WAWA鱼曲折的大学四年回忆录
声明:本文内容纯属个人主观臆断,如与事实不符,请参考事实
前言:
早想写一下大学四年的总结了,但总是感觉无从下手,不知道从哪里开始写,通过这篇文章主要想做一个记录,并从现在的认知和视角出发反思下大学期间哪些地方做的不好,可以及时纠正。会从每个阶段的认知和想法去进行分析和探讨,并思考如果现在回到那个时候会怎么做。
背景:
出生在河南贫困小县城的农村(地狱开局,劝大家早日逃离河南)
大学前没接触过编程(大学前word、excel等办公工具都不会用)
性格
星座
巨蟹座
学生时代
ISFJ型:保守、悲观、自卑、胆怯、不敢尝试
现在
ENTJ型:乐于尝试、积极活跃、但依旧悲观
上学期间
大一:
当时认知:
互联网一片大好,卷绩点+打ACM,退可保研985,进可去大厂拿高薪
实际
上学期,绩点卷到了3.7多,转了个专业去了主区
下学期,rank4进了实验室,但省赛选拔都没过,省赛无缘
现在看来
1、转专业多此一举,升学来讲,北区竞争小,更容易拿到保研名额,而且每年的前几名不少要转专业到主区的;就业来讲,北区进大厂的人数要多于主区,而且有专门的就业部门,会很早建群共享就业信息,同时管理相对松散,暑期容易出去实习。但主区的软工专业暑期是不放实习的(因为小学期要请培训班的老师来教学,郑州的培训班什么水平,懂的都懂,不在叙述)。
2、过于理想化,绩点和ACM很难兼顾,盲目认为自己可以取得不错的成绩,实际上,没天赋的,大学开始打ACM和高中打过NOI的有天壤之别,差距过大。同时ACM初级和中级别(区域铜及以下)的选手,无论保研还是就业性价比都太低。
现在来看,大一不转专业并all in绩点可能会更好一点,保研是性价比最高的一件事,如果拿到保研名额,进可就业,退可读研,岂不美哉。all in绩点的同时利用剩余时间打ACM也是不错的选择,因为算法题会一直伴随左右,所以大一整体规划其实还是不错的,就是绩点+ACM。
大二:
当时认知: 前期依旧是绩点+ACM竞赛,后边认为绩点竞争过于激烈,需要投入过多精力(因为本人翘课较多,因此平时分很差,所以要卷绩点的话,可能要花费较多精力挽回),同时认为即使保研也拿不到高rank,去不了较好的学校,因此选择完全放弃绩点,专心打ACM,毕业直接就业。
实际
大二上:还没有决定放弃卷绩点,一边卷绩点一边刷题打ACM,绩点依旧在保研范围的中等段位,同时ACM省赛选拔赛出线,去打了省赛,但打的很糟糕,只拿了一个铜牌;直到上学期数据结构考了70多分,导火索出现,绩点rank直接跌落在保研线上一点,因为近一年刷了非常多算法题,加上学了很多高级数据结构,自认为自己数据结构很好了,结果考题全是概念,无任何实操,拿了低分,让我非常厌恶,觉得卷绩点没有任何意义,直接放弃绩点。
大二下:课直接全翘掉了,专心刷题,同时拿到区域赛名额,但由于疫情,只能在少一名队友的情况下线上参赛,打的非常之烂,导致个人情绪非常差劲,意识到ACM可能并不适合自己,然后就陷入了很长一段时间的消极当中。
但大二做的比较好的事是开始写博客,记录知识点,事实证明写博客很有助于自己回顾知识,和反思。
现在看来
