深度学习——TensorBoard的使用
官方文档torch.utils.tensorboard — PyTorch 2.3 documentation
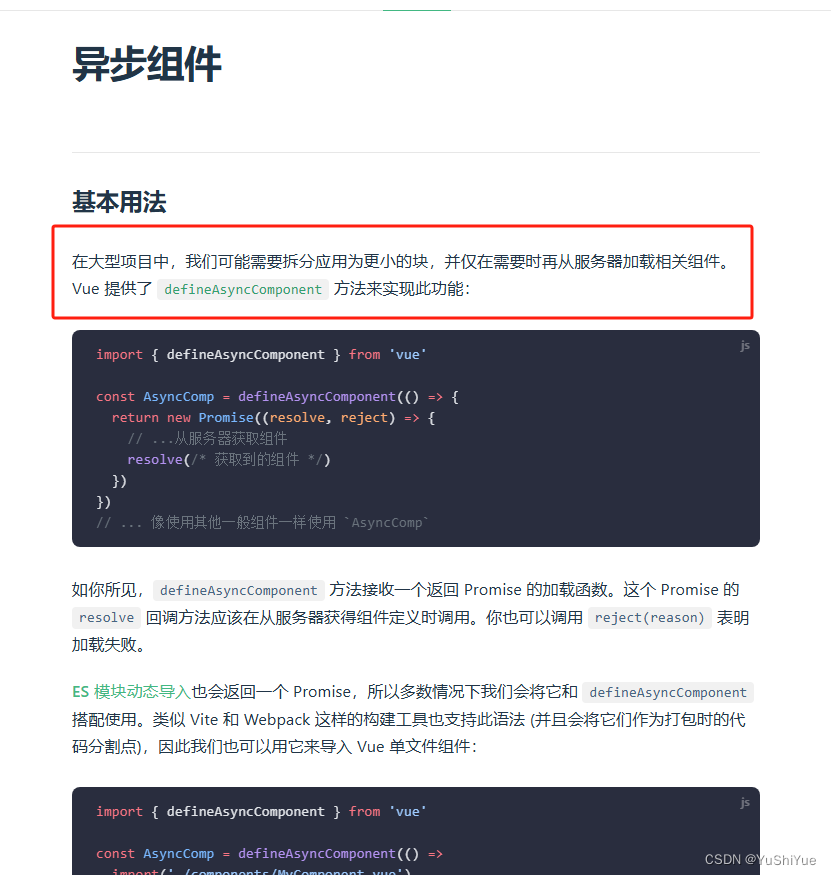
TensorBoard简介
TensorBoard是一个可视化工具,它可以用来展示网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,我们可以设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),使用TensorBoader可以很直观的帮我们进行参数的选择。它通过运行一个本地服务器,来监听6006端口。在浏览器发出请求时,分析训练时记录的数据,绘制训练过程中的图像。
TensorBoard 是Google开发的一个机器学习可视化工具。其主要用于记录机器学习过程,例如:
- 记录损失变化、准确率变化等
- 记录图片变化、语音变化、文本变化等,例如在做GAN时,可以过一段时间记录一张生成的图片
- 绘制模型
TensorBoard下载
pip install tensorboard -i https://pypi.tuna.tsinghua.edu.cn/simple
TensorBoard的使用
Pytorch使用Tensorboard主要用到了三个API:
SummaryWriter:这个用来创建一个log文件,TensorBoard面板查看时,也是需要选择查看那个log文件。
add_something: 向log文件里面增添数据。例如可以通过add_scalar增添折线图数据,add_image可以增添图片。
close:当训练结束后,我们可以通过close方法结束log写入。
接下来,我们来模拟记录训练过程中准确率的变化。
首先需要new一个SummaryWriter对象:
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter('logs')当运行完该行代码后,可以看到当前目录下生成了一个logs文件夹,并且里面有event日志
此时已经可以在终端启动tensorboard来查看了:
tensorboard --logdir=logs --port=6007
SummaryWriter中一些子类函数的使用
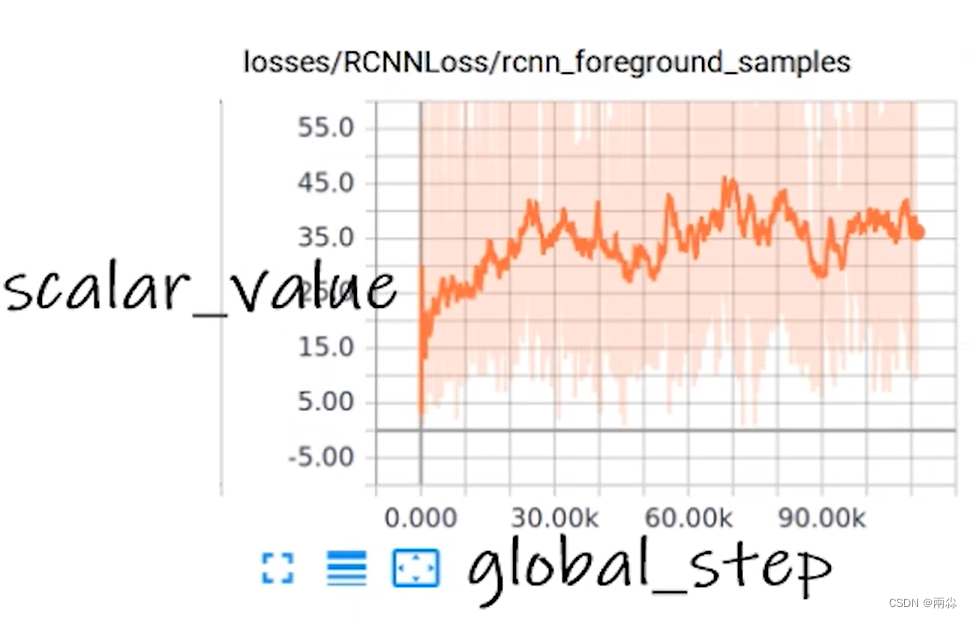
1.add_scalar():添加标量到SummaryWriter中
(1)参数详解
-
tag(string): Data的指定方式,图表的标题
-
scalar(float or string/blobname): 需要存储的数值
-
global_step(int): 训练的步数(Global step value to record),结合scalar,那就是训练到多少步的时候scalar的数值是多少。
-
walltime(float): (不常用参数,可选)Optional override default walltime(time.time()) with seconds after epoch of event
更直观的参数解释,可以表示为下图的方式:
(2)代码
from torch.utils.tensorboard import SummaryWriterwriter=SummaryWriter("logs") #将事件文件存储到logs这个文件夹底下#绘制一个y=2x的图像
for i in range(100):writer.add_scalar("y=x",2*i,i) # writer.add_scalar(图像标题,y轴,x轴)
writer.close()2.add_image():添加image到SummaryWriter
(1)参数详解
-
tag(string): Data的指定方式,图表的标题
-
img_tensor(torch.Tensor, numpy.array, or string/blobname): 图像数据
-
global_step(int): 训练的步数(Global step value to record),结合img_tensor,那就是训练到多少步的时候img_tensor的图像是什么。
-
walltime(float): (不常用参数,可选)Optional override default walltime(time.time()) with seconds after epoch of event
默认输入图像数据形状:
-
(3, H, W):三通道,高,宽
