240703_昇思学习打卡-Day15-K近邻算法实现红酒聚类
KNN(K近邻)算法实现红酒聚类
K近邻算法,是有监督学习中的分类算法,可以用于分类和回归,本篇主要讲解其在分类上的用途。
文章目录
- KNN(K近邻)算法实现红酒聚类
- 算法原理
- 数据下载
- 数据读取与处理
- 模型构建--计算距离
- 模型预测
算法原理
KNN算法虽然是机器学习算法,但是他不学习,他的原理是把所有的训练集都存储下来,在测试的时候把测试集放到原图里面,根据测试点和训练集的距离判定属于的类别。如下图示例,假设我们现在有两个类别,分别是A和B,用三角和圆圈(不太圆见谅)表示,我们把这两种类别都画在坐标系中。此时载入一个未知类别方框,我们的KNN算法就开始了。

首先我们要指定一个K值,K值就是距离值,比如我们先指定K=2,就可以在这个位置类别周围画一个圆(可以理解为半径为2),如下图:
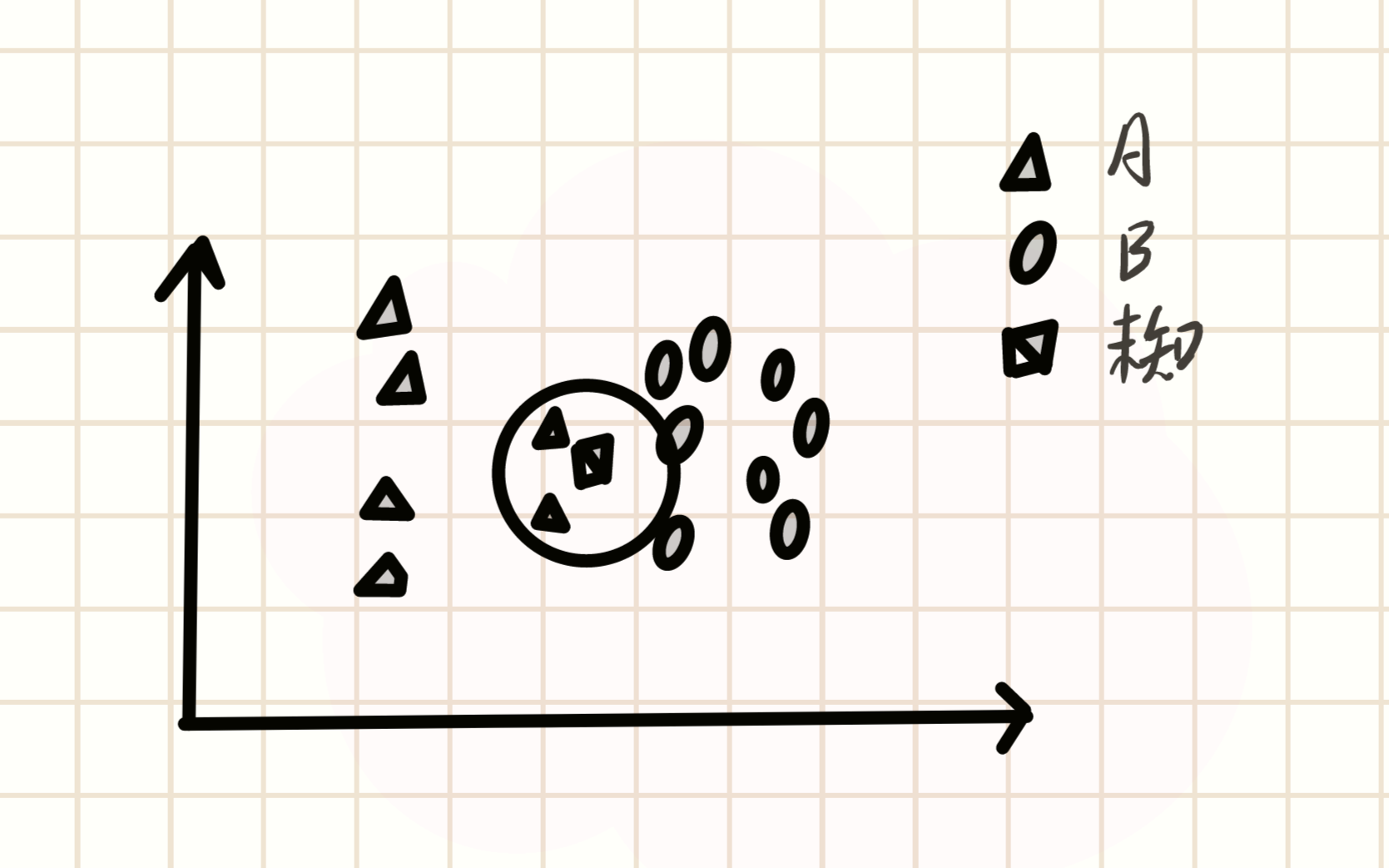
此时我们这个圆框进去了两个A类别,根据算法原理,此时就会把这个未知类别判断为A类别。而如果我们扩大K值呢

