Geoserver源码解读五 Catalog
系列文章目录
Geoserver源码解读一 环境搭建
Geoserver源码解读二 主入口
Geoserver源码解读三 GeoServerBasePage
Geoserver源码解读四 REST服务
Geoserver源码解读五 Catalog
目录
系列文章目录
前言
一、定义
二、前置知识点
1.Spring 的 Bean 生命周期
ApplicationContextAware
BeanPostProcessor
三、常见用法
四、结构梳理
1.查询工作空间
2.资源读取
五、总结
前言
Catalog数据目录是 Geoserver比较核心的内容,理解Catalog对理解Geoserver的存储机制有很大帮助,夸张点儿说就是,理解了它的逻辑就相当于理解了geoserver的逻辑。本文同样以工作空间为例梳理下它的相关逻辑。
一、定义
GeoServer 的配置形成一个目录,包括工作空间、数据源、图层、样式等。实际上就是一堆文件夹和文本文件(充当的是文件型数据库的作用)。
二、前置知识点
1.Spring 的 Bean 生命周期
Spring 的 Bean 生命周期是指从 Bean 被创建到销毁的整个过程。这个过程包括多个阶段,每个阶段都可以通过不同的方式进行自定义,在 Spring 容器启动时,它会读取配置元数据(如 XML、注解或 Java 配置),解析这些元数据,并将定义的 Bean 注册到容器中。
ApplicationContextAware
Spring 的 ApplicationContextAware 用于标记那些需要知道当前 Spring 应用上下文(ApplicationContext)的 Bean。当一个 Bean 实现 ApplicationContextAware 接口时,它可以在 Bean 的生命周期中访问和操作当前的 ApplicationContext,也就是说它的执行顺序早于Bean 的生命周期
BeanPostProcessor
Spring 的 BeanPostProcessor 允许你在 Bean 的初始化前后添加自定义逻辑。这个接口定义了两个方法,分别在 Bean 初始化之前和之后被调用。
postProcessBeforeInitialization(Object bean, String beanName): 在 Bean 的初始化方法(如afterPropertiesSet或自定义的init-method)之前被调用。postProcessAfterInitialization(Object bean, String beanName): 在 Bean 的初始化方法之后被调用
举个栗子说明
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.BeanFactory;
import org.springframework.beans.factory.BeanFactoryAware;
import org.springframework.beans.factory.BeanNameAware;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;public class MyBean implements BeanNameAware, BeanFactoryAware, ApplicationContextAware,InitializingBean, DisposableBean {private ApplicationContext applicationContext;// 1.这个最先被执行@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {this.applicationContext = applicationContext;System.out.println("ApplicationContextAware: Application context is set");}// 2.这个第二被执行@Overridepublic Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {System.out.println("Before initialization of bean: " + beanName);return bean; // 可以返回原始的 Bean 或包装后的 Bean}// 4. 这个第四@Overridepublic void afterPropertiesSet() throws Exception {System.out.println("InitializingBean: Bean properties are set");}// 3. 这个第三public void initMethod() {System.out.println("Custom init method: Bean is initializing");}// 5. 这个第五public void destroyMethod() {System.out.println("Custom destroy method: Bean is being destroyed");}
}
<bean id="myBean" class="com.example.MyBean" init-method="initMethod" destroy-method="destroyMethod">
</bean>对Spring Bean生命周期的掌握。方便了解分析Geoserver是怎么对资源目录进行解析的
三、常见用法
获取目录
Catalog catalog = geoServer.getCatalog();获取所有工作空间
WorkspaceInfo workspace = catalog.getWorkspaces();获取所有数据存储
List<DataStoreInfo> dataStores = catalog.getStores( DataStoreInfo.class );获取特定图层
LayerInfo layer = catalog.getLayer( "myLayer" );四、结构梳理
1.查询工作空间
查询入口
@RestController
@RequestMapping(path = RestBaseController.ROOT_PATH + "/workspaces",produces = {MediaType.APPLICATION_JSON_VALUE,MediaType.APPLICATION_XML_VALUE,MediaType.TEXT_HTML_VALUE})
public class WorkspaceController extends AbstractCatalogController {@Autowiredpublic WorkspaceController(@Qualifier("catalog") Catalog catalog) {super(catalog);}@GetMappingpublic RestWrapper workspacesGet() {List<WorkspaceInfo> wkspaces = catalog.getWorkspaces();return wrapList(wkspaces, WorkspaceInfo.class);}
}从上面代码可以看出来catalog是依赖注入进来的
<bean id="localWorkspaceCatalog" class="org.geoserver.catalog.impl.LocalWorkspaceCatalog"><constructor-arg ref="advertisedCatalog" /></bean><alias name="localWorkspaceCatalog" alias="catalog"/> 实际用到的Catalog是localWorkspaceCatalog而localWorkspaceCatalog使用了AbstractDecorator技术。这一点上一章的 四、前置知识点-AbstractDecorator 也有讲到,此处不多赘述,本质上就是定义了一个变量去直接操作父类。
public class LocalWorkspaceCatalog extends AbstractCatalogDecorator implements Catalog {public LocalWorkspaceCatalog(Catalog delegate) {super(delegate);}
}这里同样是个依赖注入,以此类推,下面的三级都是依赖注入
