JAVA进阶 —— Steam流
目录
一、 引言
二、 Stream流概述
三、Stream流的使用步骤
1. 获取Stream流
1.1 单列集合
1.2 双列集合
1.3 数组
1.4 零散数据
2. Stream流的中间方法
3. Stream流的终结方法
四、 练习
1. 数据过滤
2. 数据操作 - 按年龄筛选
3. 数据操作 - 演员信息要求筛选
一、 引言
初识Stream流的作用:
需求:按照下面的要求完成集合的创建和遍历,创建一个集合,存储多个字符串元素
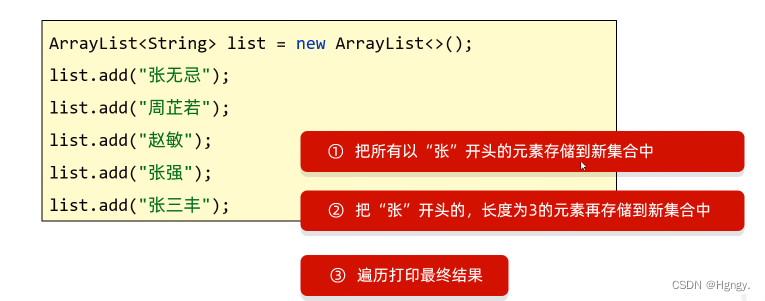
通过下面代码,显然我们清晰的看到使用Stream流更为方便,而使用不同的集合遍历就有些复杂。
public class Test01 {public static void main(String[] args) {ArrayList<String> list1 = new ArrayList<>();list1.add("张无忌");list1.add("周正若");list1.add("赵斌");list1.add("张强");list1.add("张三丰");// Stream流list1.stream().filter(name -> name.startsWith("张")).filter(name -> name.length() == 3).forEach(name -> System.out.println(name));// 张无忌// 张三丰// 1.把所有“张”姓开头元素存储到新集合ArrayList<String> list2 = new ArrayList<>();for (String name : list1) {if (name.startsWith("张")) {list2.add(name);}}System.out.println(list2); // [张无忌, 张强, 张三丰]// 2.把所有“张”姓开头且长度为3的元素存储到新集合ArrayList<String> list3 = new ArrayList<>();for (String name : list2) {if (name.length() == 3) {list3.add(name);}}System.out.println(list3); // [张无忌, 张三丰]}
}
二、 Stream流概述
例如上面的小例子,Stream流的思想如下:
 |  |  |  |
| 顺序筛选 |  | ||
Stream流的作用:
结合了Lambda表达式,简化集合、数字的操作。
三、Stream流的使用步骤
- 先得到一条Stream流(流水线),并把数据放上去。
- 使用中间方法对流水线上的数据进行操作。
- 使用终结方法对流水线上的数据进行操作。
过滤、转换 中间方法 方法调用完毕之后,还可以调用其他方法 统计、打印 终结方法 最后一步,调用完毕之后,不能调用其他方法
1. 获取Stream流
| 获取方式 | 方法名 | 说明 |
| 单列集合 | default Stream<E> stream() | Collection中的默认方法 |
| 双列集合 | 无 | 无法直接使用stream流,需要通过keySet()或者entrySet()变成单列集合 |
| 数组 | public static <T> Stream <T> stream(T [ ] array) | Arrays工具类中的静态方法 |
| 一堆零散数据 | public static <T> Stream <T> of(T... values) | stream接口中的静态方法 |
1.1 单列集合
public class StreamTest {public static void main(String[] args) {//单列集合获取Stream流ArrayList<String> list = new ArrayList<>();Collections.addAll(list, "a","b","c","d","e");//获取到一个流水线,并把集合中的数据方法流水线上//Stream<String> stream1 = list.stream();//使用终结方法打印流水线上数据//stream1.forEach( s ->System.out.println(s) );list.stream().forEach(s -> System.out.println(s));}
}1.2 双列集合
public class StreamTest {public static void main(String[] args) {//双列集合获取Stream流 //1. 创建双列集合HashMap<String, Integer> hm = new HashMap<>();//2. 添加数据hm.put("aaa", 111);hm.put("bbb", 222);hm.put("ccc", 333);//3.1 获取Stream流方法一: keySet()//键hm.keySet().stream().forEach(s -> System.out.println(s));//3.2 获取Stream流方法二:entrySet()//键值对hm.entrySet().stream().forEach(s -> System.out.println(s)); }
}
1.3 数组
Stream接口中静态方法of的细节:
- 方法的形参是一个可变参数,可以传递一堆零散数据,也可以传递数组。
- 但是数组必须是引用数据类型。
- 如果传递的是基本数据类型,是会把整个数组相当做一个元素,放到一个stream流当中。
public class StreamTest {public static void main(String[] args) {//数组获取Stream流 //1.创建基本数据类型数组int[] arr1 = {1,2,3,4,5,6,7,8,9,10};//获取streamArrays.stream(arr1).forEach(s -> System.out.println(s));//2.创建引用数据类型数组String[] arr2 = {"a","b","c"};//获取streamArrays.stream(arr2).forEach(s -> System.out.println(s));//方式是错误的!!!//Stream接口中静态方法of的细节//方法的形参是一个可变参数,可以传递一堆零散数据,也可以传递数组//但是数组必须是引用数据类型//如果传递的是基本数据类型,是会把整个数组相当做一个元素,放到一个stream流当中Stream.of(arr2).forEach(s -> System.out.println(s));Stream.of(arr1).forEach(s -> System.out.println(s)); //[I@1b28cdfa}
}1.4 零散数据
细节: 一堆零散数据需要是相同的数据类型。
public class StreamTest {public static void main(String[] args) {//零散数据获取Stream流 //基本数据类型Stream.of(1,2,3,4,5).forEach(s -> System.out.println(s));//引用数据类型Stream.of("a","b","c","d","e").forEach(s -> System.out.println(s));}
}2. Stream流的中间方法
| 方法名称 | 说明 |
| Stream<T> filter ( Predicate<? super T> predicate ) | 过滤 |
| Stream<T> limit ( long maxSize) | 获取前几个元素 |
