卷积神经网络(CNN)理解
1、引言(卷积概念)
在介绍CNN中卷积概念之前,先介绍一个数字图像中“边缘检测edge detection”案例,以加深对卷积的认识。图中为大小8X8的灰度图片,图片中数值表示该像素的灰度值。像素值越大,颜色越亮,所以为了示意,我们把右边小像素的地方画成深色,图的中间两个颜色的分界线就是我们要检测的边界。
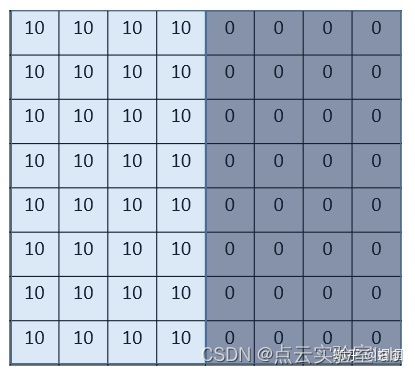
该怎么检测边界呢?我们可以设计这样的一个 滤波器(filter,也称为kernel),大小3×3:

然后,我们用这个filter,往我们的图片上“盖”,覆盖一块跟filter一样大的区域之后,对应元素相乘,然后求和。计算一个区域之后,就向其他区域挪动,接着计算,直到把原图片的每一个角落都覆盖到了为止。这个过程就是 “卷积”。 (我们不用管卷积在数学上到底是指什么运算,我们只用知道在CNN中是怎么计算的。) 这里的“挪动”,就涉及到一个步长,假如我们的步长是1,那么覆盖了一个地方之后,就挪一格,容易知道,总共可以覆盖6×6个不同的区域。

通过上述操作,发现边界被准确探测出。
卷积神经网络(CNN)中的卷积,就是通过一个个的filter,不断地提取特征,从局部的特征到总体的特征,从而进行图像识别等等功能。
那么问题来了,我们怎么可能去设计这么多各种各样的filter?首先,我们都不一定清楚对于一大堆图片,我们需要识别哪些特征,其次,就算知道了有哪些特征,想真的去设计出对应的filter,恐怕也并非易事,要知道,特征的数量可能是成千上万的。
其实学过神经网络之后,我们就知道,这些filter,根本就不用我们去设计,每个filter中的各个数字,不就是参数吗,我们可以通过大量的数据,来让机器自己去“学习”这些参数嘛。这就是CNN的原理。
2、CNN基本概念
在理解CNN中卷积概念后,有一些基本概念需要理解,包括padding填白、stride步长、pooling池化、对多通道图片卷积。
2.1 padding填白
从上面的引子中,我们可以知道,原图像在经过filter卷积之后,变小了,从(8,8)变成了(6,6)。假设我们再卷一次,那大小就变成了(4,4)了。
这样有啥问题呢? 主要有两个问题: 每次卷积,图像都缩小,这样卷不了几次就没了; 相比于图片中间的点,图片边缘的点在卷积中被计算的次数很少。这样的话,边缘的信息就易于丢失。
为了解决这个问题,我们可以采用padding的方法。我们每次卷积前,先给图片周围都补一圈空白,让卷积之后图片跟原来一样大,同时,原来的边缘也被计算了更多次。
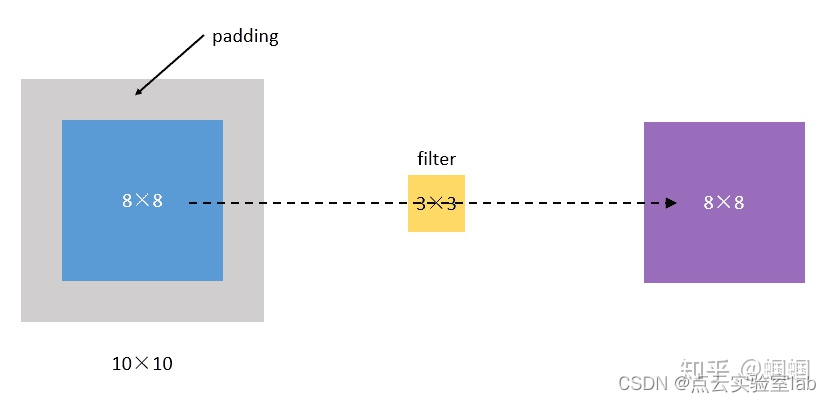
比如,我们把(8,8)的图片给补成(10,10),那么经过(3,3)的filter之后,就是(8,8),没有变。
我们把上面这种“让卷积之后的大小不变”的padding方式,称为 “Same”方式, 把不经过任何填白的,称为 “Valid”方式。这个是我们在使用一些框架的时候,需要设置的超参数。
2.2 stride步长
前面我们所介绍的卷积,都是默认步长是1,但实际上,我们可以设置步长为其他的值。 比如,对于(8,8)的输入,我们用(3,3)的filter, 如果stride=1,则输出为(6,6); 如果stride=2,则输出为(3,3)。
举栗子:
- 栗子1:stride=1,padding=0(遍历采样,无填充:padding=‘valid’)
- 栗子2:stride=1,padding=1(遍历采样,有填充:padding=‘same’)
- 栗子3:stride=2,padding=0(降采样,无填充:尺寸缩小二点五分之一)
- 栗子4:stride=2,padding=1(降采样,有填充;尺寸缩小二分之一)
Stride的作用:是成倍缩小尺寸,而这个参数的值就是缩小的具体倍数,比如步幅为2,输出就是输入的1/2;步幅为3,输出就是输入的1/3。
栗子1: 一个特征图尺寸为4*4的输入,使用3*3的卷积核,步幅=1,填充=0输出的尺寸=(4 - 3)/1 + 1 = 2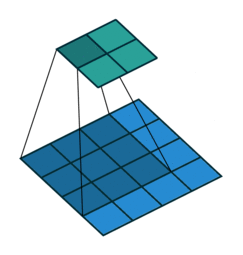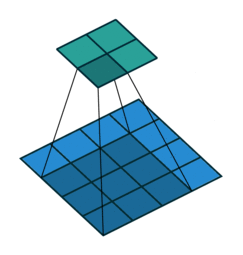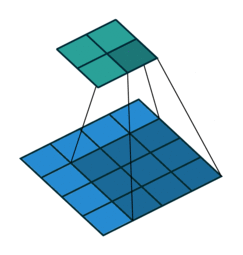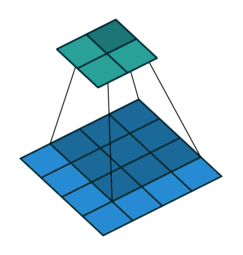
栗子2: 一个特征图尺寸为5*5的输入,使用3*3的卷积核,步幅=1,填充=1输出的尺寸=(5 + 2*1 - 3)/1 + 1 = 5
栗子3: 一个特征图尺寸为5*5的输入, 使用3*3的卷积核,步幅=2,填充=0输出的尺寸=(5-3)/2 + 1 = 2