<bean id="rawCatalog" class="org.geoserver.catalog.impl.CatalogImpl" depends-on="configurationLock"><property name="resourceLoader" ref="resourceLoader"/> </bean><bean id="secureCatalog" class="org.geoserver.security.SecureCatalogImpl" depends-on="accessRulesDao,extensions"><constructor-arg ref="rawCatalog" /> </bean><bean id="advertisedCatalog" class="org.geoserver.catalog.impl.AdvertisedCatalog"><constructor-arg ref="secureCatalog" /><property name="layerGroupVisibilityPolicy"><bean id="org.geoserver.catalog.LayerGroupVisibilityPolicy.HIDE_NEVER" class="org.springframework.beans.factory.config.FieldRetrievingFactoryBean"/></property></bean> <bean id="localWorkspaceCatalog" class="org.geoserver.catalog.impl.LocalWorkspaceCatalog"><constructor-arg ref="advertisedCatalog" /></bean>根据上面代码可以看到,最终的生效的父类Catalog是 rawCatalog 也就是 org.geoserver.catalog.impl.CatalogImpl,从depends-on看出它的前置条件是
<bean id="configurationLock" class="org.geoserver.GeoServerConfigurationLock"/>先看下这个前置条件我替大家看过了就是一个线程锁,当两个用户同时尝试更改同一设置时,这个锁可以确保它们不会互相覆盖对方的更改。
然后再看org.geoserver.catalog.impl.CatalogImpl里面是怎么查询工作空间的
@Overridepublic List<WorkspaceInfo> getWorkspaces() {return facade.getWorkspaces();}@Overridepublic WorkspaceInfo getWorkspace(String id) {return facade.getWorkspace(id);}可以看出来catalog内部又使用了个facade,这层级套用的是真的深啊,静不下心的话根本就看不下去,再继续往下看这个facade
/** data access facade */protected CatalogFacade facade;public CatalogImpl() {setFacade(new DefaultCatalogFacade(this));dispatcher = new CatalogEventDispatcher();resourcePool = ResourcePool.create(this);}在构造函数中的给了它一个 DefaultCatalogFacade
src/main/java/org/geoserver/catalog/impl/DefaultCatalogFacade.java
继续查看DefaultCatalogFacade可以看到下面的代码
/** workspaces */protected CatalogInfoLookup<WorkspaceInfo> workspaces =new CatalogInfoLookup<>(WORKSPACE_NAME_MAPPER);@Overridepublic List<WorkspaceInfo> getWorkspaces() {return ModificationProxy.createList(new ArrayList<>(workspaces.values()), WorkspaceInfo.class);}@Overridepublic WorkspaceInfo getWorkspace(String id) {WorkspaceInfo ws = workspaces.findById(id, WorkspaceInfo.class);return wrapInModificationProxy(ws, WorkspaceInfo.class);}可以看出来DefaultCatalogFacade下面还有一层workspaces也就是CatalogInfoLookup
src/main/java/org/geoserver/catalog/impl/CatalogInfoLookup.java
这是一个内部工具类,用于在 GeoServer 的目录(catalog)中查找和存储 CatalogInfo 对象。CatalogInfo 是 GeoServer 目录中的一个接口,它代表目录中的一个信息对象,如工作空间(Workspace)、数据存储(DataStore)、覆盖范围(Coverage)等
class CatalogInfoLookup<T extends CatalogInfo> {public T add(T value) {if (Proxy.isProxyClass(value.getClass())) {ModificationProxy h = (ModificationProxy) Proxy.getInvocationHandler(value);value = (T) h.getProxyObject();}Map<Name, T> nameMap = getMapForValue(nameMultiMap, value);Name name = nameMapper.apply(value);nameMap.put(name, value);Map<String, T> idMap = getMapForValue(idMultiMap, value);return idMap.put(value.getId(), value);}public Collection<T> values() {List<T> result = new ArrayList<>();for (Map<String, T> v : idMultiMap.values()) {result.addAll(v.values());}return result;}
}从上面代码可以看出来查询出来的实际上是 idMultiMap 它的新增方法是add,到这里整个查询的逻辑基本上已经梳理到头了,但是这个idMultiMap 到底是在什么时候生成的也就是说这个add是在什么时候调用的就又是另外一条业务梳理线了
2.资源读取
上面讲到查询工作目录的时候最终到了CatalogInfoLookup的 idMultiMap ,我在add方法中打了个断点,跟踪了下进程,梳理出了下面的逻辑
首先是入口
src/main/java/applicationContext.xml
当项目起来后读取这个配置文件并初始化
<bean id="geoServerLoader" class="org.geoserver.config.GeoServerLoaderProxy"><constructor-arg ref="resourceLoader"/></bean>读到配置文件后进入Bean生命周期(上面有讲到)
public class GeoServerLoaderProxyimplements BeanPostProcessor,ApplicationListener<ContextClosedEvent>,ApplicationContextAware,GeoServerReinitializer {/** resource loader */protected GeoServerResourceLoader resourceLoader;/** the actual loader */GeoServerLoader loader;public GeoServerLoaderProxy(GeoServerResourceLoader resourceLoader) {this.resourceLoader = resourceLoader;}@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {this.loader = lookupGeoServerLoader(applicationContext);loader.setApplicationContext(applicationContext);}@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName)throws BeansException {if (loader != null) {return loader.postProcessAfterInitialization(bean, beanName);}return bean;}@Overridepublic Object postProcessBeforeInitialization(Object bean, String beanName)throws BeansException {if (loader != null) {return loader.postProcessBeforeInitialization(bean, beanName);}return bean;}protected GeoServerLoader lookupGeoServerLoader(ApplicationContext appContext) {GeoServerLoader loader = GeoServerExtensions.bean(GeoServerLoader.class, appContext);if (loader == null) {loader = new DefaultGeoServerLoader(resourceLoader);}return loader;}@Overridepublic void initialize(GeoServer geoServer) throws Exception {loader.initializeDefaultStyles(geoServer.getCatalog());}
