Elasticsearch-ES查询单字段去重
ES 语句
整体数据
GET wkl_test/_search
{"query": {"match_all": {}}
}
结果:
{"took" : 123,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "wkl_test","_type" : "_doc","_id" : "aK0tFpABTkLj5j4c34pE","_score" : 1.0,"_source" : {"name" : "zhangsan","aa" : 1}},{"_index" : "wkl_test","_type" : "_doc","_id" : "aa0uFpABTkLj5j4cFYrJ","_score" : 1.0,"_source" : {"name" : "lisi","aa" : 2}},{"_index" : "wkl_test","_type" : "_doc","_id" : "aq0uFpABTkLj5j4cKYqF","_score" : 1.0,"_source" : {"name" : "wangwu","aa" : 2}},{"_index" : "wkl_test","_type" : "_doc","_id" : "a60uFpABTkLj5j4c2IoF","_score" : 1.0,"_source" : {"name" : "maliu","aa" : 2}},{"_index" : "wkl_test","_type" : "_doc","_id" : "bK1IFpABTkLj5j4cqYop","_score" : 1.0,"_source" : {"name" : "gouqi","aa" : 3}}]}
}1:collapse折叠功能- 查询去重后的数据列表(ES5.3之后支持)
- 推荐原因:性能高,占内存小
- 注意:使用此方式去重时,不会去除掉不存在去重字段的数据。
- 去重字段只能是数字long类型或keyword。
- Field Collapsing(字段折叠)不能与scroll、rescore以及search after 结合使用。
GET wkl_test/_search
{"query": {"match_all": {}},"collapse": {"field": "aa"}
}
结果:hits 中total虽然=5,但是只返回了去重后的 3 条数据
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "wkl_test","_type" : "_doc","_id" : "aK0tFpABTkLj5j4c34pE","_score" : 1.0,"_source" : {"name" : "zhangsan","aa" : 1},"fields" : {"aa" : [1]}},{"_index" : "wkl_test","_type" : "_doc","_id" : "aa0uFpABTkLj5j4cFYrJ","_score" : 1.0,"_source" : {"name" : "lisi","aa" : 2},"fields" : {"aa" : [2]}},{"_index" : "wkl_test","_type" : "_doc","_id" : "bK1IFpABTkLj5j4cqYop","_score" : 1.0,"_source" : {"name" : "gouqi","aa" : 3},"fields" : {"aa" : [3]}}]}
}2:cardinality - 查询去重后的数据总数
- 聚合+cardinality:即去重计算,类似sql中 count(distinct),先去重再求和
- 注意:使用此方式统计去重后的数量时,会去除掉不存在去重字段的数据。
GET wkl_test/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"distinct_count": {"cardinality": {"field": "aa"}}}
}
结果:distinct_count = 3,说明去重后有3个,既aggregations聚合下,返回了按名字查询去重后的结果数,但是只有去重后的条数,没有具体的数据。
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"aggregations" : {"distinct_count" : {"value" : 3}}
}3:整体语句
- 使用collapse 折叠查询后,虽然返回了去重后的数据,但是total 还是所有的数据量
- 使用 cardinality 聚合 ,虽然在aggs 聚合结果中返回了正确的数据量,但是hits中还是全部的数据
- 所以我们需要 两个综合使用,如下:
GET wkl_test/_search
{"query": {"match_all": {}},"collapse": {"field": "aa"}, "aggs": {"distinct_count": {"cardinality": {"field": "aa"}}}
}
结果:
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 5,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "wkl_test","_type" : "_doc","_id" : "aK0tFpABTkLj5j4c34pE","_score" : 1.0,"_source" : {"name" : "zhangsan","aa" : 1},"fields" : {"aa" : [1]}},{"_index" : "wkl_test","_type" : "_doc","_id" : "aa0uFpABTkLj5j4cFYrJ","_score" : 1.0,"_source" : {"name" : "lisi","aa" : 2},"fields" : {"aa" : [2]}},{"_index" : "wkl_test","_type" : "_doc","_id" : "bK1IFpABTkLj5j4cqYop","_score" : 1.0,"_source" : {"name" : "gouqi","aa" : 3},"fields" : {"aa" : [3]}}]},"aggregations" : {"distinct_count" : {"value" : 3}}
}注:我们使用cardinality聚合后的distinct_count 作为去重后的总数,用 collapse 折叠后的列表作为数据结果集
分页使用解释说明:
-
1.hits中total的总条数实际上是去重前的总条数,原数据条数,这里我们知道就行,分页中我们并不使用它。hits中数组的大小刚好等于courseAgg聚合的值,数组中的数据就是去重后的数据。
-
2.aggregations中的courseAgg条数,这个才是去重后的实际条数,也是分页用的总条数。
-
3.from 查询的偏移量,也就是从哪里开始查。
-
4.size 查询条数,一次查几条。
-
接下来,你就可以把它当做一个简单分页查询来用了,传入from和size就ok啦~
JAVA API使用
1:collapse 查询去重的结果集
// 使用collapse来指定去重的字段,例如"your_distinct_field"CollapseBuilder collapseBuilder = new CollapseBuilder("your_distinct_field");searchSourceBuilder.collapse(collapseBuilder);
2:cardinality - 查询去重后的数据总数
// 添加一个cardinality聚合来计算去重字段的唯一值数量CardinalityAggregationBuilder aggregation = AggregationBuilders.cardinality("distinct_count")//这里是聚合结果的字段名.field("your_distinct_field")//这里是需要聚合的字段.precisionThreshold(40000); // 根据需要调整精度阈值searchSourceBuilder.aggregation(aggregation);
3:整体使用
package com.wenge.system.utils;import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.metrics.CardinalityAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.ParsedCardinality;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.collapse.CollapseBuilder;import java.io.IOException;
import java.util.Map;/*** @author wangkanglu* @version 1.0* @description* @date 2024-06-17 16:48*/
public class TestES {public static void main(String[] args) throws IOException {//创建ES客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost",9200,"http")));try {// 创建一个搜索请求并设置索引名SearchRequest searchRequest = new SearchRequest("your_index");// 构建搜索源构建器SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 设置查询条件,例如匹配所有文档,这里根据业务自己修改searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 使用collapse来指定去重的字段,例如"your_distinct_field"CollapseBuilder collapseBuilder = new CollapseBuilder("your_distinct_field");searchSourceBuilder.collapse(collapseBuilder);// 添加一个cardinality聚合来计算去重字段的唯一值数量CardinalityAggregationBuilder aggregation = AggregationBuilders.cardinality("distinct_count")//这里是聚合结果的字段名.field("your_distinct_field")//这里是需要聚合的字段.precisionThreshold(40000); // 根据需要调整精度阈值searchSourceBuilder.aggregation(aggregation);// 设置搜索源searchRequest.source(searchSourceBuilder);// 执行搜索SearchResponse searchResponse = esClient.search(searchRequest, RequestOptions.DEFAULT);SearchHit[] hits = searchResponse.getHits().getHits();for (SearchHit hit : hits) {Map<String, Object> sourceAsMap = hit.getSourceAsMap();System.out.println("去重结果: " + sourceAsMap);}// 处理搜索结果,获取去重数量ParsedCardinality parsedCardinality = searchResponse.getAggregations().get("distinct_count");long distinctCount = parsedCardinality.getValue();System.out.println("去重结果数量:" + distinctCount);} finally {// 关闭clientesClient.close();}}
}相关文章:

