二叉树之遍历
二叉树之遍历
- 二叉树遍历
- 遍历分类
- 前序遍历
- 流程描述
- 代码实现
- 中序遍历
- 流程描述
- 代码实现
- 后序遍历
- 流程描述
- 代码实现
- 层次遍历
- 流程描述
- 代码实现
- 总结
二叉树遍历
遍历分类
遍历二叉树的思路有 4 种,分别是:
- 前序遍历二叉树,有递归和非递归两种方式;
- 中序遍历二叉树,有递归和非递归两种方式;
- 后序遍历二叉树,有递归和非递归两种方式;
- 层次遍历二叉树
前序遍历
流程描述
所谓前序遍历二叉树,指的是从根结点出发,按照以下步骤访问二叉树的每个结点:
- 访问当前结点;
- 进入当前结点的左子树,以同样的步骤遍历左子树中的结点;
- 遍历完当前结点的左子树后,再进入它的右子树,以同样的步骤遍历右子树中的结点;
举个简单的例子,下图是一棵二叉树:

前序遍历这棵二叉树的过程是:
访问根节点 1;
进入 1 的左子树,执行同样的步骤:访问结点 2;进入 2 的左子树,执行同样的步骤:访问结点 4;结点 4 没有左子树;结点 4 没有右子树;进入 2 的右子树,执行同样的步骤:访问结点 5;结点 5 没有左子树;结点 5 没有右子树;
进入 1 的右子树,执行同样的步骤:访问结点 3;进入 3 的左子树,执行同样的步骤:访问结点 6;结点 6 没有左子树;结点 6 没有右子树;进入 3 的右子树,执行同样的步骤:访问结点 7;结点 7 没有左子树;结点 7 没有右子树;
经过以上过程,就访问了二叉树中的各个结点,访问的次序是:
1 2 4 5 3 6 7
代码实现
/*** 前序遍历- 递归实现* 访问当前结点;* 进入当前结点的左子树,以同样的步骤遍历左子树中的结点;* 遍历完当前结点的左子树后,再进入它的右子树,以同样的步骤遍历右子树中的结点;* @param treeNode*/public static void preTraverseForRecursion(TreeNode treeNode){if (treeNode != null){// 访问当前节点printTreeNode(treeNode);// 访问当前节点的左子节点preTraverseForRecursion(treeNode.left);// 访问当前节点的右子节点preTraverseForRecursion(treeNode.right);}}/*** 前序遍历- 非递归实现* 众所周知:递归实现无非是使用了栈结构来实现的,压栈,出栈,所以非是递归实现前序遍历就是自己实现栈* 访问当前结点;* 进入当前结点的左子树,以同样的步骤遍历左子树中的结点;* 遍历完当前结点的左子树后,再进入它的右子树,以同样的步骤遍历右子树中的结点;* @param treeNode*/public static void preTraverseForNoRecursion(TreeNode treeNode){TreeNode curr = treeNode;TreeNodeStack stack = new TreeNodeStack();while (curr != null || !stack.isEmpty()){if (curr != null){// 访问当前节点printTreeNode(curr);stack.push(curr);curr = curr.left;}else {TreeNode pop = stack.pop();curr = pop.right;}}}
/*** 树节点栈*/
@Data
public class TreeNodeStack {private int top = -1;private TreeNode[] stack = new TreeNode[10];public boolean isEmpty(){return top < 0;}/*** 入栈* @param treeNode*/public void push(TreeNode treeNode){top++;stack[top] = treeNode;}/*** 出栈* @return*/public TreeNode pop(){if (top < 0){return null;}TreeNode treeNode = stack[top];top--;return treeNode;}
}
中序遍历
流程描述
二叉树的中序遍历,指的是从根结点出发,按照以下步骤访问二叉树中的每个结点:
- 先进入当前结点的左子树,以同样的步骤遍历左子树中的结点;
- 访问当前结点;
- 最后进入当前结点的右子树,以同样的步骤遍历右子树中的结点。

