概率论与数理统计_下_科学出版社
contents
- 前言
- 第5章 大数定律与中心极限定理
- 独立同分布中心极限定理
- 第6章 数理统计的基本概念
- 6.1 总体与样本
- 6.2 经验分布与频率直方图
- 6.3 统计量
- 6.4 正态总体抽样分布定理
- 6.4.1 卡方分布、t 分布、F 分布
- 6.4.2 正态总体抽样分布基本定理
- 第7章 参数估计
- 7.1 点估计
- 7.1.1 矩估计法
- 7.1.2 极大似然估计法
- 7.2 估计量的评价标准
- 7.2.1 无偏性
- 7.2.2 有效性
- 7.2.3 一致性
- 7.3 区间估计
- 7.3.1 基本概念
- 7.3.2 区间估计常用方法之主元法
- 7.3.3 正态总体的区间估计
- 第8章 假设检验
- 8.1 假设检验的基本概念
- 8.2 单个正态总体均值的假设检验
- 8.3 单个正态总体方差的假设检验
前言
更好的阅读体验:https://blog.dwj601.cn/GPA/4th-term/ProbAndStat/
笔记范围:五至八章。一至四章请跳转:https://blog.csdn.net/qq_73408594/article/details/140190525
教材情况:
| 课程名称 | 选用教材 | 版次 | 作者 | 出版社 | ISBN号 |
|---|---|---|---|---|---|
| 概率论与数理统计Ⅰ | 概率论与数理统计 | 第一版 | 刘国祥王晓谦 等主编 | 科学出版社 | 978-7-03-038317-4 |
学习资源:
- 📺 视频资源:《概率论与数理统计》教学视频全集(宋浩)
- 📖 教材答案:https://pan.baidu.com/s/1yeC0rxatHaLeNHQaW85Kpw?pwd=448w
第5章 大数定律与中心极限定理
{% note light %}
本章只需要知道一个独立同分布中心极限定理即可,至于棣莫弗-拉普拉斯中心极限定理其实就是前者的 { X i } i = 1 ∞ \{X_i\}_{i=1}^{\infty} {Xi}i=1∞ 服从伯努利 n n n 重分布罢了。
{% endnote %}
独立同分布中心极限定理
定义: { X i } i = 1 ∞ \{X_i\}_{i=1}^{\infty} {Xi}i=1∞ 独立同分布且非零方差,其中 E X i = μ , D X i = σ 2 EX_i=\mu,DX_i=\sigma^2 EXi=μ,DXi=σ2,则有:
∑ i = 1 n X i ∼ N ( ∑ i = 1 n ( E X i ) , ∑ i = 1 n ( D X i ) ) ∼ N ( n μ , n σ 2 ) \begin{aligned} \sum_{i=1}^n X_i &\sim N(\sum_{i=1}^n(EX_i),\sum_{i=1}^n(DX_i)) \\ &\sim N(n\mu,n\sigma^2) \end{aligned} i=1∑nXi∼N(i=1∑n(EXi),i=1∑n(DXi))∼N(nμ,nσ2)
解释:其实就是对于独立同分布的随机事件 X i X_i Xi,在事件数 n n n 足够大时,就近似为正态分布(术语叫做依分布)。这样就可以很方便利用正态分布的性质计算当前事件的概率。至于棣莫弗-拉普拉斯中心极限定理就是上述 μ = p , σ 2 = p ( 1 − p ) \mu=p,\sigma^2=p(1-p) μ=p,σ2=p(1−p) 的特殊情况罢了
第6章 数理统计的基本概念
{% note light %}
开始统计学之旅。
{% endnote %}
6.1 总体与样本
类比 ML:数据集=总体,样本=样本。
我们只研究一种样本:简单随机样本 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn)。符合下列两种特点:
- ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn) 相互独立
- ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn) 同分布
同样的,我们研究总体 X X X 的分布与概率密度,一般概率密度会直接给,需要我们在此基础之上研究所有样本的联合密度:
-
分布:由于样本相互独立,故:
F ( x 1 , x 2 , . . . , x n ) = F ( x 1 ) F ( x 2 ) ⋯ F ( x n ) F(x_1,x_2,...,x_n)=F(x_1)F(x_2) \cdots F(x_n) F(x1,x2,...,xn)=F(x1)F(x2)⋯F(xn) -
联合密度:同样由于样本相互独立,故:
p ( x 1 , x 2 , . . . , x n ) = p ( x 1 ) p ( x 2 ) ⋯ p ( x n ) p(x_1,x_2,...,x_n)=p(x_1)p(x_2) \cdots p(x_n) p(x1,x2,...,xn)=p(x1)p(x2)⋯p(xn)
6.2 经验分布与频率直方图
经验分布函数是利用样本得到的。也是给区间然后统计样本频度进而计算频率,只不过区间长度不是固定的。
频率直方图就是选定固定的区间长度,然后统计频度进而计算频率作图。
6.3 统计量
统计量定义:关于样本不含未知数的表达式。
常见统计量:假设 ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn) 为来自总体 X X X 的简单随机样本
一、样本均值和样本方差
-
样本均值: X ‾ = 1 n ∑ i = 1 n X i \displaystyle \overline{X} = \frac{1}{n} \sum_{i=1}^n X_i X=n1i=1∑nXi
-
样本方差: S 0 2 = 1 n ∑ i = 1 n ( X i − X ‾ ) 2 = 1 n ∑ i = 1 n X i 2 − X ‾ 2 \displaystyle S_0^2 = \frac{1}{n} \sum_{i=1}^n (X_i - \overline{X})^2 = \frac{1}{n}\sum_{i=1}^n X_i^2 - \overline{X}^2 S02=n1i=1∑n(Xi−X)2=n1i=1∑nXi2−X2
-
样本标准差: S 0 = S 0 2 \displaystyle S_0 = \sqrt{S_0^2} S0=S02
-
修正样本方差: S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 \displaystyle S^2 = \frac{1}{n-1} \sum_{i=1}^n (X_i - \overline{X})^2 S2=n−11i=1∑n(Xi−X)2
-
修正样本标准差: S = S 2 \displaystyle S = \sqrt{S^2} S=S2
{% fold light @推导 %}设总体 X X X 的数学期望和方差分别为 μ \mu μ 和 σ 2 \sigma^2 σ2, ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn) 是简单随机样本,则:
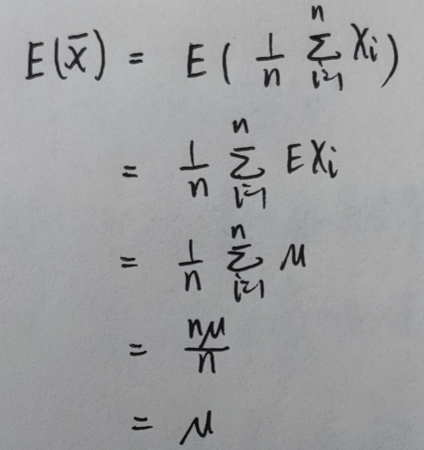
即:样本均值的数学期望 = = = 总体的数学期望
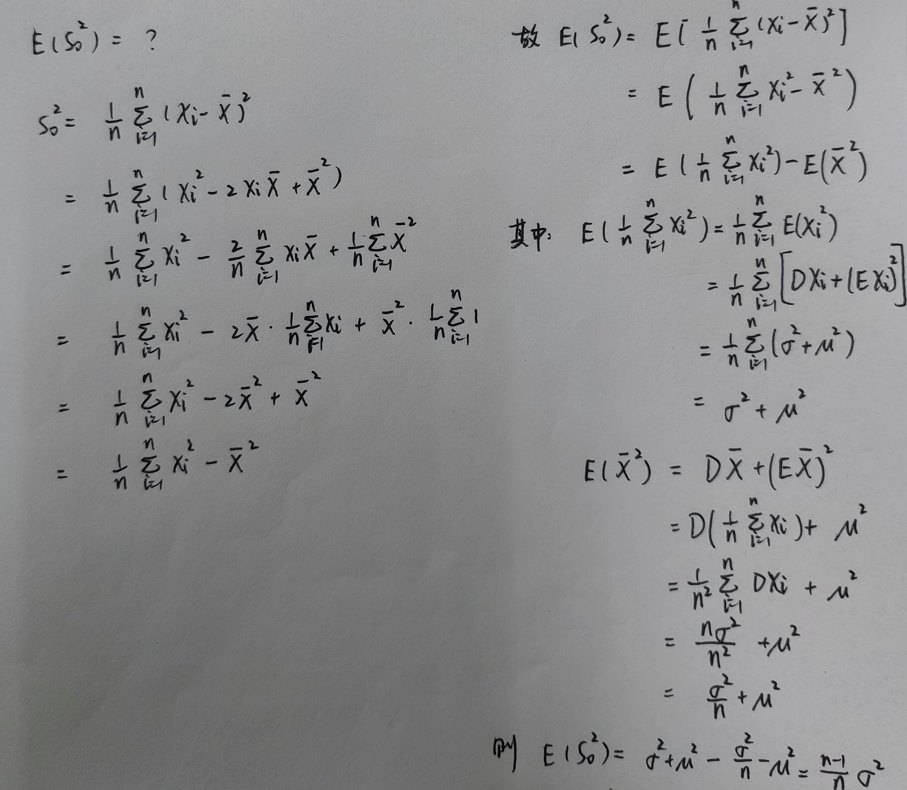
即:样本方差的数学期望 ≠ \ne = 总体的数学期望
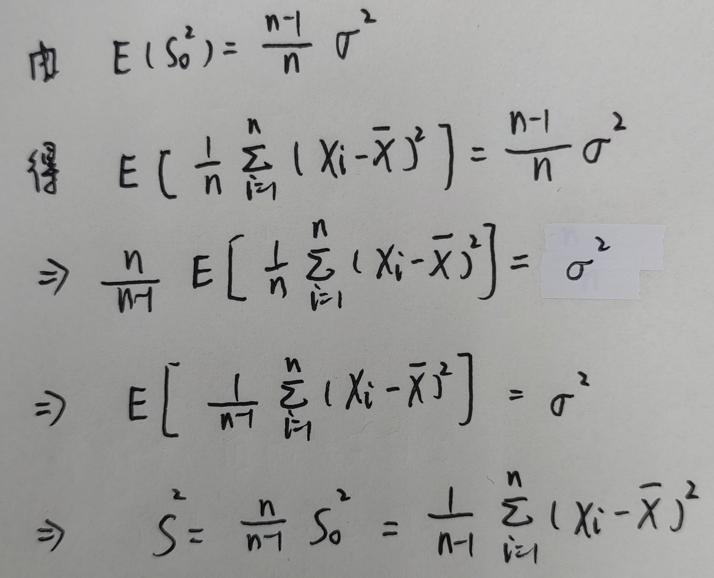
上图即:修正样本方差推导
{% endfold %}
-
样本 k k k 阶原点矩: A k = 1 n ∑ i = 1 n X i k , k = 1 , 2 , ⋯ \displaystyle A_k = \frac{1}{n} \sum_{i=1}^n X_i^k,\quad k=1,2,\cdots Ak=n1i=1∑nXik,k=1,2,⋯
-
样本 k k k 阶中心矩: B k = 1 n ∑ i = 1 n ( X i − X ‾ ) k , k = 2 , 3 , ⋯ \displaystyle B_k = \frac{1}{n} \sum_{i=1}^n (X_i-\overline{X})^k,\quad k=2,3,\cdots Bk=n1i=1∑n(Xi−X)k,k=2,3,⋯
二、次序统计量
- 序列最小值
- 序列最大值
- 极差 = 序列最大值 - 序列最小值
6.4 正态总体抽样分布定理
{% note light %}
时刻牢记一句话:构造性定义!
{% endnote %}
6.4.1 卡方分布、t 分布、F 分布
分位数
- 我们定义实数 λ α \lambda_\alpha λα 为随机变量 X X X 的上侧 α \alpha α 分位数(点)当且仅当 P ( X > λ α ) = α P(X > \lambda_\alpha) = \alpha P(X>λα)=α
- 我们定义实数 λ 1 − β \lambda_{1-\beta} λ1−β 为随机变量 X X X 的下侧 β \beta β 分位数(点)当且仅当 P ( X < λ 1 − β ) = β P(X < \lambda_{1-\beta})=\beta P(X<λ1−β)=β
χ 2 \chi^2 χ2 分布
{% fold light @密度函数图像 %}

