diffusion model(十八):diffusion model中negative prompt的工作机制
| info | |
|---|---|
| 个人博客主页 | http://myhz0606.com/article/ncsn |
前置阅读:
DDPM: http://myhz0606.com/article/ddpm
classifier-guided:http://myhz0606.com/article/guided
classifier-free guided:http://myhz0606.com/article/classifier_free
Score based generative model:http://myhz0606.com/article/ncsn
引言
在用Stable Diffusion生成图片时,除了输入图片表述文本外(positive prompt),我们还经常会使用negative prompt作为condition来让模型避免生成negative prompt所表述的概念。查阅源码发现stable diffusion中negative prompt的实现机制是将classifier-free guided中 ϵ θ ( x t , y = ∅ , t ) \epsilon_{\theta}(x_t, y=\empty, t) ϵθ(xt,y=∅,t)替换为 ϵ θ ( x t , y ~ , t ) \epsilon_{\theta}(x_t, \tilde{y}, t) ϵθ(xt,y~,t),( y ~ \tilde{y} y~表示negative prompt)。即:
原生classifier-free guided每一个timestep的噪声估计如下:
ϵ ^ θ ( x t , y , t ) = ϵ θ ( x t , y = ∅ , t ) + s [ ϵ θ ( x t , y , t ) − ϵ θ ( x t , y = ∅ , t ) ] \begin{align} \hat{\epsilon}_{\theta}(x_t, y, t)=\epsilon_{\theta}(x_t, y=\empty,t) + s[\epsilon_{\theta}(x_t, y, t) - \epsilon_{\theta}(x_t, y=\empty, t) ]\tag{1} \end{align} ϵ^θ(xt,y,t)=ϵθ(xt,y=∅,t)+s[ϵθ(xt,y,t)−ϵθ(xt,y=∅,t)](1)
当有negative prompt condition时,将上式改为
ϵ ^ θ ( x t , y , t ) = ϵ θ ( x t , y ~ , t ) + s [ ϵ θ ( x t , y , t ) − ϵ θ ( x t , y ~ , t ) ] \begin{align} \hat{\epsilon}_{\theta}(x_t, y, t)=\epsilon_{\theta}(x_t, \tilde{y},t) + s[\epsilon_{\theta}(x_t, y, t) - \epsilon_{\theta}(x_t, \tilde{y}, t) ]\tag{2} \end{align} ϵ^θ(xt,y,t)=ϵθ(xt,y~,t)+s[ϵθ(xt,y,t)−ϵθ(xt,y~,t)](2)
源码位置位于(diffuser版本v0.29.1): https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py#L427
那么为什么negative prompt能够work呢?
How do negative prompt take effect
为了引出相关推导,先快速回顾一下classifier-guided和classifier-free的motivation。
为了做条件生成(即从条件分布 p ( x ∣ y ) p(x|y) p(x∣y)中采样样本),我们可以根据贝叶斯公式进行如下推导:
p ( x ∣ y ) = p ( y ∣ x ) p ( x ) p ( y ) log p ( x ∣ y ) = log p ( y ∣ x ) + log p ( x ) − log p ( y ) ⇒ ∇ x log p ( x ∣ y ) = ∇ x log p ( y ∣ x ) + ∇ x log p ( x ) − ∇ x log p ( y ) ⏟ = 0 ⇒ ∇ x log p ( x ∣ y ) = ∇ x log p ( y ∣ x ) + ∇ x log p ( x ) (3) \begin{aligned} p(\mathrm{x}|y) &= \frac{p(y|\mathrm{x})p(\mathrm{x})}{p(y)} \\ \log p(\mathrm{x}|y) &= \log p(y|\mathrm{x}) + \log p(\mathrm{x}) - \log p(y) \\ \Rightarrow \nabla_{\mathrm{x}} \log p(\mathrm{x}|y) &= \nabla_{\mathrm{x}} \log p(y|\mathrm{x}) + \nabla_{\mathrm{x}} \log p(\mathrm{x}) - \underbrace{ \nabla_{\mathrm{x}} \log p(y) }_{=0} \\ \Rightarrow \nabla_{\mathrm{x}} \log p(\mathrm{x}|y) &= \nabla_{\mathrm{x}} \log p(y|\mathrm{x}) + \nabla_{\mathrm{x}} \log p(\mathrm{x}) \end{aligned} \tag{3} p(x∣y)logp(x∣y)⇒∇xlogp(x∣y)⇒∇xlogp(x∣y)=p(y)p(y∣x)p(x)=logp(y∣x)+logp(x)−logp(y)=∇xlogp(y∣x)+∇xlogp(x)−=0 ∇xlogp(y)=∇xlogp(y∣x)+∇xlogp(x)(3)
在classifier-guided任务中,我们已知无条件输入的score based model能够估计出 ∇ x log p ( x ) \nabla_{\mathrm{x}} \log p(\mathrm{x}) ∇xlogp(x) ,因此,为了得到 ∇ x log p ( y ∣ x ) \nabla_{\mathrm{x}} \log p(y|\mathrm{x}) ∇xlogp(y∣x) ,我们只需额外训练一个分类器来估计 ∇ x log p ( y ∣ x ) \nabla_{\mathrm{x}} \log p(y|\mathrm{x}) ∇xlogp(y∣x)即可。为了控制condition的强度,引入一个guidance scale s s s。
