lucene原理
一、正排索引
Lucene的基础层次结构由索引、段、文档、域、词五个部分组成。正向索引的生成即为基于Lucene的基础层次结构一级一级处理文档并分解域存储词的过程。
索引文件层级关系如图1所示:
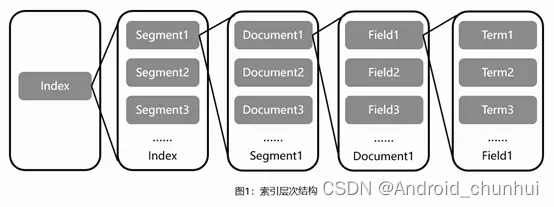
索引:Lucene索引库包含了搜索文本的所有内容,可以通过文件或文件流的方式存储在不同的数据库或文件目录下。
段:一个索引中包含多个段,段与段之间相互独立。由于Lucene进行关键词检索时需要加载索引段进行下一步搜索,如果索引段较多会增加较大的I/O开销,减慢检索速度,因此写入时会通过段合并策略对不同的段进行合并。
文档:Lucene会将文档写入段中,一个段中包含多个文档。
域:一篇文档会包含多种不同的字段,不同的字段保存在不同的域中。
词:Lucene会通过分词器将域中的字符串通过词法分析和语言处理后拆分成词,Lucene通过这些关键词进行全文检索。
二、倒排索引
词到文档ID的映射。包括term Dictionary 和Posting List两部分。
1、Term Dictionary
Term Dictionary 分为.tim, tip文件存储。 .tim 文件,其内部采用 NodeBlock 对 Term 进行压缩前缀存储,处理过程会将相同前缀的的 Term 压缩为一个 NodeBlock,NodeBlock 会存储公共前缀,然后将每个 Term 的后缀以及对应 Term 的 Posting 关联信息处理为一个 Entry 保存到 Block。
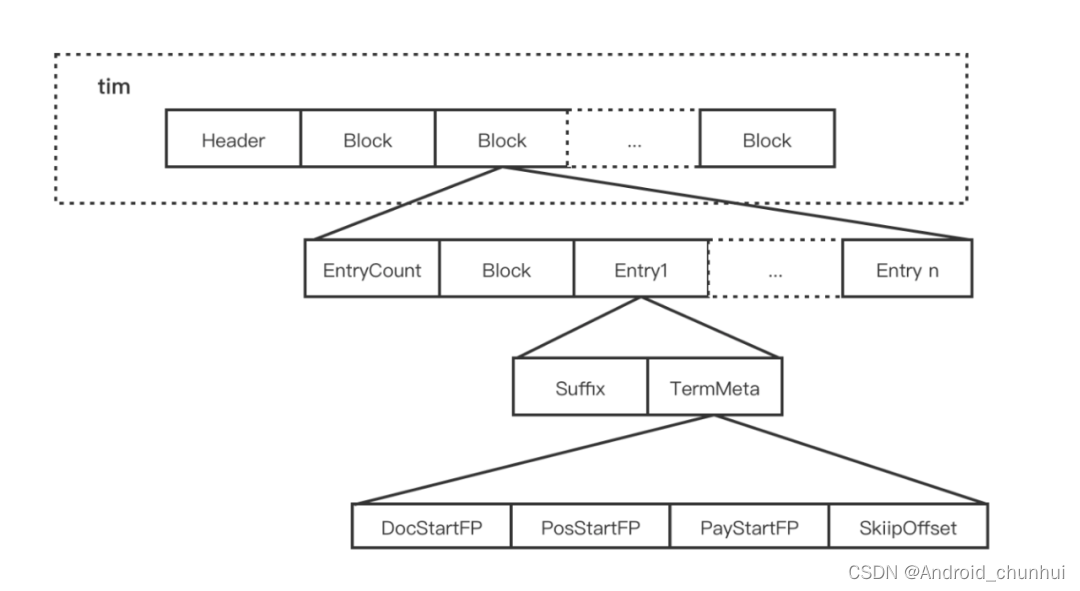
搜索词典巨大,用map存储无法一次性加载到内存里,因此使用FST对tim文件创建索引。
FST(Finite StateTransducers),中文名有限状态机转换器。其主要特点在于以下四点:
- 查找词的时间复杂度为O(len(str));
- 通过将前缀和后缀分开存储的方式,减少了存放词所需的空间;
- 加载时仅将前缀放入内存索引,后缀词在磁盘中进行存放,减少了内存索引使用空间的损耗;
- FST结构在对PrefixQuery、FuzzyQuery、RegexpQuery等查询条件查询时,查询效率高。
具体存储方式如图3所示:
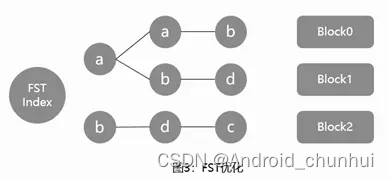
倒排索引相关文件包含.tip、.tim和.doc这三个文件,其中:
tip:用于保存倒排索引Term的前缀,来快速定位.tim文件中属于这个Field的Term的位置,即上图中的aab、abd、bdc。
tim:保存了不同前缀对应的相应的Term及相应的倒排表信息,倒排表通过跳表实现快速查找,通过跳表能够跳过一些元素的方式对多条件查询交集、并集、差集之类的集合运算也提高了性能。
doc:包含了文档号及词频信息,根据倒排表中的内容返回该文件中保存的文本信息。
2、Posting List
2.1、索引构建期间
Field被分词后变成一系列Terms的集合,而后遍历这个Terms的集合,为每个Term分配一个ID,叫TermID。Lucene用一个类HashMap的数据结构来存储Term与TermID的映射关系,同时实现去重的目的。分配完TermID之后,后续就可以使用TermID来表示Term。
在Postings构建过程中,会在PostingsArrays存储上个文档的(DocID, TermFreq),还有Term上次出现的位置(Postion,Offset, Payload)信息。PostingsArrays由几个int[]组成,其下标即为TermID(TermID是连续分配的整型数,所以PostingsArrays是紧凑的),对应的值便是记录TermID上一次出现的相关信息。

