【NoSQL数据库】Redis Cluster集群(含redis集群扩容脚本)
Redis Cluster集群
- Redis Cluster
- Redis 分布式扩展之 Redis Cluster 方案
- 功能
- 数据如何进行存储
- redis 集群架构
- 集群伸缩
- 向集群中添加一个新的master节点,并向其中存储 num=10 .
- 脚本对redis集群扩容缩容,脚本参数为redis集群,固定从6001移动2000个哈希槽到新实例上
- 故障转移
- 集群总线
- Redis性能管理
- 查看Redis内存使用
- 内存碎片率
- 内存使用率
- 内存回收key
Redis Cluster
Redis 分布式扩展之 Redis Cluster 方案
主从切换的过程中会丢失数据,因为只有一个 master,只能单点写,没有解决水平扩容的问题。而且每个节点都保存了所有数据,一个是内存的占用率较高,另外就是如果进行数据恢复时,非常慢。而且数据量过大对数据 IO 操作的性能也会有影响。
所以我们同样也有对 Redis 数据分片的需求,所谓分片就是把一份大数据拆分成多份小数据,在 3.0 之前,我们只能通过构建多个 redis 主从节点集群,把不同业务数据拆分到不冉的集群中,这种方式在业务层需要有大量的代码来完成数据分片、路由等工作,导致维护成本高、增加、移除节点比较繁琐。
Redis3.0 之后引入了 Redis Cluster 集群方案,它用来解决分布式扩展的需求,同时也实现了高可用机制。
功能
- 读和写可以负载均衡
- 自动故障转移
- 突破了单机存储限制,方便扩展
数据如何进行存储
- 槽(slot)
使用hash算法,16384(2^14)个hash槽,每个hash槽有512字节
redis 集群架构
- redis的集群模式中可以实现多个节点同时提供写操作,redis集群模式采用无中心结构,节点之间互相连接从而知道整个集群状态。
- redis 集群采用了多主多从,按照一定的规则进行分片,每个节点都保存数据,将数据分别存储,一定程度上解决了哨兵模式下单机存储有限的问题。
- 下面我这里采用的是三主三从的架构模式,由于硬件问题,主从都配置到了同一台服务器上,启动6个redis实例。
开启群集功能
#其他5个文件夹的配置文件以此类推修改,注意6个端口都要不一样。
vim redis.conf
#bind 127.0.0.1 #69行,注释掉bind 项,默认监听所有网卡
protected-mode no #88行,修改,关闭保护模式
port 6379 #92行,修改,redis监听端口,
daemonize yes #136行,开启守护进程,以独立进程启动
cluster-enabled yes #832行,取消注释,开启群集功能
cluster-config-file nodes-6379.conf #840行,取消注释,群集名称文件设置
cluster-node-timeout 15000 #846行,取消注释群集超时时间设置
appendonly yes #699行,修改,开启AOF持久化cd /usr/local/redis/bin
mkdir -p redis-cluster/redis600{1..6}
for i in {1..6}
do
cp -i redis.conf redis-cluster/redis600$i
cp -i redis-cli redis-server redis-cluster/redis600$i
sed -i "s/6379/600$i/" redis-cluster/redis600$i/redis.conf
done
启动redis节点
for d in {1..6}
do
cd /usr/local/redis/bin/redis-cluster/redis600$d
redis-server redis.conf
done
ps -ef | grep redis
启动集群
redis-cli \
#-a redis123 起名
--cluster create \
127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 \ #随机分组--cluster-replicas 1#IP1:6001 IP1:6004 IP2:6002 IP2:6005 IP3:6003 IP3:6006
六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。下面交互的时候 需要输入 yes才可以创建。
–replicas 1 表示每个主节点有1个从节点。
测试群集
redis-cli -p 6001 -c #加-c参数,节点之间就可以互相跳转
127.0.0.1:6001> cluster slots #查看节点的哈希槽编号范围