∇ x log p ( x ∣ y ) : = s ∇ x log p ( y ∣ x ) + ∇ x log p ( x ) (4) \nabla_{\mathrm{x}} \log p(\mathrm{x}|y) := s \nabla_{\mathrm{x}} \log p(y|\mathrm{x}) + \nabla_{\mathrm{x}} \log p(\mathrm{x}) \tag{4} ∇xlogp(x∣y):=s∇xlogp(y∣x)+∇xlogp(x)(4)
对于classifier-free任务中,通过随机drop标签,我们同时训练 ∇ x log p ( x ) \nabla_{\mathrm{x}} \log p(\mathrm{x}) ∇xlogp(x) 和 ∇ x log p ( x ∣ y ) \nabla_{\mathrm{x}} \log p(\mathrm{x}|y) ∇xlogp(x∣y) 两个score based model。虽然我们可以通过 ∇ x log p ( x ∣ y ) \nabla_{\mathrm{x}} \log p(\mathrm{x}|y) ∇xlogp(x∣y) 直接进行条件生成,但为了控制生成时条件的强度,沿用了公式(4) guidance scale的概念。并且 ∇ x log p ( y ∣ x ) = ∇ x log p ( x ∣ y ) − ∇ x log p ( x ) \nabla_{\mathrm{x}} \log p(y|\mathrm{x}) = \nabla_{\mathrm{x}} \log p(\mathrm{x}|y) - \nabla_{\mathrm{x}} \log p(\mathrm{x}) ∇xlogp(y∣x)=∇xlogp(x∣y)−∇xlogp(x) ,故有:
∇ x log p ( x ∣ y ) : = s ( ∇ x log p ( x ∣ y ) − ∇ x log p ( x ) ) + ∇ x log p ( x ) (5) \nabla_{\mathrm{x}} \log p(\mathrm{x}|y) := s (\nabla_{\mathrm{x}} \log p(\mathrm{x}|y) - \nabla_{\mathrm{x}} \log p(\mathrm{x}) ) + \nabla_{\mathrm{x}} \log p(\mathrm{x}) \tag{5} ∇xlogp(x∣y):=s(∇xlogp(x∣y)−∇xlogp(x))+∇xlogp(x)(5)
stable diffusion代码路径:https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py#L1019
当有negative prompt作为condition时,此时的condition为两项,一项是 y y y: positive prompt condition,另一项为 n o t y ~ \mathrm{not} \, \tilde{y} noty~:negative prompt condition。
只要得到 ∇ x log p ( x ∣ y , n o t y ~ ) \nabla_{\mathrm{x}} \log p(\mathrm{x}|y, \mathrm{not} \, \tilde{y}) ∇xlogp(x∣y,noty~)我们就可以参考之前的采样算法生成样本。重新直接训练一个score based model来估计 ∇ x log p ( x ∣ y , n o t y ~ ) \nabla_{\mathrm{x}} \log p(\mathrm{x}|y, \mathrm{not} \, \tilde{y}) ∇xlogp(x∣y,noty~)当然可行,但成本巨大。下面来看如何进行简化[1,2]
p ( x ∣ y , n o t y ~ ) = p ( x , y , n o t y ~ ) p ( y , n o t y ~ ) = p ( y , n o t y ~ ∣ x ) p ( x ) p ( y , n o t y ~ ) = 在 x 条件下 y 与 n o t y ~ 独立 p ( y ∣ x ) p ( n o t y ~ ∣ x ) p ( x ) p ( y , n o t y ~ ) ∝ p ( x ) p ( y , n o t y ~ ) p ( y ∣ x ) p ( y ~ ∣ x ) ⇒ ∇ x log p ( x ∣ y , n o t y ~ ) ∝ ∇ x log p ( x ) + ∇ x log p ( y ∣ x ) − ∇ x log p ( y ~ ∣ x ) (6) \begin{aligned} p(\mathrm{x}|y, \mathrm{not}\, \tilde{y} ) & = \frac{p(\mathrm{x},y, \mathrm{not}\, \tilde{y})}{p(y, \mathrm{not}\, \tilde{y})} \\ &= \frac{p(y, \mathrm{not}\, \tilde{y}|\mathrm{x})p(\mathrm{x})}{p(y, \mathrm{not}\, \tilde{y})} \\ & \stackrel{在x条件下y与\mathrm{not} \, \tilde{y}独立}= \frac{p(y|\mathrm{x})p(\mathrm{not}\, \tilde{y}|\mathrm{x})p(\mathrm{x})}{p(y,\mathrm{not}\, \tilde{y})} \\ & \propto \frac{p(\mathrm{x})}{{p(y,\mathrm{not}\, \tilde{y})}} \frac{p(y|\mathrm{x})}{p(\tilde{y}|\mathrm{x})} \\ \Rightarrow \nabla_{\mathrm{x}} \log p(\mathrm{x}|y, \mathrm{not}\, \tilde{y} ) & \propto \nabla_{\mathrm{x}} \log p(\mathrm{x}) + \nabla_{\mathrm{x}} \log p(y|\mathrm{x}) - \nabla_{\mathrm{x}} \log {p(\tilde{y}|\mathrm{x})} \end{aligned} \tag{6} p(x∣y,noty~)⇒∇xlogp(x∣y,noty~)=p(y,noty~)p(x,y,noty~)=p(y,noty~)p(y,noty~∣x)p(x)=在x条件下y与noty~独立p(y,noty~)p(y∣x)p(noty~∣x)p(x)∝p(y,noty~)p(x)p(y~∣x)p(y∣x)∝∇xlogp(x)+∇xlogp(y∣x)−∇xlogp(y~∣x)(6)