| Stream<T> skip ( long n ) | 跳过前几个元素 |
| Stream<T> distinct ( ) | 元素去重,依赖(hashCode和equals方法) |
| static <T> Stream<T> concat ( Stream a , Stream b ) | 合并a和b两个流为一个流 |
| Stream<R> map ( Function<T ,R> mapper ) | 转换流中的数据类型 |
注意一:中间方法,返回新的Stream流,原来的Stream流只能使用一次,建议使用链式编程。
注意二:修改Stream流中的数据,不会影响原来集合或者数组中的数据。
public class StreamTest01 {public static void main(String[] args) {//1.过滤:把开头的留下,其余数据过滤不要ArrayList<String> list = new ArrayList<>();Collections.addAll(list, "张三","李四","王五","赵六","张七");ArrayList<String> list2 = new ArrayList<>();Collections.addAll(list2, "张三","李四","王五","赵六","张三");ArrayList<String> list3 = new ArrayList<>();Collections.addAll(list3, "孙七","钱八");ArrayList<String> list4 = new ArrayList<>();Collections.addAll(list2, "张三-23","李四-24","王五-25");list.stream().filter(new Predicate<String>() {//匿名内部类太麻烦 需要缩写@Overridepublic boolean test(String s) {//如果返回值为true,表示当前数据留下//如果返回值为false,表示当前数据舍弃return s.startsWith("张");}}).forEach(s -> System.out.println(s)); //张三 张七list.stream().filter(s -> s.startsWith("张")).forEach(s -> System.out.println(s));//2. 获取前几个元素 list.stream().limit(3).forEach(s -> System.out.println(s)); //张三 李四 王五//3. 跳过list.stream().skip(4).forEach(s -> System.out.println(s)); //张七//4.去重list2.stream().distinct().forEach(s -> System.out.println(s)); //张三 李四 王五 赵六//5. 合并Stream.concat(list2.stream(), list3.stream()).forEach(s -> System.out.println(s));//6.转换数据类型//只能获取集合里面的年龄并打印//第一个类型:流中原本的数据类型//第二个类型:将要转变成为的数据类型list4.stream().map(new Function<String,Integer>() {@Override//apply: 依次表示流中的每一盒数据//返回值:表示转化之前的数据public Integer apply(String s) {String[] arr = s.split("-");String ageString = arr[1];int age = Integer.parseInt(ageString);return age;}}).forEach(s -> System.out.println(s));list.stream().map(s ->Integer.parseInt(s.split("-")[1])).forEach(s -> System.out.println(s));}
}3. Stream流的终结方法
| 方法名称 | 说明 |
| void forEach ( Consumer action ) | 遍历 |
| long count ( ) | 统计 |
| toArray ( ) | 收集流中的数据,放到数组中 |
| collect ( Collector collector ) | 收集流中的数据,放到集合中 |
public class StreamTest02 {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();Collections.addAll(list, "张三", "李四", "王五", "赵六");// 遍历// Consumer的泛型:表示流中的数据类型// accept方法的形参s:依次表示流中的每一个数据//list.stream().forEach(new Consumer<String>() {@Overridepublic void accept(String s) {System.out.println(s);}});list.stream().forEach(s -> System.out.println(s)); // 张三 李四 王五 赵六// 统计long count = list.stream().count();System.out.println(count); // 4// 收集数据放进数组Object[] arr1 = list.stream().toArray();System.out.println(Arrays.toString(arr1)); // [张三, 李四, 王五, 赵六]// 指定数据类型// Infunction的泛型:具体类型的数组// apply中形参:流中数据的个数,要跟数组长度一致// apply的返回值:具体类型的数组String[] arr2 = list.stream().toArray(new IntFunction<String[]>() {@Overridepublic String[] apply(int value) {return new String[value];}});// toArray方法中的参数:只是创建一个指定类型的数组// toArray底层: 会此意得到流中的每一个数据,并把数据放到数组中// toArray的返回值:是一个装着流里面所有数据的数组System.out.println(Arrays.toString(arr2));// lambda表达式String[] arr3 = list.stream().toArray(value -> new String[value]);System.out.println(Arrays.toString(arr3));}
}collect方法:
