基于LangChain框架搭建知识库
基于LangChain框架搭建知识库
- 说明
- 流程
- 1.数据加载
- 2.数据清洗
- 3.数据切分
- 4.获取向量
- 5.向量库保存到本地
- 6.向量搜索
- 7.汇总调用
说明
本文使用openai提供的embedding模型作为框架基础模型,知识库的搭建目的就是为了让大模型减少幻觉出现,实现起来也很简单,假如你要做一个大模型的客服问答系统,那么就把历史客服问答数据整理好,先做数据处理,在做数据向量化,最后保存到向量库中就可以了,下面文章中只是一个简单工作流程,只能用来参考,希望对大家有所帮助!
流程
上传知识库的文档不限于txt,pdf,markdown等数据格式,不同的数据格式用不同的方法来处理,文章内仅使用pdf文件做测试
1.数据加载
def load_data():from langchain.document_loaders.pdf import PyMuPDFLoader# 本地pdf文档路径loader = PyMuPDFLoader("./knowledge_db/pumkin_book/pumpkin_book.pdf")pdf_pages = loader.load()print(f"载入后的变量类型为:{type(pdf_pages)},", f"该 PDF 一共包含 {len(pdf_pages)} 页")pdf_page = pdf_pages[1]page_content = pdf_page.page_contentprint(f"每一个元素的类型:{type(pdf_page)}.",f"该文档的描述性数据:{pdf_page.metadata}",f"查看该文档的内容:\n{pdf_page.page_content}",sep="\n------\n")return page_content,pdf_pages
2.数据清洗
def clean_data(pdf_content):# 匹配非中文字符和换行符pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)# 将匹配到的换行符替换为空字符串new_pdf_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_content)# 去除。和空格符号new_pdf_content = new_pdf_content.replace('。', '').replace(' ', '')return new_pdf_content
3.数据切分
def split_data(pdf_pages,new_pdf_content):'''* RecursiveCharacterTextSplitter 递归字符文本分割RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置RecursiveCharacterTextSplitter需要关注的是4个参数:* separators - 分隔符字符串数组* chunk_size - 每个文档的字符数量限制* chunk_overlap - 两份文档重叠区域的长度* length_function - 长度计算函数'''from langchain.text_splitter import RecursiveCharacterTextSplitter# 知识库中单段文本长度CHUNK_SIZE = 500# 知识库中相邻文本重合长度OVERLAP_SIZE = 50# 使用递归字符文本分割器text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE)text_splitter.split_text(new_pdf_content[0:1000])split_docs = text_splitter.split_documents(pdf_pages)print(f"切分后的文件数量:{len(split_docs)}")print(f"切分后的字符数(可以用来大致评估 token 数):{sum([len(doc.page_content) for doc in split_docs])}")return split_docs
4.获取向量
def gpt_config():import httpx# 使用httpx设置代理proxy = 'http://127.0.0.1:8080' # 修改为自己的代理地址proxies = {'http://': proxy, 'https://': proxy}http_client = httpx.Client(proxies=proxies, verify=True)return http_clientdef get_vector(split_docs):# from langchain.embeddings import OpenAIEmbeddingsfrom langchain_openai import OpenAIEmbeddingsfrom langchain.vectorstores.chroma import Chromafrom dotenv import load_dotenv, find_dotenv# 获取key_ = load_dotenv(find_dotenv()) # 可注释api_key = os.environ.get("OPENAI_API_KEY")http_client = gpt_config()# 官网有提供3个embedding模型,按需选择embedding = OpenAIEmbeddings(model="text-embedding-3-small",openai_api_key=api_key,http_client=http_client)# 保存路径persist_directory = './vector_db/chroma'vectordb = Chroma.from_documents(documents=split_docs[:20], # 为了速度,只选择前 20 个切分的 doc 进行生成embedding=embedding,persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上)return vectordb
5.向量库保存到本地
def save_vector(vectordb):vectordb.persist()print(f"向量库中存储的数量:{vectordb._collection.count()}")
6.向量搜索
def search_vector(vectordb):question = '什么是机器学习'# 余弦相似度搜索search_result = vectordb.similarity_search(question, k=2) # k表示返回的相似文档数量print(f"检索到的内容数:{len(search_result)}")for i, sim_doc in enumerate(search_result):print(f"检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")# MMR搜索# 核心思想是在已经选择了一个相关性高的文档之后,再选择一个与已选文档相关性较低但是信息丰富的文档。这样可以在保持相关性的同时,增加内容的多样性,避免过于单一的结果。mmr_docs = vectordb.max_marginal_relevance_search(question, k=2)for i, sim_doc in enumerate(mmr_docs):print(f"MMR 检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")
7.汇总调用
def main_task():# 加载数据pdf_content,pdf_pages = load_data()# 数据清洗new_pdf_content = clean_data(pdf_content)# 切分数据split_docs = split_data(pdf_pages,new_pdf_content)# 获取向量vectordb = get_vector(split_docs)# 将向量库内容保存到本地文件中# save_vector(vectordb)# 向量搜索search_vector(vectordb)
相关文章:

基于LangChain框架搭建知识库
基于LangChain框架搭建知识库 说明流程1.数据加载2.数据清洗3.数据切分4.获取向量5.向量库保存到本地6.向量搜索7.汇总调用 说明 本文使用openai提供的embedding模型作为框架基础模型,知识库的搭建目的就是为了让大模型减少幻觉出现,实现起来也很简单&a…...

LeetCode 1789, 6, 138
目录 1789. 员工的直属部门题目链接表要求知识点思路代码 6. Z 字形变换题目链接标签思路代码 138. 随机链表的复制题目链接标签思路代码 1789. 员工的直属部门 题目链接 1789. 员工的直属部门 表 表Employee的字段为employee_id,department_id和primary_flag。…...

Redis部署模式全解析:单点、主从、哨兵与集群
Redis是一个高性能的键值存储系统,以其丰富的数据结构和优异的读写性能而闻名。在实际应用中,根据业务需求的不同,Redis可以部署在多种模式下。本文将详细介绍Redis的四种主要部署模式:单点模式、主从复制模式、哨兵模式以及集群模…...

python-docx顺序读取word内容
来源How to use Python iteration to read paragraphs, tables and pictures in word? Issue #650 python-openxml/python-docx (github.com) from docx import Document from docx.oxml.ns import qndef iter_block_items(parent):"""生成 paren…...
)
kafka 集群原理设计和实现概述(一)
kafka 集群原理设计和实现概述(一) Kafka 集群的设计原理是为了实现高可用性、高吞吐量、容错性和可扩展性。以下是 Kafka 集群的设计原 理及其实现方法: 1. 分布式架构设计 Kafka 采用分布式架构,集群中的多个 Broker 共同工作,负责接收、存储和传递消息。通过将数据分布…...

three.js 第十一节 - uv坐标
// ts-nocheck // 引入three.js import * as THREE from three // 导入轨道控制器 import { OrbitControls } from three/examples/jsm/controls/OrbitControls // 导入lil.gui import { GUI } from three/examples/jsm/libs/lil-gui.module.min.js // 导入tween import * as T…...