由于:
∇ x log p ( y ∣ x ) = ∇ x log p ( x ∣ y ) − ∇ x log p ( x ) ∇ x log p ( y ~ ∣ x ) = ∇ x log p ( x ∣ y ~ ) − ∇ x log p ( x ) (7) \begin{aligned}\nabla_{x} \log p(y|\mathrm{x}) = \nabla_{x} \log p(\mathrm{x}|y) - \nabla_{\mathrm{x}} \log p(\mathrm{x}) \\ \nabla_{\mathrm{x}} \log p(\tilde{y}|\mathrm{x}) = \nabla_{x} \log p(\mathrm{x}|\tilde{y}) - \nabla_{\mathrm{x}} \log p(\mathrm{x}) \end{aligned} \tag{7} ∇xlogp(y∣x)=∇xlogp(x∣y)−∇xlogp(x)∇xlogp(y~∣x)=∇xlogp(x∣y~)−∇xlogp(x)(7)
记 s + s^{+} s+为positive prompt condition的guidance scale, s − s^{-} s−为negative prompt的guidance scale,有
∇ x log p ( x ∣ y , n o t y ~ ) : = ∇ x log p ( x ) + s + ( ∇ x log p ( x ∣ y ) − ∇ x log p ( x ) ) − s − ( ∇ x log p ( x ∣ y ~ ) − ∇ x log p ( x ) ) (8) \nabla_{\mathrm{x}} \log p(\mathrm{x}|y, \mathrm{not}\, \tilde{y} ) := \nabla_{\mathrm{x}} \log p(\mathrm{x}) + s^{+}(\nabla_{x} \log p(\mathrm{x}|y) - \nabla_{\mathrm{x}} \log p(\mathrm{x})) - s^{-} (\nabla_{x} \log p(\mathrm{x}|\tilde{y}) - \nabla_{\mathrm{x}} \log p(\mathrm{x})) \tag{8} ∇xlogp(x∣y,noty~):=∇xlogp(x)+s+(∇xlogp(x∣y)−∇xlogp(x))−s−(∇xlogp(x∣y~)−∇xlogp(x))(8)
通过式(8)可以得出,我们只需计算 ∇ x log p ( x ) \nabla_{\mathrm{x}} \log p(\mathrm{x}) ∇xlogp(x) , ∇ x log p ( x ∣ y ) \nabla_{x} \log p(\mathrm{x}|y) ∇xlogp(x∣y), ∇ x log p ( x ∣ y ~ ) \nabla_{x} \log p(\mathrm{x}|\tilde{y}) ∇xlogp(x∣y~)三项即可估计出 ∇ x log p ( x ∣ y , n o t y ~ ) \nabla_{\mathrm{x}} \log p(\mathrm{x}|y, \mathrm{not}\, \tilde{y} ) ∇xlogp(x∣y,noty~)。
当 1 − s + + s − = 0 1 - s^{+} + s^{-} = 0 1−s++s−=0时, s − = s + − 1 s^{-} = s^{+} - 1 s−=s+−1有
∇ x log p ( x ∣ y , n o t y ~ ) = s + ∇ x log p ( x ∣ y ) − ( s + − 1 ) ∇ x log p ( x ∣ y ~ ) = ∇ x log p ( x ∣ y ~ ) + s + ( ∇ x log p ( x ∣ y ) − ∇ x log p ( x ∣ y ~ ) ) (9) \begin{aligned} \nabla_{\mathrm{x}} \log p(\mathrm{x}|y, \mathrm{not}\, \tilde{y} ) &= s^{+}\nabla_{x} \log p(\mathrm{x}|y) - (s^{+} - 1)\nabla_{x} \log p(\mathrm{x}|\tilde{y}) \\ & = \nabla_{x} \log p(\mathrm{x}|\tilde{y}) + s^{+}(\nabla_{x} \log p(\mathrm{x}|y) - \nabla_{x} \log p(\mathrm{x}|\tilde{y})) \end{aligned} \tag{9} ∇xlogp(x∣y,noty~)=s+∇xlogp(x∣y)−(s+−1)∇xlogp(x∣y~)=∇xlogp(x∣y~)+s+(∇xlogp(x∣y)−∇xlogp(x∣y~))(9)
式(9) 就是stable diffusion源码中实现形式
源码位置位于(diffuser版本v0.29.1): https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py#L427
文献[3]通过“Neutralization Hypothesis”,“Reverse Activation”解释negative prompt conditioning的工作机制,感兴趣的同学可以后续阅读。
When do negative prompt take effect
定性分析
上文我们通过理论推导证明了negative prompt conditioning的可行性。本节将从可视化的角度分析negative prompt conditioning是如何影响图片生成的。主要文献参考[3]
类似Prompt-to-prompt[4]的研究思路,我们可以绘制不同时间步token-wise attention map热力图。从图中发现,negative prompt作用存在一定延迟。positive prompt conditioning在生成的早期(t=0-3)时就关注到对应的区域,而negative prompt conditioning直到t=8-11才能正确关注到对应的区域。