当我们把K值从2扩大到4时(小圆外面的大圆),可以看到,此时包进来了4个B类别值,A类别值仍然只有2个,此时就会判断为B类别。这个算法有一点划地盘的意思,画个圈,这圈里谁人多,你就跟谁走,是这意思。歪理原理就这么结束了,下面让我们看看正经的解释。
K近邻算法(K-Nearest-Neighbor, KNN)是一种用于分类和回归的非参数统计方法,最初由 Cover和Hart于1968年提出(Cover等人,1967),是机器学习最基础的算法之一。它正是基于以上思想:要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本,统计出这些样本的类别并进行投票,票数最多的那个类就是分类的结果。KNN的三个基本要素:
- K值,一个样本的分类是由K个邻居的“多数表决”确定的。K值越小,容易受噪声影响,反之,会使类别之间的界限变得模糊。
- 距离度量,反映了特征空间中两个样本间的相似度,距离越小,越相似。常用的有Lp距离(p=2时,即为欧式距离)、曼哈顿距离、海明距离等。
- 分类决策规则,通常是多数表决,或者基于距离加权的多数表决(权值与距离成反比)。
预测算法(分类)的流程如下:
(1)在训练样本集中找出距离待测样本x_test最近的k个样本,并保存至集合N中;
(2)统计集合N中每一类样本的个数𝐶𝑖,𝑖=1,2,3,…,𝑐𝐶𝑖,𝑖=1,2,3,…,𝑐;
(3)最终的分类结果为argmax𝐶𝑖𝐶𝑖 (最大的对应的𝐶𝑖𝐶𝑖)那个类。
在上述实现过程中,k的取值尤为重要。它可以根据问题和数据特点来确定。在具体实现时,可以考虑样本的权重,即每个样本有不同的投票权重,这种方法称为带权重的k近邻算法,它是一种变种的k近邻算法。
数据下载
我们使用Wine数据集进行展示,Wine数据集的官网:Wine Data Set,这个数据集是对同一地区三个不同品种的葡萄酒进行化学分析后记录的结果。数据集分析了三种葡萄酒中每种所含13种成分的量。这些13种属性是
- Alcohol,酒精
- Malic acid,苹果酸
- Ash,灰
- Alcalinity of ash,灰的碱度
- Magnesium,镁
- Total phenols,总酚
- Flavanoids,类黄酮
- Nonflavanoid phenols,非黄酮酚
- Proanthocyanins,原花青素
- Color intensity,色彩强度
- Hue,色调
- OD280/OD315 of diluted wines,稀释酒的OD280/OD315
- Proline,脯氨酸
可以采用两种下载方式:
- 方式一,从Wine数据集官网下载wine.data文件。
- 方式二,从华为云OBS中下载wine.data文件。
此时我们默认已经安装了Mindspore环境,采用从华为云OBS中下载数据集
from download import download# 下载红酒数据集
url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
path = download(url, "./", kind="zip", replace=True)
数据读取与处理
数据下载下来了,我们就进行读取和预处理呗。
%matplotlib inline
import os
import csv
import numpy as np
import matplotlib.pyplot as pltimport mindspore as ms
from mindspore import nn, opsms.set_context(device_target="CPU")
with open('wine.data') as csv_file:data = list(csv.reader(csv_file, delimiter=','))
print(data[56:62]+data[130:133])
执行完这几行代码后我们会打印出来部分数据进行查看,比如我这里打印出这样的数据

