TWM论文阅读笔记

- 这是ICLR2023的一篇world model论文,用transformer来做世界模型的sequence prediction。
- 文章贡献是transformer-based world model(不同于以往的如transdreamer的world model,本文的transformer-based world model在inference 的时候可以丢掉)两个损失,一个采样策略。
WM
- TWM用的仍然是经典的world model框架:
- encoder-decoder用的是VAE,不过输入是四帧而不是一帧
- dynamic model用过去 l l l 步的 z z z a a a r r r 和当前的 z z z a a a作为输入,用transformer预测 h t h_t ht,再用 h t h_t ht预测 r t r_t rt, γ t \gamma_t γt和 z t + 1 z_{t+1} zt+1,如下:
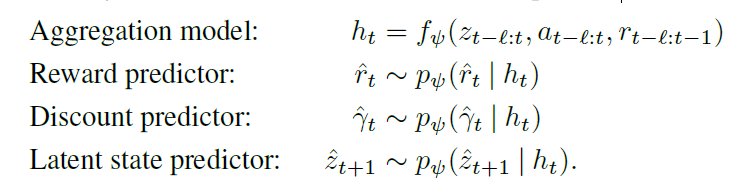
- 上面的三个 p p p都是MLP, f f f是transformerXL, 3 l − 1 3l-1 3l−1个token输入,预测一个token:
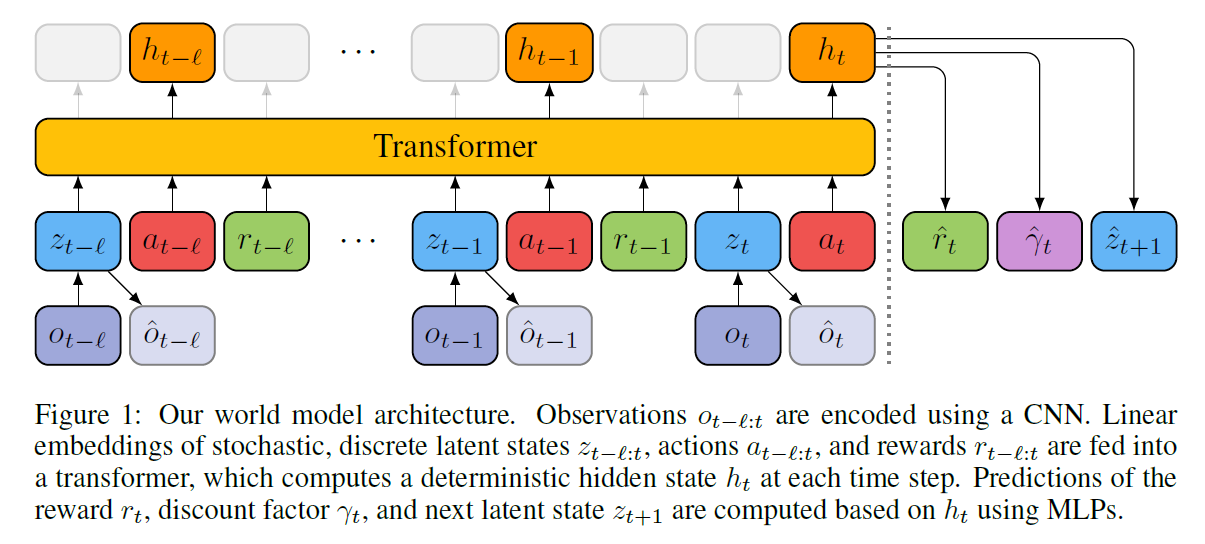
- z,r,gamma的MLP的输出分别是:a vector of independent categorical distributions, a normal distribution,
and a Bernoulli distribution
- 提的两个损失,一个是如下的encoder-decoder的损失,由三项组成,第一项是VAE的损失,第二项是对z的熵损失,第三项是与sequence model的一致损失:
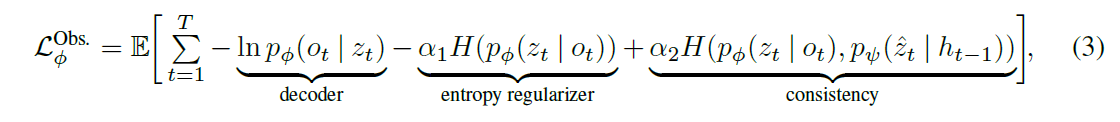
- 第二个损失是用来train sequence model的,第一项其实跟上一个损失的第三项一样,但是上一个损失是train VAE的,这个损失是train sequence model的;第二项第三项不用说,就是正常的reward和discount的损失:
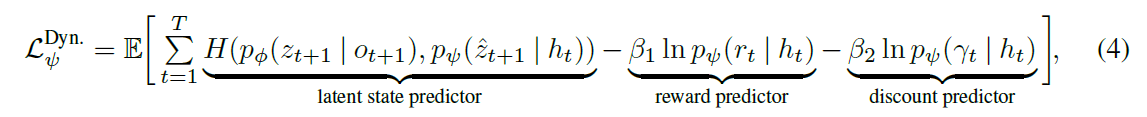
- 相比LSTM GRU之类模型,transformer的好处在于长序列建模,sequence model总是能看到过去 l l l步发生的确切的事情,而非仅能观察到一个压缩的状态 h t h_t ht
RL
