大数据Spark 面经
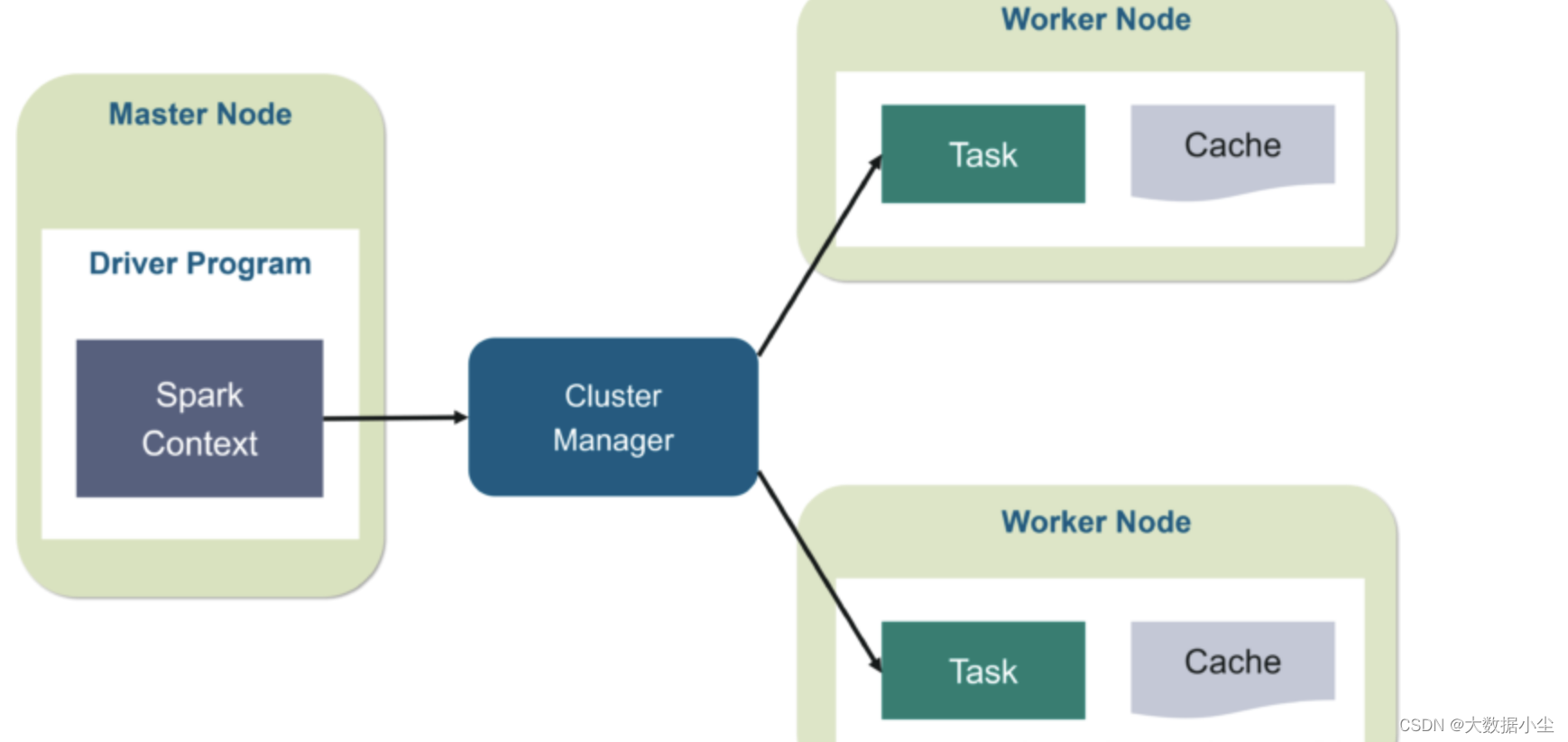
1: Spark 整体架构
Spark 是新一代的大数据处理引擎,支持批处理和流处理,也还支持各种机器学习和图计算,它就是一个Master-worker 架构,所以整个的架构就如下所示:
2: Spark 任务提交命令
一般我们使用shell 命令提交,命令如下:
./bin/spark-submit \--master yarn \--deploy-mode cluster \--driver-cores 2 \--driver-memory 1g \--executor-cores 4 \--num-executors 10 \--executor-memory 8g \--class PackageName.ClassName XXXX.jar \--name "Spark Job Name" \
driver 和executor 就是对应的spark的 driver 和executor 的配置,然后再指定个部署模式master 就可以了。
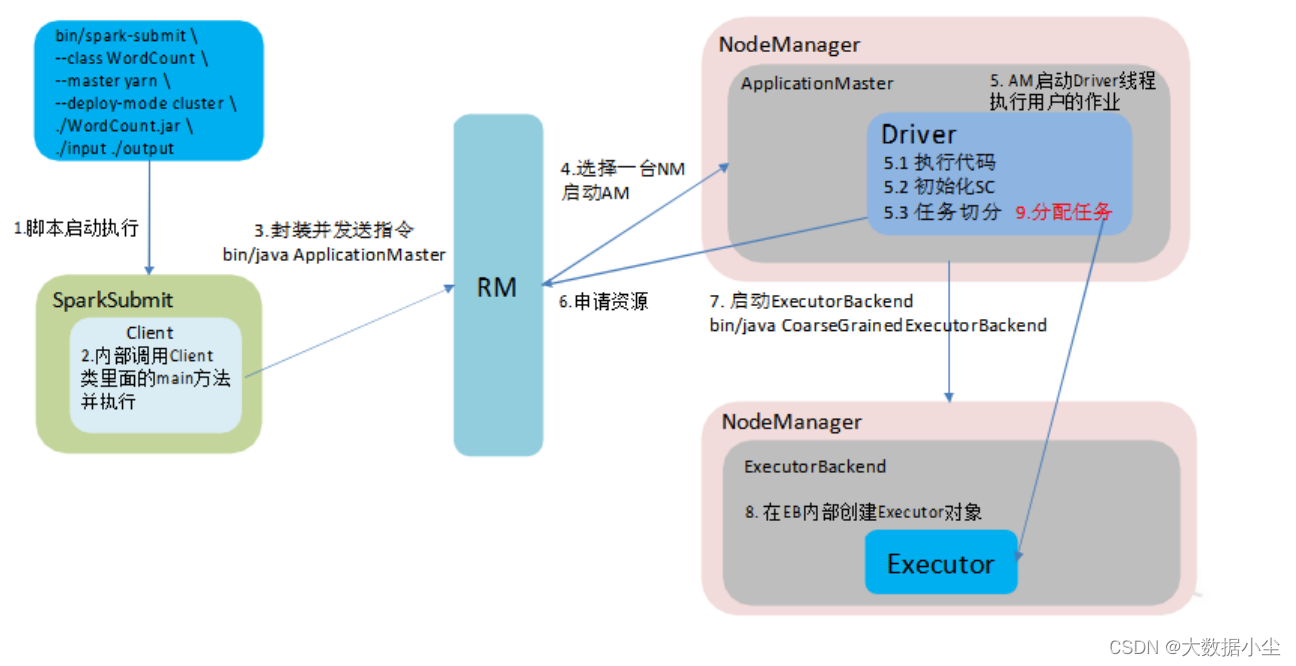
3: spark提交任务的流程
如上所示,我们在提交spark 任务的时候,有个参数可供选择模式,就是deploy-mode 的参数,它的值有client 和cluster 之分;client 说白了就是driver 在客户端,任务的分配和调度都在客户端,这种只适合用于测试;毕竟一旦流量大了的话客户端是顶不住的啊;而cluster 模式是spark对应的driver 和executor 都是在yarn集群上,相对来说稳定,我们这里只着重说yarn-cluster 的提交流程
3.1: 首先如上面的第二点所示,我们先提交启动命令
3.2: 然后客户端这边先运行提交的jar包里面的main方法
3.3: 接着和RM 通信,告诉RM 启动ApplicationMaster,./bin/ApplicatioMaster
3.4: RM 随机选择一台NM 准备启动AM
3.5: 在AM 里面启动driver,然后让driver 进行SparkContext 的初始化以及进行任务的切分
3.6:AM 再向RM 申请资源
3.7: 申请资源后AM 就启动ExecutionBackend,
3.8: ExecutionBackend 启动 Executors
3.9:Driver 把任务分配给Executors
cluster 流程图如下所示:
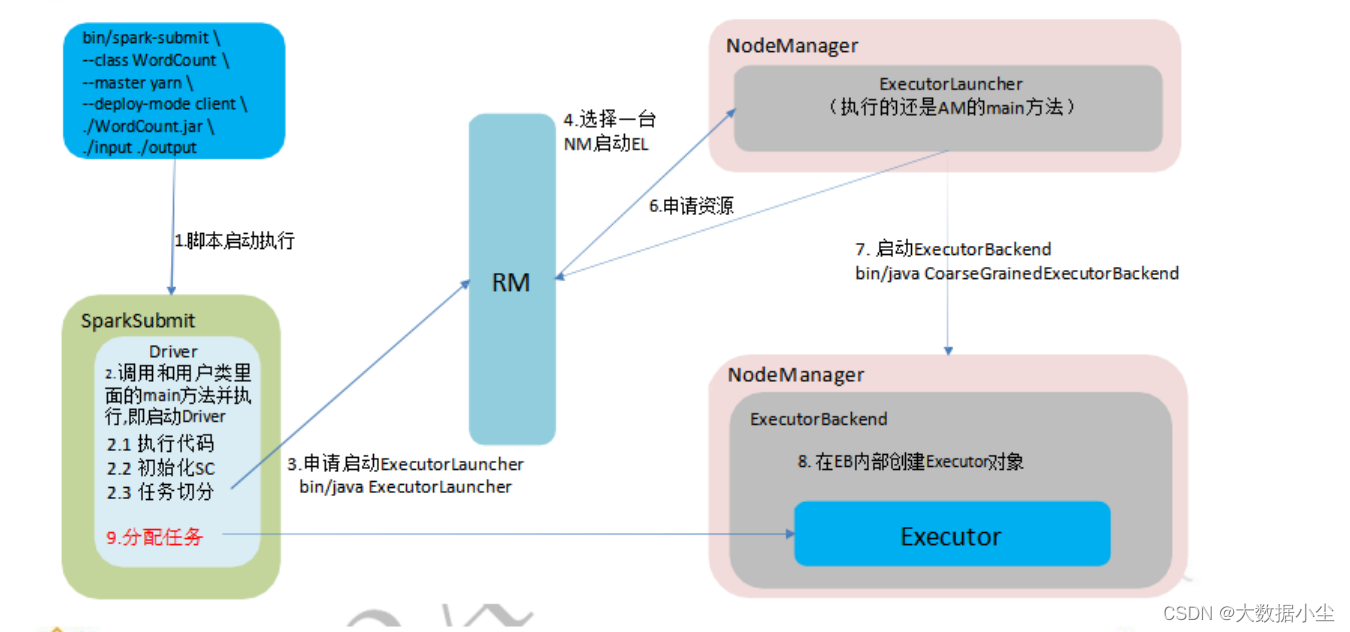
client 流程图如下所示:
4: Spark 中的RDD
4.1: RDD 概念
还是老样子,先理解一个东西之前我们看看它的学名是什么,Resilient Distribute DataSet ,就是弹性分布式数据集;说白了,它的本质还是数据的集合,MR 和Flink的输入是一条条数据,这Spark 说我乖点了,输入我就先把它们整成一个个数据集;哈哈哈,符合预先聚合的思想。说白了,RDD 就是三个层次的抽象,Dataset, partition, 以及record;对应到生活中的例子,就是班级,组以及单个同学;
