Python第二语言(十四、高阶基础)
目录
1. 闭包
1.1 使用闭包注意事项
1.2 小结
2. 装饰器:实际上也是一种闭包;
2.1 装饰器的写法(闭包写法) :基础写法,只是解释装饰器是怎么写的;
2.2 装饰器的语法糖写法:@函数注解 :可以说是,当前函数没有发生变动,但是功能增加了;
3. 什么是设计模式
4. 设计模式-单例模式
4.1 单例模式的作用
4.2 单例模式的实现
5. 设计模式-工厂模式:创建额外的工厂类,去获得想要的对象
5.1 工厂模式的使用
5.2 工厂模式的优点
6. 多线程:进程-线程概念
7. 多线程编程-threading 模块
7.1 threading 模块使用
7.2 参数传递args(tuple), kwargs(dict)
8. 网络编程:Socket服务端开发
8.1 Socket客户端和Socket服务端
8.2 Socket编程(客户端 & 服务端)
9. 正则表达式-基础方法
9.1 正则表达式概念
9.2 正则的三个基础方法
9.3 小结
10. 正则表达式-元字符匹配
10.1 元字符匹配
10.2 元字符匹配-数量匹配
10.3 元字符匹配-边界匹配-分组匹配
10.4 练习习题
10.4.1 案例:匹配账号,只能由字母和数字组成,长度限制6-10位
10.4.2 案例:匹配QQ号,要求纯数字,长度5-11,第一位不为0
10.4.3 案例:匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址
11. 递归算法
11.1 概念:即方法(函数)自己调用自己的一种特殊编程写法;
11.2 文件结构
11.3 os模块获取文件操作
11.3.1 读取文件夹中的内容
11.3.2 判断这个路径是否是文件夹
11.3.3 判断这个路径是否存在
11.4 递归
导航:
Python第二语言(一、Python start)-CSDN博客
Python第二语言(二、Python语言基础)-CSDN博客
Python第二语言(三、Python函数def)-CSDN博客
Python第二语言(四、Python数据容器)-CSDN博客
Python第二语言(五、Python文件相关操作)-CSDN博客
Python第二语言(六、Python异常)-CSDN博客
Python第二语言(七、Python模块)-CSDN博客
Python第二语言(八、Python包)-CSDN博客
Python第二语言(九、Python第一阶段实操)-CSDN博客
Python第二语言(十、Python面向对象(上))-CSDN博客
Python第二语言(十一、Python面向对象(下))-CSDN博客
Python第二语言(十二、SQL入门和实战)-CSDN博客
Python第二语言(十三、PySpark实战)-CSDN博客
Python第二语言(十四、高阶基础)-CSDN博客
1. 闭包
-
引言:
-
全局变量是可能被别的类import进行篡改的;存在风险;
-
- 序章:
- 在闭包中修改外部函数的值:需要使用
nonlocal关键字修饰外部函数的变量才可以在内部函数中修改它; - 闭包解决全局变量被篡改的可能性:
- 讲解:大致就是说,initial_amount 是外部全局变量传入,而内部def可以调用到initial_amount ,也可以用到num,最终account_create返回的是一个函数,函数是atm ,而
fn = account_create("xxx"),fn("xxx")实际代笔的是内部函数,实现闭包; - 实际上fn得到的是
retrun的atm函数; - fn就是返回的函数,一个函数,而这个函数就是atm,所以解释的通为什么fn输出的内容会是
存款:+xxx,账户余额:xxx,因为atm调用了initial_amount和num; initial_amount=0这相当于是个变量,在整个程序account_create(xxx)调用的过程中,他是一直有在更改的,但是可以看见在外界无法篡改到他,而是作为一个临时变量被atm函数使用;-
def account_create(initial_amount=0): # 函数嵌套def atm(num, deposit=True):nonlocal initial_amount # 内部函数使用外部函数变量if deposit:initial_amount += numprint(f"存款:+{num},账户余额:{initial_amount}")else:initial_amount -= numprint(f"取款:-{num},账户余额:{initial_amount}")return atm # 返回内部函数fn = account_create() fn(300) fn(300) fn(100, False)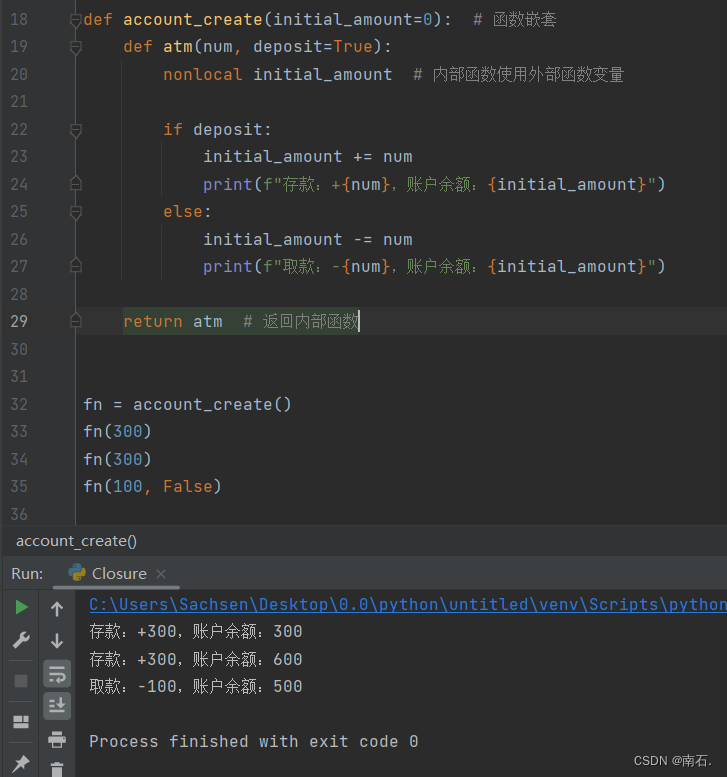
- 在闭包中修改外部函数的值:需要使用
1.1 使用闭包注意事项
-
优点:
无需定义全局变量即可实现通过函数,持续的访问、修改某个值;
闭包使用的变量的所用于在函数内,难以被错误的调用修改;
-
缺点:
由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间不被释放,一直占用内存;
1.2 小结
-
闭包:
定义双层嵌套函数内层函数可以访问外层函数的变量;
将内存函数作为外层函数的返回,此内层函数就是闭包函数;
-
闭包的好处和缺点:
优点:不定义全局变量,也可以让函数持续访问和修改一个外部变量;
优点:闭包函数引用的外部变量,是外层函数的内部变量。作用域封闭难以被误操作修改;
缺点:额外的内存占用(基本可以忽略不记);
-
nonlocal关键字的作用:
在闭包函数(内部函数中)想要修改外部函数的变量值需要用nonlocal声明这个外部变量;
2. 装饰器:实际上也是一种闭包;
- 装饰器概念:
- 装饰器具有装饰器语法糖,与Spring的AOP思想很像,在调用某个函数时增强函数功能;
- 装饰器其实也是一种闭包,其功能就是在不破坏目标函数原有的代码和功能的前提下,为目标函数增加新功能;
2.1 装饰器的写法(闭包写法) :基础写法,只是解释装饰器是怎么写的;
就是在使用闭包时,调用outer函数时传递了一个函数实参,实现装饰器sleep写法;
def outer(func): # 装饰器一般写法(闭包)def inner():print("睡觉")func()print("起床")return innerdef sleep():import randomimport timeprint("ZZZ...")h = random.randint(1, 5)time.sleep(h)print(f"睡了:{h}小时")fn = outer(sleep)
fn()
2.2 装饰器的语法糖写法:@函数注解 :可以说是,当前函数没有发生变动,但是功能增加了;
在代码中,@outer 这行代码就是在使用装饰器 outer。它的作用是把 sleep 函数作为参数传递给 outer 函数,并用 outer 函数返回的 inner 函数来替换 sleep 函数。使用 @ 符号,装饰器调用的方式非常简洁,等效于:
虽然调用的是sleep,但是,实际上调用是outer的inner;
sleep = outer(sleep) 这样,在调用 sleep() 时,实际上是在调用 outer 返回的 inner 函数。这个函数会先打印 “睡觉”,然后调用原始的 sleep 函数,最后再打印 “起床”。
def outer(func):def inner():print("睡觉")func()print("起床")return inner@outer
def sleep():import randomimport timeprint("ZZZ...")h = random.randint(1, 5)time.sleep(h)print(f"睡了:{h}小时")sleep()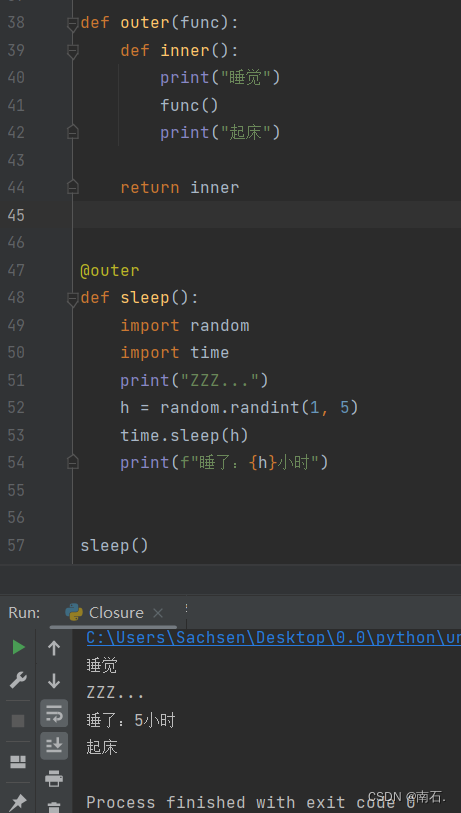
3. 什么是设计模式
- 设计模式是一种编程套路,可以极大的方便程序的开发;
- 最常见、最经典的设计模式,是面向对象设计模式;
- 除了面向对象外,在编程中也有很多既定的套路可以方便开发,我们称之为设计模式:单例、工厂模式、建造者、责任链、状态、备忘录、解释器、访问者、观察者、中介、模板、代理模式等...
4. 设计模式-单例模式
4.1 单例模式的作用
- 创建类的实例后,通常都会得到一个完整的、独立的类对象,但是在某些场景下,创建一个类,无论获取多少次类对象,都仅仅提供一个具体的实例,用以节省创建类对象的开销和内存开销;例如:工具类仅要1个实例,可以被用很多次;
4.2 单例模式的实现
- 保证类或方法函数,只有一个,保证单例的使用;
- 看到控制台,输出的对象地址是相同的,说明他们是同一个对象;
from str_tools import str_tools1 = str_tool()
s2 = str_tool()print(id(s1))