{% endfold %}
定义:
- 对于 n n n 个独立同分布的标准正态随机变量 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots ,X_n X1,X2,⋯,Xn,若 Y = X 1 2 + X 2 2 + ⋯ + X n 2 Y = X_1^2 + X_2^2 + \cdots + X_n^2 Y=X12+X22+⋯+Xn2
- 则 Y Y Y 服从自由度为 n n n 的 χ 2 \chi^2 χ2 分布,记作: Y ∼ χ 2 ( n ) Y \sim \chi^2(n) Y∼χ2(n)
性质:
-
可加性:若 Y 1 ∼ χ 2 ( n 1 ) , Y 2 ∼ χ 2 ( n 2 ) Y_1 \sim \chi^2(n_1), Y_2 \sim \chi^2(n_2) Y1∼χ2(n1),Y2∼χ2(n2) 且 Y 1 , Y 2 Y_1,Y_2 Y1,Y2 相互独立,则 Y 1 + Y 2 ∼ χ 2 ( n 1 + n 2 ) Y_1+Y_2 \sim \chi^2(n_1+n_2) Y1+Y2∼χ2(n1+n2)
-
统计性:对于 Y ∼ χ 2 ( n ) Y \sim \chi^2(n) Y∼χ2(n),有 E Y = n , D Y = 2 n EY = n, DY = 2n EY=n,DY=2n
{% fold light @推导 %}
EY 的推导利用: E X 2 = D X − ( E X ) 2 EX^2 = DX - (EX)^2 EX2=DX−(EX)2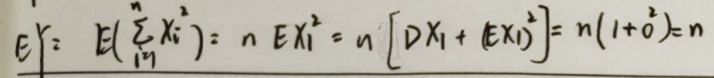
DY 的推导利用:方差计算公式、随机变量函数的数学期望进行计算
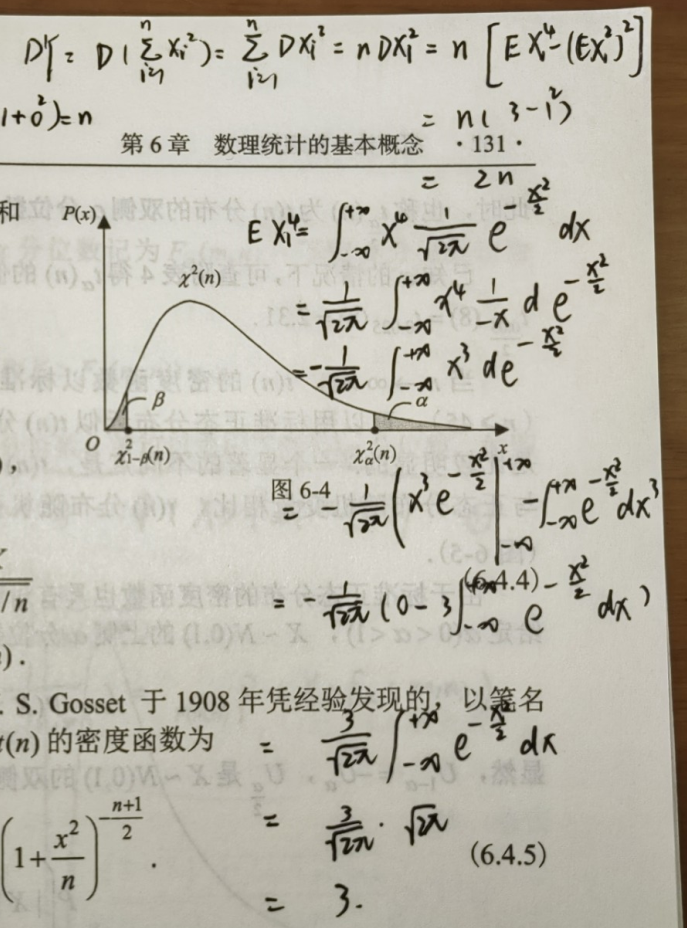
{% endfold %}
t t t 分布
{% fold light @密度函数图像 %}