public class StreamTest {public static void main(String[] args) {ArrayList<String> list = new ArrayList<>();Collections.addAll(list, "张三-男-23", "李四-男-24", "王五-男-25", "赵六-女-27", "孙八-女-28");//收集到List集合当中//需求://将所有的男性收集起来List<String> newList = list.stream().filter(s-> "男".equals(s.split("-")[1])).collect(Collectors.toList());System.out.println(newList); //[张三-男-23, 李四-男-24, 王五-男-25]//收集到Set集合当中Set<String> newSet = list.stream().filter(s-> "男".equals(s.split("-")[1])).collect(Collectors.toSet());System.out.println(newSet);//收集到Map集合当中//键: 姓名 值: 年龄//toMap://参数一表示键的生成规则 参数二表示值得生成规则//参数一: //Function泛型一:表示流中每一个数据的类型 ;// 泛型二:表示Map集合中键的数据类型//方法apply 形参:一次表示流里面的每一个数据// 方法体:生成键的代码 // 返回值:已生成的键//参数二://Function泛型一:表示流中每一个数据的类型 ;// 泛型二:表示Map集合中值的数据类型//方法apply 形参:一次表示流里面的每一个数据// 方法体:生成值的代码 // 返回值:已生成的值Map<String, Integer> newMap = list.stream().filter(s-> "男".equals(s.split("-")[1])).collect(Collectors.toMap(new Function<String, String>() {@Overridepublic String apply(String s) {return s.split("-")[0];}}, new Function<String, Integer >() {@Overridepublic Integer apply(String s) {return Integer.parseInt(s.split("-")[2]);}}));System.out.println(newMap); //{李四=24, 张三=23, 王五=25}//lambda表达式Map<String, Integer> newMap1 = list.stream().filter(s-> "男".equals(s.split("-")[1])).collect(Collectors.toMap( s-> s.split("-")[0], s-> Integer.parseInt(s.split("-")[2])));System.out.println(newMap1);}
}四、 练习
1. 数据过滤
需求:
定义一个集合,并添加一些整数1,2,3,4,5,6,7,8,9,10
过滤奇数,只留下偶数。
并将结果保存起来
public class StreamDemo {public static void main(String[] args) {// 1.定义一个集合ArrayList<Integer> list = new ArrayList<>();// 2.添加数据Collections.addAll(list, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 3.过滤奇数,只留偶数// 进行判断,如果是偶数,返回trueList<Integer> list2 = list.stream().filter(n -> n % 2 == 0).collect(Collectors.toList());System.out.println(list2); //[2, 4, 6, 8, 10]}
}2. 数据操作 - 按年龄筛选
需求:
创建一个ArrayList集合,并添加以下字符串,字符串中前面是姓名,后面是年龄“zhangsan,23”
“lisi,24"
“wangwu,25”
保留年龄大于等于24岁的人,并将结果收集到Map集合中,姓名为键,年龄为值
public class StreamDemo {public static void main(String[] args) {// 1.定义一个集合ArrayList<String> list = new ArrayList<>();//2.集合添加字符串list.add( "zhangsan,23");list.add("lisi,24");list.add("wangwu,25");//3.保留年龄大于24岁的人Map<String, Integer> map = list.stream().filter(s -> Integer.parseInt(s.split(",")[1]) >= 24).collect(Collectors.toMap(s -> s.split(",")[0], s -> Integer.parseInt(s.split(",")[1])));System.out.println(map); //{lisi=24, wangwu=25}}
}3. 数据操作 - 演员信息要求筛选
现在有两个ArrayList集合,
第一个集合中:存储6名男演员的名字和年龄。第二个集合中:存储6名女演员的名字和年龄。姓名和年龄中间用逗号隔开。比如:张三,23
要求完成如下的操作:
- 男演员只要名字为3个字的前两人
- 女演员只要姓杨的,并且不要第一个
- 把过滤后的男演员姓名和女演员姓名合并到一起
- 将上一步的演员信息封装成Actor对象。
- 将所有的演员对象都保存到List集合中。
备注:演员类Actor,属性有:name,age
public class StreamDemo {public static void main(String[] args) {// 1.定义两个集合ArrayList<String> manList = new ArrayList<>();ArrayList<String> womenList = new ArrayList<>();// 2.添加数据Collections.addAll(manList, "蔡坤坤,24", "叶购成,23", "刘不甜,22", "吴签,24", "谷嘉,30", "肖梁梁,27");Collections.addAll(womenList, "赵小颖,35", "杨颖,36", "高元元,43", "张天天,31", "刘诗,35", "杨小幂,33");// 3. 男演员只要名字为3个字的前两个人Stream<String> stream1 = manList.stream().filter(s -> s.split(",")[0].length() == 3).limit(2);
// .forEach(s -> System.out.println(s)); // 蔡坤坤,24 叶购成,23// 叶购成,23//4.女演员只要姓杨的 并且不要第一个Stream<String> stream2 = womenList.stream().filter(s -> s.split(",")[0].startsWith("杨")).skip(1);
// .forEach(s -> System.out.println(s)); //杨小幂,33//5.把过滤的男演员和女演员信息合并在一起//演员信息封装进Actor对象//String -> Actor对象(类型转换)List<Actor> list = Stream.concat(stream1, stream2).map(s -> new Actor(s.split(",")[0],Integer.parseInt(s.split(",")[1]))).collect(Collectors.toList());System.out.println(list);}
}相关文章:
JAVA进阶 —— Steam流
目录 一、 引言 二、 Stream流概述 三、Stream流的使用步骤 1. 获取Stream流 1.1 单列集合 1.2 双列集合 1.3 数组 1.4 零散数据 2. Stream流的中间方法 3. Stream流的终结方法 四、 练习 1. 数据过滤 2. 数据操作 - 按年龄筛选 3. 数据操作 - 演员信息要求…...

