PythonSQL应用随笔4——PySpark创建SQL临时表
零、前言
Python中直接跑SQL,可以很好的解决数据导过来导过去的问题,本文方法主要针对大运算量时,如何更好地让Python和SQL打好配合。
工具:Zeppelin
语法:PySpark(Apache Spark的Python API)、SparkSQL
数据库类型:Hive
一、相关方法
.createOrReplaceTempView()
在PySpark中,createOrReplaceTempView是一个用于DataFrame的方法,它允许你将DataFrame的内容注册为一个临时的SQL视图,这样就可以在Spark SQL查询中引用这个视图,就像正常查询常规数仓表一样。.toPandas()
最终取数结果,以DataFrame形式输出。
二、实例
Zeppelin中编辑器与Jupyter Notebook类似,以代码块形式呈现,只是需要提前指定好代码块的语言,如:%pyspark;
日常工作中,库存数据是常见的大数据量取数场景,下述代码以取 sku每天的库存 为例展开。
%pyspark
# 工具包及基础配置(视具体情况进行配置,非本文重点,可略过)
import pandas as pd
from pyspark import SparkConf
from pyspark import SparkContext
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from pyspark.sql import SQLContextspark_conf = SparkConf()
spark_conf.setMaster("local[*]")
spark_conf.setAppName("Test")
spark_conf.set("zeppelin.spark.sql.stacktrace", "true")
spark_conf.set('hive.exec.dynamic.partition.mode', 'nonstrict')
spark_conf.set("spark.sql.execution.arrow.enabled", "true")
spark_conf.set("spark.sql.execution.arrow.fallback.enabled", "true")
spark = SparkSession.builder.config(conf=spark_conf).config("zeppelin.spark.sql.stacktrace", "true").enableHiveSupport().getOrCreate()
%pyspark
# 配置取数参数(省事小技巧,避免重复编码,根据实际情况可配置多个参数)
## 开始、结束日期、品牌、……
start_date = '2024-01-01'
end_date = '2024-01-31'
brand = 'brand01'# sql1:日期维表
tmp_dim_date = '''select date_stringfrom edw.dim_datewhere 1=1and date_string >= '{start_date}'and date_string <= '{end_date}''''.format(start_date=start_date, end_date=end_date)
tmp_dim_date = spark.sql(tmp_dim_date).createOrReplaceTempView('tmp_dim_date') # 创建日期临时表:tmp_dim_date# sql2:商品维表
tmp_dim_sku = '''select brand_name,sku_skfrom edw.dim_skuwhere 1=1and brand_name = '{brand}'group by 1, 2'''.format(brand=brand)
tmp_dim_sku = spark.sql(tmp_dim_sku).createOrReplaceTempView('tmp_dim_sku') # 创建sku临时表:tmp_dim_sku# 最终sql:sku每天的库存
sku_stock = '''select tb0.date_string,tb1.sku_sk,sum(coalesce(tb1.stock_qty, 0)) stock_qty -- 库存量from tmp_dim_date tb0 -- 日期临时表left join edw.stock_zipper tb1 -- 库存拉链表on tb1.date_begin <= tb0.date_string -- 开链时间and tb1.date_end > tb0.date_string -- 闭链时间inner join tmp_dim_sku tb2 -- sku临时表on tb1.sku_sk = tb2.sku_skgroup by 1, 2'''
df_sku_stock = spark.sql(tmp_stock_zipper).toPandas()# 删除临时视图(在不需要时及时做垃圾回收,减少资源占用)
spark.catalog.dropTempView("tmp_dim_stockorg")
spark.catalog.dropTempView("tmp_dim_sku")
至此,sku天维度库存数据已取出,实际应用常见可能比本案例复杂许多,故临时表的方法才更重要,一方面能理清楚取数代码的结构,一方面也提高代码性能。
三、总结
NULL
[手动狗头]
本文简短,也没总结的必要,那便在此祝各位新年快乐吧(bushi
相关文章:

PythonSQL应用随笔4——PySpark创建SQL临时表
零、前言 Python中直接跑SQL,可以很好的解决数据导过来导过去的问题,本文方法主要针对大运算量时,如何更好地让Python和SQL打好配合。 工具:Zeppelin 语法:PySpark(Apache Spark的Python API)…...

C# OpenCvSharp 矩阵计算-determinant、trace、eigen、calcCovarMatrix、solve
🚀 在C#中使用OpenCvSharp库进行矩阵操作和图像处理 在C#中使用OpenCvSharp库,可以实现各种矩阵操作和图像处理功能。以下是对所列函数的详细解释和示例,包括运算过程和结果。📊✨ 1. determinant - 计算行列式 🧮 定义: double determinant(InputArray mtx); 参数…...

