操作系统总结
进程和线程的区别
- 本质区别:
- 进程是资源调度以及分配的基本单位。
- 线程是
CPU调度的基本单位。
- 所属关系:一个线程属于一个进程,一个进程可以拥有多个线程。
- 地址空间:
- 进程有独立的虚拟地址空间。
- 线程没有独立的虚拟地址空间:线程有调用栈、程序计数器(
PC)、本地存储(LS)等少量独立空间。
- 内存:
- 系统会为每个进程分配不同的内存空间。
- 系统不会为线程分配内存,线程所使用的资源来自其所属的进程。
- 并发性:
- 进程的并发性较低。
- 线程的并发性较高。
- 对于单个
CPU,操作系统会把CPU的运行时间划分为多个时间段,再将时间段分配给各个线程执行。 - 切换效率:
- 进程切换效率低(因为所属的资源多),线程切换效率高。
- 都会涉及到上下文切换。
- 健壮性:
- 一个进程崩溃后,不会影响其他进程,进程的健壮性高。
- 一个线程崩溃后,导致整个进程崩溃,线程的健壮性低。
- 进程隔离性强一些。
进程与线程的上下文切换过程
- 进程由哪几个部分构成:
task_struct。- 进程的虚拟地址空间。
- 上下文由哪几个部分构成:
- 用户级上下文 → 虚拟地址空间:
- 代码。
- 数据。
- 堆栈等。
- 系统级上下文 →
task_struct:- 进程标识信息。
- 进程现场信息。
- 进程控制信息。
- 系统内核栈。
- 寄存器上下文(硬件上下文)。
CPU各寄存器的内容。- 进程的现场信息,存储在系统内核栈(中断栈)。
- 用户级上下文 → 虚拟地址空间:
- 何时发生切换:
- 主动:系统调用,产生软中断。
- 被动:时间片到了,时间中断。
- 由中断来完成切换。
- 进程切换过程:
- 保存当前进程的硬件上下文。
- 修改当前进程的状态(存储在 PCB 中),状态由运行态改为就绪态或阻塞态,加入相关队列(就绪队列或阻塞队列)。
- 调度另外一个进程。
- 修改被调度进程的状态,将其状态改为运行态。
- 把当前进程的存储管理数据改为被调度进程的存储管理信息(页表、
cacheTLB) → 用户级上下文切换。 - 恢复被调度进程的硬件上下文,让
PC指向被调度的进程代码。
进程调度策略有哪几种
- 调度对象:
- 线程和进程相对于操作系统而言都是任务(
task_struct)。 - 线程也被称之为共享用户虚拟地址空间的进程。
- 包含多个线程的进程被称之为线程组。
- 只有一个线程的进程被称之为进程。
- 没有用户虚拟地址空间的进程被称之为内核线程(内核中的所有线程共享内核虚拟地址空间)。
- 线程和进程相对于操作系统而言都是任务(
- 进程调度用于决定由谁(哪个或哪几个)获得处理器的执行权。
- 进程的状态:
- 从新建到就绪:当进程创建完毕,初始化所有必要资源后,它被放入就绪队列。
- 从就绪到运行:调度程序从就绪队列中选择一个进程并分配
CPU时间片。 - 从运行到就绪:当进程的时间片用完但进程尚未完成时,它会被放回就绪队列。
- 从运行到阻塞:如果进程请求了当前不可用的资源或等待操作完成,它将转入阻塞状态。
- 从阻塞到就绪:当进程等待的事件发生或资源变得可用时,它将被移回就绪队列。
- 从运行到退出:进程完成所有操作并自行退出或由于某种原因被操作系统终止。

