使用 flask + qwen 实现 txt2sql 流式输出
前言
一般的大模型提供的 api 都是在提问之后过很久才会返回对话内容,可能要耗时在 3 秒以上了,如果是复杂的问题,大模型在理解和推理的耗时会更长,这种展示结果的方式对于用户体验是很差的。
其实大模型也是可以进行流式输出,也就是像 chatgpt 一个字一个字往出崩,这样用户可以一直追踪输出的内容,而不是枯燥的没有止境的等待,本文以我的 txt2sql 实际项目为例,简单介绍使用通义千问 api + flask 框架搭建出一个可以流式输出结果的服务。
txt2sql 任务
我的 txt2sql 任务是基于我的业务数据库内容,用户会提出相关的业务问题,我会让大模型在理解数据库内容的情况下,输出对于问题的理解和思考过程,并最终返回正确的 sql 。
服务
这里的代码虽然很长,但是内容不多,这里需要关心的点有以下几个:
- flask 的路由函数
getAnwser正常写即可,但是最后的返回为了支持流输出,需要另外封装定义一个函数getStream,并在getAnwser最后使用下面方式调用getStream进行流式输出:
Response(stream_with_context(getStream()), content_type='text/event-stream')- 很多关于大模型的 tools 回调、 rag 框架细节、prompt 模板都被我封装了,剩下的就是使用
get_llm_prompt获取最终的 prompt ,然后喂给通义千问最强模型qwen-max-longcontext,设置到参数stream=True 和 incremental_output=True,让通义千问进行流式输出,将获得的responses结果进行处理即可,结果要用yield生成输出流数据。 - 其他的代码是日志管理和异常处理。
import logging
from http import HTTPStatusimport dashscope
from flask import request, Flask, Response, stream_with_context
from config import config
from llm import MyCustomLLM
from tools_imp import get_llm_prompt
from my_util import get_question_sqlapp = Flask(__name__)
model = MyCustomLLM(config.DB_HOST, config.DB_PORT, config.DB_NAME, config.DB_USER, config.DB_PASS)
logging.basicConfig(level=logging.INFO, encoding="utf-8",filename=config.LOG_PATH, filemode='a',format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s')
question_sql = get_question_sql()@app.route('/getAnwser', methods=["POST"])
def getAnwser():def getStream():data = request.get_json()if 'question' not in data or not data['question']:yield "无法理解,请重新输入问题"question = data['question']try:prompt = get_llm_prompt(model, question, question_sql)dashscope.api_key = config.API_KEYllm_response = ""responses = dashscope.Generation.call(model="qwen-max-longcontext", messages=prompt, result_format='message', stream=True, incremental_output=True )r = Nonefor r in responses:if r.status_code == HTTPStatus.OK:info = r['output']['choices'][0]['message']['content']llm_response += infoyield infoelse:raise Exception("大模型执行报错")logging.info(f"llm_response: {llm_response}")logging.info(f"input_tokens: {r['usage']['input_tokens']}, output_tokens: {r['usage']['output_tokens']}")except BaseException as e:logging.error(f'question:{question}, Error: {e}')yield f"Error: {str(e)}\n\n".encode()return Response(stream_with_context(getStream()), content_type='text/event-stream')if __name__ == '__main__':app.run(config.FLASK_HOST, config.FLASK_PORT, debug=True)测试
另外写一个访问 post 请求的测试代码,请求我的服务接口,结果会持续地一点一点打印完整。
import requestsurl = 'http://localhost:9001/getAnwser'
payload = {"question": "沈塘桥地铁站的信息"}
response = requests.post(url, json=payload, stream=True)
if response.status_code == 200:try:for chunk in response.iter_content(chunk_size=1024):if chunk:print(chunk.decode('utf-8'), end="") except Exception as e:print(f"流处理过程中出现错误: {e}")控制台中会一点点持续输出以下内容,就是流式输出样式,但是我没法使用 gif 动态展示,只能直接显示最后的整体内容:
您的问题是:沈塘桥地铁站的信息思考过程:
- 用户想了解关于“沈塘桥地铁站”的具体信息。
- 关键点在于定位到名为“沈塘桥”的地铁站,这涉及到模糊匹配站名。
- 需要从dtzpt表中查询,因为该表存储了地铁站点的详细信息。
- 查询时,需确保返回所有字段信息,以便提供完整详情。```sql
SELECT * FROM dtzpt WHERE name LIKE '%沈塘桥%'```那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
相关文章:
使用 flask + qwen 实现 txt2sql 流式输出
前言 一般的大模型提供的 api 都是在提问之后过很久才会返回对话内容,可能要耗时在 3 秒以上了,如果是复杂的问题,大模型在理解和推理的耗时会更长,这种展示结果的方式对于用户体验是很差的。 其实大模型也是可以进行流式输出&a…...