}然后重点看一下它的postProcessBeforeInitialization方法
protected GeoServerLoader lookupGeoServerLoader(ApplicationContext appContext) {GeoServerLoader loader = GeoServerExtensions.bean(GeoServerLoader.class, appContext);if (loader == null) {loader = new DefaultGeoServerLoader(resourceLoader);}return loader;}实际上就是loader(src/main/java/org/geoserver/config/GeoServerLoader.java)的postProcessBeforeInitialization方法
public final Object postProcessBeforeInitialization(Object bean, String beanName)throws BeansException {if (bean instanceof Catalog) {// ensure this is not a wrapper but the real dealif (bean instanceof Wrapper && ((Wrapper) bean).isWrapperFor(Catalog.class)) {return bean;}postProcessBeforeInitializationCatalog(bean);}if (bean instanceof GeoServer) {postProcessBeforeInitializationGeoServer(bean);}return bean;}再继续看postProcessBeforeInitializationCatalog方法
private void postProcessBeforeInitializationCatalog(Object bean) {// loadtry {// setup ADMIN_ROLE security context to load secured resourcesactivateAdminRole();Catalog catalog = (Catalog) bean;XStreamPersister xp = xpf.createXMLPersister();xp.setCatalog(catalog);loadCatalog(catalog, xp);// initialize stylesinitializeStyles(catalog, xp);} catch (Exception e) {throw new RuntimeException(e);} finally {// clear security contextSecurityContextHolder.clearContext();}}重点在loadCatalog,再继续往下看loadCatalog
@Overrideprotected void loadCatalog(Catalog catalog, XStreamPersister xp) throws Exception {catalog.setResourceLoader(resourceLoader);readCatalog(catalog, xp);if (!legacy) {// add the listener which will persist changescatalog.addListener(new GeoServerConfigPersister(resourceLoader, xp));catalog.addListener(new GeoServerResourcePersister(catalog));}executeListener(catalog, xp);}重点在readCatalog,再继续往下看readCatalog
重点来了啊 重点来了
protected void readCatalog(Catalog catalog, XStreamPersister xp) throws Exception {// we are going to synch up the catalogs and need to preserve listeners,// but these two fellas are attached to the new catalog as wellcatalog.removeListeners(ResourcePool.CacheClearingListener.class);catalog.removeListeners(GeoServerConfigPersister.class);catalog.removeListeners(GeoServerResourcePersister.class);// look for catalog.xml, if it exists assume we are dealing with// an old data directoryResource f = resourceLoader.get("catalog.xml");CatalogImpl catalog2;if (!Resources.exists(f)) {// assume 2.x style data directoryStopwatch sw = Stopwatch.createStarted();LOGGER.config("Loading catalog " + resourceLoader.getBaseDirectory());catalog2 = (CatalogImpl) readCatalog(xp);LOGGER.config("Read catalog in " + sw.stop());} else {// import old style catalog, register the persister now so that we start// with a new version of the catalogcatalog2 = (CatalogImpl) readLegacyCatalog(f, xp);}List<CatalogListener> listeners = new ArrayList<>(catalog.getListeners());// make to remove the old resource pool catalog listener((CatalogImpl) catalog).sync(catalog2);// attach back the old listenersfor (CatalogListener listener : listeners) {catalog.addListener(listener);}} /** Reads the catalog from disk. */Catalog readCatalog(XStreamPersister xp) throws Exception {CatalogImpl catalog = new CatalogImpl();catalog.setResourceLoader(resourceLoader);xp.setCatalog(catalog);xp.setUnwrapNulls(false);// see if we really need to verify stores on startupboolean checkStores = checkStoresOnStartup(xp);if (!checkStores) {catalog.setExtendedValidation(false);}// global stylesloadStyles(resourceLoader.get("styles"), catalog, xp);// workspaces, stores, and resourcesResource workspaces = resourceLoader.get("workspaces");if (Resources.exists(workspaces)) {// do a first quick scan over all workspaces, setting the defaultResource dws = workspaces.get("default.xml");WorkspaceInfo defaultWorkspace = null;if (Resources.exists(dws)) {try {defaultWorkspace = depersist(xp, dws, WorkspaceInfo.class);if (LOGGER.isLoggable(Level.CONFIG)) {LOGGER.config("Loaded default workspace '" + defaultWorkspace.getName() + "'");}} catch (Exception e) {LOGGER.log(Level.WARNING, "Failed to