4.2:RDD 的特点是啥?从学名可以窥见一二,弹性,分布式
我们先说弹性,说白了就是灵活,可以容错,它是怎么容错的呢?就是RDD之间互相有依赖关系,如果某个RDD的分区没有了,可以从原始数据和依赖关系得来,不用让其他分区重算;
那么分布式呢,就是一个RDD的分区数据可以分发到不同的节点上进行计算;靠近数据的计算嘛;
一个RDD的分区数可以自定义;如果没有自定义,则和hdfs的block数一样,或者和cpu的核数成比例关系,一核心大概可以处理2-4个分区。
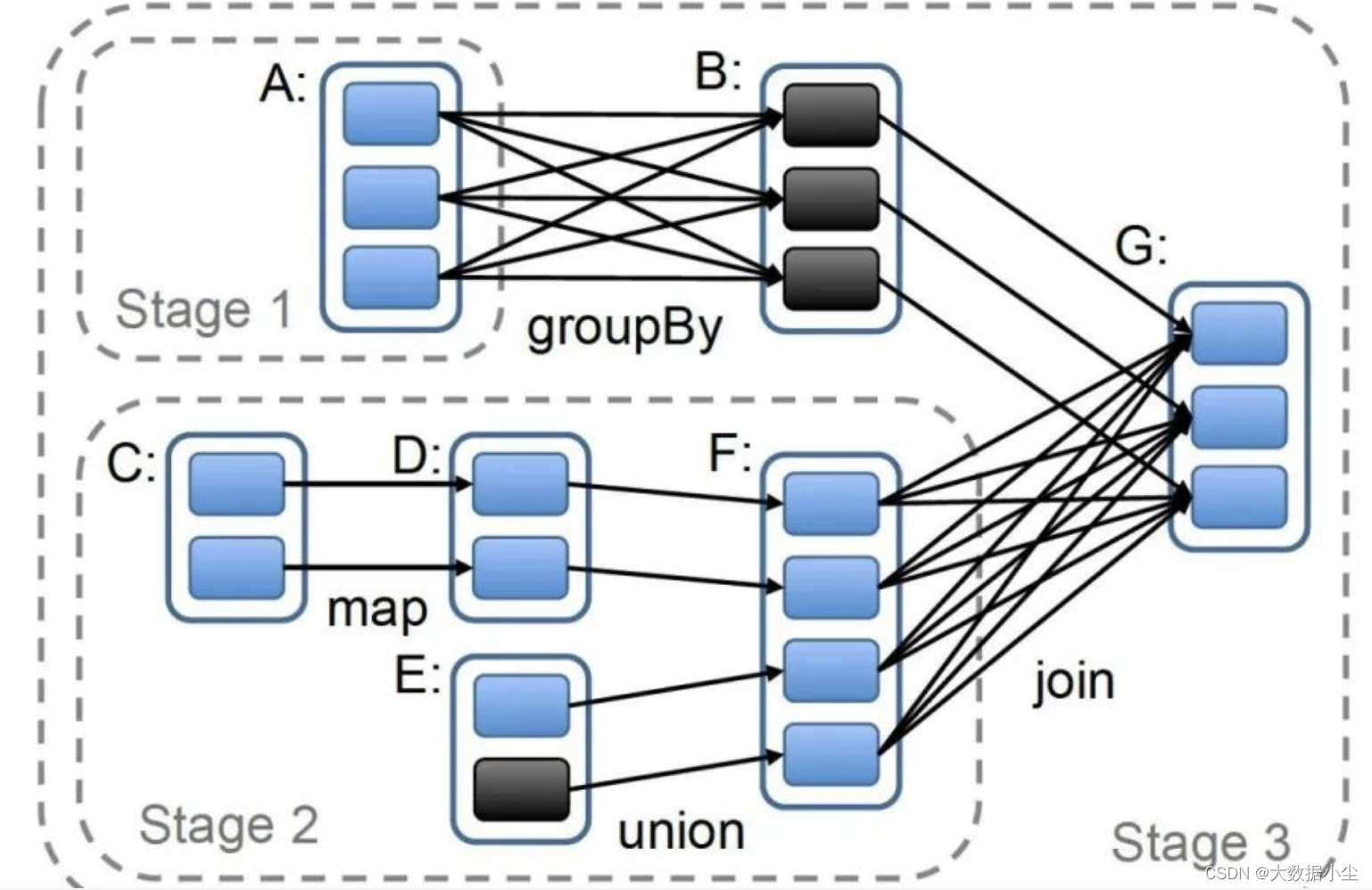
4.3: RDD 之间的血缘关系
血缘血缘,套到数据集这边就知道是上下游RDD的关系了,这里的血缘指的就是子RDD和父RDD 之间是分区之间一对一还是多对一;说白了如果一个父RDD的一个分区的数据给到了子RDD的多个分区,这明摆着宽广嘛,就是宽依赖;否则就是摘依赖,一对一的关系;如下所示
4.4: RDD 之间的stage 划分
这里就有个问题了,为什么要进行stage的划分呢? 大家可以想想,这个spark的RDD 也是基于内存的计算,如果一个任务一直这样计算下去,比如算到90%的时候,机器突然宕机了,任务全部失败了,是不是又得重新计算,所以我们就要进行个中间数据的备份嘛,比如算完了一个stage的数据,先把它存储到外部系统,这样就不怕任务突然中断了;
所以大家是不是结合上面的宽窄依赖就想到了,如果出现了宽依赖我们就截断,划分一个stage;毕竟可以先保存一份数据嘛,可能一个子RDD有多个父RDD,每个父RDD就自己先把数据保存起来,做个备份嘛;
所以我们stage 划分就是根据宽窄依赖去划分的,碰到宽依赖就划分一个stage,stage 里面的算子和数据自成一个天地。
4.5: spark的编程思想之RDD
所以兄弟们可以看到,说白了,我们进行spark的编程的时候,就是基于RDD的,然后和算子一起,把RDD当作点,这些算子当成边,不就构建成了我们的这个有向无环图(DAG) 嘛;没有相互依赖的RDD 进行一个并行计算,有相互依赖的窄依赖的类型也可以进行并行计算,当碰到宽依赖的时候,就要进行数据打散了,不就是shuffle嘛,最后算好的数据落盘就行了。
5: Spark中groupByKey,reduceByKey,, combineByKey, aggregrateByKey的区别
怎么说呢,其实这些算子都是针对数据做聚合的操作,groupByKey 和reduceByKey 没有定义初始值的结构,groupByKey 默认用的hash 分区,而reduceByKey 可以自定义分区,也会提前进行combine;这两个算子分区内的逻辑和分区间的逻辑都是一致的;
而aggregrateByKey 和 combineByKey 和 则在reduceByKey的基础上做了些变化,aggregrateByKey 是自定义分区内和分区间的逻辑;而combineByKey 是在上述的基础上也增加一个初始值自定义。
