贝叶斯优化算法(Bayesian Optimization)及其Python 和 MATLAB 实现
贝叶斯优化算法(Bayesian Optimization)是一种基于贝叶斯统计理论的优化方法,通常用于在复杂搜索空间中寻找最优解。该算法能够有效地在未知黑盒函数上进行优化,并在相对较少的迭代次数内找到较优解,因此在许多领域如超参数优化、自动机器学习等中得到了广泛应用。
**背景:**
贝叶斯优化算法最早由Jonh Mockus等人提出,借鉴了高斯过程回归与贝叶斯优化技术相结合的优点。它适用于复杂的非凸函数优化问题,特别适用于一些黑盒函数难以求解、计算代价昂贵的场景。
**原理:**
贝叶斯优化的核心思想是通过构建目标函数的后验分布,利用先验信息和观测数据来推断参数的分布,并以此指导下一步的搜索。算法会根据当前已有数据,在未知区域寻找使目标函数有望最小化的点。通过不断建立高斯过程模型,不断地选择最具信息量的点进行探索,直到找到最优解。
**实现步骤:**
1. 选择高斯过程作为目标函数的先验模型;
2. 假设目标函数服从高斯过程,利用先验数据更新高斯过程的超参数;
3. 根据后验概率计算下一个最优的探索点;
4. 评估目标函数在这个探索点处的值,并更新高斯过程的后验分布;
5. 根据新的后验概率计算下一个最优的探索点,并反复迭代直到收敛。
**优缺点:**
- 优点:
1. 高效:相对于传统优化算法,贝叶斯优化算法通常在较少的迭代次数内找到最优解;
2. 对于复杂、高维的搜索空间有较好的鲁棒性;
3. 对于高代价的函数优化更加有效;
4. 能够很好地平衡探索(Exploration)和利用(Exploitation)。
- 缺点:
1. 对于高维度的搜索空间来说,计算复杂度较高;
2. 在已有数据量较小的情况下,容易受到数据噪声的影响;
3. 对于具有大量局部最优解的问题可能陷入局部最优解。
**相关应用:**
1. 超参数优化:机器学习中的超参数优化是贝叶斯优化的常见应用领域,能够有效地提高模型效果;
2. 自动化机器学习:自动机器学习中的自动调参、自动特征选择等过程可以利用贝叶斯优化来提高效率;
3. 化学工程:在化学反应优化中,可以利用贝叶斯优化来减少实验次数,降低成本;
4. 计算机网络:网络资源动态分配、自适应控制等方面也可以应用贝叶斯优化算法。
总之,贝叶斯优化算法是一种强大的优化方法,能够在高维度、非凸函数等复杂情况下高效地寻找最优解,为许多领域的问题提供了有效的解决方案。
下面是使用 Python 和 MATLAB 实现贝叶斯优化算法来优化 SVM 超参数的简单示例代码:
Python 代码示例:
from sklearn.model_selection import cross_val_score
from sklearn import svm
from bayes_opt import BayesianOptimization
# 超参数优化的目标函数
def svm_cv(C, gamma):
clf = svm.SVC(C=C, gamma=gamma)
scores = cross_val_score(clf, X_train, y_train, cv=5)
return scores.mean()
# 定义超参数搜索空间
pbounds = {'C': (1, 100), 'gamma': (0.001, 1)}
# 实例化贝叶斯优化对象
optimizer = BayesianOptimization(f=svm_cv, pbounds=pbounds, random_state=1)
# 运行优化过程
optimizer.maximize(init_points=5, n_iter=10)
# 输出最优超参数值
print(optimizer.max)
在这个示例中,首先定义了一个交叉验证函数 svm_cv,该函数将 SVM 的超参数 C 和 gamma 作为输入,返回交叉验证的平均得分。然后设定超参数搜索空间 pbounds,实例化了一个贝叶斯优化对象并通过 maximize() 方法执行优化过程,最后输出最优的超参数值。
MATLAB 代码示例:
% 加载数据集
load fisheriris
X_train = meas;
y_train = species;
% 定义目标函数
fun = @(x) svm_cv(x.C, x.gamma, X_train, y_train);
% 设置超参数搜索范围
lb = [1, 0.001];
ub = [100, 1];
% 使用基于高斯过程的贝叶斯优化
options = optimoptions('bayesopt', 'PlotFcn', 'bayesoptplot');
results = bayesopt(fun, lb, ub, 'IsObjectiveDeterministic', true, 'Options', options);
% 输出最优超参数值
best_params = results.XAtMinObjective;
disp(['Best C value: ', num2str(best_params.C)]);
disp(['Best gamma value: ', num2str(best_params.gamma)]);
function score = svm_cv(C, gamma, X_train, y_train)
mdl = fitcsvm(X_train, y_train, 'KernelFunction', 'rbf', 'BoxConstraint', C, 'KernelScale', gamma);
score = mean(crossval('mcr', X_train, y_train, 'Predfun', mdl));
end
在这个 MATLAB 示例中,首先加载了示例数据集 iris,然后定义了目标函数 svm_cv,该函数接受超参数 C 和 gamma 作为输入,并返回 SVM 的交叉验证得分。随后设置了超参数搜索范围,并使用 bayesopt 函数执行贝叶斯优化过程,最后输出最优的超参数值。
以上是贝叶斯优化算法优化 SVM 超参数的简单示例代码,可以根据实际情况对代码进行调整和扩展。
相关文章:
及其Python 和 MATLAB 实现)
贝叶斯优化算法(Bayesian Optimization)及其Python 和 MATLAB 实现
贝叶斯优化算法(Bayesian Optimization)是一种基于贝叶斯统计理论的优化方法,通常用于在复杂搜索空间中寻找最优解。该算法能够有效地在未知黑盒函数上进行优化,并在相对较少的迭代次数内找到较优解,因此在许多领域如超…...