git从master分支创建分支
1. 切换到主分支或你想从哪里创建新分支 git checkout master 2. 创建并切换到新的本地分支 develop git checkout -b develop 3. 将新分支推送到远程存储库 git push origin develop 4. 设置本地 develop 分支跟踪远程 develop 分支 git branch --set-upstream-toorigi…...
Chromium 调试指南2024 Mac篇 - 准备工作 (一)
1.引言 Chromium是一个由Google主导开发的开源浏览器项目,它为Google Chrome浏览器提供了基础框架。Chromium不仅是研究和开发现代浏览器技术的重要平台,还为众多其他基于Chromium的浏览器(如Microsoft Edge、Brave等)提供了基础…...
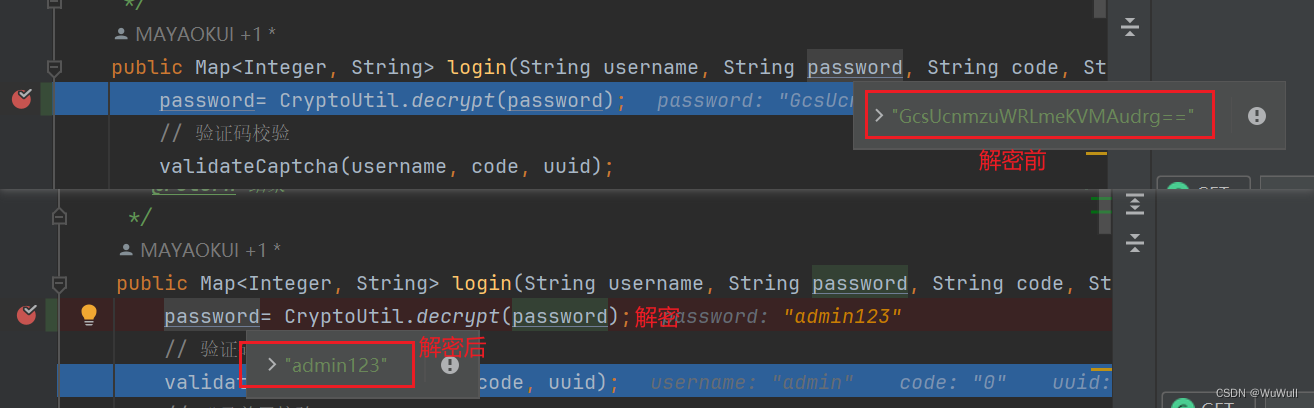
vue登陆密码加密,java后端解密
前端 安装crypto-js npm install crypto-js加密 //引入crypto-js import CryptoJS from crypto-js;/** ---密码加密 start--- */ const SECRET_KEY CryptoJS.enc.Utf8.parse("a15q8f6s5s1a2v3s"); const SECRET_IV CryptoJS.enc.Utf8.parse("a3c6g5h4v9sss…...
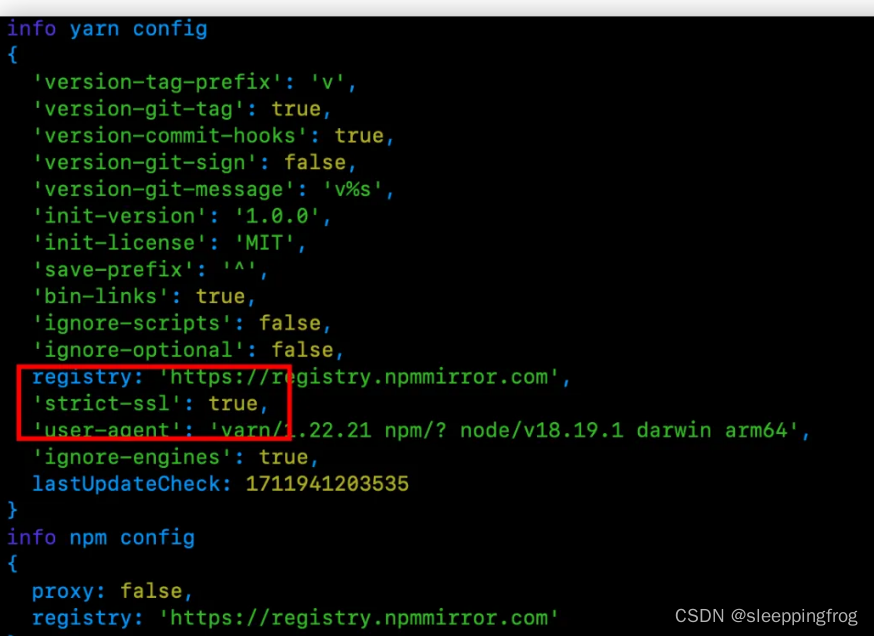
npm 安装踩坑
1 网络正常,但是以前的老项目安装依赖一直卡住无法安装?哪怕切换成淘宝镜像 解决办法:切换成yarn (1) npm i yarn -g(2) yarn init(3) yarn install在安装的过程中发现: [2/4] Fetching packages... error marked11.1.0:…...

内容安全复习 6 - 白帽子安全漏洞挖掘披露的法律风险
文章目录 安全漏洞的法律概念界定安全漏洞特征白帽子安全漏洞挖掘面临的法律风险“白帽子”安全漏洞挖掘的风险根源“白帽子”的主体边界授权行为边界关键结论 安全漏洞的法律概念界定 可以被利用来破坏所在系统的网络或信息安全的缺陷或错误;被利用的网络缺陷、错…...

dp经典问题:爬楼梯
dp经典问题:爬楼梯 爬楼梯 三步问题。有个小孩正在上楼梯,楼梯有n阶台阶,小孩一次可以上1阶、2阶或3阶。实现一种方法,计算小孩有多少种上楼梯的方式。结果可能很大,你需要对结果模1000000007。 Step1: 识别问题 这…...
示例:推荐一个基于第三方QRCoder.Xaml封装的二维码显示控件
一、目的:基于第三方QRCoder.Xaml封装的二维码控件,为了方便WPF调用 二、效果如下 功能包括:背景色,前景色,中心图片设置和修改大小,二维码设置等 三、环境 VS2022 四、使用方式 1、安装nuget包…...