栗子4: 一个特征图尺寸为6*6的输入, 使用3*3的卷积核,步幅=2,填充=1输出的尺寸=(6 + 2*1 - 3)/2 + 1 = 2.5 + 1 = 3.5 向下取整=3(降采样:边长减少1/2)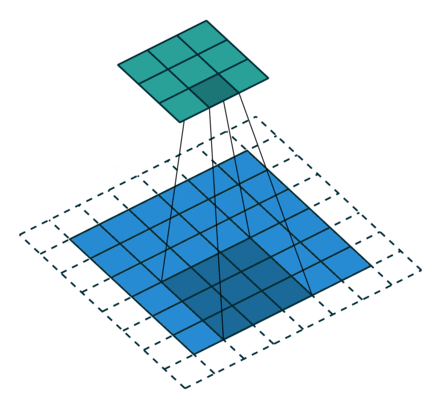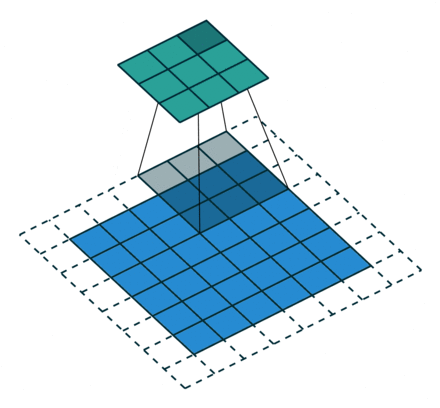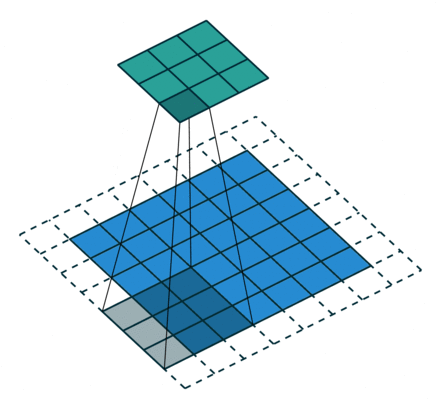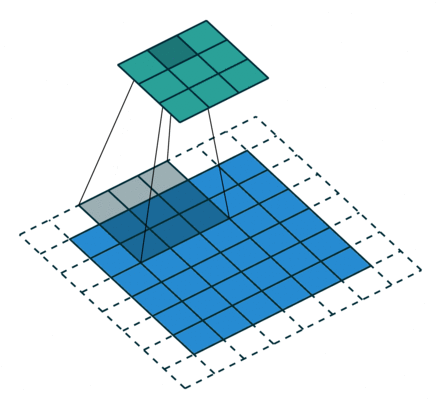
在PyTorch中,卷积层的步幅(stride)也是一个一维张量,通常包含两个或四个元素,具体取决于卷积层的类型(2D或3D卷积)。对于2D卷积层,步幅通常是一个包含两个元素的张量,格式为 [stride_height, stride_width]。对于3D卷积或其他更复杂的层,步幅可能包含四个元素,格式为 [stride_batch, stride_height, stride_width, stride_channel],但这种情况较少见,因为通常不会在批处理维度或通道维度上应用步幅。
import torch.nn as nn# 定义一个2D卷积层,步幅为(2, 2)
conv_layer = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=(2, 2), padding=1) 在这个例子中,stride=(2, 2) 表示卷积核在高度和宽度方向上每次移动两个像素。这种设置通常用于减少特征图的尺寸,实现下采样。
2.3 pooling池化
这个pooling,是为了提取一定区域的主要特征,并减少参数数量,防止模型过拟合。 比如下面的MaxPooling,采用了一个2×2的窗口,并取stride=2:
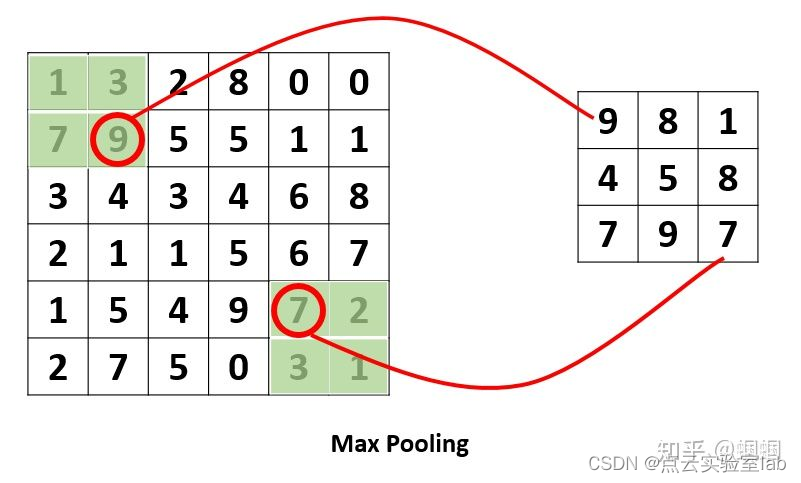
除了MaxPooling,还有AveragePooling,顾名思义就是取那个区域的平均值。
2.4 对多通道(channels)图片的卷积
这个需要单独提一下。彩色图像,一般都是RGB三个通道(channel)的,因此输入数据的维度一般有三个:(长,宽,通道)。 比如一个28×28的RGB图片,维度就是(28,28,3)。
前面的引子中,输入图片是2维的(8,8),filter是(3,3),输出也是2维的(6,6)。