NLP - 基于bert预训练模型的文本多分类示例
项目说明 项目名称 基于DistilBERT的标题多分类任务 项目概述 本项目旨在使用DistilBERT模型对给定的标题文本进行多分类任务。项目包括从数据处理、模型训练、模型评估到最终的API部署。该项目采用模块化设计,以便于理解和维护。 项目结构 . ├── bert_dat…...

数据库备份和还原
一、备份 备份类型 1.完全备份 全备份是指对整个数据集进行完整备份。每次备份都会复制所有选定的数据,无论这些数据是否发生了变化。 2.增量备份 增量备份是指仅备份自上次备份(无论是全备份还是增量备份)以来发生变化的数据。它记录了…...
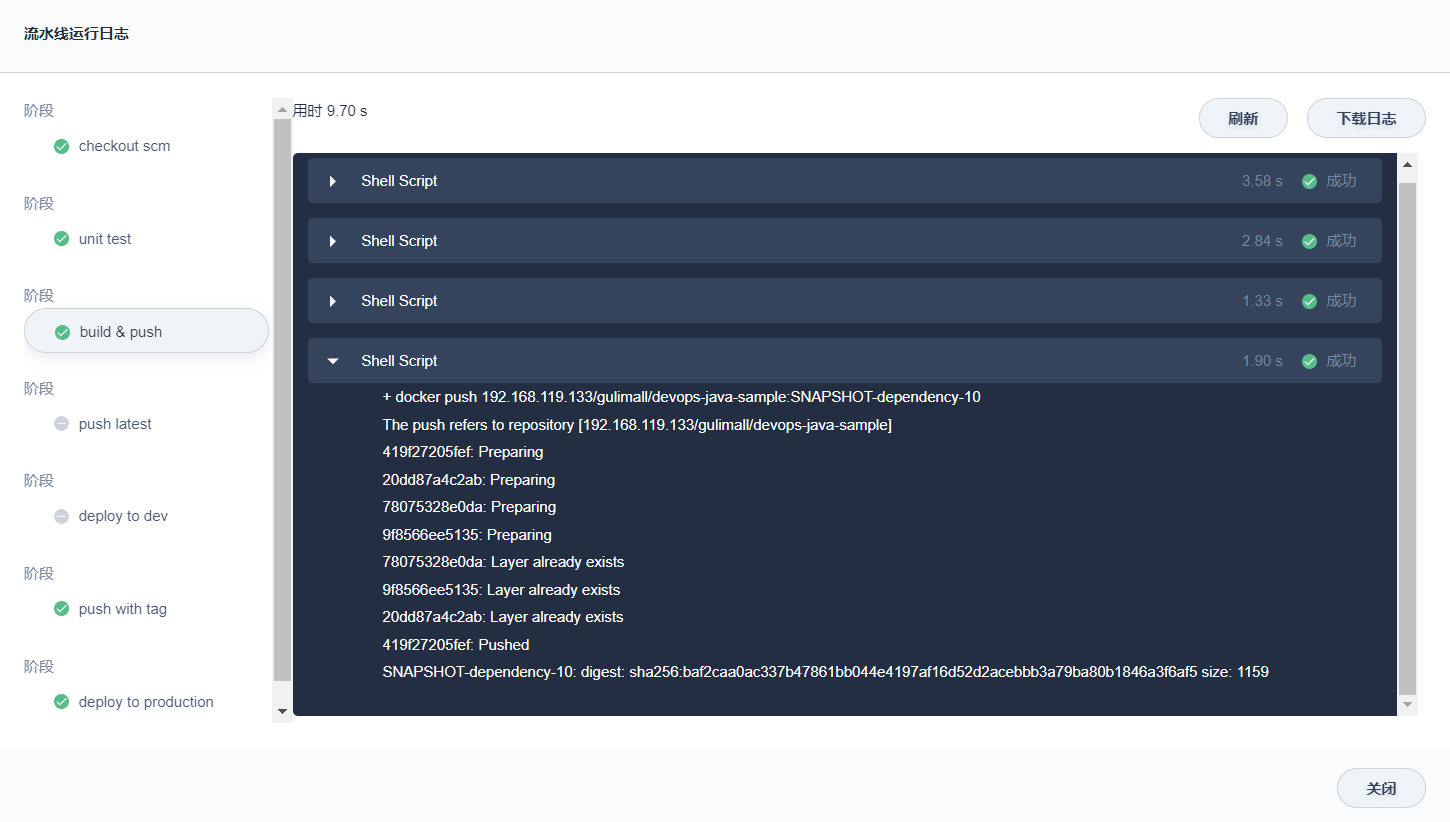
谷粒商城-个人笔记(集群部署篇一)
前言 学习视频:Java项目《谷粒商城》架构师级Java项目实战,对标阿里P6-P7,全网最强学习文档: 谷粒商城-个人笔记(基础篇一)谷粒商城-个人笔记(基础篇二)谷粒商城-个人笔记(基础篇三)谷粒商城-个人笔记(高级篇一)谷粒商城-个…...

Linux环境下的字节对齐现象