-
注意:如果输入数据为 (H, W, 3) 也是可以的,但是需要设置
dataformats,如dataformats='HWC'
(2)代码
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Imagewriter = SummaryWriter('logs')
image_path = 'img_data/train/ants_image/5650366_e22b7e1065.jpg'
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)print(type(img_array))
print(img_array.shape)
writer.add_image('test', img_array,2, dataformats="HWC")writer.close()3.add_images():添加image到SummaryWriter
add_images(tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')参数:
-
tag(string) -数据标识符
-
img_tensor(torch.Tensor,numpy.array, 或者字符串/blob 名称) -图像数据
-
global_step(int) -要记录的全局步长 值
-
walltime(float) -事件纪元后的可选覆盖默认 walltime (time.time()) 秒
-
dataformats(string) -NCHW、NHWC、CHW、HWC、HW、WH等形式的图像数据格式规范。
将批量图像数据添加到摘要中。
请注意,这需要pillow 包。
形状:
img_tensor:默认为(N,3,W,H) 。如果指定dataformats,则接受其他形状。例如NCHW 或 NHWC。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor())test_loader =DataLoader(dataset=test_data, batch_size=64, shuffle=False, num_workers=0, drop_last=True)
# shuffle 是否打乱 False不打乱
# drop_last 最后一轮数据不够时,是否舍弃 true舍弃#img, target = test_loader[0] TypeError: 'DataLoader' object is not subscriptable
img, target = test_data[0]
print(img.shape)
print(target)writer = SummaryWriter('dataloader')for epoch in range(2):step = 0for data in test_loader:imgs, targets = data# print(imgs.shape)# print(targets)writer.add_images('Epoch:{}'.format(epoch),imgs,step)step = step+1writer.close()参考
TensorBoard快速入门(Pytorch使用TensorBoard)-CSDN博客
深度学习(二)——TensorBoard的使用 - 码头牛牛 - 博客园 (cnblogs.com)
Pytorch学习笔记之tensorboard - 奥辰 - 博客园 (cnblogs.com)
Python PyTorch SummaryWriter.add_images用法及代码示例 - 纯净天空 (vimsky.com)
相关文章:
深度学习——TensorBoard的使用
官方文档torch.utils.tensorboard — PyTorch 2.3 documentation TensorBoard简介 TensorBoard是一个可视化工具,它可以用来展示网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,我们可以设置不同的参数(比如࿱…...
⭐⭐⭐)
【设计模式】观察者模式(行为型)⭐⭐⭐
文章目录 1.概念1.1 什么是观察者模式1.2 优点与缺点 2.实现方式3. Java 哪些地方用到了观察者模式4. Spring 哪些地方用到了观察者模式 1.概念 1.1 什么是观察者模式 观察者模式(Observer Pattern)是一种行为型设计模式,它允许对象在状态改…...

