【机器学习】基于Transformer的迁移学习:理论与实践
引言
在机器学习领域,迁移学习已成为提升模型训练效率和性能的重要策略,特别是在标注数据稀缺的场景下。Transformer模型自2017年由Google提出以来,在自然语言处理(NLP)领域取得了突破性进展,并逐渐扩展到计算机视觉(CV)等多个领域。本文旨在深入探讨基于Transformer的迁移学习,从理论与实践两个维度分析其原理、优势及具体实现方法,并结合实际案例和代码示例,展示其在不同场景下的应用。

Transformer在机器学习领域的应用
原理与优势
Transformer是一种基于自注意力机制的深度学习模型,专门设计用于处理序列数据。其核心组件包括编码器(Encoder)和解码器(Decoder),每个部分由多个自注意力层和前馈神经网络层组成。相较于传统的循环神经网络(RNNs)和长短期记忆网络(LSTMs),Transformer通过完全去除循环结构,实现了高度的并行化,极大地加速了模型训练速度和推理效率。此外,自注意力机制使Transformer能够捕捉输入序列中各元素间的复杂依赖关系,无论这些元素在序列中的距离远近,这对于理解长文本尤为关键。
迁移学习
迁移学习,作为机器学习领域的一个重要分支,专注于利用在一个或多个源任务上学到的知识,来帮助提升在目标任务上的学习效果。这种学习方法的核心在于,它允许模型将从一个环境或任务中学到的经验和表示,迁移到另一个不同但相关的环境或任务中。
迁移学习的关键优势在于其能够显著降低对大量标注数据的依赖。在许多实际应用场景中,标注数据往往是稀缺且昂贵的,而迁移学习通过利用已有的、相关的标注或未标注数据,可以有效地减轻这一负担。此外,迁移学习还能够加速模型的训练过程,提高模型的泛化能力,使其更好地适应新的、未见过的数据。
迁移学习的方法多种多样,包括但不限于基于实例的迁移、基于特征的迁移、基于参数的迁移以及基于关系的迁移等。这些方法可以根据具体的应用场景和需求进行选择和优化,以实现最佳的迁移效果。
实现迁移学习
Transformer是一种基于自注意力机制的深度学习模型,专门设计用于处理序列数据。其核心组件包括编码器(Encoder)和解码器(Decoder),每个部分由多个自注意力层和前馈神经网络层组成。相较于传统的循环神经网络(RNNs)和长短期记忆网络(LSTMs),Transformer通过完全去除循环结构,实现了高度的并行化,极大地加速了模型训练速度和推理效率。此外,自注意力机制使Transformer能够捕捉输入序列中各元素间的复杂依赖关系,无论这些元素在序列中的距离远近,这对于理解长文本尤为关键。
实践技巧与方法
实际案例:基于BERT的文本分类
BERT(Bidirectional Encoder Representations from Transformers)是Transformer的一个重要变体,通过大规模预训练在自然语言处理任务中表现出色。以下是一个基于BERT进行文本分类的实践案例:
- 数据准备:准备用于文本分类的标注数据集,包括训练集和测试集。
- 模型加载与微调:
- 加载预训练的BERT模型。
- 根据分类任务的需求,修改BERT模型顶部的全连接层,以适应分类任务的类别数。
- 在训练集上对修改后的模型进行微调,通过反向传播优化模型参数。
- 评估与调优:在测试集上评估模型性能,根据需要进行参数调优或超参数搜索。
代码示例
以下是一个简化的PyTorch代码示例,展示如何加载BERT模型并进行微调:
import torch
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import DataLoader, TensorDataset # 假设已有预处理好的数据:inputs_ids, attention_masks, labels
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2) # 假设是二分类任务 # 创建DataLoader
dataset = TensorDataset(torch.tensor(inputs_ids), torch.tensor(attention_masks), torch.tensor(labels))
dataloader = DataLoader(dataset, batch_size=32, shuffle=True) # 定义优化器和损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
loss_fn = torch.nn.CrossEntropyLoss() # 训练模型
model.train()
for epoch in range(num_epochs): for batch in dataloader: inputs, masks, labels = batch optimizer.zero_grad() outputs = model(inputs, attention_mask=masks, labels=labels) loss = outputs.loss loss.backward() optimizer.step() # ...(评估模型等后续步骤)代码示例:基于ViT的图像分类
以下是一个使用PyTorch和timm库(一个流行的PyTorch图像模型库)来实现基于ViT的图像分类的代码示例:
import torch
from timm.models import vision_transformer
from torch.utils.data import DataLoader
from torchvision import datasets, transforms # 数据准备和预处理
transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(),
])
dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True) # 加载预训练的ViT模型
model = vision_transformer('vit_base_patch16_224', pretrained=True, num_classes=10) # CIFAR-10有10个类别 # 定义优化器和损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-4)
loss_fn = torch.nn.CrossEntropyLoss() # 训练模型
model.train()
for epoch in range(num_epochs): for batch in dataloader: images, labels = batch optimizer.zero_grad() outputs = model(images) loss = loss_fn(outputs, labels) loss.backward() optimizer.step() # ...(评估模型等后续步骤)在这个例子中,我们首先准备了CIFAR-10数据集,并对图像进行了必要的预处理。然后,我们加载了一个预训练的ViT模型,并修改了其顶部的全连接层以适应CIFAR-10的10个类别。接着,我们定义了优化器和损失函数,并开始训练模型。
- 数据预处理是深度学习流程中至关重要的一步,它直接影响到模型的训练效果和泛化能力。
结论
本文深入探讨了基于Transformer的迁移学习,从模型原理、优势到具体实践技巧和方法进行了全面介绍。通过实际案例和代码示例,展示了如何在文本分类等任务中应用BERT等预训练模型进行迁移学习。Transformer及其变体以其强大的序列建模能力、高效的并行计算和对长距离依赖的有效捕捉,在自然语言处理及其他领域展现了广泛的应用前景。随着研究的深入,基于Transformer的迁移学习将继续推动机器学习技术的发展,为更多实际应用场景提供有力支持。
相关文章:
【机器学习】基于Transformer的迁移学习:理论与实践
引言 在机器学习领域,迁移学习已成为提升模型训练效率和性能的重要策略,特别是在标注数据稀缺的场景下。Transformer模型自2017年由Google提出以来,在自然语言处理(NLP)领域取得了突破性进展,并逐渐扩展到…...