在Linux环境下,字节对齐是指数据在内存中的存储方式。字节对齐是为了提高内存访问的效率和性能。 在Linux中,默认情况下,结构体和数组的成员会进行字节对齐。具体的对齐方式可以通过编译器选项来控制。 在使用C语言编写程序时,可…...
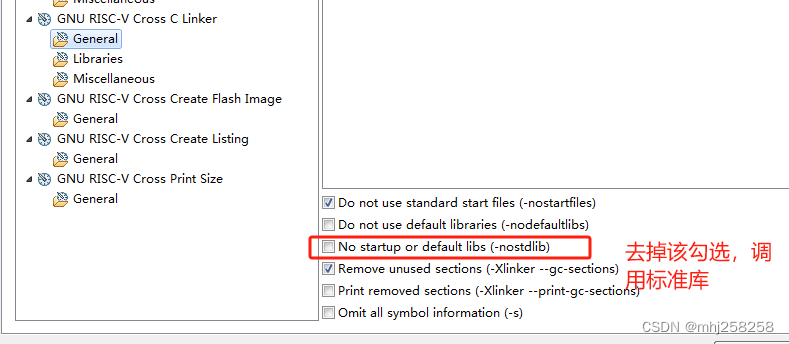
没有调用memcpy却报了undefined reference to memcpy错误
现象 在第5行出现了,undefined reference to memcpy’ 1 static void printf_x(unsigned int val) 2{ 3 char buffer[32]; 4 const char lut[]{0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F}; 5 char *p buffer; 6 while (val || p buffer) { 7 *(p) …...

import和require的区别
import是ES6标准中的模块化解决方案,require是node中遵循CommonJS规范的模块化解决方案。 后者支持动态引入,也就是require(${path}/xx.js),前者目前不支持,但是已有提案。 前者是关键词,后者不是。 前者是编译时加…...