{% endfold %}
定义:
- 若随机变量 X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) X \sim N(0, 1),Y \sim \chi^2 (n) X∼N(0,1),Y∼χ2(n) 且 X , Y X,Y X,Y 相互独立
- 则称随机变量 T = X Y / n T = \displaystyle \frac{X}{\sqrt{Y/n}} T=Y/nX 为服从自由度为 n n n 的 t t t 分布,记作 T ∼ t ( n ) T \sim t(n) T∼t(n)
性质:
- 密度函数是偶函数,具备对称性
F F F 分布
{% fold light @密度函数图像 %}

{% endfold %}
定义:
- 若随机变量 X ∼ χ 2 ( m ) , Y ∼ χ 2 ( n ) X \sim \chi^2(m), Y \sim \chi^2(n) X∼χ2(m),Y∼χ2(n) 且相互独立
- 则称随机变量 G = X / m Y / n G=\displaystyle \frac{X/m}{Y/n} G=Y/nX/m 服从自由度为 ( m , n ) (m,n) (m,n) 的 F F F 分布,记作 G ∼ F ( m , n ) G \sim F(m, n) G∼F(m,n)
性质:
- 倒数自由度转换: 1 G ∼ F ( n , m ) \displaystyle \frac{1}{G} \sim F(n, m) G1∼F(n,m)
- 三变性质: F 1 − α ( m , n ) = [ F α ( n , m ) ] − 1 \displaystyle F_{1-\alpha}(m, n) = \left [F_\alpha (n, m)\right]^{-1} F1−α(m,n)=[Fα(n,m)]−1
6.4.2 正态总体抽样分布基本定理
设 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots ,X_n X1,X2,⋯,Xn 是来自正态总体 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2) 的简单随机样本, X ‾ , S 2 \overline{X},S^2 X,S2 分别是样本均值和修正样本方差。则有:
定理:
- X ‾ ∼ N ( μ , σ 2 n ) \displaystyle \overline{X} \sim N(\mu, \frac{\sigma^2}{n}) X∼N(μ,nσ2)
- ( n − 1 ) S 2 σ 2 ∼ χ 2 ( n − 1 ) \displaystyle \frac{(n-1)S^2}{\sigma^2} \sim \chi^2(n-1) σ2(n−1)S2∼χ2(n−1)
- X ‾ \overline{X} X 和 S 2 S^2 S2 相互独立
推论:
- n ( X ‾ − μ ) S ∼ t ( n − 1 ) \displaystyle \frac{\sqrt{n}(\overline{X} - \mu)}{S} \sim t(n-1) Sn(X−μ)∼t(n−1)
第7章 参数估计
{% note light %}
有些时候我们知道数据的分布类型,但是不清楚表达式中的某些参数,这就需要我们利用「已有的样本」对分布表达式中的参数进行估计。本章我们将从点估计、估计评价、区间估计三部分出发进行介绍。
{% endnote %}
7.1 点估计
{% note light %}
所谓点估计策略,就是直接给出参数的一个估计值。本目我们介绍点估计策略中的两个方法:矩估计法、极大似然估计法。
{% endnote %}
7.1.1 矩估计法
其实就一句话:我们用样本的原点矩 A k A_k Ak 来代替总体 E ( X k ) E(X^k) E(Xk), k k k 个未知参数就需要用到 k k k 个原点矩:
E ( X k ) = A k = 1 n ∑ i = 1 n X i k E(X^k) = A_k = \frac{1}{n}\sum_{i=1}^nX_i^k E(Xk)=Ak=n1i=1∑nXik
7.1.2 极大似然估计法
基本原理是:在当前样本数据的局面下,我们希望找到合适的参数使得当前的样本分布情况发生的概率最大。由于各样本相互独立,因此我们可以用连乘的概率公式来计算当前局面的概率值:
L ( θ ; x 1 , x 2 , ⋯ , x n ) L(\theta;x_1,x_2,\cdots,x_n) L(θ;x1,x2,⋯,xn)
上述 L ( θ ; x 1 , x 2 , ⋯ , x n ) L(\theta;x_1,x_2,\cdots,x_n) L(θ;x1,x2,⋯,xn) 即似然函数,目标就是选择适当的参数 θ \theta θ 来最大化似然函数。无论是离散性还是连续型,都可以采用下面的方式来计算极大似然估计:
- 写出似然函数 L ( θ ) L(\theta) L(θ)
- 将上述似然函数取对数
- 求对数似然函数关于所有未知参数的偏导并计算极值点
- 解出参数关于样本统计量的表达式
离散型随机变量的似然函数表达式
L ( θ ) = ∏ i = 1 n p ( x i ; θ ) = ∏ i = 1 n P ( X i = x i ) L(\theta) = \prod_{i=1}^n p(x_i;\theta) = \prod_{i=1}^n P(X_i = x_i) L(θ)=i=1∏np(xi;θ)=i=1∏nP(Xi=xi)
连续型随机变量的似然函数表达式
L ( θ ) = ∏ i = 1 n p ( x i ; θ ) L(\theta) = \prod_{i=1}^n p(x_i;\theta) L(θ)=i=1∏np(xi;θ)
可以看出极大似然估计本质上就是一个多元函数求极值的问题。特别地,当我们没法得到参数关于样本统计量的表达式 L ( θ ) L(\theta) L(θ) 时,可以直接从定义域、原函数恒增或恒减等角度出发求解这个多元函数的极值。
7.2 估计量的评价标准
{% note light %}
如何衡量不同的点估计方法好坏?我们引入三种点估计量的评价指标:无偏性、有效性、一致性。其中一致性一笔带过,不做详细讨论。补充一点,参数的估计量 θ \theta θ 是关于样本的统计量,因此可以对其进行求期望、方差等操作。