Elasticsearch-ES查询单字段去重
ES 语句 整体数据 GET wkl_test/_search {"query": {"match_all": {}} }结果: {"took" : 123,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0…...

【Apache Doris】周FAQ集锦:第 7 期
【Apache Doris】周FAQ集锦:第 7 期 SQL问题数据操作问题运维常见问题其它问题关于社区 欢迎查阅本周的 Apache Doris 社区 FAQ 栏目! 在这个栏目中,每周将筛选社区反馈的热门问题和话题,重点回答并进行深入探讨。旨在为广大用户和…...

EE trade:炒伦敦金的注意事项及交易指南
在贵金属市场中,伦敦金因其高流动性和全球认可度,成为广大投资者的首选。然而,在炒伦敦金的过程中,投资者需要注意一些关键点。南华金业小编带您一起来看看。 国际黄金报价 一般国际黄金报价会提供三个价格: 买价(B…...
JAVA医院绩效考核系统源码 功能特点:大型医院绩效考核系统源码
JAVA医院绩效考核系统源码 功能特点:大型医院绩效考核系统源码 医院绩效管理系统主要用于对科室和岗位的工作量、工作质量、服务质量进行全面考核,并对科室绩效工资和岗位绩效工资进行核算的系统。医院绩效管理系统开发主要用到的管理工具有RBRVS、DRGS…...