轻松搞定阿里云域名DNS解析
本文将会讲解如何设置阿里云域名DNS解析。在进行解析设置之前,你需要提前准备好需要设置的云服务器IP地址、域名以及CNAME记录。 如果你还没有云服务器和域名,可以参考下面的方法注册一个。 申请域名:《Namesilo域名注册》注册云服务器&…...

GAT1399协议分析(10)--单图像删除
一、官方接口 由于批量删除的接口,图像只能单独删除。 二、wireshark实例 这个接口比较简单,调用request delete即可 文本化: DELETE /VIID/Images/34078100001190001002012024060513561300065 HTTP/1.1 Host: 10.0.201.56:31400 User-Age…...

Hudi CLI 安装配置总结
前言 上篇文章 总结了Spark SQL Rollback, Hudi CLI 也能实现 Rollback,本文总结下 Hudi CLI 安装配置以及遇到的问题。 官方文档 https://hudi.apache.org/cn/docs/cli/ 版本 Hudi 0.13.0(发现有bug)、(然后升级)0.14.1Spark 3.2.3打包 mvn clean package -DskipTes…...
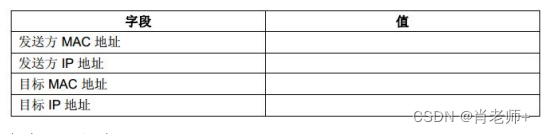
实验八、地址解析协议《计算机网络》
水逆退散,学业进步,祝我们都好,不止在夏天。 目录 一、实验目的 二、实验内容 (1)预备知识 (2)实验步骤 三、实验小结 一、实验目的 完成本练习之后,您应该能够确定给定 IP 地…...

