Python数据分析与机器学习在医疗诊断中的应用
文章目录
- 📑引言
- 一、数据收集与预处理
- 1.1 数据收集
- 1.2 数据预处理
- 二、特征选择与构建
- 2.1 特征选择
- 2.2 特征构建
- 三、模型选择与训练
- 3.1 逻辑回归
- 3.2 随机森林
- 3.3 深度学习
- 四、模型评估与调优
- 4.1 交叉验证
- 4.2 超参数调优
- 五、模型部署与应用
- 5.1 模型保存与加载
- 5.2 Web服务部署
- 六、实际应用案例
- 6.1 数据集介绍
- 6.2 数据预处理
- 6.3 模型训练
- 6.4 模型部署
- 七、小结
📑引言
在现代医疗领域,数据分析与机器学习的应用已经成为提升医疗诊断效率和准确性的关键手段。医疗诊断系统通过对大量患者数据进行分析,帮助医生预测疾病风险、制定个性化治疗方案,并且在疾病早期阶段提供预警。Python作为一种灵活且功能强大的编程语言,结合其丰富的数据分析和机器学习库,成为医疗诊断系统开发的首选工具。本文将探讨Python数据分析与机器学习在医疗诊断中的应用,详细介绍构建医疗诊断系统的步骤和技术。

一、数据收集与预处理
在构建医疗诊断系统之前,需要收集并预处理医疗数据。医疗数据包括电子健康记录(EHR)、影像数据、基因组数据等。
1.1 数据收集
数据收集是构建医疗诊断系统的第一步。数据来源包括医院数据库、健康监测设备、基因测序公司等。以下是一个简单的示例,展示如何从数据库中收集患者的电子健康记录。
import pandas as pd
import sqlite3# 连接到SQLite数据库
conn = sqlite3.connect('medical_records.db')# 查询患者健康记录
query = '''
SELECT patient_id, age, gender, blood_pressure, cholesterol, glucose, diagnosis
FROM patient_health_records
'''
df = pd.read_sql_query(query, conn)# 关闭数据库连接
conn.close()# 查看数据
print(df.head())
1.2 数据预处理
数据预处理是数据分析和机器学习的关键步骤。它包括数据清洗、处理缺失值、特征工程等。
# 数据清洗:去除重复记录
df = df.drop_duplicates()# 处理缺失值:填充或删除缺失值
df = df.fillna(df.mean())# 特征工程:将分类变量转换为数值
df['gender'] = df['gender'].map({'male': 0, 'female': 1})# 查看预处理后的数据
print(df.head())
二、特征选择与构建
特征选择是从原始数据中提取有用信息的过程。在医疗诊断中,选择合适的特征对于提高模型的准确性至关重要。
2.1 特征选择
可以使用统计方法和机器学习算法进行特征选择。例如,使用相关性分析和LASSO回归。
from sklearn.linear_model import LassoCV
import numpy as np# 选择特征和标签
X = df.drop(columns=['patient_id', 'diagnosis'])
y = df['diagnosis']# 使用LASSO进行特征选择
lasso = LassoCV()
lasso.fit(X, y)# 查看选择的特征
selected_features = X.columns[(lasso.coef_ != 0)]
print("Selected features:", selected_features)
2.2 特征构建
特征构建是从原始数据中创建新的特征,以提高模型的表现。例如,可以构建年龄和血压的交互特征。
# 构建交互特征
df['age_bp_interaction'] = df['age'] * df['blood_pressure']# 查看新特征
print(df[['age', 'blood_pressure', 'age_bp_interaction']].head())
三、模型选择与训练
在医疗诊断中,可以使用多种机器学习模型进行疾病预测和诊断。常用的模型包括逻辑回归、决策树、随机森林和深度学习模型。
3.1 逻辑回归
逻辑回归是一种常用的二分类模型,适用于预测患者是否患有某种疾病。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X[selected_features], y, test_size=0.2, random_state=42)# 训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
print(f"ROC AUC: {roc_auc:.2f}")
3.2 随机森林
随机森林是一种集成学习方法,通过构建多个决策树来提高模型的准确性和稳定性。
from sklearn.ensemble import RandomForestClassifier# 训练随机森林模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
print(f"ROC AUC: {roc_auc:.2f}")
3.3 深度学习
深度学习模型(如卷积神经网络和循环神经网络)在处理复杂数据(如医疗影像和时间序列数据)时表现出色。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout# 构建深度学习模型
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(X_train.shape[1],)))
model.add(Dropout(0.5))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])# 训练模型
history = model.fit(X_train, y_train, epochs=20, batch_size=32, validation_split=0.2)# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Accuracy: {accuracy:.2f}")

