【HiveSQL】join关联on和where的区别及效率对比
测试环境:hive on spark
spark版本:3.3.1
- 一、执行时机
- 二、对结果集的影响
- 三、效率对比
- 1.内连接
- 1)on
- 2)where
- 2.外连接
- 1)on
- 2)where
- 四、总结
- PS
一、执行时机
sql连接中,where属于过滤条件,用于对join的结果集进行过滤,所以理论上的执行时机在join之后。on属于关联条件,决定了满足什么样条件的数据才可以被关联到一起,因此理论上的执行时机在join时。
但是,大多数数据库系统为了提升效率都采用了一些优化技术,思想都是将where中的筛选条件或是on中的关联条件尽可能的提前到数据源侧进行筛选,目的是减少参与关联的数据量。因此它们实际的执行时机大多时候和理论上的不同。
二、对结果集的影响
内连接中,条件放在where或者on中对结果集无影响。
外连接中(以左外连接为例),因为左外连接是完全保留左表记录,on在join时生效,因此最终的结果集也会保留左表的全部记录。where是对join后的结果集进行操作,所以会过滤掉一些数据导致二者的结果集不相同。
三、效率对比
测试数据量如下:
poi_data.poi_res表:数据量8300W+
bi_report.mon_ronghe_pv表:分区表,总数据量120E+,本次采用分区20240522的数据关联,数据量5900W+,其中 bid like ‘1%’ & pv>100 的数据量120W+
两表的关联字段均无重复值。
1.内连接
1)on
selectt1.bid,t1.name,t1.point_x,t1.point_y,t2.pv
from poi_data.poi_res t1
join (select bid, pv from bi_report.mon_ronghe_pv where event_day='20240522') t2
on t1.bid=t2.bid
and t2.bid like '1%' and t2.pv>100;
== Physical Plan ==
AdaptiveSparkPlan (28)
+- == Final Plan ==CollectLimit (17)+- * Project (16)+- * SortMergeJoin Inner (15):- * Sort (6): +- AQEShuffleRead (5): +- ShuffleQueryStage (4), Statistics(sizeInBytes=5.3 GiB, rowCount=4.57E+7): +- Exchange (3): +- * Filter (2): +- Scan hive poi_data.poi_res (1)+- * Sort (14)+- AQEShuffleRead (13)+- ShuffleQueryStage (12), Statistics(sizeInBytes=58.5 MiB, rowCount=1.28E+6)+- Exchange (11)+- * Project (10)+- * Filter (9)+- * ColumnarToRow (8)+- Scan parquet bi_report.mon_ronghe_pv (7)
+- == Initial Plan ==CollectLimit (27)+- Project (26)+- SortMergeJoin Inner (25):- Sort (20): +- Exchange (19): +- Filter (18): +- Scan hive poi_data.poi_res (1)+- Sort (24)+- Exchange (23)+- Project (22)+- Filter (21)+- Scan parquet bi_report.mon_ronghe_pv (7)(1) Scan hive poi_data.poi_res
Output [4]: [bid#297, name#299, point_x#316, point_y#317]
Arguments: [bid#297, name#299, point_x#316, point_y#317], HiveTableRelation [`poi_data`.`poi_res`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [bid#297, type#298, name#299, address#300, phone#301, alias#302, post_code#303, catalog_id#304, c..., Partition Cols: []](2) Filter [codegen id : 1]
Input [4]: [bid#297, name#299, point_x#316, point_y#317]
Condition : (StartsWith(bid#297, 1) AND isnotnull(bid#297))(3) Exchange
Input [4]: [bid#297, name#299, point_x#316, point_y#317]
Arguments: hashpartitioning(bid#297, 600), ENSURE_REQUIREMENTS, [plan_id=774](4) ShuffleQueryStage
Output [4]: [bid#297, name#299, point_x#316, point_y#317]
Arguments: 0(5) AQEShuffleRead
Input [4]: [bid#297, name#299, point_x#316, point_y#317]
Arguments: coalesced(6) Sort [codegen id : 3]
Input [4]: [bid#297, name#299, point_x#316, point_y#317]
Arguments: [bid#297 ASC NULLS FIRST], false, 0(7) Scan parquet bi_report.mon_ronghe_pv
Output [3]: [bid#334, pv#335, event_day#338]
Batched: true
Location: InMemoryFileIndex [afs://kunpeng.afs.baidu.com:9902/user/g_spark_rdw/rdw/poi_engine/warehouse/bi_report.db/mon_ronghe_pv/event_day=20240522]
PartitionFilters: [isnotnull(event_day#338), (event_day#338 = 20240522)]
PushedFilters: [IsNotNull(bid), IsNotNull(pv), StringStartsWith(bid,1), GreaterThan(pv,100)]
ReadSchema: struct<bid:string,pv:int>(8) ColumnarToRow [codegen id : 2]
Input [3]: [bid#334, pv#335, event_day#338](9) Filter [codegen id : 2]
Input [3]: [bid#334, pv#335, event_day#338]
Condition : (((isnotnull(bid#334) AND isnotnull(pv#335)) AND StartsWith(bid#334, 1)) AND (pv#335 > 100))(10) Project [codegen id : 2]
Output [2]: [bid#334, pv#335]
Input [3]: [bid#334, pv#335, event_day#338](11) Exchange
Input [2]: [bid#334, pv#335]
Arguments: hashpartitioning(bid#334, 600), ENSURE_REQUIREMENTS, [plan_id=799](12) ShuffleQueryStage
Output [2]: [bid#334, pv#335]
Arguments: 1(13) AQEShuffleRead
Input [2]: [bid#334, pv#335]
Arguments: coalesced(14) Sort [codegen id : 4]
Input [2]: [bid#334, pv#335]
Arguments: [bid#334 ASC NULLS FIRST], false, 0(15) SortMergeJoin [codegen id : 5]
Left keys [1]: [bid#297]
Right keys [1]: [bid#334]
Join condition: None(16) Project [codegen id : 5]
Output [5]: [bid#297, name#299, point_x#316, point_y#317, pv#335]
Input [6]: [bid#297, name#299, point_x#316, point_y#317, bid#334, pv#335](17) CollectLimit
Input [5]: [bid#297, name#299, point_x#316, point_y#317, pv#335]
Arguments: 1000(18) Filter
Input [4]: [bid#297, name#299, point_x#316, point_y#317]
Condition : (StartsWith(bid#297, 1) AND isnotnull(bid#297))(19) Exchange
Input [4]: [bid#297, name#299, point_x#316, point_y#317]
Arguments: hashpartitioning(bid#297, 600), ENSURE_REQUIREMENTS, [plan_id=759](20) Sort
Input [4]: [bid#297, name#299, point_x#316, point_y#317]
Arguments: [bid#297 ASC NULLS FIRST], false, 0(21) Filter
Input [3]: [bid#334, pv#335, event_day#338]
Condition : (((isnotnull(bid#334) AND isnotnull(pv#335)) AND StartsWith(bid#334, 1)) AND (pv#335 > 100))(22) Project
Output [2]: [bid#334, pv#335]
Input [3]: [bid#334, pv#335, event_day#338](23) Exchange
Input [2]: [bid#334, pv#335]
Arguments: hashpartitioning(bid#334, 600), ENSURE_REQUIREMENTS, [plan_id=760](24) Sort
Input [2]: [bid#334, pv#335]
Arguments: [bid#334 ASC NULLS FIRST], false, 0(25) SortMergeJoin
Left keys [1]: [bid#297]
Right keys [1]: [bid#334]
Join condition: None(26) Project
Output [5]: [bid#297, name#299, point_x#316, point_y#317, pv#335]
Input [6]: [bid#297, name#299, point_x#316, point_y#317, bid#334, pv#335](27) CollectLimit
Input [5]: [bid#297, name#299, point_x#316, point_y#317, pv#335]