set name zhangli

cluster keyslot name #查看name键的槽编号

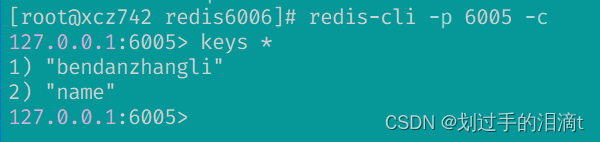
127.0.0.1:6002> quitredis-cli -p 6005 -c
127.0.0.1:6005> keys * #对应的slave节点也有这条数据,但是别的节点没有
集群伸缩
作为分片集群,其中有一个很重要的功能,就是支持集群伸缩。比如平时非活动期间访问量不会很大,使用三主三从就可以,618、双十一期间,大促活动时候,这种访问量很高的,这个时候,就需要我们对Redis集群进行扩容了,当活动过后,流量下来会,我们又要进行缩容。那么分片集群怎么做到集群伸缩的。
cluster meet
CLUSTER MEET 是 Redis Cluster 内置的命令,可以直接在任何一个节点上执行。它需要指定要加入集群的新节点的 IP 地址和端口号。
【注意】若 cluster meet 加入已存在于其它集群的节点,会致使集群合并,造成数据错乱!建议使用redis-cli add-node
#Redis Cluster是Redis的集群模式,它通过分片和复制来提供高可用性和可扩展性。
#下面是一些常用的Redis Cluster命令:
CLUSTER MEET <ip> <port>:将当前节点与指定的节点进行集群连接。
CLUSTER ADDSLOTS <slot> [<slot> ...]:将指定的槽位分配给当前节点。
CLUSTER DELSLOTS <slot> [<slot> ...]:从当前节点中移除指定的槽位。
CLUSTER REPLICATE <node_id>:将当前节点设置为指定节点的从节点。
CLUSTER INFO:查看集群的整体信息,包括节点数量、槽位分布、复制信息等。
CLUSTER NODES:列出所有的集群节点及其状态、角色、地址等详细信息。
CLUSTER SLOTS:显示集群中的槽位信息,以及这些槽位所属的主节点和从节点。
CLUSTER KEYSLOT <key>:根据键名计算该键所属的槽位。
CLUSTER COUNTKEYSINSLOT <slot>:统计指定槽位中的键数量。
CLUSTER FORGET <node_id>:从集群中移除指定的节点。
CLUSTER FLUSHSLOTS:清空当前节点的所有槽位信息。
CLUSTER REPLICATE <node_id>:将当前节点设置为指定节点的从节点。
CLUSTER SAVECONFIG:将集群的配置保存到硬盘上的redis.conf文件中。
redis-cli --cluster 和 cluster meet区别
- 当您希望将一个新节点添加到已经运行的 Redis 集群时,可以使用CLUSTER MEET 命令来告诉现 有集群关于这个新节点。
- 而对于初始化一个全新的 Redis集群,首先需要选择其中一个作为种子(seed)或引导 (bootstrap)节点,并使用 --cluster add-node 选项来添加其他所有主从节点。
提供了很多操作集群的命令,我们可以通过help方式查看:
redis-cli --cluster help
比如,添加节点命令:
向集群中添加一个新的master节点,并向其中存储 num=10 .
步骤:
①:启动一个新的Redis实例,地址为192.168.99.121:6010;
②:添加192.168.99.121:6010到之前的集群中,并作为一个master节点;
③:给192.168.99.121:6010节点分片插槽,是的num这个key可以存放到192.168.99.121:6010实例中。
对需求进行分析,我们可以知道,这里其实需要两个新的功能:
①:添加一个节点到集群中;
②:将部分插槽分配到新的master节点上
127.0.0.1:6001> set num 100
创建新的Redis实例
redis6010