- lastPostion/lastOffset/lastDocId:term在上个文档的倒排信息。
- textStarts:用来记录Term词面在CharBlockPool中的起始位置。(早期版本term存储在ByteBlockPool后来单独放到CharBlockPool)。
- intStarts:用来记录拉链当前doc在IntBlockPool中的记录位置。
- byteStarts:用来记录拉链表头在ByteBlockPool中的起始位置。
term有两条倒排拉链,节点叫做Slice,一条存储[docId, termFreq],一条存储[pos,offset,payload],分成两条是因为Lucene这两种信息的构建是可选的,可以选择不构建[pos,offset,payload]信息。如下图,根据intStarts知道doc信息在intPool中的存储位置,进而知道在BytePool中的存储起始位置,两种Slice数据[docId, termFreq]和[pos,offset,payload]相邻存放,且大小固定的。可以看到,term的每个doc信息在ByteBlockPool中时分散存储的,但是Slice中有指向下一节点的指针,flush磁盘时byteStarts记录了拉链头结点位置,intStarts对应的IntPool数据记录了拉链尾结点位置,因此可以从ByteBlockPool中获取整条链表。
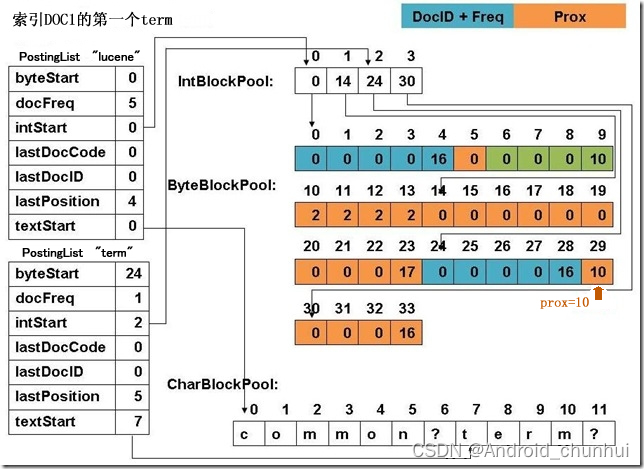
为什么在PostingArray里记录上个doc的信息呢,比如lastPostion/lastOffset/lastDocId?
因为可以做差值存储,节省存储空间。
构建过程中每个Term拉链的长度都是不确定的,因此需要用链表来存储拉链。构建中Term到来的顺序也是不固定的,不同term的倒排信息是交叉写入的。
Lucene使用了IntBlockPool和ByteBlockPool,避免Java堆中由于分配小对象而引发内存碎片化从而导致Full GC的问题,同时还解决数组长度增长所需要的数据拷贝问题,最后是不再需要申请超大且连续的内存。
2.2、索引查询期间
文档 id、词频、位置等是否构建倒排是可选的,因此 Lucene 将 Postings List 被拆成三个文件存储:
.doc后缀文件:记录 Postings 的 docId 信息和 Term 的词频
.pay后缀文件:记录 Payload 信息和偏移量信息
.pos后缀文件:记录位置信息
三个文件整体实现差不太多,这里以.doc 文件为例分析其实现。
.doc 文件存储的是每个 Term 对应的文档 Id 和词频。每个 Term 都包含一对 TermFreqs 和 SkipData 结构。
其中 TermFreqs 存放 docId 和词频信息,SkipData 为跳表信息,用于实现 TermFreqs 内部的快速跳转。