- 调度时机:
- 主动调度:系统调用等待某个资源。
- 周期调度:某些进程不主动让出
CPU,内核依靠周期性时钟来抢占调度。 - 唤醒抢占、创建新进程抢占、内核线程抢占。
- 进程调度算法:
- 先来先服务(
FCFS):- 也称为先进先出。
- 从就绪队列中选择存在时间最长的任务执行调度。
- 短作业优先(
SJF):- 从就绪队列中选择估计运行时间最短的任务执行调度。
- 高响应比优先:
FCFS和SJF的综合。- 综合考虑等待时间和估计运行时间来选择任务执行调度。
- 时间片轮转调度:
- 为任务分配时间片,当执行完时间片后放入就绪队列。
- 优先级调度:
- 从就绪队列中选择优先级最高的若干任务执行调度。
- 优先级用来描述运行的紧迫程度。
- 多级反馈队列调度:
- 时间片轮转调度和优先级调度的综合。
- 动态调整任务的优先级和时间片大小,从而兼顾多方面的系统目标。
linux(会根据时间片的剩余时间动态调整优先级,更加公平) 和windows(严格按照优先级取出任务分配时间片) 采用。
- 先来先服务(
后台进程有什么特点
- 前台进程:
- 运行在前台的进程。
- 终端是该进程的控制终端。
- 如果终端关闭,则向依赖该终端的所有进程发送一个
SIGHUP信号,然后进程退出。 - 可接收终端输入,并可在终端输出。
- 后台进程:
- 运行在后台的进程,若在终端运行,终端关闭,进程可能退出。
- 不可接收终端输入,可在终端输出。
- 前后台程序切换:
Ctrl + Z:将前台程序切换为后台程序,但是后台程序是挂起状态。jobs:显示所有的后台程序。fg %编号:将后台程序切换为前台程序。bg %编号:让后台程序处于运行状态。& = (Ctrl + Z) + bg %编号。nohup:忽略SIGHUP信号。Ctrl + D:断开终端session,依赖该终端的所有进程都会收到SIGHUP信号。
- 守护进程:
- 后台进程的延伸,脱离终端的后台进程,不需要考虑
SIGHUP信号。 - 如何成为守护进程:
fork子进程,并让父进程退出,从而让子进程被init进程接管,成为孤儿进程。- 使用
setsid()系统调用建立新的进程会话,让孤儿进程成为新建会话的首进程,从而脱离与终端的关联。 - 打开
/dev/null,把0,1,2重新定向到/dev/null,从而防止守护进程意外地从终端接收输入或向终端发送输出。
void daemonize(void) {int fd;if (fork() != 0) exit(0); // 父进程退出setsid(); if ((fd = open("/dev/null", O_RDWR, 0)) != -1) {dup2(fd, STDIN_FILENO);dup2(fd, STDOUT_FILENO);dup2(fd, STDERR_FILENO);if (fd > STDERR_FILENO) close(fd);} }
- 后台进程的延伸,脱离终端的后台进程,不需要考虑
用户态和内核态
- 用户态:用户程序运行时的状态。
- 内核态:操作系统运行时的状态。
- 为什么要区分用户态和内核态 ?
- 内核态具备特权,能够操作外部资源。
- 为了系统的安全与稳定。
- 如何实现用户态和内核态 ?
CPU:- 特权寄存器 → 操作系统使用。
- 普通寄存器 → 用户程序使用。
- 内存:
- 内核空间 → 操作系统使用。
- 用户空间 → 用户程序使用。
- 什么时候需要切换 ?
- 用户态程序在需要操作系统完成特权操作的时候才发生切换。
- 什么条件引起用户态与内核态之间的切换 ?
- 系统调用。
- 异常,比如缺页异常。
- 中断。
- 用户态和内核态的区别:
- 运行实体不同。
- 是否具备特权。
- 是否安全和稳定。
- 实现机制。
描述系统调用整个流程
- 系统调用是内核给用户程序提供的编程接口。
- 为什么需要系统调用:
- 内核具有最高的权限,可直接访问所有资源。
- 而用户只能访问受限资源,不能直接访问内存、网络、磁盘等硬件资源。
- 中断:使程序从用户态切换到内核态或者从内核态切换到用户态。
- 属性:根据中断号去查询中断向量表,从而找到中断处理程序。
- 中断号。
- 中断向量表。
- 中断处理程序。
- 类别:
- 硬件中断。
- 软件中断:系统调用对应
int 0x80,中断号是0x80。
- 属性:根据中断号去查询中断向量表,从而找到中断处理程序。
- 系统调用是否会引起进程或线程切换 ?
- 不一定。
- 如果是阻塞
IO,且IO未就绪,将引起线程切换;线程将由运行态转为阻塞态。 - 如果是非阻塞
IO,且IO未就绪,不会引起线程切换,仅仅涉及到用户态和内核态之间的切换。
- 系统调用引起中断上下文切换:
- 进程状态先由用户态转为内核态,再由内核态转为用户态。
- 保存运行现场:保存
CPU寄存器原来的用户态指令。 - 运行内核代码:更新
CPU寄存器内容为内核态指令,执行内核代码。 - 恢复运行现场:更新
CPU寄存器内容为用户态指令。
- 系统调用流程:
- 触发中断:
- 将系统调用号放入
eax寄存器。 - 执行
int 0x80。
- 将系统调用号放入
- 切换堆栈:用户态切换为内核态。
- 执行中断处理:
- 根据中断号找到中断处理程序 → 通过
0x80找到system_call。 - 根据系统调用号从系统调用表上找到系统调用处理函数并调用。
- 根据中断号找到中断处理程序 → 通过
- 从中断处理程序返回:通过
iret将返回值返回,并且程序从内核态切换为用户态。
- 触发中断:
CPU 是怎么执行指令的
- 指令是二进制的机器码,由程序编译产生。
- 程序编译运行过程:
- 编译阶段:通过词法句法分析,源代码 → 汇编代码。
- 汇编阶段:汇编代码 → 二进制机器码(
.o目标文件)。 - 链接阶段:目标文件
+库文件 → 可执行程序。 - 载入阶段:
- 将可执行程序加载到内存中。
- 给进程分配虚拟内存地址空间。
- 创建页表。
- 加载代码段和数据段等数据,并在页表中写入映射关系。
- 加载器把入口指令地址写入程序计数器。
- 将可执行程序加载到内存中。
CPU采用流水线的方式执行指令;指令执行过程被称之为指令周期;CPU周而复始地执行指令周期。- 指令执行过程涉及到两个组件:
CPU和内存,CPU和内存之间通过总线进行交互。CPU:- 寄存器:
- 通用寄存器 → 存储计算时所需的数据。
- 程序计数器 → 存储要执行的指令的地址(虚拟内存地址)。
- 指令寄存器 → 存储要执行的指令。
- 控制单元(控制器)。
- 逻辑运算单元(运算器)。
- 寄存器:
- 总线:
- 地址总线 → 操作内存地址。
- 数据总线 → 读写内存数据。
- 控制总线 → 用来发送或者接收信号。
- 指令周期:
- 取得指令:
- 控制单元从程序计数器获取指令地址,通过地址总线通知内存准备数据。
- 如果内存数据准备好了,控制单元通过数据总线获取指令内容,然后写入指令寄存器。
- 指令译码:
CPU将指令解析成不同的操作信息。 - 执行指令:
CPU将指令放入逻辑运算单元进行运算。 - 数据回写:控制单元将操作结果通过数据总线回写到内存中。
- 取得指令:
- 开启下一个指令周期:控制单元将程序计数器中的指令地址
+8(如果是64位操作系统)。
内存管理有哪几种方式
- 背景:
- 为了多进程之间的内存地址访问不受影响并且相互隔离,操作系统会为每个进程独立分配虚拟地址空间。
- 每个进程都有虚拟地址空间,而物理内存只有一个,当启动程序过多时,实际使用的内存超过物理内存,则会发生内存交换。
- 内存交换:把不常用的内存交换到磁盘中(换出),需要的时候再加载回内存(换入)。
- 虚拟地址需要映射到物理地址。
- 怎么管理映射关系。
- 内存管理的方式有三种:分段内存管理、分页内存管理、段页式内存管理。
分段内存管理
- 程序逻辑分段:代码段、数据段、堆段、文件映射段、栈段。
- 虚拟地址:段号、段内偏移量等构成。
- 根据段号从段表找到段内起始地址加上段内偏移量得到真实的物理地址。
- 优点:程序无需关注具体的物理内存地址。
- 缺点:
- 会产生外部内存碎片 → 段与段之间的间隙不足以容纳其他程序。
- 每次内存交换都会把一个程序的全部内存换出,内存交换效率低。
分页内存管理
- 将虚拟内存和物理内存划分为多个连续且固定大小的页,
linux页大小为4KB。 - 虚拟地址通过查找页表获得物理地址。
- 虚拟内存地址转换为物理内存地址的工作是由
CPU中的mmu来处理的。 - 若在页表中找不到物理地址,则会触发缺页异常(缺页中断)。
- 优点:
- 页与页是紧密排列的,不会有外部内存碎片。
- 在内存交换中,只会将若干个页换出,内存交换效率高。
- 装载程序时,无需一次性把程序装载到物理内存中,运行中需要时才会加载到内存。
- 缺点:
- 分配内存的最小单位是一页,可能没用到一页数据,造成内部内存碎片。
- 单级分页(每一个页表大约
4MB) 将耗费更多内存用于存储页表。
段页式内存管理
- 将程序划分为多个逻辑段。
- 将段划分为多个页。
- 虚拟地址:段号、段内页、页内偏移。
- 段页式内存管理得到物理地址需要三次内存访问:
- 访问段表,得到页表起始地址。
- 访问页表,得到物理页号。
- 根据物理页号和页内偏移值得到物理地址。
- 优点:提高了内存利用率。
- 缺点:增加了系统开销。
malloc 是如何分配内存的