添加新的节点到redis集群中
redis-cli --cluster add-node 192.168.99.121:6010 192.168.99.121:6001
通过命令查看集群状态。命令:
redis-cli -h 192.168.99.121 -p 6001 cluster nodes
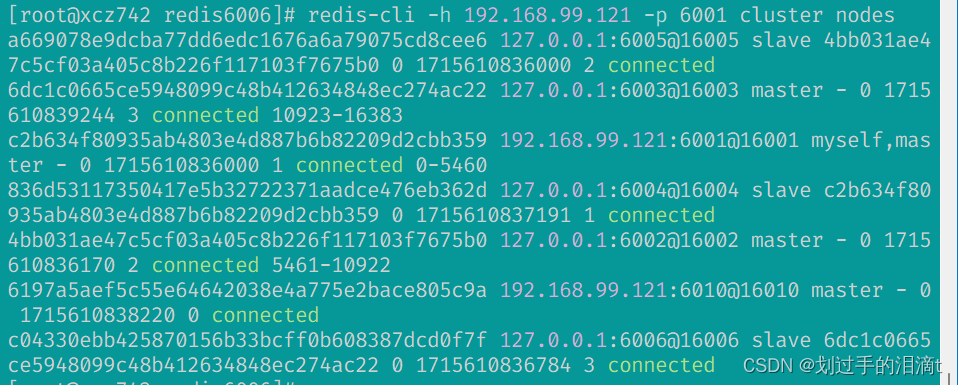
从上图中,我们可以看到,新加入的6001节点,是以master身份加入到了集群中,但是,没有插槽。如果没有插槽的话,也就意味着没有任何数据可以存储到6010上。
那么接下来,我们就来进行插槽的转移。
转移插槽
我们要将key为num的数据存储在6001,这个新插入节点上,因此,需要先看看key==num对应的插槽是多少。可以执行CLUSTER KEYSLOT
命令:
CLUSTER KEYSLOT num
那么我们可以将0~3000的插槽从1节点转移到10这个新节点上。
redis-cli --cluster reshard 192.168.99.121:6010
依次输入
#插槽数量
3000
#6010的node id
6197a5aef5c55e64642038e4a775e2bace805c9a
#6001的node id
c2b634f80935ab4803e4d887b6b82209d2cbb359
done
yes
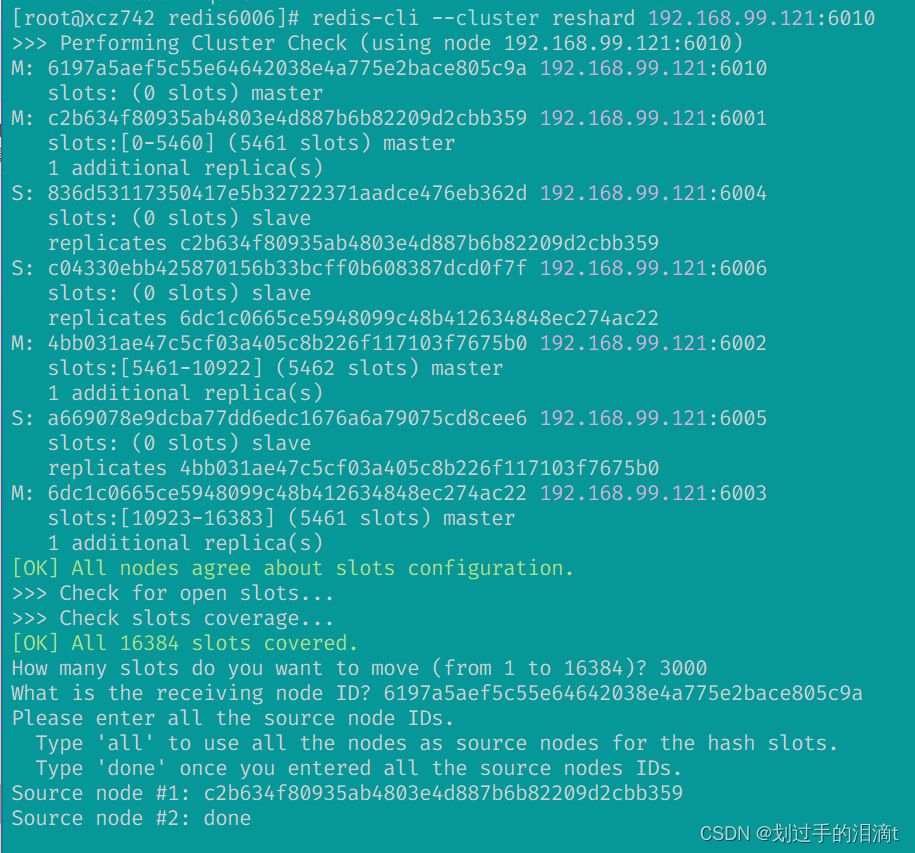
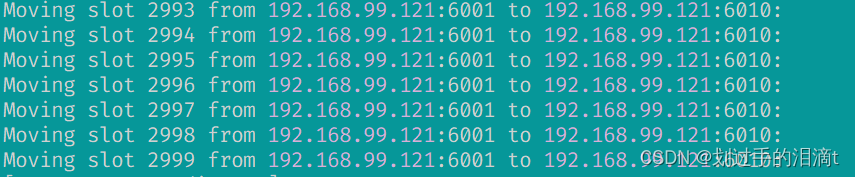
验证是否转移插槽成功
127.0.0.1:6001> get num
-> Redirected to slot [2765] located at 192.168.99.121:6010
"100"
脚本对redis集群扩容缩容,脚本参数为redis集群,固定从6001移动2000个哈希槽到新实例上
#!/bin/bash
# 定义槽的数量,用于Redis集群重新分配槽
SlotsNumber=2000
# 定义接收迁移槽的节点IP和端口
ReceiveIP=192.168.99.121
ReceivePort=6010
# 定义源节点IP和端口,即迁移槽来源的节点
SourceIP=192.168.99.121
SoursePort=6001
# 通过Redis命令行工具获取接收节点和源节点的ID,用于后续的槽迁移操作
ReceiveNodeID=$(redis-cli -h $SourceIP -p $SoursePort cluster nodes | grep $ReceiveIP:$ReceivePort | awk '{print $1}')
SourseNodeID=$(redis-cli -h $SourceIP -p $SoursePort cluster nodes | grep $SourceIP:$SoursePort | awk '{print $1}')