1、绩点是背概念背出来的,并不是技术或实操至上,更不需要去拓展知识边界,而是规则至上,应试至上,包括考题范围,历年试题等,完全借助于这些规则去刷高绩点,当时太愚蠢,依旧认为拓展知识边界就能拿高分,事实上压根就不会考,也没人能证明学的好。
2、在比赛上有个很大的问题是过于依赖算法课程和模板题,比赛打的太少,导致很多变种题依旧不会,本质还是缺乏实际锻炼
3、没有更好的控制情绪,在比赛打的很烂后,没有及时收住,而是一段时间内陷入非常消极的情绪中,并想放弃比赛,大二暑假基本没有训练,而是在学乱七八糟的东西
大二整体还好,但也是走下坡路的开始。如果让我现在回去,我可能还会放弃绩点,因为我是比较倔的人,我会日夜兼程的打各种ACM比赛,真的不想打铁了,不想给自己留下遗憾。
大三:
当时认知: 要准备准备找实习了,学的越多越好,先学下前端,在去学Java,计网和数据库
实际
大三上:大二下打完昆明后,就没怎么训练了,但依旧打了区域赛,因为疫情,线上赛队伍激增,难度激增,差了20min罚时遗憾拿铁牌,离奖牌最近的一次,非常遗憾。同时这个时候学了前端,Java后端,mysql,但都学的很浅且并没有确定技术路线,就是在瞎学。由于自己自卑的性格,也不敢投简历,觉得自己压根找不到工作,又看到互联网行情很差,整个人又一次陷入完全消极的心理当中,觉得毕业能去比亚迪拿个7、8k的薪资就不错了(因为当时23年,比亚迪是保底,深圳7500一个月),由于一直消极,其实学的很少,大多数时间在躺尸了。
大三下:过完年意识到不能再消极了,要赶紧学技术找实习了,此时定了自己的技术栈,做C++开发,实际上我这届的C++开发,工作极其难找。然后花了1500买了一个webserver的教程(事实证明极其不划算,这个项目没什么用,还不如背背八股文),找实习刚开始不敢投简历,3,4月份正值大厂招实习时也没敢投,5月份投简历时,只剩下小公司了,然后约了面试回答也结结巴巴,好在一家公司问的问题我都会,然后过了面试,拿到了offer,开始了第一段实习。
现在看来
大三是大学规划最差的一年
1、技术栈学的乱七八糟,从前端,Java后端,数据库,C++,服务器,到后来的音视频开发实习,大模型SDK,学的乱七八糟,但没任何一个技术栈深入进去的
2、性格问题极其严重,过于胆怯自卑,不敢尝试,有ACM实验室这么好的信息资源聚集地,却不敢开口问就业,不敢找学长私聊,找实习时更是不敢投简历,面试时更是不自信,回答结结巴巴,自我认知非常不到位,一直以为自己找不到工作。现在看真的有被自己气到,有什么不敢尝试的,有什么消极的,多大点事。。。
大三是很关键的一年,最好在大三上定位好自己的技术栈方向,然后深耕其中,比如我是做C++的,我会回去把Linux内核的源码好好扒出来看一看,而不是学什么前端和Java,方向不知道的话,一定要开口多问,学长们其实都是很友好的,很乐意分享自己的观点,在找实习前,一定要把自己基础打好,最好简历上有一定的亮点,这样后边进好公司的概率就会大大增加。
实习后:
第一段实习 — 深圳市麦谷科技 C++音视频开发
性格依旧内向,但好在同事们都非常好,在这家公司实习除了学习了很多音视频相关的知识以外,把整个公司的架构摸清楚了,商业模式也弄懂了一点,对正常的工作流程也有了一些认知。
离职时把图表整理出来了。


