算法常见手写代码
1.NMS
def py_cpu_nms(dets, thresh):"""Pure Python NMS baseline."""#x1、y1、x2、y2、以及score赋值x1 = dets[:, 0]y1 = dets[:, 1]x2 = dets[:, 2]y2 = dets[:, 3]scores = dets[:, 4]#每一个检测框的面积areas = (x2 - x1 + 1) * (y2 - y1 + 1)#按照score置信度降序排序order = scores.argsort()[::-1]keep = [] #保留的结果框集合while order.size > 0:i = order[0]keep.append(i) #保留该类剩余box中得分最高的一个#得到相交区域,左上及右下xx1 = np.maximum(x1[i], x1[order[1:]])yy1 = np.maximum(y1[i], y1[order[1:]])xx2 = np.minimum(x2[i], x2[order[1:]])yy2 = np.minimum(y2[i], y2[order[1:]])#计算相交的面积,不重叠时面积为0w = np.maximum(0.0, xx2 - xx1 + 1)h = np.maximum(0.0, yy2 - yy1 + 1)inter = w * h#计算IoU:重叠面积 /(面积1+面积2-重叠面积)ovr = inter / (areas[i] + areas[order[1:]] - inter)#保留IoU小于阈值的boxinds = np.where(ovr <= thresh)[0]order = order[inds + 1] #因为ovr数组的长度比order数组少一个,所以这里要将所有下标后移一位return keep2.交叉熵损失函数
实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。
![]()
a.Python 实现
def cross_entropy(a, y):
return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))
b.# tensorflow version
loss = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y), reduction_indices=[1]))
c.# numpy version
loss = np.mean(-np.sum(y_*np.log(y), axis=1))
3.Softmax 函数
将激活值与所有神经元的输出值联系在一起,所有神经元的激活值加起来为1。
第L层(最后一层)的第j个神经元的激活输出为:
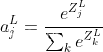
Python 实现:
def softmax(x):
shift_x = x - np.max(x) # 防止输入增大时输出为nan
exp_x = np.exp(shift_x)
return exp_x / np.sum(exp_x)
4.iou
def IoU(box1, box2) -> float:
"""
IOU, Intersection over Union
:param box1: list, 第一个框的两个坐标点位置 box1[x1, y1, x2, y2]
:param box2: list, 第二个框的两个坐标点位置 box2[x1, y1, x2, y2]
:return: float, 交并比
"""
weight = max(min(box1[2], box2[2]) - max(box1[0], box2[0]), 0)
height = max(min(box1[3], box2[3]) - max(box1[1], box2[1]), 0)
s_inter = weight * height
s_box1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
s_box2 = (box2[2] - box2[0]) * (box2[3] - box2[1])
s_union = s_box1 + s_box2 - s_inter
return s_inter / s_union
if __name__ == '__main__':
box1 = [0, 0, 50, 50]
box2 = [0, 0, 100, 100]
print('IoU is %f' % IoU(box1, box2))
5. 将一维数组转变成二维数组
class Solution:def construct2DArray(self, original: List[int], m: int, n: int) -> List[List[int]]:return [original[i: i + n] for i in range(0, len(original), n)] if len(original) == m * n else []6.MAP
AP衡量的是对一个类检测好坏,mAP就是对多个类的检测好坏。就是简单粗暴的把所有类的AP值取平均就好了。比如有两类,类A的AP值是0.5,类B的AP值是0.2,那么mAP=(0.5+0.2)/2=0.35
# AP的计算
def _average_precision(self, rec, prec):"""Params:----------rec : numpy.arraycumulated recallprec : numpy.arraycumulated precisionReturns:----------ap as float"""if rec is None or prec is None:return np.nanap = 0.for t in np.arange(0., 1.1, 0.1): #十一个点的召回率,对应精度最大值if np.sum(rec >= t) == 0:p = 0else:p = np.max(np.nan_to_num(prec)[rec >= t])ap += p / 11. #加权平均return ap7.手写conv2d
class Conv2D(Layer):"""A 2D Convolution Layer.Parameters:-----------n_filters: intThe number of filters that will convolve over the input matrix. The number of channelsof the output shape.filter_shape: tupleA tuple (filter_height, filter_width).input_shape: tupleThe shape of the expected input of the layer. (batch_size, channels, height, width)Only needs to be specified for first layer in the network.padding: stringEither 'same' or 'valid'. 