6: spark中的hashShuffle,sortShuffle, 以及优化后的这两个变种
6.1: 普通的hashShuffle ,说白了就是在shuffle的过程中使用hash对key 进行分组,假如上游有100个类似的mapTask,下游有100个reduce task,每个mapTask 会针对下游生成100个文件,总共就是10000个小文件了,这个对于集群来说负担就太大了,如下所示:
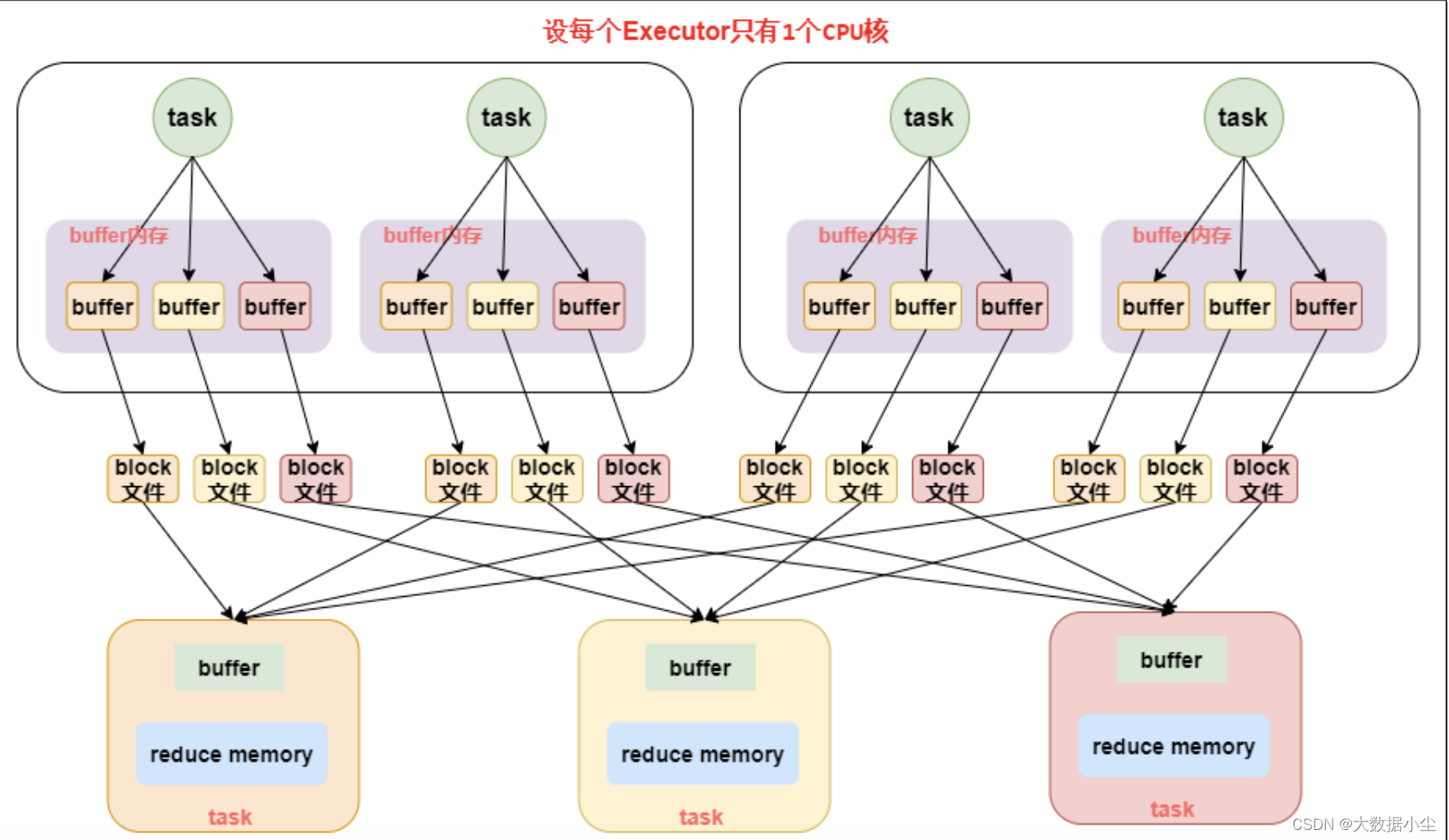
6.2: 优化后的HashShuffle
上述的普通版产生的小文件个数太多了,所以我们需要优化下,优化的重点思路就是复用,既然每个上游的task都要生成这么多文件,可不可以一个Executor 里面的缓冲区复用呢?答案是可以的,spark 官方就根据cpu core 的数量 * 下一个stage的task个数来确定缓冲区数量以及文件个数,相对来说少了挺多的,原先要10000个,现在可能只要5*100个就可以了。哈哈哈,不过这个优化机制要通过spark.shuffle.consolidateFiles=true 开启;
6.3: sortShuffle
sortShuffle 是什么呢?说白了就是在shuffle 之前先进行排序,然后也会有溢写到磁盘,可能会生成多个文件,但是最终每个task会对所有的文件进行合并,最终只生成一个文件和文件对应的索引,让下游的task 根据索引文件去找数据,拉取数据。如下所示:
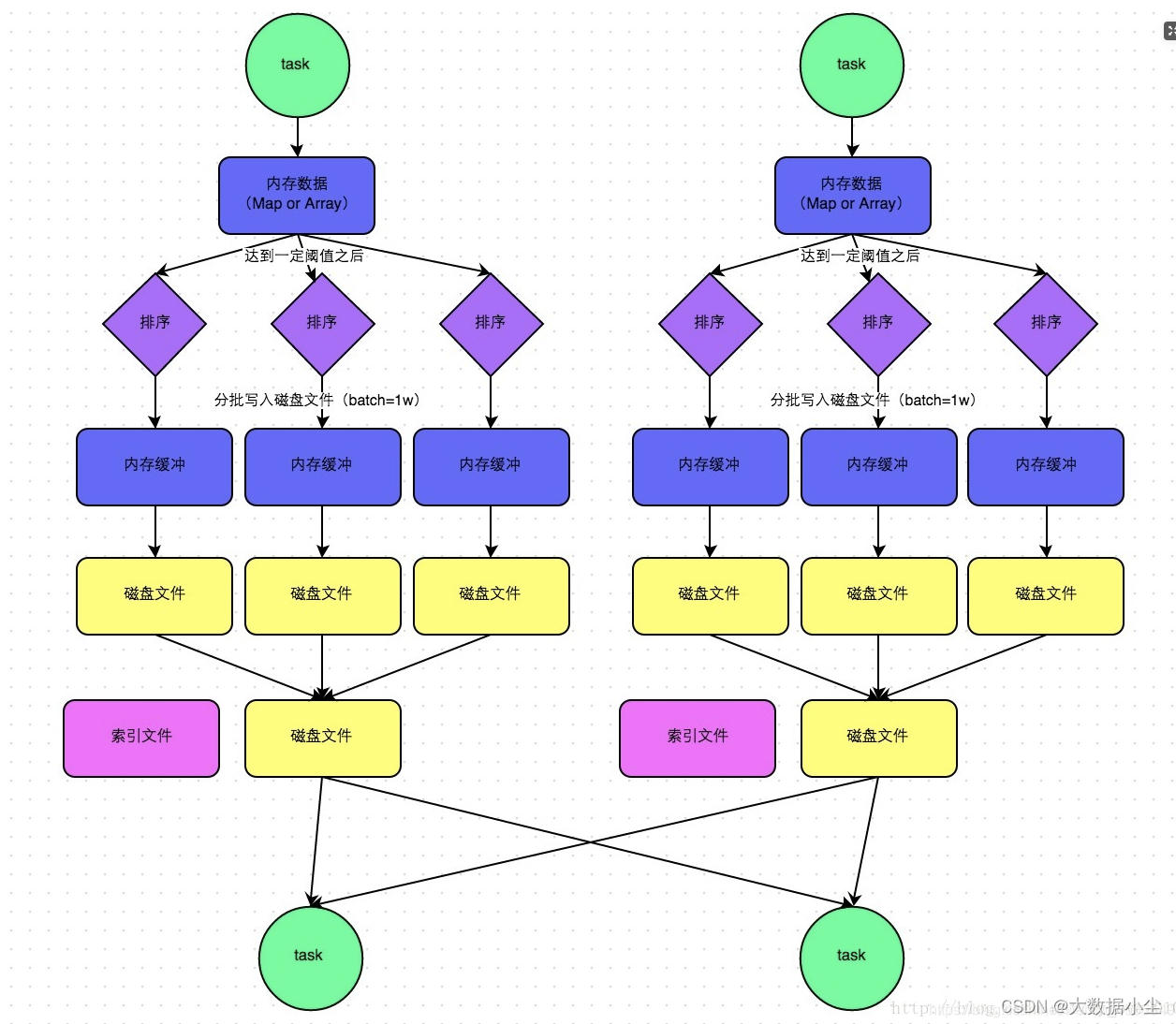
这个对应的文件更少了,对下游的压力也更小了。
6.4: byPassSortShuffle
这个和上面的sortShuffle 如出一辙,唯一的区别就是在写文件的时候不会进行排序,省去了这部分的开销;不过这个需要触发的点有两个,
6.4.1: shuffle map task 数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
6.4.2: 不是聚合类的 shuffle 算子
兄弟们最终是不是还想问问,现阶段该怎么启用sortShuffle,spark2.x 已经把所有的shuffle都默认成了sortShuffle了。
7: spark中的cache,persist 和checkpoint 的区别
三者都是把数据持久化的,前面两个是把数据缓存到内存,而checkpoint 是吧数据存到hdfs 或者本地文件;前者不会截断血缘关系,后者会截断,毕竟hdfs副本可以容错;cache 实际上就是调用的persist
8: RDD , DataFrame, 以及DataSet 的区别
8.1: RDD 就是我们刚刚说的弹性分布式数据集嘛,是面向对象的,是需要序列化和反序列化的,在网络IO中性能消耗大,是不支持Spark Sql的;但是它是编译类型安全的;
8.2: DataFrame 怎么说呢?就是相当于一个表,类似于python 和R,它只知道表头,只知道下面的Name,age,Height;不知道具体每个字段对应的数据类型,它就相当于表里的v如下所示:
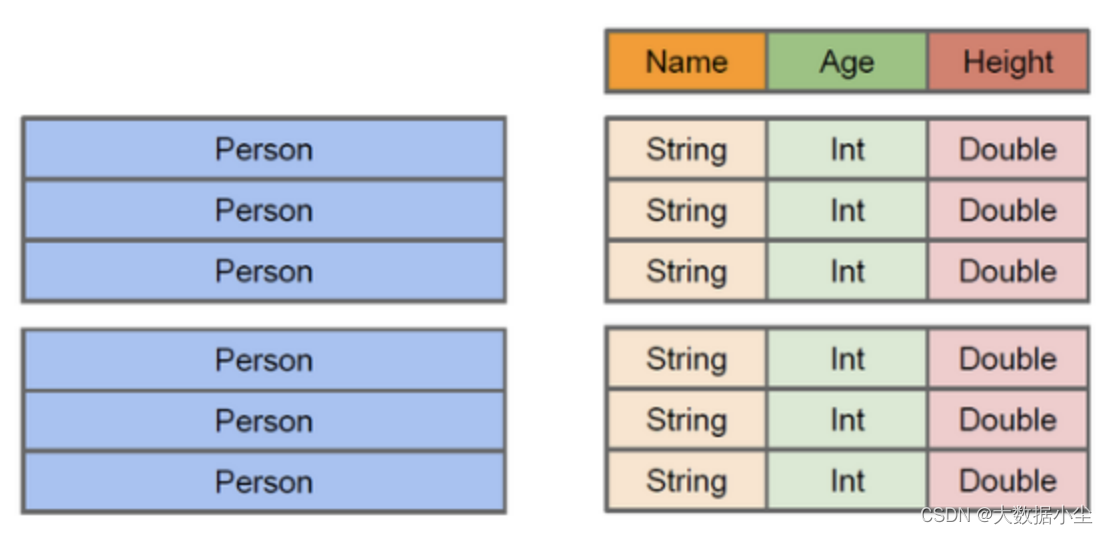
所以它是编译时类型不安全的;不过它有个优点,它的存储是放在java的堆外内存,不用进行GC了,也不用进行序列化和反序列化带来的开销了
8.3: 这就是天生为sql 创建的数据集了,它就相当于sql里面的表,既知道表的字段头,也知道每个表的字段的数据类型;而且它还支持序列化的时候轻量的序列化,它结合了DF 和 RDD的优点,编译时也是类型安全的,并且带来了一个全新的概念,Encode,它可以保证按需序列化数据了。
9: SparkShuffle 的优化:
上一步我们讲了spark上游MapTask生成小文件的优化,那么接下来我们也可以看看sparkReduce的这个Reduce 端的优化。
9.1: 既然要优化reducer端,首先能不能让每次buffer存储的数据量多点,就节省了reduce 拉取的个数,这个值通过spark.shuffle.file.buffer 来控制,一般32k,可以是64k;
9.2: 既然要拉取的数据量少点,是不是可以提高每批次拉取的数据量呢?那就是spark.reducer.maxSizeInFlight 的值控制的,一般是48M,可以到96M;
10. sparkStreaming 和kafka的连接方式
说白了,这个问题就是问的sparkStreaming 如何从kafka 拉取数据的,
10.1:Receiver 方式,这个是Spark 1.5 之前的版本,说白了就是Executor 里面有个receiver的组件,它负责和kafka创建连接,并且使用kafka的高阶api 去和kafka 通信,从kafka 消费过来的数据基本上是先放在内存中,然后供spark的executor 去做其他处理,所以数据量激增的时候有可能导致内存炸掉; 毕竟数据放在内存中很有可能丢失,是吧?所以它做了一个checkPoint,会对每个批次的数据做个备份,学名叫做WAL(Write ahead log) 机制,就是会把数据备份到分布式文件系统比如hdfs上面;
10.2:Direct 方式,直接每次轮询kafka的partition的数据,有几个partition 这边也就轮询几次,使用kafka的低阶的api,自己保存每个partition的offset,自己维护,保证了可以和kafka的同步;可以做到数据精确消费一次;
生产环境一般都用DIrect 方式,毕竟不用checkpoint,不用降低数据处理速率,而且可以精准消费一次;不存在重复消费的可能。
说白了,就是Receiver 是被动的,可能会被kafka的数据给干爆;Direct 是主动的,自己掌握offset ,去主动消费
11:sparkStreaming 窗口函数的原理
因为sparkStreaming 本质上是微批数据当作实时数据(如下所示)
val ssc = new StreamingContext(sc,Seconds(5))//5表示5秒中对数据进行切分形成一个RDD
``
所以窗口数据也是微批的合集,窗口一定要是微批的整数倍,这样才能算是可以统计出来的有效窗口