阿里云服务器618没想到这么便宜,买早了!
2年前,我买了个服务器,租用服务器(ECS5)和网络宽带(1M),可以说是非常非常低的配置了。 当时5年的折扣力度最大,但是打完折后,价格依然要近3000多元。 最近看到阿里云618活…...

提升Python技能的七个函数式编程技巧
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 文章内容 📒📝 递归📝 结构化模式匹配📝 不变性📝 纯函数📝 高阶函数📝 函数组合📝 惰性求值⚓️ 相关链接 ⚓️📖 介绍 📖 在现代编程中,虽然Python并不是一门纯粹的函数式编程语言,但函数式编程(Funct…...
微型操作系统内核源码详解系列五(五):cm3下Pendsv切换任务上篇
系列一:微型操作系统内核源码详解系列一:rtos内核源码概论篇(以freertos为例)-CSDN博客 系列二:微型操作系统内核源码详解系列二:数据结构和对象篇(以freertos为例)-CSDN博客 系列…...

Django测试平台搭建学习笔记1
一安装 pip离线安装requests2.32.0所需要的依赖: : charset-normalizer<4,>2 (3.0.0b1) : idna<4,>2.5 (3.7) : urllib3<3,>1.21.1 (2.2.0) : certifi>2017.4.17 (2024.6.2) pip离线安装pytest8.2.0所需要的依赖: : iniconfig (2…...
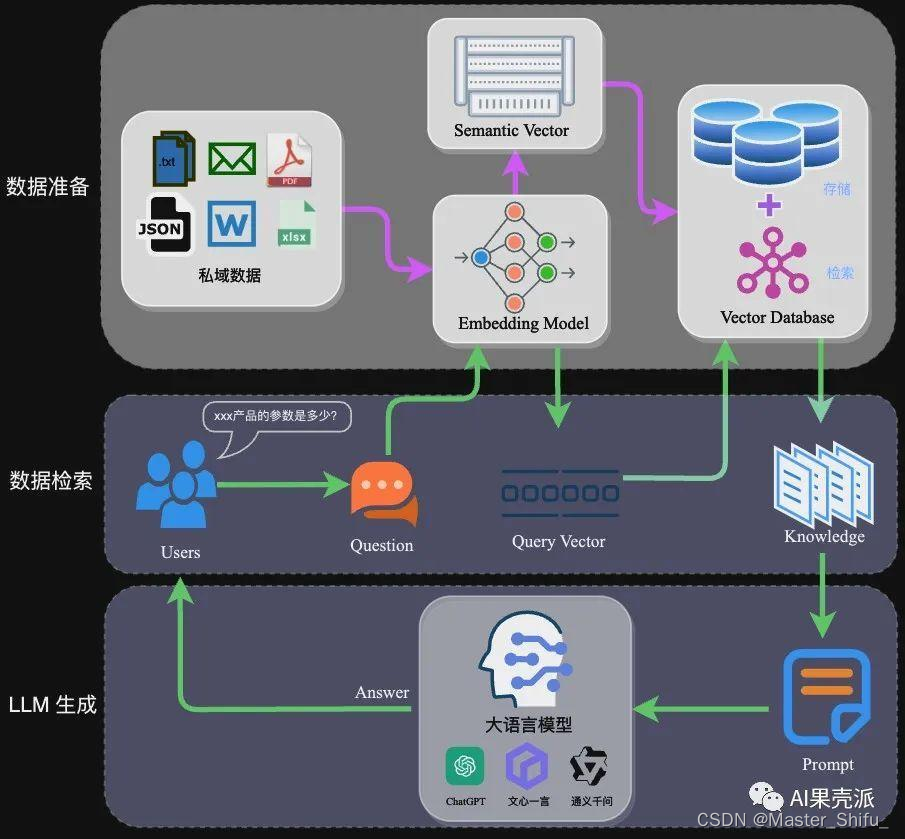
本地离线模型搭建指南-RAG架构实现
搭建一个本地中文大语言模型(LLM)涉及多个关键步骤,从选择模型底座,到运行机器和框架,再到具体的架构实现和训练方式。以下是一个详细的指南,帮助你从零开始构建和运行一个中文大语言模型。 本地离线模型搭…...

