Kafka搭建(集群版)
Kafka单机版
部署前提
VMware环境 : 两台centos系统
Jdk包:jdk-8u202-linux-x64.tar.gz
Kafka包:kafka_2.12-3.5.0.tgz
Zookeeper包:apache-zookeeper-3.7.2-bin.tar.gz百度网盘自取: 链接: https://pan.baidu.com/s/11EWuhBoSmH3musd_3Rgodw?pwd=e32t 提取码: e32t
Kafka搭建(集群版)
创建服务器
- 修改克隆机主机名,以下以kafka-broker1举例说明
#使用root用户登录
#修改主机名
vim /etc/hostname
kafka-broker1 #末尾追加
- 配置Linux克隆机主机名称映射hosts文件,打开/etc/hosts
# 修改主机名称映射vim /etc/hosts添加如下内容:
192.168.233.106 kafka-broker1
192.168.233.107 kafka-broker2
- 重启克隆机kafka-broker1
# 重启
reboot
- 其他机器也同样配置
以下操作默认在kafka-broker1里操作
创建xsync文件
cd /root
mkdir bin
cd bin
vim xsync
- 增加如下内容
#!/bin/bash#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi#2. 遍历集群所有机器
for host in kafka-broker1 kafka-broker2
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done- 修改xsync文件权限
# 进入/root/bin目录
cd /root/bin
# 修改权限
chmod 777 xsync
SSH无密登录配置
分发文件时,需要通过脚本切换主机进行指令操作,切换主机时,是需要输入密码的,每一次都输入就显得有点麻烦,所以这里以虚拟机kafka-broker1为例配置SSH免密登录(其他节点执行同样步骤即可),配置完成后,脚本执行时就不需要输入密码了。
生成公钥和私钥
# 公钥和私钥
ssh-keygen -t rsa#然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
- 将公钥拷贝到要免密登录的目标机器上,拷贝过程需要输入目标机器密码
# ssh-copy-id 目标机器
ssh-copy-id kafka-broker1
ssh-copy-id kafka-broker2
安装JDK1.8
卸载现有JDK
-
不同节点都要执行操作
rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
上传Java压缩包
- 将jdk-8u202-linux-x64.tar.gz文件上传到虚拟机的/opt/software目录中
解压Java压缩包
-
进入/opt/software目录
cd /opt/software/ -
解压缩文件到指定目录
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/ -
进入/opt/module目录
cd /opt/module -
改名
mv jdk1.8.0_212/ java
配置Java环境变量
-
新建 /etc/profile.d/my_env.sh文件
vim /etc/profile.d/my_env.sh -
添加内容
#JAVA_HOME export JAVA_HOME=/opt/module/java export PATH=$PATH:$JAVA_HOME/bin -
让环境变量生效
source /etc/profile.d/my_env.sh
安装测试
java -version
分发软件
-
分发环境变量文件
xsync /etc/profile.d/my_env.sh -
进入/opt/module路径
cd /opt/module -
调用分发脚本将本机得Java安装包分发到其他两台机器
xsync java
在每个节点让环境变量生效
安装ZooKeeper
上传ZooKeeper压缩包
将apache-zookeeper-3.7.2-bin.tar.gz文件上传到三台虚拟机的/opt/software目录中
解压ZooKeeper压缩包
-
进入到/opt/software目录中
cd /opt/software/ -
解压缩文件到指定目录
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/ -
进入/opt/module目录
cd /opt/module -
文件目录改名
mv apache-zookeeper-3.7.1-bin/ zookeeper
配置服务器编号
-
在/opt/module/zookeeper/目录下创建zkData
-
进入/opt/module/zookeeper目录
cd /opt/module/zookeeper -
创建zkData文件目录
mkdir zkData -
创建myid文件
-
进入/opt/module/zookeeper/zkData目录
cd /opt/module/zookeeper/zkData -
创建myid文件
vim myid -
在文件中增加内容
1
修改配置文件
-
重命名/opt/module/zookeeper/conf目录下的zoo_sample.cfg文件为zoo.cfg文件
-
进入cd /opt/module/zookeeper/conf文件目录
cd /opt/module/zookeeper/conf -
修改文件名称
mv zoo_sample.cfg zoo.cfg -
修改文件内容
vim zoo.cfg -
修改zoo.cfg文件
以下内容为修改内容
# **以下内容为修改内容**
dataDir=/opt/module/zookeeper/zkData#以下内容为新增内容####################### cluster ##########################