Ubuntu Protobuf 安装(测试有效)
安装流程 下载软件 下载自己要安装的版本:https://github.com/protocolbuffers/protobuf 下载源码编译: 系统环境:Ubuntu16(其它版本亦可),Protobuf-3.6.1 编译源码 cd protobuf# 当使用 git clone 下来的…...

驱动程序开发:FTP服务器和OpenSSH的移植与搭建、以及一些笔记
目录一、FTP服务器移植与搭建1、在ubuntu下安装vsftpd2、在window下安装FileZilla3、移植vsftpd到开发板上4、Filezilla 连接测试5、注意点二、开发板 OpenSSH 移植与使用1、移植 zlib 库2、移植 openssl 库3、移植 openssh 库4、openssh 使用测试三、关于u-boot上的操作及根文…...
优化改进YOLOv5算法之添加GIoU、DIoU、CIoU、EIoU、Wise-IoU模块(超详细)
目录 1、IoU 1.1 什么是IOU 1.2 IOU代码 2、GIOU 2.1 为什么提出GIOU 2.2 GIoU代码 3 DIoU 3.1 为什么提出DIOU 3.2 DIOU代码 4 CIOU 4.1 为什么提出CIOU 4.2 CIOU代码 5 EIOU 5.1 为什么提出EIOU 5.2 EIOU代码 6 Wise-IoU 7 YOLOv5中添加GIoU、DIoU、CIoU、…...
windows电脑pc如何使用svn获取文档和代码
一、安装svn 下载链接 也可通过其他方式下载 二、使用 2.1 随便找一个文件夹 2.2 点击右键,选择SVN Checkout 2.3输入网址 如当你在网页上访问时地址为https://10.197.78.78/!/#aaa/view/head/bbb 在这里不能直接填入,而是 https://10.197.78.78/sv…...

