sql资料库
1、distinct(关键词distinct用于返回唯一不同的值):查询结果中去除重复行的关键字
select distinct(university) from user_profile select distinct university from user_profile distinct是紧跟在select后面的,不能在其他位置,不然就会报错,
当distinct去重多个字段,是去掉多行一摸一样的数据,保留一行数据的:
SELECT distinct name, continent FROM world多个列去重的时候,不能用distinct(name,continent),不能加括号,
2、limit:限制返回的数据的数量
SELECT column1, column2, ...
FROM table_name
LIMIT [offset,] row_count;offset,row_count都是可选的;offset是从第几行开始;row_count是显示多少行;
显示前两行数据:
select device_id from user_profile limit 2从第一行开始显示2行数据:
select device_id from user_profile limit 0,23、as:为列指定别名,可以省略
给返回值device_id这一列重新命名为:user_infos_example
select device_id as user_infos_example from user_profile limit 2 省略写法:
select device_id user_infos_example from user_profile limit 2 4、age不为空
where age is not null或where age!=" "5、and的优先级高于or
select device_id,gender,age,university,gpa
from user_profile
where gpa>3.5 and university="山东大学"or
gpa>3.8 and university="复旦大学"6、聚合函数:对一组值执行计算并返回单一的值
常见的5个聚合函数:sum()、avg() 、max() 、min() 、count()
聚合函数不能作为where的条件,不能用where筛选可以用having
select university,
avg(question_cnt) as avg_question_cnt ,
avg(answer_cnt) as avg_answer_cnt
from user_profile
group by university
having avg_question_cnt<5 or avg_answer_cnt<20聚合函数忽略空值
7、SQL语句执行顺序
sql的语法顺序:
select、from、join、where、group by、having、order by、limit
SELECT COUNT(*)
FROM employees
JOIN departments ON employees.department_id = departments.id
WHERE departments.name = 'Sales'
GROUP BY employees.name
HAVING COUNT(*) > 2
ORDER BY COUNT(*) DESC
LIMIT 5;sql的执行顺序:
from、where、group by、having、select、order by、limit
8、select后面的要查询的结果,可以用函数,可以进行计算,
就是select 字段名,计算字段,函数 。。。
select name, gdp, population, gdp/population 人均gdp from world看上面的算“人均gdp”的列,就直接用“gdp/population”了

9、like是模糊查询,后面跟通配符,"_" ,"%"两种
"_"是占位符,"%"是通配符,
例如:查询name中第二个字母是“t“的字段
select name
from world
where name like '_t%'10、order by 字段名 asc/desc,字段名 asc/desc (默认升序排序,asc升序排序可以省略)
11、count(*)计算总行数
12、group by和select的相互牵制