# server.A=B:C:D
#
# A是一个数字,表示这个是第几号服务器
# B是A服务器的主机名
# C是A服务器与集群中的主服务器(Leader)交换信息的端口
# D是A服务器用于主服务器(Leader)选举的端口
#########################################################server.1=kafka-broker1:2888:3888
server.2=kafka-broker2:2888:3888
设置防火墙端口
firewall-cmd --zone=public --add-port=2181/tcp --permanent
firewall-cmd --zone=public --add-port=2888/tcp --permanent
firewall-cmd --zone=public --add-port=3888/tcp --permanent
firewall-cmd --reload
firewall-cmd --zone=public --list-ports
启动ZooKeeper
在每个节点下执行如下操作
-
进入zookeeper目录
cd /opt/module/zookeeper -
启动ZK服务
bin/zkServer.sh start
关闭ZooKeeper
在每个节点下执行如下操作
-
进入zookeeper目录
cd /opt/module/zookeeper -
关闭ZK服务
bin/zkServer.sh stop
查看ZooKeeper状态
在每个节点下执行如下操作
-
进入zookeeper目录
cd /opt/module/zookeeper -
查看ZK服务状态
bin/zkServer.sh status
分发软件
-
进入/opt/module路径
cd /opt/module -
调用分发脚本将本机得ZooKeeper安装包分发到其他机器
xsync zookeeper
分别将不同虚拟机/opt/module/zookeeper/zkData目录下myid文件进行修改
vim /opt/module/zookeeper/zkData/myid
# kafka-broker1:1
# kafka-broker2:2
启停脚本
ZooKeeper软件的启动和停止比较简单,但是每一次如果都在不同服务器节点执行相应指令,也会有点麻烦,所以我们这里将指令封装成脚本文件,方便我们的调用。
-
在虚拟机kafka-broker1的/root/bin目录下创建zk.sh脚本文件
-
在/root/bin这个目录下存放的脚本,root用户可以在系统任何地方直接执行
-
进入/root/bin目录
cd /root/bin -
创建zk.sh脚本文件
vim zk.sh
在脚本中增加内容:
#!/bin/bash
case $1 in
"start"){for i in kafka-broker1 kafka-broker2doecho ---------- zookeeper $i 启动 ------------ssh $i "/opt/module/zookeeper/bin/zkServer.sh start"done
};;
"stop"){for i in kafka-broker1 kafka-broker2doecho ---------- zookeeper $i 停止 ------------ssh $i "/opt/module/zookeeper/bin/zkServer.sh stop"done
};;
"status"){for i in kafka-broker1 kafka-broker2doecho ---------- zookeeper $i 状态 ------------ssh $i "/opt/module/zookeeper/bin/zkServer.sh status"done
};;
esac
增加脚本文件权限
-
给zk.sh文件授权
chmod 777 zk.sh
脚本调用方式
-
启动ZK服务
zk.sh start -
查看ZK服务状态
zk.sh status -
停止ZK服务
zk.sh stop
安装Kafka
上传Kafka压缩包
将kafka_2.12-3.5.0.tgz文件上传到虚拟机的/opt/software目录中
解压Kafka压缩包
-
进入/opt/software目录
cd /opt/software -
解压缩文件到指定目录
tar -zxvf kafka_2.12-3.5.0.tgz -C /opt/module/ -
进入/opt/module目录
cd /opt/module -
修改文件目录名称
mv kafka_2.12-3.5.0/ kafka
修改配置文件
-
进入cd /opt/module/kafka/config文件目录
cd /opt/module/kafka/config -
修改配置文件
vim server.properties -
输入以下内容:
#broker的全局唯一编号,每个服务节点不能重复,只能是数字。 broker.id=1 #broker对外暴露的IP和端口 (每个节点单独配置) advertised.listeners=PLAINTEXT://**kafka-broker1**:9092 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘IO的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/opt/module/kafka/datas #topic在当前broker上的分区个数 num.partitions=1 #用来恢复和清理data下数据的线程数量 num.recovery.threads.per.data.dir=1 #每个topic创建时的副本数,默认时1个副本 offsets.topic.replication.factor=1 #segment文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个segment文件的大小,默认最大1G log.segment.bytes=1073741824 #检查过期数据的时间,默认5分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理) zookeeper.connect=kafka-broker1:2181,kafka-broker2:2181/kafka
