Kafka-服务端-网络层-源码流程
整体架构如下所示:
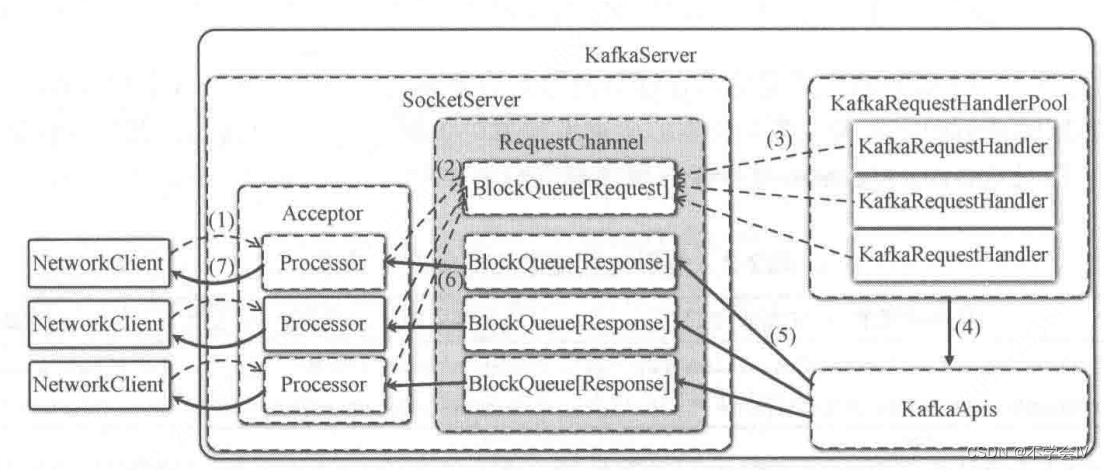
responseQueue不在RequestChannel中,在Processor中,每个Processor内部有一个responseQueue
- 客户端发送的请求被Acceptor转发给Processor处理
- 处理器将请求放到RequestChannel的requestQueue中
- KafkaRequestHandler取出requestQueue中的请求
- 调用KafkaApis进行业务逻辑处理
- KafkaApis将响应结果放到对应的Processor的responseQueue中
- processor从responseQueue中取出响应结果
- processor将响应结果返回给客户端
KafkaServer是Kafka服务端的主类,KafkaServer中和网络成相关的服务组件包括SocketServer、KafkaApis和KafkaRequestHandlerPool。SocketServer主要关注网络层的通信协议,具体的业务处理逻辑则交给KafkaRequestHandler和KafkaApis来完成。
class KafkaServer(val config: KafkaConfig) {def startup() {socketServer = new SocketServer(config, metrics, time, credentialProvider)socketServer.startup(startupProcessors = false)/* start processing requests */apis = new KafkaApis(socketServer.requestChannel, ...)requestHandlerPool = new KafkaRequestHandlerPool(config.brokerId, ...)}}
SocketServer
def startup(startupProcessors: Boolean = true) {this.synchronized {...createAcceptorAndProcessors(config.numNetworkThreads, config.listeners)if (startupProcessors) {startProcessors()}}private def createAcceptorAndProcessors(processorsPerListener: Int,endpoints: Seq[EndPoint]): Unit = synchronized {...endpoints.foreach { endpoint =>...val acceptor = new Acceptor(endpoint, ...)addProcessors(acceptor, endpoint, processorsPerListener)KafkaThread.nonDaemon(s"kafka-socket-acceptor-$listenerName-$securityProtocol-${endpoint.port}", acceptor).start()acceptor.awaitStartup()acceptors.put(endpoint, acceptor)}}
可以看出SocketServer.startup()中会根据listener的个数创建相同个数的acceptor,每个acceptor关联数个processor。这是一种典型的Reactor模式,acceptor负责与客户端建立连接,并将连接分发给processor,processor负责所分连接后续的所有读写交互。
Acceptor
def run() {serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)startupComplete()try {var currentProcessor = 0while (isRunning) {try {val ready = nioSelector.select(500)if (ready > 0) {val keys = nioSelector.selectedKeys()val iter = keys.iterator()while (iter.hasNext && isRunning) {try {val key = iter.nextiter.remove()if (key.isAcceptable) {val processor = synchronized {currentProcessor = currentProcessor % processors.sizeprocessors(currentProcessor)}accept(key, processor)} elsethrow new IllegalStateException("Unrecognized key state for acceptor thread.")