植物大战僵尸杂交版最新2.0.88手机+电脑+苹果+修改器
在这个充满奇妙的平行宇宙中,植物和僵尸竟然能够和谐共存!是的,你没听错!一次意外的实验,让这两个看似对立的生物种类发生了基因杂交,创造出了全新的生物种类——它们既能够进行光合作用,也具备…...

Vite - 开发初体验,以及按需导入配置
目录 开始 创建一个 Vite 项目 项目结构 /src/main.js index.html package.json vite.config.js Vite 项目中使用 vue-router Vite 组件的“按需引入” 传统的方式引入一个组件 传统方式引入带来的问题 解决办法(配置 按需引入 插件) 示例&…...

推荐云盘哪个好,各有各的优势
选择合适的云盘服务是确保数据安全、便捷分享和高效协作的关键。下面将从多个维度对目前主流的云盘服务进行详细的对比和分析: 速度性能 百度网盘青春版:根据测试,其上传和下载确实不限速,但主要定位是办公人群,适用于…...

面试题之webpack与vite系列
今天继续来分享面试题,今天要分享的技术是webpack和vite的一些区别,下面我列举了最常见的关于webpack和vite的面试题,主要有以下几个: 1.说说你对webpack的理解?plugin和loader有什么区别? Webpack是一个…...

单调队列 加 二分
雾粉与最小值(简单版) 链接: 牛客 思路 题意是 给定我们数组a让我们完成{x,l,r}询问,判断是否在a中存在子数组满足长度在l,r之间且子数组最小值大于等于x,输出yes 或者 on 一个数组,长度越长,其最小值越小ÿ…...

Node.js 和 Vue 的区别的基本知识科普
Node.js和Vue.js在多个方面存在显著的区别。以下是这两者的主要区别,按照清晰的分点表示和归纳: Node.js 服务器端环境: Node.js是一个基于Chrome V8引擎的JavaScript运行环境,它使JavaScript能够在服务器端运行。为JavaScript提供服务器端的环境服务,方便地搭建响应速度…...
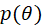
统计信号处理基础 习题解答10-10
题目 在本题中,我们讨论再生PDF。回顾前面 其中分母与无关。如果选择一个,使得它与相乘时,我们得到与相同形式的PDF,那么后验PDF 将有和相同的形式。例10.1的高斯PDF正是这样的一种情况。现在假设在条件下的的PDF是指数形式&…...

【蓝桥杯】C语言常见高级算法
🌸个人主页:Yang-ai-cao 📕系列专栏:蓝桥杯 C语言 🍍博学而日参省乎己,知明而行无过矣 目录 🌸个人主页:Yang-ai-cao 📕系列专栏:蓝桥杯 C语言 &a…...
FastJson
目录 FastJson 新建一个SpringBoot项目 pom.xml 一、JavaBean与JSON数据相互转换 LoginController FastJsonApplication启动类 编辑二、FastJson的JSONField注解 Log实体类 TestLog测试类 三、FastJson对JSON数据的增、删、改、查 TestCrud FastJson 1、JSON使用手册…...