分发kafka软件
-
进入 /opt/module目录
cd /opt/module -
执行分发指令
xsync kafka
按照上面的配置文件内容,在每一个Kafka节点进行配置
vim /opt/module/kafka/config/server.properties
配置环境变量
-
修改 /etc/profile.d/my_env.sh文件
vim /etc/profile.d/my_env.sh -
添加内容
#KAFKA_HOME export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/bin -
让环境变量生效
source /etc/profile.d/my_env.sh -
分发环境变量,并让环境变量生效
xsync /etc/profile.d/my_env.sh -
每个节点执行刷新操作
source /etc/profile.d/my_env.sh
启动Kafka
启动前请先启动ZooKeeper服务
-
进入/opt/module/kafka目录
cd /opt/module/kafka -
执行启动指令
bin/kafka-server-start.sh -daemon config/server.properties
关闭Kafka
-
进入/opt/module/kafka目录
cd /opt/module/kafka -
执行关闭指令
bin/kafka-server-stop.sh
启停脚本
(1) 在虚拟机kafka-broker1的/root/bin目录下创建kfk.sh脚本文件,对kafka服务的启动停止等指令进行封装
-
进入/root/bin目录
cd /root/bin -
创建kfk.sh脚本文件
vim kfk.sh -
在脚本中增加内容:
#! /bin/bash case $1 in "start"){for i in kafka-broker1 kafka-broker2doecho " --------启动 $i Kafka-------"ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"done };; "stop"){for i in kafka-broker1 kafka-broker2doecho " --------停止 $i Kafka-------"ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "done };; esac
增加脚本文件权限
-
给文件授权
chmod 777 kfk.sh
脚本调用方式
-
启动kafka
kfk.sh start -
停止Kafka
kfk.sh stop
注意:停止Kafka集群时,一定要等Kafka所有节点进程全部停止后再停止ZooKeeper集群。因为Zookeeper集群当中记录着Kafka集群相关信息,Zookeeper集群一旦先停止,Kafka集群就没有办法再获取停止进程的信息,只能手动杀死Kafka进程了。
联合脚本
因为Kafka启动前,需要先启动ZooKeeper,关闭时,又需要将所有Kafka全部关闭后,才能关闭ZooKeeper,这样,操作起来感觉比较麻烦,所以可以将之前的2个脚本再做一次封装。
-
在虚拟机kafka-broker1的/root/bin目录下创建xcall脚本文件
-
进入/root/bin目录
cd /root/bin -
创建xcall文件
vim xcall -
在脚本中增加内容:
#! /bin/bashfor i in kafka-broker1 kafka-broker2 doecho --------- $i ----------ssh $i "$*" done
增加脚本文件权限
-
进入/root/bin目录
cd /root/bin -
增加权限
chmod 777 xcall
创建cluster.sh脚本文件
-
进入/root/bin目录
cd /root/bin -
创建cluster.sh脚本文件
vim cluster.sh -
在脚本中增加内容:
#!/bin/bashcase $1 in "start"){echo ================== 启动 Kafka集群 ==================#启动 Zookeeper集群zk.sh start#启动 Kafka采集集群kfk.sh start};; "stop"){echo ================== 停止 Kafka集群 ==================#停止 Kafka采集集群kfk.sh stop#循环直至 Kafka 集群进程全部停止kafka_count=$(xcall jps | grep Kafka | wc -l)while [ $kafka_count -gt 0 ]dosleep 1kafka_count=$(xcall | grep Kafka | wc -l)echo "当前未停止的 Kafka 进程数为 $kafka_count"done#停止 Zookeeper集群zk.sh stop };; esac
增加脚本文件权限
-
进入/root/bin目录
cd /root/bin -
增加权限
chmod 777 cluster.sh
脚本调用方式
-
集群启动
cluster.sh start -
集群关闭
cluster.sh stop
相关文章:
)
Kafka搭建(集群版)
Kafka单机版 部署前提 VMware环境 : 两台centos系统 Jdk包:jdk-8u202-linux-x64.tar.gz Kafka包:kafka_2.12-3.5.0.tgz Zookeeper包:apache-zookeeper-3.7.2-bin.tar.gz 百度网盘自取: 链接: https://pan.baidu.com/s/11EWuhBoSmH3musd_3Rgodw?pwde32t 提取码: e32t Kafka搭建…...