- 背景:
- 进程的虚拟内存空间分布(由低地址到高地址划分):
- 代码段:存储二进制可执行代码。
- 已初始化的数据段:静态常量。
- 未初始化的数据段:未初始化的静态变量或全局变量。
- 堆段:动态分配的内存,由低地址往高地址分配。
- 文件映射段:动态库、共享内存等,由高地址往低地址分配。
- 栈段:局部变量、函数调用的上下文等。
- 内核空间。
malloc分配的是物理内存还是虚拟内存 ?- 分配的是虚拟内存。
- 如果分配的内存没有被访问,则不会映射到物理内存 → 不访问就不会占用物理内存。
- 如果分配的内存被访问了,则通过缺页异常建立虚拟内存到物理内存的映射关系。
- 进程的虚拟内存空间分布(由低地址到高地址划分):
malloc分配内存的过程:- 如果分配内存的大小 < < <
128 KB,则通过brk系统调用从堆区分配内存。- 由低地址往高地址分配。
- 优先从内存池中进行分配,可以减少系统调用的次数。
- 页表中的映射关系仍然存在,可以减少缺页异常的次数。
- 缺点:频繁
malloc/free会出现很多的内部内存碎片。
- 如果分配内存的大小 ≥ \geq ≥
128 KB,则通过mmap系统调用从文件映射区分配内存。- 由高地址往低地址分配。
- 每次都会发生系统调用,进行用户态到内核态的切换。
- 第一次访问内存时将发生缺页异常。
- 如果分配内存的大小 < < <
free如何工作:- 释放内存后,是否会把内存归还给操作系统 ?
- 如果是通过
brk系统调用分配内存,该内存仍然在malloc的内存池中,下次可以继续使用。 - 如果是通过
mmap系统调用分配内存,free后会立刻归还给操作系统。
- 如果是通过
free(ptr)传入的是内存地址,如何知道释放多大的内存 ?malloc返回给用户态的内存起始地址比进程的堆空间起始地址多了16个字节。16个字节记录了内存块的描述信息,其中包含了内存块的大小。- 当释放内存时,会对
free传入的内存地址向左偏移16个字节,从而分析出该释放多大的内存。
- 释放内存后,是否会把内存归还给操作系统 ?
页面置换算法有哪些
- 背景:
- 缺页异常:当
CPU访问的页面不在物理内存时,便会产生缺页异常,请求操作系统将缺页调入到物理内存。 - 缺页异常处理流程(页面目前位于磁盘上的交换空间):
- 在
CPU中访问load M指令,接着查找M对应的页表项。 - 若页表项有效,
CPU直接访问物理内存,若无效,则CPU发起缺页异常。 - 操作系统收到缺页异常,执行缺页异常处理函数,先查找页面在磁盘中的位置。
- 找到磁盘中的页面后,把页面换入到物理内存空闲页中。
- 修改页表中对应页表项的状态位为有效。
CPU继续执行访问物理内存。
- 在
- 缺页异常处理流程(页面目前位于尚未初始化的内存区域):
- 进入内核态、分配物理内存、更新进程页表映射关系、返回到用户态,恢复进程的运行。
- 如果没有找到物理内存空闲页,则需要调用页面置换算法,将一个物理页换出到磁盘,并将页表项置为无效。
- 缺页异常:当
- 页面置换算法:
- 当出现缺页异常,且物理内存无空闲页时,选择被置换物理页面的过程。
- 选择物理页换出到磁盘,把需要访问的页换入到物理页。
- 目标:尽可能减少页面的换入换出次数。
最佳页面置换算法
- 置换在未来最长时间不访问的页面。
- 每个页需要记录访问时间。
- 实际系统不会实现,代价太大。
先进先出置换算法
- 选择在内存驻留时间最长的页面进行置换。
- 实际系统不会使用,可能没法实现目标。
最近最久未使用置换算法
- 选择最长时间没有被访问的页面进行置换。
- 代价很高,需要在内存中维护更新所有页面的链表,开销较大。
最不常用置换算法
- 选择访问次数最少的页面作为置换页。
- 每个页面都需要记录访问次数。
- 实际不会使用。
时钟页面置换算法
- 对
LRU的一种改进。 - 把所有页面保存在环形链表中,并用一个指针指向最久未使用的页面,检查具体页的访问位。
1:访问过。0:未访问。- 移动过程中若访问位为
1,则清除访问位(置为0);遇到0,选择为置换页。 - 优化:加一个修改位,由访问位和修改位构成元组:
u = 0, m = 0→ 未访问且未修改。u = 1, m = 0→ 访问过但未修改。u = 0, m = 1→ 未访问但修改过。u = 1, m = 1→ 既访问又修改过。
写文件时进程宕机,数据会丢失吗