知识普及:什么是边缘计算(Edge Computing)?
边缘计算是一种分布式计算架构,它将数据处理、存储和服务功能移近数据产生的边缘位置,即接近数据源和用户的位置,而不是依赖中心化的数据中心或云计算平台。边缘计算的核心思想是在靠近终端设备的位置进行数据处理,以降低延迟、减…...

大型企业IT基础架构和应用运维体系
大型企业IT基础架构和应用运维体系 在数字化转型的浪潮中,大型企业面临着日益复杂的IT环境。高效的IT基础架构和应用运维体系,是确保企业业务连续性和竞争力的关键。本文将探讨大型企业如何构建强健的IT基础架构,并建立高效的应用运维体系&a…...
【源码】16国语言交易所源码/币币交易+期权交易+秒合约交易+永续合约+交割合约+新币申购+投资理财/手机端uniapp纯源码+PC纯源码+后端PHP
测试环境:Linux系统CentOS7.6、宝塔面板、Nginx、PHP7.3、MySQL5.6,根目录public,伪静态laravel5,开启ssl证书 语言:16种,看图 这套带前端uniapp纯源码,手机端和pc端都有纯源码,后…...

word空白页删除不了怎么办?
上方菜单栏点击“视图”,下方点击“大纲视图”。找到文档分页符的位置。将光标放在要删除的分节符前,按下键盘上的“Delet”键删除分页符。...
Java web应用性能分析之【prometheus+Grafana监控springboot服务和服务器监控】
Java web应用性能分析之【java进程问题分析概叙】-CSDN博客 Java web应用性能分析之【java进程问题分析工具】-CSDN博客 Java web应用性能分析之【jvisualvm远程连接云服务器】-CSDN博客 Java web应用性能分析之【java进程问题分析定位】-CSDN博客 Java web应用性能分析之【…...

JavaEE——声明式事务管理案例:实现用户登录
一、案例要求 本案例要求在控制台输入用户名密码,如果用户账号密码正确则显示用户所属班级,如果登录失败则显示登录失败。实现用户登录项目运行成功后控制台效果如下所示。 欢迎来到学生管理系统 请输入用户名: zhangsan 请输入zhangsan的密…...

解决用Three.js实现嘴型和语音同步时只能播放部分部位的问题 Three.js同时渲染播放多个组件变形动画的方法
前言 参考这篇文章ThreeJSChatGPT 实现前端3D数字人AI互动,前面搭后端、训练模型组内小伙伴都没有什么问题,到前端的时候,脸部就出问题了。看我是怎么解决的。 好文章啊,可惜百度前几个都找不到,o(╥﹏╥)o 问题情况 …...
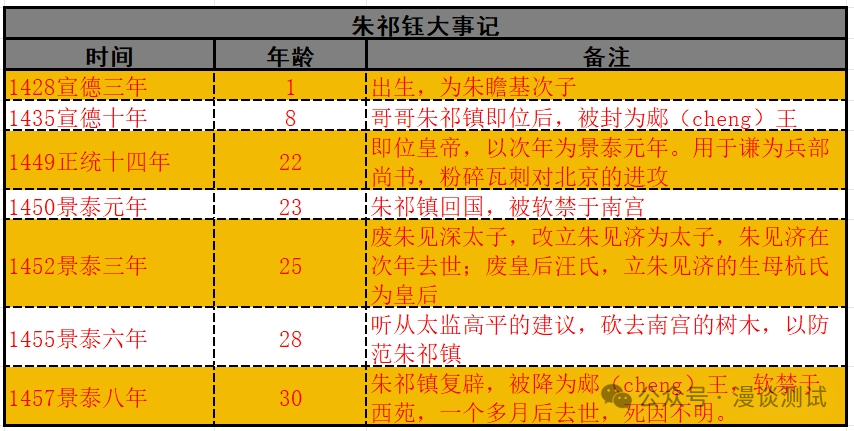
阅读笔记:明朝那些事儿太监弄乱的王朝
阅读豆评高分作品《明朝那些事儿太监弄乱的王朝》第三部,截止到今天告一段落了,前两部皇帝,太子相对比较少,了解故事的主线,分支不算多,记忆起来还能应付过来,第三部皇帝,太子更换的…...
算法第六天:力扣第977题有序数组的平方
一、977.有序数组的平方的链接与题目描述 977. 有序数组的平方的链接如下所示:https://leetcode.cn/problems/squares-of-a-sorted-array/description/https://leetcode.cn/problems/squares-of-a-sorted-array/description/ 给你一个按 非递减顺序 排序的整数数组…...