# 创建一个Expect脚本,用于自动交互式地执行Redis集群槽迁移命令
cat >RedisClusterReshard.exp <<EOF
#!/bin/expect
spawn redis-cli --cluster reshard $ReceiveIP:$ReceivePort
# 自动回答迁移的槽数量
expect "How many slots do you want to move (from 1 to 16384)?"
send "$SlotsNumber\r"
# 自动提供接收节点ID
expect "What is the receiving node ID?"
send "$ReceiveNodeID\r"
# 自动提供源节点ID
expect "Source node #1:"
send "$SourseNodeID\r"
# 因为只有一个源节点,所以此处人为输入"done"结束源节点输入
expect "Sourse node #2:"
send "done\r"
# 确认迁移操作
expect "*(yes/no)?"
send "yes\r"
interact
EOF
# 设置Expect脚本的执行权限
chmod 755 RedisClusterReshard.exp
# 执行Expect脚本,开始槽迁移操作
./RedisClusterReshard.exp故障转移
自动故障转移
当集群中有一个master宕机会发生什么
- 首先该实例与其他实例失去连接
- 疑似宕机
- 确定下线,自动提升一个slave为新的master
手动故障转移
数据迁移
在新的slave节点利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移.
手动的failover支持三种不同模式:
- 缺省:默认的流程
- force:省略了对offset的一致性校验
- takeover:直接执行第5步,忽略数据一致性、忽略master状态和其他master的意见
集群总线
Redis集群中的每个节点都需要打开两个TCP连接。一个连接用于正常的给Client提供服务,比如 6379,那么对应的还有一个额外的端口就是16379作为数据端口。
这个作为数据端口是在6379端口端号上加10000。
例如:redis的端口为 6379,那么另外一个需要开通的端口是:6379 + 10000, 即需要开启 16379。
16379 端口用于集群总线,这是一个用二进制协议的点对点通信信道。这个集群总线(Cluster bus)用于节点的失败侦测、配置更新、故障转移授权,等等。
解决问题:
开放16379等端口即可:
sudo firewall-cmd --add-port=16370-16379/tcp --permanent
