VACUUM 剖析
VACUUM 剖析
为什么需要 Vacuum
MVCC
MVCC:Multi-Version Concurrency Control,即多版本并发控制。
PostgreSQL 使用多版本并发控制(MVCC)来支持高并发的事务处理,同时保持数据的一致性和隔离性。MVCC 是一种用于管理数据库并发操作的技术,它允许多个事务同时访问同一数据,而不会产生冲突或阻塞。
MVCC 的工作原理
-
版本化:
PostgreSQL 为表中的每行数据存储多个版本。当一个事务更新一行数据时,它不会立即覆盖原始数据,而是创建该数据的新版本。
-
事务ID:
每个事务被分配一个唯一的事务ID(XID),该ID 用于跟踪数据的变更。 -
快照:
当一个事务开始时,它会创建一个快照,该快照是数据库在某一时刻的状态。即使其他事务在该事务进行时对数据进行了更改,该事务仍然可以看到它开始时的数据库状态。 -
可见性规则:
MVCC 通过一组可见性规则来确定事务可以看到哪些数据版本。通常,一个事务只能看到在它开始之前已经提交的其他事务所做的更改。 -
垃圾回收:
PostgreSQL 使用VACUUM 命令来清理不再需要的数据版本,释放空间。VACUUM 操作由系统自动调度,也可以手动执行。
MVCC 的关键特点:
- 无锁读取:
MVCC 允许其他事务在读取数据时不被锁定,因为它们可以访问数据的旧版本。 - 写入时复制:
当数据被更新时,PostgreSQL 会复制旧版本的数据并创建新版本,而不是直接在原地修改。 - 隔离级别:
PostgreSQL 支持不同的事务隔离级别,如读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。隔离级别决定了事务可以看到其他事务更改的时间点。 - 性能:
MVCC 可以提高数据库的性能,因为它减少了锁的争用和事务间的阻塞。 - 一致性:
通过使用快照,MVCC 确保了事务在整个过程中看到的是一致性的数据视图。
MVCC 的挑战:
- 表膨胀:
由于多版本的存在,表可能会膨胀,需要定期维护。 - 长事务:
长事务可能导致较旧的数据版本长时间不被回收,从而影响性能和空间。 - 系统资源:
MVCC 需要额外的系统资源来管理多个数据版本。
MVCC 是 PostgreSQL 强大并发控制机制的核心,它使得数据库能够高效地处理大量的并发事务,同时保持数据的一致性和隔离性。
表膨胀
多版本并发控制机制(MVCC)的原理在于,当它需要更改某块数据的时候,它不会直接去更改,而是会创建这份数据的新版本,在新版本进行更改,所以会存储多份版本,每个事务能看见哪一份版本的数据,由事务隔离级别控制。
MVCC引入了一个问题,如何消除老旧的、没有使用的无用数据(版本),目前主流上有3种处理实现方式:
来看看各种数据库的解决方式:
-
以Oracle为代表的,把旧版本数据放入UNDO,新数据放入REDO,然后更改数据。这种方式,旧版本的数据放入了UNDO,所以可以有效避免膨胀。
-
以SQL Server为代表的,把旧版本的数据写入专门的临时表空间,新数据写入日志,然后去更改数据。这种方式,旧版本的数据放入了专门的临时表空间,所以也可以有效地避免膨胀。
-
以PostgreSQL为代表的,把旧版本标示为无效,新数据写入日志,成功后把新版本的数据写入新的位置。这种实现机制是导致数据膨胀严重的一个重要原因,因为旧版本的数据虽然表示为无效状态,但是没被回收前还是占据存储空间。
Vacuum 工作原理
PostgreSQL的表膨胀清理就需要依赖vacuum,vacuum的主要任务就是清理表和索引中不需要的数据(dead tuples),为新加入的数据清理出来空间。
Vacuum
PostgreSQL中的VACUUM命令是一种数据库维护任务,用于清理数据库中的无用空间(也称为“dead tuples”或“ghost tuples”),并防止表膨胀。VACUUM还更新数据库的统计信息,这些信息由查询优化器用来选择最有效的查询计划。以下是VACUUM如何工作的详细步骤:
- 标记删除:
PostgreSQL使用一种称为标记-清除(mark-sweep)的垃圾收集机制。当DELETE或UPDATE命令删除或修改表中的数据行时,原始数据行不会被立即从存储中移除,而是被标记为“已删除”。这意味着这些行仍然占用空间,但对查询来说是不可见的。 - 移除元组:
这里的移除dead tuples只是标记为可重用该空间,并没有真正物理删除。所以vacuum清理表后,表的实际空间并没有减小。dead tuples在做移除标记后,vacuum会重新排列剩余的元组以进行碎片化整理。然后,需要更新目标表的VM(可见性映射文件)和FSM(空闲空间映射文件)。 - 更新统计信息:
VACUUM收集有关表和索引中数据分布的统计信息,并将这些信息存储在系统目录中。这些统计信息对于查询优化器来说是至关重要的,因为它们帮助优化器决定如何执行查询。