如果输入图片是三维的呢(即增多了一个channels),比如是(8,8,3),这个时候,我们的filter的维度就要变成(3,3,3)了,它的最后一维要跟输入的channel维度一致。 这个时候的卷积,是三个channel的所有元素对应相乘后求和,也就是之前是9个乘积的和,现在是27个乘积的和。因此,输出的维度并不会变化。还是(6,6)。
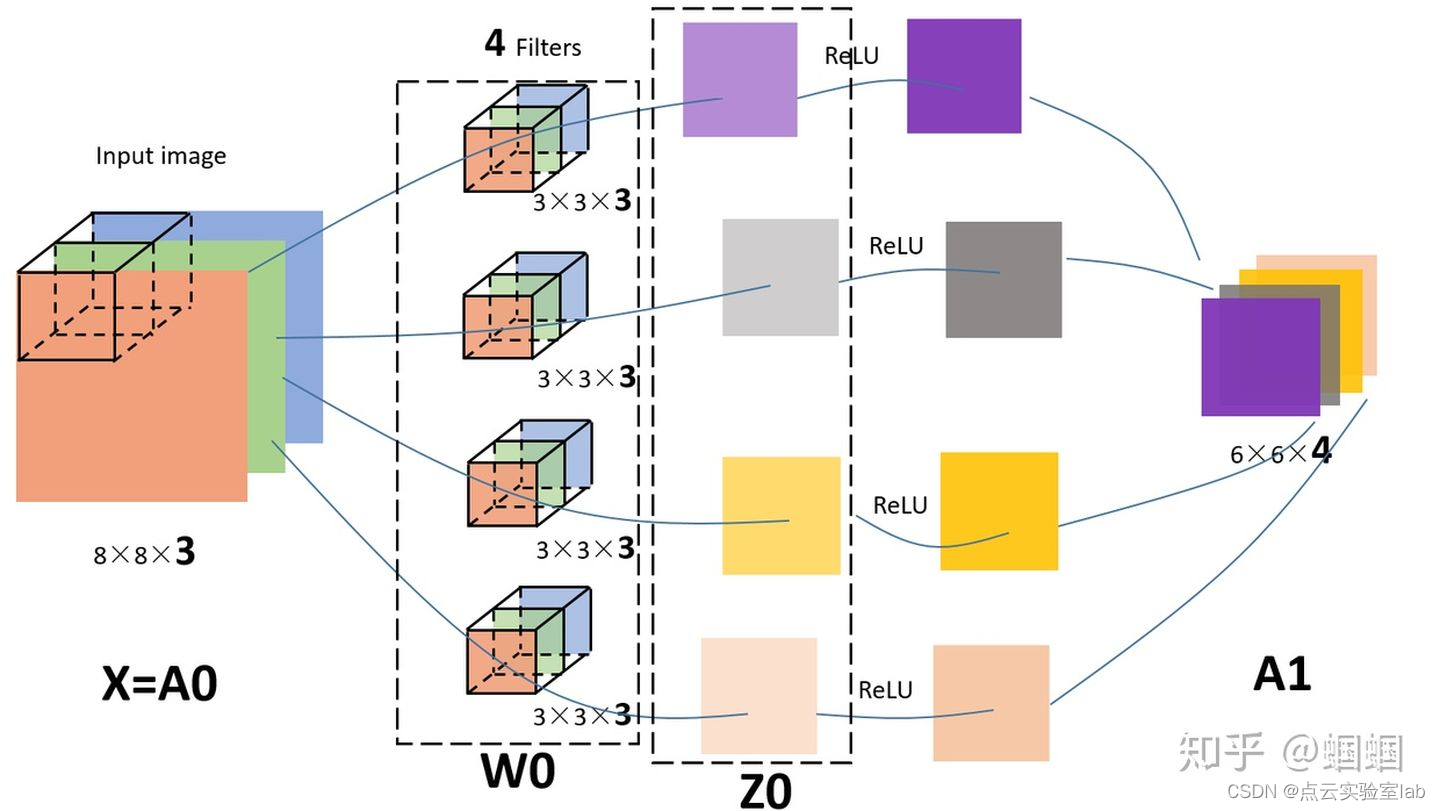
但是,一般情况下,我们会 使用多个filters同时卷积,比如,如果我们同时使用4个filter的话,那么 输出的维度则会变为(6,6,4)。
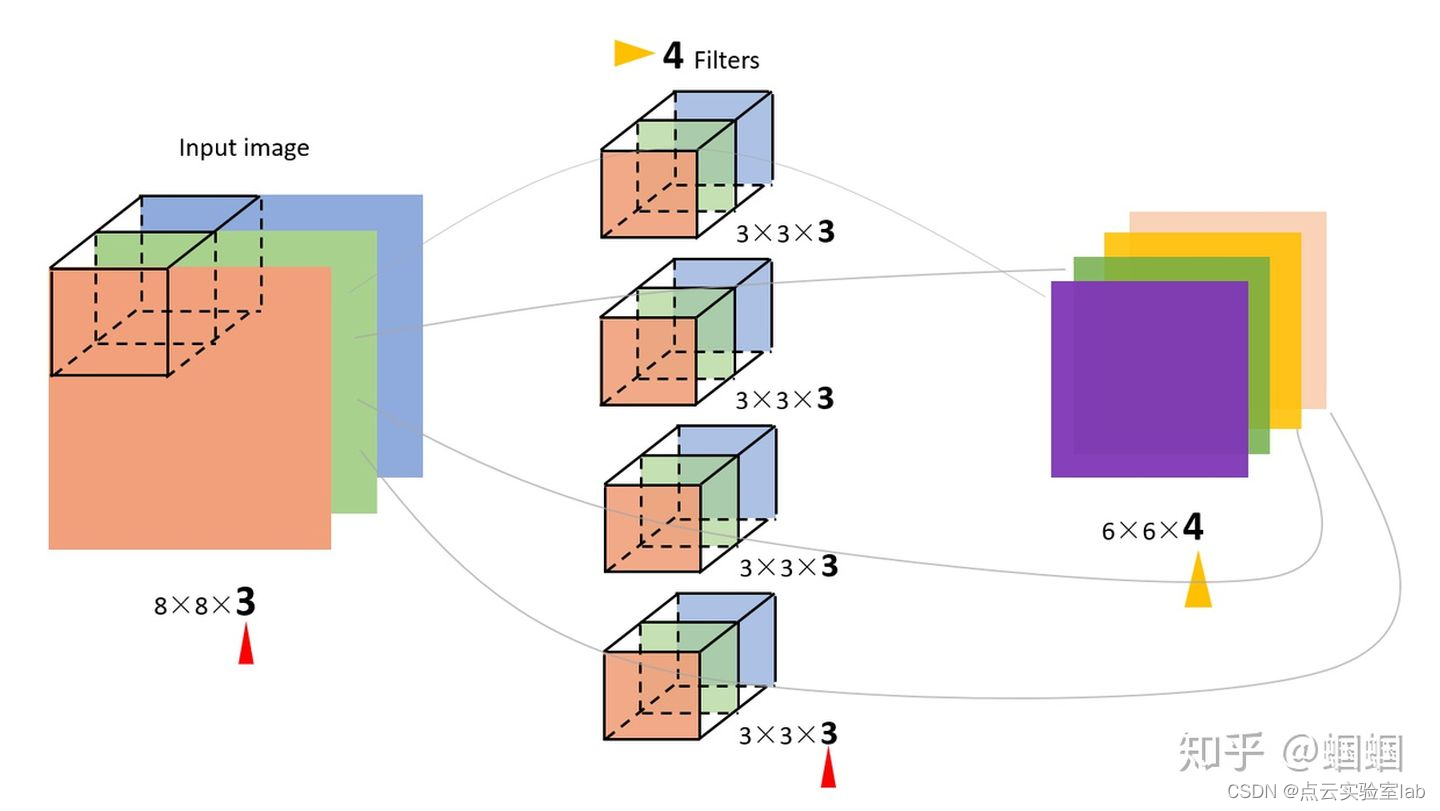
图中的输入图像是(8,8,3),filter有4个,大小均为(3,3,3),得到的输出为(6,6,4)。
其实,如果套用我们前面学过的神经网络的符号来看待CNN的话,
- 我们的输入图片就是X,shape=(8,8,3);
- 4个filters其实就是第一层神金网络的参数W1,shape=(3,3,3,4),这个4是指有4个filters;
- 我们的输出,就是Z1,shape=(6,6,4);
- 后面其实还应该有一个激活函数,比如relu,经过激活后,Z1变为A1,shape=(6,6,4);
所以,在前面的图中,我加一个激活函数,给对应的部分标上符号,就是这样的:
在pytorch中,自定义卷积层代码如下:
self.conv2 = nn.Sequential(nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)-
卷积层 (
nn.Conv2d):in_channels=16: 输入通道数,这里是16,意味着这个卷积层期望接收具有16个通道的输入数据。out_channels=32: 输出通道数,设置为32,表示这个卷积层会产生32个特征图(filters/feature maps)。kernel_size=3: 卷积核的大小是3x3像素。stride=1: 步长为1,表示卷积核每次移动一个像素。padding=1: 填充为1,表示在输入数据的周围添加一圈0值填充,使得卷积操作后输出的空间维度与输入相同。
-
激活层 (
nn.ReLU):- 应用ReLU(Rectified Linear Unit)激活函数,它将每个输入值转换为最大值0和输入值本身。这有助于引入非线性,使得网络能够学习更复杂的特征。