print(id(s2))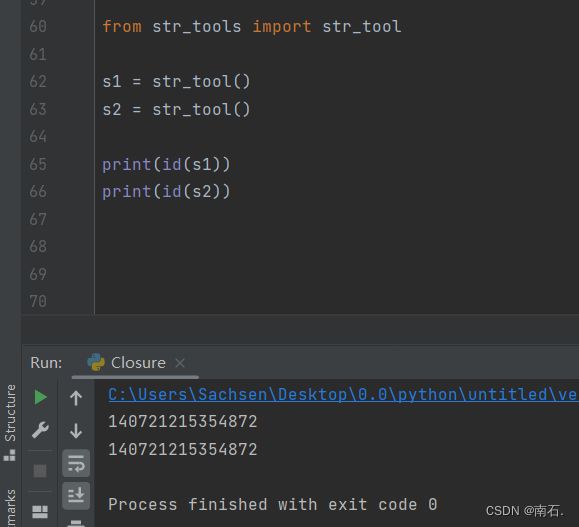
5. 设计模式-工厂模式:创建额外的工厂类,去获得想要的对象
5.1 工厂模式的使用
- 当大量创建一个类的实例时,可以使用工厂模式来帮我们获取到类对象;
- 与原始获取类的基础上多了一个工厂类,由原本的获取对象方式变成了通过工厂来获取到对象;
class Person:passclass Worker(Person):pass
class Student(Person):pass
class Teacher(Person):passclass Factory: # 工厂类def get_person(self, p_type):if p_type == 'w':return Worker()if p_type == 's':return Student()if p_type == 't':return Teacher()factory = Factory()
worker = factory.get_person('w')
student = factory.get_person('s')
teacher = factory.get_person('t')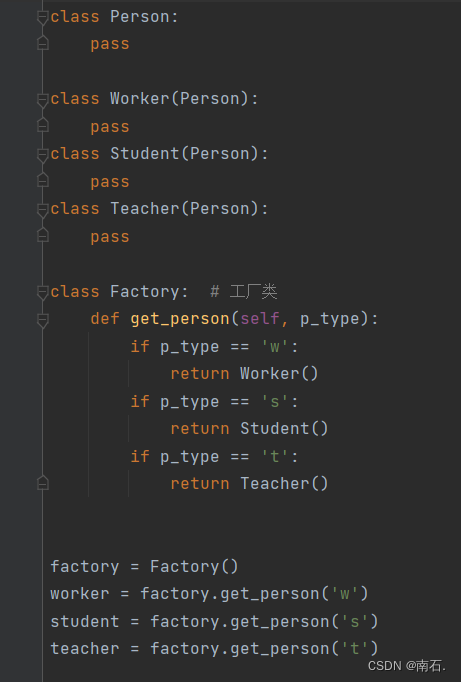
5.2 工厂模式的优点
- 大批量创建对象的时候有统一的入口,易于代码维护;
- 当发生修改,仅修改工厂类的创建方法即可;
- 符合现实世界的模式,即由工厂来制作产品对象;
6. 多线程:进程-线程概念
- 进程:就是一个程序,运行在系统之上。那么便称之为这个程序为一个运行进程,并分配进程ID方便系统管理;
- 线程:线程是归属于进程的,一个进程可以开启多个线程,执行不同的工作,是基进程的实际工作最小单位;
- 进程之间是内存隔离的,及不同的进程拥有各自的内存空间,这就类似于不同的公司拥有不同的办公场所;
- 线程之间是内存共享的,线程是属于进程的,一个进程内的多个线程之间是共享这个进程所拥有的内存空间的,这就好比,公司员工之间的共享公司的办公场所;
- 并行执行:在同一时间做不同的工作,进程之间并行执行,线程之间并行执行;
7. 多线程编程-threading 模块
7.1 threading 模块使用
thread_obj = threading.Thread(group=None, target=None, name=None, args=(), kwargs={})group=None: 预留参数,目前未使用,保留默认值。target=None: 要在线程中执行的目标函数,默认为None,需要提供一个可调用对象。args=(): 传递给目标函数的位置参数,默认为空元组。kwargs={}: 传递给目标函数的关键字参数,默认为空字典。name=None: 线程名称,默认为None,可以不设置,系统会自动生成。
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
group | None | None | 预留参数 |
target | callable | None | 要执行的函数 |
args | tuple | () | 位置参数 |
kwargs | dict | {} | 关键字参数 |
name | str | None | 线程名称 |
案例:
import threading
import time
from datetime import datetime
def sing():while True:print("唱歌,啦啦啦")time.sleep(1)print("唱歌停顿,1秒" + datetime.now().strftime("%H:%M:%S"))def dance():while True:print("跳舞,")time.sleep(1)print("跳舞停顿,1秒" + datetime.now().strftime("%H:%M:%S"))if __name__ == '__main__':sing_thread = threading.Thread(target=sing) # 创建唱歌任务线程dance_thread = threading.Thread(target=dance) # 创建跳舞任务线程sing_thread.start() # 唱歌线程开启dance_thread.start()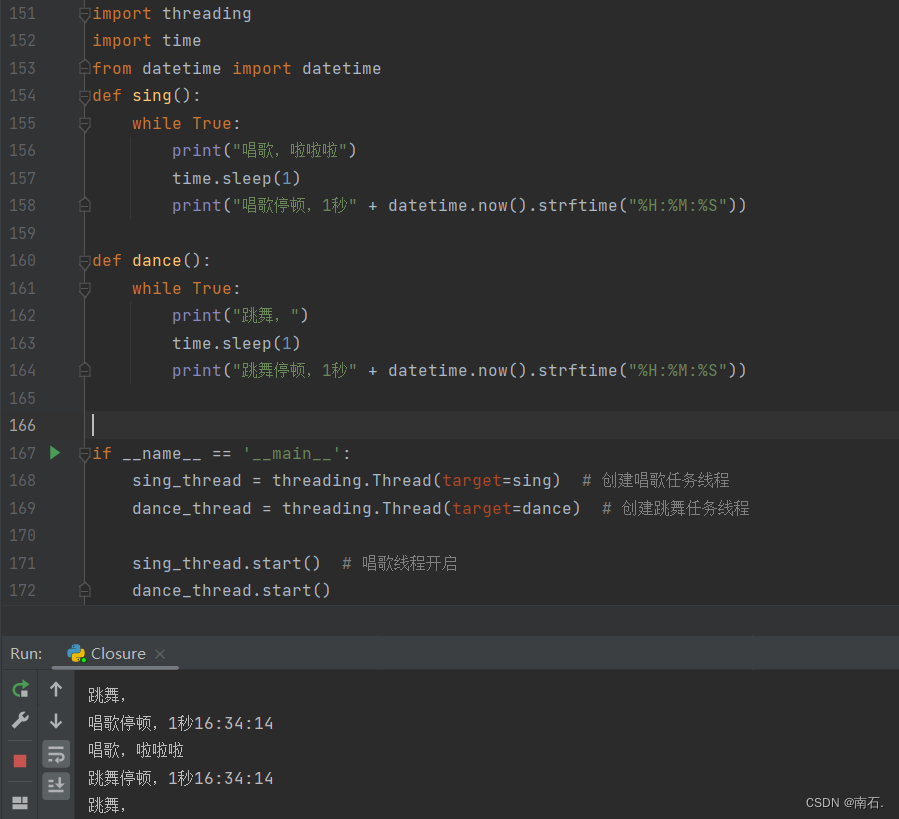
7.2 参数传递args(tuple), kwargs(dict)
import threading
import time
from datetime import datetimedef sing(money):while True:print(f"唱歌,啦啦啦,这首歌赚了:{money}元")time.sleep(1)print("唱歌停顿,1秒 " + datetime.now().strftime("%H:%M:%S"))def dance(msg):while True:print(f"跳舞,{msg}")time.sleep(1)print("跳舞停顿,1秒 " + datetime.now().strftime("%H:%M:%S"))if __name__ == '__main__':sing_thread = threading.Thread(target=sing, args=(20,)) # 创建唱歌任务线程, target=sing传递函数本身dance_thread = threading.Thread(target=dance, kwargs={"msg": "跳舞让我很开心"}) # 创建跳舞任务线程, target=dance传递函数本身sing_thread.start() # 唱歌线程开启dance_thread.start()sing_thread.join() # 等待唱歌线程结束dance_thread.join() # 等待跳舞线程结束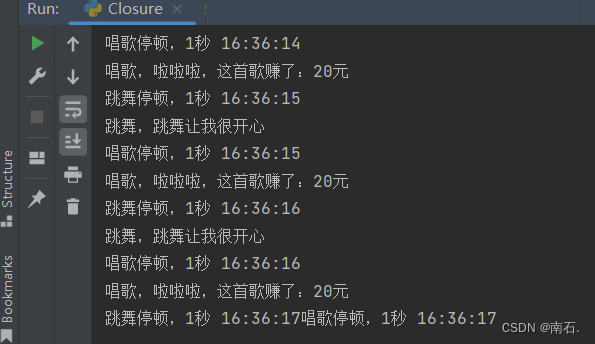
8. 网络编程:Socket服务端开发
- 概念:
- scoket(套接字)是进程之间网络通信的一个工具;
- 2个进程之间通过Socket进行相互通讯,就必须有服务端和客户端;
- Socket服务端:等待其他进程的连接、可接受发来的消息,可以回复消息;
- Socket客户端:主动连接服务端、可以发送消息、可以接受回复;
8.1 Socket客户端和Socket服务端
Socket服务端:等待其它进程的连接,可接收发来的消息,可以回复消息;
Socket客户端:主动连接服务端,可以发送消息,可以接收回复;
8.2 Socket编程(客户端 & 服务端)
server:
import socket # 1.导包socket_server = socket.socket()socket_server.bind(('localhost', 8888)) # 2.绑定socket_server到指定IP和地址socket_server.listen(1) # 3.服务端开始监听端口,设置接收连接的数量# 4.接收客户端连接,获得连接对象; 返回的是元组(连接对象,客户端地址信息); accept是阻塞,等待客户端连接
conn, address = socket_server.accept()
print(f"接收到客户端连接,连接来自:{address}")while True:# 5.客户端连接后,通过recv方法,接收客户端发送的消息; recv缓冲区大小; decode将bytes对象转成字符串data = conn.recv(1024).decode("UTF-8")if data == 'exit':breakprint("接收到发送的数据:", data)conn.send("你好".encode("UTF-8")) # 6.通过conn(客户端当次连接对象,调用send方法回复消息)conn.close() # 7.关闭连接
socket_server.close()client:
import socketsocket_client = socket.socket()# 连接到服务器
socket_client.connect(('localhost', 8888))# 发送消息
while True:message = input("请输入要发送的消息(输入 'exit' 结束): ")socket_client.send(message.encode("UTF-8"))if message == 'exit':breakdata = socket_client.recv(1024).decode("UTF-8")# 接收到服务器返回的消息print("接收到服务器的消息:", data)# 关闭连接
socket_client.close()
两个服务启动后:
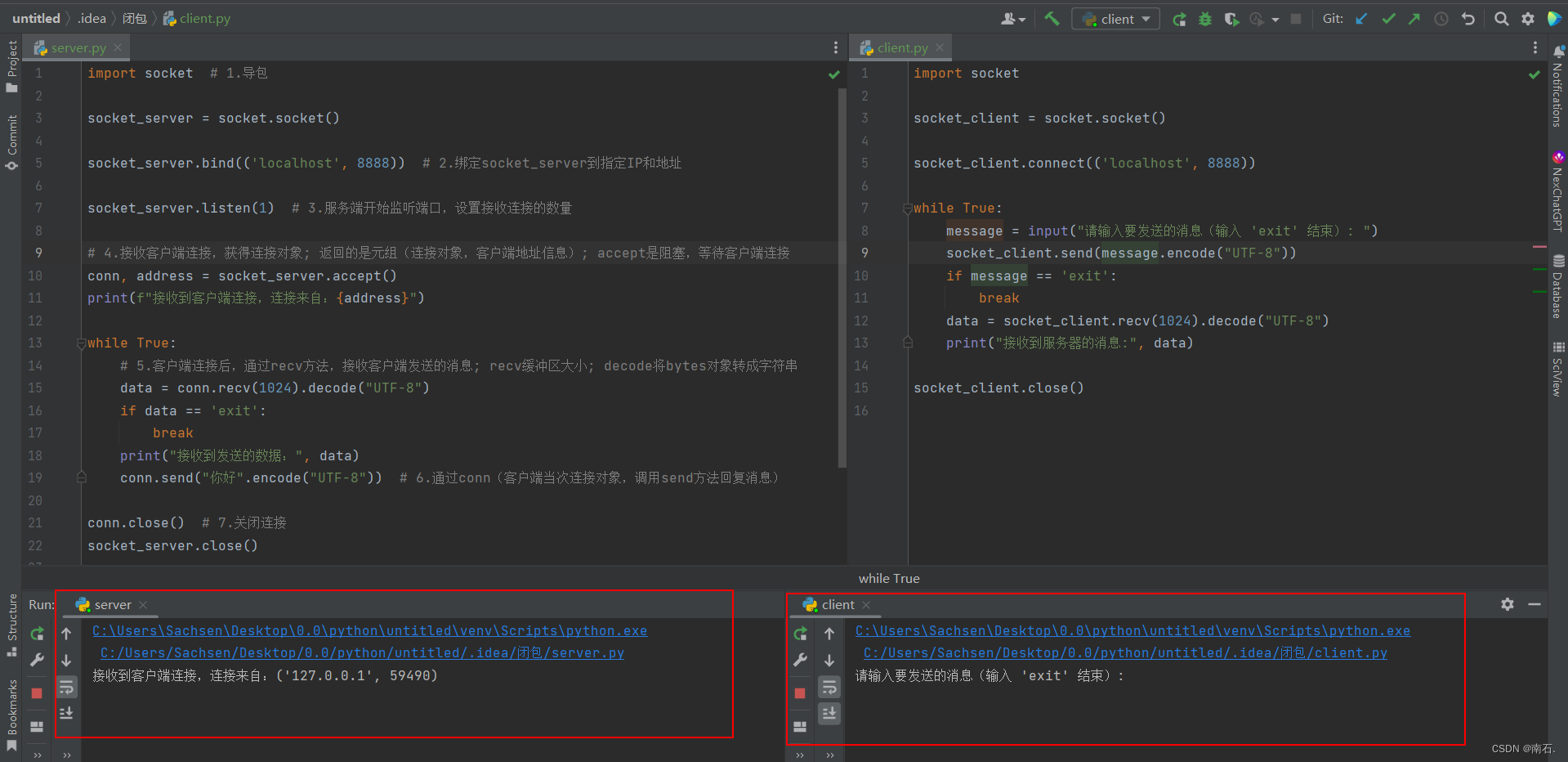