12: spark 常见算子解释
12.1: mapToPair, 说白了就是把原来的数据转换成关系对的形式,不管之前的数据怎么样,转换之后的数据就是pair对的形式,比如 tuple<String,Long>
12.2: transform, tranformToPair, 都是基于sparkStreaming 的流式数据结构上的算子,transform可能就是返回一个流式的数据Dstream, 里面的数据单位是Object; 而tranformToPair 返回的是带有pair 对的流是数据。
12.3: spark 编程,最关键的是你要知道你的输入是什么,你要输出什么,是tuple呢,还是String呢,还是其他数据呢,RDD里面装载的基础数据结构要知道;
12.3:
自定义排序类就是要实现Ordered 以及 Serialziable 接口,定义好大于,小于,compreTo的逻辑;
自定义的accumulator 说白了就是一个累加器,继承实现AccumulatorParam的方法,最关键的是要知道这个累加器的逻辑是什么,对哪个值累加,在addAccumulator 中实现这个累加的逻辑;
自定义的聚合函数,也就是udaf的function , 是要继承UserDefinedAggregateFunction的类,最重要的是要做三件事,初始化传进来的值,在update方法里面对每个分区的值做业务判断处理;
在merge 方法里面对所有分区的值做个融合判断处理,最终在buffer中更新
13:spark电商项目的核心
13.1: 首先从业务方面可以分为session访问指标计算(top10 session),页面转换率计算(点击/下单/支付);广告相关的指标计算(top10 广告,省份广告),订单指标(省份销量高的产品,属性销量高的产品) 的相关统计计算;产品相关(各区域内产品点击次数) 的指标计算;核心点是和产品经理核对好各个指标的计算方法;
13.2: 大数据大数据,最重要的关注点就是我们要关注性能,因为好的性能和差的性能跑任务的时间可以相差到几个甚至十几个小时,所以我们在编写代码的时候就要尽可能考虑到这些点;从系统可用资源方面,代码层面,数据倾斜和组成方面进行考虑,尽量达到最大的性能;尽量考虑稳定性。
13.3: spark调优
13.3.1: 算子调优
13.3.2: shuffle 调优
13.3.3: 资源调优
13.3.4: jvm 调优,降低cache 内存的比例
14: Spark 内存管理机制
14.1: 静态内存变为动态内存,统一内存管理了,分成了Storage Memory 和Execution Memory ,分别是1:1 的关系,存储数据,存储shuffle过程中的数据
相关文章:
大数据Spark 面经
1: Spark 整体架构 Spark 是新一代的大数据处理引擎,支持批处理和流处理,也还支持各种机器学习和图计算,它就是一个Master-worker 架构,所以整个的架构就如下所示: 2: Spark 任务提交命令 一般我们使用shell 命令提…...