因为select是最后执行的,group by先分组,然后去重
如果不使用group by时,使用聚合函数,那么select后面不能有字段名,只能用聚合函数或者聚合函数参与的运算:
select name, count(*) from students像上面的代码会报错,不能聚合函数和非聚合函数一起查询
只有使用了group by,select后面才能跟字段名,而且是 group by后面出现的字段名,不是后面出现的也不能用
下面这个可以,因为sex是group by后面出现过的字段
select sex, count(*) from students
group by sex这个不可以,因为name不是 group by后面出现过的字段
select name, count(*) from students
group by sex13、 group by的原理
先把数据分区:
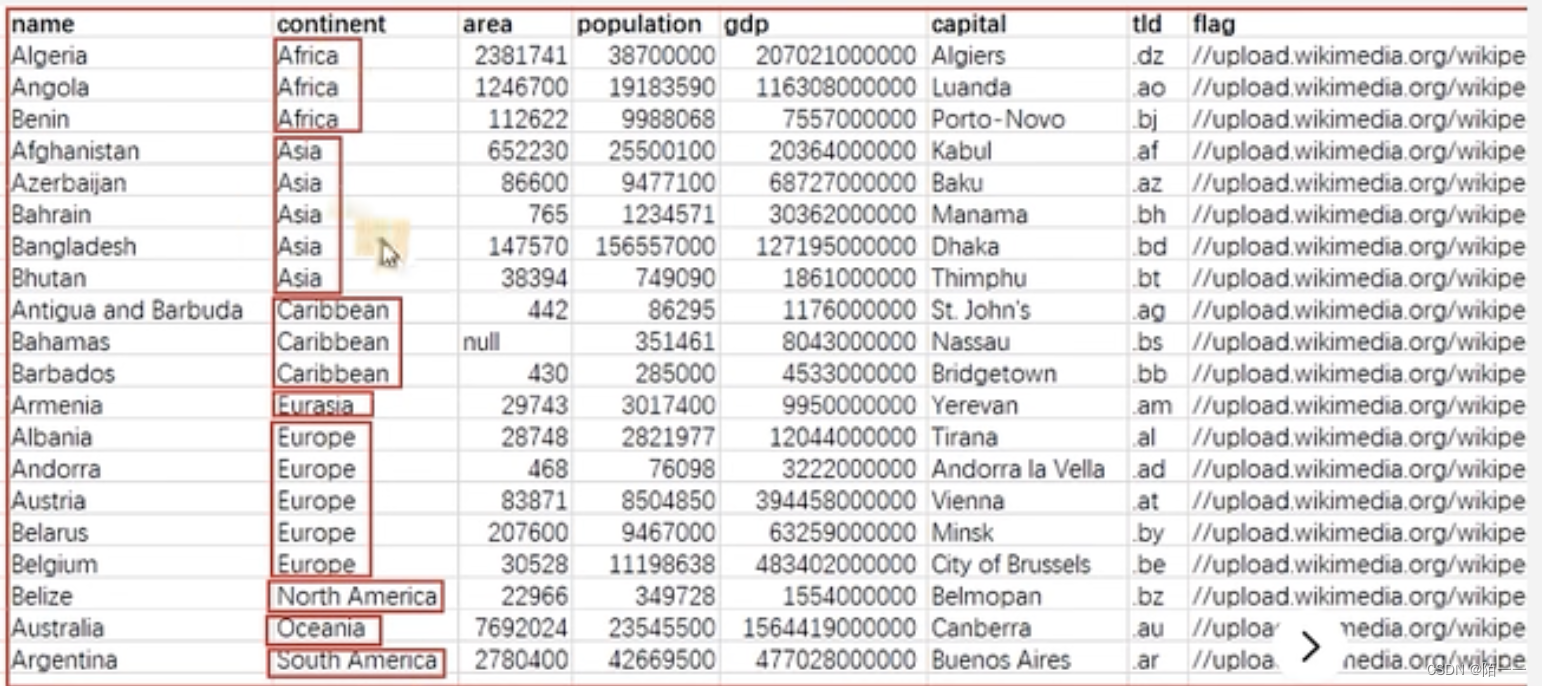
然后把分区的这列数据单独拿出来分组去重:
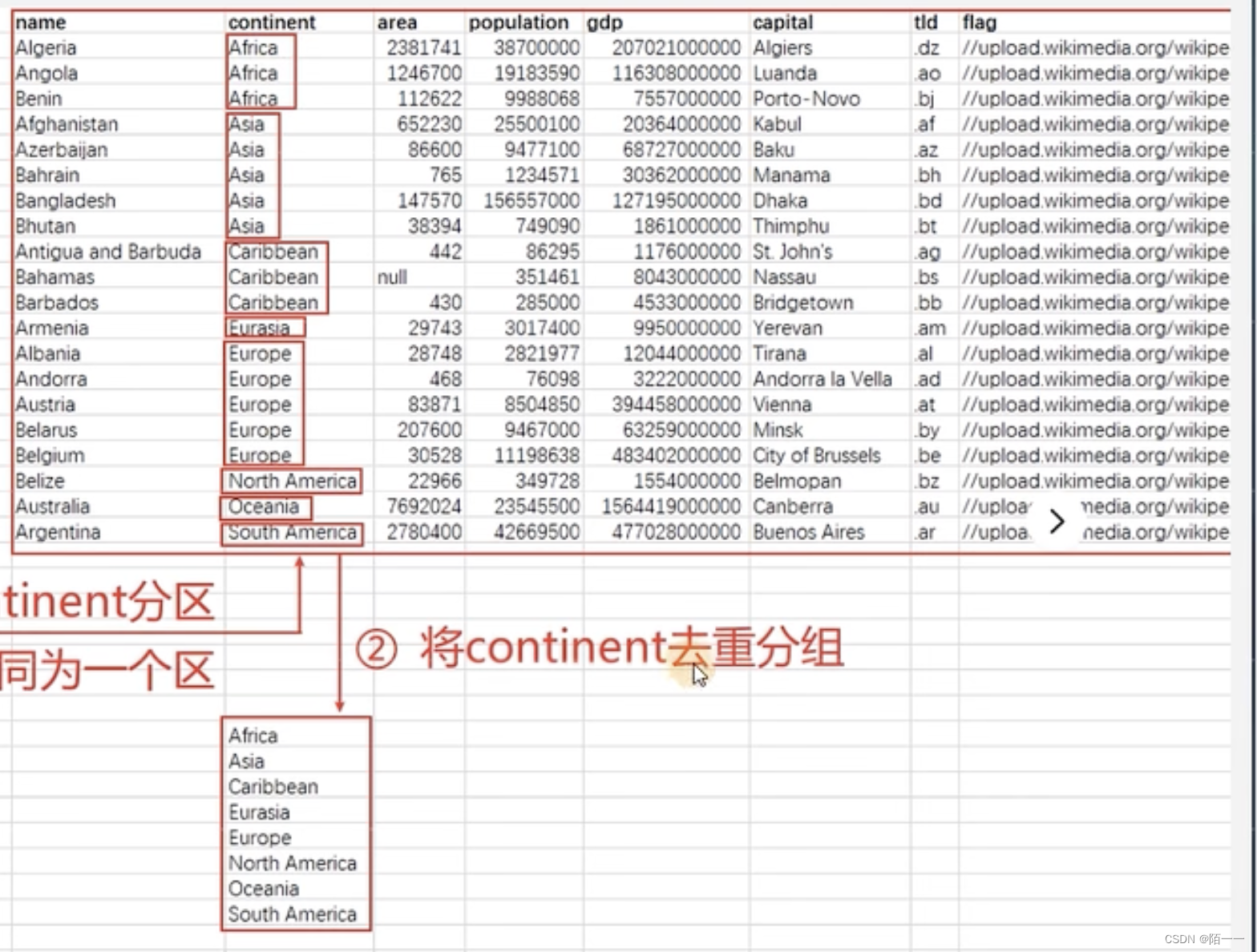
然后聚合计算就是按照分组后的这些数据进行计算
14、where和having的区别
where是在group by之前对原表格的数据进行筛选,而having是在group by之后对group by分组的数据进行筛选,
having只能用聚合函数和group by作为分组依据的字段
where不能使用聚合函数
15、sql执行原理:

16、函数
1️⃣:round(x,y):四舍五入函数
对x值进行四舍五入,精确到小数点后y位
y为负值时,保留小数点左边相应的位数为0,不进行四舍五入
例如:round(3.15,1)返回3.2 round(14.15,-1)返回10
2️⃣:concat(s1,s2...):连接字符串函数
当任意参数是null时,结果返回null
例如:concat('my', ,'sql')返回值为my sql(中间还有一个空格不要忽略)
concat('my',null,'sql')返回null
3️⃣:replace(s,s1,s2)替换函数
使用字符串s2替换s中的所有s1
例如:replace('MySQLMySQL‘,'SQL','sql')返回结果是:MysqlMysql
4️⃣:截取字符串里的一部分函数
left(s,n)函数:从左往右,截取字符串s中前n位,例如:left(“abcdefg”,3)结果返回:abc
right(s,n)函数:从右往左,截取字符串s中n位,例如:right(“abcdefg”,3)结果返回:efg
substring(s,n,len)函数:从n开始截取s中长度位len的几位(n可以为负数,但截取顺序都是从左往右)
例如:substring(“abcdefg”,-2,3)结果返回:fg
substring(“abcdefg”,2,3)结果返回:bcd
5️⃣:时间日期函数
year(date):获取日期中的年份
month(date):获取日期中的月份
day(date):获取日期中的日
date_add(date,interval expr type):对指定起始时间进行加操作
date_sub(date,interval expr type):对指定起始时间进行减操作
参数说明:date是起始时间
expr是从起始时间中加或者减的时间间隔
type是指定时间间隔的类型,也就是指定expr的类型,类型有:day、week、month、year
例如:date_add('2021-08-03 23:29:29',interval 1 day) 返回2021-08-04 23:29:29
也就是在起始时间上增加一天
datediff(date1,date2):计算两个日期之间间隔的天数,只有日期部分参与计算,时间不参与
date_format(date,format):将日期和时间输出为format格式
SELECT DATE_FORMAT(NOW(), '%Y-%m-%d');常见的格式化选项有:%Y 年份,四位数
%y 年份,两位数
%m 月份,两位数
%d 日期,两位数
%H 小时,24小时制,两位数
%h 小时,12小时制,两位数
%i 分钟,两位数
%s 秒,两位数
%p AM/PM
6️⃣:窗口函数
写法:函数() over(子句):over()指定函数执行的数据范围
函数() over(partition by 字段名 order by 字段名 asc/desc rows between 范围 and 范围)子句有三个:partition by 要分的组,分组、order by 要排序的列 asc/desc,排序、窗口(rows)字句
窗口子句(rows):
窗口字句的描述:
(1)起始行:N preceding/unbounded preceding
(2)当前行:current row
(3)终止行:N following/unbounded following
举例子:
rows between unbounded preceding and current row 从之前所有的行到当前行
rows between N preceding and current row 从前面两行到当前行
rows between current row and unbounded preceding 从当前行到之后所有的行
rows between current row and 1 preceding 从当前行到最后一行
注意:排序字句后面缺少窗口子句,窗口默认是:rows between unbounded preceding and current row 从之前所有的行到当前行
排序子句和窗口子句都缺失,窗口默认是:rows between unbounded preceding and unbounded following 全部的数据
执行流程:
(1)通过partition by和order by 子句确定大窗口(定义出上界unbounded preceding和下界unbounded following)
(2)通过row子句针对每一行数据确定小窗口
(3)对每行的小窗口内的数据执行函数并生成新的列
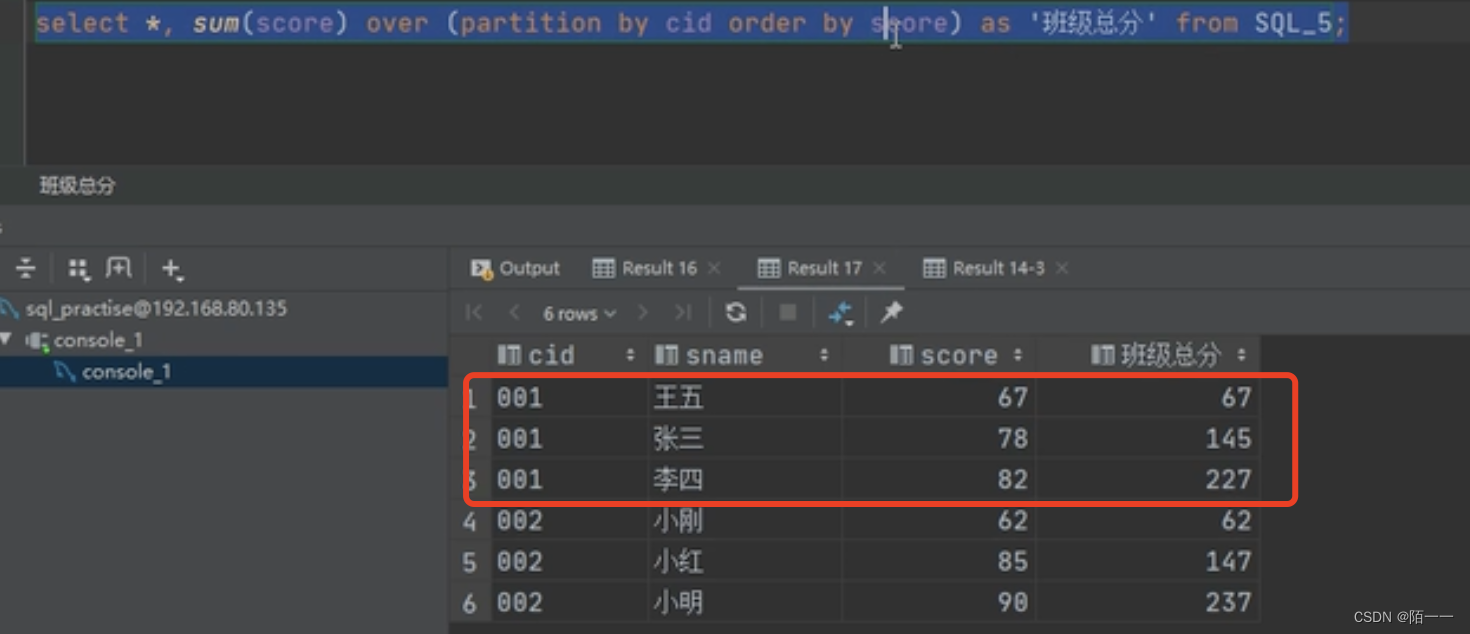
partition by和group by的区别:
前者只分组,不去重;后者分组还去重
前者分组后的数据可以显示非聚合列,但后者只能显示聚合列
partition by:![]()
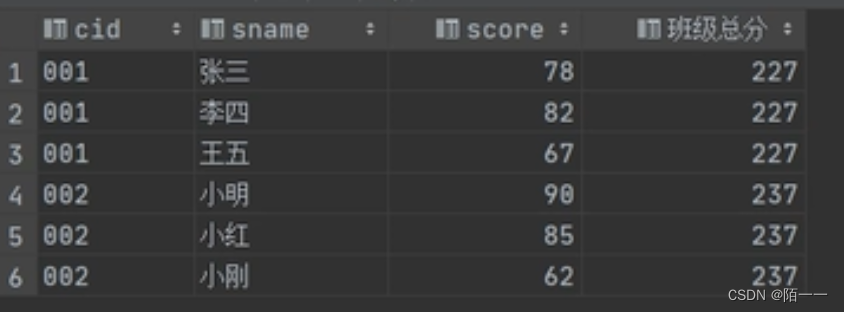
group by:

7️⃣:条件判断函数:

17、表连接
内连接(inner join/join)、左连接(left join)、右连接(right join)
写法:
select 表名
from 表1 join 表2 on 表1.字段名=表2.字段名
完全连接图示:
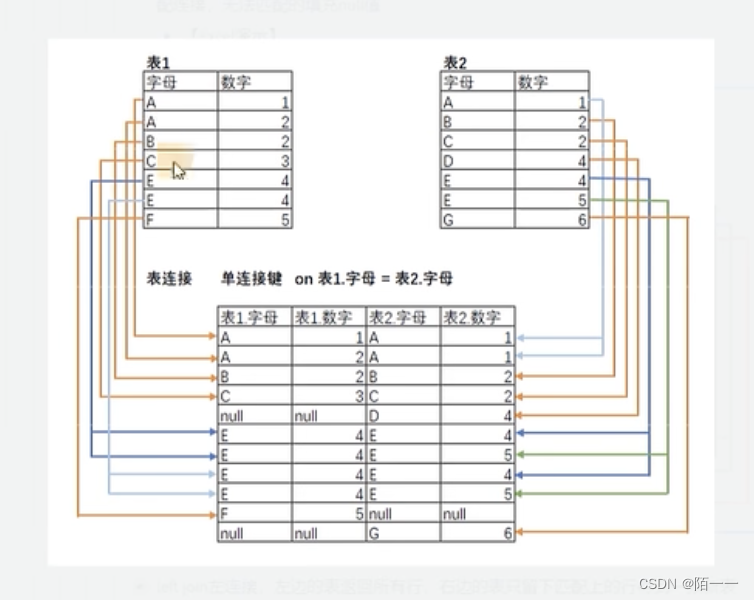
内连接图示:会把null值去除,就是不取一边有一边没有的值,取两边都有的值进行相✖️
这样理解:先完全连接,然后内连接就是去除有null值的行,只保留全部有值的行