{% endnote %}
7.2.1 无偏性
顾名思义,就是希望估计出来的参数量尽可能不偏离真实值。我们定义满足下式的估计量 θ ^ \hat \theta θ^ 为真实参数的无偏估计:
E θ ^ = θ E\hat \theta =\theta Eθ^=θ
7.2.2 有效性
有效性是基于比较的定义方法。对于两个无偏估计 θ ^ 1 , θ ^ 2 \hat\theta_1,\hat\theta_2 θ^1,θ^2,谁的方差越小谁就越有效。即若 D ( θ ^ 1 ) , D ( θ ^ 2 ) D(\hat\theta_1),D(\hat\theta_2) D(θ^1),D(θ^2) 满足下式,则称 θ ^ 1 \hat\theta_1 θ^1 更有效
D ( θ ^ 1 ) < D ( θ ^ 2 ) D(\hat\theta_1) < D(\hat\theta_2) D(θ^1)<D(θ^2)
7.2.3 一致性
即当样本容量 n 趋近于无穷时,参数的估计值也能趋近于真实值,则称该估计量 θ ^ \hat\theta θ^ 为 θ \theta θ 的一致估计量
7.3 区间估计
{% note light %}
由于点估计只能进行比较,无法对单一估计进行性能度量。因此引入「主元法」的概念与「区间估计」策略
{% endnote %}
7.3.1 基本概念
可靠程度:参数估计区间越长,可靠程度越高
精确程度:参数估计区间越短,可靠程度越高
7.3.2 区间估计常用方法之主元法
主元法的核心逻辑就一个:在已知数据总体分布的情况下,构造一个关于样本 X X X 和待估参数 θ \theta θ 的函数 Z ( X , θ ) Z(X,\theta) Z(X,θ),然后利用置信度和总体分布函数,通过查表得到 Z ( X , θ ) Z(X,\theta) Z(X,θ) 的取值范围,最后通过移项变形得到待估参数的区间,也就是估计区间。
7.3.3 正态总体的区间估计
我们只需要掌握「一个总体服从正态分布」的情况。这种情况下的区间估计分为三种,其中估计均值 μ \mu μ 有 2 种,估计方差 σ 2 \sigma^2 σ2 有 1 种。估计的逻辑我总结为了以下三步:
- 构造主元 Z ( X , θ ) Z(X,\theta) Z(X,θ)
- 利用置信度 1 − α 1-\alpha 1−α 计算主元 Z Z Z 的取值范围
- 对主元 Z Z Z 的取值范围移项得到参数 θ \theta θ 的取值范围
为了提升区间估计的可信度,我们希望上述第 2 步计算出来的关于主元的取值范围尽可能准确。我们不加证明的给出以下结论:取主元的取值范围为 主元服从的分布的上下 α 2 \frac{\alpha}{2} 2α 分位数之间。
(一) 求 μ \mu μ 的置信区间, σ 2 \sigma^2 σ2 已知
构造主元 Z ( X , θ ) Z(X,\theta) Z(X,θ):
Z = X ‾ − μ σ / n ∼ N ( 0 , 1 ) Z = \frac{\overline{X} - \mu}{\sigma / \sqrt{n}} \sim N(0,1) Z=σ/nX−μ∼N(0,1)
利用置信度 1 − α 1-\alpha 1−α 计算主元 Z Z Z 的取值范围:
P ( ∣ Z ∣ ≤ λ ) = 1 − α ↓ Z ∈ [ − λ , λ ] = [ − u α 2 , u α 2 ] \begin{aligned} P(|Z| \le \lambda) &= 1-\alpha \\ &\downarrow\\ Z \in [-\lambda,\lambda] &= [-u_{\frac{\alpha}{2}},u_\frac{\alpha}{2}] \end{aligned} P(∣Z∣≤λ)Z∈[−λ,λ]=1−α↓=[−u2α,u2α]
对主元 Z Z Z 的取值范围移项得到参数 θ \theta θ 的取值范围:
X ‾ − σ n u α 2 ≤ μ ≤ X ‾ + σ n u α 2 \overline{X} - \frac{\sigma}{\sqrt{n}} u_\frac{\alpha}{2} \le \mu \le \overline{X} + \frac{\sigma}{\sqrt{n}} u_\frac{\alpha}{2} X−nσu2α≤μ≤X+nσu2α
(二) 求 μ \mu μ 的置信区间, σ 2 \sigma^2 σ2 未知
构造主元 Z ( X , θ ) Z(X,\theta) Z(X,θ):
Z = X ‾ − μ S / n ∼ t ( n − 1 ) Z = \frac{\overline{X} - \mu}{S / \sqrt{n}} \sim t(n-1) Z=S/nX−μ∼t(n−1)
利用置信度 1 − α 1-\alpha 1−α 计算主元 Z Z Z 的取值范围:
P ( ∣ Z ∣ ≤ λ ) = 1 − α ↓ Z ∈ [ − λ , λ ] = [ − t α 2 ( n − 1 ) , t α 2 ( n − 1 ) ] \begin{aligned} P(|Z| \le \lambda) &= 1-\alpha \\ &\downarrow\\ Z \in [-\lambda,\lambda] &= [-t_{\frac{\alpha}{2}}(n-1),t_\frac{\alpha}{2}(n-1)] \end{aligned} P(∣Z∣≤λ)Z∈[−λ,λ]=1−α↓=[−t2α(n−1),t2α(n−1)]
对主元 Z Z Z 的取值范围移项得到参数 θ \theta θ 的取值范围:
X ‾ − S n t α 2 ( n − 1 ) ≤ μ ≤ X ‾ + S n t α 2 ( n − 1 ) \overline{X} - \frac{S}{\sqrt{n}} t_\frac{\alpha}{2}(n-1) \le \mu \le \overline{X} + \frac{S}{\sqrt{n}} t_\frac{\alpha}{2}(n-1) X−nSt2α(n−1)≤μ≤X+nSt2α(n−1)
(三) 求 σ 2 \sigma^2 σ2 的置信区间,构造的主元与总体均值无关,因此不需要考虑 μ \mu μ 的情况:
构造主元 Z ( X , θ ) Z(X,\theta) Z(X,θ):