第二段实习 — 科大讯飞 C++大模型SDK开发
这段实习给我带来了非常多的收获,在这里再次感谢我在讯飞的老大锋哥,收获在离职后也总结出来了


第三段实习 — 小米 C++浏览器内核开发
校招拿到offer,提前去实习,这倒没什么好说的,只能说遇到了一个很好的团队。
总结
回头看,发现已经走过那么长的路了,尽管大多数时刻都未能得偿所愿,但都做了当下认为最正确的选择,虽有遗憾不甘,但始终如一,不断朝自己目标靠近。
大学四年的收获,转换成五句话就是:
1、做一个长期主义者,沉下心去,保持专注
2、热爱技术,深入技术,有技术追求
3、丢掉胆怯和自卑,内心坚定,勇于尝试,抓住机会,不留遗憾
4、多问,多交流,多做,多思考
5、保持活跃,尽可能的展示自己,贡献自己的力量
相关文章:
WAWA鱼曲折的大学四年回忆录
声明:本文内容纯属个人主观臆断,如与事实不符,请参考事实 前言: 早想写一下大学四年的总结了,但总是感觉无从下手,不知道从哪里开始写,通过这篇文章主要想做一个记录,并从现在的认…...

Go 依赖注入设计模式
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

使用React复刻ThreeJS官网示例——keyframes动画
最近在看three.js相关的东西,想着学习一下threejs给的examples。源码是用html结合js写的,恰好最近也在学习react,就用react框架学习一下。 本文参考的是threeJs给的第一个示例 three.js examples (threejs.org) 一、下载threeJS源码 通常我们…...
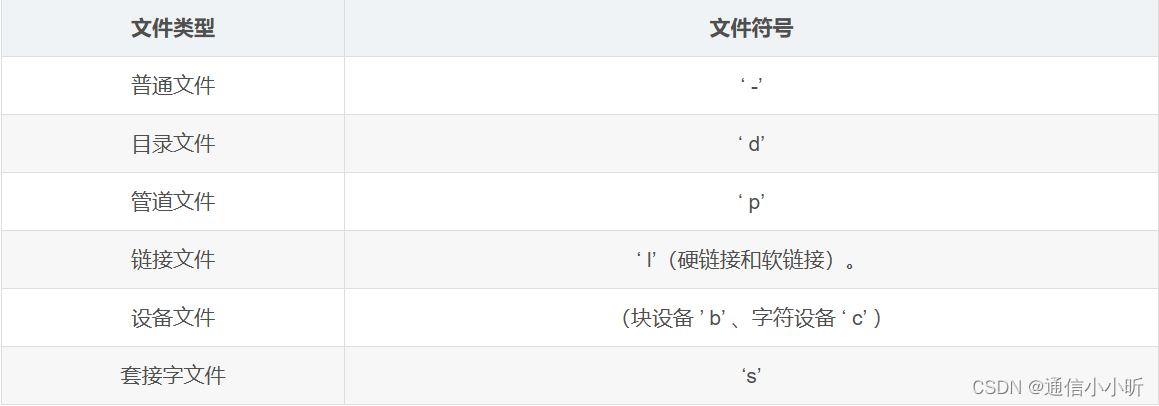
嵌入式linux面试1
1. linux 1.1. Window系统和Linux系统的区别 linux区分大小写windows在dos(磁盘操作系统)界面命令下不区分大小写; 1.2. 文件格式区分 windows用扩展名区分文件;如.exe代表执行文件,.txt代表文本文件,.…...

智能交通(3)——Learning Phase Competition for Traffic Signal Control
论文分享 https://dl.acm.org/doi/pdf/10.1145/3357384.3357900https://dl.acm.org/doi/pdf/10.1145/3357384.3357900 论文代码 https://github.com/gjzheng93/frap-pubhttps://github.com/gjzheng93/frap-pub 摘要 越来越多可用的城市数据和先进的学习技术使人们能够提…...

【扩散模型】LCM LoRA:一个通用的Stable Diffusion加速模块
潜在一致性模型:[2310.04378] Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference (arxiv.org) 原文:Paper page - Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference (…...

【PYG】pytorch中size和shape有什么不同
一般使用tensor.shape打印维度信息,因为简单直接 在 PyTorch 中,size 和 shape 都用于获取张量的维度信息,但它们之间有细微的区别。下面是它们的定义和用法: size: size 是一个方法(size())和…...

备份服务器出错怎么办?
在企业的日常运营中,备份服务器扮演着至关重要的角色,它确保了数据的安全和业务的连续性。然而,备份服务器也可能遇到各种问题,如备份失败、数据损坏或备份系统故障等。这些问题可能导致数据丢失或业务中断,给企业带来…...

数据库(表)
要求如下: 一:数据库 1,登录数据库 mysql -uroot -p123123 2,创建数据库zoo create database zoo; Query OK, 1 row affected (0.01 sec) 3,修改字符集 mysql> use zoo;---先进入数据库zoo Database changed …...

Feign-未完成
Feign Java中如何实现接口调用?即如何发起http请求 前三种方式比较麻烦,在发起请求前,需要将Java对象进行序列化转为json格式的数据,才能发送,然后进行响应时,还需要把json数据进行反序列化成java对象。 …...

