分享AI学习笔记之Python
当你说"抓取网站数据"时,通常指的是网络爬虫(web scraping)或网络抓取(web crawling)。Python提供了很多库可以帮助你实现这个功能,其中最常见的有requests(用于发送HTTP请求)和BeautifulSoup(用于解析HTML和XML文档)。
以下是一个简单的示例,展示了如何使用requests和BeautifulSoup从网站抓取数据:
import requests
from bs4 import BeautifulSoup def scrape_website(url): # 发送HTTP GET请求 response = requests.get(url) # 检查响应状态码是否为200(成功) if response.status_code == 200: # 使用BeautifulSoup解析HTML内容 soup = BeautifulSoup(response.text, 'html.parser') # 这里假设我们要抓取所有的<p>标签的内容 for p_tag in soup.find_all('p'): print(p_tag.get_text()) else: print(f"Failed to retrieve the webpage. Status code: {response.status_code}") # 使用示例
scrape_website('https://example.com') # 请替换为你想要抓取的网站URL注意:
遵守robots.txt:在抓取任何网站之前,都应该检查其robots.txt文件以了解哪些页面可以被爬虫访问。
不要过度抓取:频繁的请求可能会给服务器带来压力,甚至可能导致你的IP地址被封禁。
处理异常:上述代码没有处理可能发生的异常,如网络错误、超时等。在实际应用中,你应该添加适当的异常处理。
使用代理和延迟:对于需要登录或有限制的网站,你可能需要使用代理服务器,并在请求之间添加延迟来避免被封禁。
法律和道德:在抓取网站数据时,确保你的行为是合法和道德的。不要抓取受版权保护的内容或私人信息。
使用专门的库:除了requests和BeautifulSoup之外,还有其他一些库可以简化网络抓取过程,如Scrapy、Selenium等。根据你的需求选择合适的库。
相关文章:

分享AI学习笔记之Python
当你说"抓取网站数据"时,通常指的是网络爬虫(web scraping)或网络抓取(web crawling)。Python提供了很多库可以帮助你实现这个功能,其中最常见的有requests(用于发送HTTP请求…...

多版本GCC安装及切换
目录 1 背景2 安装2.1 Ubuntu 20.042.2 Ubuntu 18.04 3 配置4 切换4.1 切换到版本94.2 切换到版本10 1 背景 最近在研究C20中的协程需要安装GCC版本10。用到GCC多版本切换,记录步骤。 2 安装 2.1 Ubuntu 20.04 运行如下命令安装两个版本编译器: sudo apt insta…...

Redis进阶 - 朝生暮死之Redis过期策略
概述 Redis 是一种常用的内存数据库,其所有的数据结构都可以设置过期时间,时间一到,就会自动删除。你可以想象 Redis 内部有一个死神,时刻盯着所有设置了过期时间的 key,寿命一到就会立即收割。 你还可以进一步站在死神…...

MySQL实训--原神数据库
原神数据库 er图DDL/DML语句查询语句存储过程/触发器 er图 DDL/DML语句 SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS 0;DROP TABLE IF EXISTS artifacts; CREATE TABLE artifacts (id int NOT NULL AUTO_INCREMENT,artifacts_name varchar(255) CHARACTER SET utf8 COLLATE …...

Retrieval-Augmented Generation for Large Language Models A Survey
Retrieval-Augmented Generation for Large Language Models: A Survey 文献综述 文章目录 Retrieval-Augmented Generation for Large Language Models: A Survey 文献综述 Abstract背景介绍 RAG概述原始RAG先进RAG预检索过程后检索过程 模块化RAGModules部分Patterns部分 RAG…...

【曦灵平台】深度体验百度智能云曦灵平台之数字人3.0、声音克隆、直播等功能,AI加持就是不一样,快来一起体验
目录 资产数字人 2D数字人克隆声音克隆 AI卡片更多功能总结推荐文章 资产 可进行人像与声音的定制,让数字人形象和声音成为我们的专属资产,用于后续的内容生产工作 数字人 这里拍摄的视频分辨率和帧率必须要确保是官方要求,这里博主通过第…...

如何使用GPT?初学者的指南
ChatGPT是一个非常先进的AI工具,它使用GPT-4架构,能够生成自然的语言回应。它的多功能性和理解复杂指令的能力,使得很多人用它来回答各种问题,就像用Google一样输入关键词。不过,ChatGPT还能做更多事情,下面…...
24年了 直播带货的未来如何?
32 个国家在取消电商, 那我国的电商呢,首先电商是不会被取缔的。直播电商会被严格的控制,比如有一家饼店,它线下的销售是 3000 万,线上抖音的销售是 5, 000 万。 这一类型小而精又专业的品牌企业,未来在抖…...