- 小结:服务端是被动的,客户端是主动的,服务端接受消息并回复,客户端发送消息,会并回复;
9. 正则表达式-基础方法
9.1 正则表达式概念
- 正则表达式,又称规则表达式(Regular Expression)是使用单个字符串来描述、匹配某个句法规则的字符串,常被用来检索、替换那些符合某个模式(规则)的文本;
- 正则表达式就是使用:字符串定义规则,并通过规则去验证字符串是否匹配;
- 比如,验证一个字符串是否是符合条件的电子邮箱地址,只需要配置好正则规则,即可匹配任意邮箱:
- 比如通过正则规则:
(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)即可匹配一个字符串是否是标准邮箱格式; - 但如果不使用正则,使用if else来对字符串做判断就非常困难了;
- 比如通过正则规则:
9.2 正则的三个基础方法
1. re.match('字符单词', 字符串变量):字符串匹配规则,从头匹配,只从头匹配一次符合条件的字符串;
import res = 'python zhangSan python nihao python wolai'result = re.match('python', s)print(result) # 显示匹配对象或者 None
print(result.span()) # 打印了匹配子串在原始字符串 s 中的起始和结束索引
print(result.group()) # 打印了实际匹配到的子串s = '1python zhangSan python nihao python wolai'
result = re.match('python', s)
print('-----------------')
print(result)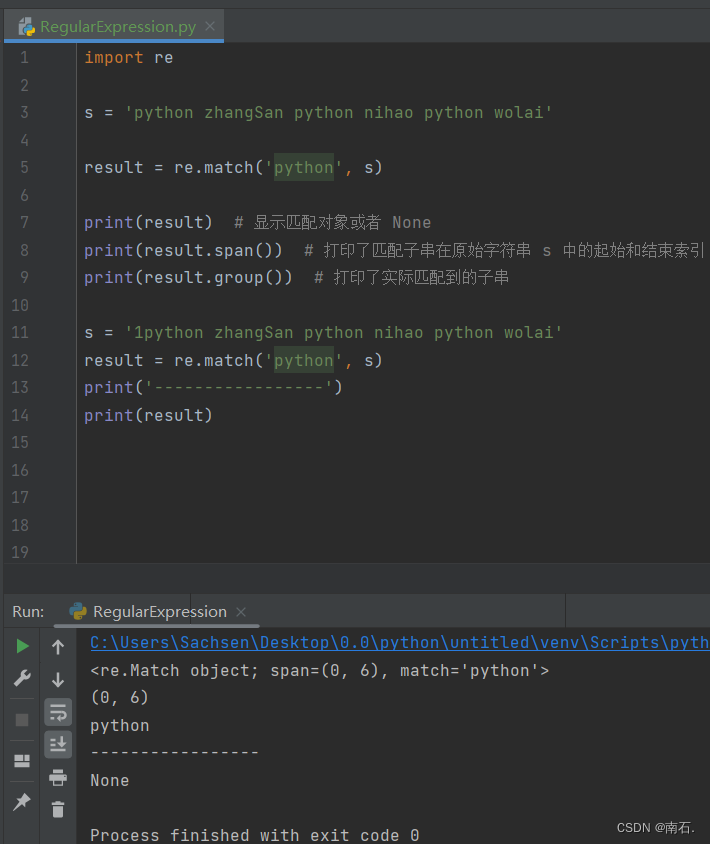
2. re.search('字符单词', 字符串变量) :字符串匹配规则,搜索匹配,从所有字符串中匹配一次符合条件的字符串;
import res = '1python zhangSan python nihao wolai'result = re.search('python', s)print(result) # 显示匹配对象或者 None
print(result.span()) # 打印了匹配子串在原始字符串 s 中的起始和结束索引
print(result.group()) # 打印了实际匹配到的子串s = 'nihao'
result = re.search('python', s)
print('-----------------')
print(result)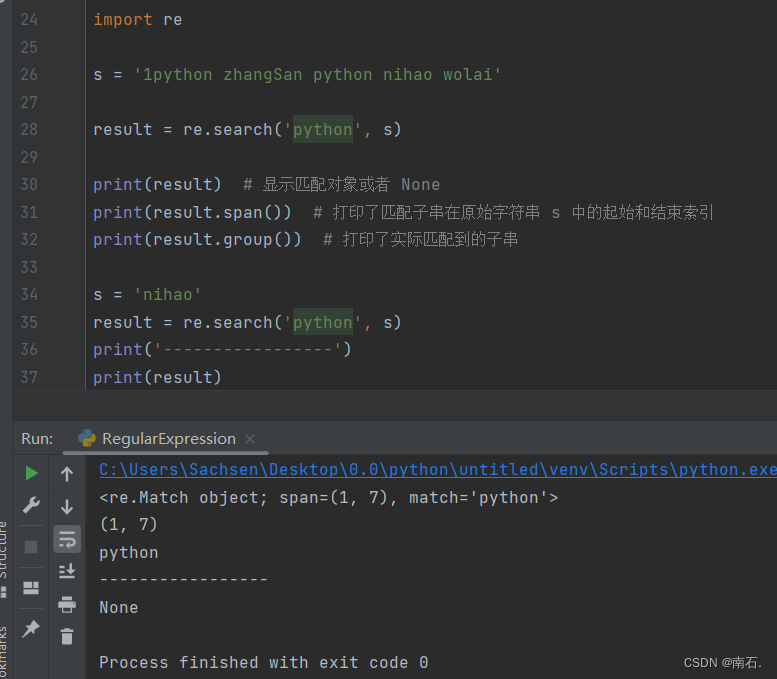
3. re.findall('字符单词', 字符串变量):字符串匹配规则,搜索全部匹配,从所有字符串中匹配所有符合条件的字符;
import res = '1python zhangSan python nihao wolai'result = re.findall('python', s)print(result) # 显示匹配对象或者 []s = 'nihao'
result = re.findall('python', s)
print('-----------------')
print(result)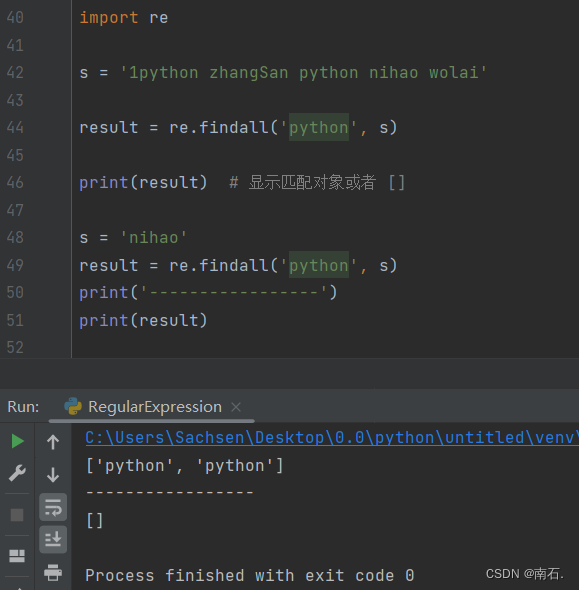
9.3 小结
- 什么是正则表达式:
- 是一种字符串验证的规则,通过特殊的字符串组合来确立规则;
- 用规则去匹配字符串是否满足;
- 如
(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)可以表示为一个标准邮箱的格式;
- re模块的三个主要方法:
re.match从头开始匹配,匹配第一个命中项;re.search全局匹配,匹配第一个命中项;re.findall全局匹配,匹配全部命中项;
10. 正则表达式-元字符匹配
10.1 元字符匹配
注意在使用.匹配的时候需要在匹配前面加上一个r ,因为\.或者\d在编码中可能代表着其他的含义,不能被正则使用,所以r把他们标记无效,所以要带上r;
| 元字符 | 含义 | 示例案例 |
|---|---|---|
| . | 匹配任意一个字符(除了换行符) | re.findall(r'he.t', 'hello hat heat') 匹配到 'heat' |
| . | 匹配点本身 | re.findall(r'.com', 'example.com google.com') 匹配到 '.com' |
| [] | 匹配[]中列举的字符 | re.findall(r'[aeiou]', 'hello world') 匹配到 'e', 'o' |
| \d | 匹配数字(0-9) | re.findall(r'\d', 'abc123def456') 匹配到 '1', '2', '3', '4', '5', '6' |
| \D | 匹配非数字 | re.findall(r'\D', 'abc123def456') 匹配到 'a', 'b', 'c', 'd', 'e', 'f' |