- 这里可以看到,dreamerv3等模型预测的是奖励 r t r_t rt 和terminate d t d_t dt,但是TWM预测的是discount factor γ \gamma γ,在这里就可以派上用场了,预测的 γ \gamma γ用来train RL模型(而其他的WM,RL模型的 γ \gamma γ用的是固定值)。那么训练的时候 γ \gamma γ怎么监督呢,文章定义的label是 γ t = 0 \gamma_t=0 γt=0和 γ t = γ \gamma_t=\gamma γt=γ,即当terminate的时候 γ = 0 \gamma=0 γ=0而其他时候 γ \gamma γ是固定值,label是这样,而模型应该会灵活预测?不知道
- 这里有一些新的损失,比如对策略的熵的损失,不能低于一个阈值:
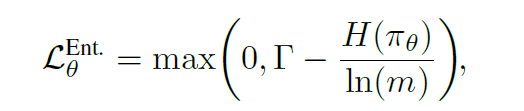
- 这里还要关注的是policy model的输入,一般policy model的输入是 z t z_t zt和 h t h_t ht的concate,如dreamerv3和STORM,文章试了发现decoder的输出也可以(IRIS就这么干的), o t o_t ot也可以,本文用的是 z t z_t zt,比较轻量快速,只需要encoder而不需要sequence model。并且,训练的时候用的是sequence model预测的zt,而测试的时候则用的是encoder编码的zt加上frame stacking操作(这里有点疑问,维度?)
- train的时候还是常规的三步走:用RL model采样,train world model,用world model train RL model。
- training的时候有个sampling的stategy,如下, 是为了让模型更关注后面采样得到的sample,但vt的公式也没给,之说是incremented every time an entry is sampled:
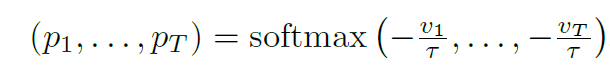
相关文章:
TWM论文阅读笔记
这是ICLR2023的一篇world model论文,用transformer来做世界模型的sequence prediction。文章贡献是transformer-based world model(不同于以往的如transdreamer的world model,本文的transformer-based world model在inference 的时候可以丢掉…...
探索ChatTTS项目:高效的文字转语音解决方案
文章目录 📖 介绍 📖📒 ChatTTS 📒📝 项目介绍📝 项目亮点📝 UI 🎈 项目地址 🎈 📖 介绍 📖 在AI技术迅速发展的今天,文本到语音&…...