Python神经影像数据的处理和分析库之nipy使用详解
概要 神经影像学(Neuroimaging)是神经科学中一个重要的分支,主要研究通过影像技术获取和分析大脑结构和功能的信息。nipy(Neuroimaging in Python)是一个强大的 Python 库,专门用于神经影像数据的处理和分析。nipy 提供了一系列工具和方法,帮助研究人员高效地处理神经影…...

非关系型数据库NoSQL数据层解决方案 之 Mongodb 简介 下载安装 springboot整合与读写操作
MongoDB 简介 MongoDB是一个开源的面向文档的NoSQL数据库,它采用了分布式文件存储的数据结构,是当前非常流行的数据库之一。 以下是MongoDB的主要特点和优势: 面向文档的存储: MongoDB是一个面向文档的数据库管理系统࿰…...

使用Redis优化Java应用的性能
使用Redis优化Java应用的性能 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们来探讨如何使用Redis优化Java应用的性能。Redis是一种开源的内存数据结构…...

基于Python的数据可视化大屏的设计与实现
基于Python的数据可视化大屏的设计与实现 Design and Implementation of Python-based Data Visualization Dashboard 完整下载链接:基于Python的数据可视化大屏的设计与实现 文章目录 基于Python的数据可视化大屏的设计与实现摘要第一章 导论1.1 研究背景1.2 研究目的1.3 研…...

什么是N卡和A卡?有什么区别?
名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 本篇笔记整理:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、什么是N卡和A卡?有什么区别?…...
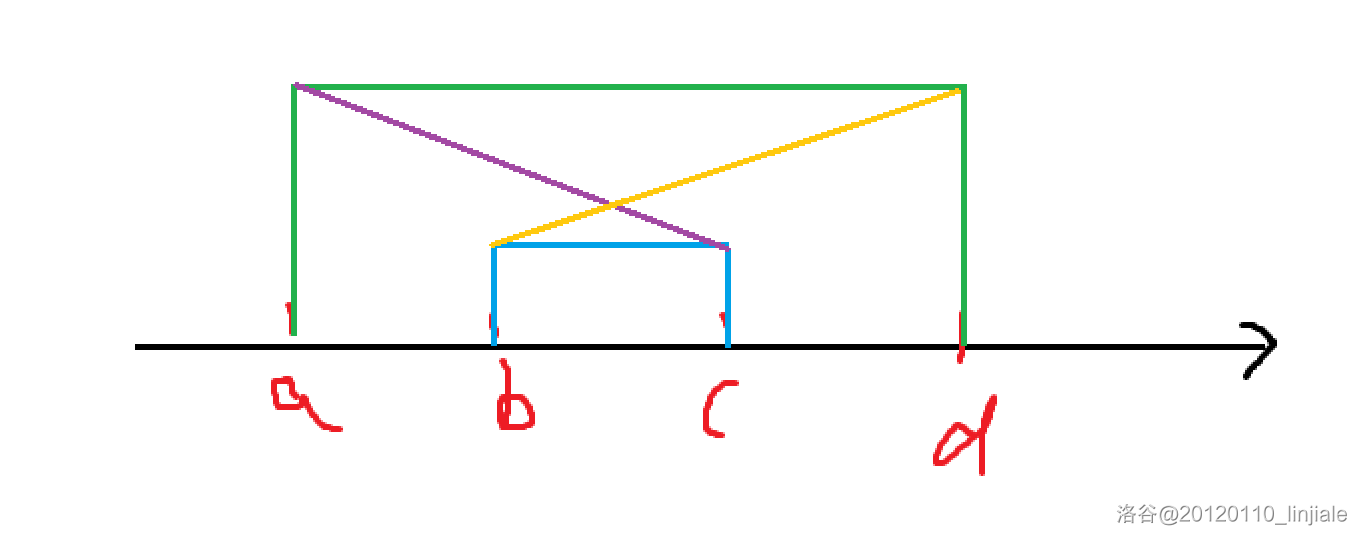
四边形不等式优化
四边形不等式优化 应用于类似以下dp转移方程。 f i min 1 ≤ j ≤ i ( w i , j , f i ) f_{i}\min_{1\le j\le i}(w_{i,j},f_{i}) fi1≤j≤imin(wi,j,fi) 假设 w i , j w_{i,j} wi,j 可以在 O ( 1 ) O(1) O(1) 的时间内进行计算。 在正常情况下,…...