如何应对情绪和培养理性的书
以下是几本关于如何应对情绪和培养理性的书籍推荐: 《情绪智商》(Emotional Intelligence) - 丹尼尔戈尔曼(Daniel Goleman) 这本书探讨了情绪智商(EQ)的重要性以及如何通过提高EQ来改善个人和职…...

[数据集][目标检测]电缆钢丝绳线缆缺陷检测数据集VOC+YOLO格式1800张3类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1800 标注数量(xml文件个数):1800 标注数量(txt文件个数):1800 标注…...

【Git 学习笔记】Ch1.1 Git 简介 + Ch1.2 Git 对象
还是绪个言吧 今天整理 GitHub 仓库,无意间翻到了几年前自学 Git 的笔记。要论知识的稳定性,Git 应该能挤进前三——只要仓库还在,理论上当时的所有开发细节都可以追溯出来。正好过段时间会用到 Git,现在整理出来就当温故知新了。…...
Python 中别再用 ‘+‘ 拼接字符串了!
目录 引言 为什么不推荐使用 "" 示例代码 更高效的替代方法 使用 join 方法 示例代码 使用格式化字符串(f-strings) 示例代码 引言 大家好,在 Python 编程中,我们常常需要对字符串进行拼接。你可能会自然地想到…...

六西格玛绿带培训的证书有什么用处?
近年来,六西格玛作为一套严谨而系统的质量管理方法,被广泛运用于各行各业。而六西格玛绿带培训证书,作为这一方法论中基础且重要的认证,对于个人和企业而言,都具有不可忽视的价值。本文将从多个角度深入探讨六西格玛绿…...

《妃梦千年》第二十章:风雨欲来
第二十章:风雨欲来 战斗的胜利让林清婉和皇上的关系更加亲密,但宫中的阴谋却并未因此而停止。一天,林清婉正在寝宫中思考未来的对策,忽然接到一个紧急消息。小翠匆匆跑来,神色紧张:“娘娘,太后…...

深入理解二分法
前言 二分法(Binary Search)是一种高效的查找算法,广泛应用于计算机科学和工程领域。它用于在有序数组中查找特定元素,其时间复杂度为 O(log n),显著优于线性搜索的 O(n)。本文将深入介绍二分法的原理、实现及其应用场…...

【C命名规范】遵循良好的命名规范,提高代码的可读性、可维护性和可复用性
/******************************************************************** * brief param return author date version是代码书写的一种规范 * brief :简介,简单介绍函数作用 * param :介绍函数参数 * return:函数返回类型说明 * …...

Hbase面试题总结
一、介绍下HBase架构 --HMaster HBase集群的主节点,负责管理和协调整个集群的操作。它处理元数据和表的分区信息,控制RegionServer的负载均衡和故障恢复。--RegionServer HBase集群中的工作节点,负责存储和处理数据。每个RegionServer管理若…...