# [0705] Task06 DDPG 算法、PPO 算法、SAC 算法【理论 only】
easy-rl PDF版本 笔记整理 P5、P10 - P12 joyrl 比对 补充 P11 - P13 OpenAI 文档整理 ⭐ https://spinningup.openai.com/en/latest/index.html 最新版PDF下载 地址:https://github.com/datawhalechina/easy-rl/releases 国内地址(推荐国内读者使用): 链…...

Open3D 点云CPD算法配准(粗配准)
目录 一、概述 二、代码实现 2.1关键函数 2.2完整代码 三、实现效果 3.1原始点云 3.2配准后点云 一、概述 在Open3D中,CPD(Coherent Point Drift,一致性点漂移)算法是一种经典的点云配准方法,适用于无序点云的非…...
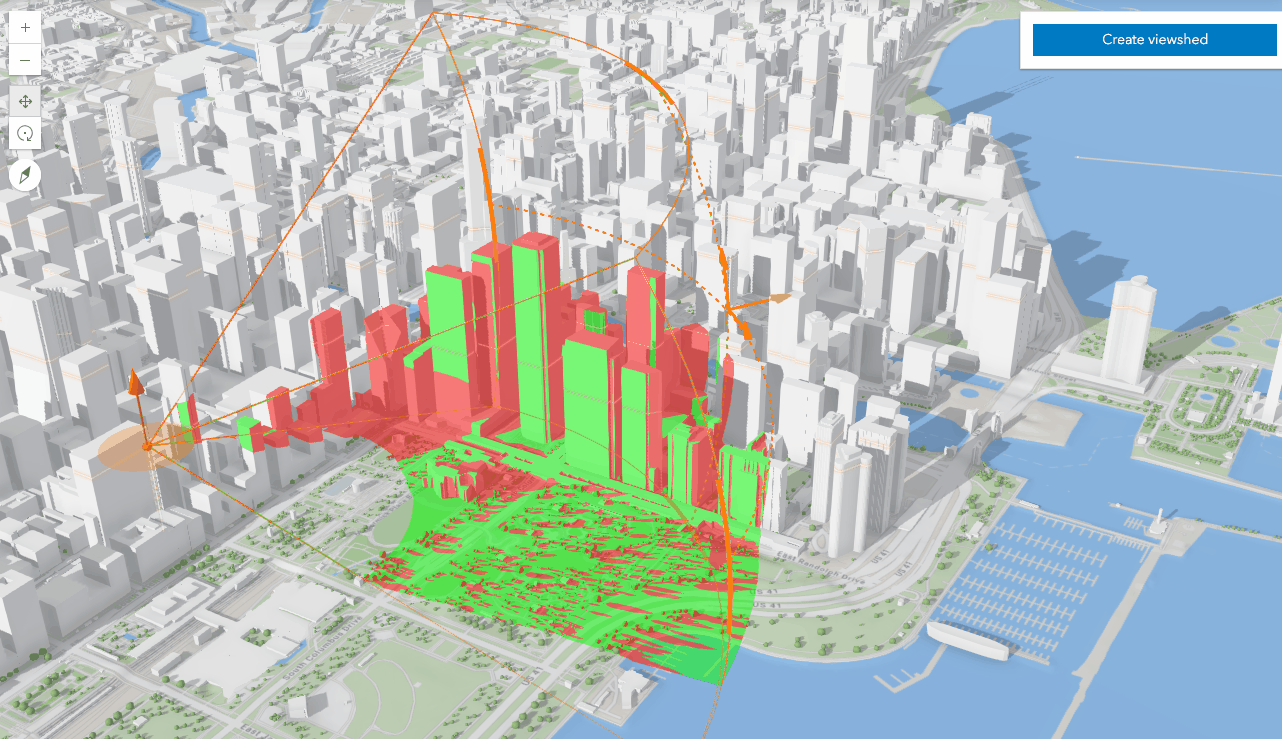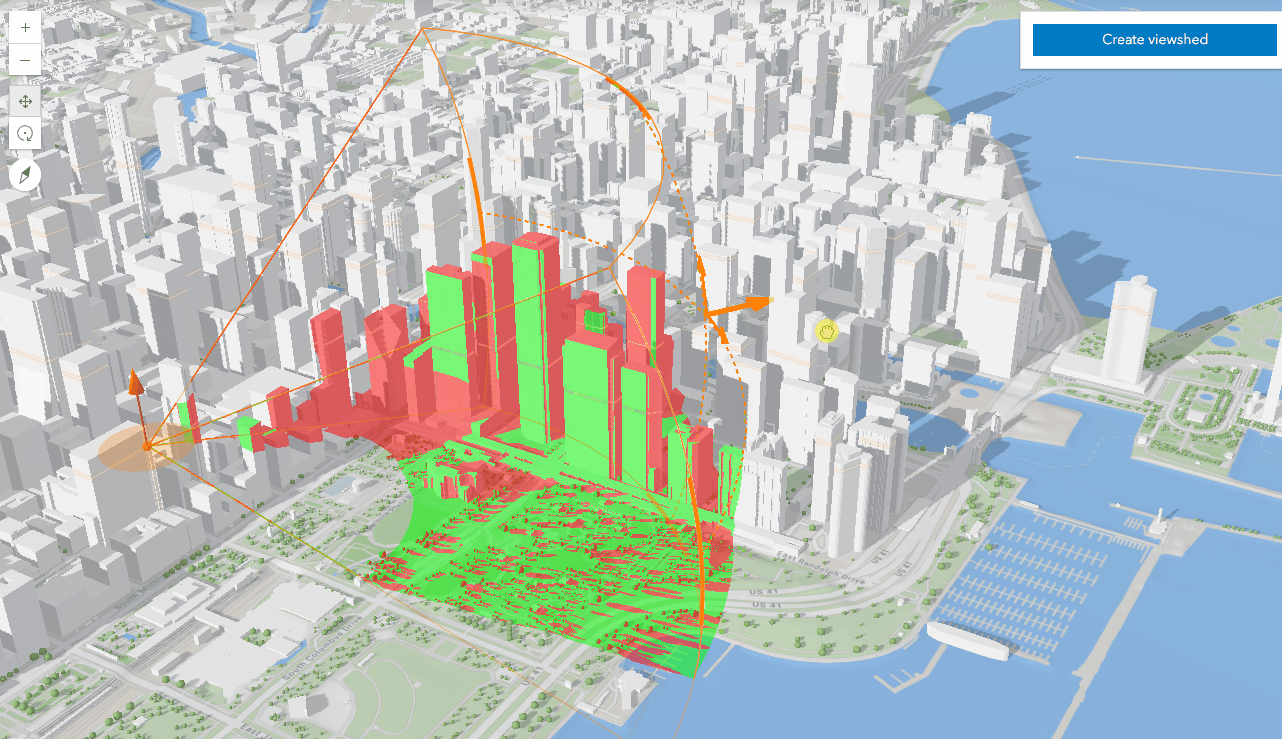