Arguments: 1000(28) AdaptiveSparkPlan
Output [5]: [bid#297, name#299, point_x#316, point_y#317, pv#335]
Arguments: isFinalPlan=true
从物理执行计划可以看到第(2)步中的Filter使用条件Condition : (StartsWith(bid#297, 1) AND isnotnull(bid#297))在t1表读取源数据时进行了过滤,在第(7)步中通过谓词下推在t2表scan源数据时使用条件PushedFilters: [IsNotNull(bid), IsNotNull(pv), StringStartsWith(bid,1), GreaterThan(pv,100)]进行了过滤,两表都是在数据源侧进行的数据过滤,减少了shuffle和参与join的数据量。
2)where
selectt1.bid,t1.name,t1.point_x,t1.point_y,t2.pv
from poi_data.poi_res t1
join (select bid, pv from bi_report.mon_ronghe_pv where event_day='20240522') t2
on t1.bid=t2.bid
where t2.bid like '1%' and t2.pv>100;
== Physical Plan ==
AdaptiveSparkPlan (28)
+- == Final Plan ==CollectLimit (17)+- * Project (16)+- * SortMergeJoin Inner (15):- * Sort (6): +- AQEShuffleRead (5): +- ShuffleQueryStage (4), Statistics(sizeInBytes=5.3 GiB, rowCount=4.57E+7): +- Exchange (3): +- * Filter (2): +- Scan hive poi_data.poi_res (1)+- * Sort (14)+- AQEShuffleRead (13)+- ShuffleQueryStage (12), Statistics(sizeInBytes=58.5 MiB, rowCount=1.28E+6)+- Exchange (11)+- * Project (10)+- * Filter (9)+- * ColumnarToRow (8)+- Scan parquet bi_report.mon_ronghe_pv (7)
+- == Initial Plan ==CollectLimit (27)+- Project (26)+- SortMergeJoin Inner (25):- Sort (20): +- Exchange (19): +- Filter (18): +- Scan hive poi_data.poi_res (1)+- Sort (24)+- Exchange (23)+- Project (22)+- Filter (21)+- Scan parquet bi_report.mon_ronghe_pv (7)(1) Scan hive poi_data.poi_res
Output [4]: [bid#350, name#352, point_x#369, point_y#370]
Arguments: [bid#350, name#352, point_x#369, point_y#370], HiveTableRelation [`poi_data`.`poi_res`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [bid#350, type#351, name#352, address#353, phone#354, alias#355, post_code#356, catalog_id#357, c..., Partition Cols: []](2) Filter [codegen id : 1]
Input [4]: [bid#350, name#352, point_x#369, point_y#370]
Condition : (StartsWith(bid#350, 1) AND isnotnull(bid#350))(3) Exchange
Input [4]: [bid#350, name#352, point_x#369, point_y#370]
Arguments: hashpartitioning(bid#350, 600), ENSURE_REQUIREMENTS, [plan_id=908](4) ShuffleQueryStage
Output [4]: [bid#350, name#352, point_x#369, point_y#370]
Arguments: 0(5) AQEShuffleRead
Input [4]: [bid#350, name#352, point_x#369, point_y#370]
Arguments: coalesced(6) Sort [codegen id : 3]
Input [4]: [bid#350, name#352, point_x#369, point_y#370]
Arguments: [bid#350 ASC NULLS FIRST], false, 0(7) Scan parquet bi_report.mon_ronghe_pv
Output [3]: [bid#387, pv#388, event_day#391]
Batched: true
Location: InMemoryFileIndex [afs://kunpeng.afs.baidu.com:9902/user/g_spark_rdw/rdw/poi_engine/warehouse/bi_report.db/mon_ronghe_pv/event_day=20240522]
PartitionFilters: [isnotnull(event_day#391), (event_day#391 = 20240522)]
PushedFilters: [IsNotNull(bid), IsNotNull(pv), StringStartsWith(bid,1), GreaterThan(pv,100)]
ReadSchema: struct<bid:string,pv:int>(8) ColumnarToRow [codegen id : 2]
Input [3]: [bid#387, pv#388, event_day#391](9) Filter [codegen id : 2]
Input [3]: [bid#387, pv#388, event_day#391]
Condition : (((isnotnull(bid#387) AND isnotnull(pv#388)) AND StartsWith(bid#387, 1)) AND (pv#388 > 100))(10) Project [codegen id : 2]
Output [2]: [bid#387, pv#388]
Input [3]: [bid#387, pv#388, event_day#391](11) Exchange
Input [2]: [bid#387, pv#388]
Arguments: hashpartitioning(bid#387, 600), ENSURE_REQUIREMENTS, [plan_id=933](12) ShuffleQueryStage
Output [2]: [bid#387, pv#388]
Arguments: 1(13) AQEShuffleRead
Input [2]: [bid#387, pv#388]
Arguments: coalesced(14) Sort [codegen id : 4]
Input [2]: [bid#387, pv#388]
Arguments: [bid#387 ASC NULLS FIRST], false, 0(15) SortMergeJoin [codegen id : 5]
Left keys [1]: [bid#350]
Right keys [1]: [bid#387]
Join condition: None(16) Project [codegen id : 5]
Output [5]: [bid#350, name#352, point_x#369, point_y#370, pv#388]
Input [6]: [bid#350, name#352, point_x#369, point_y#370, bid#387, pv#388](17) CollectLimit
Input [5]: [bid#350, name#352, point_x#369, point_y#370, pv#388]
Arguments: 1000(18) Filter
Input [4]: [bid#350, name#352, point_x#369, point_y#370]
Condition : (StartsWith(bid#350, 1) AND isnotnull(bid#350))(19) Exchange
Input [4]: [bid#350, name#352, point_x#369, point_y#370]
Arguments: hashpartitioning(bid#350, 600), ENSURE_REQUIREMENTS, [plan_id=893](20) Sort
Input [4]: [bid#350, name#352, point_x#369, point_y#370]
Arguments: [bid#350 ASC NULLS FIRST], false, 0(21) Filter
Input [3]: [bid#387, pv#388, event_day#391]
Condition : (((isnotnull(bid#387) AND isnotnull(pv#388)) AND StartsWith(bid#387, 1)) AND (pv#388 > 100))(22) Project
Output [2]: [bid#387, pv#388]
Input [3]: [bid#387, pv#388, event_day#391](23) Exchange
Input [2]: [bid#387, pv#388]
Arguments: hashpartitioning(bid#387, 600), ENSURE_REQUIREMENTS, [plan_id=894](24) Sort
Input [2]: [bid#387, pv#388]
Arguments: [bid#387 ASC NULLS FIRST], false, 0(25) SortMergeJoin
Left keys [1]: [bid#350]
Right keys [1]: [bid#387]
Join condition: None(26) Project
Output [5]: [bid#350, name#352, point_x#369, point_y#370, pv#388]
Input [6]: [bid#350, name#352, point_x#369, point_y#370, bid#387, pv#388](27) CollectLimit
Input [5]: [bid#350, name#352, point_x#369, point_y#370, pv#388]
Arguments: 1000(28) AdaptiveSparkPlan
Output [5]: [bid#350, name#352, point_x#369, point_y#370, pv#388]
Arguments: isFinalPlan=true
物理执行计划没有变化,因此可以说,当数据库支持谓词下推时,筛选条件用where还是on没有区别,数据库都会在数据源侧进行数据过滤,减少参与关联的数据量。
2.外连接
1)on