firewall-cmd --reload
firewall-cmd --list-all
Redis性能管理
查看Redis内存使用
info memory
内存碎片率
操作系统分配的内存值 used_memory_rss 除以 Redis 使用的内存总量值 used_memory 计算得出。
内存值 used_memory_rss 表示该进程所占物理内存的大小,即为操作系统分配给 Redis 实例的内存大小。
除了用户定义的数据和内部开销以外,used_memory_rss 指标还包含了内存碎片的开销, 内存碎片是由操作系统低效的分配/回收物理内存导致的(不连续的物理内存分配)。
举例来说:Redis 需要分配连续内存块来存储 1G 的数据集。如果物理内存上没有超过 1G 的连续内存块, 那操作系统就不得不使用多个不连续的小内存块来分配并存储这 1G 数据,该操作就会导致内存碎片的产生。
#跟踪内存碎片率对理解Redis实例的资源性能是非常重要的:
- 内存碎片率稍大于1是合理的,这个值表示内存碎片率比较低,也说明 Redis 没有发生内存交换。
- 内存碎片率超过1.5,说明Redis消耗了实际需要物理内存的150%,其中50%是内存碎片率。需要在redis-cli工具上输入
shutdown save命令,让 Redis 数据库执行保存操作并关闭 Redis 服务,再重启服务器。 - 内存碎片率低于1的,说明Redis内存分配超出了物理内存,操作系统正在进行内存交换。需要增加可用物理内存或减少 Redis 内存占用。
内存使用率
redis实例的内存使用率超过可用最大内存,操作系统将开始进行内存与swap空间交换。
#避免内存交换发生的方法:
- 针对缓存数据大小选择安装 Redis 实例
- 尽可能的使用Hash数据结构存储
- 设置key的过期时间
内存回收key
内存清理策略,保证合理分配redis有限的内存资源。
当达到设置的最大阀值时,需选择一种key的回收策略,默认情况下回收策略是禁止删除。
配置文件中修改 maxmemory-policy 属性值:
vim /etc/redis/6379.conf
--598--
maxmemory-policy noenviction
volatile-lru:使用LRU算法从已设置过期时间的数据集合中淘汰数据(移除最近最少使用的key,针对设置了TTL的key)
volatile-ttl:从已设置过期时间的数据集合中挑选即将过期的数据淘汰(移除最近过期的key)
volatile-random:从已设置过期时间的数据集合中随机挑选数据淘汰(在设置了TTL的key里随机
移除)
allkeys-lru:使用LRU算法从所有数据集合中淘汰数据(移除最少使用的key,针对所有的key)
allkeys-random:从数据集合中任意选择数据淘汰(随机移除key)
noenviction:禁止淘汰数据(不删除直到写满时报错)