'same' results in padding being added so that the output height and widthmatches the input height and width. For 'valid' no padding is added.stride: intThe stride length of the filters during the convolution over the input."""def __init__(self, n_filters, filter_shape, input_shape=None, padding='same', stride=1):self.n_filters = n_filtersself.filter_shape = filter_shapeself.padding = paddingself.stride = strideself.input_shape = input_shapeself.trainable = Truedef initialize(self, optimizer):# Initialize the weightsfilter_height, filter_width = self.filter_shapechannels = self.input_shape[0]limit = 1 / math.sqrt(np.prod(self.filter_shape))self.W = np.random.uniform(-limit, limit, size=(self.n_filters, channels, filter_height, filter_width))self.w0 = np.zeros((self.n_filters, 1))# Weight optimizersself.W_opt = copy.copy(optimizer)self.w0_opt = copy.copy(optimizer)def parameters(self):return np.prod(self.W.shape) + np.prod(self.w0.shape)def forward_pass(self, X, training=True):batch_size, channels, height, width = X.shapeself.layer_input = X# Turn image shape into column shape# (enables dot product between input and weights)self.X_col = image_to_column(X, self.filter_shape, stride=self.stride, output_shape=self.padding)# Turn weights into column shapeself.W_col = self.W.reshape((self.n_filters, -1))# Calculate outputoutput = self.W_col.dot(self.X_col) + self.w0# Reshape into (n_filters, out_height, out_width, batch_size)output = output.reshape(self.output_shape() + (batch_size, ))# Redistribute axises so that batch size comes firstreturn output.transpose(3,0,1,2)def backward_pass(self, accum_grad):# Reshape accumulated gradient into column shapeaccum_grad = accum_grad.transpose(1, 2, 3, 0).reshape(self.n_filters, -1)if self.trainable:# Take dot product between column shaped accum. gradient and column shape# layer input to determine the gradient at the layer with respect to layer weightsgrad_w = accum_grad.dot(self.X_col.T).reshape(self.W.shape)# The gradient with respect to bias terms is the sum similarly to in Dense layergrad_w0 = np.sum(accum_grad, axis=1, keepdims=True)# Update the layers weightsself.W = self.W_opt.update(self.W, grad_w)self.w0 = self.w0_opt.update(self.w0, grad_w0)# Recalculate the gradient which will be propogated back to prev. layeraccum_grad = self.W_col.T.dot(accum_grad)# Reshape from column shape to image shapeaccum_grad = column_to_image(accum_grad,self.layer_input.shape,self.filter_shape,stride=self.stride,output_shape=self.padding)return accum_graddef output_shape(self):channels, height, width = self.input_shapepad_h, pad_w = determine_padding(self.filter_shape, output_shape=self.padding)output_height = (height + np.sum(pad_h) - self.filter_shape[0]) / self.stride + 1output_width = (width + np.sum(pad_w) - self.filter_shape[1]) / self.stride + 1return self.n_filters, int(output_height), int(output_width)
8.手写PyTorch加载和保存模型
仅保存和加载模型参数(推荐)
a.保存模型参数
import torch
import torch.nn as nn
model = nn.Sequential(nn.Linear(128, 16), nn.ReLU(), nn.Linear(16, 1))
# 保存整个模型
torch.save(model.state_dict(), 'sample_model.pt')
加载模型参数
import torch
import torch.nn as nn
# 下载模型参数 并放到模型中
loaded_model = nn.Sequential(nn.Linear(128, 16), nn.ReLU(), nn.Linear(16, 1))
loaded_model.load_state_dict(torch.load('sample_model.pt'))
print(loaded_model)
显示如下:
Sequential(
(0): Linear(in_features=128, out_features=16, bias=True)
(1): ReLU()
(2): Linear(in_features=16, out_features=1, bias=True)
)
state_dict:PyTorch中的state_dict是一个python字典对象,将每个层映射到其参数Tensor。state_dict对象存储模型的可学习参数,即权重和偏差,并且可以非常容易地序列化和保存。
b. 保存和加载整个模型
保存整个模型
import torch
import torch.nn as nn
net = nn.Sequential(nn.Linear(128, 16), nn.ReLU(), nn.Linear(16, 1))
# 保存整个模型,包含模型结构和参数
torch.save(net, 'sample_model.pt')
#加载整个模型
import torch
import torch.nn as nn
# 加载整个模型,包含模型结构和参数
loaded_model = torch.load('sample_model.pt')
print(loaded_model)
显示如下:
Sequential(
(0): Linear(in_features=128, out_features=16, bias=True)
(1): ReLU()
(2): Linear(in_features=16, out_features=1, bias=True)
)
相关文章:
算法常见手写代码
1.NMS def py_cpu_nms(dets, thresh):"""Pure Python NMS baseline."""#x1、y1、x2、y2、以及score赋值x1 dets[:, 0]y1 dets[:, 1]x2 dets[:, 2]y2 dets[:, 3]scores dets[:, 4]#每一个检测框的面积areas (x2 - x1 1) * (y2 - y1 1)#按…...