selectt1.bid,t1.name,t1.point_x,t1.point_y,t2.pv
from poi_data.poi_res t1
left join (select bid, pv from bi_report.mon_ronghe_pv where event_day='20240522') t2
on t1.bid=t2.bid
and t2.bid like '1%' and t2.pv>100;
== Physical Plan ==
AdaptiveSparkPlan (28)
+- == Final Plan ==CollectLimit (17)+- * Project (16)+- * SortMergeJoin LeftOuter (15):- * Sort (6): +- AQEShuffleRead (5): +- ShuffleQueryStage (4), Statistics(sizeInBytes=36.5 MiB, rowCount=3.07E+5): +- Exchange (3): +- * LocalLimit (2): +- Scan hive poi_data.poi_res (1)+- * Sort (14)+- AQEShuffleRead (13)+- ShuffleQueryStage (12), Statistics(sizeInBytes=58.5 MiB, rowCount=1.28E+6)+- Exchange (11)+- * Project (10)+- * Filter (9)+- * ColumnarToRow (8)+- Scan parquet bi_report.mon_ronghe_pv (7)
+- == Initial Plan ==CollectLimit (27)+- Project (26)+- SortMergeJoin LeftOuter (25):- Sort (20): +- Exchange (19): +- LocalLimit (18): +- Scan hive poi_data.poi_res (1)+- Sort (24)+- Exchange (23)+- Project (22)+- Filter (21)+- Scan parquet bi_report.mon_ronghe_pv (7)(1) Scan hive poi_data.poi_res
Output [4]: [bid#403, name#405, point_x#422, point_y#423]
Arguments: [bid#403, name#405, point_x#422, point_y#423], HiveTableRelation [`poi_data`.`poi_res`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [bid#403, type#404, name#405, address#406, phone#407, alias#408, post_code#409, catalog_id#410, c..., Partition Cols: []](2) LocalLimit [codegen id : 1]
Input [4]: [bid#403, name#405, point_x#422, point_y#423]
Arguments: 1000(3) Exchange
Input [4]: [bid#403, name#405, point_x#422, point_y#423]
Arguments: hashpartitioning(bid#403, 600), ENSURE_REQUIREMENTS, [plan_id=1043](4) ShuffleQueryStage
Output [4]: [bid#403, name#405, point_x#422, point_y#423]
Arguments: 0(5) AQEShuffleRead
Input [4]: [bid#403, name#405, point_x#422, point_y#423]
Arguments: coalesced(6) Sort [codegen id : 3]
Input [4]: [bid#403, name#405, point_x#422, point_y#423]
Arguments: [bid#403 ASC NULLS FIRST], false, 0(7) Scan parquet bi_report.mon_ronghe_pv
Output [3]: [bid#440, pv#441, event_day#444]
Batched: true
Location: InMemoryFileIndex [afs://kunpeng.afs.baidu.com:9902/user/g_spark_rdw/rdw/poi_engine/warehouse/bi_report.db/mon_ronghe_pv/event_day=20240522]
PartitionFilters: [isnotnull(event_day#444), (event_day#444 = 20240522)]
PushedFilters: [IsNotNull(bid), IsNotNull(pv), StringStartsWith(bid,1), GreaterThan(pv,100)]
ReadSchema: struct<bid:string,pv:int>(8) ColumnarToRow [codegen id : 2]
Input [3]: [bid#440, pv#441, event_day#444](9) Filter [codegen id : 2]
Input [3]: [bid#440, pv#441, event_day#444]
Condition : (((isnotnull(bid#440) AND isnotnull(pv#441)) AND StartsWith(bid#440, 1)) AND (pv#441 > 100))(10) Project [codegen id : 2]
Output [2]: [bid#440, pv#441]
Input [3]: [bid#440, pv#441, event_day#444](11) Exchange
Input [2]: [bid#440, pv#441]
Arguments: hashpartitioning(bid#440, 600), ENSURE_REQUIREMENTS, [plan_id=1067](12) ShuffleQueryStage
Output [2]: [bid#440, pv#441]
Arguments: 1(13) AQEShuffleRead
Input [2]: [bid#440, pv#441]
Arguments: coalesced(14) Sort [codegen id : 4]
Input [2]: [bid#440, pv#441]
Arguments: [bid#440 ASC NULLS FIRST], false, 0(15) SortMergeJoin [codegen id : 5]
Left keys [1]: [bid#403]
Right keys [1]: [bid#440]
Join condition: None(16) Project [codegen id : 5]
Output [5]: [bid#403, name#405, point_x#422, point_y#423, pv#441]
Input [6]: [bid#403, name#405, point_x#422, point_y#423, bid#440, pv#441](17) CollectLimit
Input [5]: [bid#403, name#405, point_x#422, point_y#423, pv#441]
Arguments: 1000(18) LocalLimit
Input [4]: [bid#403, name#405, point_x#422, point_y#423]
Arguments: 1000(19) Exchange
Input [4]: [bid#403, name#405, point_x#422, point_y#423]
Arguments: hashpartitioning(bid#403, 600), ENSURE_REQUIREMENTS, [plan_id=1029](20) Sort
Input [4]: [bid#403, name#405, point_x#422, point_y#423]
Arguments: [bid#403 ASC NULLS FIRST], false, 0(21) Filter
Input [3]: [bid#440, pv#441, event_day#444]
Condition : (((isnotnull(bid#440) AND isnotnull(pv#441)) AND StartsWith(bid#440, 1)) AND (pv#441 > 100))(22) Project
Output [2]: [bid#440, pv#441]
Input [3]: [bid#440, pv#441, event_day#444](23) Exchange
Input [2]: [bid#440, pv#441]
Arguments: hashpartitioning(bid#440, 600), ENSURE_REQUIREMENTS, [plan_id=1030](24) Sort
Input [2]: [bid#440, pv#441]
Arguments: [bid#440 ASC NULLS FIRST], false, 0(25) SortMergeJoin
Left keys [1]: [bid#403]
Right keys [1]: [bid#440]
Join condition: None(26) Project
Output [5]: [bid#403, name#405, point_x#422, point_y#423, pv#441]
Input [6]: [bid#403, name#405, point_x#422, point_y#423, bid#440, pv#441](27) CollectLimit
Input [5]: [bid#403, name#405, point_x#422, point_y#423, pv#441]
Arguments: 1000(28) AdaptiveSparkPlan
Output [5]: [bid#403, name#405, point_x#422, point_y#423, pv#441]
Arguments: isFinalPlan=true
因为左关联,on中的条件属于连接条件,结果需要保留左表全部记录,所以t1表全量读取,t2表使用了谓词下推过滤。
2)where
selectt1.bid,t1.name,t1.point_x,t1.point_y,t2.pv
from poi_data.poi_res t1
left join (select bid, pv from bi_report.mon_ronghe_pv where event_day='20240522') t2
on t1.bid=t2.bid
where t2.bid like '1%' and t2.pv>100;
== Physical Plan ==
AdaptiveSparkPlan (28)
+- == Final Plan ==CollectLimit (17)+- * Project (16)+- * SortMergeJoin Inner (15):- * Sort (6): +- AQEShuffleRead (5): +- ShuffleQueryStage (4), Statistics(sizeInBytes=5.3 GiB, rowCount=4.57E+7): +- Exchange (3): +- * Filter (2): +- Scan hive poi_data.poi_res (1)+- * Sort (14)+- AQEShuffleRead (13)+- ShuffleQueryStage (12), Statistics(sizeInBytes=58.5 MiB, rowCount=1.28E+6)+- Exchange (11)+- * Project (10)+- * Filter (9)+- * ColumnarToRow (8)+- Scan parquet bi_report.mon_ronghe_pv (7)