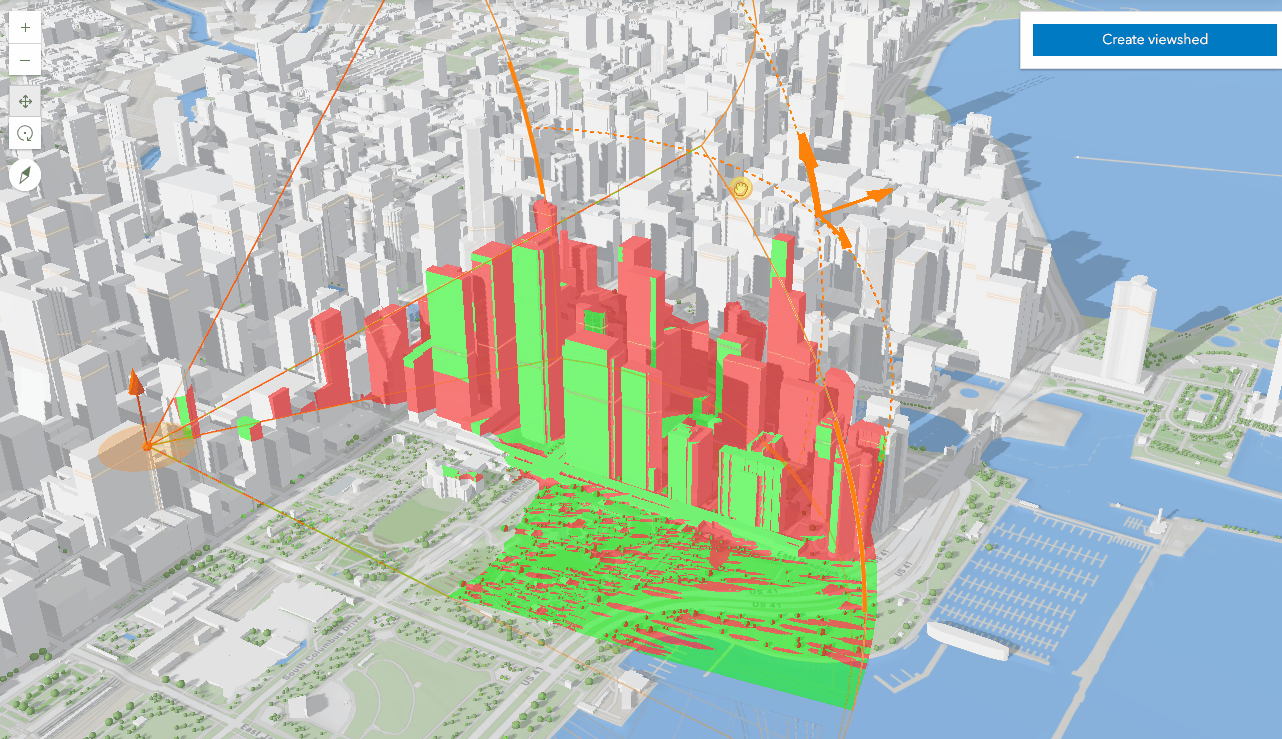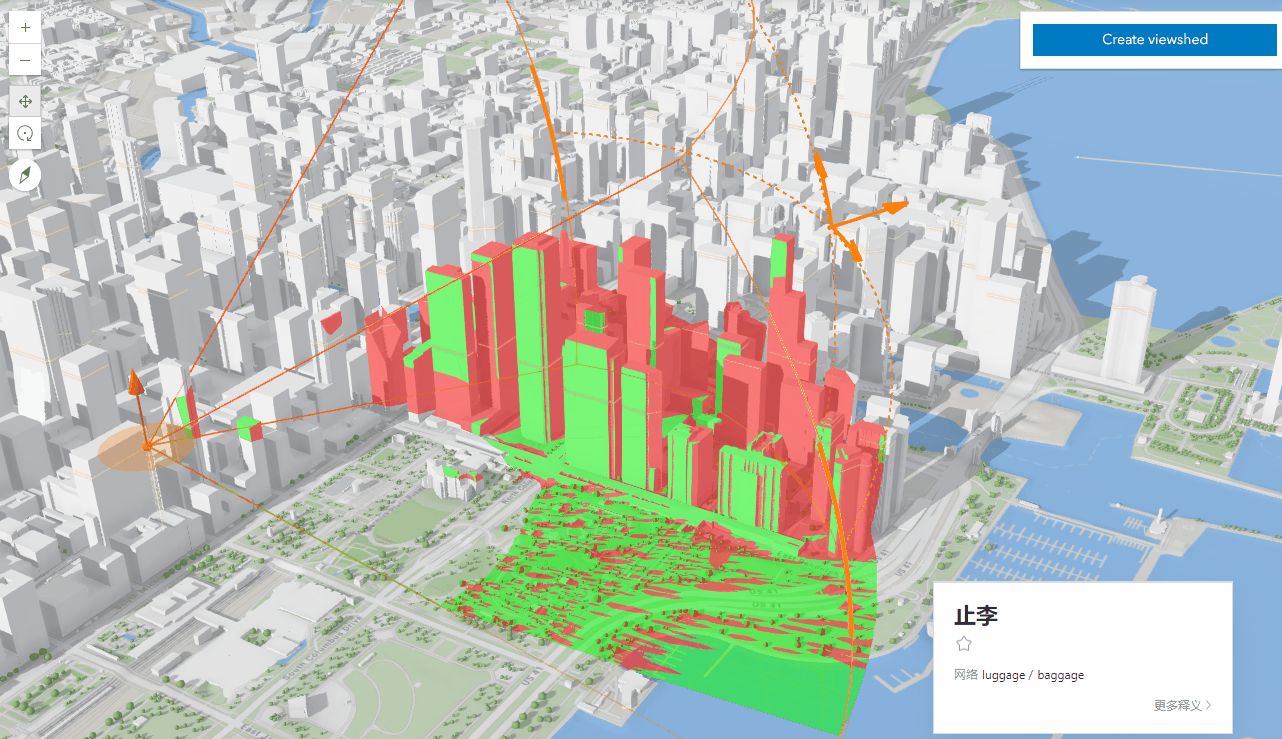
04-ArcGIS For JavaScript的可视域分析功能
文章目录 综述代码实现代码解析结果 综述 在数字孪生或者实景三维的项目中,视频融合和可视域分析,一直都是热点问题。Cesium中,支持对阴影的后处理操作,通过重新编写GLSL代码就能实现视域和视频融合的功能。ArcGIS之前支持的可视…...