数据结构9——排序
一、冒泡排序 冒泡排序(Bubble Sort),顾名思义,就是指越小的元素会经由交换慢慢“浮”到数列的顶端。 算法原理 从左到右,依次比较相邻的元素大小,更大的元素交换到右边;从第一组相邻元素比较…...

分布式锁实现方案-基于Redis实现的分布式锁
目录 一、基于Lua看门狗实现 1.1 缓存实体 1.2 延迟队列存储实体 1.3 分布式锁RedisDistributedLockWithDog 1.4 看门狗线程续期 1.5 测试类 1.6 测试结果 1.7 总结 二、RedLock分布式锁 2.1 Redlock分布式锁简介 2.2 RedLock测试例子 2.3 RedLock 加锁核心源码分析…...

MTK7628+MT7612 加PA定频数据
1、硬件型号TR726A5G121-DPA PC9.02.0017。如下所示: 2、WIFI5.8 AC模式 42(5120MHz)信道,80带宽 3、WIFI5.8 AC模式 38(5190MHz)信道,40带宽 4、WIFI5.8 AC模式 36(5180 MHz&…...

[信号与系统]关于双线性变换
前言 本文还是前置知识 双线性变换法 双线性变换法(Bilinear Transform)是一种用于将模拟滤波器转换为数字滤波器的方法。它通过将模拟域中的s平面上的传递函数映射到数字域中的z平面上的传递函数来实现这一转换。双线性变换法保证了频率响应在转换过…...
763. 划分字母区间
题目:给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。返回一个表示每个字符串片段的长度的列表…...

【PostgreSQL】AUTO_EXPLAIN - 慢速查询的日志执行计划
本文为云贝教育 刘峰 原创,请尊重知识产权,转发请注明出处,不接受任何抄袭、演绎和未经注明出处的转载。 一、介绍 在本文中,我们将了解 PostgreSQL AUTO_EXPLAIN功能的工作原理,以及为什么应该使用它来收集在生产系统…...

讯飞星火超自然语言合成的完整Demo
依赖文件和功能 requirements.txt 该文件列出了所需的依赖包。 data.py 定义了应用的配置信息,如APPId,APIKey,APISecret等。包含请求数据和请求URL。 main.py 主程序,设置了WebSocket连接,定义了处理消息的各个回调函…...
)
封装一个上拉加载的组件(无限滚动)
一、封装 1.这个是在vue3环境下的封装 2.整体思路: 2.1传入一个elRef,其实就是一个使用页面的ref。 2.2也可以不传elRef,则默认滚动的是window。 import { onMounted, onUnmounted, ref } from vue; import { throttle } from underscore;ex…...
)
WHAT - 高性能和内存安全的 Rust(二)
目录 1. 所有权(Ownership)2. 借用(Borrowing)不可变借用可变借用 3. 可变性(Mutability)4. 作用域(Scope)综合示例 了解 Rust 的所有权(ownership)、借用&am…...

办理河南建筑工程乙级设计资质的流程与要点
办理河南建筑工程乙级设计资质的流程与要点 办理河南建筑工程乙级设计资质的流程与要点主要包括以下几个方面: 流程: 工商注册与资质规划:确保企业具有独立法人资格,完成工商注册,并明确乙级设计资质的具体要求&…...

分类算法和回归算法区别
分类算法和回归算法在机器学习中扮演着不同的角色,它们的主要区别体现在输出类型、应用场景以及算法目标上。以下是对两者区别和使用场景的详细分析: 一、区别 1.输出类型: 分类算法:输出是离散的类别标签,通常表示为…...
利用Frp实现内网穿透(docker实现)
文章目录 1、WSL子系统配置2、腾讯云服务器安装frps2.1、创建配置文件2.2 、创建frps容器 3、WSL2子系统Centos服务器安装frpc服务3.1、安装docker3.2、创建配置文件3.3 、创建frpc容器 4、WSL2子系统Centos服务器安装nginx服务 环境配置:一台公网服务器(…...