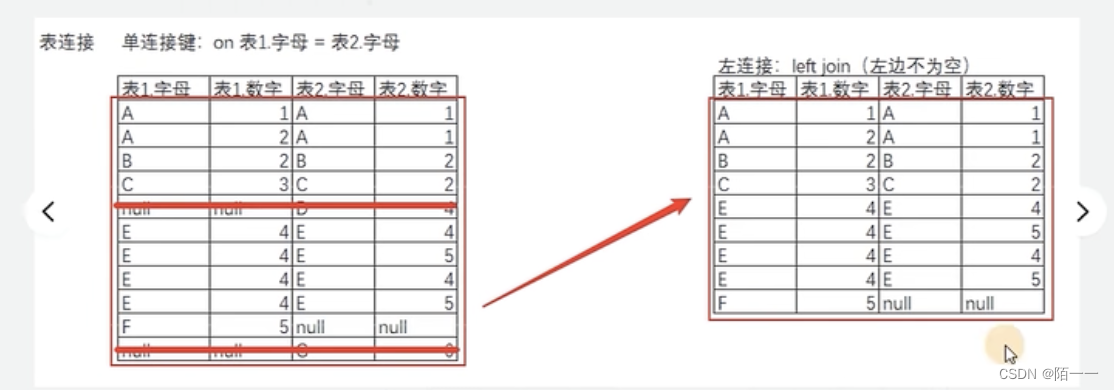
左连接图示:保留左边表的所有行来匹配右边的表,如果右边表有的字段左边表没有那就不管,就是以左边表为主,
这样理解:先完全连接,然后左连接就是去除左边为null的值的行,让左边是都有数据的
右连接图示:以右表为主,保留右边表的所有行,左边表去适应右边的表,
这样理解:先完全连接,然后右连接就是去除右边为null的值的行,让右边都是有数据的

18、子查询
如果子查询语句在from紧跟在from后面,必须要有别名
select * from (select 字段名 from 表名)as s
19、sql语句的运行顺序
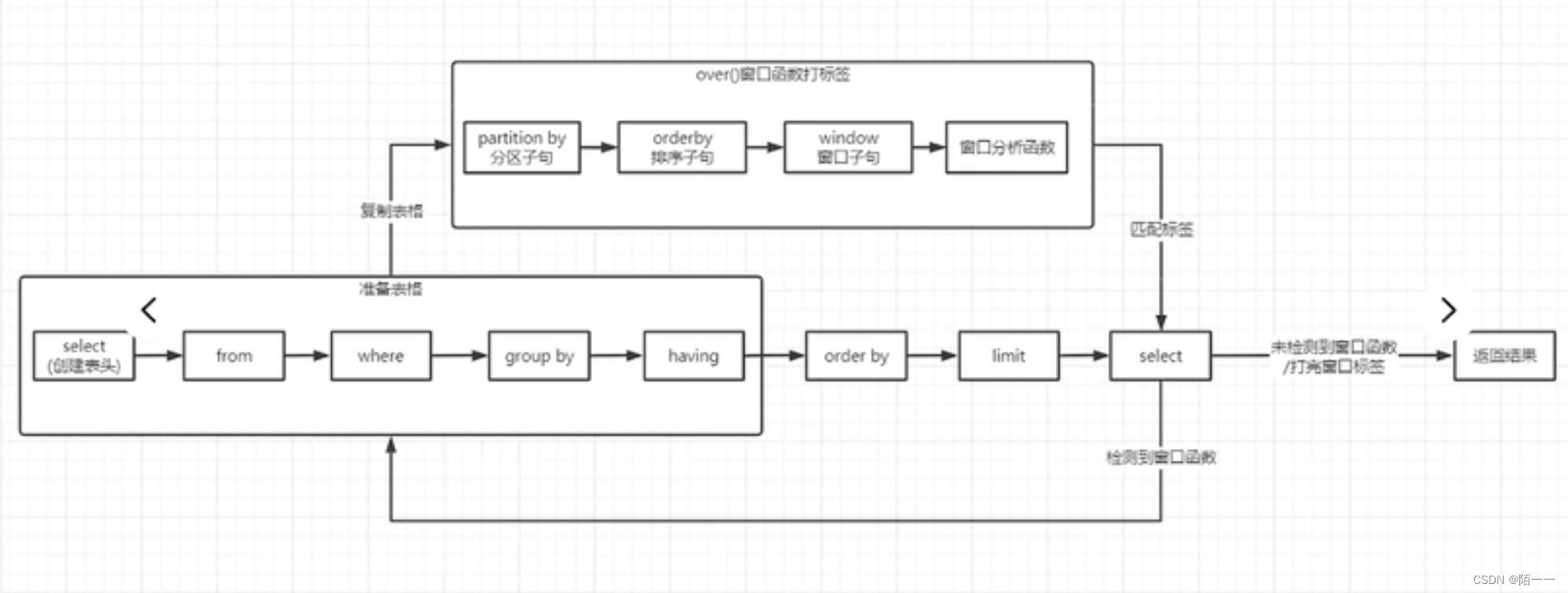
20、
相关文章:
sql资料库
1、distinct(关键词distinct用于返回唯一不同的值):查询结果中去除重复行的关键字 select distinct(university) from user_profile select distinct university from user_profile distinct是紧跟在select后面的,不能在其他位置,不然就…...