中序遍历这棵二叉树的过程是:
进入结点 1 的左子树,访问左子树中的结点;进入结点 2 的左子树,访问左子树中的结点;试图进入结点 4 的左子树,但该结点没有左子树;访问结点 4;试图进入结点 4 的右子树,但该结点没有右子树;访问结点 2;进入结点 2 的右子树,访问右子树中的结点;试图进入结点 5 的左子树,但该结点没有左子树;访问结点 5;试图进入结点 5 的右子树,但该结点没有右子树;
访问结点 1;
进入结点 1 的右子树,访问右子树中的结点;进入结点 3 的左子树,访问左子树中的结点;试图进入结点 6 的左子树,但该结点没有左子树;访问结点 6;试图进入结点 6 的右子树,但该结点没有右子树;访问结点 3;进入结点 3 的右子树,访问右子树中的结点;试图进入结点 7 的左子树,但该结点没有左子树;访问结点 7;试图进入结点 7 的右子树,但该结点没有右子树;
最终,中序遍历图 1 中的二叉树,访问各个结点的顺序是:
4 2 5 1 6 3 7
代码实现
/*** 中序遍历-递归实现* 二叉树的中序遍历,指的是从根结点出发,按照以下步骤访问二叉树中的每个结点:* 1. 先进入当前结点的左子树,以同样的步骤遍历左子树中的结点;* 2. 访问当前结点;* 3. 最后进入当前结点的右子树,以同样的步骤遍历右子树中的结点。* @param treeNode*/public static void inTraverseForRecursion(TreeNode treeNode){if (treeNode != null){// 递归-当问当前节点的左子节点inTraverseForRecursion(treeNode.left);// 访问当前节点printTreeNode(treeNode);// 递归-访问当前节点的右子节点inTraverseForRecursion(treeNode.right);}}/*** 中序遍历-非递归实现* 二叉树的中序遍历,指的是从根结点出发,按照以下步骤访问二叉树中的每个结点:* 1. 先进入当前结点的左子树,以同样的步骤遍历左子树中的结点;* 2. 访问当前结点;* 3. 最后进入当前结点的右子树,以同样的步骤遍历右子树中的结点。* @param treeNode*/public static void inTraverseForNoRecursion(TreeNode treeNode){TreeNode curr = treeNode;TreeNodeStack stack = new TreeNodeStack();while (curr != null || !stack.isEmpty()){if (curr != null){// 入栈顺序:1, 2, 4,stack.push(curr);curr = curr.left;}else {// 出栈顺序:4, 2, 1TreeNode pop = stack.pop();printTreeNode(pop);// 然后访问右节点curr = pop.right;}}}
后序遍历
流程描述
后序遍历二叉树,指的是从根结点出发,按照以下步骤访问树中的每个结点:
- 优先进入当前结点的左子树,以同样的步骤遍历左子树中的结点;
- 如果当前结点没有左子树,则进入它的右子树,以同样的步骤遍历右子树中的结点;
- 直到当前结点的左子树和右子树都遍历完后,才访问该结点。
以下图所示的二叉树为例:

后序遍历这棵二叉树的过程是:
从根节点 1 出发,进入该结点的左子树;进入结点 2 的左子树,遍历左子树中的结点:进入结点 4 的左子树,但该结点没有左孩子;进入结点 4 的右子树,但该结点没有右子树;访问结点 4;进入结点 2 的右子树,遍历右子树中的结点:进入结点 5 的左子树,但该结点没有左孩子;进入结点 5 的右子树,但该结点没有右孩子;访问结点 5;访问结点 2;
进入结点 1 的右子树,遍历右子树中的结点:进入结点 3 的左子树,遍历左子树中的结点:进入结点 6 的左子树,但该结点没有左孩子;进入结点 6 的右子树,但该结点没有右子树;访问结点 6;进入结点 3 的右子树,遍历右子树中的结点:进入结点 7 的左子树,但该结点没有左孩子;进入结点 7 的右子树,但该结点没有右孩子;访问结点 7;访问结点 3;
访问结点 1。
最终,后序遍历图 1 中的二叉树,访问各个结点的顺序是:
4 5 2 6 7 3 1
代码实现
/*** 后序遍历-递归实现* 后序遍历二叉树,指的是从根结点出发,按照以下步骤访问树中的每个结点:* 1. 优先进入当前结点的左子树,以同样的步骤遍历左子树中的结点;* 2. 如果当前结点没有左子树,则进入它的右子树,以同样的步骤遍历右子树中的结点;* 3. 直到当前结点的左子树和右子树都遍历完后,才访问该结点。* @param treeNode*/public static void postTraverseForRecursion(TreeNode treeNode){if (treeNode != null){// 递归-当问当前节点的左子节点postTraverseForRecursion(treeNode.left);// 递归-访问当前节点的右子节点postTraverseForRecursion(treeNode.right);// 访问当前节点printTreeNode(treeNode);}}/*** 后序遍历-非递归实现* 后序遍历二叉树,指的是从根结点出发,按照以下步骤访问树中的每个结点:* 1. 优先进入当前结点的左子树,以同样的步骤遍历左子树中的结点;* 2. 如果当前结点没有左子树,则进入它的右子树,以同样的步骤遍历右子树中的结点;* 3. 直到当前结点的左子树和右子树都遍历完后,才访问该结点。** 4, 5, 2, 6, 7, 3, 1* @param treeNode*/public static void postTraverseForNoRecursion(TreeNode treeNode){TreeNode curr = treeNode;LinkedList<TreeNode> stack = new LinkedList<>();// 定义最后一次出栈节点,防止陷入重复执行TreeNode pop = null;while (curr != null || !stack.isEmpty()){if (curr != null){stack.push(curr);curr = curr.left;}else {// peek方法是查询栈顶数据,但是不弹出TreeNode last = stack.peek();// last.right == pop 如果相等,那就说明已经执行过该右子节点了,这个条件是防止有右子节点的数据陷入死循环中if (last.right == null || last.right == pop){pop = stack.pop();printTreeNode(pop);}else {curr = last.right;}}}}
层次遍历
流程描述

上面这棵树一共有 3 层,根结点位于第一层,以此类推。
所谓层次遍历二叉树,就是从树的根结点开始,一层一层按照从左往右的次序依次访问树中的结点。
层次遍历用阻塞队列存储的二叉树,可以借助队列存储结构实现,具体方案是:
- 将根结点入队;
- 从队列的头部提取一个结点并访问它,将该结点的左孩子和右孩子依次入队;
- 重复执行第 2 步,直至队列为空;
假设将图 1 中的二叉树存储到链表中,那么层次遍历的过程是:
根结点 1 入队(1);
根结点 1 出队并访问它,然后将 1 的左孩子 2 和右孩子 3 依次入队(3, 2);
将结点 2 出队并访问它,然后将 2 的左孩子 4 和右孩子 5 依次入队(5,4,3);
将结点 3 出队并访问它,然后将 3 的左孩子 6 和右孩子 7 依次入队(7,6,5,4);
根结点 4 出队并访问它,然后将 4 的左孩子(无)和右孩子(无)依次入队(7,6,5);
将结点 5 出队并访问它,然后将 5 的左孩子(无)和右孩子(无)依次入队(7,6);
将结点 6 出队并访问它,然后将 6 的左孩子(无)和右孩子(无)依次入队(7);
将结点 7 出队并访问它,然后将 6 的左孩子(无)和右孩子(无)依次入队();
队列为空,层次遍历结束
最终,后序遍历图 1 中的二叉树,访问各个结点的顺序是:
1 2 3 4 5 6 7
代码实现
/*** 层次遍历* 所谓层次遍历二叉树,就是从树的根结点开始,一层一层按照从左往右的次序依次访问树中的结点。* 1. 将根结点入队;* 2. 从队列的头部提取一个结点并访问它,将该结点的左孩子和右孩子依次入队;* 3. 重复执行第 2 步,直至队列为空;* @param treeNode*/public static void levelTraverseForRecursion(TreeNode treeNode){if (treeNode != null){LinkedBlockingQueue<TreeNode> queue = new LinkedBlockingQueue<>(10);queue.offer(treeNode);doPushQueue(queue);}}/*** 使用阻塞队列实现二叉树层次遍历* 阻塞队列的特点就是先进先出* @param nowQueue*/private static void doPushQueue(LinkedBlockingQueue<TreeNode> nowQueue){if (nowQueue.isEmpty()){return;}// 从阻塞队列中弹出TreeNode poll = nowQueue.poll();while (poll != null){printTreeNode(poll);// 如果左子节点不为null, 则入队列if (poll.left != null){nowQueue.offer(poll.left);}// 如果右子节点不为null, 则入队列if (poll.right != null){nowQueue.offer(poll.right);}// 从阻塞队列中弹出poll = nowQueue.poll();}}
总结
总结各个遍历类型的流程
前序遍历:根节点 - 左节点 - 右节点
中序遍历:左节点 - 根节点 - 右节点
后序遍历:左节点 - 右节点 - 根节点
层次遍历:从根节点开始一层一层的遍历(左节点-右节点)
相关文章:
二叉树之遍历
二叉树之遍历 二叉树遍历遍历分类前序遍历流程描述代码实现 中序遍历流程描述代码实现 后序遍历流程描述代码实现 层次遍历流程描述代码实现 总结 二叉树遍历 遍历分类 遍历二叉树的思路有 4 种,分别是: 前序遍历二叉树,有递归和非递归两种…...
)
【经验贴】如何做好自己的职业规划(技术转项目经理)
我有几个问题想问大家 第一,你了解自己吗?你知道自己想要是什么吗?你了解自己的优势劣势吗? 第二,你了解这个行业吗?你知道这个行业是如何发展起来的吗?你了解这个行业的背景吗?你…...