2.2.1 TermFreqs
TermFreqs 存储文档号和对应的词频,它们两是一一对应的两个 int 值。Lucene 为了尽可能的压缩数据,采用的是混合存储 ,由 PackedBlock 和 VIntBlocks 两种结构组成。
PackedBlock
PackedInt的压缩方式是取数组中最大值所占用的 bit 长度作为一个预算的长度,然后将数组每个元素按这个长度进行存储,将一个 int[] 压缩打包成一个紧凑的 Buffer,改Buffer叫做PackedBlock。
VIntBlock
VIntBlock 是采用 VInt 来压缩 int 值,通常int 型都占4个字节,VInt 采用可变长的字节来表示一个整数。每个字节仅使用第1至第7位(共7 bits)存储数据,第8位作为标识,表示是否需要继续读取下一个字节。
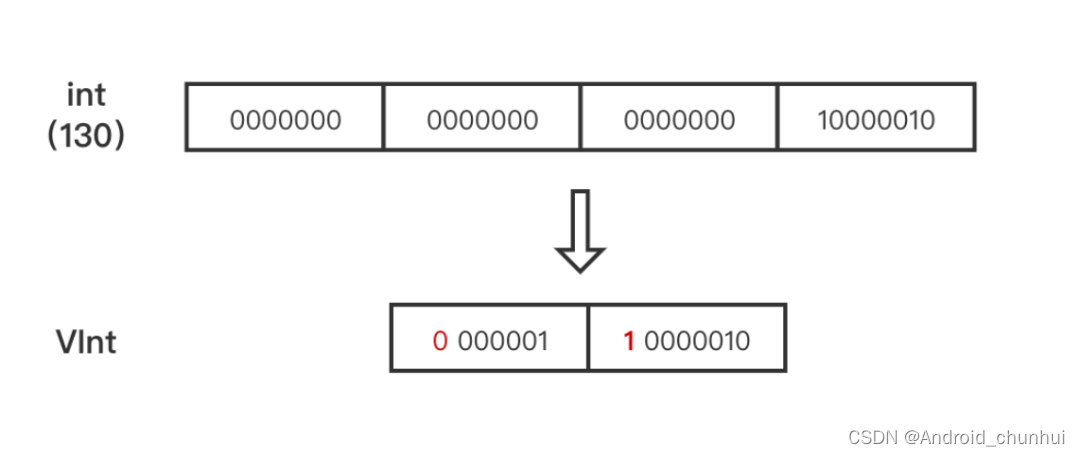
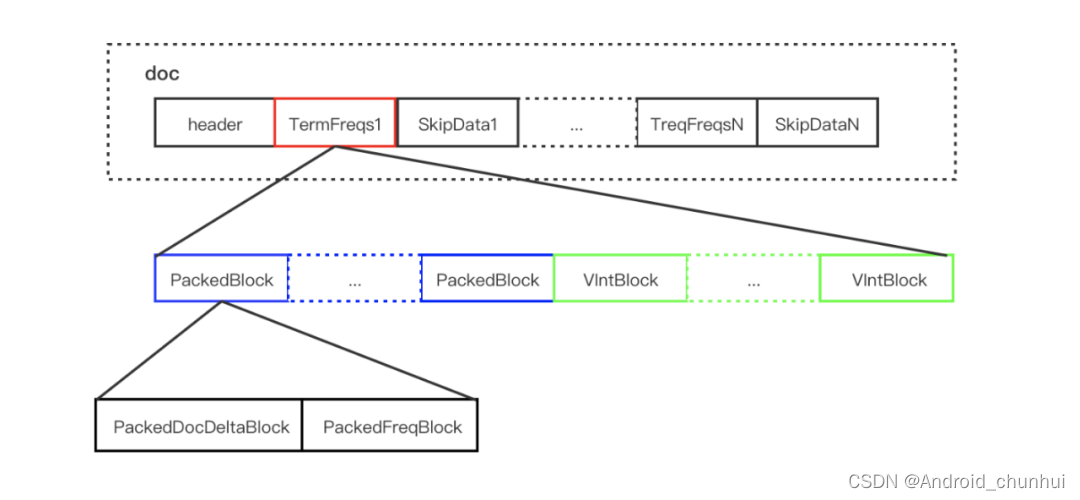
根据上述两种 Block 的特点,Lucene 会每处理包含 Term 的128篇文档,将其对应的 DocId 数组和 TermFreq 数组分别处理为 PackedDocDeltaBlock 和 PackedFreqBlock 的 PackedInt 结构,两者组成一个 PackedBlock,最后不足128的文档则采用 VIntBlock 的方式来存储。这里的PackedDocDeltaBlock是指对DocId的差值存储成PackedBlock形式,因为差值数值更小,占用存储空间更小。
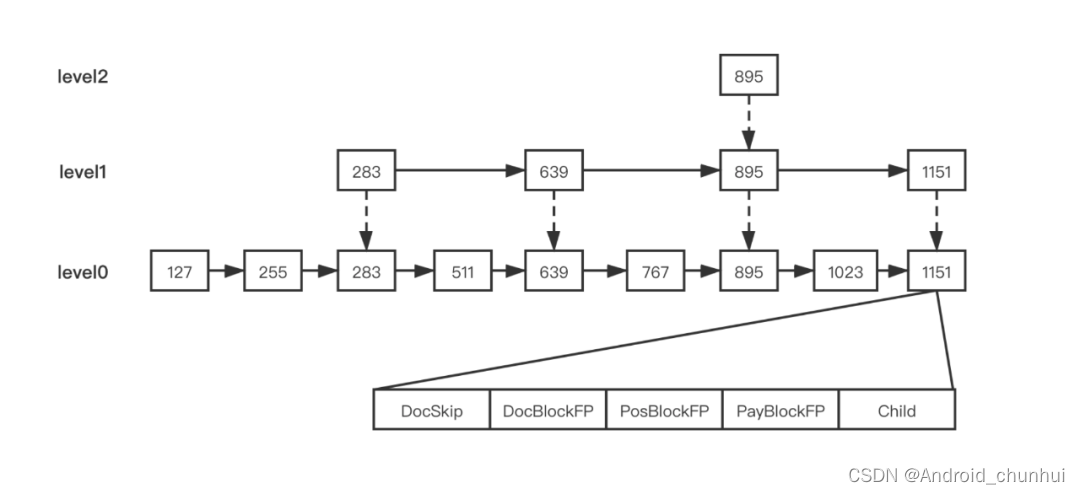
2.2.2 SkipData
对Term拉链求交集的操作,需要判断某个 Term 的 DocId 在另一个 Term 的 TermFreqs 中是否存在。Term拉链式DocId有序的,将其表示成调表结构,跳表节点的DocSkip 属性保存了 DocId 值,DocBlockFP、PosBlockFP、PayBlockFP 则表示 Block 数据对应在 .pay、.pos、.doc 文件的位置。
Posting List 采用多个文件进行存储,最终我们可以得到每个 Term 的如下信息:
SkipOffset:用来描述当前 term 信息在 .doc 文件中跳表信息的起始位置。
DocStartFP:是当前 term 信息在 .doc 文件中的文档 ID 与词频信息的起始位置。
PosStartFP:是当前 term 信息在 .pos 文件中的起始位置。
PayStartFP:是当前 term 信息在 .pay 文件中的起始位置。
3、倒排查询逻辑
在介绍了索引表和记录表的结构后,就可以得到 Lucene 倒排索引的查询步骤:
通过 Term Index 数据(.tip文件)中的 StartFP 获取指定字段的 FST
通过 FST 找到指定 Term 在 Term Dictionary(.tim 文件)可能存在的 Block
将对应 Block 加载内存,遍历 Block 中的 Entry,通过后缀(Suffix)判断是否存在指定 Term
存在则通过 Entry 的 TermStat 数据中各个文件的 FP 获取 Posting 数据
如果需要获取 Term 对应的所有 DocId 则直接遍历 TermFreqs,如果获取指定 DocId 数据则通过 SkipData 快速跳转
3、索引Segment的合并逻辑
因为
相关文章:
lucene原理
一、正排索引 Lucene的基础层次结构由索引、段、文档、域、词五个部分组成。正向索引的生成即为基于Lucene的基础层次结构一级一级处理文档并分解域存储词的过程。 索引文件层级关系如图1所示: 索引:Lucene索引库包含了搜索文本的所有内容࿰…...