-
池化层 (
nn.MaxPool2d):kernel_size=2: 池化窗口的大小是2x2像素。stride=2: 步长为2,表示池化窗口每次移动两个像素。这通常会导致输出特征图的空间尺寸减半。
3、CNN的结构组成
上面我们已经知道了卷积(convolution)、池化(pooling)以及填白(padding)是怎么进行的,接下来我们就来看看CNN的整体结构,它包含了3种层(layer):
3.1 卷积层(Convolutional layer, conv)
由滤波器filters和激活函数构成。 一般要设置的超参数包括filters的数量、大小、步长,以及padding是“valid”还是“same”。当然,还包括选择什么激活函数。
3.2 Pooling layer(池化层-pool)
这里里面没有参数需要我们学习,因为这里里面的参数都是我们设置好了,要么是Maxpooling,要么是Averagepooling。 需要指定的超参数,包括是Max还是average,窗口大小以及步长。 通常,我们使用的比较多的是Maxpooling,而且一般取大小为(2,2)步长为2的filter,这样,经过pooling之后,输入的长宽都会缩小2倍,channels不变。
3.3 Fully Connected layer(全链接层-FC)
全连接层(Fully Connected Layer),也称为密集层(Dense Layer),是神经网络中的一层,其中每个神经元都与前一层的所有神经元相连接。全连接层通常用于神经网络的最后几层,将学到的特征映射到最终的输出,例如分类任务的类别数。
在全连接层中,每个神经元都有一组参数(权重和偏置),这些参数用于对输入数据进行线性变换,然后通过激活函数进行非线性变换。全连接层的输出是输入数据和权重矩阵的线性组合,再加上偏置向量。
参考博客:
【1】多通道图片的卷积_多通道卷积过程-CSDN博客
【2】CNN中stride(步幅)和padding(填充)的详细理解_cnn stride-CSDN博客
相关文章:
卷积神经网络(CNN)理解
1、引言(卷积概念) 在介绍CNN中卷积概念之前,先介绍一个数字图像中“边缘检测edge detection”案例,以加深对卷积的认识。图中为大小8X8的灰度图片,图片中数值表示该像素的灰度值。像素值越大,颜色越亮&…...