此时最开始的每个list最开始的第一个数都是1或2或3,这就是葡萄酒的三种类别,后面紧跟着的13个参数就是他的13种化学成分。
取三类样本(共178条),将数据集的13个属性作为自变量X,将数据集的3个类别作为因变量Y。此时X和Y的值可以自行打印查看
X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
Y = np.array([s[0] for s in data[:178]], np.int32)
取样本的某两个属性进行2维可视化,可以看到在某两个属性上样本的分布情况以及可分性。
attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols','Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue','OD280/OD315 of diluted wines', 'Proline']
plt.figure(figsize=(10, 8))
for i in range(0, 4):plt.subplot(2, 2, i+1)# 选择的化学成分由循环轮数i决定a1, a2 = 2 * i, 2 * i + 1# 选择前59个类别为1的数据,化学成分选a1和a2类plt.scatter(X[:59, a1], X[:59, a2], label='1')plt.scatter(X[59:130, a1], X[59:130, a2], label='2')plt.scatter(X[130:, a1], X[130:, a2], label='3')plt.xlabel(attrs[a1])plt.ylabel(attrs[a2])plt.legend()
plt.show()
这里执行完了就可以看到四张打印出来的图,就体现了每一类葡萄酒其中两种化学成分的关系
将数据集按128:50划分为训练集(已知类别样本)和验证集(待验证样本):
train_idx = np.random.choice(178, 128, replace=False)
test_idx = np.array(list(set(range(178)) - set(train_idx)))
X_train, Y_train = X[train_idx], Y[train_idx]
X_test, Y_test = X[test_idx], Y[test_idx]
模型构建–计算距离
利用MindSpore提供的tile, square, ReduceSum, sqrt, TopK等算子,通过矩阵运算的方式同时计算输入样本x和已明确分类的其他样本X_train的距离,并计算出top k近邻