华为、H3C交换机常用巡检命令
一、硬件状态、IOS版本信息检查 • display clock:显示系统时间。 • display version:查看交换机的版本信息和最近一次重新启动的时间。 • display enviroment:显示设备温度。 • display device:显示单板运行状态。 • di…...
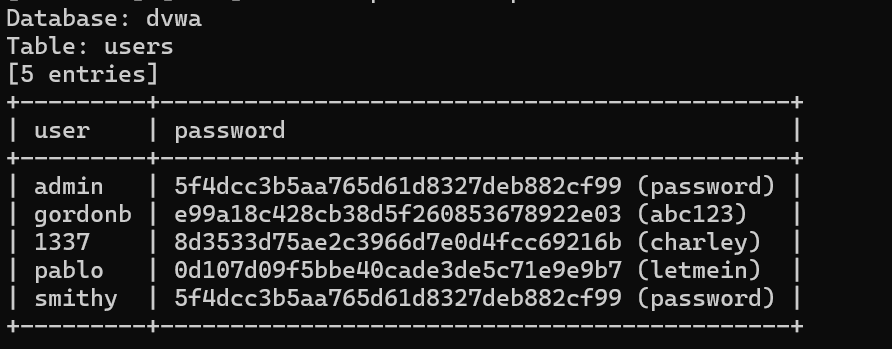
网络安全 DVWA通关指南 SQL Injection(SQL注入)
DVWA SQL Injection 文章目录 DVWA SQL InjectionLowMediumHighImpossible SQL注入漏洞基本原理 Web应用程序对用户输入的数据校验处理不严或者根本没有校验,致使用户可以拼接执行SQL命令。 可能导致数据泄露或数据破坏,缺乏可审计性,甚至导致…...

【Linux】版本
文章目录 linux版本1、linxu技术版本(内核版本)2、linux商业化版本(发行版本) 区别 linux版本 1、linxu技术版本(内核版本) 内核:提供硬件抽象层、硬盘及文件系统控制及多任务功能的系统核心程…...
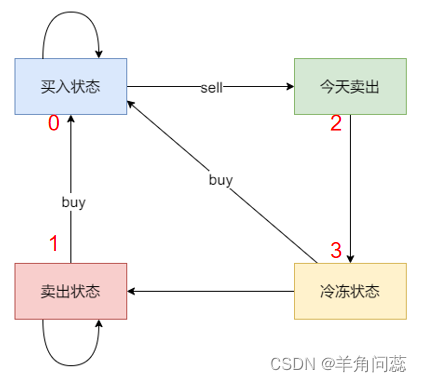
代码随想录算法训练营day47
题目:188.买卖股票的最佳时机IV、309.最佳买卖股票时机含冷冻期、714.买卖股票的最佳时机含手续费 参考链接:代码随想录 188.买卖股票的最佳时机IV 思路:本题和上题的最多两次买卖相比,改成了最多k次,使用类似思路&…...