【笔记】字符串相似度代码分享
目录 一、算法介绍1、算法1)基于编辑距离2)基于标记3)基于序列4)基于压缩5)基于发音6)简单算法 2、安装 二、代码demo1、Hamming 距离2、Levenshtein 距离3、Damerau-Levenshtein距离4、Jaro 相似度5、Jaro…...
AI墓地:738个倒闭AI项目的启示
近年来,人工智能技术迅猛发展,然而,不少AI项目却在市场上悄然消失。根据AI工具聚合网站“DANG”的统计,截至2024年6月,共有738个AI项目停运或停止维护。本文将探讨这些AI项目失败的原因,并分析当前AI初创企…...

工程文件参考——CubeMX+LL库+SPI主机 阻塞式通用库
文章目录 前言CubeMX配置SPI驱动实现spi_driver.hspi_driver.c 额外的接口补充 前言 SPI,想了很久没想明白其DMA或者IT比较好用的方法,可能之后也会写一个 我个人使用场景大数据流不多,如果是大批量数据交互自然是DMA更好用,但考…...

LLM - 模型历史
...

Go语言中的时间与日期处理:time包详解
在Go语言中,time包提供了丰富而强大的功能来处理时间和日期,这对于构建精确计时、定时任务、日期格式化等应用场景至关重要。本文将深入浅出地探讨time包的核心概念、常见问题、易错点及其规避策略,并通过实用代码示例加深理解。 一、时间与…...

Java实现单点登录(SSO)详解:从理论到实践
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 ✨✨ 帅哥美女们,我们共同加油!一起进步&am…...

【leetcode82-91动态规划,91-95多维动态规划】
动态规划【82-91】 多维动态规划【91-95】...

Django学习第四天
启动项目命令 python manage.py runserver 分页功能封装到类中去 封装的类的代码 """ 自定义的分页组件,以后如果想要使用这个分页组件,你需要做: def pretty_list(request):# 靓号列表data_dict {}search_data request.GET.get(q, &…...

redis-benchmark 使用
Redis 自带了一个叫 redis-benchmark 的工具来模拟 N 个客户端同时发出 M 个请求。 Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests>] [-k <boolean>]-h <hostname> Server hostname (default 127.0…...

什么是 qobject_cast?
前言 在 C++ 中,类型转换是一项常见的操作,比如将 int 转换为 char 或将 QString 用于 QMessageBox。但是,为什么我们需要将一个类转换为另一个类呢?本文将解释 qobject_cast 是什么,它的作用以及为什么需要类型转换。 dynamic_cast 和 qobject_cast 的概述 什么是 dyn…...