class KnnNet(nn.Cell):def __init__(self, k):super(KnnNet, self).__init__()self.k = kdef construct(self, x, X_train):#平铺输入x以匹配X_train中的样本数x_tile = ops.tile(x, (128, 1))square_diff = ops.square(x_tile - X_train)square_dist = ops.sum(square_diff, 1)dist = ops.sqrt(square_dist)#-dist表示值越大,样本就越接近values, indices = ops.topk(-dist, self.k)return indicesdef knn(knn_net, x, X_train, Y_train):x, X_train = ms.Tensor(x), ms.Tensor(X_train)indices = knn_net(x, X_train)topk_cls = [0]*len(indices.asnumpy())for idx in indices.asnumpy():topk_cls[Y_train[idx]] += 1cls = np.argmax(topk_cls)return cls
模型预测
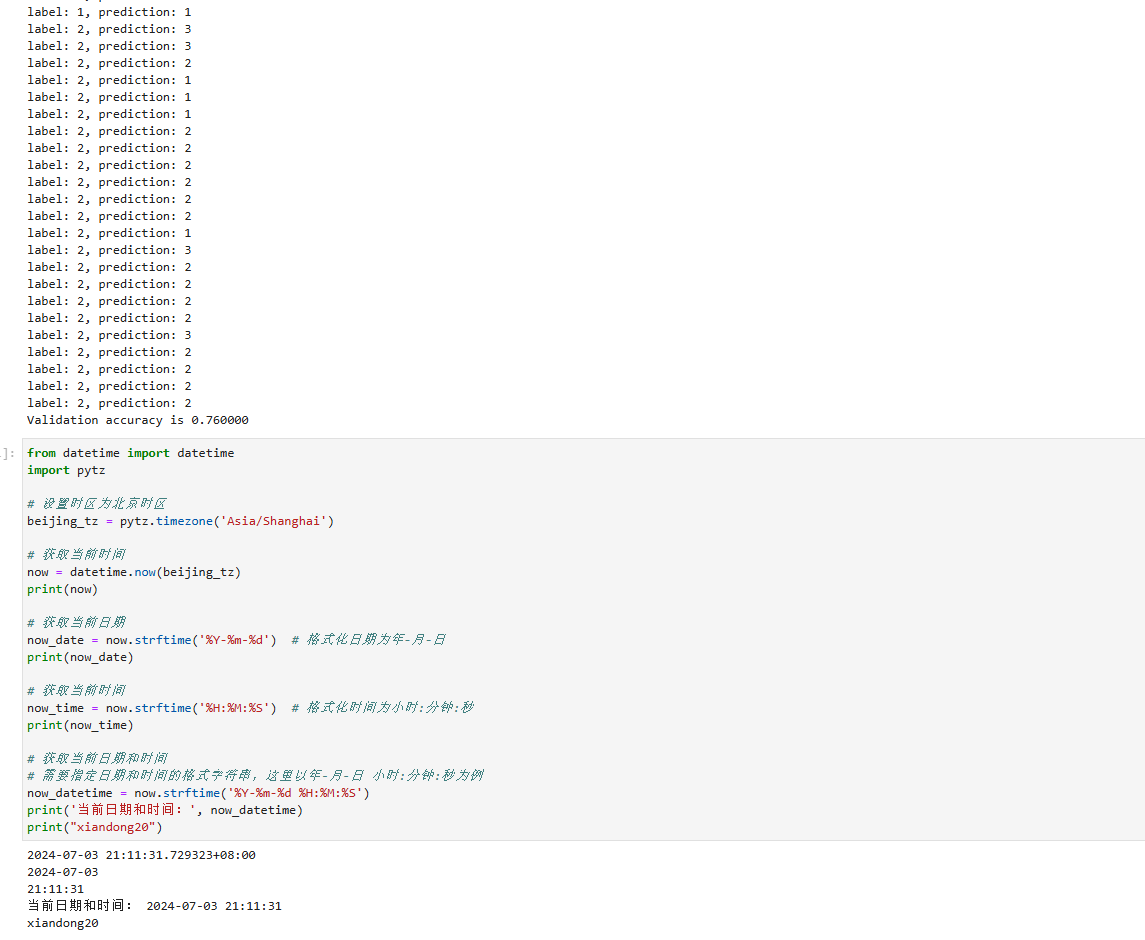
在验证集上验证KNN算法的有效性,取𝑘=5𝑘=5,验证精度接近80%,说明KNN算法在该3分类任务上有效,能根据酒的13种属性判断出酒的品种。
acc = 0
knn_net = KnnNet(5)
for x, y in zip(X_test, Y_test):pred = knn(knn_net, x, X_train, Y_train)acc += (pred == y)print('label: %d, prediction: %s' % (y, pred))
print('Validation accuracy is %f' % (acc/len(Y_test)))
打卡图片:
相关文章:
240703_昇思学习打卡-Day15-K近邻算法实现红酒聚类
KNN(K近邻)算法实现红酒聚类 K近邻算法,是有监督学习中的分类算法,可以用于分类和回归,本篇主要讲解其在分类上的用途。 文章目录 KNN(K近邻)算法实现红酒聚类算法原理数据下载数据读取与处理模型构建--计算距离模型预测 算法原理 KNN算法虽…...
keil5模拟 仿真 报错没有读写权限
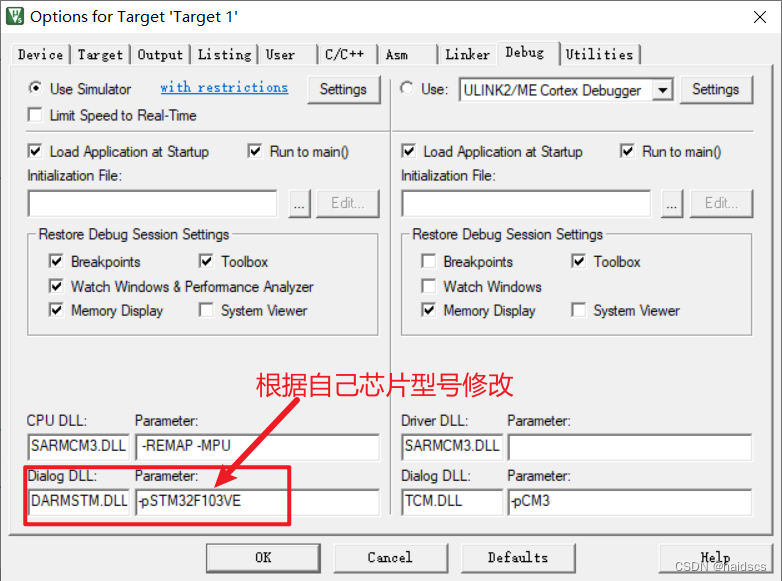
debug*** error 65: access violation at 0x4002100C : no write permission 修改为: Dialog DLL默认是DCM3.DLL Parameter默认是-pCM3 应改为 Dialog DLL默认是DARMSTM.DLL Parameter默认是-pSTM32F103VE...
)
力扣爆刷第158天之TOP100五连刷56-60(子集、最小栈、最长有效括号)
力扣爆刷第158天之TOP100五连刷56-60(子集、最小栈、最长有效括号) 文章目录 力扣爆刷第158天之TOP100五连刷56-60(子集、最小栈、最长有效括号)一、78. 子集二、105. 从前序与中序遍历序列构造二叉树三、43. 字符串相乘四、155. …...