load default workspace", e);}} else {LOGGER.warning("No default workspace was found.");}List<Resource> workspaceList =workspaces.list().parallelStream().filter(r -> Resources.DirectoryFilter.INSTANCE.accept(r)).collect(Collectors.toList());try (AsynchResourceIterator<WorkspaceContents> it =new AsynchResourceIterator<>(workspaces,Resources.DirectoryFilter.INSTANCE,new WorkspaceMapper())) {while (it.hasNext()) {WorkspaceContents wc = it.next();WorkspaceInfo ws;final Resource workspaceResource = wc.resource;try {ws = depersist(xp, wc.contents, WorkspaceInfo.class);catalog.add(ws);LOGGER.log(Level.CONFIG,() -> String.format("Loaded workspace '%s'", ws.getName()));} catch (Exception e) {LOGGER.log(Level.WARNING,"Failed to load workspace '" + workspaceResource.name() + "'",e);continue;}// load the namespaceNamespaceInfo ns = null;try {ns = depersist(xp, wc.nsContents, NamespaceInfo.class);catalog.add(ns);} catch (Exception e) {LOGGER.log(Level.WARNING,"Failed to load namespace for '" + workspaceResource.name() + "'",e);}// set the default workspace, this value might be null in the case of coming// from a// 2.0.0 data directory. See https://osgeo-org.atlassian.net/browse/GEOS-3440if (defaultWorkspace != null) {if (ws.getName().equals(defaultWorkspace.getName())) {catalog.setDefaultWorkspace(ws);if (ns != null) {catalog.setDefaultNamespace(ns);}}} else {// create the default.xml filedefaultWorkspace = catalog.getDefaultWorkspace();if (defaultWorkspace != null) {try {persist(xp, defaultWorkspace, dws);} catch (Exception e) {LOGGER.log(Level.WARNING,"Failed to persist default workspace '"+ workspaceResource.name()+ "'",e);}}}// load the styles for the workspaceResource styles = workspaceResource.get("styles");if (styles != null) {loadStyles(styles, catalog, xp);}}}// maps each store into a SingleResourceContentsResourceMapper<SingleResourceContents> storeMapper =sd -> {Resource f = sd.get("datastore.xml");if (Resources.exists(f)) {return new SingleResourceContents(f, f.getContents());}f = sd.get("coveragestore.xml");if (Resources.exists(f)) {return new SingleResourceContents(f, f.getContents());}f = sd.get("wmsstore.xml");if (Resources.exists(f)) {return new SingleResourceContents(f, f.getContents());}f = sd.get("wmtsstore.xml");if (Resources.exists(f)) {return new SingleResourceContents(f, f.getContents());}if (!isConfigDirectory(sd)) {LOGGER.warning("Ignoring store directory '" + sd.name() + "'");}// nothing foundreturn null;};for (Resource wsd : workspaceList) {// load the stores for this workspacetry (AsynchResourceIterator<SingleResourceContents> it =new AsynchResourceIterator<>(wsd, Resources.DirectoryFilter.INSTANCE, storeMapper)) {while (it.hasNext()) {SingleResourceContents SingleResourceContents = it.next();final String resourceName = SingleResourceContents.resource.name();if ("datastore.xml".equals(resourceName)) {loadDataStore(SingleResourceContents, catalog, xp, checkStores);} else if ("coveragestore.xml".equals(resourceName)) {loadCoverageStore(SingleResourceContents, catalog, xp);} else if ("wmsstore.xml".equals(resourceName)) {loadWmsStore(SingleResourceContents, catalog, xp);} else if ("wmtsstore.xml".equals(resourceName)) {loadWmtsStore(SingleResourceContents, catalog, xp);} else if (!isConfigDirectory(SingleResourceContents.resource)) {LOGGER.warning("Ignoring store directory '"+ SingleResourceContents.resource.name()+ "'");continue;}}}// load the layer groups for this workspaceResource layergroups = wsd.get("layergroups");if (layergroups != null) {loadLayerGroups(layergroups, catalog, xp);}}} else {LOGGER.warning("No 'workspaces' directory found, unable to load any stores.");}// layergroupsResource layergroups = resourceLoader.get("layergroups");if (layergroups != null) {loadLayerGroups(layergroups, catalog, xp);}xp.setUnwrapNulls(true);catalog.resolve();// re-enable extended validationif (!checkStores) {catalog.setExtendedValidation(true);}return catalog;}这就是解析工作空间的核心代码了,并且可以看到它和上一步的关联的地方
catalog.add(ws);扩展的说一下解析工作空间时用到了XStream技术,这个技术主要用于xml文件和java对象的互相转换
也就是说到此为止,Catalog的业务逻辑算是基本上梳理完了
五、总结
回顾上面的一坨坨代码,总结出来资源目录的处理就两条线
1.资源读取(上述4.2)【本质上就是读取文件】
2.资源的查询过滤(上述4.1)【本质上就是数组或者集合的增删改查】
相关文章:

Geoserver源码解读五 Catalog
系列文章目录 Geoserver源码解读一 环境搭建 Geoserver源码解读二 主入口 Geoserver源码解读三 GeoServerBasePage Geoserver源码解读四 REST服务 Geoserver源码解读五 Catalog 目录 系列文章目录 前言 一、定义 二、前置知识点 1.Spring 的 Bean 生命周期 ApplicationCon…...
自签名证书)
安全与加密常识(5)自签名证书
文章目录 什么是自签名证书?自签名证书有什么优势?自签名证书有什么缺陷?企业可以使用自签名证书吗?如何创建自签名证书?前面我们介绍了什么是证书签名请求:证书签名请求(Certificate Signing Request,CSR)是一种数据文件,通常由申请者生成,并用于向证书颁发机构(C…...

Java官网网址及其重要资源
Java是一种广泛应用于开发各种应用程序的编程语言,它具有跨平台、面向对象和高性能等优势。若你想学习Java或深入了解它的最新动态,Java官网是你的首要目的地。在本文中,我们将向你介绍Java官网的网址以及一些重要资源。 Java官网网址&#x…...

Linux--start-stop-daemon
参考:start-stop-daemon(8) - Linux manual page 1、名称 start-stop-daemon:启动和停止系统守护程序。 2、简介 start-stop-daemon [option...] command 3、描述 start-stop-daemon用于控制系统级进程的创建和终止。使用其中一个匹配选项࿰…...