白骑士的Python教学高级篇 3.3 数据库编程
系列目录 上一篇:白骑士的Python教学高级篇 3.2 网络编程 SQL基础 Structured Query Language (SQL) 是一种用于管理和操作关系型数据库的标准语言。SQL能够执行各种操作,如创建、读取、更新和删除数据库中的数据(即CRUD操作)&a…...

macOS 安装redis
安装Redis在macOS上通常通过Homebrew进行,Homebrew是macOS上一个流行的包管理器。以下是安装Redis的步骤: 一 使用Homebrew安装Redis 1、安装Homebrew(如果尚未安装): 打开终端(Terminal)并执…...
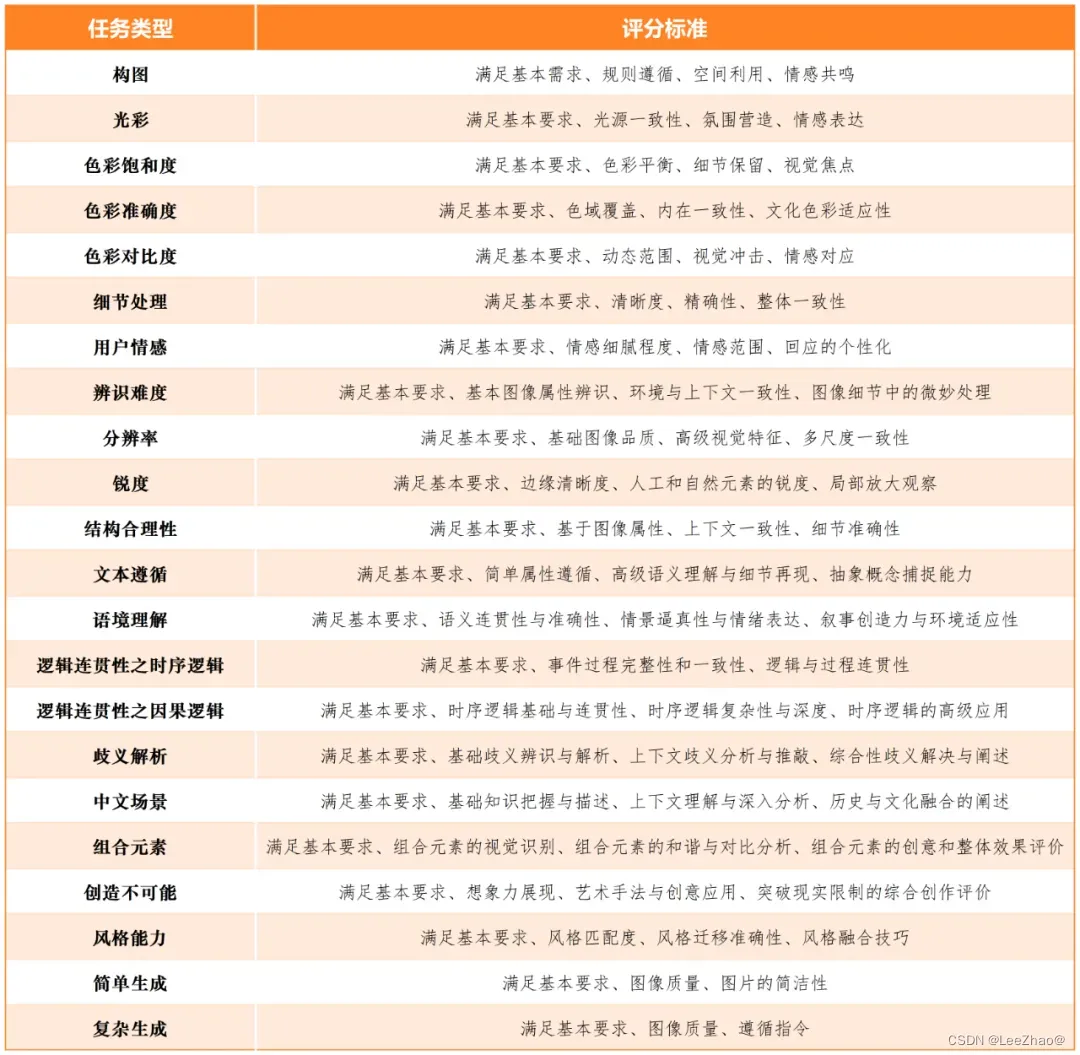
【AIGC评测体系】大模型评测指标集
大模型评测指标集 (☆)SuperCLUE(1)SuperCLUE-V(中文原生多模态理解测评基准)(2)SuperCLUE-Auto(汽车大模型测评基准)(3)AIGVBench-T2…...