Z = ( n − 1 ) S 2 σ 2 ∼ χ 2 ( n − 1 ) Z = \frac{(n-1)S^2}{\sigma^2}\sim \chi^2(n-1) Z=σ2(n−1)S2∼χ2(n−1)
利用置信度 1 − α 1-\alpha 1−α 计算主元 Z Z Z 的取值范围:
P ( λ 1 ≤ Z ≤ λ 2 ) = 1 − α ↓ Z ∈ [ λ 1 , λ 2 ] = [ χ 1 − α 2 2 ( n − 1 ) , χ α 2 2 ( n − 1 ) ] \begin{aligned} P(\lambda_1 \le Z \le \lambda_2) &= 1-\alpha \\ &\downarrow\\ Z \in [\lambda_1,\lambda_2] &= [\chi^2_{1-\frac{\alpha}{2}}(n-1),\chi^2_\frac{\alpha}{2}(n-1)] \end{aligned} P(λ1≤Z≤λ2)Z∈[λ1,λ2]=1−α↓=[χ1−2α2(n−1),χ2α2(n−1)]
对主元 Z Z Z 的取值范围移项得到参数 θ \theta θ 的取值范围:
( n − 1 ) S 2 χ α 2 2 ( n − 1 ) ≤ σ 2 ≤ ( n − 1 ) S 2 χ 1 − α 2 2 ( n − 1 ) \frac{(n-1)S^2}{\chi^2_\frac{\alpha}{2}(n-1)} \le \sigma^2 \le \frac{(n-1)S^2}{\chi^2_{1-\frac{\alpha}{2}}(n-1)} χ2α2(n−1)(n−1)S2≤σ2≤χ1−2α2(n−1)(n−1)S2
第8章 假设检验
{% note light %}
第 7 章的参数估计是在总体分布已知且未知分布表达式中某些参数的情况下,基于「抽取的少量样本」进行的参数估计。
现在的局面同样,我们已知总体分布和不完整的分布表达式参数。现在需要我们利用抽取的少量样本判断样本所在向量空间是否符合某种性质。本章的「假设检验」策略就是为了解决上述情况而诞生的。我们主要讨论单个正态总体的情况并针对均值和方差两个参数进行假设和检验:
- 假设均值满足某种趋势,利用已知数据判断假设是否成立
- 假设方差满足某种趋势,利用已知数据判断假设是否成立
{% endnote %}
8.1 假设检验的基本概念
基本思想:首先做出假设并构造一个关于样本观察值和已知参数的检验统计量,接着计算假设发生的情况下小概率事件发生时该检验统计量的取值范围(拒绝域),最终代入已知样本数据判断计算结果是否在拒绝域内。如果在,则说明在当前假设的情况下小概率事件发生了,对应的假设为假;反之说明假设为真。
为了量化「小概率事件发生」这个指标,我们引入显著性水平 α \alpha α 这一概念。该参数为一个很小的正数,定义为「小概率事件发生」的概率上界。
基于数据的实验导致我们无法避免错误,因此我们定义以下两类错误:
- 第一类错误:弃真错误。即假设正确,但由于数据采样不合理导致拒绝了真实的假设
- 第二类错误:存伪错误。即假设错误,同样因为数据的不合理导致接受了错误的假设
8.2 单个正态总体均值的假设检验
设 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots ,X_n X1,X2,⋯,Xn 是来自正态总体 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2) 的简单随机样本。后续进行假设判定计算统计量 Z Z Z 的真实值时,若总体均值 μ \mu μ 已知就直接代入,若未知题目也一定会给一个阈值,代这个阈值即可。
当总体方差 σ 2 \sigma^2 σ2 已知时,我们构造样本统计量 Z Z Z 为正态分布:
Z = X ‾ − μ σ / n ∼ N ( 0 , 1 ) Z = \frac{\overline{X} - \mu}{\sigma / \sqrt{n}} \sim N(0,1) Z=σ/nX−μ∼N(0,1)
- 检验是否则求解双侧 α \alpha α 分位数
- 检验单边则求解单侧 α \alpha α 分位数
当总体方差 σ 2 \sigma^2 σ2 未知时,我们构造样本统计量 Z Z Z 为 t t t 分布:
Z = X ‾ − μ S / n ∼ t ( n − 1 ) Z = \frac{\overline{X} - \mu}{S / \sqrt{n}} \sim t(n-1) Z=S/nX−μ∼t(n−1)
{% note warning %}
注:之所以这样构造是因为当总体 σ \sigma σ 未知时,上一个方法构造的主元已经不再是统计量,我们需要找到能够代替未知参数 σ \sigma σ 的变量,这里就采用其无偏估计「修正样本方差 S 2 S^2 S2」来代替 σ 2 \sigma^2 σ2。也是说直接拿样本的修正方差来代替总体的方差了。
{% endnote %}
- 检验是否则求解双侧 α \alpha α 分位数
- 检验单边则求解单侧 α \alpha α 分位数
8.3 单个正态总体方差的假设检验
设 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots ,X_n X1,X2,⋯,Xn 是来自正态总体 N ( μ , σ 2 ) N(\mu, \sigma^2) N(μ,σ2) 的简单随机样本。后续进行假设判定计算统计量 Z Z Z 的真实值时,若总体方差 σ 2 \sigma^2 σ2 已知就直接代入,若未知题目也一定会给一个阈值,代这个阈值即可。
我们直接构造样本统计量 Z Z Z 为 χ 2 \chi^2 χ2 分布:
Z = ( n − 1 ) S 2 σ 2 ∼ χ 2 ( n − 1 ) Z = \frac{(n-1)S^2}{\sigma^2} \sim \chi^2(n-1) Z=σ2(n−1)S2∼χ2(n−1)
- 检验是否则求解双侧 α \alpha α 分位数
- 检验单边则求解单侧 α \alpha α 分位数
相关文章:
概率论与数理统计_下_科学出版社
contents 前言第5章 大数定律与中心极限定理独立同分布中心极限定理 第6章 数理统计的基本概念6.1 总体与样本6.2 经验分布与频率直方图6.3 统计量6.4 正态总体抽样分布定理6.4.1 卡方分布、t 分布、F 分布6.4.2 正态总体抽样分布基本定理 第7章 参数估计7.1 点估计7.1.1 矩估计…...