优化Java中XML和JSON序列化
优化Java中XML和JSON序列化 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在Java应用程序中,对于XML和JSON的序列化操作是非常常见的需求。本文将…...
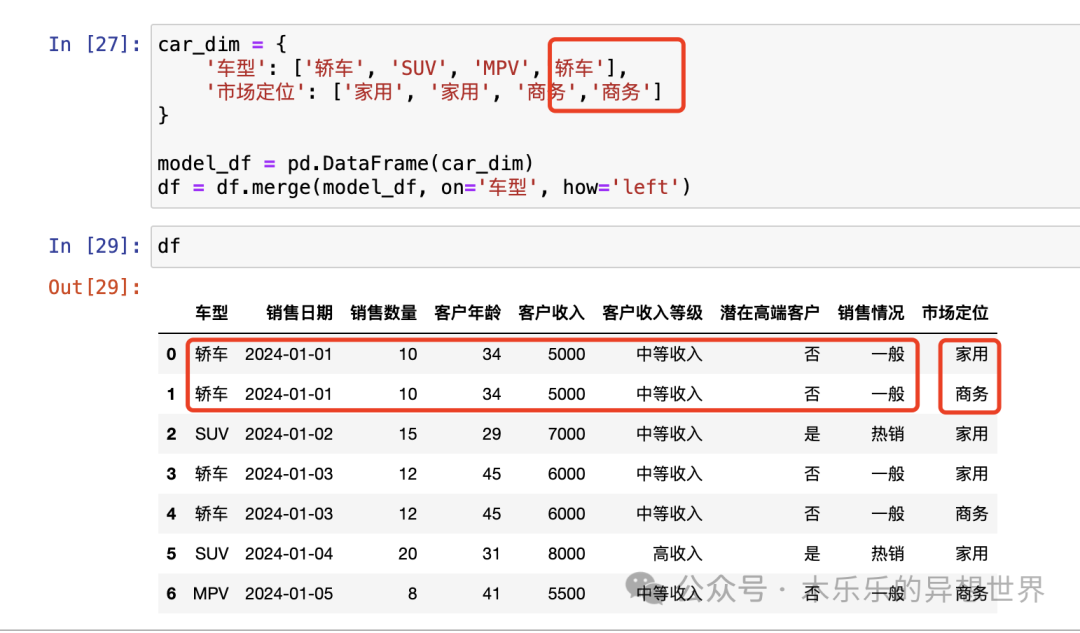
像学Excel 一样学 Pandas系列-创建数据分析维度
嗨,小伙伴们。又到喜闻乐见的Python 数据分析王牌库 Pandas 的学习时间。按照数据分析处理过程,这次轮到了新增维度的部分了。 老样子,我们先来回忆一下,一个完整数据分析的过程,包含哪些部分内容。 其中,…...

