bert文本分类微调笔记
Bert实现文本分类微调Demo
import random
from collections import namedtuple'''
有四种文本需要做分类,请使用bert处理这个分类问题
'''# 使用namedtuple定义一个类别(Category),包含两个字段:名称(name)和样例(samples)
Category = namedtuple('Category', ['name', 'samples'])# 定义四个不同的类别及其对应的样例文本
categories = [Category('Weather Forecast', ['今天北京晴转多云,气温20-25度。', '明天上海有小雨,记得带伞。']), # 天气预报类别的样例Category('Company Financial Report', ['本季度公司净利润增长20%。', '年度财务报告显示,成本控制良好。']), # 公司财报类别的样例Category('Company Audit Materials', ['审计发现内部控制存在漏洞。', '审计确认财务报表无重大错报。']), # 公司审计材料类别的样例Category('Product Marketing Ad', ['新口味可乐,清爽上市!', '买一送一,仅限今日。']) # 产品营销广告类别的样例
]def generate_data(num_samples_per_category=50):''' 生成模拟数据集输入:- num_samples_per_category: 每个类别生成的样本数量,默认为50输出:- data: 包含文本样本及其对应类别的列表,每项为一个元组(text, label)'''data = [] # 初始化存储数据的列表for category in categories: # 遍历所有类别for _ in range(num_samples_per_category): # 对每个类别生成指定数量的样本sample = random.choice(category.samples) # 从该类别的样例中随机选择一条文本data.append((sample, category.name)) # 将文本及其类别添加到data列表中return data# 调用generate_data函数生成模拟数据集
train_data = generate_data(100) # 为每个类别生成100个训练样本
test_data = generate_data(6) # 生成少量(6个)测试样本用于演示'''
train_data =
[('明天上海有小雨,记得带伞。', 'Weather Forecast'),('明天上海有小雨,记得带伞。', 'Weather Forecast'),('今天北京晴转多云,气温20-25度。', 'Weather Forecast'),('今天北京晴转多云,气温20-25度。', 'Weather Forecast'),('今天北京晴转多云,气温20-25度。', 'Weather Forecast'),('明天上海有小雨,记得带伞。', 'Weather Forecast'),('明天上海有小雨,记得带伞。', 'Weather Forecast'),('明天上海有小雨,记得带伞。', 'Weather Forecast'),('今天北京晴转多云,气温20-25度。', 'Weather Forecast'),]
'''from transformers import BertTokenizer, BertForSequenceClassification, AdamW
from torch.utils.data import DataLoader, TensorDataset
import torch
import torch.nn.functional as F# 步骤1: 定义类别到标签的映射
label_map = {category.name: index for index, category in enumerate(categories)}
num_labels = len(categories) # 类别总数# 步骤2: 初始化BERT分词器和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=num_labels)# 步骤3: 准备数据集
def encode_texts(texts, labels):# 对文本进行编码,得到BERT模型需要的输入格式encodings = tokenizer(texts, truncation=True, padding=True, return_tensors='pt')# 将标签名称转换为对应的索引label_ids = torch.tensor([label_map[label] for label in labels])return encodings, label_idsdef prepare_data(data):texts, labels = zip(*data) # 解压数据encodings, label_ids = encode_texts(texts, labels) # 编码数据dataset = TensorDataset(encodings['input_ids'], encodings['attention_mask'], label_ids) # 创建数据集return DataLoader(dataset, batch_size=8, shuffle=True) # 创建数据加载器# 步骤4: 准备训练和测试数据
train_loader = prepare_data(train_data)
test_loader = prepare_data(test_data)# 步骤5: 定义训练和评估函数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)def train_epoch(model, data_loader, optimizer):model.train()total_loss = 0for batch in data_loader:optimizer.zero_grad()input_ids, attention_mask, labels = batchinput_ids, attention_mask, labels = input_ids.to(device), attention_mask.to(device), labels.to(device)outputs = model(input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.losstotal_loss += loss.item()loss.backward()optimizer.step()return total_loss / len(data_loader)def evaluate(model, data_loader):model.eval()total_acc = 0total_count = 0with torch.no_grad():for batch in data_loader:input_ids, attention_mask, labels = batchinput_ids, attention_mask, labels = input_ids.to(device), attention_mask.to(device), labels.to(device)outputs = model(input_ids, attention_mask=attention_mask)predictions = torch.argmax(outputs.logits, dim=1)total_acc += (predictions == labels).sum().item()total_count += labels.size(0)return total_acc / total_count# 步骤6: 训练模型
optimizer = AdamW(model.parameters(), lr=2e-5)for epoch in range(3): # 训练3个epochtrain_loss = train_epoch(model, train_loader, optimizer)acc = evaluate(model, test_loader)print(f'Epoch {epoch+1}, Train Loss: {train_loss}, Test Accuracy: {acc*100:.2f}%')# 步骤7: 使用微调后的模型进行预测
def predict(text):encodings = tokenizer(text, truncation=True, padding=True, return_tensors='pt')input_ids = encodings['input_ids'].to(device)attention_mask = encodings['attention_mask'].to(device)with torch.no_grad():outputs = model(input_ids, attention_mask=attention_mask)predicted_class_id = torch.argmax(outputs.logits).item()return categories[predicted_class_id].name# 预测一个新文本
new_text = ["明天的天气怎么样?"] # 注意这里是一个列表
predicted_category = predict(new_text)
print(f'The predicted category for the new text is: {predicted_category}')相关文章:

bert文本分类微调笔记
Bert实现文本分类微调Demo import random from collections import namedtuple 有四种文本需要做分类,请使用bert处理这个分类问题 # 使用namedtuple定义一个类别(Category),包含两个字段:名称(name)和样例(samples) Category namedtuple(Ca…...

运维:k8s常用命令大全
Kubernetes是一个强大的容器编排平台,不管是运维、开发还是测试或多或少都会接触到,熟练的掌握k8s可大大提高工作效率和强化自身技能。 集群管理 1. 查看集群节点状态: kubectl get nodes 2. 查看集群资源使用情况: kubectl top nodes 3. 查看集群…...

PHP基础之错误与异常
文章目录 1 错误1.1 简介1.2 简单错误处理1.2.1 使用die1.2.2 die和exit区别 1.3 自定义错误处理1.3.1 定义1.3.2 创建错误函数 1.4 触发错误1.5 抑制错误1.5.1 行内错误抑制 2 异常2.1 引言2.2 什么是异常2.3 Try、throw、catch、finally2.4 自定义异常2.5 设置顶层异常处理器…...
详解Spring AOP(一)
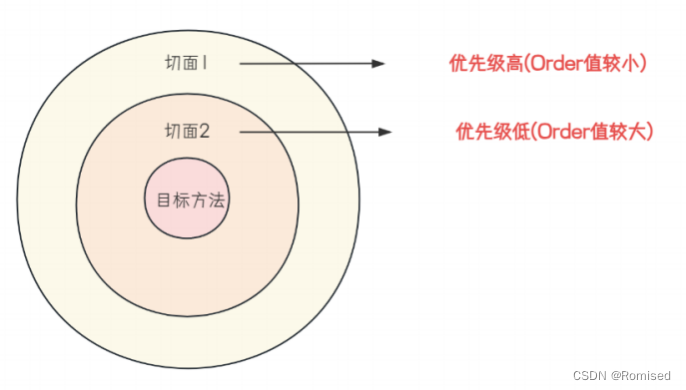
目录 1. AOP概述 2.Spring AOP快速入门 2.1引入AOP依赖 2.2编写AOP程序 3.Spring AOP核心概念 3.1切点(PointCut) 3.2连接点(Join Point) 3.3通知(Advice) 3.4切面(Aspect) …...
)
读者写者问题(读者优先、公平竞争、写者优先)
1.读者优先 当有读者进程进行读时,允许多个读者同时读,但不允许写者写;当有写者进程进行写时,不允许其他写者写,也不允许读者读 读者算法: p(r_mutex); //申请修改read_count if read_count0:p(mutex); …...
-- Easyexcel)
Springboot开发之 Excel 处理工具(二)-- Easyexcel
一、Easyexcel 简介 EasyExcel是一个基于Java的Excel处理工具库,它的核心设计理念是快速、简洁,并且能够有效解决处理大文件时的内存溢出问题。使用EasyExcel,开发者可以在几乎不需要考虑性能和内存消耗的情况下,轻松实现Excel文…...

6月27日云技术研讨会 | 中央集中架构新车型功能和网络测试解决方案
会议摘要 “软件定义汽车”新时代下,整车电气电气架构向中央-区域集中式发展已成为行业共识,车型架构的变革带来更复杂的整车功能定义、更多的新技术的应用(如SOA服务化、TSN等)和更短的车型研发周期,对整车和新产品研…...

微信小程序生命周期
微信小程序的生命周期包括两个主要部分:应用生命周期和页面生命周期。下面我将详细介绍它们的具体内容。 应用生命周期 onLaunch: 触发时机:小程序初始化完成时(全局只触发一次)。 用途:通常用于进行一些…...

【JS重点15】原型对象概述
目录 一:构造函数缺陷 二:原型 1 原型是是什么 2 原型对象的作用 3 原型对象this指向问题 4 利用原型对象添加方法 给JS内置构造函数Array添加最大值方法 给JS内置构造函数Array添加求和方法 三:Constructor属性 四:如何…...