- 写文件流程:
- 通过
stdio函数库选择具体的函数,把数据先写到stdio缓冲区中 → 减少系统调用的次数。- 也可以使用
setbuf自定义用户缓冲区。
- 也可以使用
- 通过
IO系统调用write等,写到内核缓冲区page cache中 → 减少磁盘 IO 的次数。 - 由内核发起的写操作(我们无法控制)。
- 用户层可以调用
fsync、fdatasync、sync将内核缓冲区中的数据刷到磁盘。
- 用户层可以调用
- 通过
page cache:- 优点:加快对数据的访问、减少磁盘
IO的次数。 - 缺点:
- 占用了物理内存空间,可能会引发频繁的
swap操作。 - 用户层无法优化
page cache的使用策略,通常数据库需要自己实现page管理。
- 占用了物理内存空间,可能会引发频繁的
- 优点:加快对数据的访问、减少磁盘
- 两种磁盘
IO方式:- 缓存文件
IO(小文件使用):- 不直接与磁盘交互,而是通过
page cache进行缓存。
- 不直接与磁盘交互,而是通过
- 直接文件
IO(大文件使用):- 不通过
page cache,直接与磁盘交互。
- 不通过
- 缓存文件
- 如果写文件没有调用
fflush/write,则数据丢失,因为数据还在用户态缓冲区。 - 如果写文件调用了
fflush/write,则数据在内核缓冲区,只要系统不关闭,那么数据就不会丢失。 - 假设进程宕机后,系统马上也关闭了:
- 如果系统关闭前调用了
fsync、fdatasync、sync,则数据不会丢失。 - 否则数据可能丢失,主要看系统是否调用了下面的三个接口。
- 如果系统关闭前调用了