这家民营银行起诉担保公司?暴露担保增信兜底隐患
来源 | 镭射财经(leishecaijing) 助贷领域中,各路资方依赖担保增信业务扩张数年,其风险积压也不容忽视。一旦助贷平台或担保公司兜不住底,资方就将陷入被动。 最近,一则民营银行起诉合作担保公司的消息引…...
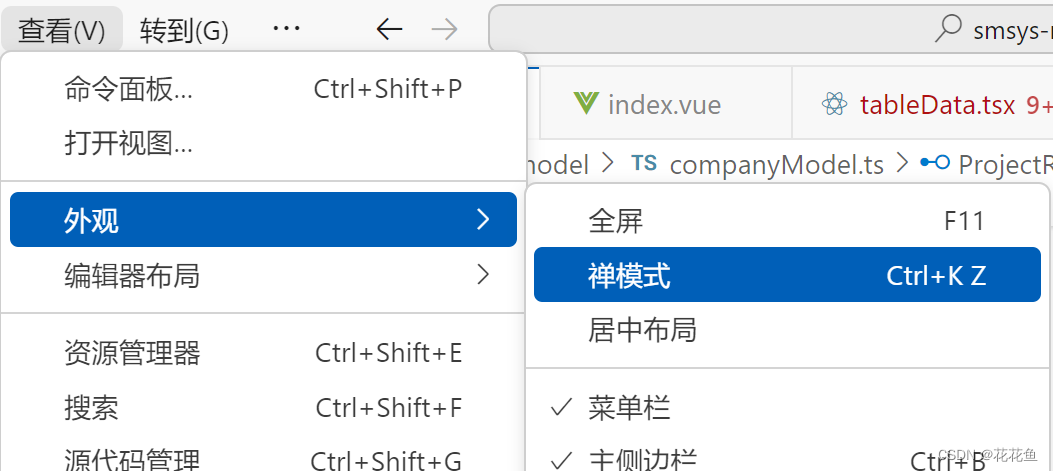
vscode禅模式怎么退出
1、如何进入禅模式:查看--外观--禅模式 2、退出禅模式 按二次ESC,就可以退出。...
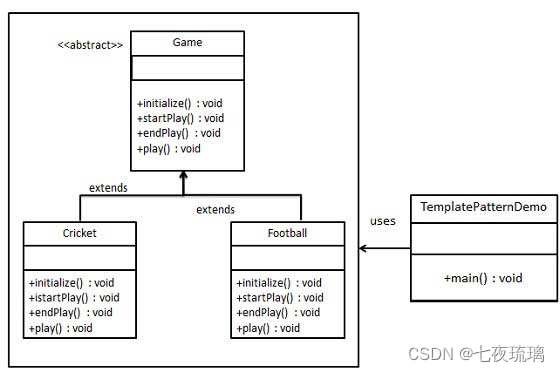
Java23种设计模式(四)
1、备忘录模式 备忘录模式(Memento Pattern)保存一个对象的某个状态,以便在适当的时候恢复对象,备忘录模式属于行为型模式。 备忘录模式允许在不破坏封装性的前提下,捕获和恢复对象的内部状态。 实现方式 创建备忘录…...

HTML静态网页成品作业(HTML+CSS)——故宫介绍网页(4个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有4个页面。 二、作品演示 三、代…...

Zookeeper:客户端命令行操作
文章目录 一、help二、ls path三、create四、get path五、set六、stat七、delete八、deleteall 一、help 显示所有操作命令。 二、ls path 使用ls命令来查看当前znode的子节点[可监听] w:监听子节点变化。s:附加次级信息。 三、create 普通创建&am…...

区块链技术介绍和用法
区块链技术是一种分布式账本技术,可以记录和存储一系列交易信息,并通过密码学算法保证信息的安全性和不可篡改性。区块链技术的核心概念是“区块”和“链”。 每个区块包含了一部分交易信息,以及一个指向上一个区块的哈希值。当新的交易发生…...

Upload-Labs-Linux1 使用 一句话木马
解题步骤: 1.新建一个php文件,编写内容: <?php eval($_REQUEST[123]) ?> 2.将编写好的php文件上传,但是发现被阻止,网站只能上传图片文件。 3.解决方法: 将php文件改为图片文件(例…...
从 Hadoop 迁移,无需淘汰和替换
我们仍然惊讶于有如此多的客户来找我们,希望从HDFS迁移到现代对象存储,如MinIO。我们现在以为每个人都已经完成了过渡,但每周,我们都会与一个决定进行过渡的主要、高技术性组织交谈。 很多时候,在这些讨论中ÿ…...
深度学习:从理论到应用的全面解析
引言 深度学习作为人工智能(AI)的核心技术之一,在过去的十年中取得了显著的进展,并在许多领域中展示了其强大的应用潜力。本文将从理论基础出发,探讨深度学习的最新进展及其在各领域的应用,旨在为读者提供全…...