Linux系统管理磁盘管理003
操作系统: CentOS Stream9 测试过程: 模拟磁盘被沾满, 创建文件 测试脚本 for i in seq 10do# echo $idd if/dev/zero of./$i-$RANDOM.txt bs1M count1024 Done[rootlocalhost ~]# vim 2.txt [rootlocalhost ~]# sh 2.txt 记录了10240 的…...

MLC工具是否适用AMD和ARM场景?如何测试内存性能?
MLC(Memory Latency Checker)主要是由Intel开发的工具,主要用于Intel平台上的内存性能测试,尤其是针对Intel处理器的内存延迟和带宽。尽管MLC主要针对Intel处理器设计,理论上它可以在任何支持Intel兼容指令集的系统上运…...

NodeJs实现脚本:将xlxs文件输出到json文件中
文章目录 前期工作和依赖笔记功能代码输出 最近有一个功能,将json文件里的内容抽取到一个xlxs中,然后维护xlxs文件。当要更新json文件时,就更新xlxs的内容并把它传回json中。这个脚本主要使用NodeJS写。 以下是完成此功能时做的一些笔记。 …...

【启程Golang之旅】网络编程与反射
欢迎来到Golang的世界!在当今快节奏的软件开发领域,选择一种高效、简洁的编程语言至关重要。而在这方面,Golang(又称Go)无疑是一个备受瞩目的选择。在本文中,带领您探索Golang的世界,一步步地了…...

nginx location正则表达式+案例解析
1、nginx常用的正则表达式 ^ :匹配输入字符串的起始位置$ :匹配输入字符串的结束位置 *:匹配前面的字符零次或多次。如“ol*”能匹配“o”及“ol”、“oll” :匹配前面的字符一次或多次。如“ol”能匹配“ol”及“oll”、“olll”…...

【YOLO系列】YOLOv10论文超详细解读(翻译 +学习笔记)
前言 研究AI的同学们面对的一个普遍痛点是,刚开始深入研究一项新技术,没等明白透彻,就又迎来了新的更新版本——就像我还在忙着逐行分析2月份发布的YOLOv9代码,5月底清华的大佬们就推出了全新的v10。。。 在繁忙之余࿰…...
植物大战僵尸杂交版2024潜艇伟伟迷
在广受欢迎的游戏《植物大战僵尸》的基础上,我最近设计了一款创新的杂交版游戏,简直是太赞了!这款游戏结合了原有游戏的塔防机制,同时引入新的元素、角色和挑战,为玩家提供了全新的游戏体验。 植物大战僵尸杂交版最新绿…...

白话解读网络爬虫
网络爬虫(Web Crawler),也称为网络蜘蛛、网络机器人或网络蠕虫,是一种自动化程序或脚本,被用来浏览互联网并收集信息。网络爬虫的主要功能是在互联网上自动地浏览网页、抓取内容并将其存储在本地或远程服务器上供后续处…...
: 从理论到实践的指南(1))
支持向量机(SVM): 从理论到实践的指南(1)
支持向量机(SVM)被誉为数据科学领域的重量级算法,是机器学习中不可或缺的工具之一。SVM以其优秀的泛化能力和对高维数据的管理而备受推崇。本文旨在梳理SVM的核心概念以及其在实际场景中的应用。 SVM的核心理念 SVM专注于为二分类问题找到最…...