四、模型评估与调优
模型评估是确保其有效性的关键。常用的评估指标包括准确率、召回率、F1值和AUC-ROC曲线。通过交叉验证和超参数调优,可以进一步提升模型性能。
4.1 交叉验证
交叉验证是一种评估模型泛化能力的方法,通过将数据集划分为多个子集进行训练和验证。
from sklearn.model_selection import cross_val_score# 交叉验证
scores = cross_val_score(model, X[selected_features], y, cv=5, scoring='accuracy')
print(f"Cross-validation accuracy: {scores.mean():.2f}")
4.2 超参数调优
超参数调优可以通过网格搜索(Grid Search)和随机搜索(Random Search)来实现,以找到最佳的模型参数。
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 10, 20, 30],'min_samples_split': [2, 5, 10]
}# 网格搜索
grid_search = GridSearchCV(RandomForestClassifier(random_state=42), param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)# 最佳参数
print(f"Best parameters: {grid_search.best_params_}")
五、模型部署与应用
在完成模型训练和评估之后,可以将模型部署到生产环境中,提供实时的医疗诊断服务。
5.1 模型保存与加载
可以使用Python的pickle库或TensorFlow的save方法保存训练好的模型,以便在生产环境中加载和使用。
import pickle# 保存模型
with open('medical_diagnosis_model.pkl', 'wb') as f:pickle.dump(model, f)# 加载模型
with open('medical_diagnosis_model.pkl', 'rb') as f:loaded_model = pickle.load(f)# 预测
y_pred = loaded_model.predict(X_test)
print(f"Loaded model accuracy: {accuracy_score(y_test, y_pred):.2f}")
对于深度学习模型,可以使用TensorFlow的save和load方法。
# 保存模型
model.save('medical_diagnosis_model.h5')# 加载模型
loaded_model = tf.keras.models.load_model('medical_diagnosis_model.h5')# 预测
y_pred = (loaded_model.predict(X_test) > 0.5).astype("int32")
print(f"Loaded model accuracy: {accuracy_score(y_test, y_pred):.2f}")
5.2 Web服务部署
可以使用Flask等Web框架,将模型部署为Web服务,提供API接口供前端或其他系统调用。
from flask import Flask, request, jsonifyapp = Flask(__name__)# 加载模型
with open('medical_diagnosis_model.pkl', 'rb') as f:model = pickle.load(f)# 预测API@app.route('/predict', methods=['POST'])
def predict():data = request.jsonX_new = pd.DataFrame(data)prediction = model.predict(X_new)return jsonify({'prediction': prediction.tolist()})# 启动服务
if __name__ == '__main__':app.run(debug=True)
六、实际应用案例
以下是一个实际应用案例,展示如何利用Python数据分析与机器学习技术,构建一个糖尿病预测系统。
6.1 数据集介绍
使用Kaggle上的糖尿病数据集(Pima Indians Diabetes Database),该数据集包含多个健康指标,如怀孕次数、血糖浓度、血压、皮褶厚度、胰岛素、体重指数(BMI)、糖尿病家族史和年龄。
6.2 数据预处理
# 导入数据集
df = pd.read_csv('diabetes.csv')# 查看数据
print(df.head())# 处理缺失值
df = df.fillna(df.mean())# 特征选择
X = df.drop(columns=['Outcome'])
y = df['Outcome']# 标准化数据
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
6.3 模型训练
使用随机森林和逻辑回归模型进行训练,并进行交叉验证评估。
# 随机森林
model_rf = RandomForestClassifier(n_estimators=100, random_state=42)
model_rf.fit(X_scaled, y)
scores_rf = cross_val_score(model_rf, X_scaled, y, cv=5, scoring='accuracy')
print(f"Random Forest Cross-validation accuracy: {scores_rf.mean():.2f}")# 逻辑回归
model_lr = LogisticRegression()
model_lr.fit(X_scaled, y)
scores_lr = cross_val_score(model_lr, X_scaled, y, cv=5, scoring='accuracy')
print(f"Logistic Regression Cross-validation accuracy: {scores_lr.mean():.2f}")
6.4 模型部署
将训练好的模型部署为Web服务,提供糖尿病预测API。
from flask import Flask, request, jsonify
import pickleapp = Flask(__name__)# 保存随机森林模型
with open('diabetes_model_rf.pkl', 'wb') as f:pickle.dump(model_rf, f)# 加载模型
with open('diabetes_model_rf.pkl', 'rb') as f:model = pickle.load(f)# 预测API
@app.route('/predict', methods=['POST'])
def predict():data = request.jsonX_new = pd.DataFrame(data)X_new_scaled = scaler.transform(X_new)prediction = model.predict(X_new_scaled)return jsonify({'prediction': prediction.tolist()})# 启动服务
if __name__ == '__main__':app.run(debug=True)
七、小结
本篇对Python数据分析与机器学习在医疗诊断中的应用,从数据收集与预处理、特征选择与构建、模型选择与训练、模型评估与调优,到模型部署与应用。通过一个糖尿病预测系统的实际案例,展示了如何利用Python的强大功能构建一个完整的医疗诊断系统。
医疗诊断系统的构建是一个复杂且持续优化的过程,需要不断迭代和改进。希望本文能为从事医疗数据分析与机器学习的研究人员和开发者提供有价值的参考和帮助。
相关文章:
Python数据分析与机器学习在医疗诊断中的应用
文章目录 📑引言一、数据收集与预处理1.1 数据收集1.2 数据预处理 二、特征选择与构建2.1 特征选择2.2 特征构建 三、模型选择与训练3.1 逻辑回归3.2 随机森林3.3 深度学习 四、模型评估与调优4.1 交叉验证4.2 超参数调优 五、模型部署与应用5.1 模型保存与加载5.2 …...