定量分析
进一步的,为了定量的描述上述机制,文献[3]定义了 r t r_t rt为negative prompt conditioning的强度
r t = Σ k ∥ F k , p − ( i ) ( t ) ∥ F Σ k ∥ F k , p + ( r ( i ) ) ( t ) ∥ F (10) r _ { t } = \frac { \Sigma _ { k } \| F _ { k , p _ { - } ( i ) } ^ { ( t ) } \| _ { F } } { \Sigma _ { k } \| F _ { k , p _ { + } ( r ( i ) ) } ^ { ( t ) } \| _ { F } } \tag{10} rt=Σk∥Fk,p+(r(i))(t)∥FΣk∥Fk,p−(i)(t)∥F(10)
假设:Positive prompt: Pofessional office woman. Negative prompt: Glasses
p _ p_{\_} p_: 表示negative prompt
p + p_{+} p+: 表示positive prompt
p _ ( i ) p_{\_ }(i) p_(i):表示negative prompt第 i i i个索引处的token
p + ( r ( i ) ) p_{+}(r(i)) p+(r(i)):表示positive prompt p + p_{+} p+中与 p _ ( i ) p_{\_ }(i) p_(i)最相关的token。 p _ ( i ) p_{\_ }(i) p_(i)=”Glasses”, 那么 p + ( r ( i ) ) p_{+}(r(i)) p+(r(i))=“woman”。
F k , p _ ( i ) t F_{k, p_{\_ (i)}}^{t} Fk,p_(i)t: 在时间步为t时,在第k层cross-attention处token p _ ( i ) p_{\_ }(i) p_(i)对应的attention map。
F k , p + ( r ( i ) ) t F_{k, p_{+}(r(i))}^{t} Fk,p+(r(i))t: 在时间步为t时,在第k层cross-attention处token p + ( r ( i ) ) p_{+}(r(i)) p+(r(i))对应的attention map。
当 r t r_t rt越小时,说明negative prompt conditioning的强度越小,反之越大。
选择了10对相应的提示对,10个不同的随机种子上进行实验,并绘制 ( r t , t ) (r_t, t) (rt,t)曲线如下:

从上图不难得出:
- negative prompt conditioning的强度初始较弱,在时间步为5-10时达到峰值。
- 当negative prompt 为名词时, r t r_t rt呈先增强后降低趋势,这是由于当negative prompt作用后,会移除生成图片中的对应实体,从而让token-wise attention map的响应变弱。
- 当negative prompt 为形容词时, r t r_t rt呈先增强后稳定。
即然negative prompt conditioning存在滞后性,可以在初始阶段(t=0-5)不引入negative prompt conditioning,之后在引入,这能起到类似局部编辑的效果。

小结
本文相对系统探讨了diffusion model中negative prompt conditioning的工作机理,解释了stable diffusion关于negative prompt conditioning源码实现的合理性(式9),并给出了更一般的形式(式8)。
参考文献
[1] Compositional Visual Generation with Energy Based Models
[2] Compositional Visual Generation with Composable Diffusion Models
[3]Understanding the Impact of Negative Prompts: When and How Do They Take Effect?
[4]http://myhz0606.com/article/p2p
相关文章:
diffusion model(十八):diffusion model中negative prompt的工作机制
info个人博客主页http://myhz0606.com/article/ncsn 前置阅读: DDPM: http://myhz0606.com/article/ddpm classifier-guided:http://myhz0606.com/article/guided classifier-free guided:http://myhz0606.com/article/classi…...