VACUUM在这段时间删除的数据,并不会从此磁盘上删除,只是将数据标为可删除,这部分可删除的空间会出现以下两种情况:
- 当有新的数据进行,新数据会写入至这部分可删除的空间中,即老数据从磁盘上移除了
- 系统执行
vacuum full ,PgSql 会重新整理所有的元组(Tuples),最终将数据从磁盘上移除,这一步比较耗费资源和时间,有可能锁表,生产环境慎用!
Vacuum Full
Vacuum Full和Vacuum最大的不同就是,Vacuum Full是物理删除dead tuples,并把释放的空间重新交给操作系统,所以在vacuum full后,表的大小会减小为实际的空间大小。其处理过程和 vacuum 大不相同,处理步骤如下:
-
创建排它锁
vacuum full 开始执行时,系统会先对目标创建一个AccessExclusiveLock ,不允许外界再进行访问(为后面拷贝做准备)。
-
创建新表
系统会创建一张表结构和源表一模一样的新表,方便后续做数据操作。
-
复制数据
扫描目标表,把表中的live tuples 拷贝到新表中。
-
替换数据表
删除目标表,在新表上,重新创建索引,更新VM, FSM以及统计信息,相关系统表等。
综上所述,vacuum full的本质是生成一个新的数据文件,然后把原有表的live tuples存放到该数据文件中。对比vacuum, vacuum full缺点就是在执行期间不能对表进行访问,由于需要往新表中导入live tuples数据,其执行效率也会很慢。优点是执行后,表空间只存放live tuples,没有冗余的dead tuples,在执行查询效率上会有所提高。
但是,vacuum full 也有存在的问题,在执行过程中,它会block所有对表的访问,不只是写操作,读操作也会全部block。很多情况下这是不可接受的,尤其是生产环境。
Vacuum 的好处
PostgreSQL中的VACUUM命令具有多个好处,主要包括:
- 回收空间:
VACUUM可以清理数据库中的无用空间,即那些被标记为“已删除”的行占用的空间,从而释放这些空间供其他数据使用。 - 更新统计信息:
VACUUM会更新数据库的统计信息,这些信息对于查询优化器选择最有效的查询计划至关重要。 - 维护索引:
VACUUM还会维护索引,删除索引中指向已删除数据行的条目,并可能重建索引以优化性能。 - 防止表膨胀:随着时间推移,表中的死元组会越来越多,这会导致存储空间利用率下降,
VACUUM可以防止这种情况。 - 提高查询性能:通过清理无用的元组,
VACUUM可以减少查询需要遍历的数据量,从而提高查询性能。 - 自动回收空间:
VACUUM可以自动回收已经释放的空闲空间,减少了数据库管理员的手动干预。
VACUUM是PostgreSQL数据库维护和性能优化的重要组成部分,正确理解和运用VACUUM命令及其变种,对于保持数据库的良好运行状态具有重要意义。
Vacuum 的最佳实践
PostgreSQL中的VACUUM操作是数据库维护的重要组成部分,以下是一些最佳实践:
- 定期执行VACUUM:根据业务负载和表的更新频率,制定合理的VACUUM策略,特别是对于频繁更新的大表。
- 启用并调优Autovacuum:依赖Autovacuum来自动维护数据库健康。通过调整
autovacuum_vacuum_threshold和autovacuum_vacuum_scale_factor等参数,可以更精确地控制自动VACUUM的触发时机。 - 考虑使用VACUUM FULL:虽然
VACUUM FULL可以最大程度地释放磁盘空间,但由于它可能会锁定表并需要较长时间执行,建议在业务低峰期使用,并确保有足够的磁盘空间来创建表的新副本。 - 监控Vacuum活动:利用
pg_stat_user_tables视图或其他监控工具,了解Vacuum操作的状态和效果,以便及时调整相关参数。 - 不要无故运行手动VACUUM或ANALYZE:Autovacuum通常可以很好地管理数据库,除非有特殊情况,否则不必频繁手动执行这些操作。
- 在数据批量加载后运行ANALYZE:在大量新数据被插入数据库后,运行ANALYZE以确保统计信息的准确性,从而帮助查询优化器制定更有效的查询计划。
- 收集数据库信息:在调整参数或实施手动VACUUM/ANALYZE之前,收集有关数据库的足够信息,如表的行数、死元组数、最后一次VACUUM/ANALYZE的时间等,以便做出更明智的决策。
通过遵循这些最佳实践,可以确保数据库的性能和健康状况得到良好的维护。
参考文档:
Kimi.ai - 帮你看更大的世界
PostgreSQL的表膨胀与Vacuum和Vacuum Full - 明矾 - 博客园
深入浅出 PostgreSQL VACUUM 流程,全面掌控数据健康与性能! - ByteZoneX社区
blog/202405/20240530_01.md at master · digoal/blog · GitHub
相关文章:

VACUUM 剖析
VACUUM 剖析 为什么需要 Vacuum MVCC MVCC:Multi-Version Concurrency Control,即多版本并发控制。 PostgreSQL 使用多版本并发控制(MVCC)来支持高并发的事务处理,同时保持数据的一致性和隔离性。MVCC 是一种用于管…...

基于LangChain框架搭建知识库
基于LangChain框架搭建知识库 说明流程1.数据加载2.数据清洗3.数据切分4.获取向量5.向量库保存到本地6.向量搜索7.汇总调用 说明 本文使用openai提供的embedding模型作为框架基础模型,知识库的搭建目的就是为了让大模型减少幻觉出现,实现起来也很简单&a…...

LeetCode 1789, 6, 138
目录 1789. 员工的直属部门题目链接表要求知识点思路代码 6. Z 字形变换题目链接标签思路代码 138. 随机链表的复制题目链接标签思路代码 1789. 员工的直属部门 题目链接 1789. 员工的直属部门 表 表Employee的字段为employee_id,department_id和primary_flag。…...

Redis部署模式全解析:单点、主从、哨兵与集群
Redis是一个高性能的键值存储系统,以其丰富的数据结构和优异的读写性能而闻名。在实际应用中,根据业务需求的不同,Redis可以部署在多种模式下。本文将详细介绍Redis的四种主要部署模式:单点模式、主从复制模式、哨兵模式以及集群模…...

python-docx顺序读取word内容
来源How to use Python iteration to read paragraphs, tables and pictures in word? Issue #650 python-openxml/python-docx (github.com) from docx import Document from docx.oxml.ns import qndef iter_block_items(parent):"""生成 paren…...
)
kafka 集群原理设计和实现概述(一)
kafka 集群原理设计和实现概述(一) Kafka 集群的设计原理是为了实现高可用性、高吞吐量、容错性和可扩展性。以下是 Kafka 集群的设计原 理及其实现方法: 1. 分布式架构设计 Kafka 采用分布式架构,集群中的多个 Broker 共同工作,负责接收、存储和传递消息。通过将数据分布…...

three.js 第十一节 - uv坐标
// ts-nocheck // 引入three.js import * as THREE from three // 导入轨道控制器 import { OrbitControls } from three/examples/jsm/controls/OrbitControls // 导入lil.gui import { GUI } from three/examples/jsm/libs/lil-gui.module.min.js // 导入tween import * as T…...

