉桥可视化解决方案,精准复现斜拉桥建造规划过程,辅助运维人员对桥梁基建过程的网格化管理。提高桥梁的建…...

【chatGPT API】Function Calling:将自然语言转换为API调用或数据库查询
文章目录 一. 介绍二. 常见用例与Function Calling调用逻辑三. 调用细节1. 调用行为:tool_choice2. 调用规定:functions 四. 实战:查询公司相关产品 一. 介绍 OpenAI可以根据用户的要求输出一个符合用户要求的入参值。然后用户拿到入参值之后…...
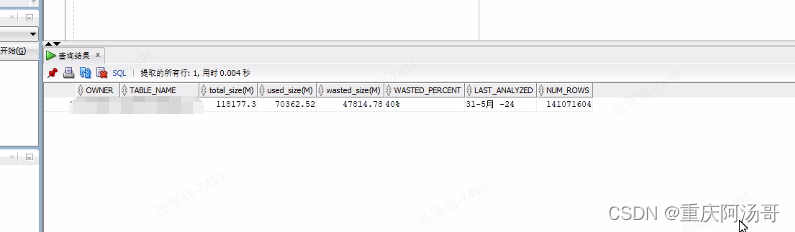
Oracle Hint /*+APPEND*/插入性能总结
oracle append用法 Oracle中的APPEND用法主要用于提高数据插入的效率。 基本用法:在使用了APPEND选项后,插入数据会直接加到表的最后面,而不会在表的空闲块中插入数据。这种做法不需要寻找freelist中的free block,从而避免了在…...

正邦科技(day3)
出厂测试 设备校准 这个需要注意的是校准电流、电压、电感的时候有时候负感器会装反,mcu会坏,需要flash一下清空内存...
mac电脑多协议远程管理软件:Termius 8.4.0激活版下载
Termius 是一款功能强大的跨平台远程访问工具,可用于管理和连接各种远程系统和服务器。它支持SSH、Telnet、SFTP和Serial协议,并提供了键盘快捷键、自动完成和多标签功能,使用户可以方便地控制和操作远程主机。 Termius 提供了端到端的加密保…...

网络攻击的常见形式
开篇 本篇文章来自于《网络安全 ——技术与实践》的学习整理笔记。 正篇 口令窃取 相比于利用系统缺陷破坏网络系统,最容易的方法还是通过窃取用户的口令进入系统。因为人们倾向于选择很糟糕的口令作为登录密码,所以口令猜测很容易成功。通常࿰…...

ReactDOM 18版本 使用createRoot 替换render详解
概述 React 18 提供了两个 root API,被称之为 Legacy Root API 和 New Root API: Legacy Root API:是指之前版本的 root API ReactDOM.render,它将创建一个以 “legacy” 模式运行的 root,其工作方式与 React 17 完全…...

【赠书活动】好书推荐—《详解51种企业应用架构模式》
导读: 企业应用包括哪些?它们又分别有哪些架构模式?世界著名软件开发大师Martin Fowler给你答案。 01 什么是企业应用 我的职业生涯专注于企业应用,因此,这里所谈及的模式也都是关于企业应用的。(企业应用…...

SpringBoot启动时使用外置yml文件
第一步:打包时排除yml文件 <build><resources><resource><!-- 排除的文件的路径 --><directory>src/main/resources</directory><excludes><!-- 排除的文件的名称 --><exclude>application-dev.yml</e…...

【开源三方库】Fuse.js:强大、轻巧、零依赖的模糊搜索库
1.简介 Fuse.js是一款功能强大且轻量级的JavaScript模糊搜索库,支持OpenAtom OpenHarmony(以下简称“OpenHarmony”)操作系统,它具备模糊搜索和排序等功能。该库高性能、易于使用、高度可配置,支持多种数据类型和多语…...
:数据代理)
vue从入门到精通(六):数据代理
一,什么是数据代理 通过一个对象代理对另一个对象中属性的操作 二,object.defineproperty方法 object.defineproperty方法可以对对象追加属性 <!DOCTYPE html> <html><head><meta charset"utf-8"><title>object…...

【C++修行之道】类和对象(二)类的6个默认成员函数、构造函数、析构函数
目录 一、类的6个默认成员函数 二、构造函数 2.1 概念 2.2 特性 2.2.5 自动生成默认构造函数 不进行显示定义的隐患: 2.2.6 自动生成的构造函数意义何在? 两个栈实现一个队列 2.2.7 无参的构造函数和全缺省的构造函数都称为默认构造函数&#x…...
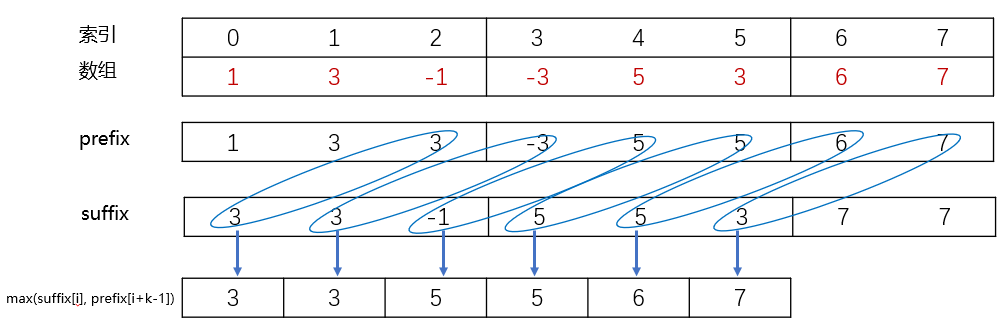
【LeetCode热题100总结】239. 滑动窗口最大值
题目描述 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums [1,3,-1,-3,5,3,6,7]…...