Python | Leetcode Python题解之第200题岛屿数量
题目: 题解: class Solution:def dfs(self, grid, r, c):grid[r][c] 0nr, nc len(grid), len(grid[0])for x, y in [(r - 1, c), (r 1, c), (r, c - 1), (r, c 1)]:if 0 < x < nr and 0 < y < nc and grid[x][y] "1":self.d…...

利用圆上两点和圆半径求解圆心坐标
已知圆上两点P1,P2,坐标依次为 ( x 1 , y 1 ) , ( x 2 , y 2 ) (x_1,y_1),(x_2,y_2) (x1,y1),(x2,y2),圆的半径为 r r r,求圆心的坐标。 假定P1,P2为任意两点,则两点连成线段的中点坐标是 x m i …...

从ChatGPT代码执行逃逸到LLMs应用安全思考
摘要 11月7日OpenAI发布会后,GPT-4的最新更新为用户带来了更加便捷的功能,包括Python代码解释器、网络内容浏览和图像生成能力。这些创新不仅开辟了人工智能应用的新境界,也展示了GPT-4在处理复杂任务方面的惊人能力。然而,与所有…...

Python入门-基础知识-变量
1.标识符与关键字 Python语言规定,标识符由字母、数字和下画线组成,且不允许以数字开头。合法的标识符可以 是student_1、 addNumber、num等,而3number、2_student等是不合法的标识符。在使用标识符时应注意以下几点。 (1)命名时应遵循见名知…...
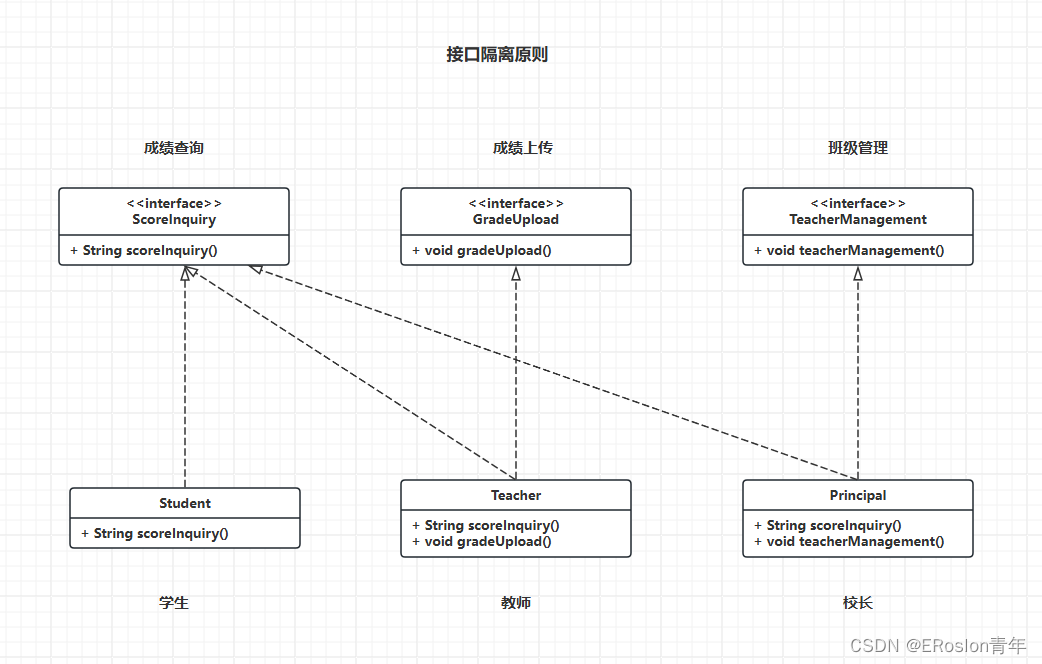
设计模式原则——接口隔离原则
设计模式原则 设计模式示例代码库地址: https://gitee.com/Jasonpupil/designPatterns 接口隔离原则 要求程序员尽量将臃肿庞大的接口拆分为更小的和更具体的接口,让接口中只包含客户感兴趣的方法接口隔离原则的目标是降低类或模块之间的耦合度&…...

MySQL数据库——在Centos7环境安装
MySQL在Centos7环境安装 1.切换root用户 安装与卸载中,用户全部切换成为root,安装好后,普通用户也能使用 2.卸载不要的环境 要将自己环境中有关mysql的全都删除,避免安装过程中被影响 ps axj | grep mariadb 先检查是否有mari…...

怎样规避液氮容器内部结霜的问题
液氮容器内部结霜问题一直是我们在使用液氮储存罐时遇到的一个棘手难题。液氮的极低温度使得容器内部很容易产生结霜现象,这不仅影响了容器的正常使用,还可能对内部样品或设备造成损坏。因此,如何有效规避液氮容器内部结霜问题成为了每个使用…...