磁盘调度算法有哪些
- 背景:
- 目的:为了提高磁盘的访问性能。
- 磁盘访问:
- 旋转时间:
4ms。 - 寻道时间:
10ms。 - 数据传输时间:
0.3ms。
- 旋转时间:
- 磁盘调度的主要目标:使磁盘的平均寻道时间最短。
先来先服务
- 按照磁盘访问的请求顺序进行调度。
- 优点:是公平的调度方式。
- 缺点:未做任何优化,平均寻道时间较长。
最短寻道时间优先
- 优先调度与当前磁道距离最近的磁道。
- 优点:平均寻道时间较短。
- 缺点:离密集访问磁道较远的请求将出现饥饿现象。
电梯扫描算法
- 先按一个方向来进行磁盘调度,直到处理完该方向的所有请求后才改变调度方向。
- 优点:解决了最短寻道时间优先的饥饿问题。
- 缺点:中间调度频率高,两边调度频率低。
循环扫描算法
- 朝特定方向进行磁盘调度,返回时直接复位磁头,仍朝原来的方向进行调度。
- 磁道只响应一个方向上的请求。
- 相较于电梯扫描算法,各个位置磁道响应频率相对平均。
进程间通信有哪几种方式
管道
- 父子进程间通信。
- 半双工。
- 速度慢、容量有限。
#include <unistd.h>int pipe(int fd[2]);
read(fd[0], buffer, size);
write(fd[1], buffer, size);
// 获取上传后返回的信息 fileid
int fd[2];
if (pipe(fd) < 0) return; // 创建无名管道:fd[0] → read,fd[1] → writepid_t pid;
pid = fork(); // fork 子进程
if (pid < 0) return;if (pid == 0) { // 子进程close(fd[0]); // 关闭读端dup2(fd[1], STDOUT_FILENO); // 将标准输出重定向到写管道 // 往标准输出写的东西都会重定向到 fd 所指向的文件 → 当 fileid 产生时输出到管道 fd[1] // 通过 execlp 执行 fdfs_upload_file → fdfs_upload_file /etc/fdfs/client.conf video.mp4execlp("fdfs_upload_file", "fdfs_upload_file", s_dfs_path_client.c_str(), file_path, NULL); // 如果 execlp 调用成功, 那么新程序将开始执行,原程序的代码则不会再继续执行, execlp 后边的代码也就不会执行了LogError("execlp fdfs_upload_file error"); // 执行失败close(fd[1]);
} else { // 父进程close(fd[1]); // 关闭写端read(fd[0], fileid, TEMP_BUF_MAX_LEN); // 等待管道写入然后读取// 等待子进程结束, 回收其资源wait(NULL); close(fd[0]);
}
FIFO
- 命名管道。
- 可以在无关的进程间交换数据。
- 速度慢。
#include <sys/types.h>
#include <sys/stat.h>int mkfifo(const char* pathname, mode_t mode);mkfifo("fifo_file", 0600);
int fd = open("./fifo_file");
read(fd, buffer, size);
write(fd, buffer, size);
消息队列
- 消息的链接表,存储在内核中。
- 消息队列独立于进程。
- 速度慢、容量有限。
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>// ftok 生产一个 ipc key
key_t ftok(const char* pathname, int proj_id);// 根据 ipc key 获取消息队列唯一标识
int msgget(key_t key, int flag);int msgsnd(int msqid, const void* ptr, size_t size, int flag);int msgrcv(int msqid, void* ptr, size_t size, long type, int flag);
key_t key = ftok(".", 'z');int msgctl(int msqid, int cmd, struct msqid_ds* buf);
共享内存
- 多个进程共享的一块存储区。
- 最快的一种
IPC。 - 需要和信号量配合使用。
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>// ftok 生产一个 ipc key
key_t ftok(const char* pathname, int proj_id);// 根据 ipc key 获取共享内存唯一标识
int shmget(key_t key, size_t size, int flag);void *shmat(int shm_id, const void* addr, int flag);
int shmdt(void* addr);
int shmctl(int shm_id, int cmd, struct shmid_ds* buf);
信号量
- 信号量是一个计数器,用于进程间的互斥与同步。
#include <semaphore.h>/*pshared == 0 → 一个进程中的多线程之间通信pshared != 0 并且是共享内存的唯一标识 → 多进程之间通信
*/
int sem_init(sem_t* sem, int pshared, unsigned int value);
int sem_post(sem_t* sem);
int sem_wait(sem_t* sem);
int sem_close(sem_t* sem);
int sem_destroy(sem_t* sem);
信号
- 信号本质上是一种软中断,一种通知机制。
- 处理方法:忽略、捕获、默认动作。
sighandler_t signal(int signum, sighandler_t handler);
int kill(pid_t pid, int sig);
/* 默认情况下,往一个读端关闭的管道或 socket 连接中写数据将引发 SIGPIPE 信号。我们需要在代码中捕获并处理该信号, 或者至少忽略它。因为程序接收到 SIGPIPE 信号的默认行为是结束进程,而我们绝对不希望因为错误的写操作而导致程序退出。SIG_IGN 忽略信号的处理程序
*/
signal(SIGPIPE, SIG_IGN); // 忽略 SIGPIPE 信号
socket
- 不会局限是否在同一机器。
线程同步的方式
- 什么是线程同步 ?
- 让线程对临界资源的访问按照规定的次序执行。
- 主要解决线程之间的协同问题。
- 为什么需要线程同步 ?
- 在一个进程中的所有线程共享该进程的资源。
- 如果不干预线程对临界资源的访问可能造成意想不到的错误,甚至导致进程崩溃。
- 线程同步有哪些方式 ?
互斥锁
- 确保同一时间只有一个线程访问临界资源。
- 当锁被占用时,其他试图获取该锁的线程都会进入阻塞状态。
- 当锁被释放时,会通过信号通知其他被锁阻塞的线程,被阻塞线程可能修改为就绪状态,也可能直接调度执行。
- 如何实现互斥锁:
- 互斥锁首先需要做一个内存标记,记录的是线程
ID,因为互斥锁需要进行线程切换。 - 互斥锁是为了保护临界资源,同时只允许一个线程去访问临界资源,所以会有一个阻塞队列,通过阻塞队列唤醒其它线程去访问临界资源。
- 要屏蔽中断。
- 底层硬件自旋锁。
- 互斥锁首先需要做一个内存标记,记录的是线程
- 互斥锁的表现:
- 先在用户态自旋一会儿。
- 获取失败,把任务挂起(放到阻塞队列中),核心会切换其它线程去执行。
- 休眠一段时间再次尝试获取锁。
// 声明一个互斥量
pthread_mutex_t mtx;
// 初始化
pthread_mutex_init(&mtx, NULL);
// 加锁
pthread_mutex_lock(&mtx);
// 解锁
pthread_mutex_unlock(&mtx);
// 销毁
pthread_mutex_destroy(&mtx);
自旋锁
- 当多个线程竞争锁的时候,只允许一个线程去访问临界资源,其他的线程不会处于阻塞态,也就是不会进行线程切换,会占用
CPU核心,轮询使用临界资源的线程是否释放锁。 - 在实际自旋锁的实现过程中,它不会一直占用
CPU不断地去轮询,它可能也会切换线程,但是和互斥锁的切换是有差别的:- 互斥锁被切换出去,会处于阻塞态,当互斥锁被释放的时候,会从阻塞队列中取出一个线程,把它转化为就绪态,进入就绪队列,未来被系统调度的时候再把它从就绪队列中取出,转化为运行态去运行。
- 自旋锁被切换出去,会处于就绪态,进入就绪队列,时刻等待被系统调度。
- 自旋锁适用于锁持有时间短的场景。
// 声明