ROS1学习笔记:tf坐标系广播与监听的编程实现(ubuntu20.04)
参考B站古月居ROS入门21讲:tf坐标系广播与监听的编程实现 基于VMware Ubuntu 20.04 Noetic版本的环境 文章目录一、创建功能包二、创建代码2.1 以C为例2.1.1 配置代码编译规则2.1.2 编译整个工作空间2.1.2 配置环境变量2.1.4 执行代码2.2 以Python为例2.2.1 配置代码…...

力扣解法汇总1590. 使数组和能被 P 整除
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接:力扣 描述: 给你一个正整数数组 nums,请你移除 最短 子数组(可以为 …...
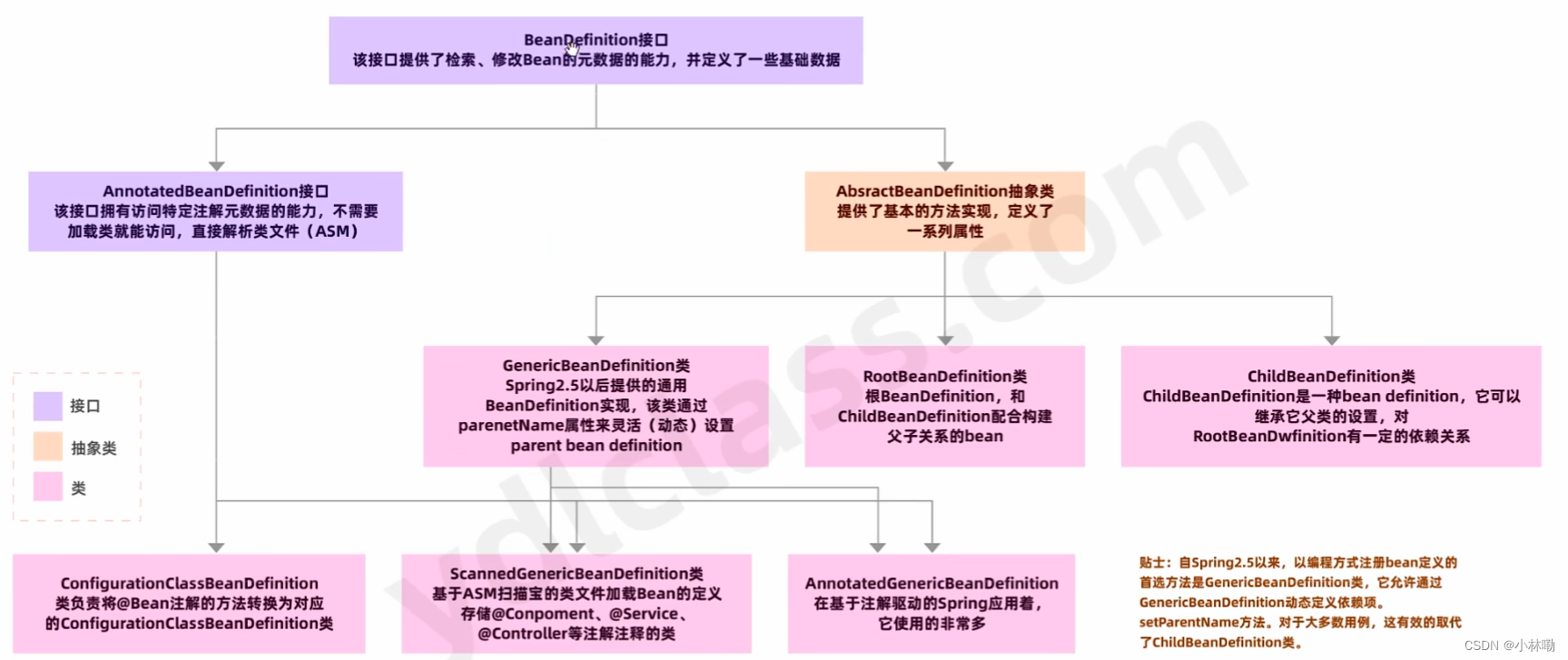
Spring源码阅读(基础)
第一章:bean的元数据 1.bean的注入方式: 1.1 xml文件 1.2 注解 Component(自己写的类才能在上面加这些注解) 1.3配置类: Configuration 注入第三方数据源之类 1.4 import注解 (引用了Myselector类下…...

服务搭建篇(九) 使用GitLab+Jenkins搭建CI\CD执行环境 (上) 基础环境搭建
1.前言 每当我们程序员开发在本地完成开发之后 , 都要部署到正式环境去使用 , 在一些传统的运维体系中 , 开发与运维都是割裂的 , 开发人员不允许操作正式服务器 , 服务器只能通过运维团队来操作 , 这样可以极大的提高服务器的安全性 , 不经过安全保护的开放服务器 , 对于黑客…...