【YOLOv9改进[Conv]】使用YOLOv10的空间通道解耦下采样SCDown模块替换部分CONv的实践 + 含全部代码和详细修改内容
本文将使用YOLOv10的空间通道解耦下采样SCDown模块替换部分CONv的实践 ,文中含全部代码和详细修改内容。 目录 一 YOLOv10 1 空间通道解耦下采样 2 可视化...

简单小游戏制作
控制台基础设置 //隐藏光标 Console.CursorVisible false; //通过两个变量来存储舞台的大小 int w 50; int h 30; //设置舞台(控制台)的大小 Console.SetWindowSize(w, h); Console.SetBufferSize(w, h);多个场景 int nowSceneID 1; while (true) …...

Delphi
Delphi,是美国 Borland(宝兰)公司於 1995 年开发在 Windows 平台下的快速应用程式开发工具 (Rapid Application Development,简称 RAD),它的前身是在 DOS 下的产品 Borland Turbo Pascal。(非开源软件&…...
)
【OpenClaw企业级智能体实战】第23篇:个人知识库+自动化工作流——让OpenClaw成为你的第二大脑(附second-brain+Obsidian+飞书三合一完整方案)
摘要:长期深耕技术领域的从业者,普遍深陷信息过载困境:海量技术文档、论文、行业动态分散在书签、收藏夹、零散笔记中,传统工具仅能完成信息存储,无法实现语义关联、智能检索与自动迭代。本文基于OpenClaw原生second-brain插件,深度打通Obsidian本地知识图谱与飞书团队协…...

科技服务机构如何提升服务专业性与客户对接效率?
观点作者:科易网-国家科技成果转化(厦门)示范基地 在数智时代浪潮下,科技服务机构面临着前所未有的机遇与挑战。数据成为关键资源,重塑了创新主体间的关系,科技成果向产业应用的转化链条发生了根本变革。然…...

Pandas 数据分析:统计每个人吃的蔬菜数量
在数据分析中,Pandas 是一个非常强大且灵活的工具,特别是当我们处理数据表格时。今天,我们将通过一个实际例子来展示如何使用 Pandas 统计每个人的蔬菜消费量。这个例子不仅展示了 Pandas 的基本操作,还深入到数据筛选和聚合的细节。 场景描述 假设我们有这样一个 CSV 文…...

免死金牌: OpenClaw + keepalived
文章目录背景解决方案查看IP检测脚本keepalived 配置演练故障openclaw-gateway.service背景 问题来自 小龙虾自杀, 当我让 OpenClaw 更新一些配置时, 它执行了一条 openclaw gateway stop 命令, 导致 OpenClaw 服务停止, 然后我就干瞪眼了, 还在傻等, 它甚至一句分别的话都没有…...

不只是“生成一张图“:2026年6款真正改变设计工作流的AI界面工具深度测评
AI界面生成工具正在经历从"生成单张界面"到"生成完整产品体验"的代际跃迁。本文深度拆解 UXbot、Figma Make、Google Stitch、Flowstep、Visily AI 和 Moonchild 共6款2026年代表性工具——从设计稿生成到原生代码输出,覆盖完整的产品交付能力谱…...

终极指南:使用android-advancedrecyclerview实现状态保存的拖拽列表
终极指南:使用android-advancedrecyclerview实现状态保存的拖拽列表 【免费下载链接】android-advancedrecyclerview RecyclerView extension library which provides advanced features. (ex. Googles Inbox app like swiping, Play Music app like drag and drop …...

建议收藏!我开发了一个免费无限制的AI绘画公益站!
大家好,最近我做了一个小网站,叫 Dreamify ,一个可以让你随便玩AI画画的小工具。不收费、不限次数、不用登录,想画就画,全凭兴趣。 今天就想简单分享一下它,顺便邀请你也来玩玩看。 🎨 为什么…...

终极指南:Linkerd与Rancher集成的完整实践方案
终极指南:Linkerd与Rancher集成的完整实践方案 【免费下载链接】linkerd Old repo for Linkerd 1.x. See the linkerd2 repo for Linkerd 2.x. 项目地址: https://gitcode.com/gh_mirrors/li/linkerd Linkerd作为一款强大的服务网格工具,与Ranche…...

PDFKit核心源码分析:揭秘HTML到PDF的转换魔法
PDFKit核心源码分析:揭秘HTML到PDF的转换魔法 【免费下载链接】pdfkit A Ruby gem to transform HTML CSS into PDFs using the command-line utility wkhtmltopdf 项目地址: https://gitcode.com/gh_mirrors/pdfk/pdfkit PDFKit是一款强大的Ruby gem&#…...

短视频 SEO 关键词优化有哪些注意事项
短视频 SEO 关键词优化有哪些注意事项 在当今数字化时代,短视频平台已经成为了信息传播和内容分享的重要渠道。无论你是个人创作者还是品牌运营者,短视频的流量和曝光度都是关键。在这个竞争激烈的环境中,如何有效地进行短视频 SEO 关键词优…...