【python入门】运算符
文章目录 算术运算符比较运算符赋值运算符逻辑运算符位运算符成员运算符身份运算符优先级 算术运算符 # 加法 print(5 3) # 输出: 8# 减法 print(5 - 3) # 输出: 2# 乘法 print(4 * 3) # 输出: 12# 除法(结果为浮点数) print(8.0 / 3) # 输出: 2.6…...

【C++高阶】掌握AVL树:构建与维护平衡二叉搜索树的艺术
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C “ 登神长阶 ” 🤡往期回顾🤡:STL-> map与set 🌹🌹期待您的关注 🌹🌹 ❀AVL树 📒1. AVL树…...

机器学习-课程整理及初步介绍
简介: 机器学习是人工智能的一个分支,它使计算机系统能够从经验中学习并改进其在特定任务上的表现,而无需进行明确的编程。机器学习涉及多种算法和统计模型,它们可以从数据中学习规律,并做出预测或决策。机器学习的应用非常广泛&…...

北斗三号短报文通信终端 | 助力户外无网络场景作业
北斗三号短报文通信终端是一款专为户外无网络场景作业设计的先进通信工具,它依托于中国自主研发的北斗卫星导航系统,为用户在偏远地区或无网络覆盖区域提供了可靠的通信保障。以下是关于北斗三号短报文通信终端的详细介绍: 一、功能特点 北斗…...
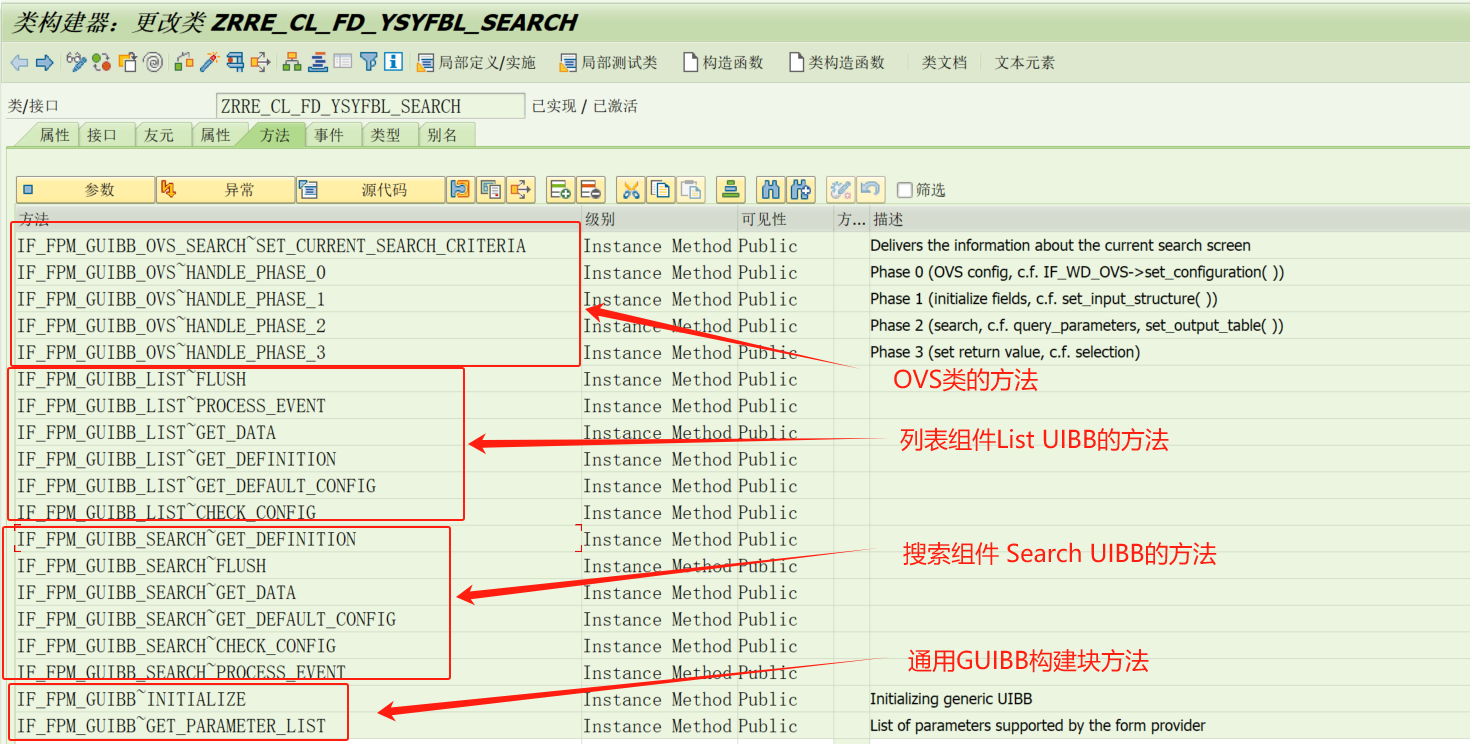
RERCS系统开发实战案例-Part05 FPM Application的Feeder Class搜索组件的实施
1、通过事务码 SE24对Feeder Class实施 1)接口页签的简单说明: ① IF_FPM_GUIBB:通用UI构建块,整个UIBB模块的基础接口; ② IF_FPM_GUIBB_SEARCH:通用搜索UI构建块,搜索组件UIBB的基础接口&…...
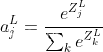
算法常见手写代码
1.NMS def py_cpu_nms(dets, thresh):"""Pure Python NMS baseline."""#x1、y1、x2、y2、以及score赋值x1 dets[:, 0]y1 dets[:, 1]x2 dets[:, 2]y2 dets[:, 3]scores dets[:, 4]#每一个检测框的面积areas (x2 - x1 1) * (y2 - y1 1)#按…...