设计模式学习(二)工厂模式——工厂方法模式
设计模式学习(二)工厂模式——工厂方法模式 前言工厂方法模式简介示例优点缺点使用场景 前言 前一篇文章介绍了简单工厂模式,提到了简单工厂模式的缺点(违反开闭原则,扩展困难),本文要介绍的工…...

TCP与UDP案例
udp不会做拆分整合什么的 多大就是多大...

Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测)
目录 效果一览基本介绍模型设计程序设计参考资料 效果一览 基本介绍 Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测) 模型设计 融合Adaboost的CNN-LSTM模型的时间序列预测,下面是一个基本的框架。 …...

你焦虑了吗
前段时间,无意间在图书馆看到一本书《认知觉醒》,书中提到了焦虑的相关话题,从焦虑的根源,焦虑的形式,如何破解焦虑给了我点启示,分享给一下。 引语: 焦虑肯定是你的老朋友了,它总像…...

一键分析Bulk转录组数据
我们前面介绍了经典的转录组分析流程:Hisat2 Stringtie,可以帮助用户快速获得基因的表达量矩阵。 云上生信,未来已来 | 转录组标准分析流程重磅上线! RNA STAR 也是一款非常流行的转录组数据分析工具。它不仅可以将测序 Reads 比…...
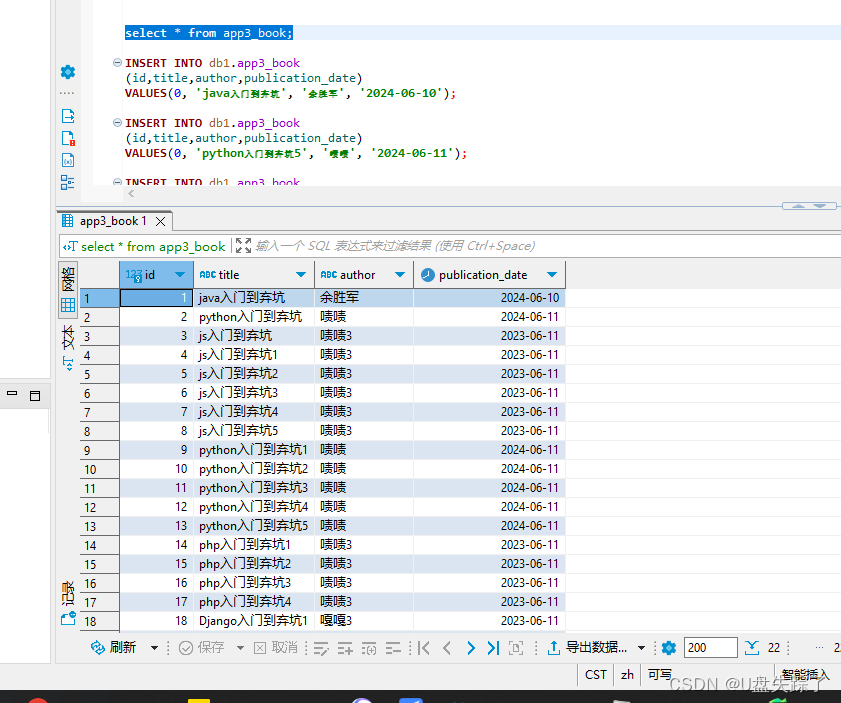
Django DetailView视图
Django的DetailView是一个用于显示单个对象详情的视图。下面是一个使用DetailView来显示单个书籍详情的例子。 1,添加视图 Test/app3/views.py from django.shortcuts import render# Create your views here. from django.views.generic import ListView from .m…...
openGauss学习笔记-300 openGauss AI特性-AI4DB数据库自治运维-DBMind的AI子功能-SQL Rewriter SQL语句改写
文章目录 openGauss学习笔记-300 openGauss AI特性-AI4DB数据库自治运维-DBMind的AI子功能-SQL Rewriter SQL语句改写300.1 概述300.2 使用指导300.2.1 前提条件300.2.2 使用方法示例300.3 获取帮助300.4 命令参考300.5 常见问题处理openGauss学习笔记-300 openGauss AI特性-AI…...

typescript-泛型
typescript-泛型 泛型程序设计是一种编程风格或编程范式,允许在程序中定义形式类型参数,然后再泛型实例化时候使用实际类型参数来替代形式类型参数,通过泛型,可以定义通用的数据结构或类型,这种数据结构或类型仅仅再它…...