冶金工业5G智能工厂工业物联数字孪生平台,推进制造业数字化转型
冶金工业5G智能工厂工业物联数字孪生平台,推进制造业数字化转型。传统生产方式难以满足现代冶金工业的发展需求,数字化转型成为必然趋势。通过引入5G、工业物联网和数字孪生等先进技术,冶金工业可以实现生产过程智能化、高效化和绿色化&#…...

一文入门机器学习参数调整实操
作者前言: 通过向身边的同事大佬请教之后,大佬指点我把本文的宗旨从“参数调优”改成了“参数调整”。实在惭愧,暂时还没到能“调优”的水平,本文只能通过实操演示“哪些操作会对数据训练产生影响”,后续加深学习之后,…...

基于51单片机的银行排队呼叫系统设计
一.硬件方案 本系统是以排队抽号顺序为核心,客户利用客户端抽号,工作人员利用叫号端叫号;通过显示器及时显示当前所叫号数,客户及时了解排队信息,通过合理的程序结构来执行排队抽号。电路主要由51单片机最小系统LCD12…...

JXCategoryView的使用总结
一、初始化 -(JXCategoryTitleView *)categoryView{if (!_categoryView) {_categoryView [[JXCategoryTitleView alloc] init];_categoryView.delegate self;_categoryView.titleDataSource self;_categoryView.averageCellSpacingEnabled NO; //是否平均分配项目之间的间…...

Centos9 安装VBox增强功能问题
安装步骤 更新gcc 首先手动更新gcc,防止无法兼容最新版本的内核,我这里将gcc 11更新到gcc 13 1.首先更新当前gcc和支持 yum install -y gcc gcc-c 2.下载新版本gcc压缩包 wget http://ftp.gnu.org/gnu/gcc/gcc-13.1.0/gcc-13.1.0.tar.gz 解压到usr ta…...

【JVM】Java虚拟机运行时数据分区介绍
JVM 分区(运行时数据区域) 文章目录 JVM 分区(运行时数据区域)前言1. 程序计数器2. Java 虚拟机栈3. 本地方法栈4. Java 堆5. 方法区6. 运行时常量池7. 直接内存 前言 之前在说多线程的时候,提到了JVM虚拟机的分区内存…...
)
大数据面试题之Kafka(2)
目录 Kafka的工作原理? Kafka怎么保证数据不丢失,不重复? Kafka分区策略 Kafka如何尽可能保证数据可靠性? Kafka数据丢失怎么处理? Kafka如何保证全局有序? 生产者消费者模式与发布订阅模式有何异同? Kafka的消费者组是如何消费数据的 Kafka的…...
)
前端面试题(基础篇十一)
一、DOCTYPE 的作用是什么? <!DOCTYPE> 声明一般位于文档的第一行,它的作用主要是告诉浏览器以什么样的模式来解析文档。一般指定了之后会以标准模式来进行文档解析,否则就以兼容模式进行解析。在标准模式下,浏览器的解析规…...
【论文阅读】Answering Label-Constrained Reachability Queries via Reduction Techniques
Cai Y, Zheng W. Answering Label-Constrained Reachability Queries via Reduction Techniques[C]//International Conference on Database Systems for Advanced Applications. Cham: Springer Nature Switzerland, 2023: 114-131. Abstract 许多真实世界的图都包含边缘标签…...

Git Flow 工作流学习要点
Git Flow 工作流学习要点 Git Flow — 流程图Git Flow — 操作指令优点:缺点:Git Flow 分支类型Git Flow 工作流程简述关于 feature 分支关于 Release 分支关于 hotfix 分支 总结 Git Flow — 流程图 图片来源:https://nvie.com/posts/a-succ…...

blender 快捷键 常见问题
一、快捷键 平移视图:Shift 鼠标中键旋转视图:鼠标中键缩放视图:鼠标滚动框选放大模型:Shift B线框预览和材质预览切换:Shift Z 二、常见问题 问题:导入模型成功,但是场景中看不到。 解…...