相关文章:
【NoSQL数据库】Redis Cluster集群(含redis集群扩容脚本)
Redis Cluster集群 Redis ClusterRedis 分布式扩展之 Redis Cluster 方案功能数据如何进行存储 redis 集群架构集群伸缩向集群中添加一个新的master节点,并向其中存储 num10 .脚本对redis集群扩容缩容,脚本参数为redis集群,固定从6001移动200…...
重邮计算机网络803-(2)物理层
一.物理层 1.介绍 物理层的主要任务描述为确定与传输媒体的接口的一些特性,即: ①机械特性 指明接口所用接线器的形状和尺寸、引线数目和排列、固定和锁定装置等等。 ②电气特性 指明在接口电缆的各条线上出现的电压的范围。 ③功能特性 指明某条线上…...

uniapp使用webview内嵌H5的注意事项
一、描述 uniapp项目中构建app,需要内嵌H5页面,在使用webview时,遇到了以下几个问题: 内嵌H5,默认全屏显示;内嵌页面遮挡住了app的自定义tabbar组件;样式修改无效; 二、解决方案&a…...

现代 C++的高效并发编程模式
现代C提供了许多高效的并发编程模式,以满足日益增长的多核和分布式系统的需求。以下是一些常用的高效并发编程模式: 异步编程:使用std::async来创建异步任务,可以在后台执行任务,将结果返回给调用者。 并行编程&#…...
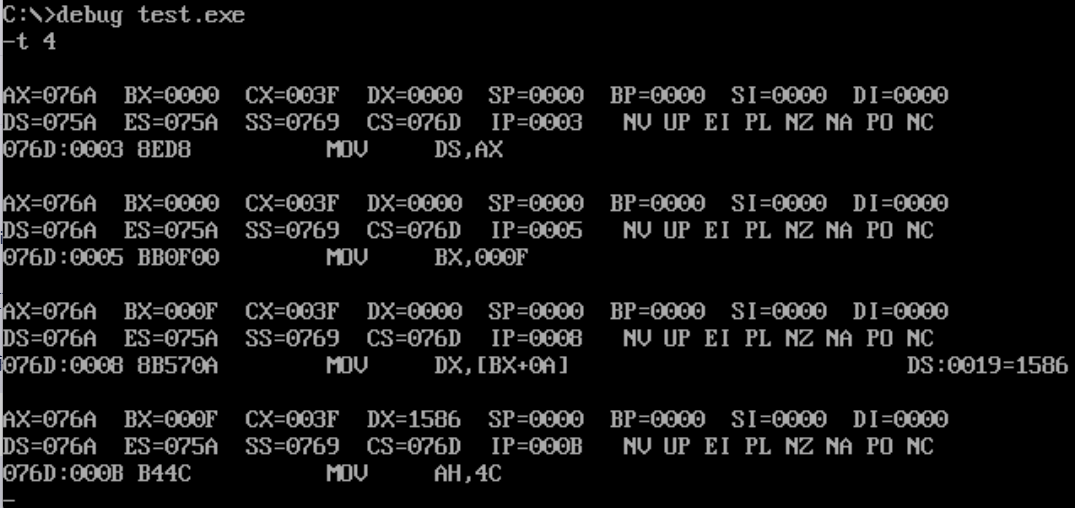
汇编语言作业(五)
目录 一、实验目的 二、实验内容 三、实验步骤以及结果 四、实验结果与分析 五、 实验总结 一、实验目的 1.熟悉掌握汇编语言的程序结构,能正确书写数据段、代码段等 2,利用debug功能,查看寄存器(CS,IP,AX,DS..)及数据段的…...
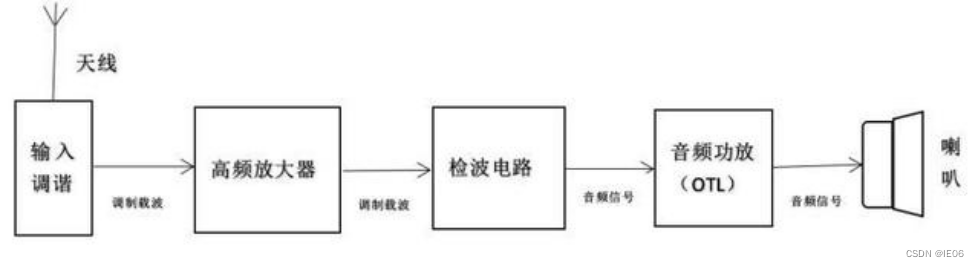
收音机的原理笔记
1. 收音机原理 有线广播:我们听到的声音是通过空气振动进行传播,因此可以通过麦克风(话筒)将这种机械振动转换为电信号,传到远处,再重新通过扬声器(喇叭)转换为机械振动,…...

排序算法案例
排序算法概述 排序算法是计算机科学中的一个重要主题,用于将一组数据按特定顺序排列。排序算法有很多种,每种算法在不同情况下有不同的性能表现。不同的排序算法适用于不同的场景和数据特征。在选择排序算法时,需要考虑数据规模、数据分布以…...

时间序列评价指标
评价指标 均方误差( M S E MSE MSE) 定义:预测值与实际值之间差异的平方和的平均值。公式: ( M S E 1 n ∑ i 1 n ( y i − y ^ i ) 2 ) (MSE \frac{1}{n}\sum_{i1}^{n}(y_i - \hat{y}_i)^2) (MSEn1∑i1n(yi−y^i)…...
Docker:安装 Orion-Visor 服务器运维的技术指南
请关注微信公众号:拾荒的小海螺 博客地址:http://lsk-ww.cn/ 1、简述 Orion-Visor 是一种用于管理和监控容器的工具。它提供了一个直观的界面,用于查看容器的状态、资源使用情况以及日志等信息。在这篇技术博客中,我们将介绍如何…...
HarmonyOS Next 系列之底部标签栏TabBar实现(三)
系列文章目录 HarmonyOS Next 系列之省市区弹窗选择器实现(一) HarmonyOS Next 系列之验证码输入组件实现(二) HarmonyOS Next 系列之底部标签栏TabBar实现(三) 文章目录 系列文章目录前言一、实现原理二、…...
mac怎么录制屏幕?这2个方法你值得拥有
在数字化时代,屏幕录制已经成为一种常见且重要的工具,无论是教学演示、游戏直播还是会议记录,屏幕录制都发挥着不可或缺的作用。对于Mac用户而言,如何高效、便捷地进行屏幕录制,是一个值得探讨的话题,可是很…...

爱德华三坐标软件ACdmis.AC-dmis密码注册机
爱德华三坐标软件 AC-DMIS 是一款功能强大的三坐标测量软件,具有以下特点: • 支持多种测量模式:包括接触式测量、非接触式测量、复合式测量等,可以满足不同类型工件的测量需求。 • 高精度测量:采用先进的测量算法和…...