[Django学习]Q对象实现多字段模糊搜索
一、应用场景 假设我们现在有一个客房系统,前端界面上展示出来了所有客房的所有信息。用户通过客房的价格、面积、人数等对客房进行模糊搜索,如检索出价格在50到100元之间的客房,同时检索面积在20平方米到30平方米之间的客房,此时后端可以借助…...

transdreamer 论文阅读笔记
这篇文章是对dreamer系列的改进,是一篇world model 的论文改进点在于,dreamer用的是循环神经网络,本文想把它改成transformer,并且希望能利用transformer实现并行训练。改成transformer的话有个地方要改掉,dreamer用ht…...

AIGC技术的发展现状与未来趋势探讨
AIGC技术的发展现状与未来趋势探讨 随着人工智能(AI)技术的迅猛发展,AI生成内容(AI-Generated Content,AIGC)成为了一项颠覆性的技术,它能够自动生成文本、图像、音频和视频等多种内容。本文将…...
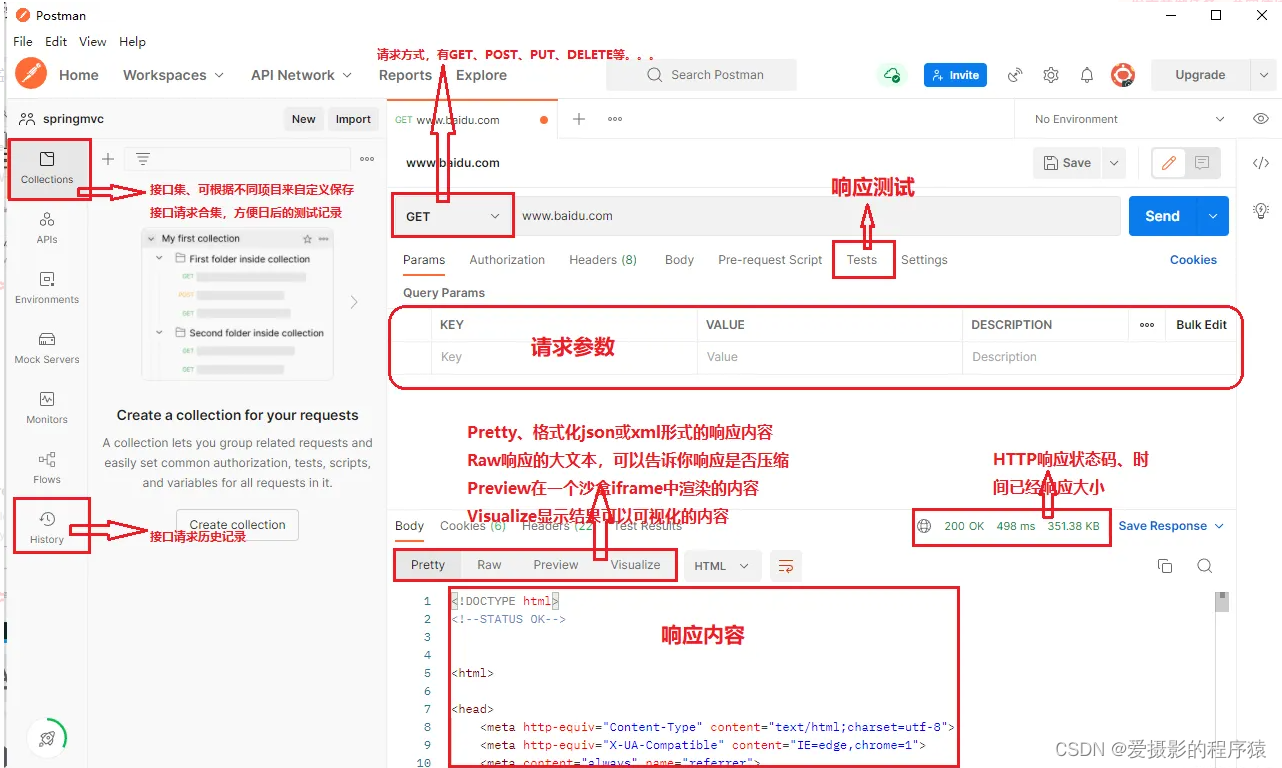
Postman Postman接口测试工具使用简介
Postman这个接口测试工具的使用做个简单的介绍,仅供参考。 插件安装 1)下载并安装chrome浏览器 2)如下 软件使用说明...
)
Java开发笔记Ⅱ(Jsoup爬虫)
Jsoup 爬虫 Java 也能写爬虫!!! Jsoup重要对象如下: Document:文档对象,每个html页面都是一个Document对象 Element:元素对象,一个Document对象里有多个Element对象 Node&#…...
一五三、MAC 安装MongoDB可视化工具连接
若没有安装brew包管理工具,在命令行输入安装命令 /bin/bash -c “$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)”上面步骤安装完成后,开始安装MongoDB,输入安装命令: brew tap mongodb/brewbrew u…...
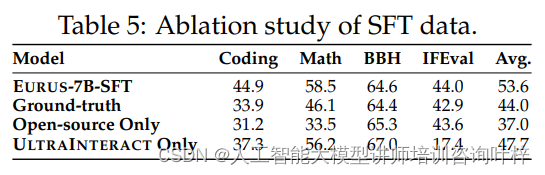
ULTRAINTERACT 数据集与 EURUS 模型:推动开源大型语言模型在推理领域的新进展
在人工智能的浪潮中,大型语言模型(LLMs)已经成为推动自然语言处理技术发展的关键力量。它们在理解、生成语言以及执行复杂任务方面展现出了巨大的潜力。然而,尽管在特定领域内取得了显著进展,现有的开源LLMs在处理多样…...
【leetcode刷题】面试经典150题 , 27. 移除元素
leetcode刷题 面试经典150 27. 移除元素 难度:简单 文章目录 一、题目内容二、自己实现代码2.1 方法一:直接硬找2.1.1 实现思路2.1.2 实现代码2.1.3 结果分析 2.2 方法二:排序整体删除再补充2.1.1 实现思路2.1.2 实现代码2.1.3 结果分析 三、…...