HTTP详解:TCP三次握手和四次挥手
一、TCP协议概述 TCP协议是互联网协议栈中传输层的核心协议之一,它提供了一种可靠的数据传输方式,确保数据包按顺序到达,并且没有丢失或重复。TCP的主要特点包括: 面向连接:TCP在传输数据之前需要建立连接。可靠传输&…...

如何在Windows上快速安装iPhone网络共享驱动:3分钟终极解决方案
如何在Windows上快速安装iPhone网络共享驱动:3分钟终极解决方案 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.c…...

谷歌首次阻止AI驱动的零日漏洞攻击,黑客利用AI找漏洞手段曝光
AI零日漏洞攻击计划浮出水面谷歌威胁情报小组(GTIG)的报告显示,“知名网络犯罪威胁行为者”正谋划利用人工智能开发的零日漏洞发动“大规模利用事件”。其目标是绕过一款未具名的“开源、基于网络的系统管理工具”的双因素认证。目前谷歌已成…...

恶意 Hugging Face 仓库 18 小时登顶热门榜,引发公共 AI 仓库安全担忧
【事件概述】一个伪装成 OpenAI 发布内容的恶意 Hugging Face 仓库,向 Windows 系统投放信息窃取恶意软件。该仓库在 18 小时内登上 Hugging Face 热门排行榜首位,被移除前下载量达 24.4 万次,引发人们对企业从公共仓库获取和验证 AI 模型的新…...

Go-ldap-admin权限系统解析:基于Casbin的RBAC实现完整指南
Go-ldap-admin权限系统解析:基于Casbin的RBAC实现完整指南 【免费下载链接】go-ldap-admin 🌉 基于GoVue实现的openLDAP后台管理项目 项目地址: https://gitcode.com/gh_mirrors/go/go-ldap-admin Go-ldap-admin作为一款基于GoVue实现的现代化Ope…...
)
告别兼容性烦恼:在Vue/React项目中优雅集成sm-crypto国密算法(附IE9+解决方案)
告别兼容性烦恼:在Vue/React项目中优雅集成sm-crypto国密算法(附IE9解决方案) 国密算法作为国内信息安全领域的重要标准,在前端项目中的集成需求日益增长。然而,现代前端框架与老旧浏览器兼容性问题往往成为开发者的拦…...

工程师的调试礼仪:如何避免一次问候毁掉两小时工作成果
1. 项目概述:一次关于“Bug礼仪”的职场博弈在硬件开发的深水区,尤其是在产品临近交付的冲刺阶段,工程师与管理者之间的互动,往往比电路板上的信号完整性更考验“设计”。这不是一个关于具体芯片型号或调试命令的技术教程…...

长沙定制开发本地生活APP打造城市便民消费场景
随着长沙城市发展,市民对便民消费的需求越来越高,长沙本地生活APP定制开发也逐渐成为本地商家、政企单位布局数字化的重要选择。不同于通用模板APP,长沙定制本地生活APP可根据长沙本地特色,整合餐饮、生鲜、家政、休闲娱乐、政务便…...

从惊叹到依赖:软件定义时代的技术信任与实用指南
1. 从“惊叹”到“依赖”:我们与技术关系的深度剖析“这玩意儿以前没有的时候,我们是怎么活过来的?” 这念头时不时就会冒出来。我能看懂纸质地图,甚至开车时有时觉得它比谷歌地图更靠谱;我也记得在厚厚的黄页里翻找电…...

观察taotoken在ubuntu高峰期调用时的稳定性与自动路由效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 在 Ubuntu 高峰期调用时的稳定性与自动路由效果 1. 背景与测试环境 在日常的开发与调试工作中,我们经常…...

Dify数据库查询插件:让AI应用轻松连接业务数据的实战指南
1. 项目概述与核心价值 如果你正在使用 Dify 构建企业级 AI 应用,并且经常需要让 AI 助手去查询数据库里的数据——比如让 LLM 帮你分析销售报表、查找用户信息或者生成业务洞察——那么你很可能遇到过这样的痛点:Dify 本身并不直接支持数据库连接。你需…...