怎么用Excel生成标签打印模板,自动生成二维码
环境: EXCEL2021 16.0 问题描述: 怎么用excel生成标签打印模板自动生成二维码 解决方案: 在Excel中生成标签打印模板并自动生成二维码,可以通过以下几个步骤完成: 1. 准备数据 首先,确保你的Excel表…...
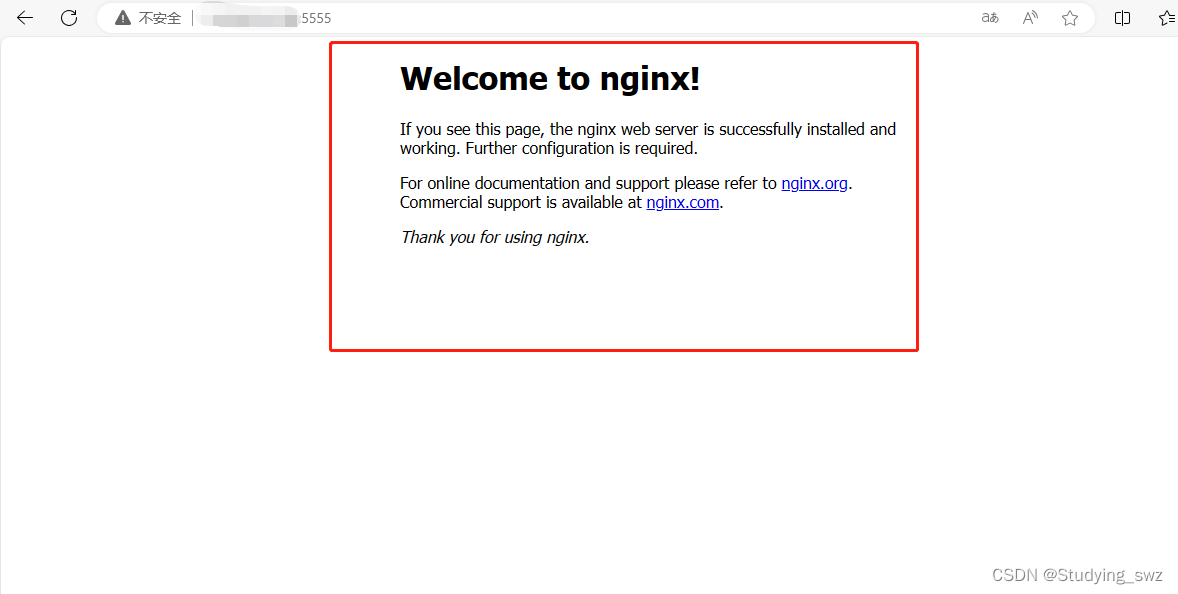
java基于ssm+jsp 美食推荐管理系统
1前台首页功能模块 美食推荐管理系统,在系统首页可以查看首页、热门美食、美食教程、美食店铺、美食社区、美食资讯、我的、跳转到后台等内容,如图1所示。 图1前台首页功能界面图 用户注册,在注册页面可以填写用户名、密码、姓名、联系电话等…...
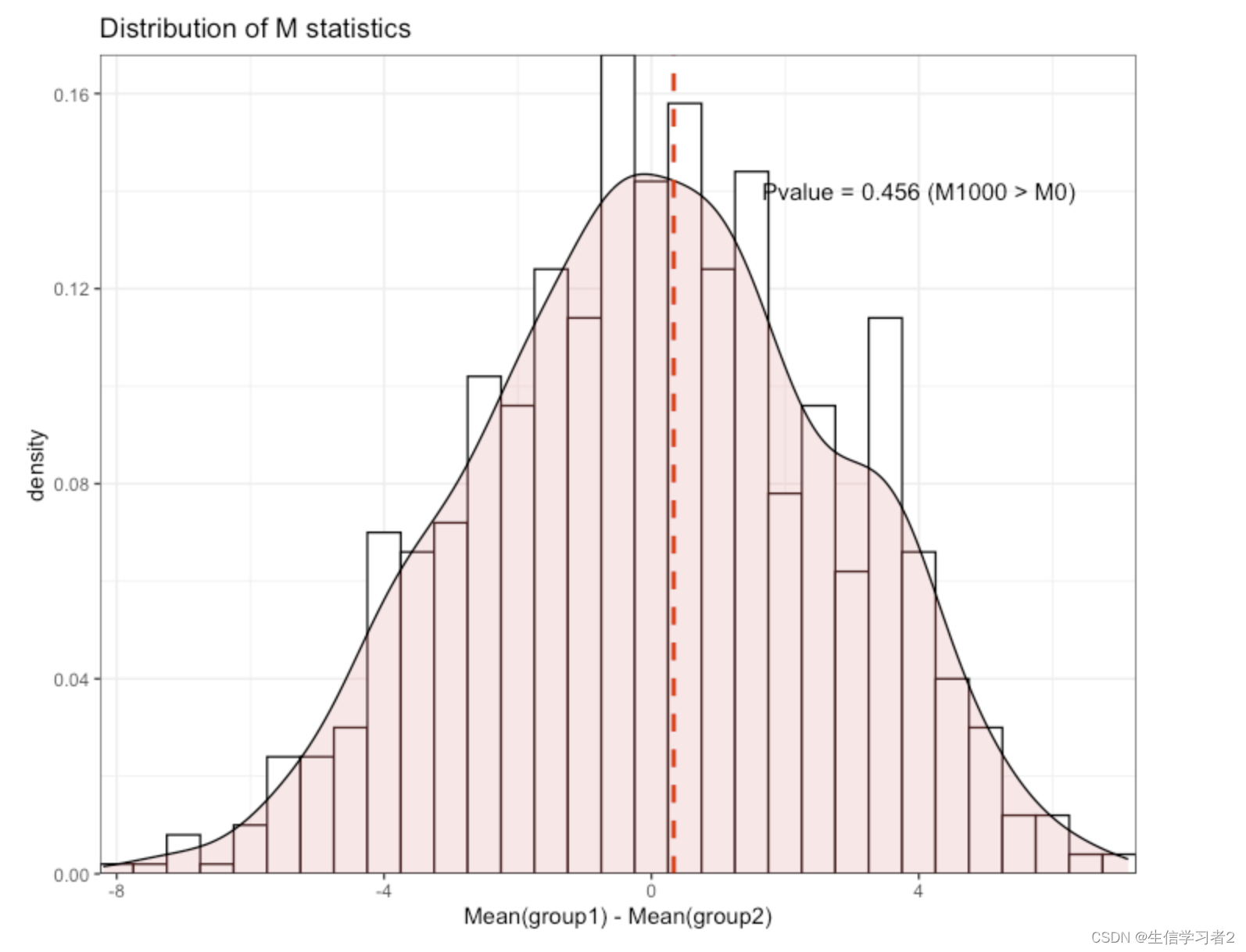
数据分析:置换检验Permutation Test