绝区叁--如何在移动设备上本地运行LLM
随着大型语言模型 (LLM)(例如Llama 2和Llama 3)不断突破人工智能的界限,它们正在改变我们与周围技术的互动方式。这些模型早已集成到我们的手机中,但到目前为止,它们理解和处理请求的能力还非常有限。然而,…...

Interview preparation--Https 工作流程
HTTP 传输的弊端 如上图,Http进行数据传输的时候是明文传输,导致任何人都有可能截获信息,篡改信息如果此时黑客冒充服务器,或者黑客窃取信息,则其可以返回任意信息给客户端,而且不被客户端察觉,…...
集成学习(三)GBDT 梯度提升树
前面学习了:集成学习(二)Boosting-CSDN博客 梯度提升树:GBDT-Gradient Boosting Decision Tree 一、介绍 作为当代众多经典算法的基础,GBDT的求解过程可谓十分精妙,它不仅开创性地舍弃了使用原始标签进行…...

后端工作之一:CrapApi —— API接口管理系统部署
一个API接口的网络请求都有这些基本元素构成: API接口大多数是由后端编写,前端开发人员进行请求调用 就是一个网络请求的流程。 API(Application Programming Interface)接口是现代软件开发中不可或缺的一部分。它们提供了一种…...
的实时驱动更换)
20240706 xenomai系统中网口(m2/minipcie I210网卡)的实时驱动更换
lspci 查看网口 查看网口驱动 1 ubuntu 查看网口驱动 在Ubuntu中,您可以使用lshw命令来查看网络接口的驱动信息。如果lshw没有安装,您可以通过执行以下命令来安装它: sudo apt-get update sudo apt-get install lshw 安装完成后ÿ…...