git从master分支创建分支
1. 切换到主分支或你想从哪里创建新分支 git checkout master 2. 创建并切换到新的本地分支 develop git checkout -b develop 3. 将新分支推送到远程存储库 git push origin develop 4. 设置本地 develop 分支跟踪远程 develop 分支 git branch --set-upstream-toorigi…...
Chromium 调试指南2024 Mac篇 - 准备工作 (一)
1.引言 Chromium是一个由Google主导开发的开源浏览器项目,它为Google Chrome浏览器提供了基础框架。Chromium不仅是研究和开发现代浏览器技术的重要平台,还为众多其他基于Chromium的浏览器(如Microsoft Edge、Brave等)提供了基础…...
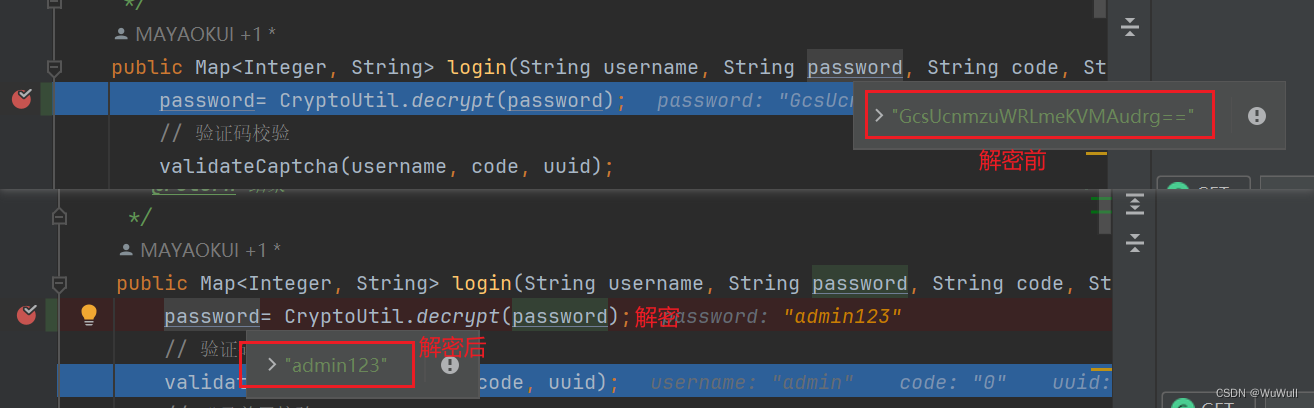
vue登陆密码加密,java后端解密
前端 安装crypto-js npm install crypto-js加密 //引入crypto-js import CryptoJS from crypto-js;/** ---密码加密 start--- */ const SECRET_KEY CryptoJS.enc.Utf8.parse("a15q8f6s5s1a2v3s"); const SECRET_IV CryptoJS.enc.Utf8.parse("a3c6g5h4v9sss…...
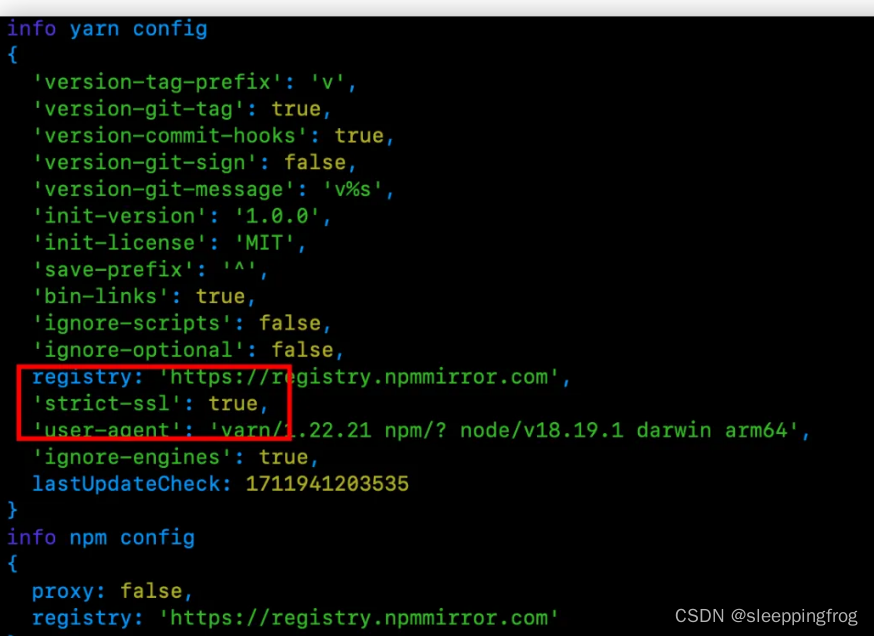
npm 安装踩坑
1 网络正常,但是以前的老项目安装依赖一直卡住无法安装?哪怕切换成淘宝镜像 解决办法:切换成yarn (1) npm i yarn -g(2) yarn init(3) yarn install在安装的过程中发现: [2/4] Fetching packages... error marked11.1.0:…...

内容安全复习 6 - 白帽子安全漏洞挖掘披露的法律风险
文章目录 安全漏洞的法律概念界定安全漏洞特征白帽子安全漏洞挖掘面临的法律风险“白帽子”安全漏洞挖掘的风险根源“白帽子”的主体边界授权行为边界关键结论 安全漏洞的法律概念界定 可以被利用来破坏所在系统的网络或信息安全的缺陷或错误;被利用的网络缺陷、错…...

dp经典问题:爬楼梯
dp经典问题:爬楼梯 爬楼梯 三步问题。有个小孩正在上楼梯,楼梯有n阶台阶,小孩一次可以上1阶、2阶或3阶。实现一种方法,计算小孩有多少种上楼梯的方式。结果可能很大,你需要对结果模1000000007。 Step1: 识别问题 这…...
示例:推荐一个基于第三方QRCoder.Xaml封装的二维码显示控件
一、目的:基于第三方QRCoder.Xaml封装的二维码控件,为了方便WPF调用 二、效果如下 功能包括:背景色,前景色,中心图片设置和修改大小,二维码设置等 三、环境 VS2022 四、使用方式 1、安装nuget包…...