C语言部分复习笔记
1. 指针和数组 数组指针 和 指针数组 int* p1[10]; // 指针数组int (*p2)[10]; // 数组指针 因为 [] 的优先级比 * 高,p先和 [] 结合说明p是一个数组,p先和*结合说明p是一个指针 括号保证p先和*结合,说明p是一个指针变量,然后指…...
 : 用override set 设置工具链)
Rust学习笔记 (命令行命令) : 用override set 设置工具链
在cargo run某个项目时出现了如下错误:error: failed to run custom build command for ring v0.16.20(无法运行“Ring v0.16.20”的自定义构建命令),在PowerShell命令行运行命令 rustup override set stable-msvc后成功运行。 o…...

cv::Mat类的矩阵内容输出的各种格式的例子
操作系统:ubuntu22.04OpenCV版本:OpenCV4.9IDE:Visual Studio Code编程语言:C11 功能描述 我们可以这样使用:cv::Mat M(…); cout << M;,直接将矩阵内容输出到控制台。 输出格式支持多种风格,包括O…...

Redis--注册中心集群 Cluster 集群-单服务器
与“多服务器集群”一致需要创建redis配置模板 参照以下链接 CSDN 创建redis容器 node01服务器上创建容器 docker run -d --name redis-6381 --net host --privilegedtrue \ -v /soft/redis-cluster/6381/conf/redis.conf:/etc/redis/redis.conf \ -v /soft/redis-cluster/6…...
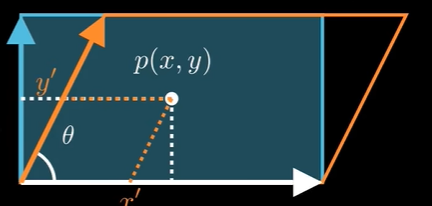
CV01_相机成像原理与坐标系之间的转换
目录 0.引言:小孔成像->映射表达式 1. 相机自身的运动如何表征?->外参矩阵E 1.1 旋转 1.2 平移 2. 如何投影到“像平面”?->内参矩阵K 2.1 图像平面坐标转换为像素坐标系 3. 三维到二维的维度是如何丢失的?…...
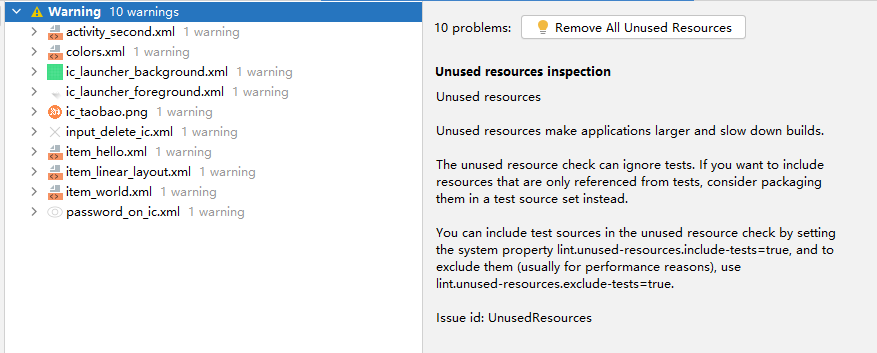
Android Lint
文章目录 Android Lint概述工作流程Lint 问题问题种类警告严重性检查规则 用命令运行 LintAndroidStudio 使用 Lint忽略 Lint 警告gradle 配置 Lint查找无用资源文件 Android Lint 概述 Lint 是 Android 提供的 代码扫描分析工具,它可以帮助我们发现代码结构/质量…...

【算法刷题 | 动态规划14】6.28(最大子数组和、判断子序列、不同的子序列)
文章目录 35.最大子数组和35.1题目35.2解法:动规35.2.1动规思路35.2.2代码实现 36.判断子序列36.1题目36.2解法:动规36.2.1动规思路36.2.2代码实现 37.不同的子序列37.1题目37.2解法:动规37.2.1动规思路37.2.2代码实现 35.最大子数组和 35.1…...
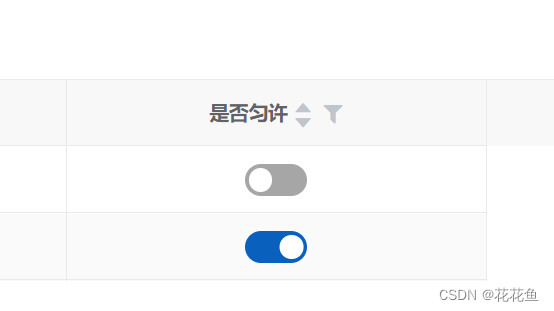
vue3 vxe-grid列中绑定vxe-switch实现数据更新
1、先上一张图: <template #valueSlot"{ row }"><vxe-switch :value"getV(row.svalue)" change"changeSwitch(row)" /></template>function getV(value){return value 1;};function changeSwitch(row) {console.l…...