【神经网络】深入理解多层神经网络(深度神经网络
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步! 深入理解多层神经网络&#x…...

CAS原理与JUC原子类
一、CAS基本原理 1、Unsafe类 (1)概念及作用:增强Java语言操作底层资源的能力,里面的方法多为native修饰的方法(基于C实现),不建议在代码中使用,不安全。 (2ÿ…...

【杂记-浅谈OSPF协议之RouterDeadInterval死区间隔】
OSPF协议之RouterDeadInterval死区间隔 一、RouterDeadInterval概述二、设置RouterDeadInterval三、RouterDeadInterval的重要性 一、RouterDeadInterval概述 RouterDeadInterval,即路由器死区间隔,它涉及到路由器如何在广播网络上发现和维护邻居关系。…...

【每日刷题】Day75
【每日刷题】Day75 🥕个人主页:开敲🍉 🔥所属专栏:每日刷题🍍 🌼文章目录🌼 1. 1833. 雪糕的最大数量 - 力扣(LeetCode) 2. 面试题 17.14. 最小K个数 - 力扣…...

文件管理器加载缓慢-禁用文件类型自动发现功能
文件管理器加载缓慢-禁用文件类型自动发现功能 右键“Shell”项,选择新建“字符串值” “FolderType”,数值为 NotSpecified。...

.[nicetomeetyou@onionmail.org].faust深入剖析勒索病毒及防范策略
引言: 在数字化时代,网络安全问题日益凸显,其中勒索病毒无疑是近年来网络安全的重大威胁之一。勒索病毒以其独特的加密机制和恶意勒索行为,给个人和企业带来了巨大的经济损失和数据安全风险。本文将从勒索病毒的传播方式、攻击链、…...

Ardupilot开源代码之ExpressLRS性能实测方法
Ardupilot开源代码之ExpressLRS性能实测方法 1. 源由2. 测试效果3. 测试配置4. 总结5. 参考资料6. 补充 1. 源由 之前一直在讨论ExpressLRS性能的问题,有理论、模拟、实测。 始终缺乏完整的同一次测试的测试数据集,本章节将介绍如何在Ardupilot上进行获…...
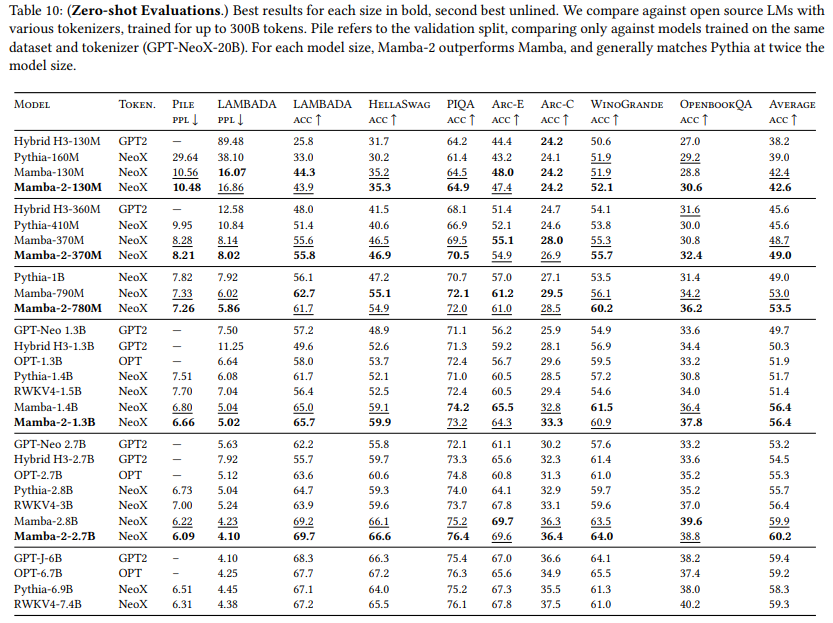
Transformers是SSMs:通过结构化状态空间对偶性的广义模型和高效算法(二)
文章目录 6、针对SSD模型的硬件高效算法6.1、对角块6.2、低秩块6.3、计算成本 7、Mamba-2 架构7.1、块设计7.2、序列变换的多头模式7.3、线性注意力驱动的SSD扩展8、系统优化对于SSMs8.1、张量并行8.2、序列并行性8.3、可变长度 9、实证验证9.1、合成任务:联想记忆9…...
Segment any Text:优质文本分割是高质量RAG的必由之路
AI应用开发相关目录 本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧 适用于具备一定算法及Python使用基础的人群 AI应用开发流程概…...