Nestjs基础
一、创建项目 1、创建 安装 Nest CLI(只需要安装一次) npm i -g nestjs/cli 进入要创建项目的目录,使用 Nest CLI 创建项目 nest new 项目名 运行项目 npm run start 开发环境下运行,自动刷新服务 npm run start:dev 2、…...

DDL:针对于数据库、数据表、数据字段的操作
数据库的操作 # 查询所有数据 SHOW DATABASE; #创建数据库 CREATE DATABASE 2404javaee; #删除数据库 DROP DATABASE 2404javaee; 数据表的操作 #创建表 CREATE TABLE s_student( name VARCHAR(64), s_sex VARCHAR(32), age INT(3), salary FLOAT(8,2), c_course VARC…...
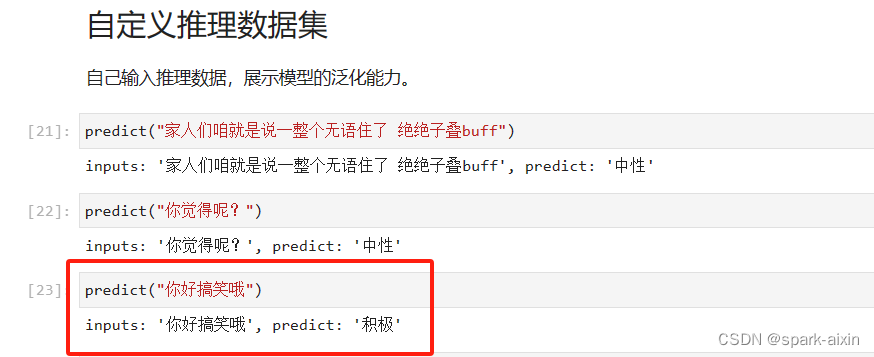
昇思学习打卡-5-基于Mindspore实现BERT对话情绪识别
本章节学习一个基本实践–基于Mindspore实现BERT对话情绪识别 自然语言处理任务的应用很广泛,如预训练语言模型例如问答、自然语言推理、命名实体识别与文本分类、搜索引擎优化、机器翻译、语音识别与合成、情感分析、聊天机器人与虚拟助手、文本摘要与生成、信息抽…...
 List中增删改查的注意事项)
Java中 普通for循环, 增强for循环( foreach) List中增删改查的注意事项
文章目录 俩种循环遍历增加删除1 根据index删除2 根据对象删除 修改 俩种循环 Java中 普通for循环, 增强for循环( foreach) 俩种List的遍历方式有何异同,性能差异? 普通for循环(使用索引遍历): for (int…...
昇思25天学习打卡营第19天|LSTM+CRF序列标注
概述 序列标注指给定输入序列,给序列中每个Token进行标注标签的过程。序列标注问题通常用于从文本中进行信息抽取,包括分词(Word Segmentation)、词性标注(Position Tagging)、命名实体识别(Named Entity Recognition, NER)等。 条件随机场(…...