Android 复习layer-list使用
<shape android:shape"rectangle"> <size android:width"1dp" android:height"100px" /> <solid android:color"#FFFFFF" /> </shape> 通过shape画线段,通过 <item android:gravity"left|top"…...

汉光联创HGLM2200N黑白激光多功能一体机加粉及常见问题处理
基本参数: 机器型号:HGLM2200N 产品名称:A4黑白激光多功能一体机 基础功能:打印、扫描、复印 打印速度:22页/分钟 纸张输入容量:150-249页 单面支持纸张尺寸:A4、A5、A6 产品尺寸&#x…...

引领汽车软件开发走向ASPICE认证之路
亚远景科技与ASPICE认证的关系可以从以下几个方面来阐述: (要明确的是:在ASPICE行业中专业来说,ASPICE项目是没有认证,而只有评估。不过,为了方便沟通,人们常将这一评估过程称为认证。) 行业专…...

【C/C++ new/delete和malloc/free的异同及原理】
new/delete和malloc/free都是用于在C(以及C语言在malloc/free的情况下)中动态申请和释放内存的机制,但它们之间存在一些显著的异同点。以下是对这两组函数/运算符的异同点的详细分析: 相同点 目的相同:两者都用于在堆…...

Maven Archetype 自定义项目模板:高效开发的最佳实践
文章目录 前言一、Maven Archetype二、创建自定义 Maven Archetype三、定制 Archetype 模板四、手动创建 Archetype 模板项目五、FAQ5.1 如何删除自定义的模板5.2 是否可以在模板中使用空文件夹 六、小结推荐阅读 前言 在软件开发中,标准化和快速初始化项目结构能够…...

vue的ESLint 4格缩进 笔记
https://chatgpt.com/share/738c8560-5271-45c4-9de0-511fad862109 一,代码4格缩进设置 .eslintrc.js文件 module.exports { "rules": { "indent": ["error", 4] } }; 自动修复命令 npx eslint --fix "src/**/*.{…...
【前端项目笔记】8 订单管理
订单管理 效果展示: 在开发功能之前先创建分支order cls 清屏 git branch 查看所有分支(*代表当前分支) git checkout -b order 新建分支order git push -u origin order 将本地的当前分支提交到云端仓库origin中命名为order 通过路由方式…...

构建Yarn依赖树:深入解析与实践指南
构建Yarn依赖树:深入解析与实践指南 在现代JavaScript开发中,依赖管理是项目成功的关键。Yarn,作为Node.js生态系统中一个强大的包管理器,以其快速、可靠和安全的特性而闻名。本文将深入探讨Yarn如何构建依赖树,并提供…...

社区活动|FlowUs知识库的发展|先进技术的落地应用|下一代生产力工具你用了吗
在当今快速发展的数字化时代,技术的进步不断推动着工作方式和知识管理的革新。FlowUs,作为一款前沿的知识管理和协作平台,正站在这一变革的浪潮之巅,引领着智能工作的新潮流。 智能化的智能学习引导工具 FlowUs不仅仅是一个工具&…...

Python基础语法(与C++对比)(持续更新ing)
代码块 Python在统一缩进体系内,为同一代码块C{...}内部的为同一代码块 注释 Python 单行注释:#... 多行注释:... C 单行注释://... 多行注释: /*...*/ 数据类型 1. Python数据类型 Python中支持数字之间使用下划线 _ 分割…...

LeetCode-Leetcode 1120:子树的最大平均值
LeetCode-Leetcode 1120:子树的最大平均值 题目描述:解题思路一:递归解题思路二:0解题思路三:0 题目描述: 给你一棵二叉树的根节点 root,找出这棵树的 每一棵 子树的 平均值 中的 最大 值。 子…...

AI在软件开发中的角色:助手还是取代者?
目录 前言 一、AI工具现状:高效助手的崛起 二、AI对开发者的影响:新技能与竞争力的重塑 三、AI开发的未来:共生而非取代 写在最后 前言 随着科技的飞速发展,生成式人工智能(AIGC)在软件开发领域的应用日…...

jboss 7.2
链接: https://pan.baidu.com/s/19PSAy-Wy8DjcUMy94eqWnw 提取码: rgxf 复制这段内容后打开百度网盘手机App,操作更方便哦 --来自百度网盘超级会员v3的分享链接: https://pan.baidu.com/s/19PSAy-Wy8DjcUMy94eqWnw 提取码: rgxf 复制这段内容后打开百度网盘手机App…...
鸿蒙开发:Universal Keystore Kit(密钥管理服务)【密钥生成介绍及算法规格】
密钥生成介绍及算法规格 当业务需要使用HUKS生成随机密钥,并由HUKS进行安全保存时,可以调用HUKS的接口生成密钥。 注意: 密钥别名中禁止包含个人数据等敏感信息。 开发前请熟悉鸿蒙开发指导文档:gitee.com/li-shizhen-skin/harm…...