Web3设计风格和APP设计风格
Web3设计风格和传统APP设计风格在视觉和交互设计上有一些显著的区别。这些差异主要源于Web3技术和理念的独特性,以及它们在用户体验和界面设计中的具体应用。以下是Web3设计风格与传统APP设计风格的主要区别。北京木奇移动技术有限公司,专业的软件外包开…...
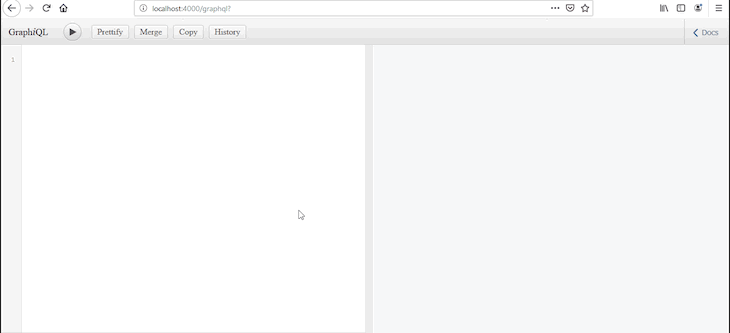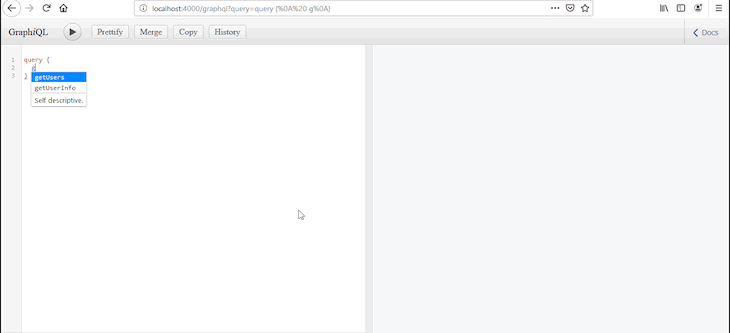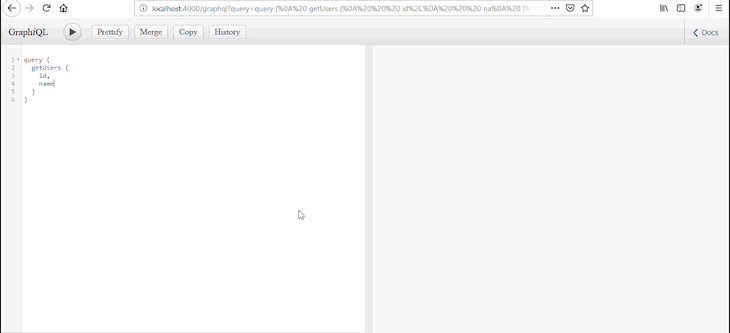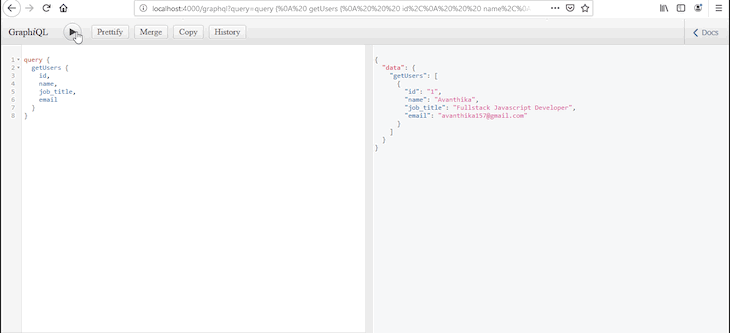
使用React和GraphQL进行CRUD:完整教程与示例
在本教程中,我们将向您展示如何使用GraphQL和React实现简单的端到端CRUD操作。我们将介绍使用React Hooks读取和修改数据的简单示例。我们还将演示如何使用Apollo Client实现身份验证、错误处理、缓存和乐观UI。 什么是React? React是一个用于构建用户…...

matplotlib 动态显示训练过程中的数据和模型的决策边界
文章目录 Github官网文档简介动态显示训练过程中的数据和模型的决策边界安装源码 Github https://github.com/matplotlib/matplotlib 官网 https://matplotlib.org/stable/ 文档 https://matplotlib.org/stable/api/index.html 简介 matplotlib 是 Python 中最常用的绘图…...

【学术小白成长之路】02三方演化博弈(基于复制动态方程)期望与复制动态方程
从本专栏开始,笔者正式研究演化博弈分析,其中涉及到双方演化博弈分析,三方演化博弈分析,复杂网络博弈分析等等。 先阅读了大量相关的博弈分析的文献,总结了现有的研究常用的研究流程,针对每个流程进行拆解。…...

短剧看剧系统投流版系统搭建,前端uni-app
目录 前言: 一、短剧看剧系统常规款短剧系统和投流版的区别? 二、后端体系 1.管理端: 2.代理投流端 三、功能区别 总结: 前言: 23年上半年共上新微短剧481部,相较于2022年全年上新的454部࿰…...

最新的ffmepg.js前端VUE3实现视频、音频裁剪上传功能
package.json "dependencies": {"ffmpeg/ffmpeg": "^0.12.10","ffmpeg/util": "^0.12.1" }vue3组件代码 根据需要更改 <script setup lang"ts"> import { FFmpeg } from ffmpeg/ffmpeg; import { fetchF…...

“Apache Kylin 实战指南:从安装到高级优化的全面教程
Apache Kylin是一个开源的分布式分析引擎,它提供了在Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力,支持超大规模数据的亚秒级查询。以下是Kylin的入门教程,帮助您快速上手并使用这个强大的工具。 1. 安装Kylin Apache Kylin的安装是一个关键步骤,它要求您具备一…...