【IPython 使用技巧整理】
IPython 使用技巧整理 IPython 是一个交互式 Python 解释器,比标准 Python 解释器提供了更加强大的功能和更友好的使用体验。它为数据科学、机器学习和科学计算提供了强大的工具,是 Python 开发人员不可或缺的工具之一。本文将深入探讨 IPython 的各种使…...
什么是孪生素数猜想
什么是孪生素数猜想 素数p与素数p2有无穷多对 孪生素数的公式(详见百度百科:孪生素数公式) 利用素数的判定法则,可以得到以下的结论:“若自然数q与q2都不能被任何不大于的素数 整除,则q与q 2都是素数”…...

Wan2.2-I2V-A14B效果展示:支持语义分割引导的多对象独立运动控制
Wan2.2-I2V-A14B效果展示:支持语义分割引导的多对象独立运动控制 1. 惊艳的视频生成能力 Wan2.2-I2V-A14B模型带来了令人惊叹的视频生成效果,特别是其独特的语义分割引导和多对象独立运动控制能力。想象一下,你只需要用文字描述一个场景&am…...

华为eNSP实战:手把手教你用单臂路由打通不同VLAN,附排错命令清单
华为eNSP单臂路由实战:跨VLAN通信配置与深度排错指南 当企业网络规模扩大时,VLAN隔离是保障安全性和广播域控制的必要手段。但实际业务中,不同部门间的数据交互需求常常需要跨越VLAN边界。在华为认证体系HCIA和HCIP的实验环境中,单…...

基于U-Net的肺部CT结节检测系统设计与实现
摘要:肺癌是当前威胁人类健康的重要疾病之一,肺结节作为肺癌早期筛查和诊断的重要影像学表现,其准确检测具有重要意义。CT影像因具有较高的空间分辨率,被广泛应用于肺部疾病检查。然而,传统人工阅片方式存在工作量大、…...

【C++27 constexpr革命性突破】:5大新增约束与3类不可逆性能跃迁,资深编译器工程师亲授落地实践
第一章:C27 constexpr革命性突破的底层动因与标准演进全景C27 将首次允许 constexpr 函数完整支持动态内存分配(std::allocator 与 new/delete)、虚函数调用、异常处理(try/catch)及完整 I/O 流子集,其根本…...

终极MCP协议指南:从协议原理到Awesome MCP Servers完整实践
终极MCP协议指南:从协议原理到Awesome MCP Servers完整实践 【免费下载链接】awesome-mcp-servers A collection of MCP servers. 项目地址: https://gitcode.com/GitHub_Trending/aweso/awesome-mcp-servers MCP(Model Context Protocol…...

开源工具Wand-Enhancer功能增强技术解析与实战指南
开源工具Wand-Enhancer功能增强技术解析与实战指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 一、问题定位:WeMod功能增强的核心挑战 …...

OpenClaw日志分析实战:Phi-3-vision-128k-instruct多维度错误模式识别
OpenClaw日志分析实战:Phi-3-vision-128k-instruct多维度错误模式识别 1. 为什么需要智能日志分析 凌晨三点,我被手机警报惊醒——服务器又崩了。揉着惺忪睡眼打开终端,面对满屏的日志文件,那种熟悉的无力感再次袭来。这已经是本…...

被头条、站长论坛力荐!爱娃子博客:五年深耕,藏着普通人最动人的生活真相
在流量至上、内容同质化严重的当下,想找到一个不迎合热度、不堆砌噱头,却能让人反复品读、获得共鸣的博客,早已成为很多人的奢望。而今天要给大家推荐的爱娃子博客,正是这样一处被各大平台力荐的“心灵栖息地”——它不仅被今日头…...
)
2026 年真正必备的 10 个 Claude 插件(以及它们的作用)
如何把 Claude 从聊天机器人,变成能写代码、联网、访问数据、自动化全流程的超级 AIClaude 刚刚获得了超能力。 而大多数人还以为它只是个聊天机器人。 2026 年 2 月 24 日,Anthropic 为企业用户推出了私有插件市场。而在此两周前,社区已经发…...

Claude Code开源第一人,竟是华人辍学博士!CC之父回应:纯手误
51万行Claude Code代码全网裸奔,背后泄密第一人竟是他。就在刚刚,CC之父回应来了:是人,不是Bun。爆出Claude Code源码第一人,竟被全网扒出来了!3月31日凌晨4点23分,安全研究员Chaofan Shou在X上…...