CDC 长沙站丨云原生技术研讨会:数字兴链,云化未来!
一、活动信息:活动主题:CDC 长沙站丨云原生技术研讨会活动时间:2023 年 3 月 14 日下午 14:30-17:30活动地点:长沙市岳麓区-拓维信息总部 1 楼多功能厅活动参与方式:免门票参与,戳此…...
)
A.特定领域知识图谱知识推理方案:知识图谱推理算法综述[二](DTransE/PairRE:基于表示学习的知识图谱链接预测算法)
推荐参考文章: A.特定领域知识图谱知识推理方案:知识图谱推理算法综述[一](基于距离的翻译模型:TransE、TransH、TransR、TransH、TransA、RotatE) A.特定领域知识图谱知识推理方案:知识图谱推理算法综述[二](DTransE/PairRE:基于表示学习的知识图谱链接预测算法) A.…...
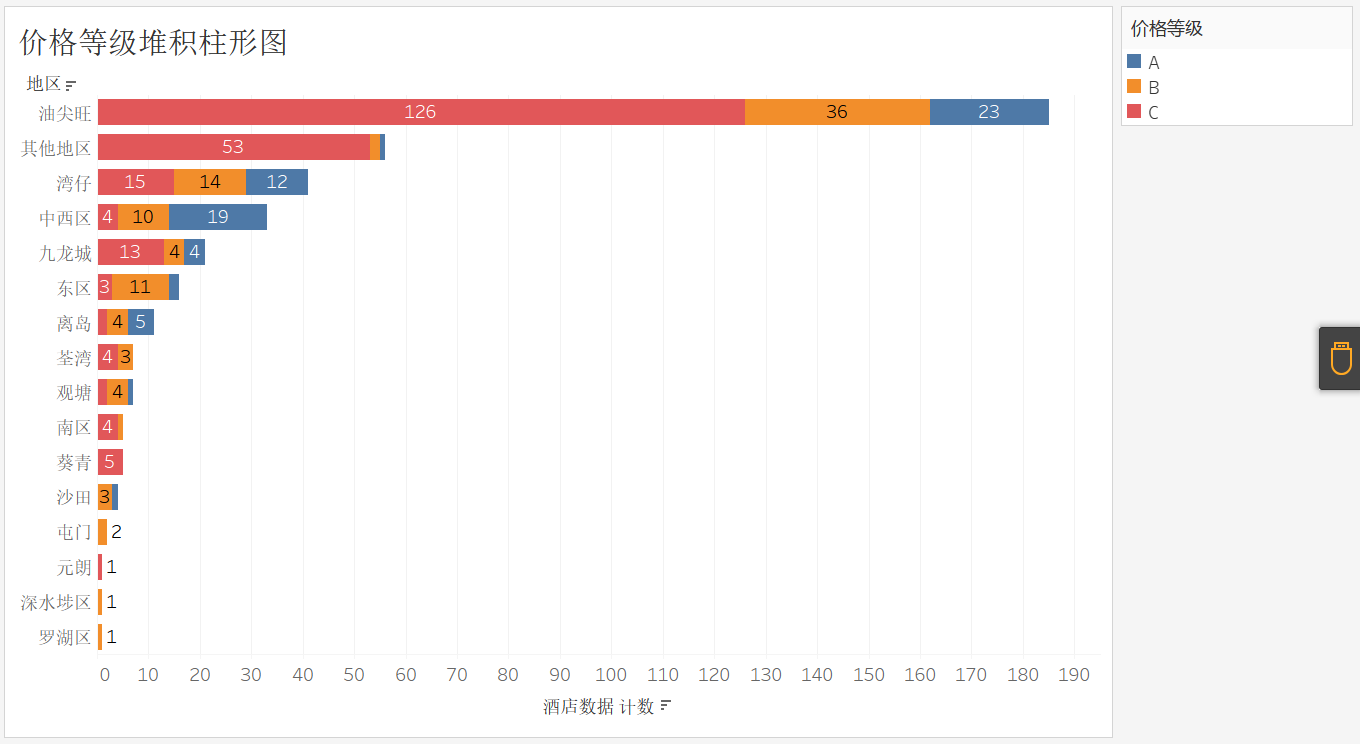
香港酒店模拟分析项目报告--使用tableau、python、matlab
转载请标记本文出处 软件:tableau、pycharm、关系型数据库:MySQL 数据大量分析考虑电脑性能的情况。 文章目录前言一、爬虫是什么?二、使用tableau数据可视化1.引入数据1.1 制作直方图-各地区酒店数量条形图1.2 各地区酒店均价1.3 价格等级堆…...