工厂模式之简单工厂模式
文章目录 工厂模式工厂模式分为工厂模式的角色简单工厂模式案例代码定义一个父类,三个子类定义简单工厂客户端使用输出结果 工厂模式 工厂模式属于创造型的模式,用于创建对象。 工厂模式分为 简单工厂模式:定义一个简单工厂类,根…...

2.(vue3.x+vite)调用iframe的方法(vue编码)
1、效果预览 2.编写代码 (1)主页面 <template><div><button @click="sendMessage">调用iframe,并发送信息...

实战项目——用Java实现图书管理系统
前言 首先既然是管理系统,那咱们就要实现以下这几个功能了--> 分析 1.首先是用户分为两种,一个是管理员,另一个是普通用户,既如此,可以定义一个用户类(user),在定义管理员类&am…...

利用DeepFlow解决APISIX故障诊断中的方向偏差问题
概要:随着APISIX作为IT应用系统入口的普及,其故障定位能力的不足导致了在业务故障诊断中,APISIX常常成为首要的“嫌疑对象”。这不仅导致了“兴师动众”式的资源投入,还可能使诊断方向“背道而驰”,从而导致业务故障“…...

sqlalchemy获取数据条数
1、sqlalchemy获取数据条数 在SQLAlchemy中,你可以使用count()函数来获取数据表中的记录条数。 from sqlalchemy import create_engine, MetaData, Table# 数据库连接字符串 DATABASE_URI = dialect+driver://username:password@host:port/database# 创建引擎 engine = crea…...
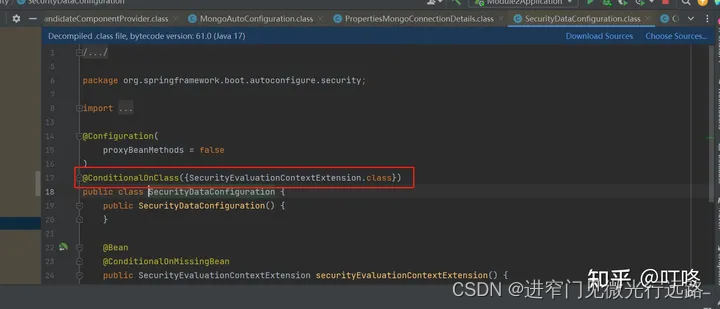
SpringBoot的自动配置核心原理及拓展点
Spring Boot 的核心原理几个关键点 约定优于配置: Spring Boot 遵循约定优于配置的理念,通过预定义的约定,大大简化了 Spring 应用程序的配置和部署。例如,它自动配置了许多常见的开发任务(如数据库连接、Web 服务器配…...