欢迎大家关注全网生信学习者系列: WX公zhong号:生信学习者Xiao hong书:生信学习者知hu:生信学习者CDSN:生信学习者2 介绍 置换检验是一种非参数统计方法,它不依赖于数据的分布形态,因此特别适…...
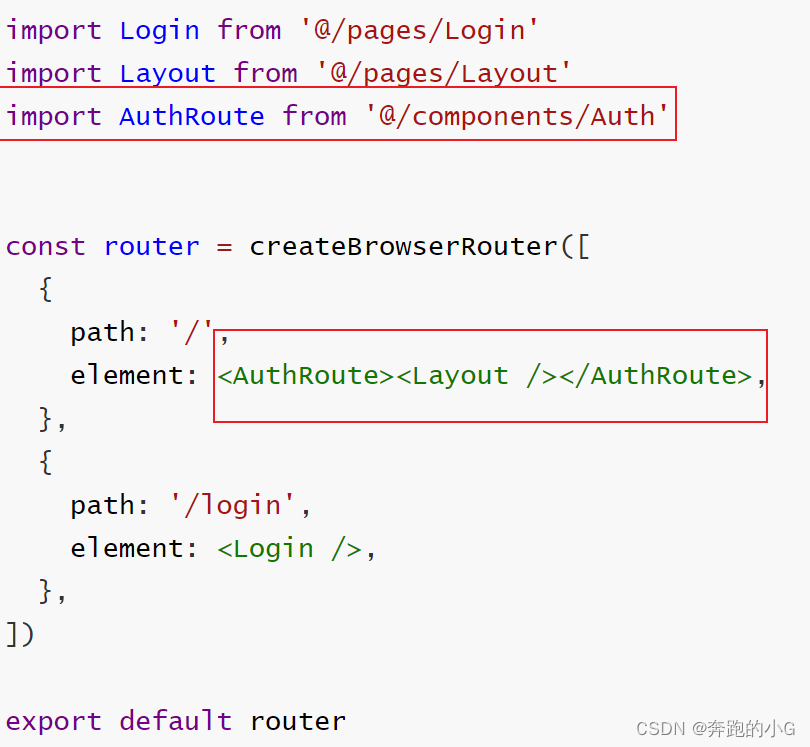
【React】使用Token做路由权限控制
在components/AuthRoute/index.js中 import { getToken } from /utils import { Navigate } from react-router-domconst AuthRoute ({ children }) > {const isToken getToken()if (isToken) {return <>{children}</>} else {return <Navigate to"/…...