Python酷库之旅-第三方库Pandas(001)
目录 一、Pandas库的由来 1、背景与起源 1-1、开发背景 1-2、起源时间 2、名称由来 3、发展历程 4、功能与特点 4-1、数据结构 4-2、数据处理能力 5、影响与地位 5-1、数据分析“三剑客”之一 5-2、社区支持 二、Pandas库的应用场景 1、数据分析 2、数据清洗 3…...
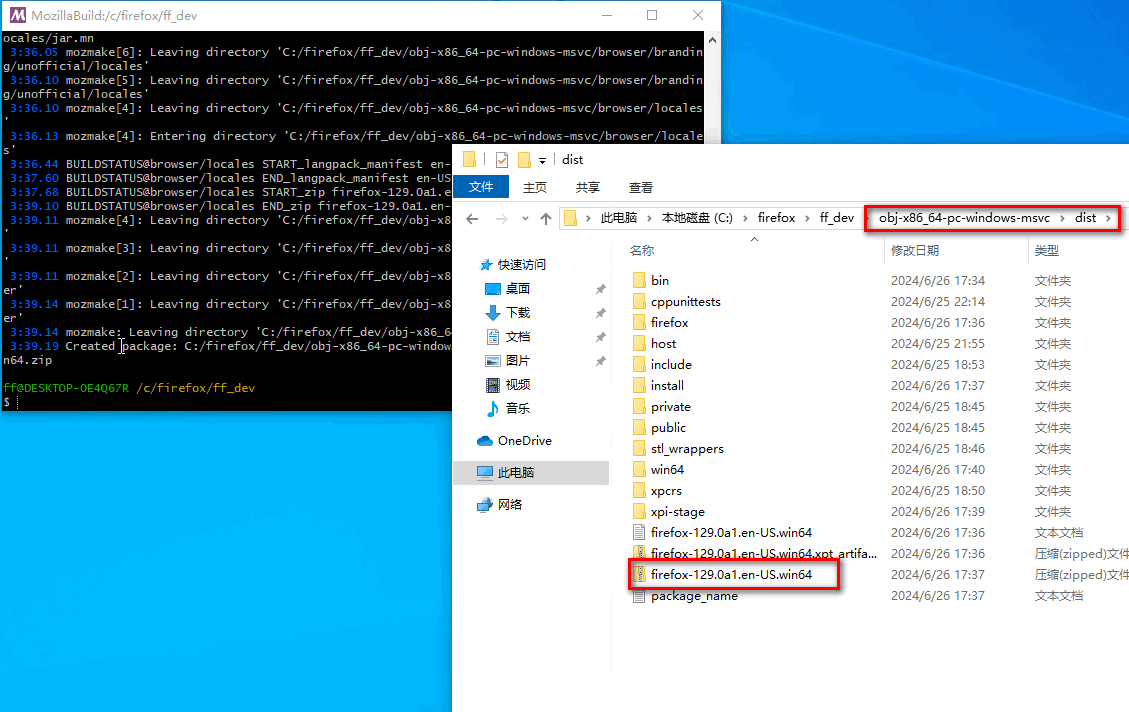
Firefox 编译指南2024 Windows10篇- 编译Firefox(三)
1.引言 在成功获取了Firefox源码之后,下一步就是将这些源码编译成一个可执行的浏览器。编译是开发流程中的关键环节,通过编译,我们可以将源代码转换为可执行的程序,测试其功能,并进行必要的优化和调试。 对于像Firef…...

CSS弹性布局:打造响应式与灵活的网页设计
一、弹性布局是什么? 弹性布局(Flexbox)是一种CSS布局模型,它提供了一种更加高效的方式来对容器中的项目进行布局、对齐和分配空间。与传统的布局方式相比,Flexbox旨在提供一个更加灵活的方式来布局复杂的网页结构&am…...

【高阶数据结构】图的应用--最短路径算法
文章目录 一、最短路径二、单源最短路径--Dijkstra算法三、单源最短路径--Bellman-Ford算法四、多源最短路径--Floyd-Warshall算法 一、最短路径 最短路径问题:从在带权有向图G中的某一顶点出发,找出一条通往另一顶点的最短路径,最短也就是沿…...

腾讯云函数node.js返回自动带反斜杠
云函数返回自动带反斜杠 这里建立了如下一个云函数,目的是当APP过来请求的时候响应支持的版本号: use strict; function main_ret(status,code){let ret {status: status,error: code};return JSON.stringify(ret); } exports.main_handler async (event, context) > {/…...