Databend 开源周报第 149 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 支持递归公共表…...
Hue Hadoop 图形化用户界面 BYD
软件简介 Hue 是运营和开发 Hadoop 应用的图形化用户界面。Hue 程序被整合到一个类似桌面的环境,以 web 程序的形式发布,对于单独的用户来说不需要额外的安装。...
【经验分享】RT600 serial boot mode测试
【经验分享】RT600 serial boot mode测试 一, 文档描述二, Serial boot mode测试2.1 evkmimxrt685_gpio_led_output 工程测试2.2 evkmimxrt685_dsp_hello_world_usart_cm33工程测试 一, 文档描述 RT600的启动模式共支持4种: 1&am…...

七种不同类型测宽仪技术参数 看看哪种能用于您的产线?
在线测宽仪种类众多,原理不同,产品不同,型号不同,其技术参数也各不相同。不同的测量范围与测量精度,适用于不同规格的板材,看看您的板材能适用于哪种范围。 1、单测头平行光测宽仪 点光源发射的光经过发射…...

【GO】rotatelogs库和sirupsen/logrus库实现日志功能的实践用例
“github.com/sirupsen/logrus” 是一个 Go 语言的日志库,它提供了一种简单、灵活的方式来记录日志。该库的主要特点包括: 支持多种日志输出目标,如控制台、文件等。 支持日志轮转,可以按照时间或文件大小进行轮转。 支持日志格式…...