+- == Initial Plan ==CollectLimit (27)+- Project (26)+- SortMergeJoin Inner (25):- Sort (20): +- Exchange (19): +- Filter (18): +- Scan hive poi_data.poi_res (1)+- Sort (24)+- Exchange (23)+- Project (22)+- Filter (21)+- Scan parquet bi_report.mon_ronghe_pv (7)(1) Scan hive poi_data.poi_res
Output [4]: [bid#456, name#458, point_x#475, point_y#476]
Arguments: [bid#456, name#458, point_x#475, point_y#476], HiveTableRelation [`poi_data`.`poi_res`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, Data Cols: [bid#456, type#457, name#458, address#459, phone#460, alias#461, post_code#462, catalog_id#463, c..., Partition Cols: []](2) Filter [codegen id : 1]
Input [4]: [bid#456, name#458, point_x#475, point_y#476]
Condition : (StartsWith(bid#456, 1) AND isnotnull(bid#456))(3) Exchange
Input [4]: [bid#456, name#458, point_x#475, point_y#476]
Arguments: hashpartitioning(bid#456, 600), ENSURE_REQUIREMENTS, [plan_id=1176](4) ShuffleQueryStage
Output [4]: [bid#456, name#458, point_x#475, point_y#476]
Arguments: 0(5) AQEShuffleRead
Input [4]: [bid#456, name#458, point_x#475, point_y#476]
Arguments: coalesced(6) Sort [codegen id : 3]
Input [4]: [bid#456, name#458, point_x#475, point_y#476]
Arguments: [bid#456 ASC NULLS FIRST], false, 0(7) Scan parquet bi_report.mon_ronghe_pv
Output [3]: [bid#493, pv#494, event_day#497]
Batched: true
Location: InMemoryFileIndex [afs://kunpeng.afs.baidu.com:9902/user/g_spark_rdw/rdw/poi_engine/warehouse/bi_report.db/mon_ronghe_pv/event_day=20240522]
PartitionFilters: [isnotnull(event_day#497), (event_day#497 = 20240522)]
PushedFilters: [IsNotNull(bid), IsNotNull(pv), StringStartsWith(bid,1), GreaterThan(pv,100)]
ReadSchema: struct<bid:string,pv:int>(8) ColumnarToRow [codegen id : 2]
Input [3]: [bid#493, pv#494, event_day#497](9) Filter [codegen id : 2]
Input [3]: [bid#493, pv#494, event_day#497]
Condition : (((isnotnull(bid#493) AND isnotnull(pv#494)) AND StartsWith(bid#493, 1)) AND (pv#494 > 100))(10) Project [codegen id : 2]
Output [2]: [bid#493, pv#494]
Input [3]: [bid#493, pv#494, event_day#497](11) Exchange
Input [2]: [bid#493, pv#494]
Arguments: hashpartitioning(bid#493, 600), ENSURE_REQUIREMENTS, [plan_id=1201](12) ShuffleQueryStage
Output [2]: [bid#493, pv#494]
Arguments: 1(13) AQEShuffleRead
Input [2]: [bid#493, pv#494]
Arguments: coalesced(14) Sort [codegen id : 4]
Input [2]: [bid#493, pv#494]
Arguments: [bid#493 ASC NULLS FIRST], false, 0(15) SortMergeJoin [codegen id : 5]
Left keys [1]: [bid#456]
Right keys [1]: [bid#493]
Join condition: None(16) Project [codegen id : 5]
Output [5]: [bid#456, name#458, point_x#475, point_y#476, pv#494]
Input [6]: [bid#456, name#458, point_x#475, point_y#476, bid#493, pv#494](17) CollectLimit
Input [5]: [bid#456, name#458, point_x#475, point_y#476, pv#494]
Arguments: 1000(18) Filter
Input [4]: [bid#456, name#458, point_x#475, point_y#476]
Condition : (StartsWith(bid#456, 1) AND isnotnull(bid#456))(19) Exchange
Input [4]: [bid#456, name#458, point_x#475, point_y#476]
Arguments: hashpartitioning(bid#456, 600), ENSURE_REQUIREMENTS, [plan_id=1161](20) Sort
Input [4]: [bid#456, name#458, point_x#475, point_y#476]
Arguments: [bid#456 ASC NULLS FIRST], false, 0(21) Filter
Input [3]: [bid#493, pv#494, event_day#497]
Condition : (((isnotnull(bid#493) AND isnotnull(pv#494)) AND StartsWith(bid#493, 1)) AND (pv#494 > 100))(22) Project
Output [2]: [bid#493, pv#494]
Input [3]: [bid#493, pv#494, event_day#497](23) Exchange
Input [2]: [bid#493, pv#494]
Arguments: hashpartitioning(bid#493, 600), ENSURE_REQUIREMENTS, [plan_id=1162](24) Sort
Input [2]: [bid#493, pv#494]
Arguments: [bid#493 ASC NULLS FIRST], false, 0(25) SortMergeJoin
Left keys [1]: [bid#456]
Right keys [1]: [bid#493]
Join condition: None(26) Project
Output [5]: [bid#456, name#458, point_x#475, point_y#476, pv#494]
Input [6]: [bid#456, name#458, point_x#475, point_y#476, bid#493, pv#494](27) CollectLimit
Input [5]: [bid#456, name#458, point_x#475, point_y#476, pv#494]
Arguments: 1000(28) AdaptiveSparkPlan
Output [5]: [bid#456, name#458, point_x#475, point_y#476, pv#494]
Arguments: isFinalPlan=true
where属于过滤条件,影响左关联的最终结果,所以执行计划第(2)步中将where提前到join关联之前按照bid对t1表进行过滤。
四、总结
假设数据库系统支持谓词下推的前提下,
- 内连接:内连接的两个执行计划中,对t2表都使用了
PushedFilters: [IsNotNull(bid), IsNotNull(pv), StringStartsWith(bid,1), GreaterThan(pv,100)],对t1表都使用了Condition : (StartsWith(bid#297, 1) AND isnotnull(bid#297)),因此可以说,内连接中where和on在执行效率上没区别。 - 外连接:还是拿左外连接来说,右表相关的条件会使用谓词下推,而左表是否会提前过滤数据,取决于where还是on以及筛选条件是否与左表相关,1)当为on时,左表的数据必须全量读取,此时效率的差别主要取决于左表的数据量。2)当为where时,如果筛选条件涉及到左表,则会进行数据的提前过滤,否则左表仍然全量读取。
PS
在内连接的物理执行计划中,对poi_res表的过滤单独作为一个Filter步骤(2)Condition : (StartsWith(bid#297, 1) AND isnotnull(bid#297)),而对mon_ronghe_pv表的过滤在第(7)步scan中PushedFilters: [IsNotNull(bid), IsNotNull(pv), StringStartsWith(bid,1), GreaterThan(pv,100)] ,二者有什么区别?查了一些资料,说的是可以将PushedFilters理解为在读取数据时的过滤,不满足条件的数据直接不读取。Filter时将数据读取之后,再判断是否满足条件,决定是否参与后续计算。
既然都是在数据源侧进行数据过滤,为什么Filter不能像PushedFilters那样,直接在读取数据的时候判断,减少读入的数据量呢,这样也可以提升效率,这是一开始个人的疑问。查了一些资料,说的是是否支持在scan时filter数据,主要受数据源的影响。大数据中的存储方式主要分为行式存储和列式存储,列式存储的数据存储方式和丰富的元数据对谓词下推技术有更好的支持。当前测试中,mon_ronghe_pv表的存储格式为parquet,poi_res表存储格式text。
相关文章:

【HiveSQL】join关联on和where的区别及效率对比
测试环境:hive on spark spark版本:3.3.1 一、执行时机二、对结果集的影响三、效率对比1.内连接1)on2)where 2.外连接1)on2)where 四、总结PS 一、执行时机 sql连接中,where属于过滤条件&#…...
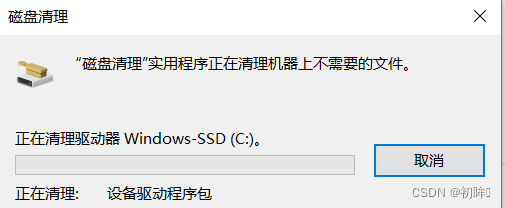
如何解决windows自动更新,释放C盘更新内存
第一步:首先关闭windows自动更新组件 没有更新windows需求,为了防止windows自动更新,挤占C盘空间,所以我们要采取停止Windows Update服务。按下WinR打开运行对话框,输入services.msc, 然后按Enter。在服务…...
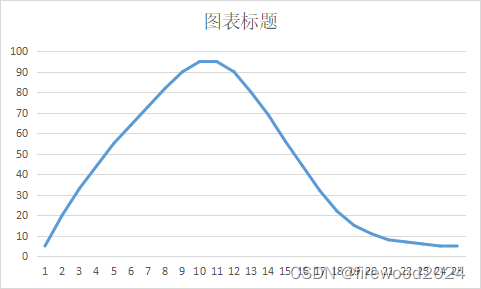
初学51单片机之PWM实例呼吸灯以及遇到的问题(已解答)
PWM全名Pulse Width Modulation中文称呼脉冲宽度调制 如图 这是一个周期10ms、频率是100HZ的波形,但是每个周期内,高低电平宽度各不相同,这就是PWM的本质。 占空比是指高电平占整个周期的比列,上图第一个波形的占空比是40%,第二个…...