【Android面试八股文】Kotlin内置标准函数apply的原理是什么?
文章目录 一、原理解析二、 示例代码2.1 具体示例应用场景2.2 为什么使用 `apply`?apply 是 Kotlin 标准库中的一个高阶函数,它的作用是在对象上执行一个代码块,并返回这个对象本身。其原理涉及到函数类型和接收者对象的结合使用。 一、原理解析 函数类型与接收者对象的结合…...

RegionClip环境安装踩坑指南
RegionClip环境安装 RegionClip环境安装)问题1问题2问题3问题4问题5 RegionClip环境安装) 特别强调,不要单独去安装detectron2,会出现model.clip不存在的错误,通过python -m pip install -e RegionCLIP就可以问题1 问题:torch-c…...
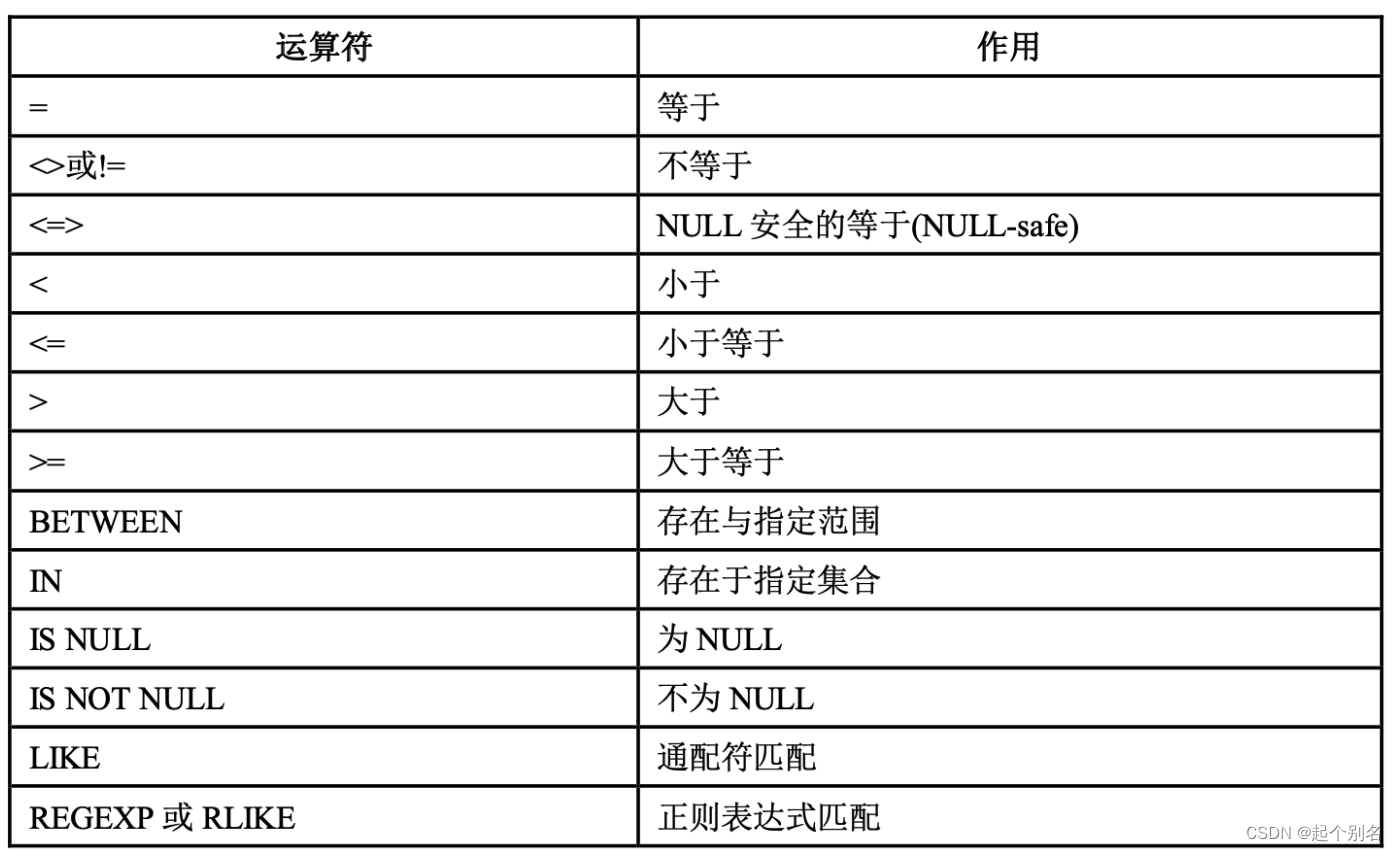
MySQL数据类型、运算符以及常用函数