第18天-商城业务(商品检索服务,基于Elastic Search完成商品检索)
1.构建商品检索页面 1.1.引入依赖 <!-- thymeleaf模板引擎 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency><!-- 热更新 --><…...
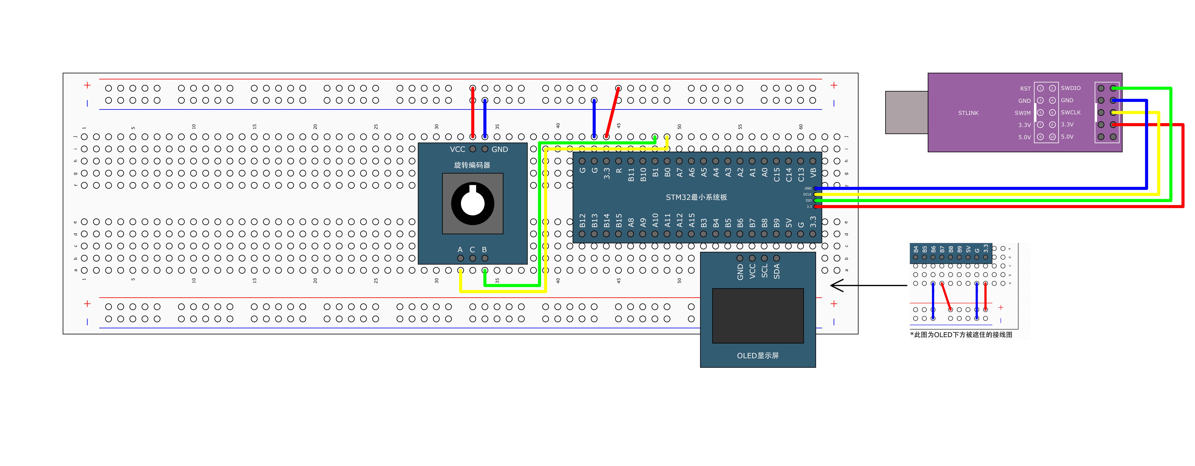
5.2 对射式红外传感器旋转编码器计次
对射式红外传感器1.1 接线图VCC GND分别接电源的正负极DO数字输出端,随意选择一个GPIO口1.2 硬件原理当挡光片或者编码盘在对射式红外传感器中间经过时,DO就会输出电平变化信号,电平跳变信号触发STM32 PB14号口中断,在中断函数中执…...

【数据库概论】第九章 关系查询处理和查询优化
第九章 关系查询处理和查询优化 本章主要介绍关系数据库查询管理和查询优化,主要分为代数优化(又称逻辑优化)和物理优化(也称非代数优化)。 9.1 关系型数据库系统的查询处理 查询处理是关系型数据库管理系统执行查询…...
 my cloud test bed (by quqi99))
(WIP) my cloud test bed (by quqi99)
作者:张华 发表于:2023-03-10 版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明 问题 想创建一个local local test bed, 用来方便做各种云实验,如openstack, k8s, ovn, lxd等…...

git | git 2023 详细版
文章目录一、Git命令1.2 设计用户签名1.3 初始化本地库1.4 查看本地库状态1.5 添加至暂存区1.6 从暂存区删除1.7 将暂存区的文件提交到本地库1.8 查看版本信息二、Git分支2.1 查看分支2.2 创建分支2.3 切换分支2.4 合并分支三、GitHub3.1 代码克隆clone3.2 给库取别名3.3 推送本…...

camunda流程引擎基本使用(笔记)
文章目录一、camunda基础1.1 安装与部署流程引擎1.2 流程引擎结构1.3 流程引擎的基本使用1.3.1 创建一个BPMN Diagram1.3.2 实现一个外部工作者1.3.3 部署流程1.3.4 创建一个流程实例并消费1.3.5 向流程中添加用户任务1.3.6 添加网关1.3.7 业务规则二、Java 集成流程引擎2.1 为…...