手机天线都去哪里了?
在手机的演变历程中,天线的设计和位置一直是工程师们不断探索和创新的领域。你是否好奇,现在的手机为什么看不到那些曾经显眼的天线了呢? 让我们一起揭开这个谜题。 首先,让我们从基础开始:手机是如何发出电磁波的&…...

计算机网络 —— 应用层(电子邮件)
计算机网络 —— 应用层(电子邮件) 电子邮件发送电子邮件的过程SMTP特性工作流程 电子邮件格式MIME关键组件工作方式 POP/IMAPPOP(邮局协议)IMAP(因特网邮件访问协议) 基于万维网的电子邮箱特点优势常见的基…...
)
Java18新特性(极简)
一、引言 自1995年Java语言首次亮相以来,它已经成为企业级应用、移动应用和游戏开发等领域不可或缺的一部分。随着技术的不断进步,Java也在持续演化,每个新版本都带来了诸多新特性和性能优化,旨在提升开发者的编程效率和应用程序的…...

vscode连接ssh远程服务器
当使用Visual Studio Code (VSCode) 连接SSH远程服务器时,可以遵循以下步骤。这些步骤将帮助你设置并连接到远程服务器,包括免密登录的设置(如果需要)。 一、安装并配置Remote-SSH插件 下载并安装VSCode:确保你已经下…...