【康复学习--LeetCode每日一题】3115. 质数的最大距离
题目: 给你一个整数数组 nums。 返回两个(不一定不同的)质数在 nums 中 下标 的 最大距离。 示例 1: 输入: nums [4,2,9,5,3] 输出: 3 解释: nums[1]、nums[3] 和 nums[4] 是质数。因此答案是…...

【yolov8系列】ubuntu上yolov8的开启训练的简单记录
前言 yolov8的广泛使用,拉取yolov8源码工程,然后配置环境后直接运行,初步验证自己数据的检测效果,在数据集准备OK的情况下 需要信手拈来,以保证开发过程的高效进行。 本篇博客更注意为了方便自己使用时参考。顺便也记录…...

Scala学习笔记15: 文件和正则表达式
目录 第十五章 文件和正则表达式1- 读取行2- 从URL或者其它源读取3- 写入文本文件4- 序列化5- 正则表达式6- 正则表达式验证输入数据格式end 第十五章 文件和正则表达式 1- 读取行 在Scala中读取文件中的行可以通过不同的方法实现 ; 一种常见的方法是使用 scala.io.Source 对…...

外卖员面试现状
说明: 以下身份角色用符号代替 # 面试官 $ 求职者 # 看了您的简历你有两年半的送外卖经验,可以简单说一下您平时是怎么送外卖的吗? $ 我首先在平台接单然后到店里取餐,取到餐后到顾客留下的地址,再通知顾客取餐 # 你们也用电动…...

异步加载与动态加载
异步加载和动态加载在概念上有相似之处,但并不完全等同。 异步加载(Asynchronous Loading)通常指的是不阻塞后续代码执行或页面渲染的数据或资源加载方式。在Web开发中,异步加载常用于从服务器获取数据,而不需要用户等…...

MUNIK解读ISO26262--什么是DFA
我们在学习功能安全过程中,经常会听到很多安全分析方法,有我们熟知的FMEA(Failure Modes Effects Analysis)和FTA(Fault Tree Analysis)还有功能安全产品设计中几乎绕不开的FMEDA(Failure Modes Effects and Diagnostic Analysis),相比于它们…...

启动spring boot项目停止 提示80端口已经被占用
可能的情况: 检查并结束占用进程: 首先,你需要确定哪个进程正在使用80端口。在Windows上,可以通过命令行输入netstat -ano | findstr LISTENING | findstr :80来查看80端口的PID,然后在任务管理器中结束该进程。在...