vite.config.js如何使用env的环境变量
了解下环境变量在vite中 官方文档走起 https://cn.vitejs.dev/guide/env-and-mode.html#env-variables-and-modes 你见到的.env,.env.production等就是放置环境变量的 官方文档说到.env.[mode] # 只在指定模式下加载,比如.env.development只在开发环境加载 至于为什么是deve…...

MySql几十万条数据,同时新增或者修改
项目场景: 十万条甚至更多的数据新增或者修改 问题描述 现在有十万条数据甚至更多数据,在这些数据中,有部分数据存在数据库中,有部分数据确是新数据,存在的数据需要更新,不存在的数据需要新增 原因分析&a…...

如何提高MySQL DELETE 速度
提高MySQL中DELETE操作的速度通常涉及多个方面,包括优化查询、索引、表结构、硬件和配置等。以下是一些建议,以及一些示例代码,用于帮助我们提高DELETE操作的速度。 1.提高MySQL DELETE 速度的方法 1.1 优化查询 只删除必要的行:…...
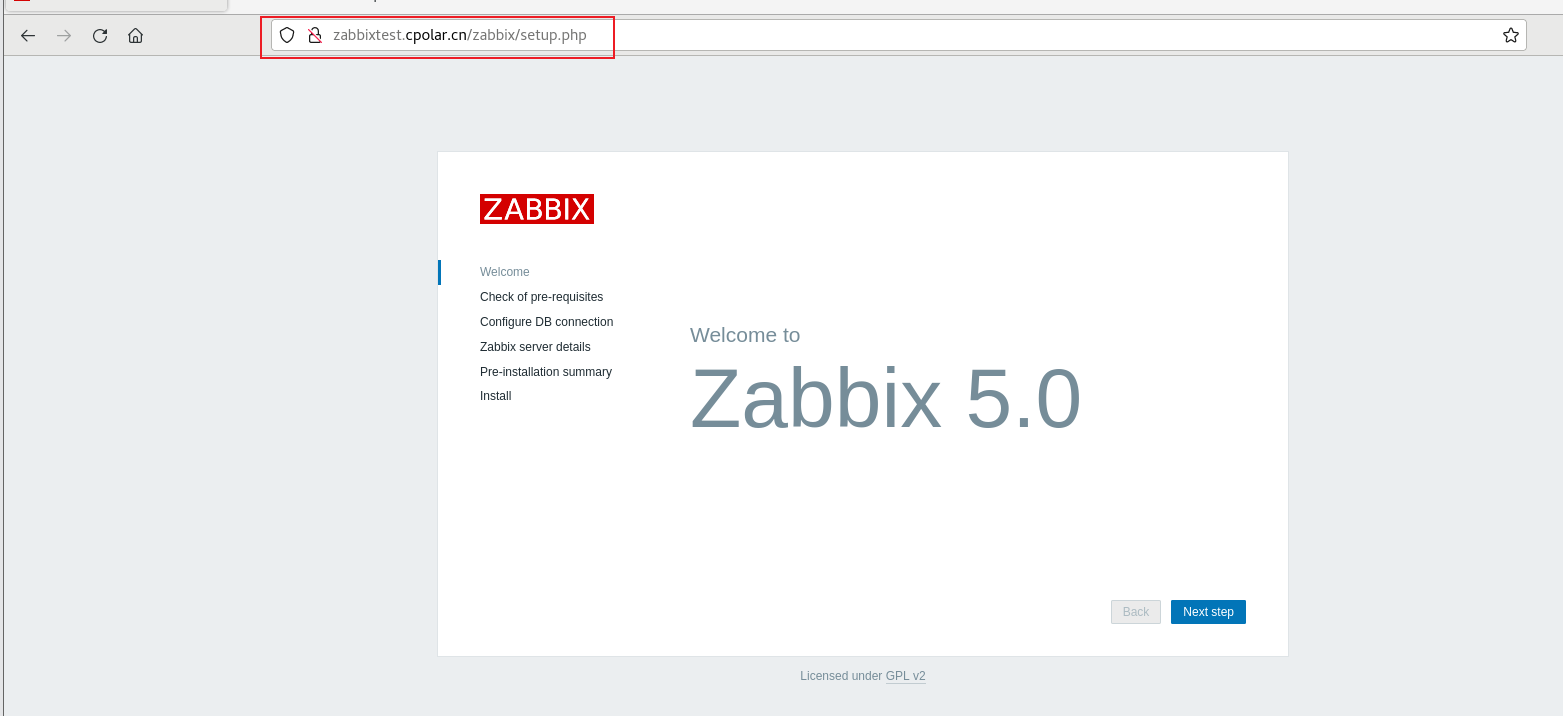
本地Zabbix开源监控系统安装内网穿透实现远程访问详细教程