Rust 基础教程
Rust 编程语言教程 Rust是一门注重安全、并发和性能的系统编程语言。本文将从Rust的基本语法、常用功能到高级特性,详细介绍Rust的使用方法。 目录 简介环境配置基础语法 变量和常量数据类型函数控制流 所有权和借用 所有权借用 结构体和枚举 结构体枚举 模块和包…...

Study--Oracle-06-Oracler网络管理
一、ORACLE的监听管理 1、ORACLE网络监听配置文件 cd /u01/app/oracle/product/12.2.0/db_1/network/admin 2、在Oracle数据库中,监听器(Listener)是一个独立的进程,它监听数据库服务器上的特定端口上的网络连接请求,…...

uniapp零基础入门Vue3组合式API语法版本开发咸虾米壁纸项目实战
嗨,大家好,我是爱搞知识的咸虾米。 今天给大家带来的是零基础入门uniapp,课程采用的是最新的Vue3组合式API版本,22年发布的uniappVue2版本获得了官方推荐,有很多同学等着我这个vue3版本的那,如果没有学过vu…...
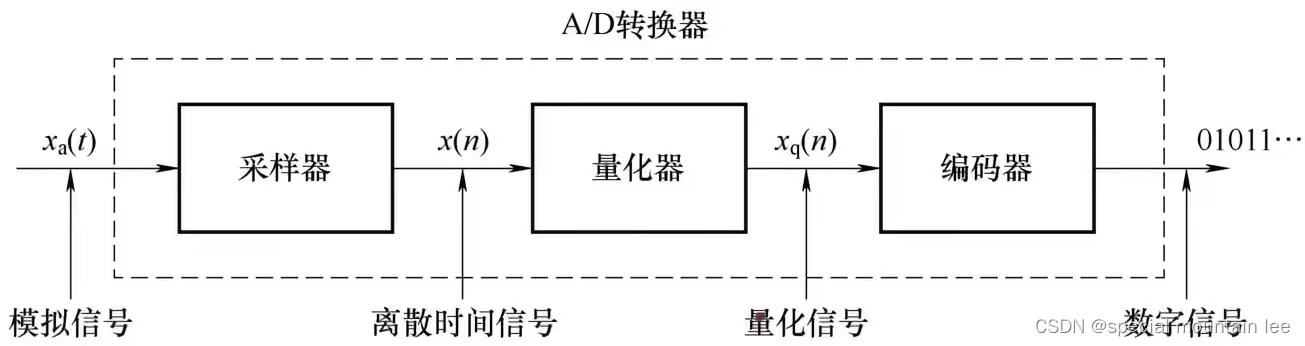
数字信号处理教程(2)——时域离散信号与时域离散系统
上回书说到数字信号处理中基本的一个通用模型框架图。今天咱们继续,可以说今天要讲的东西必须是学习数字信号处理必备的观念——模拟与数字,连续和离散。 时域离散序列 由于数字信号基本都来自模拟信号,所以先来谈谈模拟信号。模拟信号就是…...

imx6ull/linux应用编程学习(8)PWM应用编程(基于正点)
1.应用层如何操控PWM: 与 LED 设备一样, PWM 同样也是通过 sysfs 方式进行操控,进入到/sys/class/pwm 目录下 这里列举出了 8 个以 pwmchipX(X 表示数字 0~7)命名的文件夹,这八个文件夹其实就对应了…...