【趣味测试】
编程过程中遇到的趣味知识 1 Cpp 1.1 浮点数计算 if (0.1 0.2 0.3) {std::cout << "0.1 0.2 0.3 true" << std::endl;} else {std::cout << "0.1 0.2 0.3 false" << std::endl;}if (0.1 0.3 0.4) {std::cout << &…...

数据结构经典面试之数组——C#和C++篇
文章目录 1. 数组的基本概念与功能2. C#数组创建数组访问数组元素修改数组元素数组排序 3. C数组创建数组访问数组元素修改数组元素数组排序 4. 数组的实际应用与性能优化5. C#数组示例6. C数组示例总结 数组是编程中常用的数据结构之一,它用于存储一系列相同类型的…...

docker的基本知识
文章目录 前言docker的基本知识1. docker 的底层逻辑2. docker 的核心要素2.1. 镜像的基本概念:2.2. 容器的基本概念:2.3. 仓库的基本概念: 前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 …...

React Native性能优化红宝书
一、React Native介绍 React Native 是Facebook在React.js Conf2015 推出的开源框架,使用React和应用平台的原生功能来构建 Android 和 iOS 应用。通过 React Native,可以使用 JavaScript 来访问移动平台的 API,使用 React 组件来描述 UI 的…...
后端不提供文件流接口,前台js使用a标签实现当前表格数据(数组非blob数据)下载成Excel
前言:开发过程中遇到的一些业务场景,如果第三方不让使用,后端不提供接口,就只能拿到table数据(Array),实现excel文件下载。 废话不多说,直接上代码,方法后续自行封装即可: functio…...

如何使用ChatGPT辅助设计工作
文章目录 设计师如何使用ChatGPT提升工作效率?25个案例告诉你!什么是 prompt?咨询信息型 prompt vs 执行任务 prompt编写出色 prompt 的基本思路撰写 prompt 的案例和技巧1、将 ChatGPT 视作专业人士2、使用 ChatGPT 创建表单3、使用 ChatGPT…...
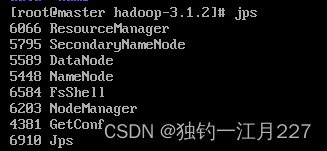
hadoop服务器启动后无法执行hdfs dfs命令
集群启动后,无法正常使用hdfs的任何命令。使用jps查看进程,发现namenode没有启动,然后再进入到Hadoop的相应目录,打开里面的logs文件 打开Hadoop的master的log 再使用vi编辑器查看(也可以用less或者more命令查看&#…...
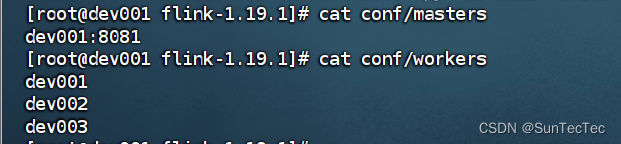
Flink 1.19.1 standalone 集群模式部署及配置
flink 1.19起 conf/flink-conf.yaml 更改为新的 conf/config.yaml standalone集群: dev001、dev002、dev003 config.yaml: jobmanager address 统一使用 dev001,bind-port 统一改成 0.0.0.0,taskmanager address 分别更改为dev所在host dev001 config.…...
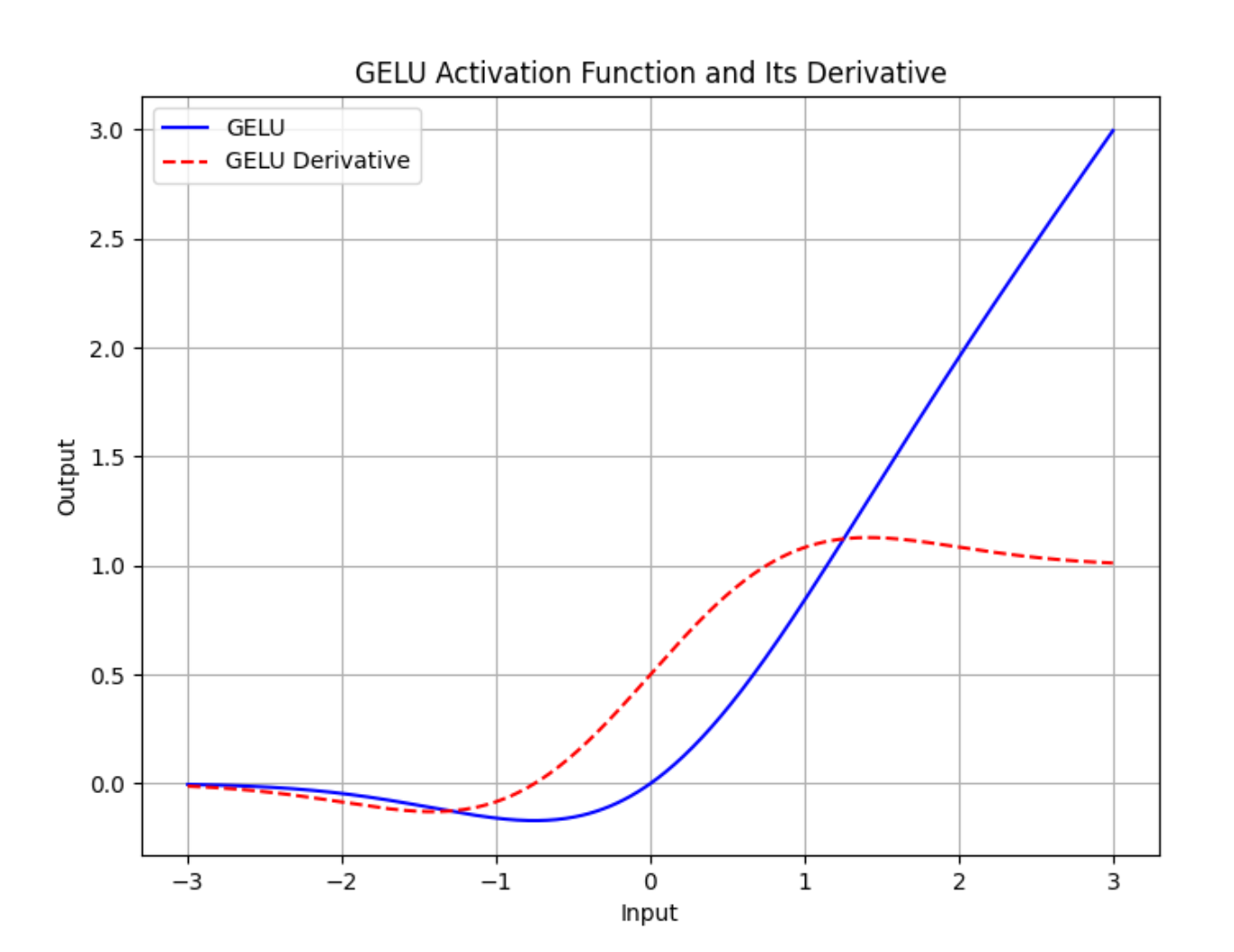
【深度学习】GELU激活函数是什么?
torch.nn.GELU 模块在 PyTorch 中实现了高斯误差线性单元(GELU)激活函数。GELU 被用于许多深度学习模型中,包括Transformer,因为它相比传统的 ReLU(整流线性单元)函数能够更好地近似神经元的真实激活行为。…...