Arc2Face - 一张图生成逼真的多风格人脸,本地一键整合包下载
Arc2Face是用于人脸的基础模型训练,可批量生成超高质量主题的AI人脸艺术风格照,完美复制人脸。只需一张照片,几秒钟,即可批量生成超高质量主题的AI人脸艺术风格照,完美复制人脸。 Arc2Face 是一个创新的开源项目&…...
swiper 幻灯片
index.html <!DOCTYPE html> <html lang"en"> <head> <meta charset"utf-8"> <title>swiper全屏响应式幻灯片代码</title> <meta name"viewport" content"widthdevice-width, initial-scale1, min…...

Ubuntu 使用Vscode的一些技巧 ROS
Ubuntu VSCode的一些设置(ROS) 导入工作空间 推荐只导入工作空间下的src目录 如果将整个工作空间导入VSCode,那么这个src就变成了次级目录,容易在写程序的时候把本应该添加到具体工程src目录里的代码文件给误添加到这个catkin_w…...

JS中的三种事件模型
JavaScript 中的事件模型主要有三种: 传统事件模型(DOM Level 0)标准事件模型(DOM Level 2)IE 事件模型(非标准,仅限于旧版本的 Internet Explorer) 下面分别介绍这三种事件模型&…...

南京邮电大学计算机网络实验二(网络路由器配置RIP协议)
文章目录 一、 实验目的和要求二、 实验环境(实验设备)三、 实验步骤四、实验小结(包括问题和解决方法、心得体会、意见与建议等)五、报告资源 一、 实验目的和要求 掌握思科路由器的运行过程,掌握思科路由器的硬件连线与接口,掌…...

仓颉语言的编译和构建
一、cjc 使用 cjc是仓颉编程语言的编译命令,其提供了丰富的功能及对应的编译选项,本章将对基本使用方法进行介绍。 cjc-frontend (仓颉前端编译器)会随 cjc 一起通过 Cangjie SDK 提供,cjc-frontend 能够将仓颉源码编…...