| \s | 匹配空白字符(空格、制表符等) | re.findall(r'\s', 'hello\tworld\n') 匹配到 '\t', '\n' |
| \S | 匹配非空白字符 | 无 |
| \w | 匹配单词字符(字母、数字、下划线) | re.findall(r'\w', 'hello123_world') 匹配到 'h', 'e', 'l', 'l', 'o', '1', '2', '3', '_', 'w', 'o', 'r', 'l', 'd' |
| \W | 匹配非单词字符 | re.findall(r'\W', 'hello123_world') 匹配到 '' (空字符串) |
10.2 元字符匹配-数量匹配
注意:{m,n} 单独介绍,配置的是字符串长度,就是返回字符串的长度区间意思;比如123是3位,123qwe是6位,那么{m,n}就应该等于{3,6} 代表可以匹配的字符是3位数和6位数的;
| 字符 | 功能 | 描述 |
|---|---|---|
| * | 匹配前一个规则的字符出现0至无数次 | re.findall(r'ab*', 'a ab abb abbb') 匹配到 'a', 'ab', 'abb', 'abbb' |
| + | 匹配前一个规则的字符出现1至无数次 | re.findall(r'ab+', 'a ab abb abbb') 匹配到 'ab', 'abb', 'abbb' |
| ? | 匹配前一个规则的字符出现0次或1次 | re.findall(r'ab?', 'a ab abb abbb') 匹配到 'a', 'ab', 'ab', 'ab' |
| {m} | 匹配前一个规则的字符出现m次 | re.findall(r'ab{2}', 'a ab abb abbb') 匹配到 'abb' |
| {m,} | 匹配前一个规则的字符出现最少m次 | re.findall(r'ab{2,}', 'a ab abb abbb') 匹配到 'abb', 'abbb' |
| {m,n} | 匹配前一个规则的字符出现m到n次 | re.findall(r'ab{1,2}', 'a ab abb abbb') 匹配到 'ab', 'abb' |
10.3 元字符匹配-边界匹配-分组匹配
^和$的使用注意项:如果要判断字符串整体就需要在字符串前后加上,如果不要求整体的字符串就不用加上,整体字符串意思是abcdefg从a开始到g结束进行匹配,而非整体就是0abcdefg1,也可以求出abcdefg的值,如果换成整体的就不会求出;
|符号表示:(qq,|163|gmail)这三个都可以,其他的都不行;
- 边界匹配:
| 字符 | 功能 | 示例 |
|---|---|---|
| ^ | 匹配字符串开头 | re.findall(r'^hello', 'hello world') 匹配到 'hello' |
| $ | 匹配字符串结尾 | re.findall(r'world$', 'hello world') 匹配到 'world' |
| \b | 匹配一个单词的边界 | re.findall(r'\bcat\b', 'The cat is black') 匹配到 'cat' |
| \B | 匹配非单词边界 | re.findall(r'\Bcat\B', 'The cat is black') 匹配到 'cat' |
- 分组匹配:
| 字符 | 功能 | 示例 |
|---|---|---|
| () | 将括号中字符作为一个分组 | re.findall(r'(hello)+', 'hellohellohello world') 匹配到 'hellohellohello' |
| | | 匹配左右任意一个表达式 | re.findall(r'cat|dog', 'I have a cat') 匹配到 'cat' |
10.4 练习习题
10.4.1 案例:匹配账号,只能由字母和数字组成,长度限制6-10位
r = '^[0-9a-zA-Z]{6,10}$' :表示^从字符串头开始,[0-9a-zA-Z]匹配的规则,{6,10}匹配的字符串长度,$匹配到字符串结尾;
import rer = '^[0-9a-zA-Z]{6,10}$'
s = '123456Ab'print(re.findall(r, s))
s = '123456Ab_'
print("------------")
print(re.findall(r, s))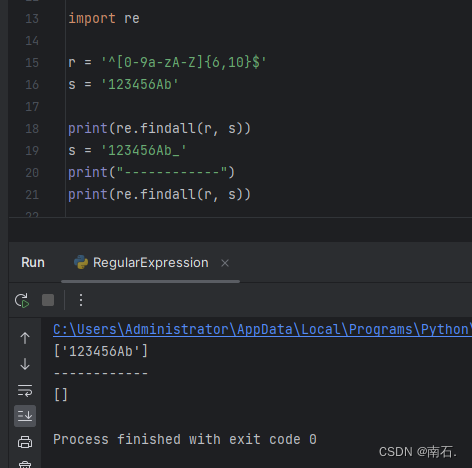
10.4.2 案例:匹配QQ号,要求纯数字,长度5-11,第一位不为0
r = '^[1-9][0-9]{4,10}$' :表示^从头开始匹配,[1-9]第一位元素只能是1-9区间,[0-9]后续的匹配规则只能在0-9之间,{4,10}原规则是5-11长度,这里4-10是由于第一个元素[1-9]占据了,所有长度要减一,$匹配到结尾;
import rer = '^[1-9][0-9]{4,10}$'
s = '123a456'
print(re.findall(r, s)) # 数字中存在字母,不符合
print("------------------")
s = '123456'
print(re.findall(r, s)) # 纯6位数字,符合