微服务: 初识 Spring Cloud
什么是微服务? 微服务就像把一个大公司拆成很多小部门,每个部门各自负责一块业务。这样一来,每个部门都可以独立工作,即使一个部门出了问题,也不会影响整个公司运作。 什么是Spring Cloud? Spring Cloud 是一套工具包&#x…...

探索InitializingBean:Spring框架中的隐藏宝藏
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》《MYSQL》 💪🏻 制定明确可量化的目标,坚持默默的做事。 ✨欢迎加入探索MYSQL索引数据结构之旅✨ 👋 Spring框架的浩瀚海洋中&#x…...

AI手势识别效果展示:彩虹骨骼惊艳可视化,21个关键点精准定位
AI手势识别效果展示:彩虹骨骼惊艳可视化,21个关键点精准定位 1. 引言:手势识别的视觉革命 想象一下,只需对着摄像头比个手势,就能控制智能家居、玩转AR游戏或者进行远程教学互动。这一切的核心技术就是手势识别。传统…...

C++ 模板参数推导机制剖析
C 模板参数推导机制剖析 C的模板参数推导是泛型编程的核心机制之一,它允许编译器在调用模板函数或类时自动推断类型参数,从而减少冗余代码并提升开发效率。理解这一机制不仅能帮助开发者编写更灵活的代码,还能避免因类型推导错误导致的编译问…...

3大核心功能解决B站资源保存难题:BiliTools跨平台工具箱深度评测
3大核心功能解决B站资源保存难题:BiliTools跨平台工具箱深度评测 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTo…...

小米智能家居与Home Assistant集成实战指南:从功能解析到问题诊断完全解析
小米智能家居与Home Assistant集成实战指南:从功能解析到问题诊断完全解析 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home 小米智能家居集成项目࿰…...

安全是跑出来的:从萝卜快跑看自动驾驶的“成人礼”
近日,武汉市区部分“萝卜快跑”自动驾驶车辆出现突发停驶异常状况,部分车辆在道路上停止运行,导致乘客被困、交通受阻。官方通报显示,此次事件为系统故障触发的车辆停滞,所有乘客已安全撤离,无人员伤亡。作…...

【MicroPython编程-ESP32篇:设备驱动】-PCF8591数据采集驱动
PCF8591数据采集驱动 文章目录 PCF8591数据采集驱动 1、PCF8591介绍 2、软件准备 3、硬件准备与接线 4、程序实现 4.1 PCF8591驱动实现 4.2 主程序 1、PCF8591介绍 PCF8591 是一款单片集成、独立电源、低功耗、8 位 CMOS 数据采集设备。 PCF8591 具有四个模拟输入、一个模拟输…...

`android.hardware.camera2.params` 是 Android Camera2 API 中用于封装相机参数配置的包
android.hardware.camera2.params 是 Android Camera2 API 中用于封装相机参数配置的包,主要包含与相机捕获请求(CaptureRequest)和输出结果(CaptureResult)相关的参数类。这些类定义了各种可配置的相机控制参数&#…...

BsMax:让Blender工作效率翻倍的终极插件指南
BsMax:让Blender工作效率翻倍的终极插件指南 【免费下载链接】BsMax BsMax Blender Addon (UI simulator/ Modeling/ Rigg & Animation/ Render Tools and ... 项目地址: https://gitcode.com/gh_mirrors/bs/BsMax 还在为Blender的学习曲线而烦恼吗&…...

千问3.5-2B应用场景:高校实验报告图解、科研论文插图说明生成、技术文档辅助
千问3.5-2B应用场景:高校实验报告图解、科研论文插图说明生成、技术文档辅助 1. 千问3.5-2B模型简介 千问3.5-2B是Qwen系列中的小型视觉语言模型,专为图片理解与文本生成任务设计。这个模型的核心能力在于:你上传一张图片,再输入…...

抖音批量下载工具终极指南:从零开始掌握高效内容采集
抖音批量下载工具终极指南:从零开始掌握高效内容采集 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...