文章目录 前言1. Linux 局域网访问Zabbix2. Linux 安装cpolar3. 配置Zabbix公网访问地址4. 公网远程访问Zabbix5. 固定Zabbix公网地址 💡推荐 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【…...

从Android刷机包提取System和Framework
因为VIVO的手机很难解锁BL和Root,故直接从ADB中获取完整的Framework代码是比较困难的。我就考虑直接从VIVO提供的刷机包文件中获取相关的代码 由于vivo把system.new.dat分割了,所以下一步,我们使用cat命令,合并这些文件࿰…...

分布式光纤测温DTS与红外热成像系统的主要区别是什么?
分布式光纤测温DTS和红外热成像系统在应用领域和工作原理上存在显著的区别,两者具有明显的差异性。红外热成像系统适用于表现扩散式发热、面式场景以及环境条件较好的情况下。它主要用于检测物体表面的温度,并且受到镜头遮挡或灰尘等因素的影响会导致失效…...
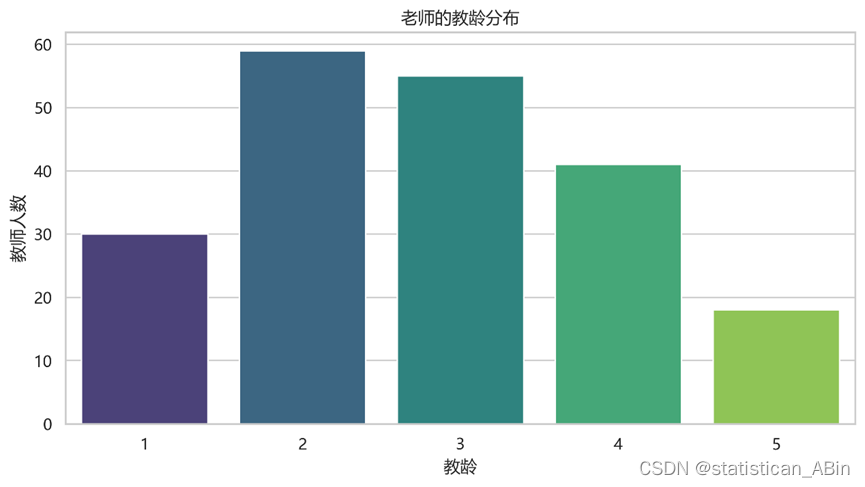
python数据分析-问卷数据分析(地理课)
学生问卷 分析学生背景:班级分布、每周地理课数量、地理成绩分布 根据问卷,可以知道: 班级分布: 七年级有118名学生。 八年级有107名学生。 每周地理课的数量: 有28名学生每周有1节地理课。 有99名学生每周有2…...