高薪程序员必修课-Java中 Synchronized锁的升级过程
目录 前言 锁的升级过程 1. 偏向锁(Biased Locking) 原理: 示例: 2. 轻量级锁(Lightweight Locking) 原理: 示例: 3. 重量级锁(Heavyweight Locking)…...

Vue项目打包上线
Nginx 是一个高性能的开源HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP代理服务器。它在设计上旨在处理高并发的请求,是一个轻量级、高效能的Web服务器和反向代理服务器,广泛用于提供静态资源、负载均衡、反向代理等功能。 1、下载nginx 2、…...

算法题中常用的C++功能
文章目录 集合优先队列双端队列排序时自定义比较函数最大数值字符串追加:删除:子串: 元组vector查找创建和初始化赋值: 字典map引入头文件定义和初始化插入元素访问元素更新元素删除元素检查元素存在遍历元素int和string转换 集合…...

左扰动和右扰动
在SLAM(Simultaneous Localization and Mapping)中,使用左扰动还是右扰动主要取决于你如何定义坐标系和你希望扰动影响的姿态表示。这通常与你的坐标系选择和你正在解决的具体问题有关。 左扰动通常用于以下情况: 当你使用局部坐…...

【计算机网络】期末复习(2)
目录 第一章:概述 第二章:物理层 第三章:数据链路层 第四章:网络层 第五章:传输层 第一章:概述 三大类网络 (1)电信网络 (2)有线电视网络 ࿰…...

ojdbc8-full Oracle JDBC 驱动程序的一个完整发行版各文件的功能
文章目录 1. ojdbc8.jar2. ons.jar -3. oraclepki.jar -4. orai18n.jar -5. osdt_cert.jar -6. osdt_core.jar -7. ojdbc.policy -8. README.txt -9. simplefan.jar -10. ucp.jar -11. xdb.jar - ojdbc8-full 是 Oracle JDBC 驱动程序的一个完整发行版,包含了连接和…...
,可能会遇到表被锁定的问题。)
在Linux环境下使用sqlite3时,如果尝试对一个空表进行操作(例如插入数据),可能会遇到表被锁定的问题。
在Linux环境下使用sqlite3时,如果尝试对一个空表进行操作(例如插入数据),可能会遇到表被锁定的问题。这通常是因为sqlite3在默认情况下会对空表进行“延迟创建”,即在实际需要写入数据之前,表不会被真正创建…...