JS之数据结构与算法
前言数据结构是计算机存储、组织数据的方式,算法是系统描述解决问题的策略。了解基本的数据结构和算法可以提高代码的性能和质量。也是程序猿进阶的一个重要技能。手撸代码实现栈,队列,链表,字典,二叉树,动态规划和贪心算法1.数据结构篇1.1 栈栈的特点:先进后出clas…...
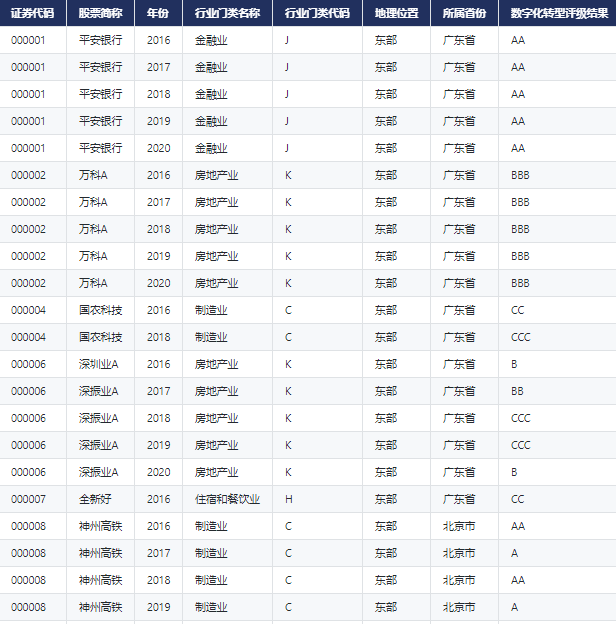
CnOpenData·A股上市企业数字化转型指数数据
一、数据简介 企业数字化转型是近年来中国社会各界重点关注的领域,但基础数据的不完善在很大程度上制约了相关科学研究的开展。构建合理、科学的数字化转型指标体系有利于学者定量地研究企业数字化的相关问题,也有利于衡量企业的数字化水平。广东金融学院…...

为你的Hermes Agent项目配置Taotoken作为自定义模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent项目配置Taotoken作为自定义模型提供商 应用场景类,假设你正在使用Hermes Agent框架并希望接入更多…...
)
【电脑自动化助手】 OpenClaw 一键部署教程(包含安装包)
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟养出你的数字员工 2026 年备受关注的开源 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标超 28 万,凭借本地运行 零代码 自动执行任务的特点收获大量…...

用C++模拟堆宝塔游戏:PTA L2-045题解与保姆级代码逐行解析
用C模拟堆宝塔游戏:PTA L2-045题解与保姆级代码逐行解析 堆宝塔游戏是一个有趣的逻辑挑战,它不仅能锻炼编程思维,还能帮助我们深入理解数据结构中的栈操作。本文将带你从零开始,用C实现这个游戏,并逐行解析代码逻辑&a…...

国产多模态大模型:产业协同全景与实战指南
国产多模态大模型:产业协同全景与实战指南 引言 在人工智能浪潮席卷全球的背景下,国产多模态大模型正从技术探索迈向广泛的产业协同应用。与只能处理文本或图像的单一模态模型相比,多模态大模型能同时理解、关联和生成文本、图像、音频、视频…...

服务器训练过程程序崩溃,显卡资源释放方式
使用服务器训练过程出现程序崩溃,但是显卡资源未能释放的问题解决方式,主要是多卡使用过程,不能影响其他人正在使用的显卡资源。一、查看显卡使用情况 查看显卡正在使用的进程 watch nvidia-smi| NVIDIA-SMI 580.126.09 Driver V…...

别再乱用nn.Flatten了!详解start_dim与end_dim参数,避坑数据维度混淆
深度解析PyTorch中的nn.Flatten:从参数误区到实战应用 在深度学习模型的构建过程中,数据维度的处理往往成为许多开发者容易忽视却又至关重要的环节。特别是当我们需要将卷积层的输出传递给全连接层时,nn.Flatten操作几乎成为了标准配置。然而…...
)
【自用】Kicad 导入嘉立创元器件封装(NLBN插件)
总览 1.安装插件 2.下载元件封装 3.配置 Kicad 4.效果演示 零、特别鸣谢 感谢插件提供者:linkyourbin UP主教学视频:https://www.bilibili.com/video/BV1W6AXz2EfR/?spm_id_from333.337.search-card.all.click&vd_source38d6ea3466db371e6c07c24…...

QML数据驱动UI:从ListModel与ListElement入门到实战
1. 为什么需要数据驱动UI? 第一次接触QML开发时,我习惯直接在UI组件里写死数据。比如要显示一个水果列表,可能会这样写: Column {Text { text: "Apple - $2.45" }Text { text: "Orange - $3.25" }Text { text…...

C51开发中汇编指令定位与内存优化实战
1. 理解C51开发中的汇编指令定位问题在嵌入式开发领域,尤其是使用Keil C51这类经典工具链时,我们经常需要深入理解编译器如何将高级语言转换为机器指令。最近我在调试一个8051项目时,遇到了一个典型问题:如何准确确定C源代码对应的…...

NotebookLM电影研究实战手册:3步构建专属电影知识图谱,效率提升300%
更多请点击: https://codechina.net 第一章:NotebookLM电影研究辅助 NotebookLM 是 Google 推出的基于 AI 的研究协作者,专为深度阅读、知识整合与批判性思考设计。在电影研究场景中,它能将剧本、影评、学术论文、导演访谈、历史…...