pthread_spinlock_t spin;
// 初始化
pthread_spin_init(&spin, PTHREAD_PROCESS_PRIVATE);
// 加锁
pthread_spin_lock(&spin);
// 解锁
pthread_spin_unlock(&spin);
// 销毁
pthread_spin_destroy(&spin);
条件变量
- 用户态的条件让当前线程发生阻塞,当另外一个线程判断特定条件为真时,通知当前线程解除阻塞。
- 对条件的判断需在互斥锁的保护下进行。
- 条件变量需要和互斥锁一起使用。
读写锁
- 当加写锁成功时处于写状态,任何试图加读锁或写锁的线程都阻塞。
- 当加读锁成功时处于读状态,其他试图加读锁的线程不阻塞,而试图加写锁的线程阻塞。
- 读写锁适用于读远大于写的场景。
MySQL数据库中的行锁:S锁(读锁)、X锁(写锁)。
// 声明一个读写锁
pthread_rwlock_t rwlock;
// 在读之前加读锁
pthread_rwlock_rdlock(&rwlock);
// 读完释放锁
pthread_rwlock_unlock(&rwlock);// 在写之前加写锁
pthread_rwlock_wrlock(&rwlock);
// 写完释放锁
pthread_rwlock_unlock(&rwlock);
// 销毁读写锁
pthread_rwlock_destroy(&rwlock);
信号量
- 非负的整数计数器,用来实现对资源的控制,既可以用于线程之间、也可以用于进程之间。
- 信号量适用于多份临界资源的访问。
- 只有当信号量大于
0的时候,才能访问资源。 - 比如
A线程调用sem_wait将信号量减为0了,A线程发生阻塞;如果B线程调用sem_post把信号量+ 1,将会解除A线程的阻塞,A线程继续执行。
// 初始化信号的个数
// pshared = 0 → 线程之间通信
// pshared > 0 → 进程之间通信
sem_init(&sem, pshared, value);sem_wait(); // P 操作:--操作
sem_post(); // V 操作:++操作
线程通信的方式
- 信号:
pthread_kill(thread, 0)→ 通常用于检测其他线程是否存活 → 返回0代表存活,返回错误代表线程不存在。 - 线程同步的方式。
互斥锁和自旋锁的区别
- 共同点:
- 都具备排他性。
- 谁持有锁谁释放锁。
- 不同点:
- 获取锁失败后的行为:
- 自旋锁轮询检测。
- 互斥锁进行阻塞。
- 获取锁失败后的行为:
一个线程加锁了,另一个线程可以解锁吗 ?
- 只有条件变量是通过另外一个线程来解锁的。
虚假唤醒
- 可能会有多个线程在
pthread_cond_wait休眠。 pthread_cond_signal会唤醒至少一个休眠的线程,也就是可能会唤醒多个休眠的线程。- 如果使用
if,消费者线程被唤醒后会少了重新检查条件的步骤,所以使用while。- 为什么消费者线程被唤醒后要重新检查条件 ? 也就是为什么会出现虚假唤醒 ?
- 在多线程环境下,可能会发生信号劫持,也就是
pthread_cond_signal唤醒了多个休眠的线程。
- 在多线程环境下,可能会发生信号劫持,也就是
- 为什么消费者线程被唤醒后要重新检查条件 ? 也就是为什么会出现虚假唤醒 ?
// 消费者线程
pthread_mutex_lock(&mtx);
...
while(condition) { // while 用来解决虚假唤醒pthread_cond_wait(&cond, &mtx);// pthread_cond_wait 内部:// 1. 先 unlock(&mtx)// 2. 在 cond 休眠// --- __add_task 时唤醒// 3. 在 cond 唤醒// 4. 加上 lock(&mtx);
}
... 执行逻辑
pthread_mutex_unlock(&mtx);// 生产者线程
pthread_mutex_lock(&mtx);
... 修改条件
pthread_mutex_unlock(&mtx);
pthread_cond_signal(&cond);
static inline void
__add_task(task_queue_t *queue, void *task) {// 不限定任务类型,只要该任务的结构起始内存是一个用于链接下一个节点的指针// link 指向 task 的 next 指针void **link = (void**)task;*link = NULL;spinlock_lock(&queue->lock);*queue->tail /* 等价于 queue->tail->next */ = link;queue->tail = link;spinlock_unlock(&queue->lock);// 唤醒休眠的线程pthread_cond_signal(&queue->cond);
}static inline void *
__pop_task(task_queue_t *queue) {spinlock_lock(&queue->lock);if (queue->head == NULL) {spinlock_unlock(&queue->lock);return NULL;}task_t *task;task = queue->head;void **link = (void**)task;queue->head = *link;if (queue->head == NULL) {queue->tail = &queue->head;}spinlock_unlock(&queue->lock);return task;
}static inline void *
__get_task(task_queue_t *queue) {task_t *task;// 虚假唤醒while ((task = __pop_task(queue)) == NULL) {pthread_mutex_lock(&queue->mutex);pthread_cond_wait(&queue->cond, &queue->mutex);pthread_mutex_unlock(&queue->mutex);}return task;
}
CAS 是怎样的一种同步机制
CAS属于原子操作。- 什么是原子操作 ?
- 底层级别的同步操作:
CPU指令。 - 不会被调度机制所打断的操作。
- 原子性:该原子操作是不可分割的,要么都做完了,要么还没开始,不会被其他线程看到只完成了一部分。
- 底层级别的同步操作:
- 什么时候使用原子操作 ?
- 背景:锁会造成性能损耗。
- 操作简单、冲突较少。
- C++ 中的
CAS(compare and swap):CAS操作组成:- 内存中的值
V。 - 期待值
Expect。 - 替换值
New Value。
- 内存中的值
CAS操作流程:- 比较内存中的值与期待值是否相等。
- 如果相等,写入替换值,并返回
true。 - 如果不相等,直接返回
false。
// 基于 CAS 实现自旋锁 #include <atomic>class SpinLock { public:SpinLock() : _flag(false) {}void lock() {bool expect = false;while (!_flag.compare_exchange_weak(expect, true)) {expect = false;// 解决伪失败问题if (_flag.load() == true) {break;}}}void unlock() {_flag.store(false);} private:std::atomic<bool> _flag; };
ABA问题:- 线程
1取出A,修改为B,再次修改为A。 - 线程
2取出A,由于时间差没有感知到A值的变化。 - 解决:给
A增加版本号,将ABA问题转变为1A2B3C问题。
- 线程
- 伪失败问题:
compare_exchange_weak允许偶然错误返回(虽然内存中的值与期待值一样,但是返回了false)。- 通过循环解决。
compare_exchange_weak比compare_exchange_strong性能高。
相关文章:
操作系统总结
进程和线程的区别 本质区别: 进程是资源调度以及分配的基本单位。线程是 CPU 调度的基本单位。 所属关系:一个线程属于一个进程,一个进程可以拥有多个线程。地址空间: 进程有独立的虚拟地址空间。线程没有独立的虚拟地址空间&…...
SpringCloud整合OpenFeign实现微服务间的通信
1. 前言 1.1 为什么要使用OpenFeign? 虽说RestTemplate 对HTTP封装后, 已经⽐直接使⽤HTTPClient简单⽅便很多, 但是还存在⼀些问题. 需要拼接URL, 灵活性⾼, 但是封装臃肿, URL复杂时, 容易出错. 代码可读性差, ⻛格不统⼀。 1.2 介绍一下微服务之间的通信方式 微…...