【ARM64 常见汇编指令学习 19.3 -- ARMv8 三目运算指令 csel 详细介绍】
请阅读【嵌入式开发学习必备专栏】 文章目录 三目运算指令 csel地址获取条件选择用途 三目运算指令 csel 本篇文章以下面汇编代码介绍三目运算指令csel: adr x0, pass_messageadr x1, fail_messagecsel x1, x0, x1, pl下面是对这几行代码的详解&#x…...
)
Docker 安装部署(CentOS 8)
以下所有操作都是基于 CentOS 8 系统进行操作的。安装的 Docker 版本为 25.0.5-1.el8。 1、卸载老版本 Docker sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine注&a…...
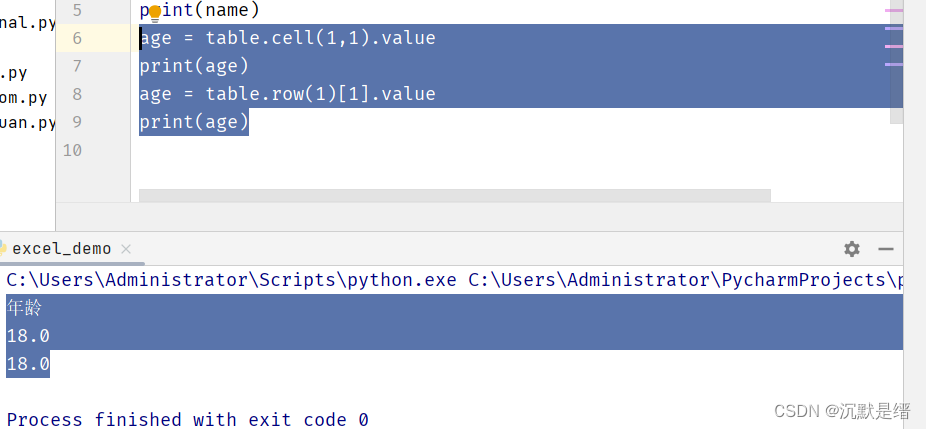
Python自动化
python操作excel # 安装第三个库 cmd -> pip install xlrb 出现success即安装成功 # 导入库函数 import xlrb # 打开的文件保存为excel文档对象 xlsx xlrb.open_workbook("文件位置") # C:\Users\Adminstator\Desktop\学生版.xlsx # 操作工作簿里的工作表 # 1.…...
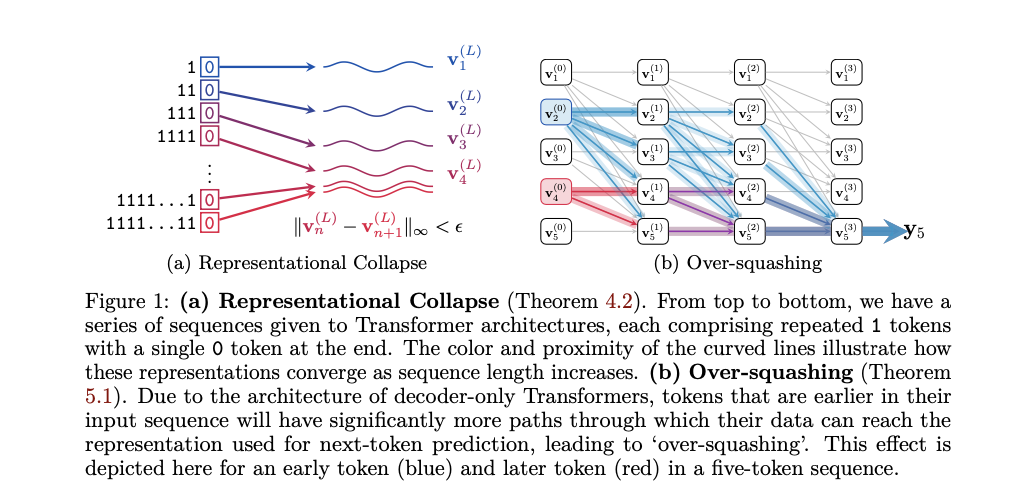
自然语言处理领域的重大挑战:解码器 Transformer 的局限性
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