SOLIDWORKS分期许可(订阅形式),降低前期的投入成本!
SOLIDWORKS 分期许可使您能够降低前期软件成本,同时提供对 SOLIDWORKS 新版本和升级程序的即时访问,以及在每个期限结束时调整产品的灵活性,帮助您跟上市场需求和竞争压力的步伐。 目 录: ★ 1 什么是SOLIDWORKS分期许可 ★ 2 …...
)
详细分析Spring Boot 数据源配置的基本知识(附配置)
目录 前言1. 基本知识2. 模版3. 实战经验前言 对于Java的基本知识推荐阅读: java框架 零基础从入门到精通的学习路线 附开源项目面经等(超全)【Java项目】实战CRUD的功能整理(持续更新)1. 基本知识 包括数据源的概念、连接池的作用、多数据源的实现与管理、Druid 连接池…...
9轴IMU ICM-20948模块SPI接口调试)
海思SD3403/SS928V100开发(15)9轴IMU ICM-20948模块SPI接口调试
1.前言 芯片平台: 海思SD3403/SS928V100 操作系统平台: Ubuntu20.04.05【自己移植】 9轴IMU模块:ICM-20948 通讯接口: SPI 模块datasheet手册: https://download.csdn.net/download/jzwjzw19900922/89517096 2. 调试记录 2.1 pinmux配置 #spi0 bspmm 0x0102F01D8 …...