电气-伺服(4)CANopen
一、CAN Controller Area Network ,控制器局域网,80年的德国Bosch的一家公司研发可以测量仪器直接的实时数据交换而开发的一款串行通信协议。 CAN发展历史 二、CAN 的osi 模型 CAN特性: CAN 的数据帧 三、CANopen 什么是CANopen CANopen 的网络模型 …...

JavaFx基础知识
1.Stage 舞台 如此这样的一个框框,舞台只是这个框框,并不管里面的内容 public void start(Stage primaryStage) throws Exception {primaryStage.setScene(new Scene(new Group()));primaryStage.getIcons().add(new Image("/icon/img.png"))…...
学会python——用python制作一个登录和注册窗口(python实例十八)
目录 1.认识Python 2.环境与工具 2.1 python环境 2.2 Visual Studio Code编译 3.登录和注册窗口 3.1 代码构思 3.2 代码实例 3.3 运行结果 4.总结 1.认识Python Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。 Python 的设计具有很强的可读…...

Vue3+Element-plus的表单重置
作用:简化代码,重置表单数据 1.创建表单,绑定表单数据对象model,并且每一表单需要绑定prop <el-button type"primary" click"Formreset">重置</el-button> <el-form :inline"true" :model"fromModel" ref"form&q…...

pytorch中的contiguous()
官方文档:https://pytorch.org/docs/stable/generated/torch.Tensor.contiguous.html 其描述contiguous为: Returns a contiguous in memory tensor containing the same data as self tensor. If self tensor is already in the specified memory forma…...

B站视频缓存转换终极指南:5秒完成m4s到MP4的无损转换
B站视频缓存转换终极指南:5秒完成m4s到MP4的无损转换 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的教…...

基于Arduino与ADXL335的自制地震预警系统:从传感器原理到多点联动实现
1. 项目概述与核心思路最近在捣鼓一个挺有意思的玩意儿——一个能自主工作的地震预警系统。这可不是什么高深莫测的科研项目,而是基于一些常见的电子模块,自己动手就能搭建起来的实用装置。它的核心目标很明确:当检测到建筑物出现异常振动时&…...

CSS盒模型完全指南
CSS盒模型完全指南 引言 CSS盒模型是理解CSS布局的基础,每个HTML元素都可以看作一个矩形盒子。本文将深入探讨盒模型的核心概念、使用方法和最佳实践。 一、盒模型基础 1.1 盒模型组成 .element {width: 300px;height: 200px;padding: 20px;border: 5px solid #333;…...

崩坏星穹铁道自动化终极指南:3分钟学会解放双手的游戏助手
崩坏星穹铁道自动化终极指南:3分钟学会解放双手的游戏助手 【免费下载链接】StarRailAssistant 崩坏:星穹铁道自动化 | 崩坏:星穹铁道自动锄大地 | 崩坏:星穹铁道锄大地 | 自动锄大地 | 基于模拟按键 项目地址: https://gitcode…...

CNN 卷积神经网络面试全集|卷积、池化、感受野
前言 计算机视觉算法岗必考核心就是 CNN,从基础卷积运算、池化操作,到经典网络结构、感受野、参数量计算全是高频考题。本文整理最全 CNN 面试精简答案,条理清晰直接背诵,视觉方向面试稳稳通关。 一、CNN 整体三大核心结构 卷积层:提取局部纹理、边缘、形状等空间特征 池…...

微波流式细胞术与机器学习融合:实现非球形微塑料全电子化形态检测
1. 项目概述与核心挑战微塑料污染已成为全球性的环境与健康威胁,其检测与表征是环境科学领域的一项关键技术挑战。传统的主流检测方法,如傅里叶变换红外光谱(FTIR)和拉曼光谱,虽然能够提供高精度的化学成分鉴定&#x…...

符号的魔法:数学、物理、化学中那些有趣的故事
🔬 符号的魔法:数学、物理、化学中那些有趣的故事 📖 开篇:为什么符号如此重要? 想象一下,如果没有符号: ❌ 没有数学符号: “一个数加上另一个数等于第三个数,如果第一个…...

深入理解css-grid-polyfill原理:从源码角度解析实现机制
深入理解css-grid-polyfill原理:从源码角度解析实现机制 【免费下载链接】css-grid-polyfill A working implementation of css grids for current browsers. 项目地址: https://gitcode.com/gh_mirrors/cs/css-grid-polyfill CSS Grid布局是现代Web开发中强…...

告别卡顿!用IL2CPP优化你的Unity游戏:性能提升与包体瘦身实测
告别卡顿!用IL2CPP优化你的Unity游戏:性能提升与包体瘦身实测最近在优化一款Unity游戏时,我发现了一个令人头疼的问题:游戏在低端设备上频繁卡顿,包体大小也超出了预期。经过一番探索,我决定尝试将脚本后端…...
)
别急着买云服务器!手把手教你用闲置Win10电脑搭建个人SSH服务器(保姆级教程)
闲置Win10变身SSH服务器:零成本打造远程开发环境家里那台吃灰的旧电脑,其实藏着个免费云服务器——这话听起来像天方夜谭?去年我用一台2015年的联想笔记本搭建的SSH服务器,至今稳定运行着三个Python爬虫和两个测试项目。下面这套方…...