print("------------------")
s = '012345'
print(re.findall(r, s)) # 0开头,不符合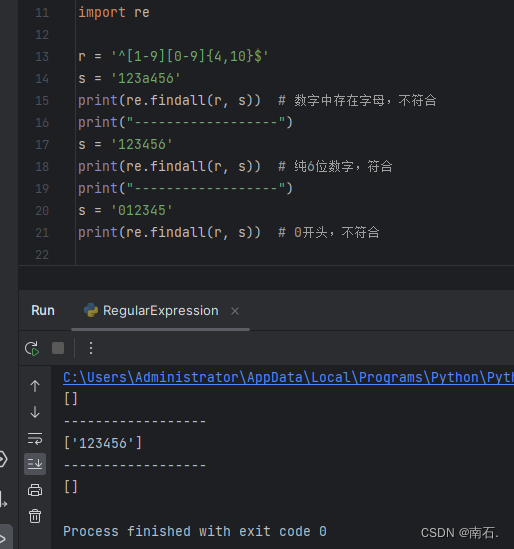
10.4.3 案例:匹配邮箱地址,只允许qq、163、gmail这三种邮箱地址
r = r'(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
^: 字符串的开始[\w-]+: 匹配邮箱用户名部分,包含一个或多个字母、数字、下划线或连字符(\.[\w-]+)*: 匹配可选的点号后跟一个或多个字母、数字、下划线或连字符的部分,重复零次或多次@: 匹配@符号(qq|163|gmail): 匹配qq、163或gmail这三个域名之一(\.[\w-]+)+: 匹配至少一个点号后跟一个或多个字母、数字、下划线或连字符的部分$: 字符串的结尾
这个正则表达式整体上用于匹配 qq.com、163.com 或 gmail.com 这些特定域名的电子邮件地址,例如 username@qq.com、user.name@163.com 或 user-name@gmail.com;
import rer = r'(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
s = 'a.x.a.d.a@qq.com.cn'print(re.findall(r, s)) # 符合邮箱规则
print('-----------------')
s = 'a.x.a.d.a@q123q.com.cn'
print(re.findall(r, s)) # 不符合邮箱规则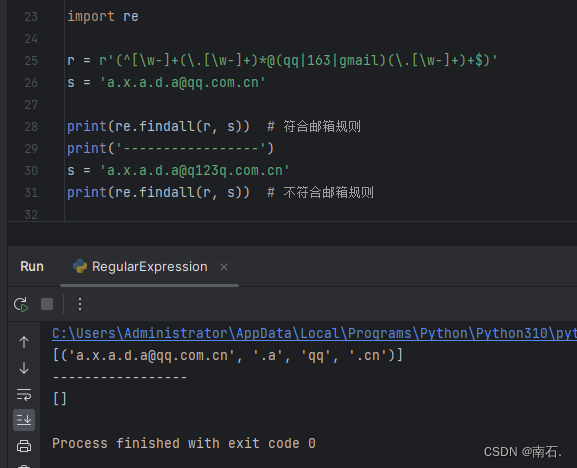
11. 递归算法
11.1 概念:即方法(函数)自己调用自己的一种特殊编程写法;
函数调用自己,即称之为递归调用;
def func():if ...:func()return ...- 使用递归场景:递归找文件,找出一个文件夹汇总全部的文件,用递归编程完成;
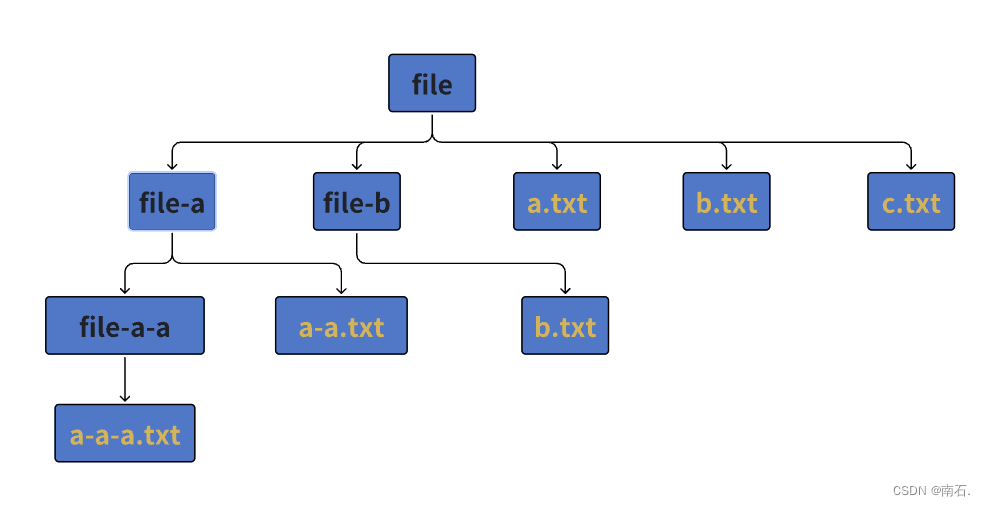
11.2 文件结构
11.3 os模块获取文件操作
11.3.1 读取文件夹中的内容
import osdef test_os():print(os.listdir(r"C:\Users\Administrator\Desktop\file"))if __name__ == '__main__':test_os()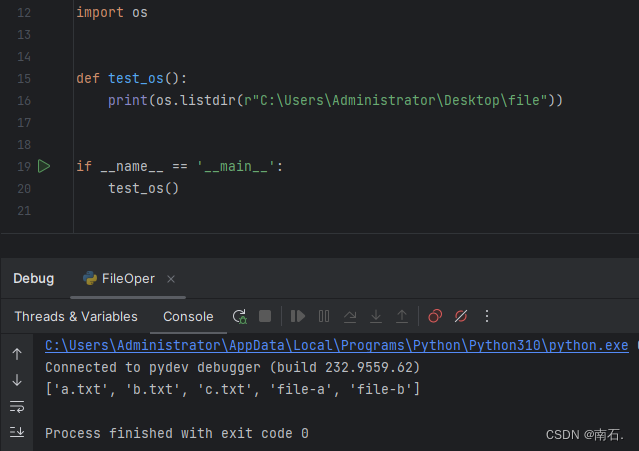
11.3.2 判断这个路径是否是文件夹
import osdef test_os():print(os.path.isdir(r"C:\Users\Administrator\Desktop\file"))if __name__ == '__main__':test_os()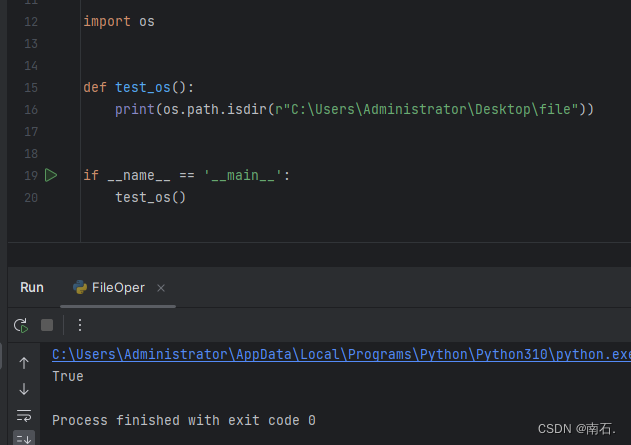
11.3.3 判断这个路径是否存在
import osdef test_os():print(os.path.exists(r"C:\Users\Administrator\Desktop\file"))if __name__ == '__main__':test_os()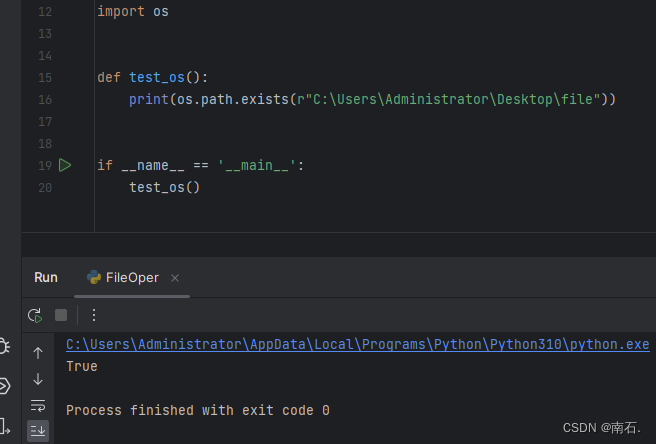
11.4 递归
实际上自己调用自己,不过在调用的外层有一个for循环,最终将值累计,实现递归操作;
主要理解return返回值,以及函数的调用方式,更容易理解递归;
import osdef get_files_recusion_dir(path):file_list = []if os.path.exists(path): # 1.判断路径是否存在for f in os.listdir(path):new_path = path + "/" + f # 2.将此路径加上反斜杠/ + 当前目录下的其他文件或文本,再次判断if os.path.isdir(new_path):file_list += get_files_recusion_dir(new_path) # 3.存在当前文件夹即再次调用当前函数,并记录用调用的函数返回值进行累计,实现自己调用自己else:file_list.append(new_path) # 4.没有就追加文本文件else:print(f"指定目录{path}不存在")return []return file_list # 最终返回所有的文本文件if __name__ == '__main__':print(get_files_recusion_dir(r"C:\Users\Administrator\Desktop\file"))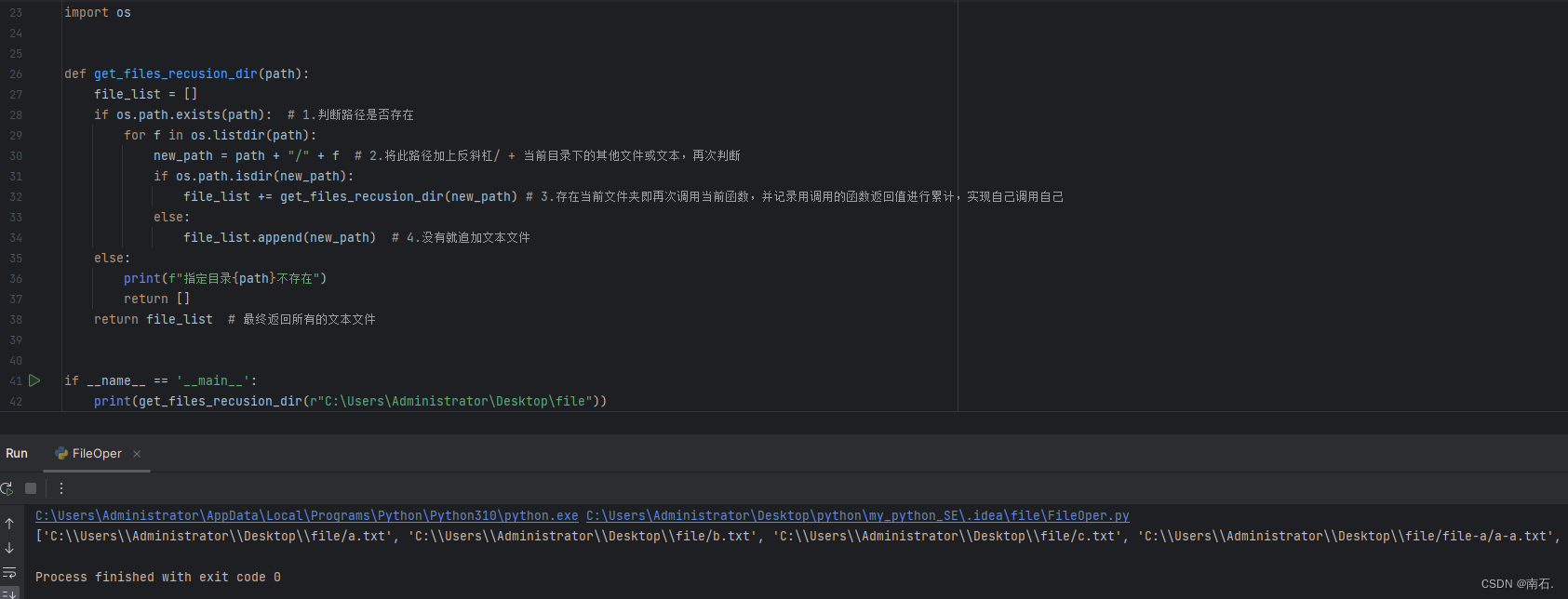
相关文章:
Python第二语言(十四、高阶基础)
目录 1. 闭包 1.1 使用闭包注意事项 1.2 小结 2. 装饰器:实际上也是一种闭包; 2.1 装饰器的写法(闭包写法) :基础写法,只是解释装饰器是怎么写的; 2.2 装饰器的语法糖写法:函数…...