计算机网络 期末复习(谢希仁版本)第3章
对于点对点的链路,目前使用得最广泛的数据链路层协议是点对点协议 PPP (Point-to-Point Protocol)。局域网的传输媒体,包括有线传输媒体和无线传输媒体两个大类,那么有线传输媒体有同轴电缆、双绞线和光纤;无线传输媒体有微波、红…...

代码随想录——数组
给定一个n个元素有序(升序)的整型数组nums和一个目标值target,写一个函数搜索nums中的target,如果目标值存在返回下标,否则返回-1. //这个题说实话从逻辑上来看实在是太简单了,但是为什么每一次我写起来都感…...
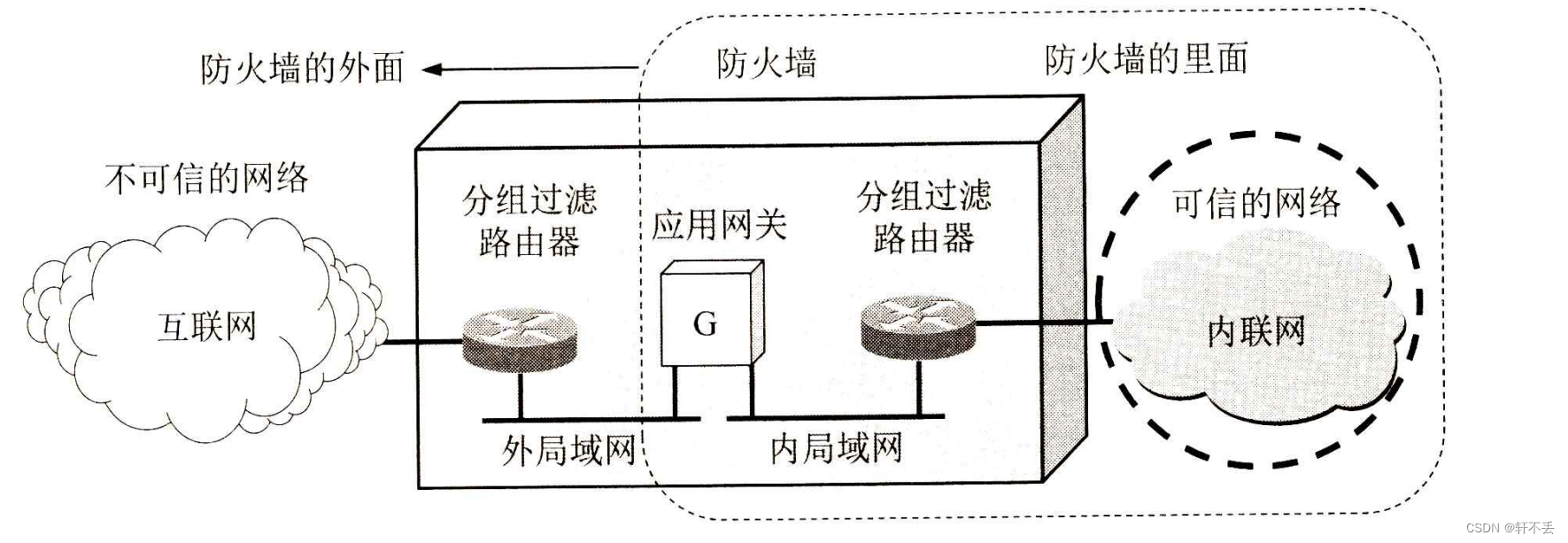
计算机网络7——网络安全4 防火墙和入侵检测
文章目录 一、系统安全:防火墙与入侵检测1、防火墙1)分组过滤路由器2)应用网关也称为代理服务器(proxy server), 二、一些未来的发展方向 一、系统安全:防火墙与入侵检测 恶意用户或软件通过网络对计算机系统的入侵或攻击已成为当今计算机安…...

html+CSS+js部分基础运用20
根据下方页面效果如图1所示,编写程序,代码放入图片下方表格内 图1.效果图 <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta http-equiv"X-UA-Compatible" conte…...