【机器学习】机器学习赋能医疗健康:从诊断到治疗的智能化革命
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀目录 📒1. 引言📙2. 机器学习在疾病诊断中的应用🧩医学影像分析:从X光到3D成像带代码…...

Elasticsearch6.7版本,内网中其他电脑无法连接
对于Elasticsearch 6.7版本,如果内网中其他电脑无法连接,配置文件可能是问题的一个关键部分。以下是一些可能的配置问题和相应的解决步骤,你可以按照这些步骤进行排查: 网络配置: 检查elasticsearch.yml配置文件中的ne…...

交友系统定制版源码 相亲交友小程序源码全开源可二开 打造独特的社交交友系统
交友系统源码的实现涉及到多个方面,包括前端页面设计、后端逻辑处理、数据库设计以及用户交互等。以下是一个简单的交友系统源码实现的基本框架和关键步骤: 1.数据库设计:用户表:存储用户基本信息,如用户ID、用户名、密码、头像、性别、年龄、地理位置…...

数据结构笔记39-48
碎碎念:想了很久,不知道数据结构这个科目最终该以什么笔记方式呈现出来,是纸质版还是电子版?后来想了又想,还是电子版吧?毕竟和计算机有关~(啊哈哈哈哈哈哈哈) 概率论已经更新完了&…...

2-3 基于matlab的NSCT-PCNN融合和创新算法(NSCT-ML-PCNN )图像融合
基于matlab的NSCT-PCNN融合和创新算法(NSCT-ML-PCNN )图像融合。NSSCTest.m文件:用于查看利用NSSC算法分解出的图像并保存。其中的nlevel可调test.m文件:用于产生融合结果,其中一个参数需要设置:Low_Coeffs…...
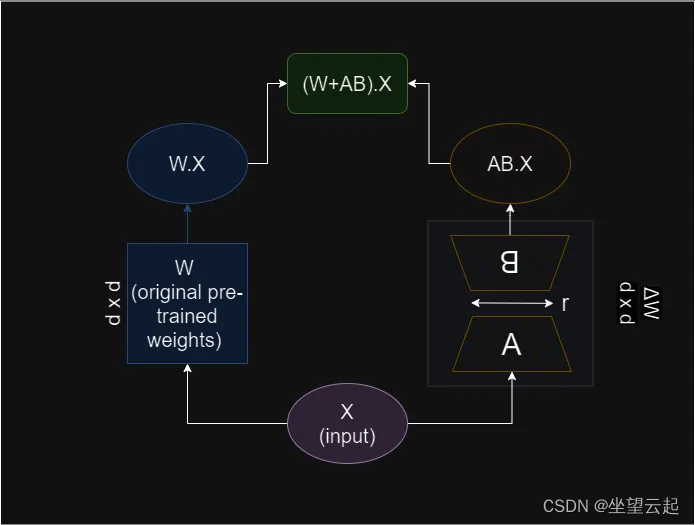
机器学习笔记 - LoRA:大型语言模型的低秩适应
一、简述 1、模型微调 随着大型语言模型 (LLM) 的规模增加到数千亿,对这些模型进行微调成为一项挑战。传统上,要微调模型,我们需要更新所有模型参数。这也称为完全微调 (FFT) 。下图详细概述了此方法的工作原理。 完全微调FFT 的计算成本和资源需求很大,因为更新每…...