模型训练之数据集
我们知道人工智能的四大要素:数据、算法、算力、场景。我们训练模型离不开数据 目标 一、数据集划分 定义 数据集:训练集是一组训练数据。 样本:一组数据中一个数据 特征:反映样本在某方面的表现、属性或性质事项 训练集&#…...

【TB作品】数码管独立按键密码锁,ATMEGA16单片机,Proteus仿真 atmega16数码管独立按键密码锁
文章目录 基于ATmega16的数码管独立按键密码锁设计实验报告实验背景硬件介绍主要元器件电路连接 设计原理硬件设计软件设计 程序原理延时函数独立按键检测密码显示主函数 资源代码 基于ATmega16的数码管独立按键密码锁设计实验报告 实验背景 本实验旨在设计并实现一个基于ATm…...
数据库主从复制
目录 一.主从复制架构 二.主从复制原理 三.实现主从复制配置 1.新建主从复制 2.实战遇到问题 3.复制错误解决方法 4.级联 主从复制 5.半同步复制 MySQL数据库的主从复制(Master-Slave Replication)是一种常见的数据库复制架构,用于提…...

昇思25天学习打卡营第13天|BERT
一、简介: BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),它是Google于2018年末开发并发布的一种新型语言模型。与BERT模型相似的预训练语言模型例如问答、命名实体识别、自…...

跨平台书签管理器 - Raindrop
传统的浏览器书签功能虽然方便,但在管理和分类上存在诸多局限。今天,我要向大家推荐一款功能强大的跨平台书签管理-Raindrop https://raindrop.io/ 📢 主要功能: 智能分类和标签管理 强大的搜索功能 跨平台支持 分享与协作 卡片式…...
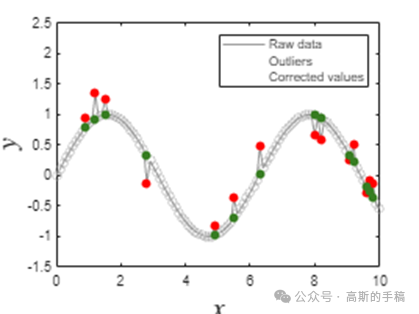
均匀采样信号的鲁棒Savistky-Golay滤波(MATLAB)
S-G滤波器又称S-G卷积平滑器,它是一种特殊的低通滤波器,用来平滑噪声数据。该滤波器被广泛地运用于信号去噪,采用在时域内基于多项式最小二乘法及窗口移动实现最佳拟合的方法。与通常的滤波器要经过时域-频域-时域变换…...

c++ 可以再头文件种直接给成员变量赋值吗
在C中,你通常不能在头文件中直接给类的成员变量赋值,因为这会导致每个包含该头文件的源文件中都尝试进行赋值,从而引发多重定义错误。然而,你可以在类的构造函数中初始化成员变量,或者在类声明中使用初始化列表或默认成…...

47.HOOK引擎优化支持CALL与JMP位置做HOOK
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 上一个内容:46.修复HOOK对代码造成的破坏 以 46.修复HOOK对代码造成的破坏 它的代码为基础进行修改 优化的是让引擎支持从短跳JMP(E9&…...

liunx上修改Firefox版本号
在Linux上修改Firefox的版本号并不直接推荐也不鼓励,因为这可能会影响到浏览器的安全性、兼容性和自动更新功能。但如果你因为某些特殊测试场景确实需要修改其显示的版本号(请注意,这样做可能会引发不可预料的问题),可…...

bug——多重定义
bug——多重定义 你的问题是在C代码中遇到了"reference to data is ambiguous"的错误。这个错误通常发生在你尝试引用一个具有多重定义的变量时。 在你的代码中,你定义了一个全局变量data,同时,C标准库中也有一个名为data的函数模板…...
与最大值(Xmx)设置为相同的配置,可以防止JVM在运行过程中根据需要动态调整堆内存大小)
将堆内存的最小值(Xms)与最大值(Xmx)设置为相同的配置,可以防止JVM在运行过程中根据需要动态调整堆内存大小
将堆内存的最小值(Xms)与最大值(Xmx)设置为相同的配置,可以防止JVM在运行过程中根据需要动态调整堆内存大小,从而避免因内存分配策略变化引起的性能波动,也就是所谓的"内存震荡"&…...