Java之Hutool/Guava/Apache Commons工具包项目实践
概述 Hutool是一个Java工具包,提供了丰富的工具类和方法,目的是简化开发任务提高开发效率;适用于需要快速开发和实现多种功能的场景,适合项目需要处理字符串、日期、文件等常见任务时~ toBeBetterJavaer/docs/common-tool/StringUtils.md at master itwanger/toBeBetterJavae…...

哈喽GPT-4o——对GPT-4o 提示词的思考与看法
目录 一、提示词二、常用的提示词案例1、写作助理2、改写为小红书风格3、英语翻译和改写4、论文式回答5、主题解构6、提问助手7、Nature风格润色8、结构总结9、编程助手10、充当终端/解释器 大家好,我是哪吒。 最近,ChatGPT在网络上广受欢迎,…...

《计算机英语》 Unit 3 Software Engineering 软件工程
Section A Software Engineering Methodologies 软件工程方法论 Software development is an engineering process. 软件开发是一个工程过程。 The goal of researchers in software engineering is to find principles that guide the software development process and lea…...

2024-6-18(沉默Spring,Springboot)
1.Spring小结 我们最后再来体会一下用 Spring 创建对象的过程: 通过 ApplicationContext 这个 IoC 容器的入口,用它的两个具体的实现子类,从 class path 或者 file path 中读取数据,用 getBean() 获取具体的 bean instance。 那…...
Java热部署:让应用更新如丝般顺滑,告别繁琐重启!
目录 手动启动热部署 自动启动热部署 参与热部署监控的文件范围配置 关闭热部署 什么是热部署?简单说就是你程序改了,现在要重新启动服务器,嫌麻烦?不用重启,服务器会自己悄悄的把更新后的程序给重新加载一遍&…...

微信小程序毕业设计-小区疫情防控系统项目开发实战(附源码+论文)
大家好!我是程序猿老A,感谢您阅读本文,欢迎一键三连哦。 💞当前专栏:微信小程序毕业设计 精彩专栏推荐👇🏻👇🏻👇🏻 🎀 Python毕业设计…...
PyTorch -- RNN 快速实践
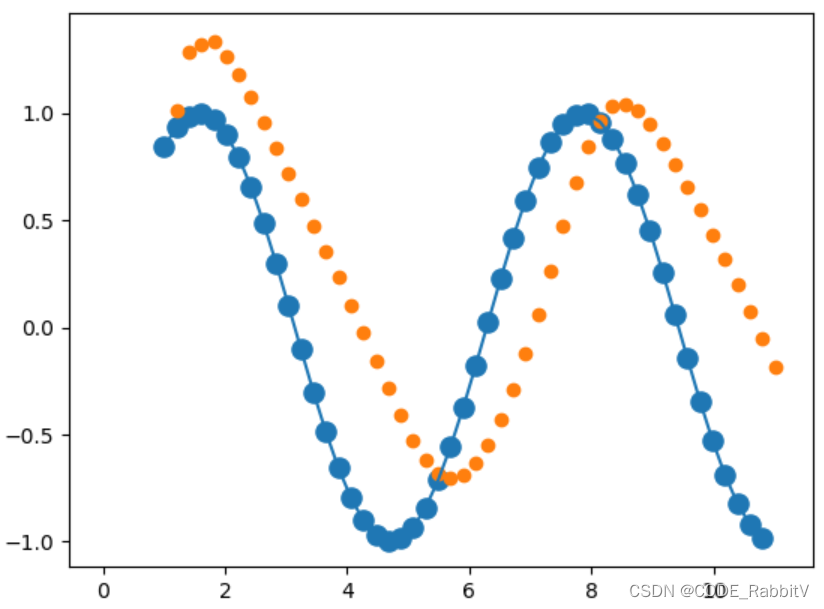
RNN Layer torch.nn.RNN(input_size,hidden_size,num_layers,batch_first) input_size: 输入的编码维度hidden_size: 隐含层的维数num_layers: 隐含层的层数batch_first: True 指定输入的参数顺序为: x:[batch, seq_len, input_size]h0:[batc…...

SpringBoot 快速入门(保姆级详细教程)
目录 一、Springboot简介 二、SpringBoot 优点: 三、快速入门 1、新建工程 方式2:使用Spring Initializr创建项目 写在前面: SpringBoot 是 Spring家族中的一个全新框架,用来简化spring程序的创建和开发过程。SpringBoot化繁…...
【第18章】Vue实战篇之登录界面
文章目录 前言一、数据绑定1. 数据绑定2. 数据清空 二、表单校验1. 代码2. 展示 三、登录1.登录按钮2.user.js3. login 四、展示总结 前言 上一章完成用户注册,这一章主要做用户登录。 一、数据绑定 登录和注册使用相同的数据绑定 1. 数据绑定 <!-- 登录表单 -…...
[C++]使用C++部署yolov10目标检测的tensorrt模型支持图片视频推理windows测试通过
【测试通过环境】 vs2019 cmake3.24.3 cuda11.7.1cudnn8.8.0 tensorrt8.6.1.6 opencv4.8.0 【部署步骤】 获取pt模型:https://github.com/THU-MIG/yolov10训练自己的模型或者直接使用yolov10官方预训练模型 下载源码:https://github.com/laugh12321/yol…...