网络基础-协议
一、ARP 通过IP得到Mac 首先会查看缓存的arp表中是否有相应的IP和Mac对应关系,如果有直接进行包封装。如果没有则进行广播当对应的地址就收到广播包后会根据arp中的源地址进行单播返回相应的IP和Mac对应关系。 arp -a 查看现有的arp缓存 二、RARP反向地址解析 通过…...
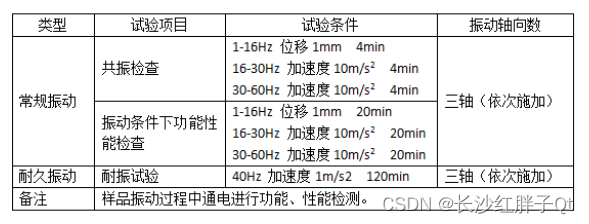
电子设备抗震等级与电子设备震动实验
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/139923445 红胖子(红模仿)的博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、OpenGL、ffmpeg、OSG、单片机、软…...
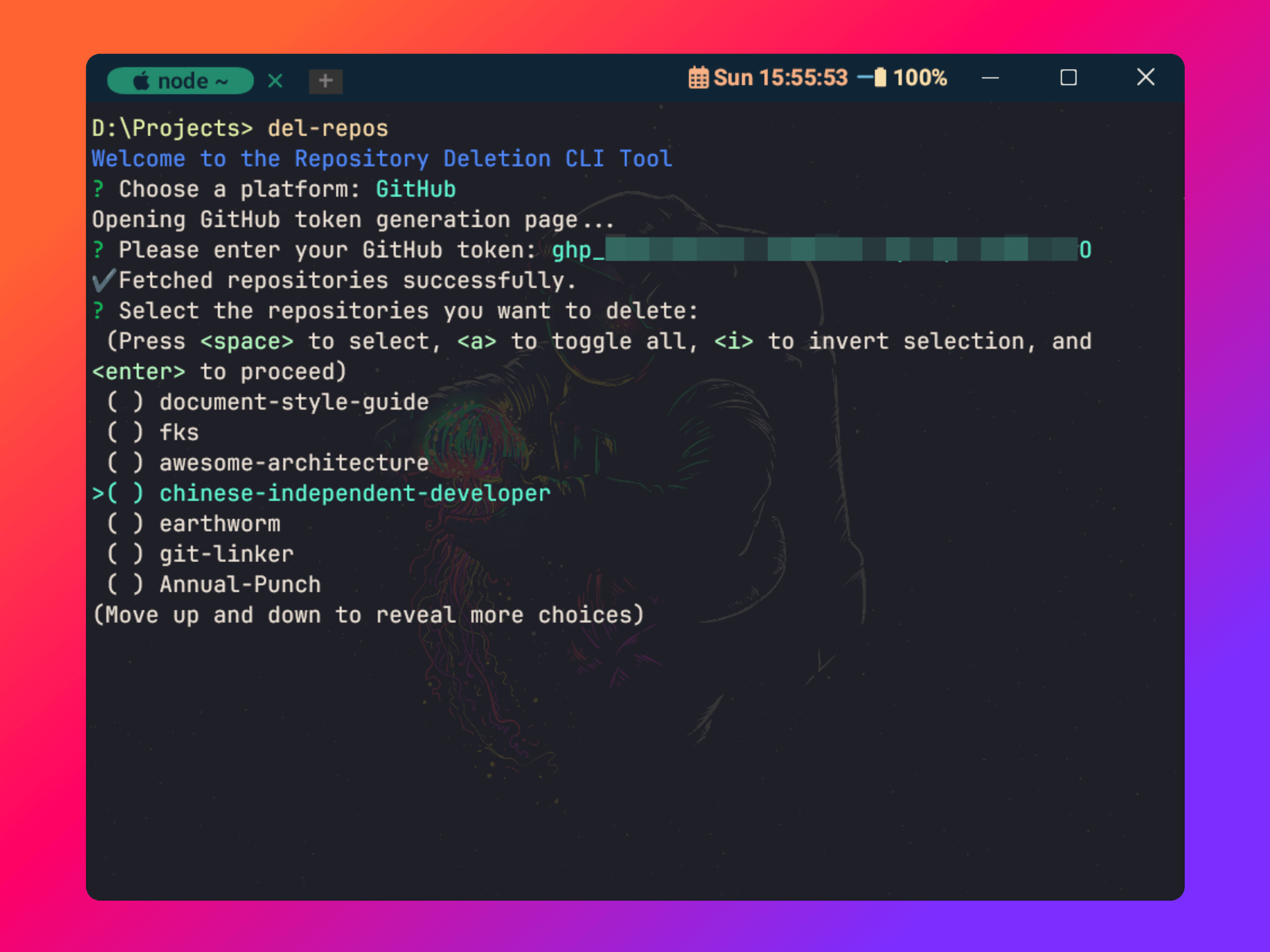
你还在手动操作仓库?这款 CLI 工具让你效率飙升300%!
前言 作为一名开发者,我经常会在 GitHub 和 Gitee 上 fork 各种项目。时间一长,这些仓库就会堆积如山,变成了“垃圾仓库”。每次打开代码托管平台,看到那些不再需要的仓库,我的强迫症就会发作。手动一个一个删除这些仓…...

未来已来!GPT-5震撼登场,工作与生活面临新变革!
随着科技界领袖对AI系统发展之快的惊叹,新一代大语言模型GPT-5即将登场,引发了我们对工作和日常生活的新一轮思考。微软CTO Kevin Scott和阿里巴巴董事长蔡崇信等人的言论为我们描绘了一幅生动的未来图景,即AI将在我们的生活中扮演越来越重要…...

洗地机选购指南,什么品牌最值得购买?2024四大口碑品牌推荐
随着炎炎夏日的到来,家里的地板清洁会成为人们“沉重”的负担,而拥有一台能够高效又轻松完成地板深度清洁的洗地机是一件非常幸福的事儿。但是,面对市场上琳琅满目的洗地机品牌和型号,如何找到一款综合性能都不错的洗地机成为了许…...

住宅IP与普通IP的区别
在互联网连接中,IP地址是识别每个网络节点的关键。在众多类型的IP地址中,住宅IP和普通IP是两种常见的分类。本文将深入探讨住宅IP与普通IP之间的主要区别。 一、定义与来源 住宅IP指的是由互联网服务提供商(ISP)直接分配给家庭或…...
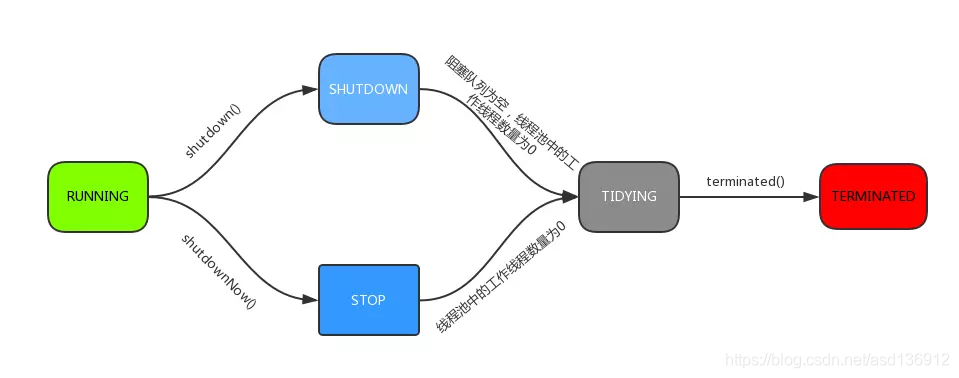
【Java】线程池技术(三)ThreadPoolExecutor 状态与运行源码解析
ThreadPoolExecutor 状态 ThreadPoolExecutor 继承了 AbstractExecutorService,并实现了 ExecutorService 接口,用于管理线程。内部使用了原子整型 AtomicInteger ctl 来表示线程池状态和 Worker 数量。前 3 位表示线程池状态,后 29 位表示 …...