MySQL数据类型 MySQL数据类型定义了数据的大小范围,因此使用时选择合适的类型,不仅会降低表占用的磁盘空间, 间接减少了磁盘I/O的次数,提高了表的访问效率,而且索引的效率也和数据的类型息息相关。 数值类型 浮点类型…...
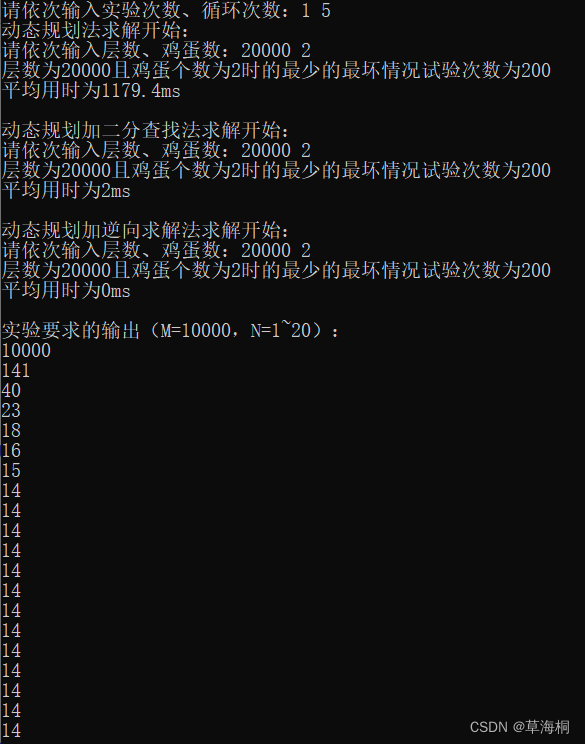
算法设计与分析:动态规划法求扔鸡蛋问题 C++
目录 一、实验目的 二、问题描述 三、实验要求 四、算法思想和实验结果 1、动态规划法原理: 2、解决方法: 2.1 方法一:常规动态规划 2.1.1 算法思想: 2.1.2 时间复杂度分析 2.1.3 时间效率分析 2.2 方法二:动态规划加…...
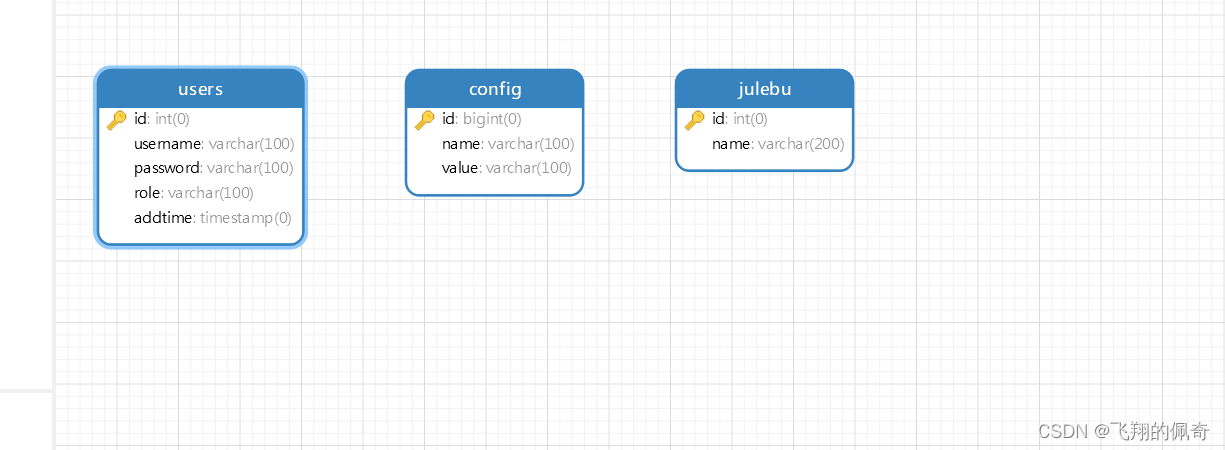
Java项目:基于SSM框架实现的电子竞技管理平台【ssm+B/S架构+源码+数据库+毕业论文】
一、项目简介 本项目是一套基于SSM框架实现的电子竞技管理平台 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观、操作简单、功能…...