阿里云服务器618没想到这么便宜,买早了!
2年前,我买了个服务器,租用服务器(ECS5)和网络宽带(1M),可以说是非常非常低的配置了。 当时5年的折扣力度最大,但是打完折后,价格依然要近3000多元。 最近看到阿里云618活…...

提升Python技能的七个函数式编程技巧
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 文章内容 📒📝 递归📝 结构化模式匹配📝 不变性📝 纯函数📝 高阶函数📝 函数组合📝 惰性求值⚓️ 相关链接 ⚓️📖 介绍 📖 在现代编程中,虽然Python并不是一门纯粹的函数式编程语言,但函数式编程(Funct…...
微型操作系统内核源码详解系列五(五):cm3下Pendsv切换任务上篇
系列一:微型操作系统内核源码详解系列一:rtos内核源码概论篇(以freertos为例)-CSDN博客 系列二:微型操作系统内核源码详解系列二:数据结构和对象篇(以freertos为例)-CSDN博客 系列…...

Django测试平台搭建学习笔记1
一安装 pip离线安装requests2.32.0所需要的依赖: : charset-normalizer<4,>2 (3.0.0b1) : idna<4,>2.5 (3.7) : urllib3<3,>1.21.1 (2.2.0) : certifi>2017.4.17 (2024.6.2) pip离线安装pytest8.2.0所需要的依赖: : iniconfig (2…...
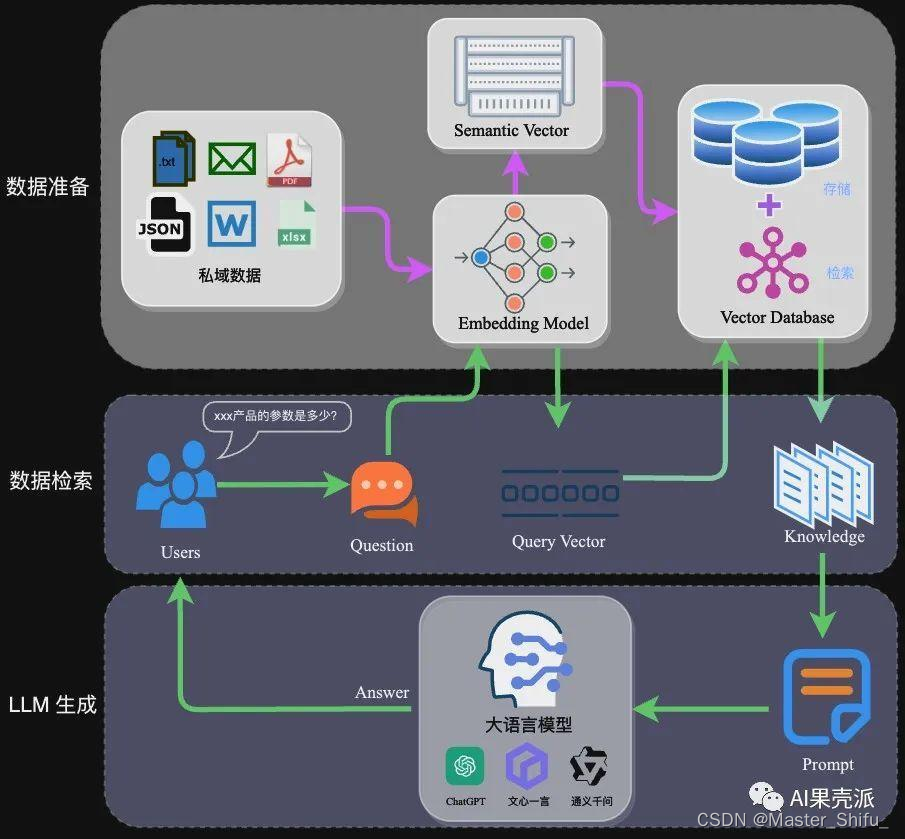
本地离线模型搭建指南-RAG架构实现
搭建一个本地中文大语言模型(LLM)涉及多个关键步骤,从选择模型底座,到运行机器和框架,再到具体的架构实现和训练方式。以下是一个详细的指南,帮助你从零开始构建和运行一个中文大语言模型。 本地离线模型搭…...