【02】区块链技术应用
区块链在金融、能源、医疗、贸易、支付结算、证券等众多领域有着广泛的应用,但是金融依旧是区块链最大且最为重要的应用领域。 1. 区块链技术在金融领域的应用 1.2 概况 自2019年以来,国家互联网信息办公室已发布八批境内区块链信息服务案例清单&#…...

跨平台图形API实战选型:从Vulkan、DirectX到Metal与WebGPU的架构抉择
1. 图形API的演变与现状 十年前我刚入行时,OpenGL还是图形开发的主流选择。记得第一次在Ubuntu上配置GLFW环境就花了整整两天,而现在Vulkan只需要几行命令就能跑起来。这种变化背后是GPU架构的革命性演进——从固定功能管线到可编程着色器,再…...

企业数据安全第一关:基于RBAC模型,用CloudQuery搞定数据库权限管控与审计日志
企业数据安全第一关:基于RBAC模型构建数据库权限管控与审计体系 当企业业务规模从初创期迈向成长期时,数据库访问权限往往像一间未经整理的仓库——所有人都能找到入口,但没人清楚哪些物品可以触碰。某互联网金融公司的技术负责人曾分享过这样…...

全境透视·智域重构系统 技术发布会完整版宣讲稿
全境透视智域重构系统 技术发布会完整版宣讲稿 镜像视界浙江科技有限公司 尊敬的各位领导、行业专家、合作伙伴、各界来宾: 大家上午好! 当下数字智慧建设迈入全新进阶阶段,传统二维监控视野受限、物理遮挡形成大量管理盲区,静态…...

CUDA编程书籍大汇总:涵盖入门到高级,2022 - 2026年最新版本全收录!
跳过内容导航菜单 切换导航 [ ](/) [ 登录 ](/login?return_tohttps%3A%2F%2Fgithub.com%2Falternbits%2Fawesome-cuda-books) 外观设置 - **平台** - **AI 代码创作** - [GitHub Copilot:借助 AI 编写更优质代码](https://github.com/features/copilot) -…...

listmonk容器资源监控告警:资源使用率阈值
listmonk容器资源监控告警:资源使用率阈值 你是否遇到过listmonk邮件列表管理器在高负载时突然卡顿?或者因服务器资源耗尽导致邮件发送中断?本文将详细介绍如何为listmonk容器配置资源监控与告警阈值,帮助你提前识别并解决资源瓶…...

7步掌握listmonk API认证:从令牌生成到权限验证实战指南
7步掌握listmonk API认证:从令牌生成到权限验证实战指南 listmonk是一款高性能、自托管的新闻通讯和邮件列表管理器,具有现代化的仪表板,采用单一二进制应用形式。本文将详细介绍如何通过7个简单步骤掌握listmonk的API认证,包括令…...

TimeMixer终极指南:如何用完全MLP架构实现时间序列预测的SOTA性能
TimeMixer终极指南:如何用完全MLP架构实现时间序列预测的SOTA性能 【免费下载链接】TimeMixer [ICLR 2024] Official implementation of "TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting" 项目地址: https://gitcode.com/gh_m…...

批量处理二维码图片,真的需要联网吗?这款离线高效工具给你答案!
批量处理二维码图片,真的需要联网吗?这款离线高效工具给你答案! 【免费下载链接】QrScan 离线批量检测图片是否包含二维码以及识别二维码 项目地址: https://gitcode.com/gh_mirrors/qrs/QrScan 想象一下这个场景:公司市场…...
:auto_ptr的缺陷与unique_ptr)
【c++面向对象编程】第30篇:RAII与智能指针(一):auto_ptr的缺陷与unique_ptr
目录 一、一个手动管理的痛点 二、RAII 核心思想 三、auto_ptr:C98 的尝试与缺陷 auto_ptr 的核心缺陷 四、unique_ptr:真正的独占式智能指针 基本用法 常用成员函数 五、unique_ptr 与数组 六、自定义删除器 七、make_unique(C14&a…...

基于MCP协议实现AI安全访问MongoDB:架构、部署与安全实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想让大语言模型(LLM)能直接操作数据库,比如MongoDB。这听起来很酷,对吧?想象一下,你直接告诉AI助手“帮我查一下上个月销量最高的产品”&…...