ISO 19115-2:2019 附录C XML 模式实现
C.1 XML 模式 本文件中定义的 UML 模型的 XML 模式在 ISO/TS 19115-3 中定义的适当 XML 命名空间中提供。新增内容包括: 命名空间前缀模式文件名Metadata for ACquisition (mac)acquisitionInformationImagery.xsdMetadata for Resource Content (mrc)contentInfo…...
)
DevOps的原理及应用详解(一)
本系列文章简介: 在当今快速变化的商业环境中,企业对于软件交付的速度、质量和安全性要求日益提高。传统的软件开发和运维模式已经难以满足这些需求,因此,DevOps(Development和Operations的组合)应运而生&a…...
)
【冲刺秋招,许愿offer】第 三 天(水一天)
【冲刺秋招,许愿offer】第 二 天(水一天) 知识点牛客emo 知识点 今天端午,上午去摘杏下午理发,一天没咋看电脑。晚上刷刷LeetCode看看八股。 牛客 spring事务失效的情况 捕获到异常,自己手动处理 方法修…...
使用 C# 学习面向对象编程:第 6 部分
继承 亲爱的读者,继承意味着从源头继承一些东西。例如,儿子可以继承父亲的习惯。同样的概念也用于面向对象编程;它是 OOP 的第二大支柱。 继承允许创建一个新类,该新类继承另一个类或基类的属性,继承这些成员的类称为…...

如何用LinkSwift解锁九大网盘下载新姿势?完整攻略揭秘
如何用LinkSwift解锁九大网盘下载新姿势?完整攻略揭秘 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...
Translumo终极指南:5步掌握实时屏幕翻译与OCR识别技术
Translumo终极指南:5步掌握实时屏幕翻译与OCR识别技术 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾…...

终极MifareOneTool使用指南:零基础玩转MIFARE经典卡的Windows图形化神器
终极MifareOneTool使用指南:零基础玩转MIFARE经典卡的Windows图形化神器 【免费下载链接】MifareOneTool A GUI Mifare Classic tool on Windows(停工/最新版v1.7.0) 项目地址: https://gitcode.com/gh_mirrors/mi/MifareOneTool 想要…...

ncmdump终极解决方案:解锁网易云音乐NCM格式的完整指南
ncmdump终极解决方案:解锁网易云音乐NCM格式的完整指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密文件无法在其他设备播放而烦恼吗?ncmdump工具使用为你提供了完美的NCM格…...

Win10下VSCode与OpenCV环境搭建:从零到一的避坑指南
1. 环境准备:安装必要工具链 在Windows 10上搭建OpenCV开发环境,首先需要准备好三个核心工具:MinGW、CMake和VSCode。这三个工具就像盖房子需要的钢筋、水泥和施工图纸,缺一不可。 MinGW是Windows下的GNU工具集,相当…...

从stakpak/paks看现代软件包管理:不可变、声明式与分层架构实践
1. 项目概述:从“stakpak/paks”看现代软件包管理的演进最近在折腾一个老项目的依赖管理,又被各种版本冲突和依赖地狱搞得焦头烂额。这让我想起了几年前第一次接触stakpak/paks这个项目时的情景。当时,它更像是一个前沿的探索,试图…...

ARM Cortex-A9 MPCore多核处理器架构与优化实践
1. ARM Cortex-A9 MPCore硬件架构概述ARM Cortex-A9 MPCore是一款广泛应用于嵌入式系统的高性能多核处理器。作为ARMv7-A架构的代表性产品,它在工业控制、汽车电子和消费电子等领域有着广泛应用。这款处理器最显著的特点是支持1-4个核心的对称多处理(SMP)配置&#…...

本事同根生,相煎何太急
简 介: 【轮腿组比赛难度调整建议】针对智能车竞赛轮腿穿越组室外赛道的视觉识别难题,参赛选手提出以下建议:1.科目三元素应避开塑胶跑道线干扰区域;2.当前轮腿组任务量(机械、控制、导航、视觉等)已远超往…...

超声波,毫米波,激光雷达
一、技术原理与核心特性 1.超声波传感器 (1)原理:利用20kHz以上机械波的反射时间差(ToF)测距,典型工作频率40-58kHz。 (2)核心特性: 非接触式测量࿰…...

从限速到全速:ctfileGet如何彻底改变城通网盘下载体验
从限速到全速:ctfileGet如何彻底改变城通网盘下载体验 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 清晨的阳光透过窗户洒在设计师小李的电脑屏幕上,他正焦急地等待着一个500M…...