用随机森林算法进行的一次故障预测
本案例将带大家使用一份开源的S.M.A.R.T.数据集和机器学习中的随机森林算法,来训练一个硬盘故障预测模型,并测试效果。 实验目标 掌握使用机器学习方法训练模型的基本流程;掌握使用pandas做数据分析的基本方法;掌握使用scikit-l…...
24位DAC转换的FPGA设计及将其封装成自定义IP核的方法
在vivado设计中,为了方便的使用Block Desgin进行设计,可以使用vivado软件把自己编写的代码封装成IP核,封装后的IP核和原来的代码具有相同的功能。本文以实现24位DA转换(含并串转换,使用的数模转换器为CL4660)为例,介绍VIVADO封装IP核的方法及调用方法,以及DAC转换的详细…...
【大模型LLM面试合集】大语言模型基础_llm概念
1.llm概念 1.目前 主流的开源模型体系 有哪些? 目前主流的开源LLM(语言模型)模型体系包括以下几个: GPT(Generative Pre-trained Transformer)系列:由OpenAI发布的一系列基于Transformer架构…...

Qt时间日期处理与定时器使用总结
一、日期时间数据 1.QTime 用于存储和操作时间数据的类,其中包括小时(h)、分钟(m)、秒(s)、毫秒(ms)。函数定义如下: //注:秒(s)和毫秒(ms)有默认值0 QTime::QTime(int h, int m, int s 0, int ms 0) 若无须初始化时间数据,可…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

2026年,揭秘那些真正安全的原生态食材厂家你不可不知的秘密
随着人们生活水平的提升以及对健康的日益重视,选择真正安全的原生态食材已经成为许多人购买食物的标准。但市场的繁杂使得甄别真正安全的食材厂家变得愈加困难。今天,我将通过几个关键角度,为大家揭秘那些真正安全的原生态食材厂家的秘密&…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

基于Meshtastic构建LoRa Mesh网络:从硬件自制到传感器集成实战
1. 项目概述:构建一个灵活且易用的LoRa Mesh网络 如果你对物联网、远程传感或者去中心化通信网络感兴趣,那么LoRa技术一定不会陌生。它以其超低功耗、超远距离和强大的抗干扰能力,成为了构建广域传感网络的理想选择。然而,传统的…...

从《吃豆人》到开放世界:聊聊Unity Navigation里Agent Radius和Cost的那些‘潜规则’
从《吃豆人》到开放世界:Unity Navigation中Agent Radius与Cost的隐藏逻辑1980年诞生的《吃豆人》用简单的迷宫路径定义了早期游戏AI的移动规则——幽灵们沿着固定路线巡逻,遇到转角时随机选择方向。这种设计在当时堪称革命性,但以今天的标准…...

昇腾CANN elec-ops-simulation 实战:电力系统仿真——潮流计算与暂态稳定分析在 NPU 上的加速
电力系统仿真:500 节点电网的牛顿-拉夫逊潮流计算 → 解 10001000 稀疏雅可比矩阵(每迭代 1 次矩阵求逆)→ CPU 迭代 15 次 2.4s。实时调度要求 < 100ms → NPU 加速:雅可比矩阵求解用 Cube 单元做批量小矩阵 LU 分解 → 每迭…...

DSP、FPGA、STM32大对决:谁才是嵌入式开发的“天选之子”?
在嵌入式开发的广阔天地里,DSP、FPGA 和 STM32(作为通用 MCU 的典型代表)可以说是三款绕不开的核心处理器。很多初学者甚至有一定经验的工程师在选择时都会陷入纠结:我的项目到底该选哪一个?为了帮你彻底理清思路&…...

5分钟掌握文件完整性验证:HashCalculator终极免费批量哈希计算工具指南
5分钟掌握文件完整性验证:HashCalculator终极免费批量哈希计算工具指南 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/…...

利用Taotoken多模型聚合能力为AIGC应用提供备选方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken多模型聚合能力为AIGC应用提供备选方案 在构建AIGC内容生成应用时,开发者通常会选择一个主流模型作为服务…...
)
保姆级教程:用Prometheus Operator在K8S里一键搞定监控全家桶(附Grafana仪表盘)
云原生监控革命:用Prometheus Operator构建K8S智能监控体系 当Kubernetes集群规模突破50个节点时,传统监控方案的维护成本会呈指数级增长。我曾亲眼见证一个电商团队在"黑五"大促期间,因为手动配置的Prometheus抓取规则失效&#x…...