应急响应 | 基本技能 | 01-系统排查
系统排查 目录 系统基本信息 Windows系统Linux系统 用户信息 Windows系统 1、命令行方式2、图形界面方法3、注册表方法4、wmic方法 Linux系统 查看所有用户信息分析超级权限账户查看可登录的用户查看用户错误的登录信息查看所有用户最后的登录信息查看用户最近登录信息查看当…...

AI安全自动化测试:FuzzyAI模糊测试框架实战指南
1. 项目概述:当AI安全遇上自动化“模糊测试” 在大型语言模型(LLM)如ChatGPT、Claude、Gemini等日益普及的今天,我们享受其强大能力的同时,也面临着一个严峻的挑战:如何确保它们的安全与可控?你…...

ARM GIC中断控制器架构与关键寄存器详解
1. ARM GIC中断控制器架构概述ARM通用中断控制器(GIC)是现代ARM处理器中负责中断管理的核心组件,它实现了复杂的中断分发和处理机制。GIC架构从v2版本发展到现在的v4版本,功能不断增强,支持多核处理、虚拟化扩展和安全隔离等高级特性。GIC主要…...

离散数学“黑话”指南:命题、谓词、群论,一次讲清程序员常遇到的术语
离散数学“黑话”指南:程序员视角下的概念破译 刚接触算法优化时,我盯着论文里的"幺半群"概念发愣——这和我在代码里写的if-else有什么关系?直到某天用状态机处理用户权限时突然顿悟:原来离散数学的抽象术语࿰…...

基于MCP协议与FFmpeg构建AI视频处理服务器:原理、部署与实战
1. 项目概述:一个面向视频处理的MCP服务器 最近在折腾一些AI应用,发现很多工具在处理视频内容时,总感觉差了那么一口气。要么是功能太单一,只能做简单的剪辑或转码;要么就是流程太复杂,需要把视频下载、处…...

阿里云效前端流水线自动化部署
一、权限准备 如果你想实现这个功能,那么你的云效必须要有权限!!这非常重要!!如何确定自己是否有相关权限呢? 流水线权限 制品仓库权限 就是云服务器的权限,这个权限是要你可以读写文件的…...

2026年国民技术数字IC笔试试卷带答案
满分:100分 时间:90分钟 一、单选题(每题3分,共30分) 1. 在静态时序分析(STA)中,建立时间检查的公式为( ) A. Tclk + Tskew ≥ Tck-q + Tlogic + Tsetup B. Tclk - Tskew ≥ Tck-q + Tlogic + Tsetup C. Tclk ≥ Tck-q + Tlogic - Tsetup D. Tlogic ≥ Tsetup + Tho…...

别再乱装驱动了!Ubuntu 20.04显卡驱动‘掉了’的终极排查与修复思路
Ubuntu 20.04显卡驱动失效的系统化诊断与修复指南 当你正专注于一个重要项目时,突然发现Ubuntu的NVIDIA显卡驱动"神秘消失"——这种体验对Linux用户来说简直像一场噩梦。nvidia-smi命令返回"驱动未加载",外接显示器黑屏,…...

AI编程助手效率革命:结构化配置与提示词工程实战
1. 项目概述:一个为AI编程时代量身定制的开发者工具箱如果你和我一样,日常开发已经离不开像 Cursor 和 Claude 这样的 AI 编程助手,那你肯定也遇到过类似的困扰:每次开启一个新项目,或者在不同项目间切换时,…...
)
别再想当然!用AD628/INA等差分放大器做单端采集,必须搞懂的共模电压计算(附Excel工具)
差分放大器单端采集实战指南:共模电压计算与设计避坑 在工业传感器接口和医疗设备信号链设计中,差分放大器常被用于单端信号采集的场景。许多工程师习惯性地认为,只要将差分放大器的负输入端接地,就能轻松实现单端转差分功能。但实…...

Windows 10/11 下 Node.js 安装踩坑实录:为鸿蒙HarmonyOS开发扫清环境障碍
Windows 10/11 下 Node.js 安装踩坑实录:为鸿蒙HarmonyOS开发扫清环境障碍 当你在Windows系统上准备搭建鸿蒙HarmonyOS开发环境时,Node.js的安装往往是第一个拦路虎。不同于官方文档中"下一步到底"的理想化流程,真实场景中你会遇到…...