万字长文|OpenAI模型规范(全文)
本文是继《OpenAI模型规范概览》之后对OpenAI Model Spec的详细描述,希望能对各位从事大模型及RLHF研究的朋友有帮助。万字长文,建议收藏后阅读。 一、概述 在AI的世界里,确保技术的行为符合我们的期望至关重要。OpenAI最近发布了一份名为Mo…...
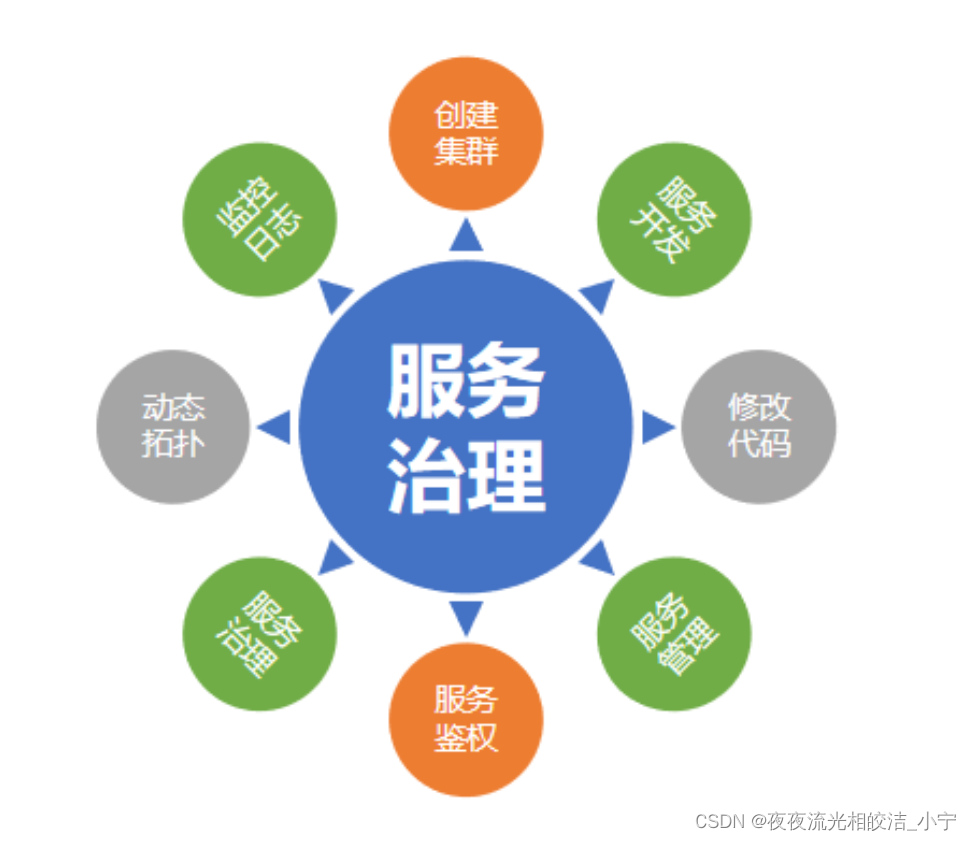
微服务架构-正向治理与治理效果
目录 一、正向治理 1.1 概述 1.2 效率治理 1.2.1 概述 1.2.2 基于流量录制和回放的测试 1.2.3 基于仿真环境的测试 1.3 稳定性治理 1.3.1 概述 1.3.2 稳定性治理模型 1.3.3 基于容器化的稳定性治理 1.3.3.1 概述 1.3.3.2 测试 1.3.3.3 部署 1.3.3.3.1 概述 1.3.3…...

normalizing flows vs 直方图规定化
normalizing flows名字的由来 The base density P ( z ) P(z) P(z) is usually defined as a multivariate standard normal (i.e., with mean zero and identity covariance). Hence, the effect of each subsequent inverse layer is to gradually move or “flow” the da…...
vite打包优化常用的技巧及思路
面试题:vitevue项目如何进行优化? 什么情况下会去做打包优化?一种是在搭建项目的时候就根据自己的经验把vite相关配置给处理好,另外一种是开发的过程中发现打包出来的静态资源越来越大,导致用户访问的时候资源加载慢&a…...

k8s学习--kubernetes服务自动伸缩之水平收缩(pod副本收缩)HPA详细解释与案例应用
文章目录 前言HPA简介简单理解详细解释HPA 的工作原理监控系统负载模式HPA 的优势使用 HPA 的注意事项应用类型 应用环境1.metircs-server部署2.HPA演示示例(1)部署一个服务(2)创建HPA对象(3)执行压测 前言…...