红队内网攻防渗透:内网渗透之内网对抗:横向移动篇PTH哈希PTT票据PTK密匙Kerberoast攻击点TGTNTLM爆破
红队内网攻防渗透 1. 内网横向移动1.1 首要知识点1.2 PTH1.2.1 利用思路第1种:利用直接的Hash传递1.2.1.1、Mimikatz1.2.2 利用思路第2种:利用hash转成ptt传递1.2.3 利用思路第3种:利用hash进行暴力猜解明文1.2.4 利用思路第4种:修改注册表重启进行获取明文1.3 PTT1.3.1、漏…...

springBoot不同module之间互相依赖
在 Spring Boot 多模块项目中,不同模块之间的依赖通常是通过 Maven 或 Gradle 来管理的。以下是一个示例结构和如何设置这些依赖的示例。 项目结构 假设我们有一个多模块的 Spring Boot 项目,结构如下: my-springboot-project │ ├── p…...

[modern c++] 类型萃取 type_traits
前言: #include <type_traits> type_traits 又叫类型萃取,是一个在编译阶段用于进行 类型判断/类型变更 的库,在c11中引入。因为其工作阶段是在编译阶段,因此被大量应用在模板编程中,同时也可以结合 constexpr…...

函数模板和类模板的区别
函数模板和类模板在C中都是重要的泛型编程工具,但它们之间存在一些显著的区别。以下是它们之间的主要区别: 实例化方式: 函数模板:隐式实例化。当函数模板被调用时,编译器会根据传递给它的参数类型自动推断出模板参数…...

ChatGPT 提示词技巧一本速通
目录 一、基本术语 二、提示词设计的基本原则 三、书写技巧 2.1 赋予角色 2.2 使用分隔符 2.2 结构化输出 2.3 指定步骤 2.4 提供示例 2.5 指定长度 2.6 使用或引用参考文本 2.7 提示模型进行自我判断 2.8 思考问题的解决过程 编辑 2.10 询问是否有遗漏 2.11 …...
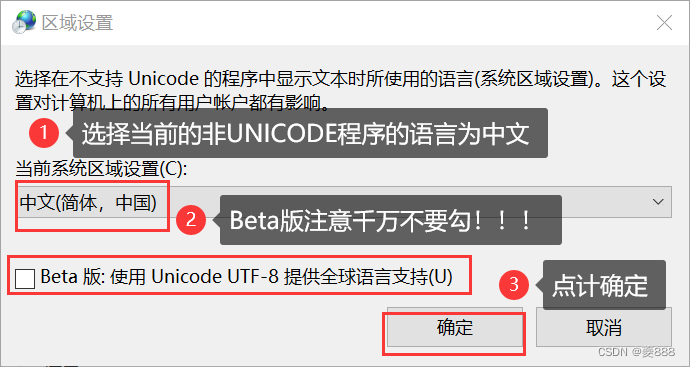
【windows解压】解压文件名乱码
windows解压,文件名乱码但内容正常。 我也不知道什么时候设置出的问题。。。换了解压工具也没用,后来是这样解决的。 目录 1.环境和工具 2.打开【控制面板】 3.点击【时钟和区域】 4.选择【区域】 5.【管理】中【更改系统区域设置】 6.选择并确定…...

使用Flink CDC实时监控MySQL数据库变更
在现代数据架构中,实时数据处理变得越来越重要。Flink CDC(Change Data Capture)是一种强大的工具,可以帮助我们实时捕获数据库的变更,并进行处理。本文将介绍如何使用Flink CDC从MySQL数据库中读取变更数据࿰…...