数据结构9——排序
一、冒泡排序 冒泡排序(Bubble Sort),顾名思义,就是指越小的元素会经由交换慢慢“浮”到数列的顶端。 算法原理 从左到右,依次比较相邻的元素大小,更大的元素交换到右边;从第一组相邻元素比较…...

分布式锁实现方案-基于Redis实现的分布式锁
目录 一、基于Lua看门狗实现 1.1 缓存实体 1.2 延迟队列存储实体 1.3 分布式锁RedisDistributedLockWithDog 1.4 看门狗线程续期 1.5 测试类 1.6 测试结果 1.7 总结 二、RedLock分布式锁 2.1 Redlock分布式锁简介 2.2 RedLock测试例子 2.3 RedLock 加锁核心源码分析…...

MTK7628+MT7612 加PA定频数据
1、硬件型号TR726A5G121-DPA PC9.02.0017。如下所示: 2、WIFI5.8 AC模式 42(5120MHz)信道,80带宽 3、WIFI5.8 AC模式 38(5190MHz)信道,40带宽 4、WIFI5.8 AC模式 36(5180 MHz&…...

[信号与系统]关于双线性变换
前言 本文还是前置知识 双线性变换法 双线性变换法(Bilinear Transform)是一种用于将模拟滤波器转换为数字滤波器的方法。它通过将模拟域中的s平面上的传递函数映射到数字域中的z平面上的传递函数来实现这一转换。双线性变换法保证了频率响应在转换过…...
763. 划分字母区间
题目:给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。返回一个表示每个字符串片段的长度的列表…...

【PostgreSQL】AUTO_EXPLAIN - 慢速查询的日志执行计划
本文为云贝教育 刘峰 原创,请尊重知识产权,转发请注明出处,不接受任何抄袭、演绎和未经注明出处的转载。 一、介绍 在本文中,我们将了解 PostgreSQL AUTO_EXPLAIN功能的工作原理,以及为什么应该使用它来收集在生产系统…...

讯飞星火超自然语言合成的完整Demo
依赖文件和功能 requirements.txt 该文件列出了所需的依赖包。 data.py 定义了应用的配置信息,如APPId,APIKey,APISecret等。包含请求数据和请求URL。 main.py 主程序,设置了WebSocket连接,定义了处理消息的各个回调函…...
)
封装一个上拉加载的组件(无限滚动)
一、封装 1.这个是在vue3环境下的封装 2.整体思路: 2.1传入一个elRef,其实就是一个使用页面的ref。 2.2也可以不传elRef,则默认滚动的是window。 import { onMounted, onUnmounted, ref } from vue; import { throttle } from underscore;ex…...
)
WHAT - 高性能和内存安全的 Rust(二)
目录 1. 所有权(Ownership)2. 借用(Borrowing)不可变借用可变借用 3. 可变性(Mutability)4. 作用域(Scope)综合示例 了解 Rust 的所有权(ownership)、借用&am…...