【IPython 使用技巧整理】
IPython 使用技巧整理 IPython 是一个交互式 Python 解释器,比标准 Python 解释器提供了更加强大的功能和更友好的使用体验。它为数据科学、机器学习和科学计算提供了强大的工具,是 Python 开发人员不可或缺的工具之一。本文将深入探讨 IPython 的各种使…...

Claude颠覆AI编程
🚀 Claude 4 正式发布!Anthropic 这次真的要颠覆 AI 编程了 今天,AI 领域迎来核弹级更新——Anthropic 正式发布 Claude 4 系列模型!免费可用、7 小时自主编程,开发者直呼"生产力革命来了"! 一、…...

文墨共鸣大模型在网络安全领域的应用:模拟攻击脚本分析与安全报告撰写
文墨共鸣大模型在网络安全领域的应用:模拟攻击脚本分析与安全报告撰写 最近和几个做安全的朋友聊天,他们都在抱怨同一个问题:每天面对海量的告警日志和五花八门的攻击脚本,分析起来耗时费力,写报告更是头疼。技术细节…...

OpenClaw技能共享:将Qwen2.5-VL-7B定制插件发布到ClawHub
OpenClaw技能共享:将Qwen2.5-VL-7B定制插件发布到ClawHub 1. 为什么需要共享OpenClaw技能 去年我开发了一个基于Qwen2.5-VL-7B的图片分析插件,能够自动识别截图中的UI元素并生成操作指令。当我发现这个插件在团队内部被反复复制粘贴使用时,…...

Amazon Q 从入门到实战,AWS 专属 AI 助手超全指南
目录 一、Amazon Q 到底是什么 二、Amazon Q 有两个版本 1、Amazon Q Developer(给开发者/运维) 2、Amazon Q Bussiness(给企业/业务人员) 三、Amazon Q能解决什么实际问题 四、Amazon Q 和 Chat GPT 同类助手的有什么区别 …...

Open-AutoGLM场景实战:电商购物、出行旅游、内容浏览一键完成
Open-AutoGLM场景实战:电商购物、出行旅游、内容浏览一键完成 1. 引言:手机AI助手的革命性突破 想象一下这样的场景:早上醒来,你对手机说"帮我订一杯星巴克拿铁和一份三明治",手机自动完成打开外卖应用、选…...
基于 Python + PyQt5 + Matplotlib + Pandas 实现的学生成绩分析系统框架)
Python➕PyQt5➕numpy➕pandas实现学生成绩分析系统(可视化)基于 Python + PyQt5 + Matplotlib + Pandas 实现的学生成绩分析系统框架
基于 Python PyQt5 Matplotlib Pandas 实现的学生成绩分析系统框架 Python➕PyQt5➕numpy➕pandas实现学生成绩分析系统(可视化) (源码项目文档详细README) !!代码注释非常详细 !!…...
)
Python MCP服务可观测性革命:OpenTelemetry+Prometheus+Grafana三件套零代码接入方案(附完整YAML模板)
第一章:Python MCP服务可观测性革命概述在微服务架构持续演进的今天,Python构建的MCP(Metrics, Context, and Propagation)服务正成为可观测性实践的关键载体。传统日志聚合与单点监控已难以应对跨服务调用链中上下文丢失、指标语…...

Phi-4-mini-reasoning推理能力展示:多步分析题目的简洁结论生成效果
Phi-4-mini-reasoning推理能力展示:多步分析题目的简洁结论生成效果 1. 模型介绍 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,特别擅长处理需要多步分析的题目。与通用聊天模型不同,它被设计用来解决数学题、逻辑题等需要严谨…...

再次了解 AI Harness
这其实是一次 tenantId 联调 bug,暴露了 AI 项目最缺的不是模型,而是Harness前面没整理完的关于Harness Engineering 的文章,为啥整理这一篇是因为这让我意识到一个趋势正在形成:AI 开发正在从"写提示词"转向"构建…...

当AI真正“看懂“你的屏幕:GPT-5.4如何重新定义人机协作的边界
摘要: 2026年3月,OpenAI发布了GPT-5.4。这不是一次普通的模型迭代,而是一次能力边界的重新定义——它首次实现了原生的"计算机使用"能力,能在桌面上像人类一样点击按钮、填写表单、操作软件;它拥有五级可调的…...