// round robin to the next processor thread, mod(numProcessors) will be done latercurrentProcessor = currentProcessor + 1} catch {case e: Throwable => error("Error while accepting connection", e)}}}}catch {// We catch all the throwables to prevent the acceptor thread from exiting on exceptions due// to a select operation on a specific channel or a bad request. We don't want// the broker to stop responding to requests from other clients in these scenarios.case e: ControlThrowable => throw ecase e: Throwable => error("Error occurred", e)}}} finally {debug("Closing server socket and selector.")CoreUtils.swallow(serverChannel.close(), this, Level.ERROR)CoreUtils.swallow(nioSelector.close(), this, Level.ERROR)shutdownComplete()}}
上面是Acceptor的run()方法,可以看出,Acceptor在通道上注册了SelectionKey.OP_ACCEPT事件(OP_READ、OP_WRITE、OP_CONNECT、OP_ACCEPT,客户端监听OP_CONNECT事件,负责发起连接,服务端监听OP_CONNECT事件,负责建立连接),负责与客户端建立连接。并将建立的连接通过轮询的方式指派给processor。
Processor
每个Processor都会分到数个与客户端的连接。Processor的处理逻辑如下所示:
override def run() {startupComplete()try {while (isRunning) {try {// 在新分到的客户端连接上注册OP_READ事件configureNewConnections()// 从responseQueue中取响应,赋值给KafkaChannel的send,等待poll时发送processNewResponses()// selector轮询各种事件,读取请求或者发送响应poll()// 封装selector.completedReceives中的请求,放入requestQueueprocessCompletedReceives()// 处理selector.completedSends响应(移除inflightResponses中的记录;执行响应的回调函数)processCompletedSends()processDisconnected()} catch {...}}} finally {...}}
Processor线程的名字中有kafka-network字样,可以通过jstack -l pid | grep kafka-network进行筛选。
KafkaRequestHandlerPool
KafkaServer会创建请求处理线程池(KafkaRequestHandlerPool),在请求处理线程池中会创建并启动多个请求处理线程(KafkaRequestHandler)。KafkaRequestHandler会获取RequestChannel.requestQueue中的请求进行处理,在内部实际处理会交给KafkaApis完成。
class KafkaRequestHandlerPool(val brokerId: Int, ...) {...for (i <- 0 until numThreads) {createHandler(i)}def createHandler(id: Int): Unit = synchronized {runnables += new KafkaRequestHandler(..., requestChannel, apis, time)KafkaThread.daemon("kafka-request-handler-" + id, runnables(id)).start()}
}
KafkaRequestHandler的run()方法如下:
class KafkaRequestHandler(id: Int,...) extends Runnable with Logging {...def run() {while (!stopped) {val req = requestChannel.receiveRequest(300)req match {case RequestChannel.ShutdownRequest =>shutdownComplete.countDown()returncase request: RequestChannel.Request =>try {request.requestDequeueTimeNanos = endTimeapis.handle(request)} catch {case e: FatalExitError =>shutdownComplete.countDown()Exit.exit(e.statusCode)case e: Throwable => error("Exception when handling request", e)} finally {request.releaseBuffer()}case null => // continue}}shutdownComplete.countDown()}}
相关文章:
Kafka-服务端-网络层-源码流程
整体架构如下所示: responseQueue不在RequestChannel中,在Processor中,每个Processor内部有一个responseQueue 客户端发送的请求被Acceptor转发给Processor处理处理器将请求放到RequestChannel的requestQueue中KafkaRequestHandler取出reque…...