python脚本之调用其他目录脚本
import sys# 添加新路径到搜索路径中 sys.path.append(/脚本父级)# 现在可以导入该路径下的模块了 from 脚本 import 方法方法()...
定义及其使用)
C# 事件(Event)定义及其使用
1.定义个委托和类 //委托 public delegate void ProductEventHandler(Product product);/// <summary> /// 产品 /// </summary> public class Product {public int Id { get; set; }public string Code { get; set; }public string Name { get; set; }private de…...

2.负载压力测试
负载压力测试是一种重要的系统测试方法,旨在评估系统在正常和峰值负载情况下的性能表现。 一、基本概念: 负载压力测试是在一定约束条件下,通过模拟实际用户访问系统的行为,来测试系统所能承受的并发用户数、运行时间、数据量等&…...
【AI工具】jupyter notebook和jupyterlab对比和安装
简单说,jupyterlab是jupyter notebook的下一代。 选择安装一个即可。 一、这里是AI对比介绍 Jupyter Notebook和JupyterLab都是基于Jupyter内核的交互式计算环境,但它们在设计和功能上有一些关键的区别: 用户界面: Jupyter Not…...

Linux 基本指令3
date指令 date[选项][格式] %Y--年 %m--月 %d--日 %H--小时 %M--分 %S--秒 中间可用其他符号分割,不能使用空格。 -s 设置时间,会返回设置时间的信息并不是改变当前时间 设置全部时间年可用-或者:分割日期和时间用空格分隔ÿ…...
、PEM格式的公钥和PEM格式的私钥。)
在Linux系统中,可以使用OpenSSL来生成CSR(Certificate Signing Request)、PEM格式的公钥和PEM格式的私钥。
在Linux系统中,可以使用OpenSSL来生成CSR(Certificate Signing Request)、PEM格式的公钥和PEM格式的私钥。以下是生成这些文件的命令: 首先,生成私钥(通常是以.key结尾,但可以转换成PEM格式&am…...
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 团队派遣(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 🍓OJ题目截图 📎在线评测链接 团队派遣(100分) 🌍 评测功能需要订阅专栏…...