老师必备!一文教你如何高效收集志愿填报信息
高考志愿填报季,对于每一位老师来说,无疑是一场信息收集与管理的硬仗。如何在众多的志愿信息中,高效、准确地掌握每位学生的志愿意向? 高考志愿填报的重要性。不仅是学生人生的一个重要转折点,也是老师教育生涯中的一次…...

创建 MFC DLL-使用DEF文件
本文仅供学习交流,严禁用于商业用途,如本文涉及侵权请及时联系本人将于及时删除 利用“MFC动态链接库”项目模板可以创建MFC DLL。DLL文件与可执行文件非常相似,不同点在于DLL包含有导出表(Export Table)。导出表包含DLL中每个导出函数的名字…...

如何将HTTP升级成HTTPS?既简单又免费的方法!
在当今数字化时代,网络安全已成为用户和企业关注的焦点。HTTPS作为一种更加安全的网络通信协议,正逐渐取代传统的HTTP成为新的标准。对于许多网站管理员和内容创作者来说,如何免费升级到HTTPS是一个值得探讨的问题。本文将详细介绍一些免费的…...

数据仓库之核心模型与扩展模型分离
在数据仓库的设计和实施过程中,核心模型与扩展模型分离是一种常见的策略,旨在提高数据仓库的灵活性、可维护性和扩展性。这种分离策略的主要优势和实施方法如下: 核心模型(Core Model) 核心模型是数据仓库中稳定、共…...
大龄职场人的春招机遇:技术岗位主导,高薪与挑战并存
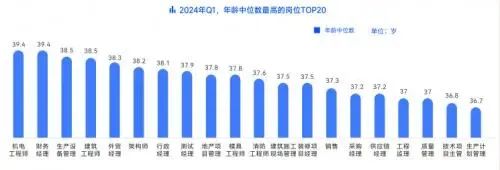
随着6月毕业季的临近,大批年轻人即将涌入人才市场,为职场注入新鲜血液。然而,这也意味着一些职场人可能面临被“优化”的风险。近几年,职场环境呈现出明显的年轻化趋势,企业更倾向于招聘具有创新活力的青年人才&#x…...
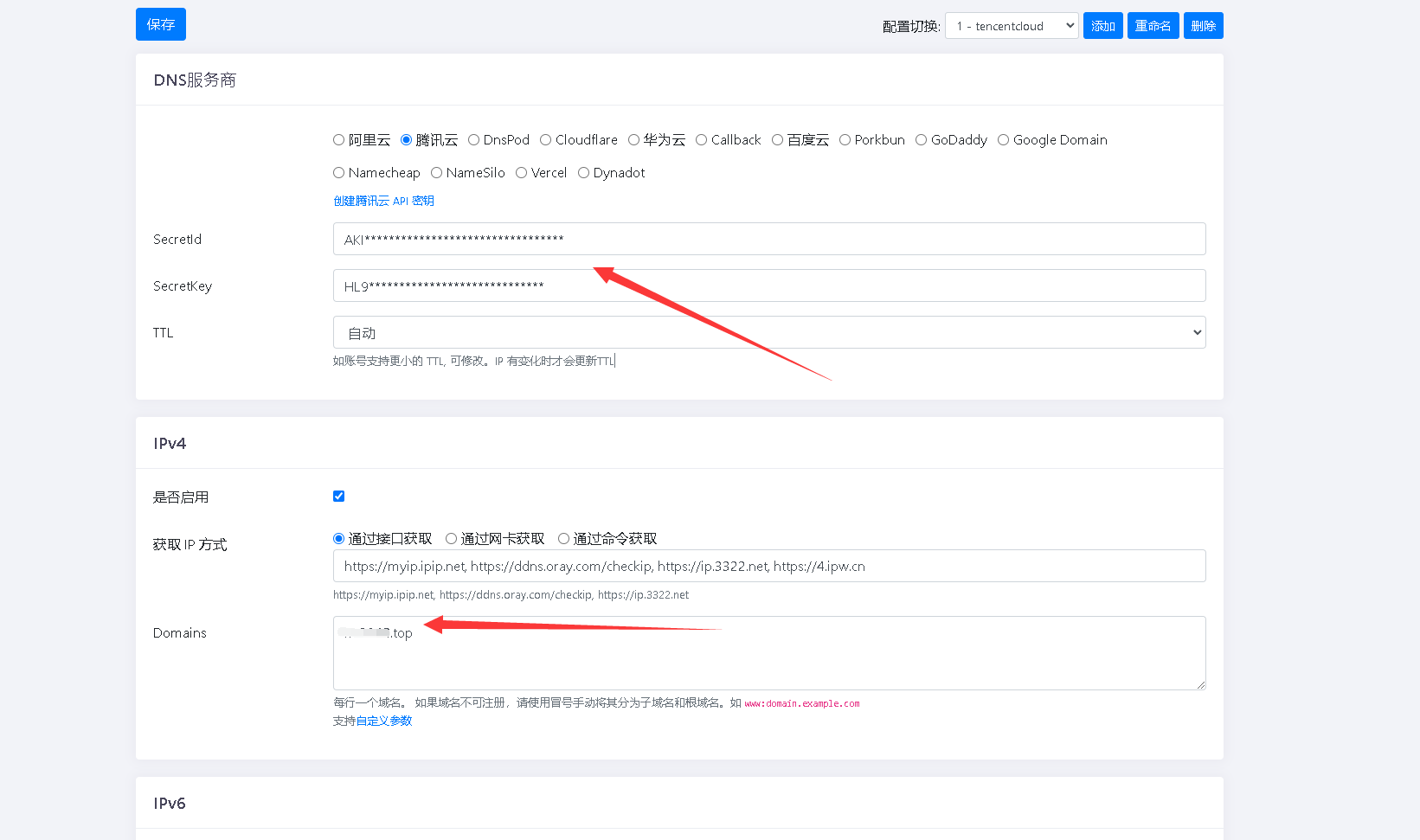
家宽动态公网IP,使用docker+ddns 实现动态域名解析
官方地址:https://github.com/jeessy2/ddns-go 安装docker docker pull jeessy/ddns-godocker run -d --name ddns-go --restartalways --nethost -v /opt/ddns-go:/root jeessy/ddns-go然后访问ip端口 配置时注意如下...

【力扣刷题 动态规划】LeetCode 139 单词拆分、LeetCode 300 最长递增子序列 ✌
文章目录 1. 单词拆分2. 最长递增子序列 1. 单词拆分 题目链接 🍎 解题思路: class Solution {bool dp[310] {false};public:bool wordBreak(string s, vector<string>& wordDict) {unordered_set<string> myset;for(auto& str :…...

【位运算】【前缀和】个人练习-Leetcode-1177. Can Make Palindrome from Substring
题目链接:https://leetcode.cn/problems/can-make-palindrome-from-substring/description/ 题目大意:给出一个字符串s,每次query给出l, r, k,要求判断子串s[l:r1]在经过k次操作后是否能变为回文串。一次操作可以将子串内的一个字…...
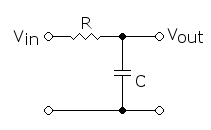
最小相位系统
最小相位系统 1、传递函数 一个线性系统的响应。 比如一个RC低通滤波器: 交流分量在电容的充放电中被滤除掉,通过设置电容器的电容值,以及电阻值,能够控制这种滤除能力,这个参数为RC。 电容的电抗为 1 / j w C 1/j…...

css系列:进度条
前言 技术来源于需求,近期遇到了做语音的需求,有个调整语速和音量的进度条,UI组件库的进度条大部分不支持拖动和点击修改当前进度,所以自己手写了一个。 实现思路 MDN文档介绍 <input type"range"> - HTML&am…...