如何编译和运行您的第一个Java程序
如何编译和运行您的第一个Java程序 让我们从一个简单的java程序开始。 简单的Java程序 这是一个非常基本的java程序,它会打印一条消息“这是我在java中的第一个程序”。 public class FirstJavaProgram {public static void main(String[] args){System.…...

vscode用vue框架写一个登陆页面
目录 一、创建登录页面 二、构建好登陆页面的路由 三、编写登录页代码 1.添加基础结构 2.给登录页添加背景 3.解决填充不满问题 4.我们把背景的红颜色替换成背景图: 5.在页面中央添加一个卡片来显示登录页面 6.设置中间卡片页面的左侧 7.设置右侧的样式及…...

腾讯云API安全保障措施?有哪些调用限制?
腾讯云API的调用效率如何优化?怎么使用API接口发信? 腾讯云API作为腾讯云提供的核心服务之一,广泛应用于各行各业。然而,随着API应用的普及,API安全问题也日益突出。AokSend将详细探讨腾讯云API的安全保障措施&#x…...

在建设工程合同争议案件中,如何来认定“竣工验收”?
在建设工程合同争议案件中,如何来认定“竣工验收”? 建设工程的最终竣工验收,既涉及在建设单位组织下的五方单位验收,又需政府质量管理部门的监督验收以及竣工验收备案,工程档案还需递交工程所在地的工程档案馆归档。…...

如何用GHelper解决华硕笔记本性能管理难题:轻量级开源工具的完整指南
如何用GHelper解决华硕笔记本性能管理难题:轻量级开源工具的完整指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivoboo…...

使用 Taotoken CLI 工具一键配置团队开发环境中的大模型密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken CLI 工具一键配置团队开发环境中的大模型密钥 在团队协作开发中,统一管理大模型 API 密钥和端点配置是一…...

AI助手碳核算技能:基于MCP协议与CCDB数据库的实战指南
1. 项目概述:当AI助手学会“碳核算” 如果你是一名开发者、数据分析师,或者任何需要处理碳排放相关工作的从业者,最近可能被一个词频繁刷屏:AI Agent。我们总希望手边的AI编程助手(比如Cursor、Claude Code࿰…...

网盘直链下载助手:解锁九大网盘下载速度的终极方案
网盘直链下载助手:解锁九大网盘下载速度的终极方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

Gradle多模块项目实战:从settings.gradle的三种写法到自定义目录结构的完整指南
Gradle多模块项目实战:从settings.gradle的三种写法到自定义目录结构的完整指南 当你面对一个逐渐膨胀的单体项目时,如何优雅地拆分成多个模块?Gradle的多项目构建能力正是解决这一痛点的利器。本文将带你深入探索settings.gradle文件的奥秘&…...

开源AI工具集Muse:模块化架构与创意工作流实践指南
1. 项目概述:一个面向创意工作者的开源AI工具集最近在开源社区里,一个名为myths-labs/muse的项目引起了我的注意。乍一看这个名字,你可能会联想到艺术灵感,但实际上,它是一个定位非常精准的开发者工具集合。简单来说&a…...

外汇延迟套利检测系统演进:从规则到AI的行为博弈
1. 项目概述:当速度优势不再是护城河 在电子外汇交易的世界里,速度套利一直是一个古老而又充满技术魅力的游戏。它的核心逻辑简单到近乎纯粹:如果你能比你的交易对手更快地获取到市场价格变动的信息,你就能在对手更新其报价之前&a…...

巧用历史版本溯源法,化解R包依赖链安装难题
1. 为什么R包安装总是报错?从依赖链说起 每次看到RStudio里跳出一串红色报错信息,我就知道又要开始"解谜"了。特别是当你想装个ggplot2画个图,结果提示rlang版本不对;升级rlang后又发现pillar不兼容...这种连环套问题&a…...

深度解析Layui formSelects:现代Web应用中的多选下拉框终极解决方案
深度解析Layui formSelects:现代Web应用中的多选下拉框终极解决方案 【免费下载链接】layui-formSelects Layui select多选小插件 项目地址: https://gitcode.com/gh_mirrors/la/layui-formSelects 在当今的Web开发领域,表单交互体验直接影响着用…...

63岁黄仁勋再添博士头衔、英特尔CEO为其披袍,最新演讲刷屏:人类编写软件、计算机执行指令的范式已终结!
整理 | 苏宓 出品 | CSDN(ID:CSDNnews) 日前,在卡内基梅隆大学(CMU)的 2026 届毕业典礼上,英伟达 CEO 黄仁勋的头衔再加一,最新获得 CMU 科学与技术荣誉博士学位,而这也是…...