百日筑基第十一天-看看SpringBoot
百日筑基第十一天-看看SpringBoot 创建项目 Spring 官方提供了 Spring Initializr 的方式来创建 Spring Boot 项目。网址如下: https://start.spring.io/ 打开后的界面如下: 可以将 Spring Initializr 看作是 Spring Boot 项目的初始化向导ÿ…...

Generative Modeling by Estimating Gradients of the Data Distribution
Generative Modeling by Estimating Gradients of the Data Distribution 本文介绍宋飏提出的带噪声扰动的基于得分的生成模型。首先介绍基本的基于得分的生成模型的训练方法(得分匹配)和采样方法(朗之万动力学)。然后基于流形假…...

vector与list的简单介绍
1. 标准库中的vector类的介绍: vector是表示大小可以变化的数组的序列容器。 就像数组一样,vector对其元素使用连续的存储位置,这意味着也可以使用指向其元素的常规指针上的偏移量来访问其元素,并且与数组中的元素一样高效。但与数…...

四种线程池的使用,优缺点分析
池化思想:线程池、字符串常量池、数据库连接池 提高资源的利用率 下面是手动创建线程和执行任务过程,可见挺麻烦的,而且线程利用率不高。 手动创建线程对象执行任务执行完毕,释放线程对象 线程池的优点: 提高线程的…...

什么是 BEM 规范
BEM(Block, Element, Modifier)是一种 CSS 命名规范,旨在提高代码的可读性和可维护性。BEM 规范通过明确的命名规则来定义组件和组件的各个部分,使开发者能够更容易地理解和维护代码。 BEM 命名规范的基本概念 Block(…...

【Node.JS】入门
文章目录 Node.js的入门涉及对其基本概念、特点、安装、以及基本使用方法的了解。以下是对Node.js入门的详细介绍: 一、Node.js基本概念和特点 定义:Node.js是一个基于Chrome V8引擎的JavaScript运行环境,它使得JavaScript能够运行在服务器…...

Amazon SageMaker 机器学习之旅的助推器
一、前言 在当今的数字化时代,人工智能和机器学习已经成为推动社会进步的重要引擎。亚马逊云科技在 2023 re:Invent 全球大会上,宣布推出五项 Amazon SageMaker 新功能: Amazon SageMaker HyperPod 通过为大规模分布式训练提供专用的基础架构…...

TransMIL:基于Transformer的多实例学习
MIL是弱监督分类问题的有力工具。然而,目前的MIL方法通常基于iid假设,忽略了不同实例之间的相关性。为了解决这个问题,作者提出了一个新的框架,称为相关性MIL,并提供了收敛性的证明。基于此框架,还设计了一…...

3.用户程序与驱动交互
驱动程序请使用第二章https://blog.csdn.net/chenhequanlalala/article/details/140034424 用户app与驱动交互最常见的做法是insmod驱动后,生成一个设备节点,app通过open,read等系统调用去操作这个设备节点,这里先用mknode命令调…...
尽量不写一行if...elseif...写出高质量可持续迭代的项目代码
背景 无论是前端代码还是后端代码,都存在着定位困难,不好抽离,改造困难的问题,造成代码开发越来越慢,此外因为代码耦合较高,总是出现改了一处地方,然后影响其他地方,要么就是要修改…...

xcrun: error: unable to find utility “simctl“, not a developer tool or in PATH
目录 前言 一、问题详情 二、解决方案 1.确认Xcode已安装 2.安装Xcode命令行工具 3.指定正确的开发者目录 4. 确认命令行工具路径 5. 更新PATH环境变量 前言 今天使用cocoapods更新私有库的时候,遇到了"xcrun: error: unable to find utility &…...

【linux高级IO(一)】理解五种IO模型
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:Linux从入门到精通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学更多操作系统知识 🔝🔝 Linux高级IO 1. 前言2. 重谈对…...

前端引用vue/element/echarts资源等引用方法Blob下载HTML
前端引用下载vue/element/echarts资源等引用方法 功能需求 需求是在HTML页面中集成Vue.js、Element Plus(Element UI的Vue 3版本)、ECharts等前端资源,使用Blob下载HTML。 解决方案概述 直接访问线上CDN地址:简单直接,…...

昇思MindSpore学习笔记2-01 LLM原理和实践 --基于 MindSpore 实现 BERT 对话情绪识别
摘要: 通过识别BERT对话情绪状态的实例,展现在昇思MindSpore AI框架中大语言模型的原理和实际使用方法、步骤。 一、环境配置 %%capture captured_output # 实验环境已经预装了mindspore2.2.14,如需更换mindspore版本,可更改下…...

uniapp实现图片懒加载 封装组件
想要的效果就是窗口滑动到哪里,哪里的图片进行展示 主要原理使用IntersectionObserver <template><view><image error"HandlerError" :style"imgStyle" :src"imageSrc" :id"randomId" :mode"mode&quo…...

持续交付:自动化测试与发布流程的变革
目录 前言1. 持续交付的概念1.1 持续交付的定义1.2 持续交付的核心原则 2. 持续交付的优势2.1 提高交付速度2.2 提高软件质量2.3 降低发布风险2.4 提高团队协作 3. 实施持续交付的步骤3.1 构建自动化测试体系3.1.1 单元测试3.1.2 集成测试3.1.3 功能测试3.1.4 性能测试 3.2 构建…...