【iOS】内存泄漏检查及原因分析
目录 为什么要检测内存泄漏?什么是内存泄漏?内存泄漏排查方法1. 使用Zombie Objects2. 静态分析3. 动态分析方法定位修改Leaks界面分析Call Tree的四个选项: 内存泄漏原因分析1. Leaked Memory:应用程序未引用的、不能再次使用或释…...

“深入探讨Java中的对象拷贝:浅拷贝与深拷贝的差异与应用“
前言:在Java编程中,深拷贝(Deep Copy)与浅拷贝(Shallow Copy)是两个非常重要的概念。它们涉及到对象在内存中的复制方式,对于理解对象的引用、内存管理以及数据安全都至关重要。 ✨✨✨这里是秋…...

Docker 进入指定容器内部(以Mysql为例)
文章目录 一、启动容器二、查看容器是否启动三、进入容器内部 一、启动容器 这个就不多说了 直接docker run… 二、查看容器是否启动 查看正在运行的容器 docker ps查看所有的容器 docker ps -a结果如下图所示: 三、进入容器内部 通过CONTAINER ID进入到容器…...

Zotero插件市场TOP1新势力:Perplexity Connector v2.3正式发布,支持LLM上下文感知文献溯源,仅限前500名开发者早鸟激活
更多请点击: https://intelliparadigm.com 第一章:Perplexity Zotero整合方案全景概览 Perplexity 作为新一代 AI 驱动的研究型搜索引擎,其核心优势在于实时引用溯源与上下文感知问答;Zotero 则是学术工作者广泛采用的开源文献管…...

Yarbo 机器人割草机调整策略:远程后门访问功能将设为可选安装
Yarbo 调整远程后门访问功能,设为可选安装Yarbo 原有的远程后门访问功能可能使不法分子通过互联网对机器人进行重新编程。如今,该公司计划彻底移除这一功能,联合创始人肯尼斯科尔曼承诺,客户将能够决定是否一开始就安装该功能&…...

交完Essay才发现Turnitin更新了AI检测?我是这么应对的
上学期我的一个朋友被约谈了。 教授发邮件说:"你的Essay和AI生成文本相似度过高,请来办公室解释。" 他确实用了AI——谁没用呢——但他也认真改写了好几遍。问题是,Turnitin在2025年更新了AI检测模型,现在它不只看词汇…...

从零到一:UNet环境搭建与自定义数据集实战指南
1. 环境准备:从Anaconda到PyTorch的完整配置 第一次接触UNet时,我最头疼的就是环境配置。记得当时为了跑通一个细胞分割的demo,整整折腾了两天。现在回头看,其实只要掌握几个关键步骤,整个过程可以非常顺畅。 首先需要…...

霍尔效应绝对式双码道磁编码器【附电路】
✨ 长期致力于双码道多磁极编码器、硬件设计、误差仿真与校正、算法设计与优化研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)双码道多磁极磁场检测硬…...

Go-ldap-admin权限系统解析:基于Casbin的RBAC实现完整指南
Go-ldap-admin权限系统解析:基于Casbin的RBAC实现完整指南 【免费下载链接】go-ldap-admin 🌉 基于GoVue实现的openLDAP后台管理项目 项目地址: https://gitcode.com/gh_mirrors/go/go-ldap-admin Go-ldap-admin作为一款基于GoVue实现的现代化Ope…...

保姆级教程:用Lumerical FDTD参数扫描功能,分析WO3薄膜厚度对反射率的影响
从零到精通:Lumerical FDTD参数扫描在薄膜光学设计中的实战指南 在光电材料研究和器件设计中,薄膜厚度的精确控制往往直接影响器件的光学性能。以三氧化钨(WO₃)薄膜为例,其厚度变化会显著改变反射光谱特性,…...

小熊猫Dev-C++:零配置C/C++开发环境的终极指南
小熊猫Dev-C:零配置C/C开发环境的终极指南 【免费下载链接】Dev-CPP A greatly improved Dev-Cpp 项目地址: https://gitcode.com/gh_mirrors/dev/Dev-CPP 小熊猫Dev-C(Red Panda Dev-C)是一款专为C/C开发者设计的现代化集成开发环境&…...

华为会议转任务AI精准识别整理,省事更清晰,轻松搞定工作落地
"找2026华为会议转任务AI的朋友,你要的精准识别整理、落地工作的真实测评来了。不管你是做学术研究要整访谈、转讲座,还是开会长音频要扒任务,我测了大半个月,直接给你掏实底。我接触太多做学术的朋友,都踩过AI转…...

3步实战UE4SS游戏Mod开发:从零构建你的第一个LUA脚本系统
3步实战UE4SS游戏Mod开发:从零构建你的第一个LUA脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4S…...