Python数据分析与机器学习在医疗诊断中的应用
文章目录 📑引言一、数据收集与预处理1.1 数据收集1.2 数据预处理 二、特征选择与构建2.1 特征选择2.2 特征构建 三、模型选择与训练3.1 逻辑回归3.2 随机森林3.3 深度学习 四、模型评估与调优4.1 交叉验证4.2 超参数调优 五、模型部署与应用5.1 模型保存与加载5.2 …...

vite.config.js如何使用env的环境变量
了解下环境变量在vite中 官方文档走起 https://cn.vitejs.dev/guide/env-and-mode.html#env-variables-and-modes 你见到的.env,.env.production等就是放置环境变量的 官方文档说到.env.[mode] # 只在指定模式下加载,比如.env.development只在开发环境加载 至于为什么是deve…...

MySql几十万条数据,同时新增或者修改
项目场景: 十万条甚至更多的数据新增或者修改 问题描述 现在有十万条数据甚至更多数据,在这些数据中,有部分数据存在数据库中,有部分数据确是新数据,存在的数据需要更新,不存在的数据需要新增 原因分析&a…...

如何提高MySQL DELETE 速度
提高MySQL中DELETE操作的速度通常涉及多个方面,包括优化查询、索引、表结构、硬件和配置等。以下是一些建议,以及一些示例代码,用于帮助我们提高DELETE操作的速度。 1.提高MySQL DELETE 速度的方法 1.1 优化查询 只删除必要的行:…...
本地Zabbix开源监控系统安装内网穿透实现远程访问详细教程
文章目录 前言1. Linux 局域网访问Zabbix2. Linux 安装cpolar3. 配置Zabbix公网访问地址4. 公网远程访问Zabbix5. 固定Zabbix公网地址 💡推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【…...

从Android刷机包提取System和Framework
因为VIVO的手机很难解锁BL和Root,故直接从ADB中获取完整的Framework代码是比较困难的。我就考虑直接从VIVO提供的刷机包文件中获取相关的代码 由于vivo把system.new.dat分割了,所以下一步,我们使用cat命令,合并这些文件࿰…...