等保2.0 实施方案
一、引言 随着信息技术的广泛应用,网络安全问题日益突出,为确保信息系统安全、稳定、可靠运行,保障国家安全、公共利益和个人信息安全,根据《网络安全法》及《信息安全技术 网络安全等级保护基本要求》(等保2.0&#x…...
7/3 第六周 数据库的高级查询
...

ubuntu20.04安装kazam桌面屏幕录制工具
在Ubuntu 20.04上安装Kazam可以通过以下步骤进行: 1.打开终端:可以通过按下Ctrl Alt T组合键来打开终端。 2.添加PPA源:Kazam不再在官方Ubuntu仓库中,但可以通过PPA源进行安装。在终端中输入以下命令来添加PPA: su…...

Python应对反爬虫的策略
Python应对反爬虫的策略 概述User-Agent 伪造应对302重定向IP限制与代理使用Cookies和Session管理动态内容加载数据加密与混淆请求频率限制爬虫检测算法法律与道德考量结语 概述 在数字化时代,网络数据采集已成为获取信息的重要手段之一。然而,随着技术…...
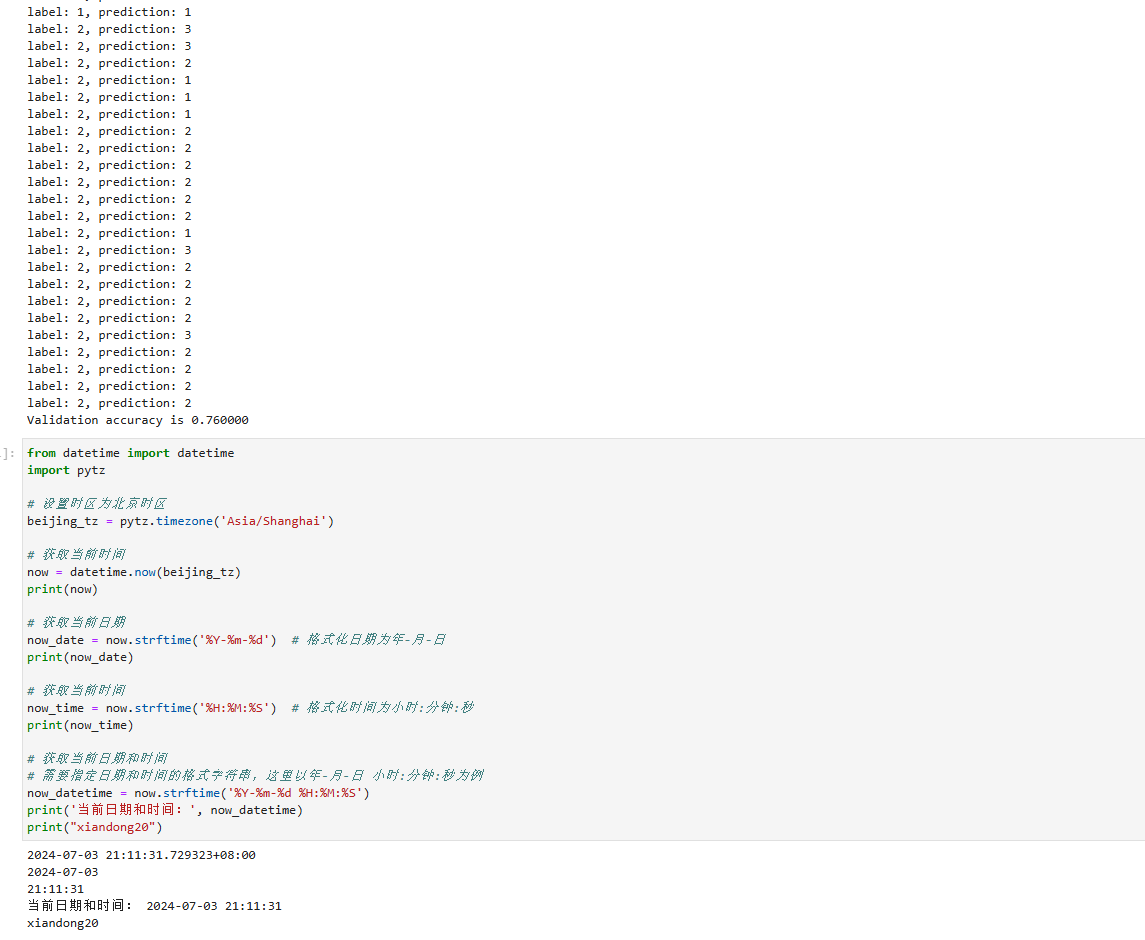
240703_昇思学习打卡-Day15-K近邻算法实现红酒聚类
KNN(K近邻)算法实现红酒聚类 K近邻算法,是有监督学习中的分类算法,可以用于分类和回归,本篇主要讲解其在分类上的用途。 文章目录 KNN(K近邻)算法实现红酒聚类算法原理数据下载数据读取与处理模型构建--计算距离模型预测 算法原理 KNN算法虽…...
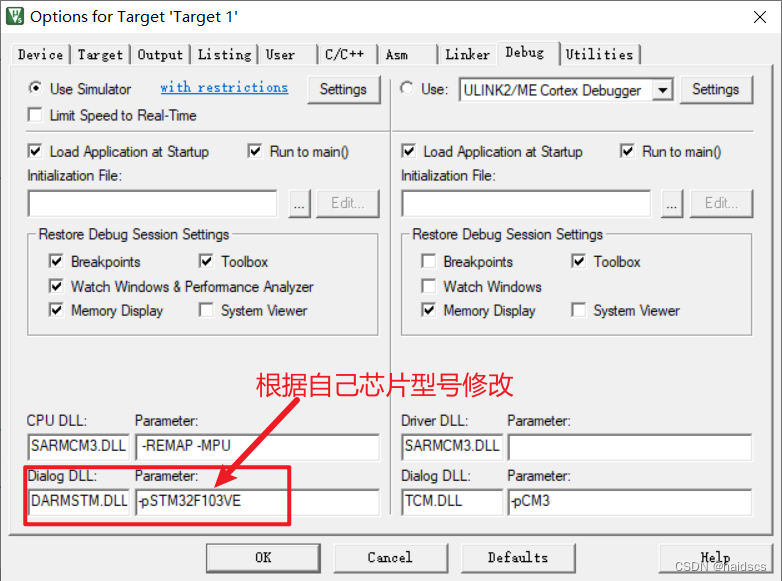
keil5模拟 仿真 报错没有读写权限
debug*** error 65: access violation at 0x4002100C : no write permission 修改为: Dialog DLL默认是DCM3.DLL Parameter默认是-pCM3 应改为 Dialog DLL默认是DARMSTM.DLL Parameter默认是-pSTM32F103VE...
)
力扣爆刷第158天之TOP100五连刷56-60(子集、最小栈、最长有效括号)
力扣爆刷第158天之TOP100五连刷56-60(子集、最小栈、最长有效括号) 文章目录 力扣爆刷第158天之TOP100五连刷56-60(子集、最小栈、最长有效括号)一、78. 子集二、105. 从前序与中序遍历序列构造二叉树三、43. 字符串相乘四、155. …...

高薪程序员必修课-Java中 Synchronized锁的升级过程
目录 前言 锁的升级过程 1. 偏向锁(Biased Locking) 原理: 示例: 2. 轻量级锁(Lightweight Locking) 原理: 示例: 3. 重量级锁(Heavyweight Locking)…...

Vue项目打包上线
Nginx 是一个高性能的开源HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP代理服务器。它在设计上旨在处理高并发的请求,是一个轻量级、高效能的Web服务器和反向代理服务器,广泛用于提供静态资源、负载均衡、反向代理等功能。 1、下载nginx 2、…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色
UE5 Mac环境搭好了,然后呢?给新手的第一个5分钟:创建、操控并理解你的第一个角色当你第一次打开UE5的Mac版本,面对那个闪烁着光芒的启动界面,内心可能既兴奋又忐忑。安装只是第一步,真正的旅程现在才开始。…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...

ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍
ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-…...

约束感知图缩减算法在量子优化中的应用
1. 约束感知图缩减算法概述在量子计算领域,资源受限一直是制约算法实际应用的主要瓶颈。以当前主流的超导量子计算机为例,其量子比特数通常在50-100个之间,且存在显著的噪声干扰。这种硬件限制使得许多经典优化问题难以直接映射到量子设备上求…...