QT中为程序加入超级管理员权限
QT中为程序加入超级管理员权限 Chapter1 QT中为程序加入超级管理员权限1. mingw编译器2. MSVC编译器3. CMAKE Chapter2 如何给QT程序添加管理员权限(UAC)的几种方法1、Qt Creator中方案一:(仅适用于使用msvc编译器)方案二:&#x…...
)
共识算法之争(PBFT,Raft,PoW,PoS,DPoS)
文章目录 共识算法拜占庭容错技术(Byzantine Fault Tolerance,BFT)PBFT:Practical Byzantine Fault Tolerance,实用拜占庭容错算法Raft协议POW(Proof of Work)工作量证明机制POSDPoS(Delegated Proof of St…...

抽象的java入门1.3.0
前言: 在1.2.0版本中我们介绍了public class hello {}并从中提取出两个新概 修饰符和作用域 public class hello {public static void main(String[] args) {System.out.println("Hello World");} } 正片: 这一期把剩余的内容刨析出来 pub…...

【Oracle生产运维】表空间可用性告警排查处理
1 前言 在生产环境中,一般设置表空间告警阈值是90%,在接到监控报警后,并不是需要立刻对表空间进行扩容。 决定是否扩容主要看表空间最近的增量是多少,假如剩余10%的空间还能支持1个月的增量,那就不需要急着扩容。如果…...

mac Network: use --host to expose
本地启动无法访问,这个不是权限问题是mac 主机端口安全策略,现在我们只需要开启端口自动检测就可以 npm run dev --host 网络:未暴露 方案一 1、执行 npm run dev -- --host 方案二 1、请在 vite.config.js server: {host: true } 1…...

ChatGPT-4o体验demo
OpenAI 最近推出了其最新的人工智能语言模型——GPT-4O。该模型是在原有 GPT-4 的基础上进行优化而成,旨在提升生成质量和响应速度。GPT-4O 采用了更加高效的架构设计,使其在处理复杂文本时表现出更快的速度和更高的准确性。GPT-4O 在训练过程中融入了最…...
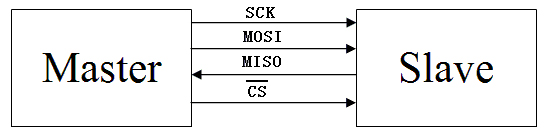
FPGA SPI采集ADC7606数据
一,SPI总线的构成及信号类型 SPI总线只需四条线(如图1所示)就可以完成MCU与各种外围器件的通讯: 1)MOSI – Master数据输出,Slave数据输入 2)MISO – Master数据输入,Slave数据输出 3)SCK – 时钟信号,由Master产生 4)/CS – Slave使能信号,由Master控制。 在一个SPI时…...
html three.js 引入.stl模型示例
1.新建一个模块用于放置模型 <div id"chart_map" style"width:800px;height:500px"></div> 2. 引入代码根据需求更改 <!-- 在head或body标签内加入以下链接 --> <script src"https://cdn.jsdelivr.net/npm/three0.137/build/t…...

FPGA以太网MAC调试架构设计与DSP优化实践
1. 项目概述:FPGA与以太网MAC的DSP调试架构在数字信号处理(DSP)的硬件实现中,调试环节往往成为开发效率的瓶颈。传统JTAG调试方式受限于带宽和灵活性,难以满足大规模数据交互的需求。我们基于Xilinx Virtex-4 FPGA平台…...

AI 写论文哪个软件最好?2026 毕业论文实测:真文献 + 真图表 + 全流程,虎贲等考 AI 稳占首选
📌 配图 1:首图海报 ——AI 写论文哪个最好|虎贲等考 AI|毕业论文神器|真实文献 实证图表 每年毕业季,所有人都在问:AI 写论文哪个软件最好?市面上工具看似很多,可一用…...

WindowsCleaner终极指南:3步告别C盘爆红,让Windows重获新生
WindowsCleaner终极指南:3步告别C盘爆红,让Windows重获新生 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘变红的警告&…...

Universal Data Tool 新功能解析:骨骼姿态标注与数据格式转换实战
1. 项目概述:一个数据标注工具的进化最近在整理一个计算机视觉项目的数据集时,我又一次打开了Universal Data Tool(UDT)。这个工具我用了快两年了,从它早期版本支持基础的图像分类和物体检测框标注开始,就一…...

Speechless微博备份工具:3分钟学会完整导出PDF的终极指南
Speechless微博备份工具:3分钟学会完整导出PDF的终极指南 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 你是否曾担心珍贵的微博回忆突然…...
)
黑莓印相≠复古滤镜!基于CIE Lab色域分析的Midjourney色彩空间偏移校准方案(附Python验证脚本)
更多请点击: https://intelliparadigm.com 第一章:黑莓印相≠复古滤镜!基于CIE Lab色域分析的Midjourney色彩空间偏移校准方案(附Python验证脚本) 黑莓印相(Blackberry Print Tone)常被误认为是…...

Redis++完全指南:C++开发者的终极Redis客户端解决方案
Redis完全指南:C开发者的终极Redis客户端解决方案 【免费下载链接】redis-plus-plus Redis client written in C 项目地址: https://gitcode.com/gh_mirrors/re/redis-plus-plus Redis是一款专为C开发者打造的高性能Redis客户端,它提供了简洁易用…...

Model2Vec最佳实践:10个技巧让你的嵌入模型又快又好
Model2Vec最佳实践:10个技巧让你的嵌入模型又快又好 【免费下载链接】model2vec Fast State-of-the-Art Static Embeddings 项目地址: https://gitcode.com/gh_mirrors/mo/model2vec Model2Vec是一个革命性的静态嵌入模型技术,它能将任何句子转换…...

基于MCP协议构建垂直领域AI知识服务:猴头菇茶MCP服务器实战
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的项目,叫jackrain19743/hou-tea-mcp-server。乍一看这个名字,可能会有点摸不着头脑,“hou-tea”是啥?其实这是一个基于Model Context Protocol&#…...

深度解析:Mermaid实时编辑器架构设计与工程实践指南
深度解析:Mermaid实时编辑器架构设计与工程实践指南 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-editor …...