【目标检测】DINO
一、引言 论文: DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection 作者: IDEA 代码: DINO 注意: 该算法是在Deformable DETR、DAB-DETR、DN-DETR基础上的改进,在学习该算法前&#…...
一文包学会ElasticSearch的大部分应用场合
ElasticSearch 官网下载地址:Download Elasticsearch | Elastic 历史版本下载地址1:Index of elasticsearch-local/7.6.1 历史版本下载地址2:Past Releases of Elastic Stack Software | Elastic ElasticSearch的安装(windows) 安装前所…...

创建kobject
1、kobject介绍 kobject的全称是kernel object,即内核对象。每一个kobject都会对应系统/sys/下的一个目录。 2、相关结构体和api介绍 2.1 struct kobject // include/linux/kobject.h 2.2 kobject_create_and_add kobject_create_and_addkobject_createkobj…...

数据结构 - C/C++ - 树
公开视频 -> 链接点击跳转公开课程博客首页 -> 链接点击跳转博客主页 目录 树的概念 结构特性 树的样式 树的存储 树的遍历 节点增删 二叉搜索树 平衡二叉树 树的概念 二叉树是树形结构,是一种非线性结构。 非线性结构:在二叉树中&#x…...
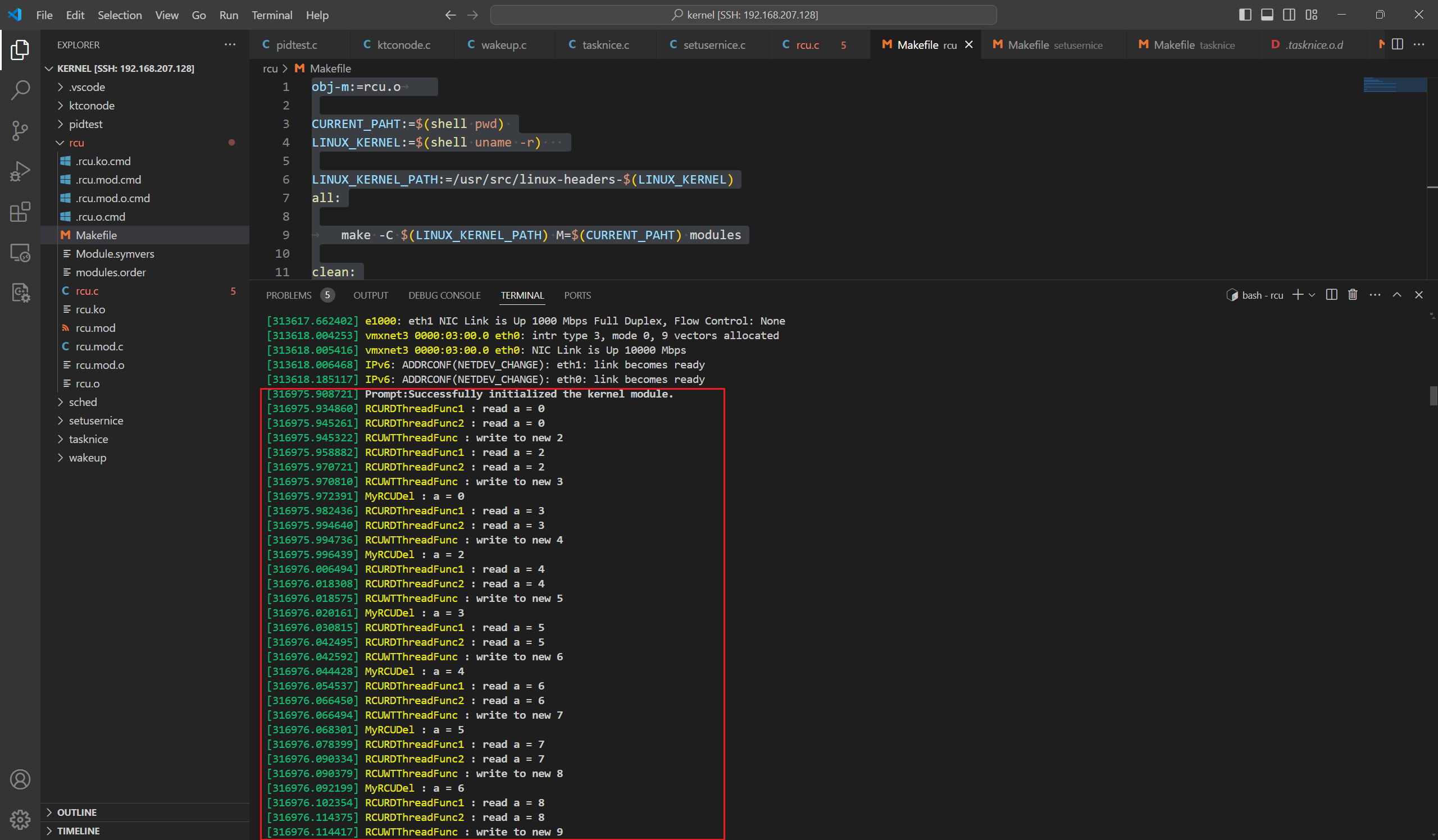
Linux源码阅读笔记12-RCU案例分析
在之前的文章中我们已经了解了RCU机制的原理和Linux的内核源码,这里我们要根据RCU机制写一个demo来展示他应该如何使用。 RCU机制的原理 RCU(全称为Read-Copy-Update),它记录所有指向共享数据的指针的使用者,当要修改构想数据时&…...