Scala入门介绍
Scala 是一种强大的多范式编程语言,旨在融合面向对象编程和函数式编程的特性。它运行在 Java 虚拟机(JVM)上,因此可以无缝地与 Java 库进行交互。以下是对 Scala 的入门介绍,并附带了一些基本代码示例。 环境设置 首先…...
品牌策划背后的秘密:我为何对此工作情有独钟?
你是否曾有过一个梦想,一份热爱,让你毫不犹豫地投身于一个行业? 我就是这样一个对品牌策划充满热情的人。 从选择职业到现在,我一直在广告行业里“混迹”,一路走来,也见证了许多对品牌策划一知半解的求职…...

超越招聘技术人才目标的最佳技术招聘统计数据
研究发现,难以找到的人才比以往任何时候都更难找到:根据新人才委员会招聘调查报告:2024年难以找到的人才的战略和战略,60%的受访者表示,熟练人才的招聘时间比一年前长。调查进一步揭示了以下关于招聘技术的关键事实&am…...
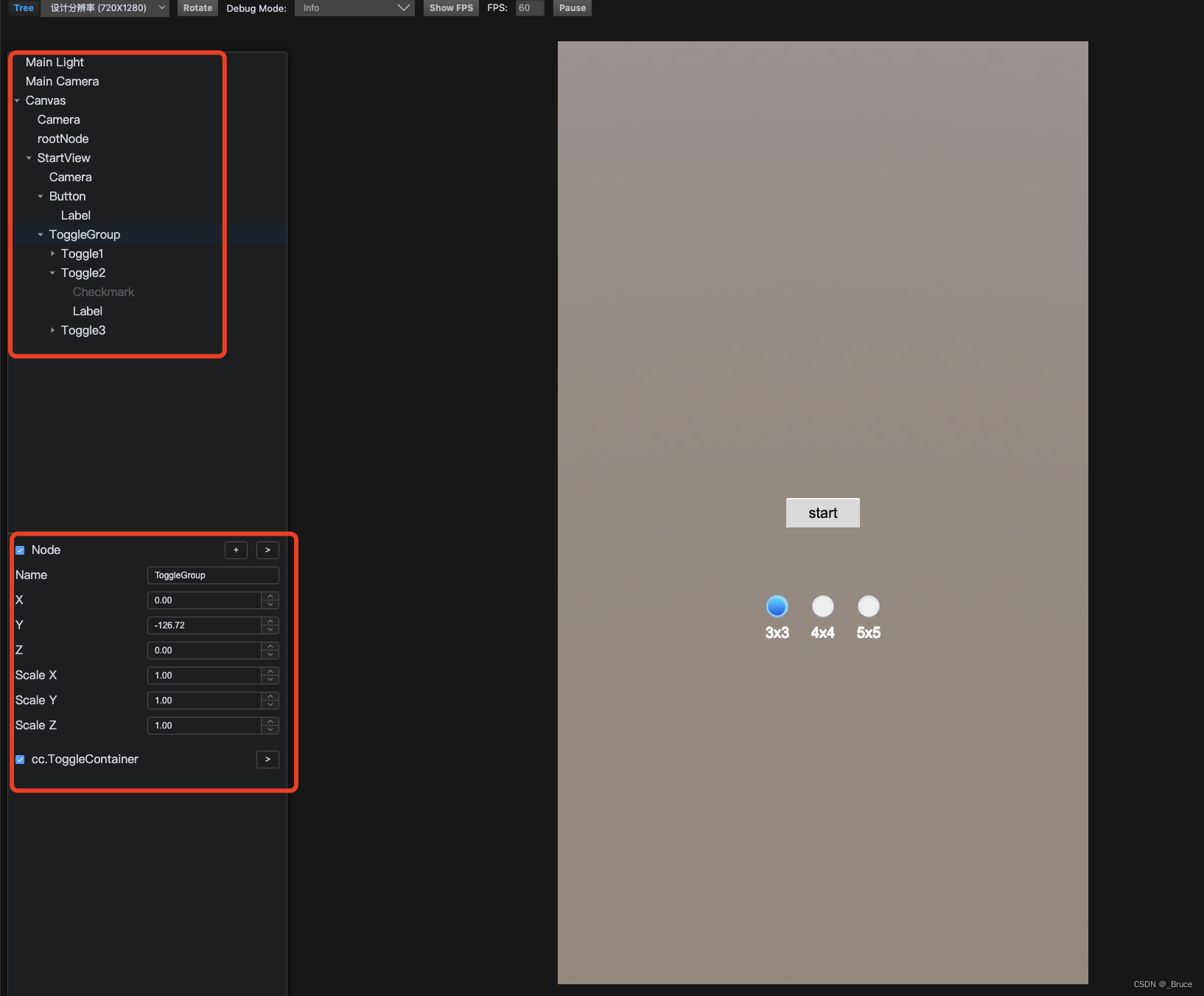
cocos creator 调试插件
适用 Cocos Creator 3.4 版本,cocos creator 使用google浏览器调试时,我们可以把事实运行的节点以节点树的形式显示在浏览器上,支持运行时动态调整位置等、、、 将下载的preview-template插件解压后放在工程根目录下,然后重新运行…...

Clickhouse监控_监控的指标以及Grafana配置Clickhouse指标异常时触发报警
使用PrometheusGrafana来监控Clickhouse服务和性能指标 Clickhouse监控指标的官方文档https://clickhouse.com/docs/zh/operations/monitoring 建议使用PrometheusGrafana组合监控Clickhouse服务和性能指标,数据流向:Prometheus的clickhouse_exporter组件…...

动手学深度学习(Pytorch版)代码实践 -卷积神经网络-27含并行连结的网络GoogLeNet
27含并行连结的网络GoogLeNet import torch from torch import nn from torch.nn import functional as F import liliPytorch as lp import matplotlib.pyplot as pltclass Inception(nn.Module):# c1--c4是每条路径的输出通道数def __init__(self, in_channels, c1, c2, c3, …...
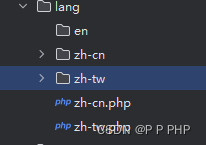
fastadmin多语言切换设置
fastadmin版本:1.4.0.20230711 以简体,繁体,英文为例 一,在application\config.php 里开启多语言 // 是否开启多语言lang_switch_on > true, // 允许的语言列表allow_lang_list > [zh-cn, en,zh-tw], 二…...

如何清理docker build的缓存
在使用 Docker 构建镜像时,Docker 会利用构建缓存来加速后续的构建过程。如果某一层及其所有上层未发生变化,Docker 就会重用这一层的缓存。虽然这可以显著提升构建速度,但有时你可能希望强制 Docker 忽略缓存,以确保从头开始重新…...