vscode使用内置插件断点调试vue2项目
1、首先项目中要开启source-map 在vue.config.js 文件中 module.exports {configureWebpack: {devtool: process.env.NODE_ENV ! "production" ? "source-map" : ,} }2、项目根目录新建.vscode/launch.js文件 {"configurations": [{"ty…...

Arm MPS3 FPGA开发板LED闪烁控制实战
1. 项目概述在嵌入式系统开发领域,FPGA(现场可编程门阵列)因其可重构特性成为硬件原型设计的首选平台。Arm MPS3 FPGA开发板作为一款功能强大的原型验证工具,为开发者提供了从算法验证到系统集成的完整解决方案。本次我们将通过经…...
)
基于AI的MRI图像超分辨率重建与去噪,当AI遇见MRI:基于深度学习的超分辨率重建与去噪实战(从SwinIR到Diffusion)
目录 1. 问题的起点:MRI为什么需要超分和去噪? 2. 最新技术选型:为什么不用简单CNN? 3. 数据准备:模拟MRI的退化过程 4. SwinIR核心原理与MRI适配 简化的SwinIR模型结构(PyTorch实现) 5. 去噪专用:Restormer(Transformer for Restoration) 关键组件:MDTA(Mu…...

Linux内核构建自动化:jpoindexter/kern工具实战指南
1. 项目概述:一个被低估的Linux内核构建工具 如果你和我一样,长期在嵌入式开发、内核模块调试或者需要频繁定制Linux内核的岗位上工作,那么你一定对内核的配置、编译、打包这一套繁琐的流程感到又爱又恨。爱的是,这是深入理解操作…...

aztfexport扩展开发:如何自定义资源映射和导入逻辑
aztfexport扩展开发:如何自定义资源映射和导入逻辑 【免费下载链接】aztfexport A tool to bring existing Azure resources under Terraforms management 项目地址: https://gitcode.com/gh_mirrors/az/aztfexport Azure Export for Terraform(a…...
AIGC面试指南:从Transformer到扩散模型,系统掌握核心技术与实战
1. 项目概述:一本面向AIGC求职者的实战指南最近几年,AI生成内容(AIGC)领域的热度可以说是“肉眼可见”地飙升。从文本生成、图像创作到视频合成,相关岗位如雨后春笋般涌现,吸引了大量开发者和研究者的目光。…...

GitHub PR全流程实战:从创建、自动化测试到代码审查与合并
1. 项目概述与核心价值 如果你参与过开源项目,或者在公司内部使用GitHub进行团队协作,那么“Pull Request”(PR)这个流程你一定不陌生。它不仅仅是把代码从一个分支合并到另一个分支那么简单,而是一整套围绕代码质量、…...

嵌入式以太网模块WIZ5500应用指南:从SPI接口到物联网稳定连接
1. 项目概述:为什么你的物联网项目需要一个有线网络“锚点”无线网络(Wi-Fi)确实方便,但做过几个实际项目的朋友都知道,它的“方便”有时是建立在“不确定性”之上的。信号波动、信道拥堵、复杂的认证流程,…...

创业团队如何用Taotoken低成本试验多个AI模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何用Taotoken低成本试验多个AI模型 对于资源有限的创业团队而言,在开发产品原型或验证AI功能时,…...

跨镜跟踪技术白皮书:ReID瓶颈与镜像无感解决方案
跨镜跟踪技术白皮书:ReID瓶颈与镜像无感解决方案前言在数字孪生、视频孪生、全域安防感知等领域,跨镜跟踪作为全域连续感知、目标轨迹溯源的核心技术,已成为智慧园区、工业厂区、城市治理、交通枢纽等场景落地的关键支撑。当前,行…...

英伟达收购SwiftStack:AI时代从算力到数据管道的战略布局
1. 项目概述:一次战略收购的深度拆解最近在梳理科技巨头的战略动向时,一个几年前的老新闻——“英伟达收购SwiftStack”——重新进入了我的视野。乍一看,这似乎只是一次普通的商业并购,一个做GPU的巨头买下了一家名不见经传的软件…...