Hive SQL:实现炸列(列转行)以及逆操作(行转列)
目录 列转行行转列 列转行 函数: EXPLODE(ARRAY):将ARRAY中的每一元素转换为每一行 EXPLODE(MAP):将MAP中的每个键值对转换为两行,其中一行数据包含键,另一行数据包含值 数据样例: 1、将每天的课程&#…...

MD5算法详解
哈希函数 是一种将任意输入长度转变为固定输出长度的函数。 一些常见哈希函数有:MD5、SHA1、SHA256。 MD5算法 MD5算法是一种消息摘要算法,用于消息认证。 数据存储方式:小段存储。 数据填充 首先对我们明文数据进行处理,使其…...
)
Vue2项目里,用lodash的debounce给搜索框‘降降温’(附完整代码和常见坑点)
Vue2实战:用lodash的debounce优化搜索框性能与避坑指南 搜索框是Web应用中最高频的交互组件之一,但处理不当可能成为性能黑洞。当用户快速输入"vue"、"react"等关键词时,传统实现会为每个字符触发搜索请求,导…...

基于MCP协议构建加密货币数据查询工具:coinpaprika-mcp详解
1. 项目概述:一个连接加密货币数据世界的桥梁 最近在折腾一个需要实时获取多种加密货币数据的项目,从价格、市值到社区动态,需求五花八门。市面上数据源不少,但要么API调用限制太死,要么数据维度不够全,要…...

Windows驱动签名实战:从证书获取到安装包封装的完整指南
1. 项目概述:为什么驱动签名是硬件开发者的“必修课” 如果你做过硬件开发,尤其是涉及USB、串口这类需要与Windows系统深度交互的设备,那你一定对那个黄色的“Windows安全”警告弹窗不陌生。用户插上你的设备,系统提示“正在安装…...

FRED应用:导入列表形式的BSDF数据
简介在FRED中,列表形式的BSDF数据可以使用如下两种方式。1. 按照FRED可以识别的数据格式直接导入作为散射模型。2. 使用BSDF数据拟合工具来产生合适的函数模型。数据文件的格式在FRED中能被识别的测试数据必须按照如下的规格形式。数据文件的开头包含两行࿰…...

基于树莓派与ROS的桌面机器人开发:从硬件组装到AI集成实战
1. 项目概述:一个“会思考”的桌面机器人伙伴最近在机器人爱好者圈子里,一个名为“Wall-E”的开源项目热度不低。这可不是那个动画电影里可爱的垃圾处理机器人,而是一个由SRA-VJTI团队开发的、运行在树莓派上的桌面级智能机器人项目。我第一次…...

从理论到实践:Ceres、G2O与GTSAM在位姿图优化中的核心实现与对比
1. 位姿图优化:从理论到代码的完整视角 想象你正在搭建一个室内扫地机器人,它需要同时完成两件事:构建房间地图(Mapping)和确定自身位置(Localization)。这就是典型的SLAM问题。而位姿图优化&am…...

把旧路由器改造成远程ADB调试服务器:OpenWrt安装adb与公网访问指南
旧路由器变身远程ADB调试服务器:OpenWrt实战指南 在移动应用开发过程中,频繁连接USB数据线进行调试不仅效率低下,更限制了开发者的工作灵活性。想象一下,当你需要同时调试多台设备,或者在不同网络环境下快速切换测试场…...

基于MCP协议与RAG技术构建智能聊天应用:架构解析与实战指南
1. 项目概述:一个基于MCP协议的RAG聊天应用最近在开源社区里,一个名为gogabrielordonez/mcp-ragchat的项目引起了我的注意。乍一看标题,它融合了当下两个非常热门的技术概念:MCP和RAG。对于从事AI应用开发,特别是希望构…...

AI智能体安全沙箱agentguard:为LLM代码执行筑起防火墙
1. 项目概述与核心价值 最近在开源社区里,一个名为 A386official/agentguard 的项目引起了我的注意。乍一看这个标题,你可能会联想到网络安全、代理防护或者某种守护进程。没错,这个项目正是为了解决一个在AI应用开发,特别是基于…...

CircuitPython硬件编程在Linux单板机上的实现:以ODROID C2为例
1. 项目概述:当CircuitPython遇见Linux单板机如果你玩过树莓派Pico或者Adafruit的Feather开发板,肯定对CircuitPython不陌生。它让Python跑在了微控制器上,用几行代码就能点亮LED、读取传感器,对硬件新手和快速原型开发来说&#…...