大力出奇迹:大语言模型的崛起与挑战
随着人工智能(AI)技术的迅猛发展,特别是在自然语言处理(NLP)领域,大语言模型(LLM)的出现与应用,彻底改变了我们与机器互动的方式。本文将探讨ChatGPT等大语言模型的定义、…...
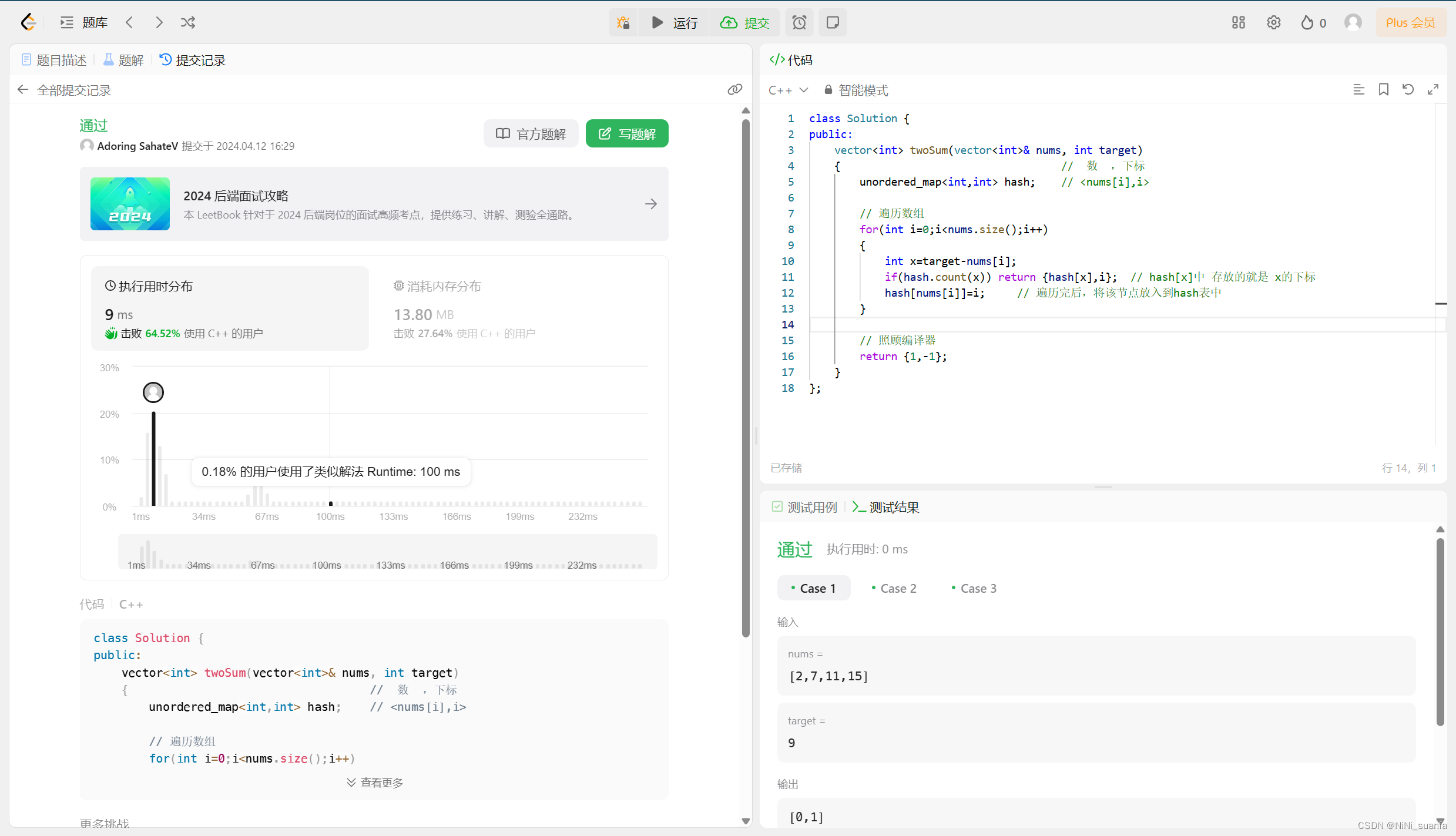
【算法 - 哈希表】两数之和
这里写自定义目录标题 两数之和题目解析思路解法一 :暴力枚举 依次遍历解法二 :使用哈希表来做优化 核心逻辑为什么之前的暴力枚举策略不太好用了?所以,这就是 这道题选择 固定一个数,再与其前面的数逐一对比完后&…...
:线性回归模型第一部分:认识线性回归模型)
【深度学习】图形模型基础(5):线性回归模型第一部分:认识线性回归模型
1. 回归模型定义 最简单的回归模型是具有单一预测变量的线性模型,其基本形式如下: y a b x ϵ y a bx \epsilon yabxϵ 其中, a a a 和 b b b 被称为模型的系数或更一般地,模型的参数。 ϵ \epsilon ϵ 代表误差项&#…...