安装 tesseract
安装 tesseract 1. Ubuntu-24.04 安装 tesseract2. Ubuntu-24.04 安装支持语言3. Windows 安装 tesseract4. Oracle Linux 8 安装 tesseract 1. Ubuntu-24.04 安装 tesseract sudo apt install tesseract-ocr sudo apt install libtesseract-devreference: https://tesseract-…...
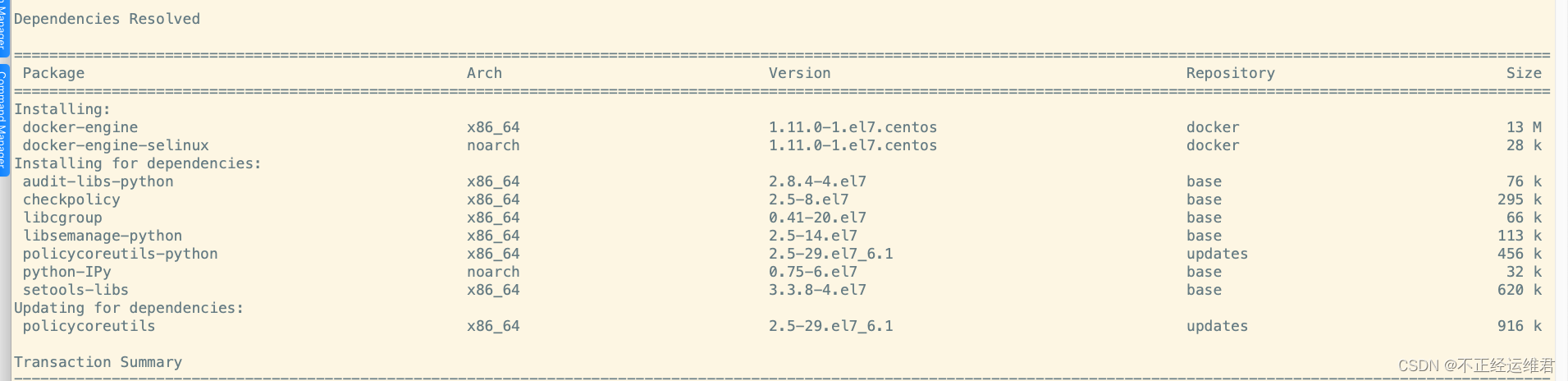
为适配kubelet:v0.4 安装指定版本的docker
系统版本信息 cat /etc/redhat-release CentOS Linux release 7.6.1810 (Core) iso 文件下载地址 https://vault.centos.org/7.6.1810/isos/x86_64/CentOS-7-x86_64-DVD-1810.iso0.4 版本的kubelet 报错信息记录 E0603 19:00:38.273720 44142 kubelet.go:734] Error synci…...

vivado CLOCK_REGION、CLOCK_ROOT
时钟区域 CLOCK_REGION属性用于将时钟缓冲区分配给 UltraScale设备,同时让Vivado放置程序将时钟缓冲区分配给最佳站点 在该区域内。 重要提示:对于UltraScale设备,不建议将时钟缓冲区固定到特定站点,因为 你可以在时钟上规划一个7…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...

想深耕网络安全行业,这些必备条件缺一不可
网络空间的攻防对抗日益激烈,网络安全已成为企业生存和国家安全的命脉,它负责构筑数字世界的坚固防线,保护核心资产与用户隐私免受侵害。 想要成为一名优秀的网络安全专家,除了敏锐的安全意识和高度的责任感,更需要锤…...
CI/CD流水线中的幽灵依赖——DeepSeek项目92%存在未声明的transitive risk,你中招了吗?
更多请点击: https://intelliparadigm.com 第一章:CI/CD流水线中的幽灵依赖——DeepSeek项目92%存在未声明的transitive risk,你中招了吗? 在现代CI/CD实践中,开发者常误以为 package.json 或 requirements.txt 中显式…...

动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿
动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Anim…...

别再只会用spline了!MATLAB csape函数详解:从自然边界到夹持边界的实战选择
MATLAB csape函数深度解析:从自然边界到夹持边界的工程实践 在工程仿真和科学计算领域,数据插值是一个永恒的话题。当我们面对一组离散的实验数据或仿真结果时,如何构建一条光滑的曲线来准确反映数据背后的物理规律?这个问题困扰…...

FM广播高精度预加重模块设计:解决传统电路缺陷,提升音质与信噪比
1. 项目概述:为什么FM广播需要高精度预加重?如果你玩过FM广播发射,或者对音频处理链路有点研究,大概率听说过“预加重”这个词。简单说,它就是在发射端人为提升高频信号电平的一个处理环节。欧洲标准是50微秒ÿ…...

温差发电驱动轻型电动车:热电模块与催化燃烧器的系统集成实践
1. 项目概述:用温差发电驱动轻型电动车最近在琢磨一个挺有意思的玩意儿:能不能给那些轻型的电动车,比如高尔夫球车、园区巡逻车或者小型载货三轮,换上一套不一样的“心脏”?传统的方案,要么背着一大块死沉死…...
)
保姆级教程:用Prometheus Operator在K8S里一键搞定监控全家桶(附Grafana仪表盘)
云原生监控革命:用Prometheus Operator构建K8S智能监控体系 当Kubernetes集群规模突破50个节点时,传统监控方案的维护成本会呈指数级增长。我曾亲眼见证一个电商团队在"黑五"大促期间,因为手动配置的Prometheus抓取规则失效&#x…...