机器学习周记(第四十四周:Robformer)2024.6.17~2024.6.23
目录 摘要ABSTRACT1 论文信息1.1 论文标题1.2 论文摘要1.3 论文引言1.4 论文贡献 2 论文模型2.1 问题描述2.2 Robformer2.2.1 Encoder2.2.2 Decoder 2.3 鲁棒序列分解模块2.4 季节性成分调整模块 摘要 本周阅读了一篇利用改进 Transformer 进行长时间序列预测的论文。论文模型…...

JAVA学习笔记DAY10——SpringBoot基础
文章目录 SpringBoot3 介绍SpringBoot 快速入门SpringBootApplication SpringBoot 配置文件统一配置管理Yaml 配置优势tips SpringBoot 整合 SpringMVC静态资源拦截器 interceptor SpringBoot 整合 DruidSpringBoot 整合 MybatisSpringBoot 整合 tx aopSpringBoot 打包 SpringB…...

如何在Android中实现多线程与线程池?
目录 一、Android介绍二、什么是多线程三、什么是线程池四、如何在Android中实现多线程与线程池 一、Android介绍 Android是一种基于Linux内核的开源操作系统,由Google公司领导开发。它最初于2007年发布,旨在为移动设备提供一种统一、可扩展的操作系统。…...

靠谱的微晶电热板机构
在实验设备领域,微晶电热板是一款重要的工具,选择靠谱的机构至关重要。微晶电热板的重要性微晶电热板在环境监测、食品安全、农产品检测等分析实验室中应用广泛。它能够为样品前处理提供稳定的加热环境,保障实验结果的准确性。行业报告显示&a…...
)
为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败?——2024最新L10n兼容性白皮书首发(附实测RTT延迟对比数据)
更多请点击: https://intelliparadigm.com 第一章:为什么92%的斯里兰卡项目在ElevenLabs僧伽罗文语音上失败? ElevenLabs 官方文档明确声明支持僧伽罗文(Sinhala),但实际部署中,斯里兰卡本地政…...

Steam游戏清单一键下载:告别繁琐操作,3分钟搞定你的游戏库管理
Steam游戏清单一键下载:告别繁琐操作,3分钟搞定你的游戏库管理 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而烦恼吗?Oneke…...

【ElevenLabs情绪语音实战指南】:3步解锁开心语音API调用、情感强度微调与合规避坑全链路
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs开心情绪语音技术全景概览 核心技术能力 ElevenLabs 的开心情绪语音生成并非简单音调拉升或语速加快,而是基于多任务情感条件建模(Multi-Task Emotional Conditionin…...

2025最权威的十大AI辅助写作助手推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下快节奏的学术钻研环境里头,做研究的人跟学生们时常会碰到时间紧张以及写作…...

3个技巧让FanControl风扇识别率提升90%:Windows 11用户的实战指南
3个技巧让FanControl风扇识别率提升90%:Windows 11用户的实战指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_…...

用 IDENTITY 数据销毁对象处理个人数据销毁,SAP ILM 场景下的信息检索与合规闭环
做 SAP 系统里的个人数据治理,最怕的不是删除动作本身,而是删除之前没有把数据的来源、用途、保留规则、可检索性和审计链路讲清楚。一个系统里只要出现客户、联系人、消费者、会员、订阅人、业务伙伴、技术访问账号等身份相关对象,围绕这些对象产生的姓名、邮箱、手机号、登…...

AppleJuice与法律边界:如何在教育框架内负责任地使用
AppleJuice与法律边界:如何在教育框架内负责任地使用 【免费下载链接】AppleJuice Apple BLE proximity pairing message spoofing 项目地址: https://gitcode.com/gh_mirrors/ap/AppleJuice AppleJuice作为一款专注于Apple BLE近距离配对消息模拟的开源项目…...

Windows平台终极ADB驱动环境一键配置指南:告别繁琐,专注开发
Windows平台终极ADB驱动环境一键配置指南:告别繁琐,专注开发 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com…...

Windows热键侦探:快速定位热键冲突的终极解决方案
Windows热键侦探:快速定位热键冲突的终极解决方案 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经遇…...