学生课程信息管理系统
摘 要 目前,随着科学经济的不断发展,高校规模不断扩大,所招收的学生人数越来越 多;所开设的课程也越来越多。随之而来的是高校需要管理更多的事务。对于日益增 长的学生相关专业的课程也在不断增多,高校对其管理具有一…...
如何看待鸿蒙HarmonyOS?
鸿蒙系统,自2019年8月9日诞生就一直处于舆论风口浪尖上的系统,从最开始的“套壳”OpenHarmony安卓的说法,到去年的不再兼容安卓的NEXT版本的技术预览版发布,对于鸿蒙到底是什么,以及鸿蒙的应用开发的讨论从来没停止过。…...
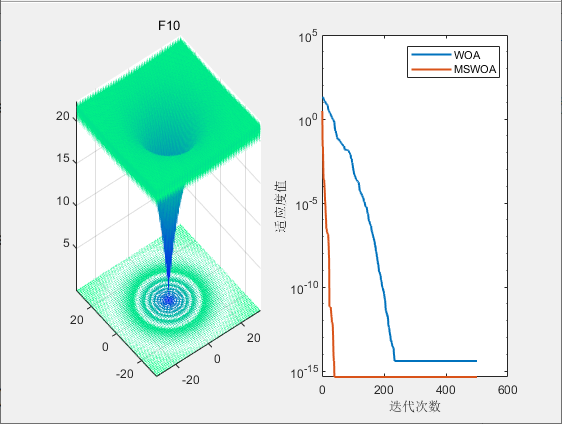
【论文复现|智能算法改进】一种基于多策略改进的鲸鱼算法
目录 1.算法原理2.改进点3.结果展示4.参考文献5.代码获取 1.算法原理 SCI二区|鲸鱼优化算法(WOA)原理及实现【附完整Matlab代码】 2.改进点 混沌反向学习策略 将混沌映射和反向学习策略结合,形成混沌反向学习方法,通过该方 法…...

独立开发者如何借助Taotoken多模型能力打造全能AI助手应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken多模型能力打造全能AI助手应用 对于独立开发者或小型工作室而言,构建一个功能全面的AI助手…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

前端工程化实战:基于 Kelivo 模板的配置即代码与自动化工作流
1. 项目概述与核心价值最近在整理个人开发环境时,发现一个挺有意思的项目,叫Chevey339/kelivo。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它是一个围绕特定开发工具或框架进行深度定制、优化和功能增…...

线程化笔记工具:重塑深度思考与知识管理的技术实践
1. 项目概述:一个为线程化思考而生的笔记工具最近在折腾个人知识管理工具时,发现了一个挺有意思的开源项目:alishobeiri/thread-notebook。乍一看名字,可能会以为是又一个普通的Markdown笔记本应用。但深入使用后,我发…...
)
乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓)
更多请点击: https://intelliparadigm.com 第一章:乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓) ElevenLabs 官方文档中仅标注 ur 为乌尔…...

天学网口碑好不好?2026年最新用户实测反馈给你答案
作为深耕教育数字化落地领域5年的从业者,最近后台收到不少公立校电教组老师、学生家长的提问:主打AI英语教学的天学网口碑到底怎么样?刚好我们团队刚做完2026年第一季度的英语教育数字化工具落地效果调研,结合一手实测数据给大家客…...

构建轻量级应用沙盒:Microverse原理与实践指南
1. 项目概述:一个轻量级、可移植的“微宇宙”开发沙盒最近在折腾一些边缘计算和嵌入式AI应用的原型验证,经常遇到一个头疼的问题:开发环境和部署环境不一致。在本地笔记本上跑得好好的Python脚本,放到树莓派或者Jetson Nano上&…...

开源大模型推理引擎Takeoff部署指南:从原理到生产实践
1. 项目概述:一个让大模型推理“起飞”的开源引擎 如果你正在为如何将那些动辄几十GB、几百亿参数的大语言模型(LLM)部署到生产环境而头疼,或者厌倦了为每一次API调用支付高昂的费用,那么今天聊的这个项目,…...

龙芯3A6000平台Loongnix系统部署实战:从固件更新到驱动配置全解析
1. 项目概述:一次国产平台上的系统部署实战最近,我拿到了一台基于龙芯3A6000处理器和7A2000桥片的国产台式机。对于长期在x86/ARM生态里打转的开发者来说,这无疑是一个充满新鲜感和挑战的“新玩具”。它的核心使命,就是运行龙芯社…...

毫米波ISAC技术:车联网中的感知与通信融合方案
1. 毫米波ISAC系统概述在智能交通系统快速发展的今天,毫米波集成感知与通信(ISAC)技术正成为解决车联网(V2X)需求的关键方案。这项技术的核心创新点在于,它巧妙地将雷达感知和无线通信两大功能整合到同一硬件平台上,通过共享60GHz毫米波频段资…...