分享uniapp + Springboot3+vue3小程序项目实战
分享uniapp Springboot3vue3小程序项目实战 经过10天敲代码,终于从零到项目测试完成,一个前后端分离的小程序实战项目学习完毕 时间从6月12日 到6月22日,具有程序开发基础,第一次写uniapp,Springboot以前用过,VUE3也…...

RVC模型训练全攻略:如何用3分钟打造专属语音模型
RVC模型训练全攻略:如何用3分钟打造专属语音模型 1. 引言:为什么选择RVC? 在当今数字内容创作蓬勃发展的时代,拥有一个独特的语音模型已经成为许多创作者和企业的刚需。RVC(Retrieval-Based Voice Conversion&#x…...

深入解析AdminBSB:Bootstrap 3.x与Material Design完美融合的终极指南
深入解析AdminBSB:Bootstrap 3.x与Material Design完美融合的终极指南 【免费下载链接】AdminBSBMaterialDesign AdminBSB - Free admin panel that is based on Bootstrap 3.x with Material Design 项目地址: https://gitcode.com/gh_mirrors/ad/AdminBSBMateri…...

WordPress内容组织终极指南:Argon主题标签与分类管理新策略
WordPress内容组织终极指南:Argon主题标签与分类管理新策略 【免费下载链接】argon-theme 📖 Argon - 一个轻盈、简洁的 WordPress 主题 项目地址: https://gitcode.com/gh_mirrors/ar/argon-theme Argon主题是一款轻盈、简洁的WordPress主题&…...

ArknightsGameResource:模块化游戏资源库与标准化数据解析技术指南
ArknightsGameResource:模块化游戏资源库与标准化数据解析技术指南 【免费下载链接】ArknightsGameResource 明日方舟客户端素材 项目地址: https://gitcode.com/gh_mirrors/ar/ArknightsGameResource ArknightsGameResource项目为《明日方舟》游戏开发者提供…...

Windows下MySQL服务报错1067别急着重装!一个my.ini参数拯救你的数据库
Windows下MySQL服务报错1067的深度修复指南 当你在Windows服务器上突然遭遇MySQL服务罢工,事件查看器里赫然显示着"错误1067:进程意外终止"的红色警告,那种焦虑感足以让任何运维人员心跳加速。但别急着掏出重装系统的终极武器——本…...

OpenClaw智能写作:Qwen3.5-9B根据截图生成技术博客
OpenClaw智能写作:Qwen3.5-9B根据截图生成技术博客 1. 为什么需要截图转技术博客的自动化方案 作为一名经常需要写技术文档的开发者和技术博主,我长期被两个问题困扰:一是截取了大量代码片段和报错信息后,整理成文章需要耗费大量…...

OpenClaw 控制面板侧边栏工具说明书
这份说明书基于 OpenClaw 官方文档整理,帮助你理解控制面板各个功能模块。版本:2026.3.31 📋 侧边栏工具概览 工具对应功能用途代理Agents(多代理)管理多个独立 AI 代理技能Skills安装和管理自定义技能节点Nodes配对的…...

玩转线控转向:从方向盘到轮胎的数学游戏
线控转向系统模型simulink, 以及理想传动比,变传动比,变角传动比simulink模块,分别在低速工况,中速工况,高速工况下进行对比仿真,结果较好 有对应绘图代码m脚本文件,模型对应的论文最近在Simuli…...

Janus-Pro-7B人力资源:简历截图信息抽取+岗位匹配度分析报告
Janus-Pro-7B人力资源:简历截图信息抽取岗位匹配度分析报告 1. 引言:智能招聘的新助手 招聘工作最头疼的是什么?每天收到上百份简历,一份份看下来眼睛都花了。更麻烦的是,还要手动从简历里提取关键信息,再…...

5个高效乐谱资源获取技巧:音乐爱好者的MuseScore下载指南
5个高效乐谱资源获取技巧:音乐爱好者的MuseScore下载指南 【免费下载链接】dl-librescore Download sheet music 项目地址: https://gitcode.com/gh_mirrors/dl/dl-librescore 在数字音乐时代,获取高质量乐谱资源往往面临格式限制、下载门槛等问题…...