【C++】双线性差值算法实现RGB图像缩放
双线性差值算法 双线性插值(Bilinear Interpolation)并不是“双线性差值”,它是一种在二维平面上估计未知数据点的方法,通常用于图像处理中的图像缩放。 双线性插值的基本思想是:对于一个未知的数据点,我…...
计算机网络知识普及之四元组
在涉及到TCP/UDP等IP类通信协议时,存在四元组概念 这里只是普及使用 先来一些前置知识,什么是IP协议? IP协议全称为互联网协议,处于网络层中,主要作用是标识网络中的设备,每个设备的IP地址是唯一的。 在网…...

深度探讨网络安全:挑战、防御策略与实战案例
目录 编辑 一、引言 二、网络安全的主要挑战 恶意软件与病毒 数据泄露 分布式拒绝服务攻击(DDoS) 内部威胁 三、防御策略与实战案例 恶意软件防护 网络钓鱼防护 数据泄露防护 总结 一、引言 随着信息技术的迅猛发展,网络安全问…...

“穿越时空的机械奇观:记里鼓车的历史与科技探秘“
在人类文明的发展历程中,科技的创新与进步不仅仅推动了社会的进步,也为我们留下了丰富的文化遗产。记里鼓车,作为一种古老的里程计量工具,其历史地位和技术成就在科技史上具有重要的意义。本文将详细介绍记里鼓车的起源、结构原理…...

DevOps CMDB平台整合Jira工单
背景 在DevOps CMDB平台建设的过程中,我们可以很容易的将业务应用所涉及的云资源(WAF、K8S、虚拟机等)、CICD工具链(Jenkins、ArgoCD)、监控、日志等一次性的维护到CMDB平台,但随着时间的推移,…...

PostgreSQL CASE语句深度解析:性能、类型与NULL安全实战指南
1. 为什么你必须真正吃透 PostgreSQL 的 CASE 语句——它远不止是 SQL 里的“if-else”翻译器在 PostgreSQL 实战中,我见过太多人把CASE当成一个语法糖:写几个WHEN...THEN,加个ELSE,再套个END,就以为搞定了。结果呢&am…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

LPCM框架:大模型驱动的计算机架构设计革命
1. LPCM框架:计算机系统架构设计的范式革命计算机系统架构设计正站在历史性的转折点上。过去八十年来,从ENIAC的真空管到现代7纳米制程的异构计算芯片,架构设计始终遵循着"专家经验EDA工具"的传统范式。但随着摩尔定律逼近物理极限…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...

ubuntu环境下为python项目配置taotoken多模型api密钥与端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu环境下为Python项目配置Taotoken多模型API密钥与端点 1. 准备工作 在Ubuntu系统上为Python项目接入Taotoken,首…...

终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题
终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 你是否还在为Windows…...