大模型知识学习
大模型训练过程 数据清洗 拟人化描述:知识库整理 预训练 拟人化描述:知识学习可以使用基于BERT预训练模型进行训练 指令微调 拟人化描述:实际工作技能学习实际操作:让大模型模仿具体的输入输出进行拟合,即模仿学…...

JAVA声明数组
一、声明并初始化数组 直接初始化:在声明数组的同时为其分配空间并初始化元素。 int[] numbers {1, 2, 3, 4, 5}; 动态初始化:先声明数组,再为每个元素分配初始值。 double[] decimals;decimals new double[5]; // 分配空间,但…...

VBA通过Range对象实现Excel的数据写入
前言 本节会介绍通过VBA中的Range对象,来实现Excel表格中的单元格写入、区域范围写入,当然也可以写入不同类型的数据,如数值、文本、公式,以及实现公式下拉自动填充的功能。 一、单元格输入数据 1.通过Value方法实现输入不同类型…...
函数的计算原理(附绘图代码))
从复平面几何到Python代码:可视化理解NumPy中angle()函数的计算原理(附绘图代码)
从复平面几何到Python代码:可视化理解NumPy中angle()函数的计算原理(附绘图代码) 在数学和工程领域,复数不仅是抽象的概念,更是解决实际问题的有力工具。当我们谈论复数68j时,它不仅仅是一个符号组合——在…...

密码学入门:区块链中的密码学原理
密码学入门:区块链中的密码学原理 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊密码学这个重要话题。作为一个Web3探索者,密码学是区块链的基础。今天就来分享一下区块链中常用的密码学原理。 为什么密码学很重要&a…...

Redis在线工具终极指南:3分钟学会数据库操作,无需安装配置
Redis在线工具终极指南:3分钟学会数据库操作,无需安装配置 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 还在为Redis环境配置而烦恼吗?还在为测试一个…...

基于Shapley值与随机森林的印度CPI通胀预测与特征重要性分析
1. 项目概述与核心价值在宏观经济预测领域,通胀预测的准确性直接关系到货币政策制定、市场预期管理乃至社会民生稳定。传统的计量经济学模型,如基于菲利普斯曲线的线性回归,虽然具有良好的可解释性,但在捕捉现实世界中复杂、非线性…...

3分钟掌握中兴光猫配置解密:ZET工具终极快速指南
3分钟掌握中兴光猫配置解密:ZET工具终极快速指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 想要自由掌控家中网络却总被光猫配置限制?中兴光猫…...

为什么选择Mesa框架?Python智能体建模的终极指南与实战秘籍
为什么选择Mesa框架?Python智能体建模的终极指南与实战秘籍 【免费下载链接】mesa Mesa is an open-source Python library for agent-based modeling, ideal for simulating complex systems and exploring emergent behaviors. 项目地址: https://gitcode.com/g…...

终极免费解决方案:如何用Neat Bookmarks拯救你混乱的Chrome书签
终极免费解决方案:如何用Neat Bookmarks拯救你混乱的Chrome书签 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 还在为满屏混乱的Chrome书…...

机器学习赋能分子模拟:从数据驱动CV到自适应采样破解采样瓶颈
1. 项目概述与核心价值在分子模拟的世界里,我们常常面临一个根本性的困境:我们想理解一个复杂系统(比如一个蛋白质如何折叠,或者一个催化剂表面如何发生反应)的微观机理,但系统的相空间维度高得吓人——动辄…...

机器学习优化多浴模型参数结合HEOM计算分子红外光谱
1. 项目概述:当机器学习遇见分子光谱模拟在分子光谱模拟这个领域里,我们这些做计算化学和理论光谱的人,常年都在和一堆复杂的方程和庞大的计算量作斗争。核心目标很明确:我们想从原子和分子的微观运动出发,精准地预测出…...

机器学习算子零样本超分辨率为何失败?多分辨率训练方案解析
1. 项目概述与核心问题在科学计算和科学机器学习领域,我们常常面临一个根本性的挑战:如何用离散的数据和模型去理解和预测连续世界的物理现象。无论是模拟流体湍流、预测天气变化,还是设计新材料,其背后的物理规律通常由偏微分方程…...