基于python实现视频和音频长度对齐合成并添加字幕
在许多视频编辑任务中,我们常常需要将视频和音频进行对齐,并添加字幕。本文将详细介绍如何使用Python实现这一功能,并在视频中添加中文字幕。我们将使用OpenCV处理视频帧,使用MoviePy处理音频和视频的合成,使用PIL库绘…...
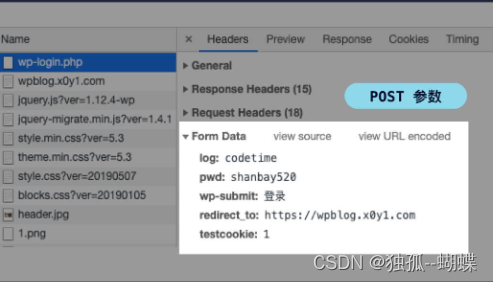
爬虫-模拟登陆博客
import requests from bs4 import BeautifulSoupheaders {user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36 } # 登录参数 login_data {log: codetime,pwd: shanbay520,wp-submit: …...

3步安装ViGEMBus虚拟手柄驱动:让Windows游戏体验全面升级
3步安装ViGEMBus虚拟手柄驱动:让Windows游戏体验全面升级 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows系统上使用任何手柄玩游戏…...
像素史诗落地企业知识库:用Pixel Epic构建内部行业情报自动摘要系统
像素史诗落地企业知识库:用Pixel Epic构建内部行业情报自动摘要系统 1. 企业知识管理的新挑战 在信息爆炸的时代,企业面临的最大挑战不是获取信息,而是如何从海量数据中提取有价值的知识。传统知识管理系统存在几个关键痛点: 信…...

MiniCPM-V-2_6 Ubuntu 20.04一键部署教程:从安装到运行
MiniCPM-V-2_6 Ubuntu 20.04一键部署教程:从安装到运行 想试试那个能看懂图片还能跟你聊天的多模态大模型MiniCPM-V-2_6吗?很多朋友在第一步——部署上就被卡住了,不是环境依赖搞不定,就是权限问题报错,折腾半天模型还…...

Realtek RTL8821CU无线网卡驱动解决方案 - Linux系统WiFi适配完美指南
Realtek RTL8821CU无线网卡驱动解决方案 - Linux系统WiFi适配完美指南 【免费下载链接】rtl8821CU Realtek RTL8811CU/RTL8821CU USB Wi-Fi adapter driver for Linux 项目地址: https://gitcode.com/gh_mirrors/rt/rtl8821CU 你是否在Linux系统上使用Realtek RTL8821CU…...
到底是怎么工作的?)
3GPP TS 23.256标准解读:无人机广播远程识别码(Broadcast Remote ID)到底是怎么工作的?
3GPP TS 23.256标准深度解析:无人机广播远程识别码的技术实现与合规路径 当一架无人机在城市上空盘旋时,地面人员如何快速确认它的合法身份?监管机构又该如何在密集的无线电环境中精准捕捉每一架飞行器的信息?这些问题的答案&…...

挖到宝!阿贝云免费云服务太香了,学生党开发者闭眼冲
做个人博客、练技术、部署轻量应用还在找高性价比云服务?阿贝云https://www.abeiyun.com 直接把免费做到极致,免费虚拟主机 免费云服务器双福利,用下来的体验真的远超预期,稳定不卡顿还免备案,新手操作也毫无门槛太省…...

别再找插件了!手把手教你用uni-app的Canvas API画一个带渐变和刻度的环形进度条
原生Canvas魔法:在uni-app中打造高性能渐变环形进度条 每次看到那些酷炫的数据可视化图表,你是不是也想过自己动手实现?但面对复杂的第三方图表库文档和性能问题又望而却步。今天我要分享的是如何用uni-app原生Canvas API,从零开始…...

SQL Server服务启动失败?手把手教你用Local System账户解决SQLEXPRESS报错126
SQL Server服务启动失败?手把手教你用Local System账户解决SQLEXPRESS报错126 当你正准备开始一天的工作,突然发现SQL Server服务无法启动,屏幕上赫然显示着错误代码126,这种突如其来的技术故障往往让人措手不及。作为数据库管理员…...
)
P3916 图的遍历 题解(反向建图)
更好的阅读体验(博客园) 题面 P3916 图的遍历 题目描述 给出 NNN 个点,MMM 条边的有向图,对于每个点 vvv,令 A(v)A(v)A(v) 表示从点 vvv 出发,能到达的编号最大的点。现在请求出 A(1),A(2),…,A(N)A(1),…...

FanControl进阶指南:从噪音诊断到智能散热系统构建
FanControl进阶指南:从噪音诊断到智能散热系统构建 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...