无人机安全测试终极实战指南:3大攻击向量深度解析与防护策略
无人机安全测试终极实战指南:3大攻击向量深度解析与防护策略 【免费下载链接】Drone-Hacking-Tool Drone Hacking Tool is a GUI tool that works with a USB Wifi adapter and HackRF One for hacking drones. 项目地址: https://gitcode.com/gh_mirrors/dr/Dron…...
)
给IPC相机调图像,别再瞎调了!一份保姆级的ISP线性模式调试顺序图(附避坑要点)
IPC相机图像调试实战指南:从线性模式到专业级画质优化 刚接触IPC相机图像调试的工程师们,常常会陷入参数迷宫——面对AE、AWB、Gamma、3DNR等数十个模块,该从何处入手?调试顺序的错误可能导致反复返工,甚至影响最终成像…...

别再到处找DEM了!手把手教你用ArcGIS Pro + Python脚本,从NASA官网免费下载并拼接出完整的中国90米高程数据
从NASA获取中国90米高程数据的自动化解决方案 在GIS和遥感研究领域,获取高质量的数字高程模型(DEM)数据是许多项目的基础工作。然而,对于中国区域的完整覆盖、高精度且免费可用的DEM数据,研究者们常常面临获取困难。本文将介绍如何利用ArcGI…...

脉冲神经网络SAST训练方法:解决代理-硬件转换差距
1. 脉冲神经网络与传感器计算的挑战脉冲神经网络(SNNs)作为第三代神经网络模型,其核心特征是采用离散的脉冲信号进行信息传递和处理。这种事件驱动的计算方式与传统的连续激活神经网络(ANNs)有着本质区别。在传感器端计…...

基于MCP协议实现AI助手个性化:Terminal Buddies项目实战解析
1. 项目概述:当你的终端伙伴遇见AI助手 如果你和我一样,每天有大量时间泡在终端和代码编辑器里,那么一个能带来些许乐趣和陪伴感的“数字伙伴”或许能点亮枯燥的编码时光。Terminal Buddies 正是这样一个巧妙结合了复古 ASCII 艺术、轻量级游…...

如何免费获取全球50+图书馆古籍资源:BookGet数字古籍下载完整指南
如何免费获取全球50图书馆古籍资源:BookGet数字古籍下载完整指南 【免费下载链接】bookget bookget 数字古籍图书下载工具。 项目地址: https://gitcode.com/gh_mirrors/bo/bookget 还在为寻找古籍文献而烦恼吗?想要从哈佛、国会图书馆等全球知名…...

十大类型学系统性阐释:自感痕迹论的发生学分类体系
十大类型学系统性阐释:自感痕迹论的发生学分类体系引言:类型学作为公理的微分展开一个完备的发生学体系,不应满足于对单一现象的孤立分类。它应当从少数基本公设出发,在不同分析层面自然衍生出互相关联又各具独立性的类型学。自感…...
)
Claude 3.5 Sonnet重磅升级(开发者必看的3个隐藏API调用技巧)
更多请点击: https://intelliparadigm.com 第一章:Claude 3.5 Sonnet重磅升级概览 Anthropic 正式发布 Claude 3.5 Sonnet,作为当前推理模型中响应速度与智能水平的全新标杆,其在多模态理解、长上下文处理及代码生成能力上实现显…...

从原理到实战:使用Kali Linux进行WiFi安全渗透测试
1. WiFi安全渗透测试基础 很多人可能觉得WiFi密码破解是个神秘的黑客技术,其实它只是网络安全领域中一个基础的安全测试手段。作为一名安全研究员,我经常需要在获得授权的情况下,对客户的无线网络进行安全评估。Kali Linux作为专业的渗透测试…...

自研系统与Odoo ERP数据集成中间件设计与实现
1. 项目概述:连接两个世界的桥梁最近在折腾企业信息化系统集成时,遇到了一个挺典型的场景:公司内部有一套自研的、基于特定业务逻辑的微服务应用(我们内部戏称为“雾系统”),同时又在使用Odoo这套成熟的ERP…...