OceanBase v4.2 特性解析:如何用分页保序功能解决MySQL模式分页查询不稳定
导言 在MySQL业务迁移OceanBase过程中,经常遇到的一个问题是分页查询结果的不稳定性,这通常需要数据库DBA介入绑定执行计划。下面简单举个例子,以便大家更好地理解为什么有的分页查询,在原来的MySQL数据库下运行没有问题…...
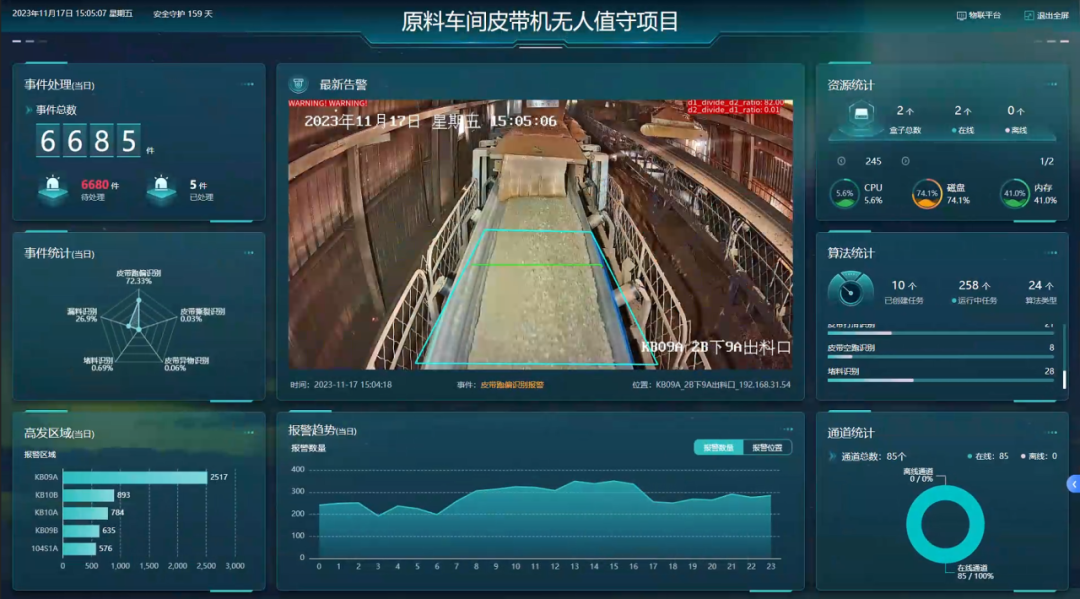
RK3588/算能/Nvidia智能盒子:加速山西铝业智能化转型,保障矿业皮带传输安全稳定运行
近年来,各类矿山事故频发,暴露出传统矿业各环节的诸多问题。随着全国重点产煤省份相继出台相关政策文件,矿业智能化建设进程加快。皮带传输系统升级是矿业智能化的一个重要环节,同时也是降本增效的一个重点方向。 △各省份智能矿山…...

如何3步搞定LaTeX中文排版?告别字体缺失烦恼的终极方案
如何3步搞定LaTeX中文排版?告别字体缺失烦恼的终极方案 【免费下载链接】latex-chinese-fonts Simplified Chinese fonts for the LaTeX typesetting. 项目地址: https://gitcode.com/gh_mirrors/la/latex-chinese-fonts 还在为LaTeX中文排版头疼吗ÿ…...

Windows驱动管理专业解决方案:Driver Store Explorer完全指南
Windows驱动管理专业解决方案:Driver Store Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer Driver Store Explorer(简称Rapr)是一款…...

不想做程序员了,听说网络安全前景好,现在转行还来得及吗?
不想做程序员了,听说网络安全前景好,现在转行还来得及吗? 我去年四月份被裁员,找了两个月工作,面试寥寥无几,就算有也都是外包,而且外包也没面试通过。我经历了挫败,迷茫࿰…...

WarcraftHelper终极指南:魔兽争霸3优化工具完整教程
WarcraftHelper终极指南:魔兽争霸3优化工具完整教程 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸III》的陈旧限制而烦…...

从零构建开源ADAS原型:车道检测、目标识别与PID控制实践
1. 项目概述:从零到一,构建一个开源的ADAS原型系统 最近几年,汽车行业最火的话题之一就是“智能驾驶”。无论是传统车企还是新势力,都在宣传自家的辅助驾驶功能,什么自适应巡航、车道保持、自动紧急制动,听…...

思源宋体CN终极指南:7种字重免费商用中文字体快速上手完整教程
思源宋体CN终极指南:7种字重免费商用中文字体快速上手完整教程 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目中文字体版权问题而烦恼吗?思源宋…...

AMD Ryzen调试工具终极指南:6步掌握硬件性能精准调控
AMD Ryzen调试工具终极指南:6步掌握硬件性能精准调控 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://git…...

低延时RS译码器优化设计【附代码】
✨ 长期致力于RS码、低延时、功耗优化、译码器研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)改进型RiBM迭代展开算法加速关键方程求解: …...

Electron鸿蒙PC上的系统托盘,坑比我想象的多三倍
Electron鸿蒙PC上的系统托盘,坑比我想象的多三倍 上个月我在做一个企业内部工具,需要在鸿蒙PC上实现系统托盘常驻和原生通知推送。本来以为这是个小功能,两三个小时搞定,结果愣是折腾了两天半。把过程记录下来,希望后…...

GitHub加速神器:5分钟安装,告别龟速下载的终极解决方案
GitHub加速神器:5分钟安装,告别龟速下载的终极解决方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还在…...