分布式光纤测温DTS与红外热成像系统的主要区别是什么?
分布式光纤测温DTS和红外热成像系统在应用领域和工作原理上存在显著的区别,两者具有明显的差异性。红外热成像系统适用于表现扩散式发热、面式场景以及环境条件较好的情况下。它主要用于检测物体表面的温度,并且受到镜头遮挡或灰尘等因素的影响会导致失效…...
python数据分析-问卷数据分析(地理课)
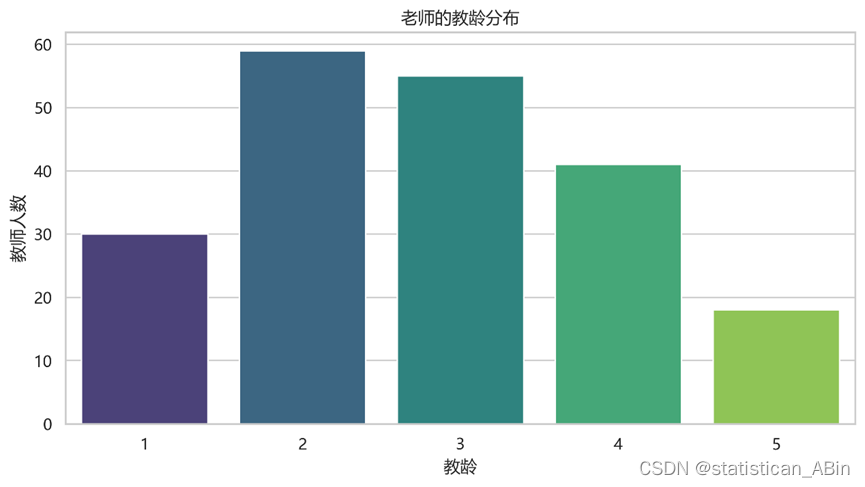
学生问卷 分析学生背景:班级分布、每周地理课数量、地理成绩分布 根据问卷,可以知道: 班级分布: 七年级有118名学生。 八年级有107名学生。 每周地理课的数量: 有28名学生每周有1节地理课。 有99名学生每周有2…...

【ARM64 常见汇编指令学习 19.3 -- ARMv8 三目运算指令 csel 详细介绍】
请阅读【嵌入式开发学习必备专栏】 文章目录 三目运算指令 csel地址获取条件选择用途 三目运算指令 csel 本篇文章以下面汇编代码介绍三目运算指令csel: adr x0, pass_messageadr x1, fail_messagecsel x1, x0, x1, pl下面是对这几行代码的详解&#x…...
)
Docker 安装部署(CentOS 8)
以下所有操作都是基于 CentOS 8 系统进行操作的。安装的 Docker 版本为 25.0.5-1.el8。 1、卸载老版本 Docker sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine注&a…...
Python自动化
python操作excel # 安装第三个库 cmd -> pip install xlrb 出现success即安装成功 # 导入库函数 import xlrb # 打开的文件保存为excel文档对象 xlsx xlrb.open_workbook("文件位置") # C:\Users\Adminstator\Desktop\学生版.xlsx # 操作工作簿里的工作表 # 1.…...
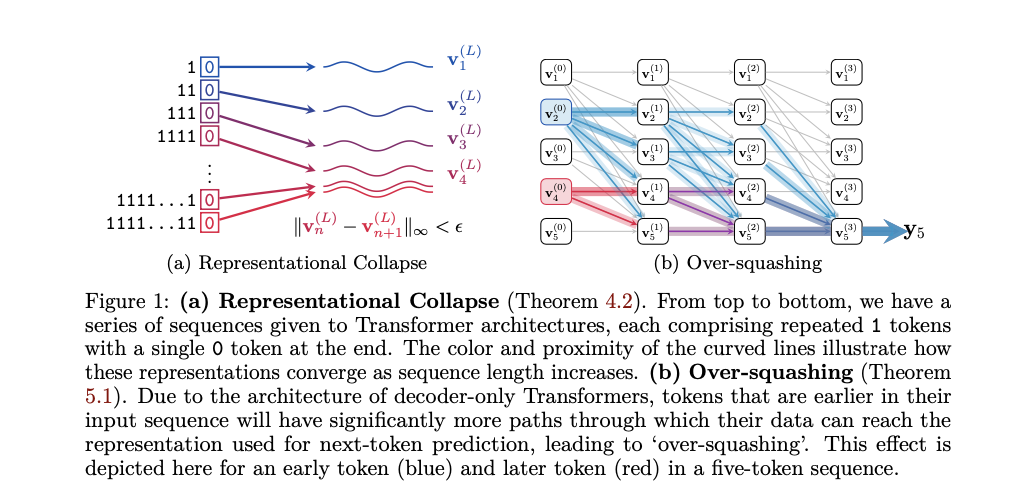
自然语言处理领域的重大挑战:解码器 Transformer 的局限性
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

浦语灵笔2.5-7B精彩案例分享:手写体题目识别+解题逻辑生成全过程
浦语灵笔2.5-7B精彩案例分享:手写体题目识别解题逻辑生成全过程 1. 引言:当AI“看懂”你的手写作业 想象一下这个场景:你正在辅导孩子做数学作业,他遇到一道难题,不仅把题目抄了下来,还在旁边画了辅助线、…...

Qwen3-14B惊艳效果展示:RTX 4090D上流畅运行14B模型的真实体验
Qwen3-14B惊艳效果展示:RTX 4090D上流畅运行14B模型的真实体验 1. 开箱即用的高性能体验 当我第一次在RTX 4090D上启动这个Qwen3-14B私有部署镜像时,最直接的感受就是"快"。从执行启动命令到WebUI界面完全加载,整个过程不到2分钟…...

Phi-4-mini-reasoning真实案例:GPT-4对比测试中更优的确定性推理表现
Phi-4-mini-reasoning真实案例:GPT-4对比测试中更优的确定性推理表现 1. 模型介绍 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,特别擅长处理需要多步逻辑推导的问题。与通用聊天模型不同,它被设计用来解决数学题、逻辑题等需…...

Python中缓存入门实战之核心概念与用法详解
缓存是提升程序性能的关键技术——将频繁访问的「计算结果/数据」临时存储在高速介质(如内存)中,避免重复计算/重复查询(如数据库、API),从而大幅降低响应时间。以下是 Python 缓存的入门指南,涵…...

深入解析DDR3与AXI接口:基于7035开发板的实战笔记
1. DDR3基础概念与7035开发板适配 第一次接触DDR3时,我也被那些专业术语搞得晕头转向。直到在7035开发板上实际调试后,才发现理解DDR3的关键在于抓住几个核心特性。DDR3全称Double Data Rate 3,顾名思义,它在时钟上升沿和下降沿都…...

Z-Image-ComfyUI场景应用:为社交媒体快速生成配图,提升内容创作效率
Z-Image-ComfyUI场景应用:为社交媒体快速生成配图,提升内容创作效率 1. 社交媒体内容创作的痛点与解决方案 每天运营社交媒体账号时,你是否也面临这样的困境:精心撰写的文案已经完成,却卡在配图制作环节?…...

3步搭建PP-DocLayoutV3服务:快速体验文档版面分析的强大能力
3步搭建PP-DocLayoutV3服务:快速体验文档版面分析的强大能力 1. 引言:文档版面分析的价值 在日常工作中,我们经常需要处理各种文档——合同、论文、报告、书籍等。传统OCR技术虽然能识别文字,但往往无法理解文档的结构ÿ…...

Deepin系统远程桌面实战:从零配置xrdp服务到Windows无缝连接
Deepin系统远程桌面实战:从零配置xrdp服务到Windows无缝连接 在跨平台协作成为常态的今天,远程桌面技术让不同操作系统间的无缝协作成为可能。对于使用Deepin系统的用户而言,如何高效地通过Windows设备远程访问和控制Deepin桌面,是…...

嵌入式C语言状态机编程实践与优化
1. 状态机编程基础概念在嵌入式系统开发中,状态机(State Machine)是一种极其重要的编程范式。它通过定义系统可能处于的状态集合、状态之间的转换条件以及状态转换时执行的动作,来清晰地描述系统的行为逻辑。状态机之所以在嵌入式领域广泛应用࿰…...
)
HuggingFace大语言模型实战:如何用Python脚本批量翻译YouTube字幕(含环境配置避坑指南)
HuggingFace大语言模型实战:Python脚本批量翻译YouTube字幕全攻略 当你在YouTube上发现一段精彩的英文技术讲座,或是需要研究某个外语行业报告时,自动翻译工具能大幅提升信息获取效率。本文将带你用HuggingFace生态构建一个本地化翻译工作流&…...