2024 年第十四届 APMCM 亚太地区大学生数学建模竞赛B题超详细解题思路+数据预处理问题一代码分享
B题 洪水灾害的数据分析与预测 亚太中文赛事本次报名队伍约3000队,竞赛规模体量大致相当于2024年认证杯,1/3个妈杯,1/10个国赛。赛题难度大致相当于0.6个国赛,0.8个妈杯。该比例仅供大家参考。 本次竞赛赛题难度A:B:C3:1:4&…...

Yarn有哪些功能特点
Yarn是一个由Facebook团队开发,并联合Google、Exponent和Tilde等公司推出的JavaScript包管理工具,旨在提供更优的包管理体验,解决npm(Node Package Manager)的一些痛点。Yarn的功能特点主要包括以下几个方面࿱…...

深度学习算法bert
bert 属于自监督学习的一种(输入x的部分作为label) 1. bert是 transformer 中的 encoder ,不同的bert在encoder层数、注意力头数、隐藏单元数不同 2. 假设我们有一个模型 m ,首先我们为某种任务使用大规模的语料库预训练模型 m …...

PyTorch - 神经网络基础
神经网络的主要原理包括一组基本元素,即人工神经元或感知器。它包括几个基本输入,例如 x1、x2… xn ,如果总和大于激活电位,则会产生二进制输出。 样本神经元的示意图如下所述。 产生的输出可以被认为是具有激活电位或偏差的加权…...
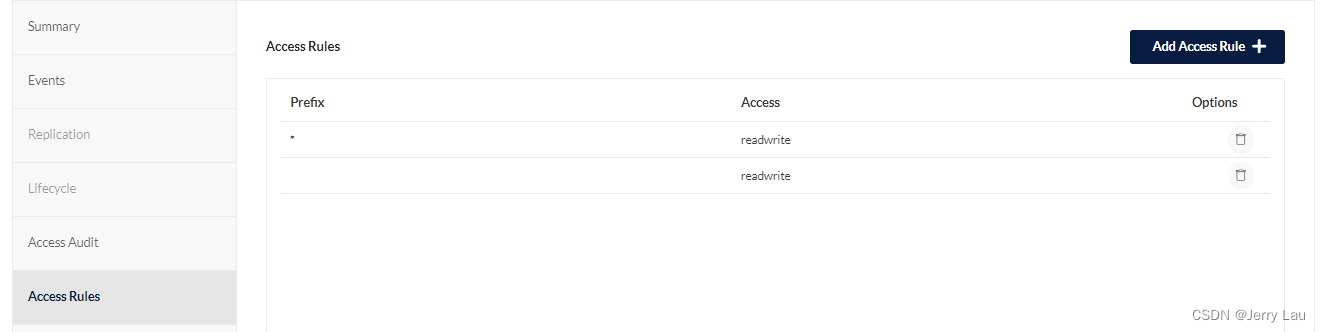
docker-compose搭建minio对象存储服务器
docker-compose搭建minio对象存储服务器 最近想使用oss对象存储进行用户图片上传的管理,了解了一下例如aliyun或者腾讯云的oss对象存储服务,但是呢涉及到对象存储以及经费有限的缘故,决定自己手动搭建一个oss对象存储服务器; 首先…...

vue3使用pinia中的actions,需要调用接口的话
actions,需要调用接口的话,假如页面想要调用actions中的方法获取数据, 必须使用try catch async await 进行包裹,详情看下面代码 import {defineStore} from pinia import {reqCode,reqUserLogin} from ../../api/hospital/i…...

VSCode R扩展:如何在5分钟内搭建完整的R语言开发环境
VSCode R扩展:如何在5分钟内搭建完整的R语言开发环境 【免费下载链接】vscode-R R Extension for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-R 如果你正在寻找一个现代化的R语言开发工具,那么VSCode配合vscode-R扩…...

终极Win11系统优化指南:Win11Debloat深度清理教程
终极Win11系统优化指南:Win11Debloat深度清理教程 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

League Akari:5个核心功能彻底改变你的英雄联盟游戏体验
League Akari:5个核心功能彻底改变你的英雄联盟游戏体验 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于官…...

Windows右键菜单终极优化:ContextMenuManager完全掌控指南
Windows右键菜单终极优化:ContextMenuManager完全掌控指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager Windows右键菜单是日常操作中使用最频繁的…...

微信聊天记录永久保存终极指南:用WeChatExporter告别数据焦虑
微信聊天记录永久保存终极指南:用WeChatExporter告别数据焦虑 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾有过这样的担忧——手机突然损坏&#…...

终极iOS越狱实战指南:解锁iPhone隐藏功能与深度定制方案
终极iOS越狱实战指南:解锁iPhone隐藏功能与深度定制方案 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址…...

如何快速提升电脑性能:5个终极系统调优技巧指南
如何快速提升电脑性能:5个终极系统调优技巧指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility 你是否遇到过这样的…...

3步解决微信网页版访问限制:企业环境下的浏览器插件方案
3步解决微信网页版访问限制:企业环境下的浏览器插件方案 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为工作电脑无法安装微信客户端…...

终极指南:使用Xenos实现Windows进程DLL注入的完整教程
终极指南:使用Xenos实现Windows进程DLL注入的完整教程 【免费下载链接】Xenos Windows dll injector 项目地址: https://gitcode.com/gh_mirrors/xe/Xenos 在Windows系统开发和安全研究中,DLL注入技术是实现进程监控、调试和功能扩展的核心手段。…...

JMeter梯度压测:精准定位系统可扩展性边界
1. 为什么“梯度式压测”不是加个线程组就完事了?很多人第一次打开JMeter,照着教程建个线程组、加个HTTP请求、跑个聚合报告,看到TPS从200涨到800就以为“压测完成了”。结果上线后流量一上来,服务直接503,监控里CPU没…...