VBA常用的字符串内置函数
前言 在VBA程序中,常用的内置函数可以按照功能分为字符串函数、数字函数、转换函数等等,本节主要会介绍常用的字符串的内置函数,包括Len()、Left()、Mid()、Right()、Split()、String()、StrConV()等。 本节的练习数据表以下表为例ÿ…...
)
大数据面试题之Spark(7)
目录 Spark实现wordcount Spark Streaming怎么实现数据持久化保存? Spark SQL读取文件,内存不够使用,如何处理? Spark的lazy体现在哪里? Spark中的并行度等于什么 Spark运行时并行度的设署 Spark SQL的数据倾斜 Spark的exactly-once Spark的…...

AI绘画 Stable Diffusion图像的脸部细节控制——采样器全解析
大家好,我是画画的小强 我们在运用AI绘画 Stable Diffusion 这一功能强大的AI绘图工具时,我们往往会发现自己对提示词的使用还不够充分。在这种情形下,我们应当如何调整自己的策略,以便更加精确、全面地塑造出理想的人物形象呢&a…...

Java并发编程:ReentrantReadWriteLock读写锁
前言在Java并发编程中,锁机制是保证线程安全的重要手段。synchronized和ReentrantLock都是排他锁,同一时刻只允许一个线程访问共享资源。但在实际业务场景中,读操作往往远多于写操作,如果多个读线程之间也要互相等待,会…...

【DeepSeek缓存策略设计权威指南】:20年架构师亲授5大核心原则与3类典型场景落地实践
更多请点击: https://intelliparadigm.com 第一章:DeepSeek缓存策略设计的演进脉络与核心挑战 DeepSeek系列模型在推理服务中对缓存机制提出了严苛要求:既要应对长上下文带来的KV缓存爆炸式增长,又要兼顾多用户并发、动态批处理与…...

大白菜与杂草识别分割数据集labelme格式2006张2类别
数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件)图片数量(jpg文件个数):2006标注数量(json文件个数):2006标注类别数:2标注类别名称:["baicai","zacao"]每个类别标注的框…...

论文提速的终极秘籍!常用的AI论文软件,秒出初稿不费力
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题纠结、资料收集困难、逻辑梳理不清、反复修改头疼、格式排版繁琐... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接翻倍,原本…...
)
【紧急预警】DeepSeek v2.3.1已确认存在默认策略绕过漏洞——立即核查你的access_control.yaml配置(附热补丁)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek访问控制配置 DeepSeek模型服务在企业级部署中需严格遵循最小权限原则,访问控制配置是保障API调用安全与资源隔离的核心环节。DeepSeek官方SDK及OpenAPI网关均支持基于Token的细粒度…...
)
DeepSeek多租户访问控制配置实战(含Kubernetes Admission Controller集成方案)
更多请点击: https://kaifayun.com 第一章:DeepSeek多租户访问控制配置实战(含Kubernetes Admission Controller集成方案) DeepSeek平台通过精细化的RBAC策略与动态准入控制实现企业级多租户隔离。其核心依赖于自定义Kubernetes …...

因果推断中倾向得分校准:提升双稳健机器学习估计精度的关键
1. 项目概述:当因果推断遇上“不准”的机器学习在观察性研究中做因果推断,就像在迷雾中寻找一条真实的路径。我们手头有大量的数据(协变量X)、处理状态(D,比如是否参加了某个培训项目)和结果&am…...

小米手机安装Burp证书失败?DER转PEM格式是关键
1. 为什么小米手机装Burp证书总卡在“安装失败”?真相和你想的不一样很多做移动App安全测试、接口调试或者逆向分析的朋友,一上手小米手机就栽在第一步:把Burp Suite导出的证书(.cer格式)拖进手机,点安装&a…...
)
Sora 2视频音频不同步?深度解析OpenAI未公开的时间戳嵌入机制,3分钟强制同步方案(含Python自动校准工具)
更多请点击: https://codechina.net 第一章:Sora 2视频音频不同步现象的系统性归因 视频与音频流在 Sora 2 模型推理及播放阶段出现时间偏移,是影响用户体验的关键缺陷。该现象并非单一环节导致,而是由多层级时序建模、硬件调度、…...

终极解密:如何使用unluac工具实现Lua字节码逆向工程
终极解密:如何使用unluac工具实现Lua字节码逆向工程 【免费下载链接】unluac fork from http://hg.code.sf.net/p/unluac/hgcode 项目地址: https://gitcode.com/gh_mirrors/un/unluac unluac是一款专业的Lua 5.x字节码反编译工具,能够将编译后的…...