办理河南建筑工程乙级设计资质的流程与要点
办理河南建筑工程乙级设计资质的流程与要点 办理河南建筑工程乙级设计资质的流程与要点主要包括以下几个方面: 流程: 工商注册与资质规划:确保企业具有独立法人资格,完成工商注册,并明确乙级设计资质的具体要求&…...

分类算法和回归算法区别
分类算法和回归算法在机器学习中扮演着不同的角色,它们的主要区别体现在输出类型、应用场景以及算法目标上。以下是对两者区别和使用场景的详细分析: 一、区别 1.输出类型: 分类算法:输出是离散的类别标签,通常表示为…...
利用Frp实现内网穿透(docker实现)
文章目录 1、WSL子系统配置2、腾讯云服务器安装frps2.1、创建配置文件2.2 、创建frps容器 3、WSL2子系统Centos服务器安装frpc服务3.1、安装docker3.2、创建配置文件3.3 、创建frpc容器 4、WSL2子系统Centos服务器安装nginx服务 环境配置:一台公网服务器(…...

怎么用Excel生成标签打印模板,自动生成二维码
环境: EXCEL2021 16.0 问题描述: 怎么用excel生成标签打印模板自动生成二维码 解决方案: 在Excel中生成标签打印模板并自动生成二维码,可以通过以下几个步骤完成: 1. 准备数据 首先,确保你的Excel表…...

基于MCP协议构建Jira连接器:打通AI助手与项目管理的技术实践
1. 项目概述:当Jira遇上MCP,一个连接器如何重塑项目管理工具链如果你和我一样,长期在软件研发一线摸爬滚打,那么对Jira这个名字一定不会陌生。它几乎是敏捷开发、缺陷跟踪和项目管理的代名词,无数团队用它来规划冲刺、…...

taotoken token plan套餐为长期项目带来的成本控制优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken Token Plan套餐为长期项目带来的成本控制优势 在持续进行AI功能开发的软件项目中,模型API的调用成本是研发预…...

SSD的‘垃圾回收’秘密:深入理解Trim指令与FTL闪存转换层的协作
SSD的‘垃圾回收’秘密:深入理解Trim指令与FTL闪存转换层的协作 当你在SSD上删除一个文件时,操作系统只是简单地标记这个文件占用的空间为"可重用",但SSD内部的实际数据擦除过程远比这复杂。这种差异源于NAND闪存的物理特性——它不…...

Spring Cloud整合XXL-Job避坑指南:调度过期策略选错,你的定时任务可能就白跑了
Spring Cloud微服务中XXL-Job调度策略深度解析与实战避坑 在微服务架构盛行的今天,定时任务作为业务系统中不可或缺的一环,其稳定性和可靠性直接影响着核心业务流程。XXL-Job作为一款轻量级分布式任务调度平台,凭借其简单易用、功能强大的特性…...

如何5分钟实现Windows系统自动化软件部署:winget-install完整指南
如何5分钟实现Windows系统自动化软件部署:winget-install完整指南 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh_…...

路由器市场新机遇:从硬件到场景化解决方案的演进
1. 项目概述:一个被低估的“家门口”战场聊到路由器,很多人的第一反应可能是“运营商送的”、“能用就行”。确实,在过去很长一段时间里,家用Wi-Fi设备是一个典型的“黑盒”产品,用户对其性能、功能和体验的感知非常模…...

使用Gemini-OpenAI代理实现零成本AI模型迁移与协议转换
1. 项目概述:一个让OpenAI生态无缝接入Gemini的桥梁如果你和我一样,长期在AI应用开发的一线折腾,肯定遇到过这样的场景:手头有一个基于OpenAI API(比如ChatGPT的gpt-3.5-turbo或gpt-4)构建得相当成熟的应用…...

【Flutter for OpenHarmony 跨平台征文】Flutter 血压数据模型设计 + WHO标准分类算法实战指南
【Flutter for OpenHarmony 跨平台征文】Flutter 血压数据模型设计 WHO标准分类算法实战指南 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net🎯 写在前面 嗨,大家好!我是上海某高校大一计算机专业的学生…...

从指标到版图:基于Cadence与gmid方法的两级运放实战设计
1. 两级运放设计入门:从指标到晶体管的思维转换 第一次接触两级运放设计时,我盯着性能指标表发呆了半小时。AV≥10M、CL10pf、SR10V/us这些数字就像天书,直到导师扔给我一本《模拟集成电路设计艺术》和一份Cadence使用手册。现在回想起来&…...

高性能JSXBIN解码器架构设计:3大核心技术优势深度解析
高性能JSXBIN解码器架构设计:3大核心技术优势深度解析 【免费下载链接】jsxer A fast and accurate JSXBIN decompiler. 项目地址: https://gitcode.com/gh_mirrors/js/jsxer Jsxer是一个快速且准确的JSXBIN反编译器,专门用于将Adobe ExtendScrip…...