IDEA 学习之 编译内存问题
目录 1. 正常的 IDEA build 日志2. 编译工具内存不足日志 (内存从小变大)2.1. 干脆无法启动2.2. Ant 任务执行报错2.3. 内存溢出:超出 GC 上限2.4. 内存溢出:超出 GC 上限,编译报错2.5. 内存溢出: 堆空间2.…...

如何将本地项目推送到gitee仓库
目录 为何用gitee管理自己项目: 如何将自己的项目推送到gitee仓库,步骤如下: 1.下载git 2.生成公钥 3.在gitee上添加公钥 4.在gitee上创建仓库 5.将本地项目推送到gitee仓库 为何用gitee管理自己项目: 1.可以使用多台电脑…...

产品经理基础入门
一、产品基础(需求收集、需求管理、需求分析、结构图、流程图、原型、PRD文档、用户画像、后台的角色管理) 产品经理定义: 1.市场分析:找准市场方向,确定哪个市场是值得进入的。 2.用户分析:针对目标市场…...

专业解析开源AI浏览器助手:Page Assist的深度技术架构与实战应用
专业解析开源AI浏览器助手:Page Assist的深度技术架构与实战应用 【免费下载链接】page-assist Use your locally running AI models to assist you in your web browsing 项目地址: https://gitcode.com/GitHub_Trending/pa/page-assist Page Assist是一款革…...

WarcraftHelper终极指南:5步解决魔兽争霸3闪退与兼容性问题
WarcraftHelper终极指南:5步解决魔兽争霸3闪退与兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3闪退问题烦恼吗…...

深入解析 magic-cli:基于模板的自动化代码生成工具设计与实践
1. 项目概述:一个能“变魔术”的命令行工具最近在折腾一些自动化脚本和项目脚手架时,发现了一个挺有意思的开源项目,叫magic-cli。乍一看这个名字,你可能会觉得有点玄乎,命令行工具还能玩出什么“魔法”来?…...

FSearch深度解析:Linux极速文件搜索的技术实现与性能优化终极方案
FSearch深度解析:Linux极速文件搜索的技术实现与性能优化终极方案 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 在Linux系统中寻找文件常常是令人头疼的…...

模型哈密顿量构建:从第一性原理到可计算有效模型的实践指南
1. 项目概述:从“黑箱”到“白箱”的化学计算桥梁 在计算化学和材料科学领域,我们常常面临一个核心矛盾:一方面,我们希望模型足够精确,能够捕捉到电子结构最细微的相互作用,比如使用密度泛函理论࿰…...
)
告别单调列表!用Unity Dropdown组件打造游戏中的动态交互式菜单(附事件处理完整代码)
告别单调列表!用Unity Dropdown组件打造游戏中的动态交互式菜单(附事件处理完整代码) 在独立游戏开发中,UI交互的细腻程度往往决定了玩家的沉浸感。想象一下:当玩家在角色创建界面选择职业时,下拉菜单不仅显…...

Windows热键冲突终极排查指南:5分钟快速定位占用进程
Windows热键冲突终极排查指南:5分钟快速定位占用进程 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经…...

忘记压缩包密码怎么办?5分钟学会用ArchivePasswordTestTool找回密码
忘记压缩包密码怎么办?5分钟学会用ArchivePasswordTestTool找回密码 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经…...
)
LM567锁相环芯片实测:手把手教你搭建10kHz音频信号检测电路(附面包板接线图)
LM567锁相环芯片实战:从零构建10kHz音频检测电路全流程解析 在电子设计领域,频率检测一直是个既基础又关键的课题。无论是红外遥控信号解码、超声波测距,还是电磁导航系统,精准的频率识别都是实现功能的前提。而LM567这款经典的锁…...
的选型与实战踩坑)
从手机SoC到汽车芯片:深入聊聊AMBA总线家族(AHB/APB/AXI)的选型与实战踩坑
从手机SoC到汽车芯片:AMBA总线家族的选型与实战经验 在移动计算和汽车电子两大领域,芯片架构师们每天都在面临类似的挑战:如何在有限的硅片面积和功耗预算内,实现最高的系统性能。AMBA总线作为连接处理器、内存和各种外设的"…...